- Plugins
Plugins handle running your events, and reporting status back to the Cronicle daemon. They can be written in virtually any language, as they are really just command-line executables. Cronicle spawns a sub-process for each job, executes a command-line you specify, and then uses pipes to pass in job information and retrieve status, all in JSON format.
So you can write a Plugin in your language of choice, as long as it can read and write JSON. Also, Cronicle ships with a built-in Plugin for handling shell scripts, which makes things even easier if you just have some simple shell commands to run, and don't want to have to deal with JSON at all. See Shell Plugin below for more on this.
To write your own Plugin, all you need is to provide a command-line executable, and have it read and write JSON over STDIN and STDOUT. Information about the current job is passed as a JSON document to your STDIN, and you can send back status updates and completion events simply by writing JSON to your STDOUT.
Please note that regardless of your choice of programming language, your Plugin needs to be a real command-line executable. So it needs to have execute file permissions (usually 0755), and a shebang line at the top of the file, indicating which interpreter to use. For example, if you write a Node.js Plugin, you need something like this at the very top of your .js file:
#!/usr/bin/node
The location of the node binary may vary on your servers.
As soon as your Plugin is launched as a sub-process, a JSON document is piped to its STDIN stream, describing the job. This will be compacted onto a single line followed by an EOL, so you can simply read a line, and not have to worry about locating the start and end of the JSON. Here is an example JSON document (pretty-printed here for display purposes):
{
"id": "jihuxvagi01",
"hostname": "joeretina.local",
"command": "/usr/local/bin/my-plugin.js",
"event": "3c182051",
"now": 1449431125,
"log_file": "/opt/cronicle/logs/jobs/jihuxvagi01.log",
"params": {
"myparam1": "90",
"myparam2": "Value"
}
}There may be other properties in the JSON (many are copied over from the event), but these are the relevant ones:
| Property Name | Description |
|---|---|
id |
A unique alphanumeric ID assigned to the job. |
hostname |
The hostname of the server currently processing the job. |
command |
The exact command that was executed to start your Plugin. |
event |
The Event ID of the event that fired off the job. |
now |
A Unix timestamp representing the "current" time for the job (very important -- see below). |
log_file |
A fully-qualified filesystem path to a unique log file specifically for the job, which you can use. |
params |
An object containing your Plugin's custom parameters, filled out with values from the Event Editor. |
The now property is special. It may or may not be the "current" time, depending on how and why the job started. Meaning, if the associated event is set to Run All Mode it is possible that a previous job couldn't run for some reason, and Cronicle is now "catching up" by running missed jobs. In this situation, the now property will be set to the time when the event should have run. For example, if you have a Plugin that generates daily reports, you'll need to know which day to run the report for. Normally this will be the current date, but if a day was missed for some reason, and Cronicle is catching up by running yesterday's job, you should use the now time to determine which day's data to pull for your report.
The log_file is designed for your Plugin's own use. It is a unique file created just for the job, and its contents are displayed in real-time via the Cronicle UI on the Job Details Tab. You can use any log format you want, just make sure you open the file in "append" mode (it contains a small header written by the daemon). Note that you can also just print to STDOUT or STDERR, and these are automatically appended to the log file for you.
The params object will contain all the custom parameter keys defined when you created the Plugin (see the Plugins Tab section), and values populated from the event editor, when the Plugin was selected for the event. The keys should match the parameter IDs you defined.
Your Plugin is expected to write JSON to STDOUT in order to report status back to the Cronicle daemon. At the very least, you need to notify Cronicle that the job was completed, and the result of the job (i.e. success or fail). This is done by printing a JSON object with a complete property set to 1, and a code property set to 0 indicating success. You need to make sure the JSON is compacted onto a single line, and ends with a single EOL character (\n on Unix). Example:
{ "complete": 1, "code": 0 }This tells Cronicle that the job was completed successfully, and your process is about to exit. However, if the job failed and you need to report an error, you need to set the code property set to any non-zero error code you want, and add a description property set to a custom error string. Include these along with the complete property in the JSON. Example:
{ "complete": 1, "code": 999, "description": "Failed to connect to database." }Your error code and description will be displayed on the Job Details Tab, and in any e-mail notifications and/or web hooks sent out for the event completion.
If your Plugin writes anything other than JSON to STDOUT (or STDERR), it is automatically appended to your log file. This is so you don't have to worry about using existing code or utilities that may emit some kind of output. Cronicle is very forgiving in this regard.
Please note that the once you send a JSON line containing the complete flag, Cronicle will consider your job completed, and not process any further JSON updates from your Plugin. So make sure it is the last JSON line you send for a job.
In addition to reporting success or failure at the end of a job, you can also optionally report progress at custom intervals while your job is running. This is how Cronicle can display its visual progress meter in the UI, as well as calculate the estimated time remaining. To update the progress of a job, simply print a JSON document with a progress property, set to a number between 0.0 and 1.0. Example:
{ "progress": 0.5 }This would show progress at 50% completion, and automatically calculate the estimated time remaining based on the duration and progress so far. You can repeat this as often as you like, with as granular progress as you can provide.
You can optionally include performance metrics at the end of a job, which are displayed as a pie chart on the Job Details Tab. These metrics can consist of any categories you like, and the JSON format is a simple perf object where the values represent the amount of time spent in seconds. Example:
{ "perf": { "db": 18.51, "http": 3.22, "gzip": 0.84 } }The perf keys can be anything you want. They are just arbitrary categories you can make up, which represent how your Plugin spent its time during the job.
Cronicle accepts a number of different formats for the perf metrics, to accommodate various performance tracking libraries. For example, you can provide the metrics in query string format, like this:
{ "perf": "db=18.51&http=3.22&gzip=0.84" }If your metrics include a total (or t) in addition to other metrics, this is assumed to represent the total time, and will automatically be excluded from the pie chart (but included in the performance history graph).
If you track metrics in units other than seconds, you can provide the scale. For example, if your metrics are all in milliseconds, just set the scale property to 1000. Example:
{ "perf": { "scale": 1000, "db": 1851, "http": 3220, "gzip": 840 } }The slightly more complex format produced by our own pixl-perf library is also supported.
In order for the pie chart to be accurate, your perf metrics must not overlap each other. Each metric should represent a separate period of time. Put another way, if all the metrics were added together, they should equal the total time. To illustrate this point, consider the following "bad" example:
{ "perf": { "database": 18.51, "run_sql_query": 3.22, "connect_to_db": 0.84 } }In this case the Plugin is tracking three different metrics, but the database metric encompasses all database related activities, including the run_sql_query and connect_to_db. So the database metric overlaps the others. Cronicle has no way of knowing this, so the pie chart would be quite inaccurate, because the three metrics do not add up to the total time.
However, if you want to track nested metrics as well as a parent metric, just make sure you prefix your perf keys properly. In the above example, all you would need to do is rename the keys like this:
{ "perf": { "db": 18.51, "db_run_sql": 3.22, "db_connect": 0.84 } }Cronicle will automatically detect that the db key is used as a prefix in the other two keys, and it will be omitted from the pie chart. Only the nested db_run_sql and db_connect keys will become slices of the pie, as they should add up to the total in this case.
Note that all the metrics are included in the performance history graph, as that is a line graph, not a pie chart, so it doesn't matter that everything add up to the total time.
Notification settings for the job are configured in the UI at the event level, and handled automatically after your Plugin exits. E-mail addresses may be entered for both successful and failure results. However, your Plugin running the job can alter these settings on-the-fly.
For example, if you only want to send a successful e-mail in certain cases, and want to disable it based on some outcome from inside the Plugin, just print some JSON to STDOUT like this:
{ "notify_success": "" }This will disable the e-mail that is normally sent upon success. Similarly, if you want to disable the failure e-mail, print this to STDOUT:
{ "notify_fail": "" }Another potential use of this feature is to change who gets e-mailed, based on a decision made inside your Plugin. For example, you may have multiple error severity levels, and want to e-mail a different set of people for the really severe ones. To do that, just specify a new set of e-mail addresses in the notify_fail property:
{ "notify_fail": "emergency-ops-pager@mycompany.com" }These JSON updates can be sent as standalone records as shown here, at any time during your job run, or you can batch everything together at the very end:
{ "complete": 1, "code": 999, "description": "Failed to connect to database.", "perf": { "db": 18.51, "db_run_sql": 3.22, "db_connect": 0.84 }, "notify_fail": "emergency-ops-pager@mycompany.com" }You can enable or disable Chain Reaction mode on the fly, by setting the chain property in your JSON output. This allows you to designate another event to launch as soon as the current job completes, or to clear the property (set it to false or a blank string) to disable Chain Reaction mode if it was enabled in the UI.
To enable a chain reaction, you need to know the Event ID of the event you want to trigger. You can determine this by editing the event in the UI and copy the Event ID from the top of the form, just above the title. Then you can specify the ID in your jobs by printing some JSON to STDOUT like this:
{ "chain": "e29bf12db" }Remember that your job must complete successfully in order to trigger the chain reaction, and fire off the next event. However, if you want to run a event only on job failure, set the chain_error property instead:
{ "chain_error": "e29bf12db" }You set both the chain and chain_error properties, to run different events on success / failure.
To disable chain reaction mode, set the chain and chain_error properties to false or empty strings:
{ "chain": "", "chain_error": "" }When a chained event runs, some additional information is included in the initial JSON job object sent to STDIN:
| Property Name | Description |
|---|---|
source_event |
The ID of the original event that started the chain reaction. |
chain_code |
The error code from the original job, or 0 for success. |
chain_description |
The error description from the original job, if applicable. |
chain_data |
Custom user data, if applicable (see below). |
You can pass custom JSON data to the next event in the chain, when using a Chain Reaction event. Simply specify a JSON property called chain_data in your JSON output, and pass in anything you want (can be a complex object / array tree), and the next event will receive it. Example:
{ "chain": "e29bf12db", "chain_data": { "custom_key": "foobar", "value": 42 } }So in this case when the event e29bf12db runs, it will be passed your chain_data object as part of the JSON sent to it when the job starts. The Plugin code running the chained event can access the data by parsing the JSON and grabbing the chain_data property.
In addition to passing chain_data to chained events (see above), you can also override some or all the parameters of the chained event (the key/value pairs normally populated by the Plugin). To do this, specify a JSON property called chain_params in your JSON output, and pass in an object containing param keys. This will be merged with the default event Plugin parameters when the chained job is executed. Example:
{ "chain": "e29bf12db", "chain_params": { "custom_key": "foobar", "value": 42 } }Note that the contents of the chain_params object will be shallow-merged into the event's default Plugin params, so your object can be sparsely populated. This is done so that you can replace any keys that you want, or even add new ones, and you do not need to specify all the params the event is expecting.
If your Plugin produces statistics or other tabular data at the end of a run, you can have Cronicle render this into a table on the Job Details page. Simply print a JSON object with a property named table, containing the following keys:
| Property Name | Description |
|---|---|
title |
Optional title displayed above the table, defaults to "Job Stats". |
header |
Optional array of header columns, displayed in shaded bold above the main data rows. |
rows |
Required array of rows, with each one being its own inner array of column values. |
caption |
Optional caption to show under the table (centered, small gray text). |
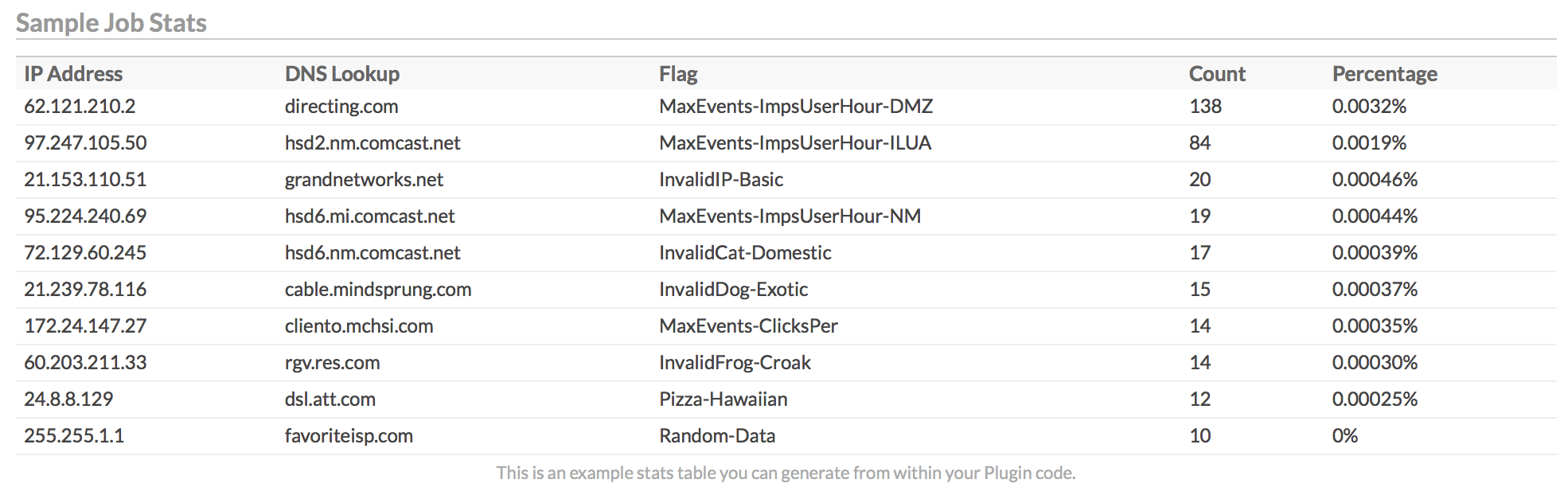
Here is an example data table. Note that this has been expanded for documentation purposes, but in practice your JSON needs to be compacted onto a single line when printed to STDOUT.
{
"table": {
"title": "Sample Job Stats",
"header": [
"IP Address", "DNS Lookup", "Flag", "Count", "Percentage"
],
"rows": [
["62.121.210.2", "directing.com", "MaxEvents-ImpsUserHour-DMZ", 138, "0.0032%" ],
["97.247.105.50", "hsd2.nm.comcast.net", "MaxEvents-ImpsUserHour-ILUA", 84, "0.0019%" ],
["21.153.110.51", "grandnetworks.net", "InvalidIP-Basic", 20, "0.00046%" ],
["95.224.240.69", "hsd6.mi.comcast.net", "MaxEvents-ImpsUserHour-NM", 19, "0.00044%" ],
["72.129.60.245", "hsd6.nm.comcast.net", "InvalidCat-Domestic", 17, "0.00039%" ],
["21.239.78.116", "cable.mindsprung.com", "InvalidDog-Exotic", 15, "0.00037%" ],
["172.24.147.27", "cliento.mchsi.com", "MaxEvents-ClicksPer", 14, "0.00035%" ],
["60.203.211.33", "rgv.res.com", "InvalidFrog-Croak", 14, "0.00030%" ],
["24.8.8.129", "dsl.att.com", "Pizza-Hawaiian", 12, "0.00025%" ],
["255.255.1.1", "favoriteisp.com", "Random-Data", 10, "0%" ]
],
"caption": "This is an example stats table you can generate from within your Plugin code."
}
}This would produce a table like the following:
If you would prefer to generate your own HTML content from your Plugin code, and just have it rendered into the Job Details page, you can do that as well. Simply print a JSON object with a property named html, containing the following keys:
| Property Name | Description |
|---|---|
title |
Optional title displayed above the section, defaults to "Job Report". |
content |
Required Raw HTML content to render into the page. |
caption |
Optional caption to show under your HTML (centered, small gray text). |
Here is an example HTML report. Note that this has been expanded for documentation purposes, but in practice your JSON needs to be compacted onto a single line when printed to STDOUT.
{
"html": {
title: "Sample Job Report",
content: "This is <b>HTML</b> so you can use <i>styling</i> and such.",
caption: "This is a caption displayed under your HTML content."
}
}If your Plugin generates plain text instead of HTML, you can just wrap it in a <pre> block, which will preserve formatting such as whitespace.
Your job can optionally trigger an event update when it completes. This can be used to do things such as disable the event (remove it from the schedule) in response to a catastrophic error, or change the event's timing, change the server or group target, and more.
To update the event for a job, simply include an update_event object in your Plugin's JSON output, containing any properties from the Event Data Format. Example:
{
"update_event": {
"enabled": 0
}
}This would cause the event to be disabled, so the schedule would no longer launch it. Note that you can only update the event once, and it happens at the completion of your job.
When processes are spawned to run jobs, your Plugin executable is provided with a copy of the current environment, along with the following custom environment variables:
| Variable | Description |
|---|---|
$CRONICLE |
The current Cronicle version, e.g. 1.0.0. |
$JOB_ALGO |
Specifies the algorithm that was used for picking the server from the target group. See Algorithm. |
$JOB_CATCH_UP |
Will be set to 1 if the event has Run All Mode mode enabled, 0 otherwise. |
$JOB_CATEGORY_TITLE |
The Category Title to which the event is assigned. See Categories Tab. |
$JOB_CATEGORY |
The Category ID to which the event is assigned. See Categories Tab. |
$JOB_CHAIN |
The chain reaction event ID to launch if job completes successfully. See Chain Reaction. |
$JOB_CHAIN_ERROR |
The chain reaction event ID to launch if job fails. See Chain Reaction. |
$JOB_COMMAND |
The command-line executable that was launched for the current Plugin. |
$JOB_CPU_LIMIT |
Limits the CPU to the specified percentage (100 = 1 core), abort if exceeded. See Event Resource Limits. |
$JOB_CPU_SUSTAIN |
Only abort if the CPU limit is exceeded for this many seconds. See Event Resource Limits. |
$JOB_DETACHED |
Specifies whether Detached Mode is enabled or not. |
$JOB_EVENT_TITLE |
A display name for the event, shown on the Schedule Tab as well as in reports and e-mails. |
$JOB_EVENT |
The ID of the event that launched the job. |
$JOB_HOSTNAME |
The hostname of the server chosen to run the current job. |
$JOB_ID |
The unique alphanumeric ID assigned to the job. |
$JOB_LOG |
The filesystem path to the job log file, which you can append to if you want. However, STDOUT or STDERR are both piped to the log already. |
$JOB_MEMORY_LIMIT |
Limits the memory usage to the specified amount, in bytes. See Event Resource Limits. |
$JOB_MEMORY_SUSTAIN |
Only abort if the memory limit is exceeded for this many seconds. See Event Resource Limits. |
$JOB_MULTIPLEX |
Will be set to 1 if the event has Multiplexing enabled, 0 otherwise. |
$JOB_NOTES |
Text notes saved with the event, included in e-mail notifications. See Event Notes. |
$JOB_NOTIFY_FAIL |
List of e-mail recipients to notify upon job failure (CSV). See Event Notification. |
$JOB_NOTIFY_SUCCESS |
List of e-mail recipients to notify upon job success (CSV). See Event Notification. |
$JOB_NOW |
The Epoch timestamp of the job time (may be in the past if re-running a missed job). |
$JOB_PLUGIN_TITLE |
The Plugin Title for the associated event. |
$JOB_PLUGIN |
The Plugin ID for the associated event. |
$JOB_RETRIES |
The number of retries to allow before reporting an error. See Event Retries. |
$JOB_RETRY_DELAY |
Optional delay between retries, in seconds. See Event Retries. |
$JOB_SOURCE |
String representing who launched the job, will be Scheduler or Manual (USERNAME). |
$JOB_STAGGER |
If Multiplexing is enabled, this specifies the number of seconds to wait between job launches. |
$JOB_TIME_START |
The starting time of the job, in Epoch seconds. |
$JOB_TIMEOUT |
The event timeout (max run time) in seconds, or 0 if no timeout is set. |
$JOB_TIMEZONE |
The timezone for interpreting the event timing settings. Needs to be an IANA timezone string. See Event Timing. |
$JOB_WEB_HOOK |
An optional URL to hit for the start and end of each job. See Event Web Hook. |
In addition, any Plugin Parameters are also passed as environment variables. The keys are converted to upper-case, as that seems to be the standard. So for example, you can customize the PATH by declaring it as a Plugin Parameter:
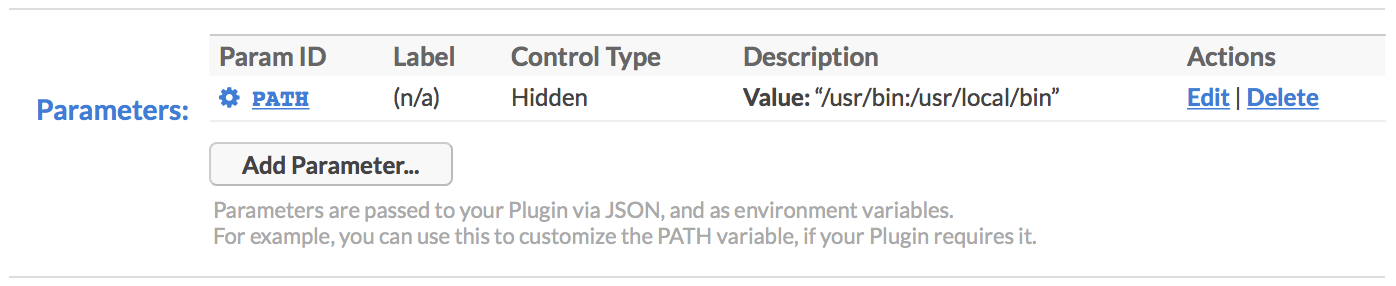
You can also include inline variables in the parameter value itself, using the syntax $VARNAME. So for example, if you wanted to append to the current PATH instead of having to set it from scratch, you could:

Please note that if you do overwrite the entire path, you must include the location of the Node.js node binary (typically in /usr/bin or /usr/local/bin). Otherwise, things will not work well.
Here is a sample Plugin written in Node.js:
#!/usr/bin/env node
var rl = require('readline').createInterface({ input: process.stdin });
rl.on('line', function(line) {
// got line from stdin, parse JSON
var job = JSON.parse(line);
console.log("Running job: " + job.id + ": " + JSON.stringify(job) );
// Update progress at 50%
setTimeout( function() {
console.log("Halfway there!");
process.stdout.write( JSON.stringify({ progress: 0.5 }) + "\n" );
}, 5 * 1000 );
// Write completion to stdout
setTimeout( function() {
console.log("Job complete, exiting.");
process.stdout.write( JSON.stringify({
complete: 1,
code: 0
}) + "\n" );
}, 10 * 1000 );
// close readline interface
rl.close();
});Here is a sample Plugin written in Perl, using the JSON module:
#!/usr/bin/env perl
use strict;
use JSON;
# set output autoflush
$| = 1;
# read line from stdin -- it should be our job JSON
my $line = <STDIN>;
my $job = decode_json($line);
print "Running job: " . $job->{id} . ": " . encode_json($job) . "\n";
# report progress at 50%
sleep 5;
print "Halfway there!\n";
print encode_json({ progress => 0.5 }) . "\n";
sleep 5;
print "Job complete, exiting.\n";
# All done, send completion via JSON
print encode_json({
complete => 1,
code => 0
}) . "\n";
exit(0);
1;Here is a sample Plugin written in PHP:
#!/usr/bin/env php
<?php
// make sure php flushes after every print
ob_implicit_flush();
// read line from stdin -- it should be our job JSON
$line = fgets( STDIN );
$job = json_decode($line, true);
print( "Running job: " . $job['id'] . ": " . json_encode($job) . "\n" );
// report progress at 50%
sleep(5);
print( "Halfway there!\n" );
print( json_encode(array( 'progress' => 0.5 )) . "\n" );
sleep(5);
print( "Job complete, exiting.\n" );
// All done, send completion via JSON
print( json_encode(array(
'complete' => 1,
'code' => 0
)) . "\n" );
exit(0);
?>Cronicle ships with a built-in "Shell Plugin", which you can use to execute arbitrary shell scripts. Simply select the Shell Plugin from the Edit Event Tab, and enter your script. This is an easy way to get up and running quickly, because you don't have to worry about reading or writing JSON.
The Shell Plugin determines success or failure based on the exit code of your script. This defaults to 0 representing success. Meaning, if you want to trigger an error, exit with a non-zero status code, and make sure you print your error message to STDOUT or STDERR (both will be appended to your job's log file). Example:
#!/bin/bash
# Perform tasks or die trying...
/usr/local/bin/my-task-1.bin || exit 1
/usr/local/bin/my-task-2.bin || exit 1
/usr/local/bin/my-task-3.bin || exit 1You can still report intermediate progress with the Shell Plugin. It can accept JSON in the standard output format if enabled, but there is also a shorthand. You can echo a single number on its own line, from 0 to 100, with a % suffix, and that will be interpreted as the current progress. Example:
#!/bin/bash
# Perform some long-running task...
/usr/local/bin/my-task-1.bin || exit 1
echo "25%"
# And another...
/usr/local/bin/my-task-2.bin || exit 1
echo "50%"
# And another...
/usr/local/bin/my-task-3.bin || exit 1
echo "75%"
# And the final task...
/usr/local/bin/my-task-4.bin || exit 1This would allow Cronicle to show a graphical progress bar on the Home and Job Details tabs, and estimate the time remaining based on the elapsed time and current progress.
Pro-Tip: The Shell Plugin actually supports any interpreted scripting language, including Node.js, PHP, Perl, Python, and more. Basically, any language that supports a Shebang line will work in the Shell Plugin. Just change the #!/bin/sh to point to your interpreter binary of choice.
Cronicle ships with a built-in "HTTP Request" Plugin, which you can use to send simple GET, HEAD or POST requests to any URL, and log the response. You can specify custom HTTP request headers, and also supply regular expressions to match a successful response based on the content. Here is the user interface when selected:
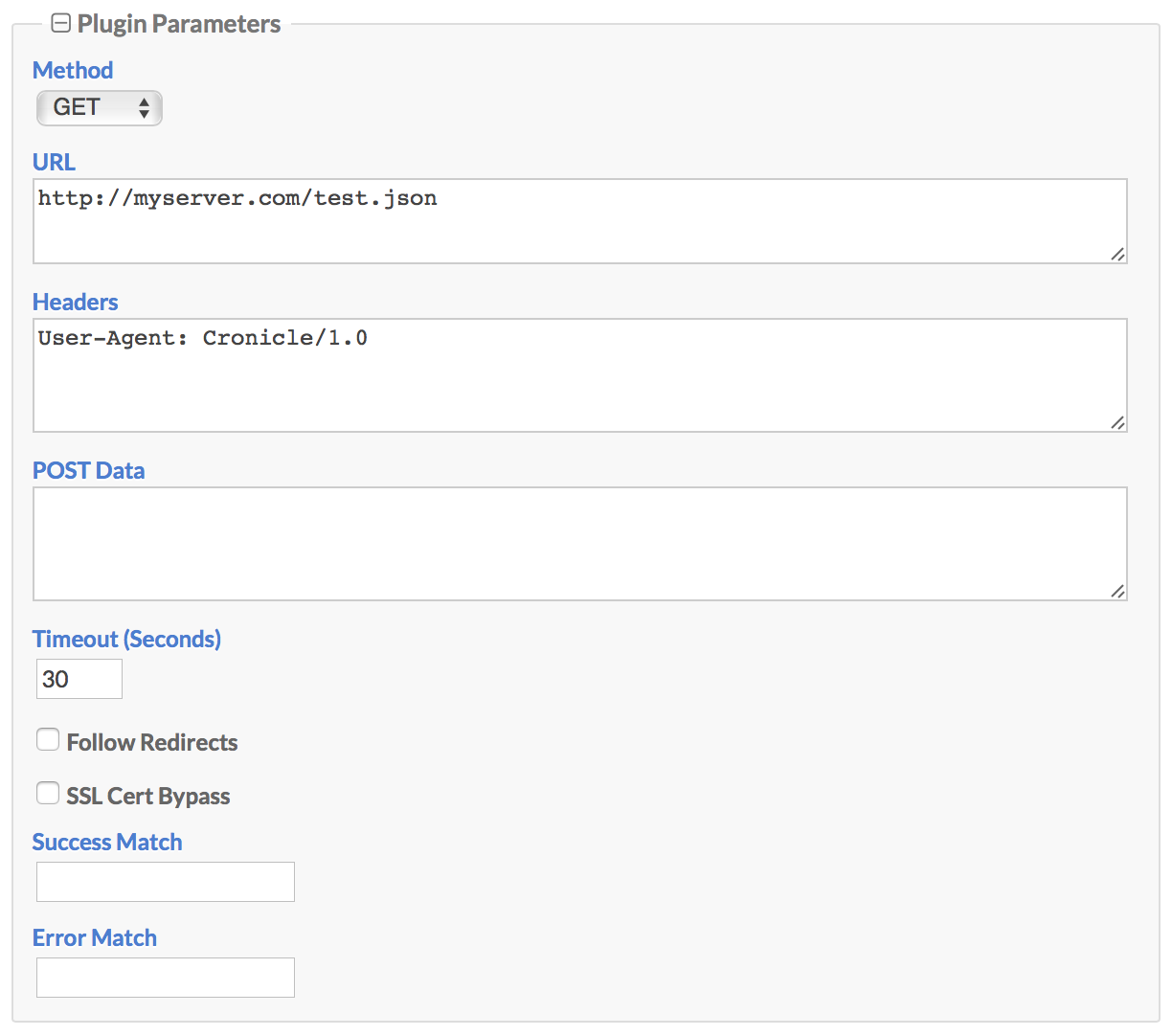
Here are descriptions of the parameters:
| Plugin Parameter | Description |
|---|---|
| Method | Select the HTTP request method, either GET, HEAD or POST. |
| URL | Enter your fully-qualified URL here, which must begin with either http:// or https://. |
| Headers | Optionally include any custom request headers here, one per line. |
| POST Data | If you are sending a HTTP POST, enter the raw POST data here. |
| Timeout | Enter the timeout in seconds, which is measured as the time to first byte in the response. |
| Follow Redirects | Check this box to automatically follow HTTP redirect responses (up to 32 of them). |
| SSL Cert Bypass | Check this box if you need to make HTTPS requests to servers with invalid SSL certificates (self-signed or other). |
| Success Match | Optionally enter a regular expression here, which is matched against the response body. If specified, this must match to consider the job a success. |
| Error Match | Optionally enter a regular expression here, which is matched against the response body. If this matches the response body, then the job is aborted with an error. |
The HTTP Request Plugin supports Cronicle's Chain Reaction system in two ways. First, information about the HTTP response is passed into the Chain Data object, so downstream chained events can read and act on it. Specifically, all the HTTP response headers, and possibly even the content body itself (if formatted as JSON and smaller than 1 MB) are included. Example:
"chain_data": {
"headers": {
"date": "Sat, 14 Jul 2018 20:14:01 GMT",
"server": "Apache/2.4.28 (Unix) LibreSSL/2.2.7 PHP/5.6.30",
"last-modified": "Sat, 14 Jul 2018 20:13:54 GMT",
"etag": "\"2b-570fb3c47e480\"",
"accept-ranges": "bytes",
"content-length": "43",
"connection": "close",
"content-type": "application/json",
"x-uuid": "7617a494-823f-4566-8f8b-f479c2a6e707"
},
"json": {
"key1": "value1",
"key2": 12345
}
}In this example an HTTP request was made that returned those specific response headers (the header names are converted to lower-case), and the body was also formatted as JSON, so the JSON data itself is parsed and included in a property named json. Downstream events that are chain-linked to the HTTP Request event can read these properties and act on them.
Secondly, you can chain an HTTP Request into another HTTP Request, and use the chained data values from the previous response in the next request. To do this, you need to utilize a special [/bracket/slash] placeholder syntax in the second request, to lookup values in the chain_data object from the first one. You can use these placeholders in the URL, Request Headers and POST Data text fields. Example:
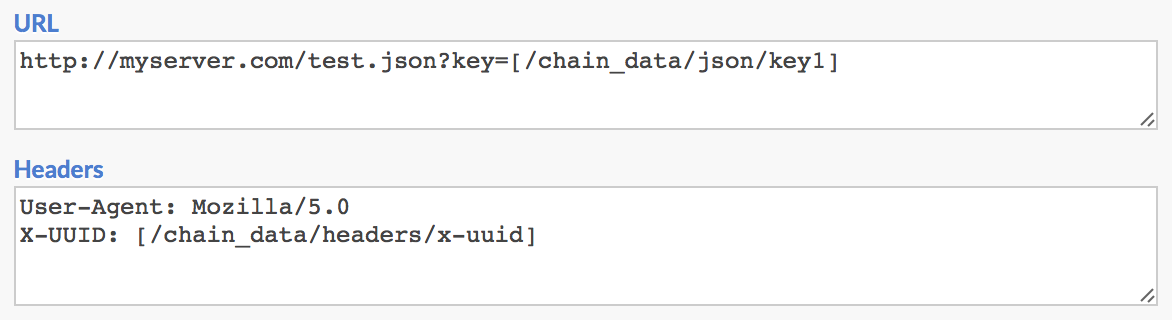
Here you can see we are using two placeholders, one in the URL and another in the HTTP request headers. These are looking up values from a previous HTTP Request event, and passing them into the next request. Specifically, we are using:
| Placeholder | Description |
|---|---|
[/chain_data/json/key1] |
This placeholder is looking up the key value from the JSON data (body content) of the previous HTTP response. Using our example response shown above, this would resolve to value1. |
[/chain_data/headers/x-uuid] |
This placeholder is looking up the X-UUID response header from the previous HTTP response. Using our example response shown above, this would resolve to 7617a494-823f-4566-8f8b-f479c2a6e707. |
So once the second request is sent off, after placeholder expansion the URL would actually resolve to:
http://myserver.com/test.json?key=value1
And the headers would expand to:
User-Agent: Mozilla/5.0
X-UUID: 7617a494-823f-4566-8f8b-f479c2a6e707
You can chain as many requests together as you like, but note that each request can only see and act on chain data from the previous request (the one that directly chained to it).