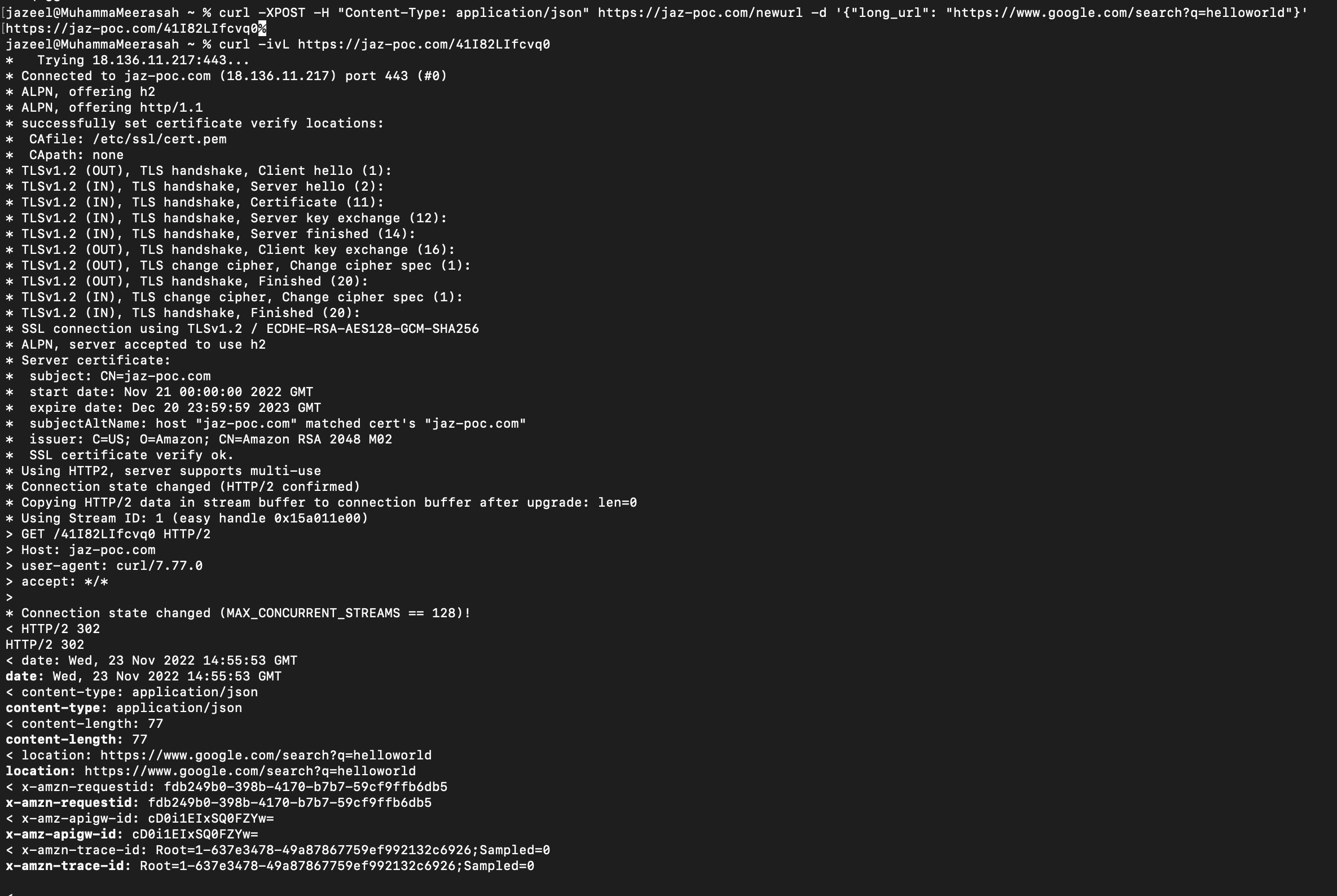
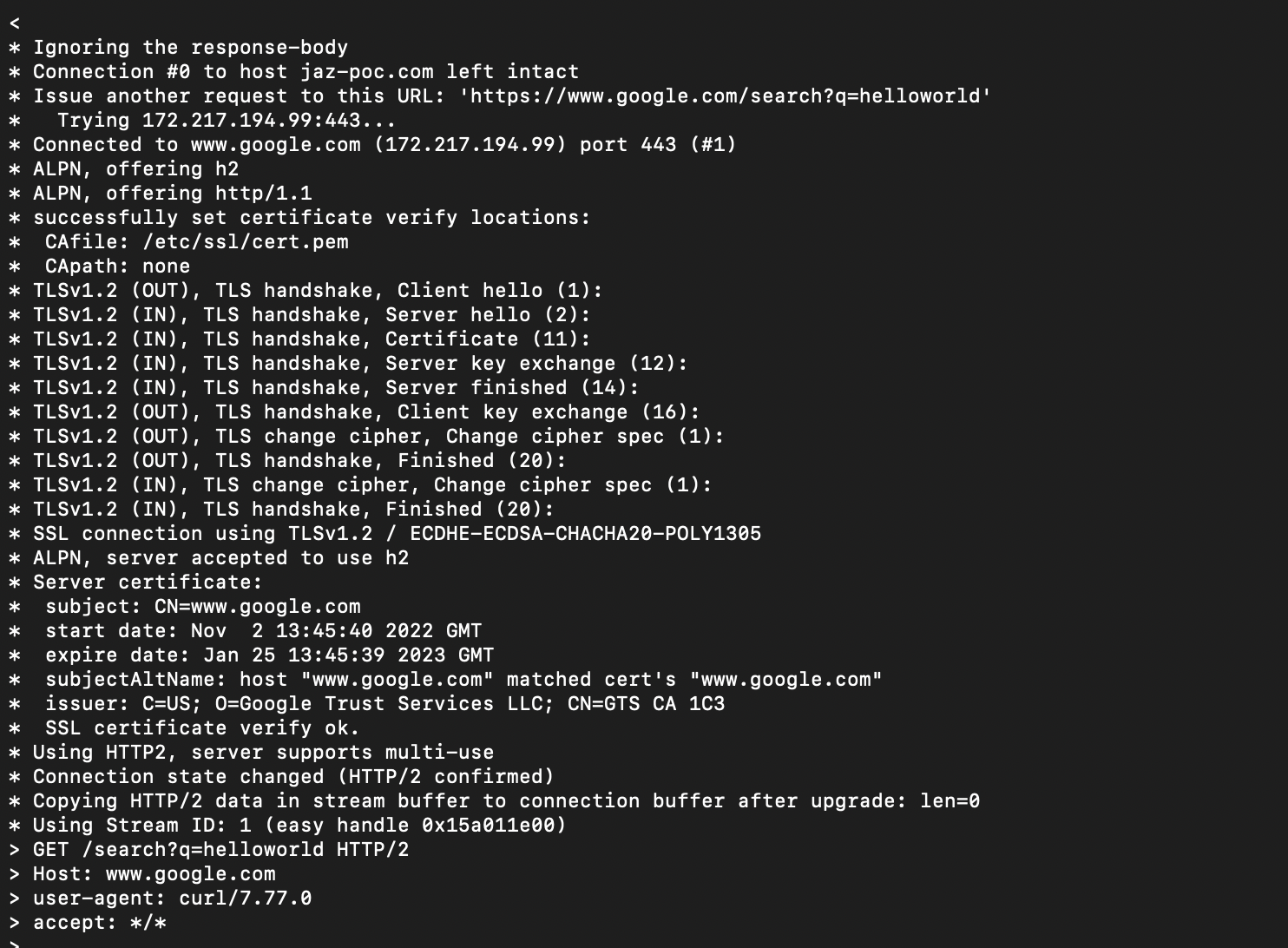
- Have a hosted zone set up for your domain in AWS Route53

- AWS route 53 domain, to add A record with Alias to API gateway custom domain
- ACM cert for API gateway custom domain
- API Gateway
- 2 lambda functions (1 for POST /newurl and 1 for GET /{shortid)
- Dynamodb with shortid as partition key, so that it would be unique
- IAM role with principle of least privilege assigned to Lambda
- High availability : Please make it highly available and no single point of failure.
- Scalability : Please make it scalable.
- Scaling target : 1000+ req/s, after scaling-up/out without major code change
Based on the design requirements, I decided to go for a serverless computing architecture on AWS, making use of Api Gateway, DynamoDB and Lambda. AWS offers technologies for running code, managing data, and integrating applications, all without managing servers. Another benefit of serverless technologies feature automatic scaling, built-in high availability, and a pay-for-use billing model to increase agility and optimize costs.
Lambda is engineered to provide managed scaling in a way that does not rely upon threading or any custom engineering in your code. This also aligns with the requirement that we do not have to do any code change as the number of requests increase. As traffic increases, Lambda increases the number of concurrent executions. Moreover, according to AWS, all AWS accounts start with a default concurrent limit of 1000 per Region. For more details: https://docs.aws.amazon.com/lambda/latest/operatorguide/scaling-concurrency.html
Amazon API Gateway acts as a proxy to the backend operations that you have configured. Amazon API Gateway will automatically scale to handle the amount of traffic your API receives. Moreover, API Gateway also has a account level throttling rate of 10000 requests per second with a burst of 5000 requests. However this might be throttled on a lambda level: https://docs.aws.amazon.com/lambda/latest/operatorguide/on-demand-scaling.html
DynamoDB offers 2 modes of Scaling. 1 is pay per request and the other is provisioned. The pay per request works similar to a lambda pricing model as you only have to pay for what you use, based on how often you Read/Write to the DB. Whereas for provisioned, you are paying for the throughput 24/7. The table below shows the use cases for each:
| Provisioned | Pay Per Request(On Demand) |
|---|---|
| Predictable Traffic | Variable traffic. Also suitable for application in dev environment, for cost optimization purposes |
| Predictable cost structure | Pay per Usage(Can be unpredictable cost based on traffic) |
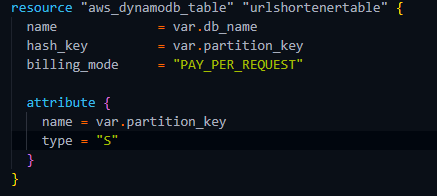
For DynamoDB, I've decided to go with the PAY-PER-REQUEST option as I felt that it was a more cost effective option for the current use case, as it's not a application in production. The pay per request option can simply be enabled using the billing_mode attribute as shown in the screenshot below taken from my my terraform code (dynamodb.tf)
DynamoDB configuration:
- Partition Key: short_id
- Billing mode: PAY PER REQUEST
I have also granted the lambda function, IAM Role based on least privilege(Only access to 1 Table and non admin rights)

I have decided to use Terraform as a IaC to deploy this application. Using IaC also gives me the advantage to deploy the whole infrastructure with a few commands that can be run inside the url-shortener-terraform directory:
terraform init (Prepares the working directory so Terraform can run the configuration)
terraform plan (Preview any changes before applying them)
terraform apply (Executes the changes defined in Terraform configuration to create, update, or destroy resources)
I have also used a s3 backend to configure remote state for terraform. This can be beneficial when working in a team, since there would only be 1 centralized state file and not multiple state files in each developers machine, which can cause conflicts in resource management.
Note: In order to deploy in your own AWS environment please change the following:
- variable domain_name in terraform.tfvars to your own domain and make sure to have a ACM certificate for that domain
- Change the s3 backend bucket name in backend.tf to your own bucket. Or you may alternatively omit using a s3 backend and store the tfstate in the machine which the code runs(Not the recommended way in a actual prod environment)