
![]()


Keploy is a functional testing toolkit for developers. It generates E2E tests for APIs (KTests) along with mocks or stubs(KMocks) by recording real API calls. KTests can be imported as mocks for consumers and vice-versa.
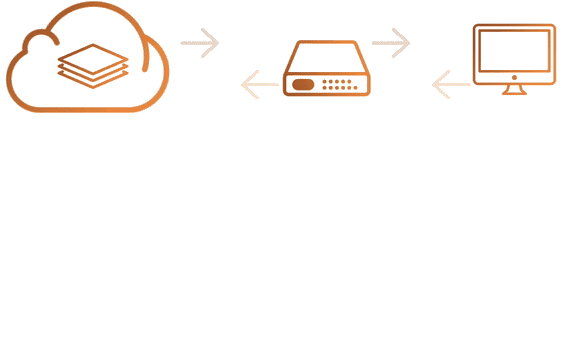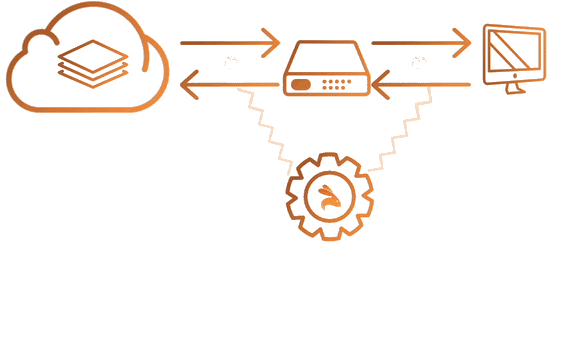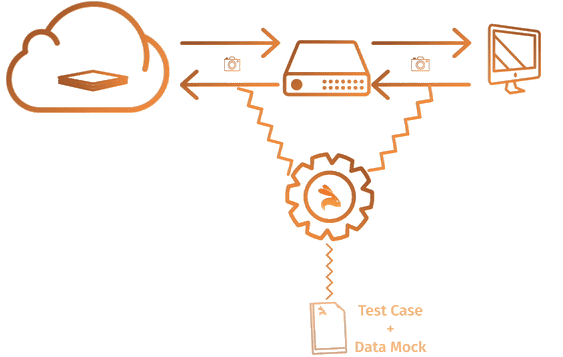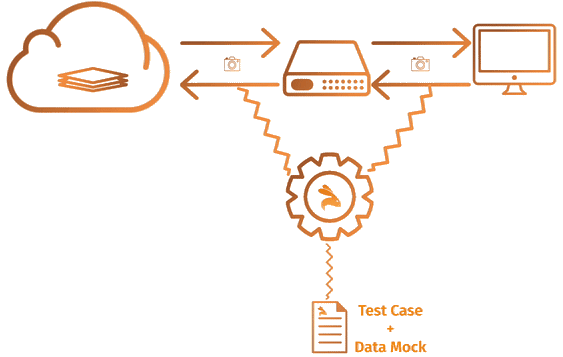
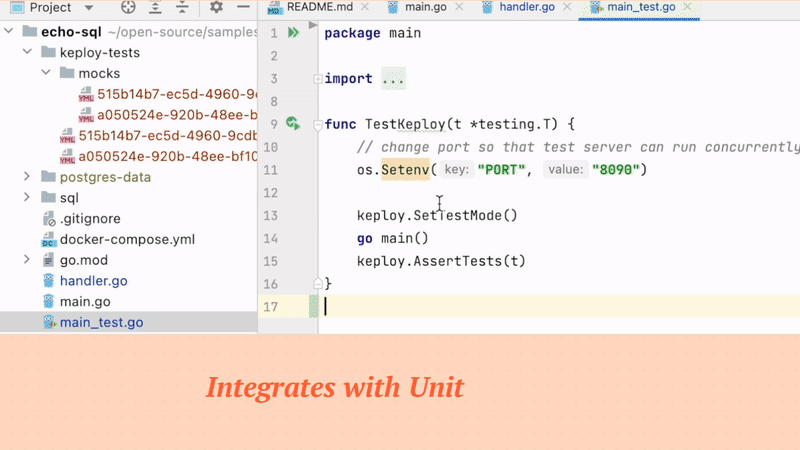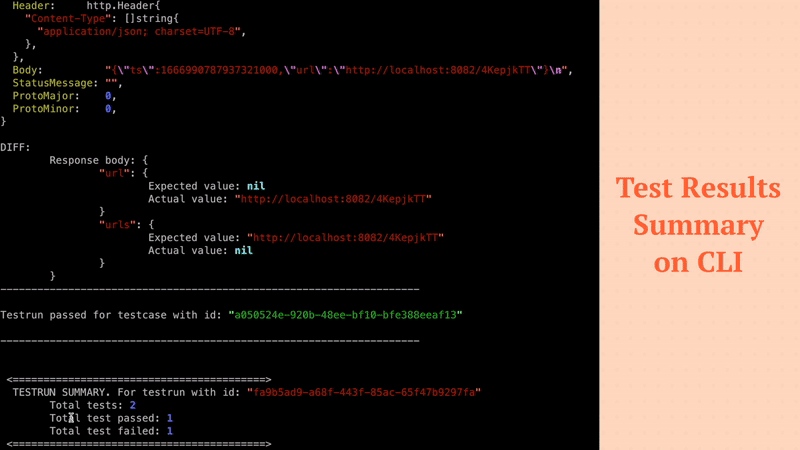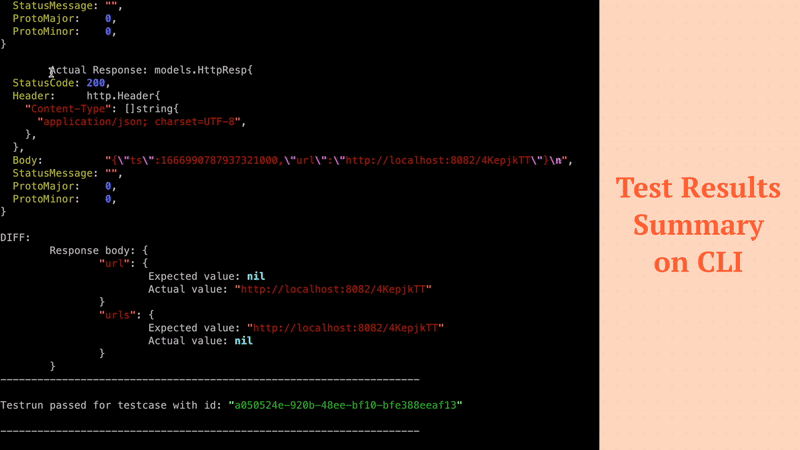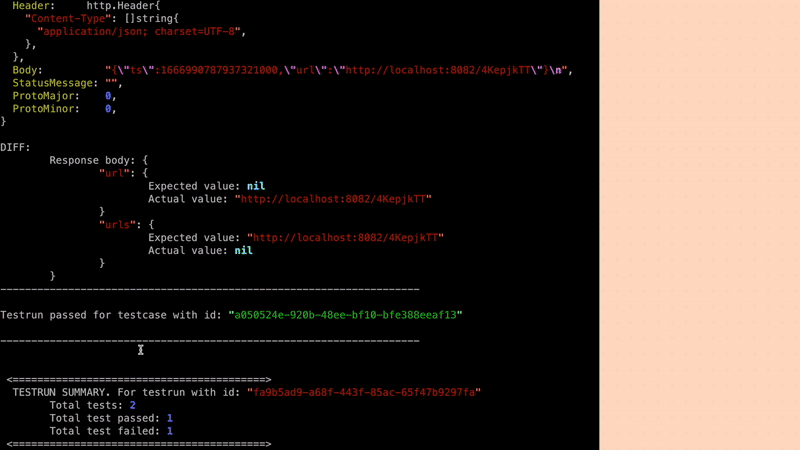
Merge KTests with unit testing libraries(like Go-Test, JUnit..) to track combined test-coverage.
KMocks can also be referenced in existing tests or use anywhere (including any testing framework). KMocks can also be used as tests for the server.
Keploy is testing itself with
without writing many test-cases or data-mocks. 😎
-
-
-
-
: WIP #58
Keploy is added as a middleware to your application that captures and replays all network interaction served to application from any source.
Visit https://docs.keploy.io to read more in detail..

Here you can find the complete Documentation which you can reffer
Whether you are a community member or not, we would love your point of view! Feel free to first check out our
- contribution guidelines
- The guide outlines the process for creating an issue and submitting a pull request.
- code of conduct
- By following the guide we've set, your contribution will more likely be accepted if it enhances the project.
Keploy has native interoperability as it integrates with popular testing libraries like go-test, junit.
Code coverage will be reported with existing plus KTests. It'll also be integrated in CI pipelines/infrastructure automatically if you already have go-test, junit integrated.
Filters noisy fields in API responses like (timestamps, random values) to ensure high quality tests.
WIP - Statistical deduplication ensures that redundant testcases are not generated. WIP (ref #27).
curl --silent --location "https://github.com/keploy/keploy/releases/latest/download/keploy_darwin_all.tar.gz" | tar xz -C /tmp
sudo mv /tmp/keploy /usr/local/bin && keployLinux
curl --silent --location "https://github.com/keploy/keploy/releases/latest/download/keploy_linux_amd64.tar.gz" | tar xz -C /tmp
sudo mv /tmp/keploy /usr/local/bin && keployLinux ARM
curl --silent --location "https://github.com/keploy/keploy/releases/latest/download/keploy_linux_arm64.tar.gz" | tar xz -C /tmp
sudo mv /tmp/keploy /usr/local/bin && keployWindows
-
Download the Keploy Windows AMD64, and extract the files from the zip folder.
-
Run the
keploy.exefile.
Windows ARM
-
Download the Keploy Windows ARM64, and extract the files from the zip folder.
-
Run the
keploy.exefile.
After running Keploy Server, let's integrate the SDK into the application. If you're integrating in custom project please choose installation documentation according to the language you're using.
Demos using Echo/PostgreSQL and Gin/MongoDB are available here. For this example, we will use the Echo/PostgreSQL sample.
git clone https://github.com/keploy/samples-go && cd samples-go/echo-sql
go mod downloaddocker-compose up -dexport KEPLOY_MODE=record && go run handler.go main.goTo genereate testcases we just need to make some API calls. You can use Postman, Hoppscotch, or simply curl
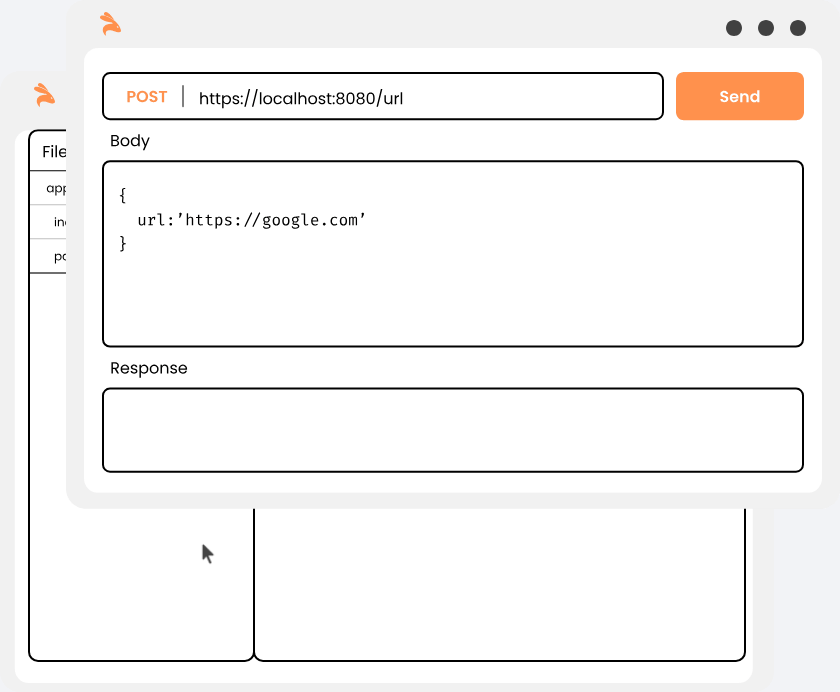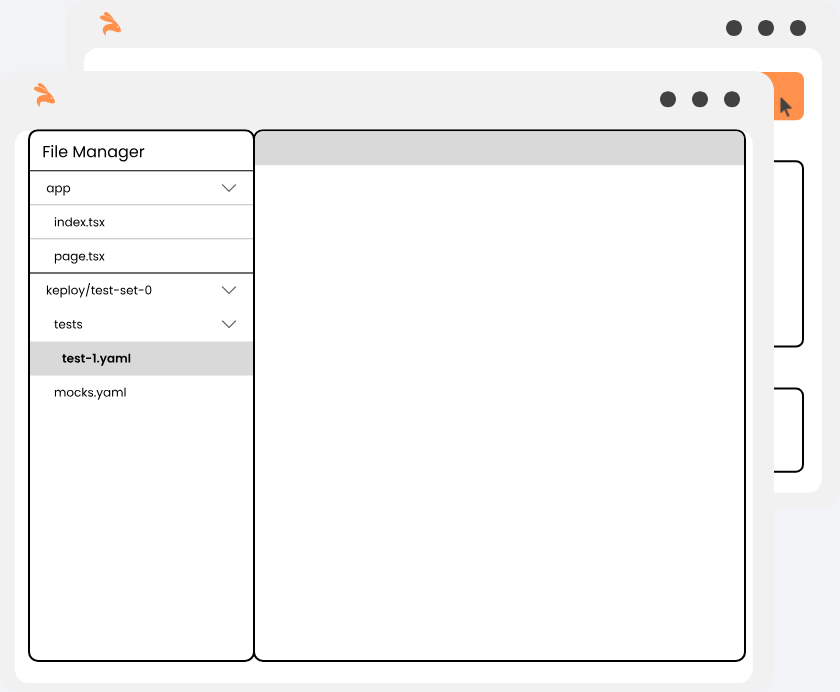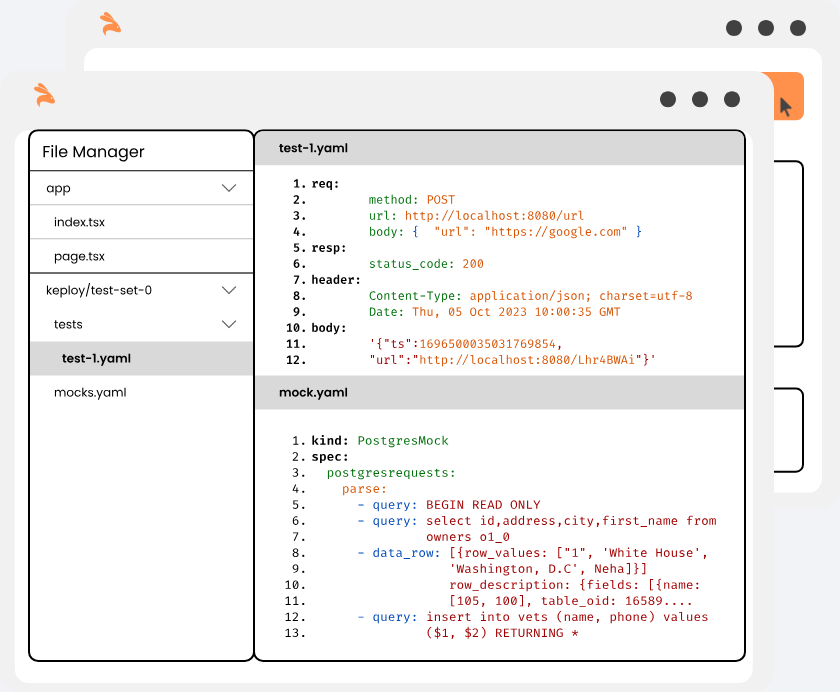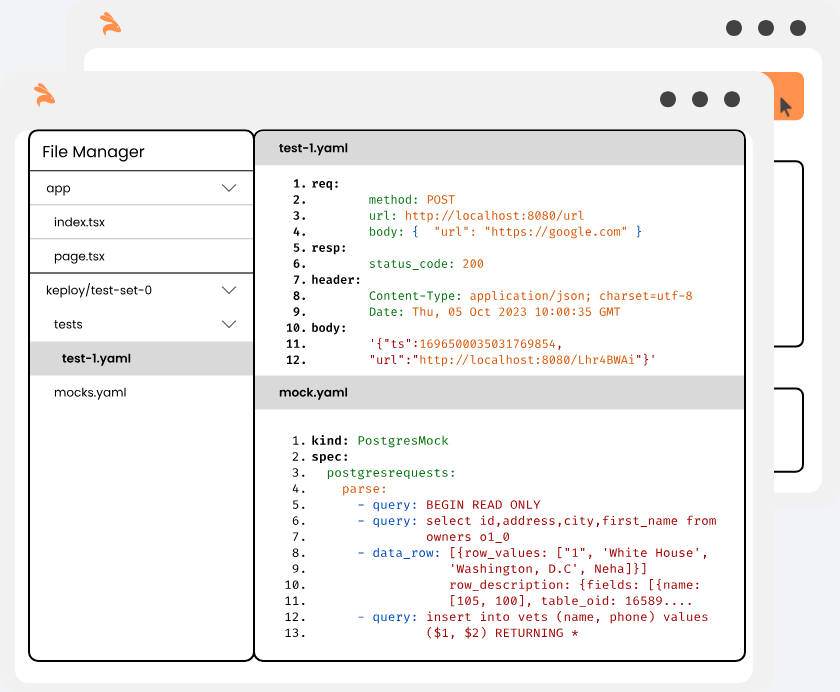
Note : KTests are exported as files in the current directory(.) by default
curl --request POST \
--url http://localhost:8082/url \
--header 'content-type: application/json' \
--data '{
"url": "https://github.com"
}'this will return the shortened url. The ts would automatically be ignored during testing because it'll always be different.
{
"ts": 1647802058801841100,
"url": "http://localhost:8082/GuwHCgoQ"
}curl --request GET \
--url http://localhost:8082/GuwHCgoQYou just need 3 lines of code in your unit test file and that's it!!🔥🔥🔥
For an example, for a file named main.go create a unit test file as main_test.go in the same folder as main.go.
Contents of main_test.go:
package main
import (
"github.com/keploy/go-sdk/keploy"
"testing"
)
func TestKeploy(t *testing.T) {
keploy.SetTestMode()
go main()
keploy.AssertTests(t)
}Note: Before running tests stop the sample application
go test -coverpkg=./... -covermode=atomic ./...this should show you have 74.4% coverage without writing any code!
ok echo-psql-url-shortener 5.820s coverage: 74.4% of statements in ./...The Test Run can be visualised in the terminal where Keploy server is running. You can also checkout the details of the Test Run Report as a report file generated locally in the Keploy Server directory.
The Keploy SDKs modes can operated by setting KEPLOY_MODE environment variable
Note: KEPLOY_MODE value is case sensitive
There are 3 Keploy SDK modes:
- Off : In the off mode the Keploy SDK will turn off all the functionality provided by the Keploy platform.
export KEPLOY_MODE="off"
- Record mode :
- Record requests, response and all external calls and sends to Keploy server.
- After keploy server removes duplicates, it then runs the request on the API again to identify noisy fields.
- Sends the noisy fields to the keploy server to be saved along with the testcase.
export KEPLOY_MODE="record"
- Test mode :
- Fetches testcases for the app from keploy server.
- Calls the API with same request payload in testcase.
- Mocks external calls based on data stored in the testcase.
- Validates the responses and uploads results to the keploy server
export KEPLOY_MODE="test"
Need another language support? Please raise an issue or discuss on our slack channel
The fastest way to start with Keploy is the Gitpod-hosted version. When you're ready, you can install locally or host yourself.
One-click deploy sample URL Shortener application sample with Keploy using Gitpod

- Unit Testing: While Keploy is designed to run alongside unit testing frameworks (Go test, JUnit..) and can add to the overall code coverage, it still generates E2E tests. So it might be easier to write unit tests for some methods instead of E2E tests.
- Production usage Keploy is currently focused on generating tests for developers. These tests can be captured from any environment, but we have not tested it on high volume production environments. This would need robust deduplication to avoid too many redundant tests being captured. We do have ideas on building a robust deduplication system #27
- De-noise requires mocking Keploy issues a duplicate request and compares the responses with the previous responses to find "noisy" or non-deterministic fields. We have to ensure all non-idempotent dependencies are mocked/wrapped by Keploy to avoid unnecessary side effects in downstream services.
🤔 FAQs
🕵️️ Why Keploy
We'd love to collaborate with you to make Keploy great. To get started: