Avant d’aborder le sujet de Spring Boot, il est important de comprendre les notions nécessaires à la compréhension de Spring.
Spring est un Framework applicatif, il permet de faciliter le développement d’applications. Spring est né de l'idée de fournir une solution plus simple et plus légère que celle proposée par Java EE. C'est pour cette raison que Spring a été initialement désigné comme un conteneur léger.
L'idée principale de Spring est de proposer un framework qui utilise de simples POJO pour développer des applications plutôt que d'utiliser des EJB complexes dans un conteneur.
Il se repose sur 2 motifs de conception l’inversion de contrôle (IoC) et la programmation orientée aspect (AOP).
Aujourd’hui Spring est à la version 5. de la version 4 à la version 5, Spring a été réécrit en Java 8. Il n’est pas possible d’utiliser Spring 5 avec une version antérieur à Java 8.
Spring Framework comporte plusieurs modules, les principaux sont les suivants :
Il contient tous les éléments nécessaires à la gestion des conteneurs Spring et la gestion des Bean Spring. Il est composé des modules Core, Beans, Context, Spel.
-
Spring Core : Fonctionnalités fondamentales en plus de l'IoC et l'injection de Dépendence.
-
Spring Beans : Fournit l'interface BeanFactory, et donc le framework de configuration et les fonctionnalités de base.
-
Spring Context : Fournit l'interface ApplicationContext, qui représente le conteneur IoC de Spring, ajoute des fonctionnalités plus "enterprise-specific".
-
Spring SpEl (Spring Expression Langage) : Langage d'expression de Spring.
- Spring AOP : L’AOP permet de mettre en place facilement différents fonctionnalités dans une application. On appel ces applications des “Advices”.
Spring repose également sur le pattern Proxy. Un objet de type proxy remplace un autre objet réel. Son rôle est de de gérer la création de l’objet réel et ses accès. Tant que le client n’a pas réellement besoin de l’objet réel, le proxy ne le crée pas. L’instanciation de cet objet réel à un coût de performance très élevé.
-
Spring Data: Comprend les modules nécessaires pour interagir avec la base de données. Spring JDBC, Spring ORM, Spring JPA. Ce module permet d’interagir avec des bases de données relationnelles et non-relationnelles.
-
Spring Batch : module de gestion des opérations batch (intéressant dans le cadre de la planification de tâches par exemple)
-
Spring Security : Framework de gestion de sécurité (mécanisme d'authentification, identification, etc.)
-
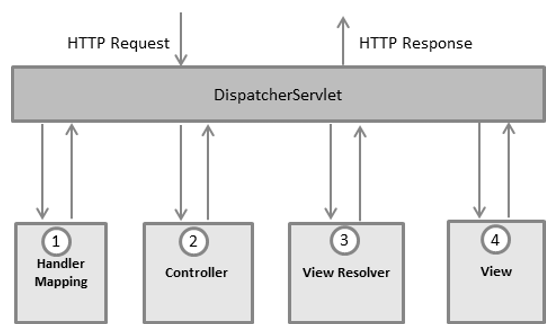
Spring MVC : Spring MVC est un Framework qui permet d’implémenter des applications selon le design pattern MVC. Spring MVC se base sur le principe décrit par le schéma ci-dessous :
-
Après avoir reçu une requête HTTP, DispatchServlet consulte le HandlerMapping pour appeler le Controller approprié.
-
Le Controller analyse la requête et appelle le la méthode du service appropriée, basé l’utilisation des méthodes POST ou GET. La méthode du service initialisera les données du model sur la base d’une logique business puis retournera le nom de la vue à la DispatcherServlet
-
La DispatcherServlet s’appuiera sur le ViewResolver pour choisir la bonne vue pour la requête
-
Une fois que la vue est finalisée, la DispatcherServlet passe les données du model à la vue, cette dernière étant finalement affichée sur le navigateur.
Tous les composants mentionnés ci-dessus (HandlerMapping, Controller et ViewResolver) font partis du WebApplicationContext, lequel est une extension du ApplicationContext auquel on a ajouté quelques caractéristiques supplémentaires pour les applications web.
Il existe 2 façons d’utiliser et de configurer Spring. Avec des Annotations ou en XML Pour profiter au maximum de la simplification d’écriture du code, on utilise des annotations. Les annotations à connaître sont les suivantes :
- Il ne faut pas mélanger du XML avec des Annotations. C'est soit l'un, soit l'autre.
Spring permet d'écrire simplement du code à l'aide d'annotations. L'annotation facilite l'écriture, mais il est très important de connaître ce qu'il se cache derrière une annotation. Sinon les performances et même la sécurité s'en retrouveront impactées.
| Annotation | Descriptions |
|---|---|
@Component |
Permet de définir des classes en tant que Bean Spring |
@Controller |
Stéréotype pour les classes de contrôleurs |
@Service |
Stereotype pour les classes de service dans la couche métier |
@Repository |
Stereotype pour les classes Data Access Object (DAO) |
@RequestMapping |
(Deprecated )Pour configurer le mappage URI dans les méthodes de gestionnaire de contrôleur. Ceci est une annotation très importante, vous devriez donc passer par Spring MVC RequestMapping |
@GetMapping |
Pour configurer le mappage URI dans les méthodes de gestionnaire de contrôleur. Cette annotation est utilisée pour les opérations GET (Récupération d’une ressource) |
@PutMapping |
Pour configurer le mappage URI dans les méthodes de gestionnaire de contrôleur. Cette annotation est utilisée pour les opérations Put (Ajout d’une ressource) |
@PostMapping |
Pour configurer le mappage URI dans les méthodes de gestionnaire de contrôleur. Cette annotation est utilisée pour les opérations POST (Modification d’une ressource) |
@DeleteMapping |
Pour configurer le mappage URI dans les méthodes de gestionnaire de contrôleur. Cette annotation est utilisée pour les opérations DELETE (Suppression d’une ressource) |
@ResponseBody |
Pour envoyer un objet en réponse, généralement pour envoyer des données XML ou JSON en réponse |
@PathVariable |
Pour mapper les valeurs dynamiques de l'URI aux arguments de la méthode de gestion. |
@Qualifier |
Il permet de spécifier le nom du bean annoté Avec l'annotation @Autowired pour éviter toute confusion lorsque plusieurs instances de type bean sont présentes et ont le même nom |
@Scope |
Permet de préciser le cycle de vie du bean. Elle s'applique sur une classe. Les valeurs utilisables sont : singleton (Une seule instance de ce bean sera managé), prototype (recréé une instance du bean à chaque fois qu'il est sollicité), session () et request. Ces deux dernières ne sont utilisables que dans des applications web. L'annotation @Scope permet de préciser une portée différente de singleton (Portée par défaut). |
@Configuration |
Cette annotation est utilisée dans une classe qui définit les beans |
@ComponentScan |
Cette annotation est utilisée avec les classes annotées @Configuration. Elle permet de spécifier dans quels packages Spring doit chercher la présence de beans. Dans les projets conséquents il est conseillé de spécifier les répertoires où se trouvent les beans. Sinon, Spring scanera tout le projet inutilement, et le temps de démarrage sera impacté |
@Bean |
Fonctionne dans les classes annotées @Configuration. Elle permet de définir des Beans de type Spring. L’annotation @Bean s’applique sur des méthodes |
@Value |
Cette annotation placée sur un champ d’une classe, permet d’initialiser la valeur du champ à partir d’un fichier de propriété. On utilise cette annotation lorsque le champ est dépendant d’un environnement (ou profil). (ex. Env d’intégration, de recette, de prod) |
@Required |
Cette annotation est utilisée sur les propriétés d’un bean |
@Autowired |
Permet à Spring de résoudre les injections de dépendances. Il existe plusieurs facon d'injecter un bean, et l'annotation @Autowired devient déprécated. Privilégier l'injection par constructeur. exemple Injection par champ (Annotation @Autowired) |
@Lazy |
Cette annotation est utilisée sur des classes annotées @Component. Par défaut Spring instantie tous les beans au démarrage. Annoter @Lazy sur un @Component, permet de créer et d’initialiser le Bean qu’à la première nécessité |
A noter : Les annotations Controller / Service / Repository sont des extensions de @Component.
NB : Différence entre Injection par champ et injection par annotation :
//Bean a injecter.
//Injection par champ
@Autowired
private final IngredientService ingredientService;
public IngredientController() {
}
exemple injection par constructeur
//Bean a injecter
private final IngredientService ingredientService;
//Injection par constructeur
public IngredientController(IngredientService ingredientService) {
this.ingredientService = ingredientService;
}

-
Controller Based Nous pouvons définir des méthodes de gestion des exceptions dans nos classes de contrôleur. Tout ce dont nous avons besoin est d'annoter ces méthodes avec l'annotation @ExceptionHandler.
-
Global Exception Handler La gestion des exceptions est une préoccupation transversale et Spring fournit une annotation @ControllerAdvice que nous pouvons utiliser avec n'importe quelle classe pour définir notre gestionnaire d'exceptions global.
-
HandlerExceptionResolver Pour les exceptions génériques, nous servons la plupart du temps des pages statiques. Spring Framework fournit l'interface HandlerExceptionResolver que nous pouvons implémenter pour créer un gestionnaire d'exception global. La raison derrière cette méthode supplémentaire de définition du gestionnaire d’exception global est que Spring Framework fournit également des classes d’implémentation par défaut que nous pouvons définir dans notre fichier de configuration du bean Spring afin d’obtenir des avantages en matière de gestion des exceptions.
Maintenant que vous êtes familier avec les modules Spring. Nous allons voir plus en détails les raisons de l’utilisation du module Spring Boot.
Spring Boot est un projet ou un micro framework qui a pour but de faciliter la création d’application Spring standalone et de s’abstraire de toute la configuration de base, redondante qui permet le démarrage d’une application Spring. De plus il permet de réduire le temps alloué au démarrage d’un projet.
Les fonctionnalités qui lui sont propre sont les suivantes :
- Créer une application Spring standalone
- Embarquer directement dans l’application un serveur d’application (Tomcat /Jetty /...)
- Ajouter les dépendances nécessaires à l’utilisation de Spring
- Configurer automatiquement Spring (configuration de base)
- Ajouter des fonctionnalités telles que les métriques, (Health check), Externaliser la configuration …
Pour arriver à remplir cet objectif, Spring Boot se base sur plusieurs éléments :
Un site web start spring.io qui vous permet de générer rapidement la structure de votre projet en y incluant toutes les dépendances Maven nécessaires à votre application. Cette génération est aussi disponible via le plugin Eclipse STS. L’utilisation de Starters pour gérer les dépendances. Par exemple si vous voulez ajouter toutes les dépendances pour gérer la sécurité il suffit d’ajouter le starter “spring-boot-starter-security”.
L’auto-configuration, qui applique une configuration par défaut au démarrage de votre application pour toutes dépendances présentes dans celle-ci. Cette configuration s’active à partir du moment où vous avez annoté votre application avec @EnableAutoConfiguration ou @SpringBootApplication. Bien entendu cette configuration peut-être surchargée via des propriétés Spring prédéfinie ou via une configuration Java. L’auto-configuration simplifie la configuration sans pour autant vous restreindre dans les fonctionnalités de Spring. Par exemple, si vous utilisez le starter « spring-boot-starter-security », Spring Boot vous configurera la sécurité dans votre application avec notamment un utilisateur par défaut et un mot de passe généré aléatoirement au démarrage de votre application.
Enfin, Spring Boot met à disposition des opérationnels, des métriques qu’ils peuvent suivre une fois l’application déployée en production. Pour cela Spring Boot utilise « Actuator » qui est un système qui permet de monitorer une application via des URLs spécifiques ou des commandes disponibles via SSH. Sachez, qu’il est possible de définir vos propres indicateurs très facilement.
Voici une liste non exhaustive des indicateurs disponibles par défaut :
| nom de la metric | description |
|---|---|
| metrics | métriques de l’application (CPU, mémoire, …) |
| beans | liste des BEANs Spring |
| trace | liste des requêtes HTTP envoyées à l’application |
| dump | liste des threads en cours |
| health | état de santé de l’application |
| env | liste des profils, des propriétés et des variables d’environnement |
De la même façon qu’avec Spring, il existe des annotations à connaître. La liste est la suivante :
| annotation | description |
|---|---|
@ComponentScan |
Permet de scanner tous les composants dans le package et sous package des répertoires indiqués |
@EnableAutoConfiguration |
Une auto-configuration est une classe de configuration (annoté par @Configuration) qui ne sera pas scannée mais listée dans un fichier spécial (META-INF/spring.factories).En activant l’auto configuration, Boot essayera de configurer l’application, en se basant sur les dépendances définies dans l’application. |
@SpringBootApplication |
l'équivalent des annotations @EnableAutoConfiguration et @ComponentScan. On annote la classe possédant la méthode "main", point d'entrée de l'application |
H2 est une base de données relationnelle écrite en Java.
Cette base de données ultra-légère n'est pas conçue pour supporter de gros volumes de données ni un nombre important d'utilisateurs, mais elle est extrêmement pratique pour les développeurs Java qui ont besoin de tester des applications ou des composants nécessitants des requêtes SQL via JDBC.
H2 présente de nombreux avantages :
- légèreté: elle tient dans un fichier "zip" de 7 mo (y compris les sources et la documentation)
- portabilité: elle est constituée d'un seul fichier "jar" qui peut être exécuté sur tout système d'exploitation disposant de Java
- fonctionnalités: H2 dispose des mêmes possibilités que les "grandes bases de données" (schémas multiples, contrôle d'intégrité référentielle, triggers, fonctions, procédures stockés, colonnes auto-incrémentées, séquences, etc)
- différents modes de fonctionnement: client/serveur ou embarqué
H2 permet de stocker les données d'une base soit en mémoire, soit sur disque. L'emplacement est déterminé lors de la connexion par la dernière partie de l'URL JDBC:

La dépendance H2 est la suivante :
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
Hibernate est une solution open source de type ORM (Object Relational Mapping) qui permet de faciliter le développement de la couche persistance d'une application. Hibernate permet donc de représenter une base de données en objets Java et vice versa.
Hibernate facilite la persistance et la recherche de données dans une base de données en réalisant lui-même la création des objets et les traitements de remplissage de ceux-ci en accédant à la base de données. La quantité de code ainsi épargnée est très importante d'autant que ce code est généralement fastidieux et redondant.
Hibernate est très populaire notamment à cause de ses bonnes performances et de son ouverture à de nombreuses bases de données.

Hibernate fournit un langage d'interrogation extrêmement puissant qui ressemble (et c'est voulu) au SQL. Mais ne soyez pas dupe de la syntaxe ; HQL est totalement orienté objet, cernant des notions comme l'héritage, le polymorphisme et les associations.
HQL respecte les paramètres lazy des mappings et garantit que ce que vous voulez charger est chargé. Cela signifie qu'une requête HQL peut entraîner plusieurs instructions SQL SELECT immédiates pour extraire le sous-graphe avec toutes les associations et collections mappées non lazy.
L'interface Criteria représente une requête sur une classe persistante donnée. La Session fournit les instances de Criteria.
Criteria respecte les paramètres lazy des mappings et garantit que ce que vous voulez charger est chargé. Cela signifie qu'une requête Criteria peut générer plusieurs instructions SELECT SQL immédiates pour extraire le sous-graphe avec toutes les associations et collections mappées non Lazy.
Les requêtes de Criteria respectent également complètement la stratégie de récupération (join vs select vs subselect).
Querydsl est né de la nécessité de maintenir les requêtes HQL typesafe. La construction incrémentielle de requêtes HQL nécessite la concaténation de chaînes et génère un code difficile à lire. Les références non sûres aux types de domaine et aux propriétés via des chaînes simples constituaient un autre problème avec la construction HQL basée sur String.
Avec un domaine en évolution, des types de modèles typesafe apportent d’énormes avantages au développement logiciel. Les modifications de domaine sont directement reflétées dans les requêtes et la saisie semi-automatique dans la construction de la requête accélère et sécurise la construction de la requête.
HQL pour Hibernate était le premier langage cible de Querydsl, mais de nos jours, il prend en charge JPA, JDO, JDBC, Lucene, Hibernate Search, MongoDB, Collections et RDFBean.
Spring Data JPA, qui fait partie de la plus grande famille Spring Data, facilite la mise en œuvre de référentiels basés sur JPA. Ce module traite de la prise en charge améliorée des couches d’accès aux données basées sur JPA. Cela facilite la création d'applications utilisant Spring, qui utilisent les technologies d'accès aux données.
L'implémentation d'une couche d'accès aux données d'une application est une tâche fastidieuse. Trop de code boilerplate doit être écrit pour exécuter des requêtes simples ainsi que pour effectuer la pagination et l'audit. Spring Data JPA vise à améliorer de manière significative la mise en œuvre des couches d’accès aux données en réduisant l’effort au niveau réellement requis. En tant que développeur, vous écrivez vos interfaces de référentiel, y compris des méthodes de recherche personnalisées, et Spring assurera automatiquement la mise en œuvre. Notamment avec la mise en place « automatique » d’un CRUD et de pagination.
Vous trouverez ci-dessous les annotations qui sont couramment utilisées pour mapper des entités du modèle aux entités de la base de données.
| Annotation | Rôle |
|---|---|
| @javax.persistence.Table | Préciser le nom de la table concernée par le mapping |
| @javax.persistence.Column | Associer un champ de la table à la propriété (à utiliser sur un getter) |
| @javax.persistence.Id | Associer un champ de la table à la propriété en tant que clé primaire (à utiliser sur un getter) |
| @javax.persistence.GeneratedValue | Demander la génération automatique de la clé primaire au besoin |
| @javax.persistence.Basic | Représenter la forme de mapping la plus simple. Cette annotation est utilisée par défaut |
Les objets Hibernate peuvent posséder à un instant donné l’un des trois états suivants :
- transient : Une nouvelle instance d’une classe persistante, qui n’est pas associée à une Session et n’a ni d’identifiant, ni de réprésentation dans la base de données.
- persistent : Vous pouvez rendre persitente une instance transient en l'associant à une session. Une instance persistante a une représentation dans la base de données, un identifiant et est associée à une Session.
- detached : Une fois la session Hibernate fermée, l’instance persistante deviendra une instance détachée.
| Get() | Load() |
|---|---|
| Si objet non trouvé: Retourne null | Si objet non trouvé : Throws ObjectNotFoundException |
| Fait appel à la base de données | Ne fait pas appel à la base de données |
| Retourne l’objet réel | Retourne un Proxy |
| A utiliser dans le cas où l’on n’est pas sûr de l’existence d’un objet | A utiliser dans le cas où l’on est sûr de l’existence d’un objet |
Eager : On effectue la jointure sql, dès que l'on récupère l'objet et donc initialise la collection.
Lazy : On n'effectue la jointure sql que à la demande, c'est à dire dès que l'on aura besoin de la collection.
Mise en cache au niveau de la session (premier niveau): la mise en cache au niveau de la session est mise en œuvre par Hibernate en tant que niveau de mise en cache par défaut. Cette mise en cache permet de mettre en cache des objets dans la session. Ces objets mis en cache résident dans la mémoire de session elle-même.
Cache de second niveau: le cache de second niveau est responsable de la mise en cache des objets entre les sessions. Lorsque la mise en cache de deuxième niveau est activée, les objets sont d'abord recherchés dans la mémoire cache, puis s'ils ne sont pas trouvés, une requête de base de données est exécutée pour la rechercher. Le cache de second niveau sera utilisé chaque fois que les objets sont chargés à l'aide de leur clé primaire. Les objets de cache de second niveau extraient également leurs associations respectives et résident dans une pile de mémoire distincte de la session.
Cache de requêtes: Le cache de requête sert à stocker les effets consécutifs d'une requête. Au moment où la mise en cache de la requête est activée, les résultats de la requête sont mis de côté par rapport à la requête et aux paramètres déclenchés. Chaque fois que la requête est relâchée, l'infrastructure du magasin vérifie la combinaison des paramètres et de la requête. Si les résultats sont trouvés dans le cache, ils sont renvoyés. En règle générale, une transaction de base de données est lancée. C’est évident, c’est tout sauf une pensée intelligente de réserver une enquête dans le cas où elle possède divers paramètres, puisqu’un paramètre isolé peut revêtir diverses qualités. Pour chacun de ces mélanges, les résultats sont conservés dans la mémoire. Cela peut entraîner une utilisation plus importante de la mémoire.
REST, ou REpresentational State Transfer, est un style architectural permettant de fournir des normes entre les systèmes informatiques sur le Web, ce qui facilite la communication entre les systèmes. Les systèmes conformes à REST, souvent appelés systèmes RESTful, sont caractérisés par la façon dont ils sont Stateless et séparent les préoccupations du client et du serveur.
| HTTP Verb | CRUD | Entire Collection (e.g. /customers) | Specific Item (e.g. /customers/{id}) |
|---|---|---|---|
| POST | Create | 201 (Created), 'Location' header with link to /customers/{id} containing new ID. | 404 (Not Found), 409 (Conflict) if resource already exists.. |
| GET | Read | 200 (OK), list of customers. Use pagination, sorting and filtering to navigate big lists. | 200 (OK), single customer. 404 (Not Found), if ID not found or invalid. |
| PUT | Update/Replace | 405 (Method Not Allowed), unless you want to update/replace every resource in the entire collection. | 200 (OK) or 204 (No Content). 404 (Not Found), if ID not found or invalid. |
| PATCH | Update/Modify | 405 (Method Not Allowed), unless you want to modify the collection itself. | 200 (OK) or 204 (No Content). 404 (Not Found), if ID not found or invalid. |
| DELETE | Delete | 405 (Method Not Allowed), unless you want to delete the whole collection—not often desirable. | 200 (OK). 404 (Not Found), if ID not found or invalid. |
Framework qui offre des outils permettant de générer la documentation pour son API Web. Il offre également une interface permettant d’explorer et tester les différentes méthodes offertes par le service.
Exemple d'interface que peut montrer Swagger:

Imports nécessaires à Swagger :
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.8.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.8.0</version>
<scope>compile</scope>
</dependency>
http://www.groupeafg.com/spring-boot-kesako/
http://javablabla.blogspot.fr/2014/10/h2-la-base-de-donnees-de-poche-au.html
https://www.jmdoudoux.fr/java/dej/chap-hibernate.htm
https://blog.octo.com/designer-une-api-rest/
https://www.mkyong.com/spring-boot/spring-boot-deploy-war-file-to-tomcat/