Presented by Izaskun Mendia at TECNALIA on Nov 29-30, Dec 1-13, 2016.
Hours Allocation Code: 058585_20200
Although numeric data is easy to work with in Python, most knowledge created by humans is actually raw, unstructured text. By learning how to transform text into data that is usable by machine learning models, you drastically increase the amount of data that your models can learn from. In this tutorial, we'll build and evaluate predictive models from real-world text using scikit-learn.
By the end of this tutorial, attendees will be able to confidently build a predictive model, including feature extraction, model building and model evaluation.
Attendees will need scikit-learn and pandas (and their dependencies) already installed. Installing the Anaconda distribution of Python is an easy way to accomplish this. Both Python 2 and 3 are welcome.
I will be leading the tutorial using the IPython/Jupyter notebook, and have added a pre-written notebook to this repository. I have also created a Python script that is identical to the notebook, which you can use in the Python environment of your choice.
- CursoML: CursoMLySKLearn_Intro.pptx. Slides concerning general concepts of Machine Learning.
- CursoML: kaggle-titanic-master.zip. Advanced solution of clasiffication modeling for TITANIC.
- CursoML/Notebooks: Titanic_initial.ipynb, Tutorial_ML.ipynb, 00_pandas.ipynb, 01_cleaning_data.ipynb,02_feature_encoding.ipynb,03_about_standardization_normalization.ipynb,04_svm_iris_pipeline_and_gridsearch.ipynb,05_matplotlib_viz_gallery.ipynb,06_linearPolynomicRegression.ipynb,07_clustering.ipynb
- CursoML/Notebooks/data: data/titanic.txt
Attendees to this tutorial should be comfortable working in Python, should understand the basic principles of machine learning, and should have at least basic experience with both pandas and scikit-learn. However, no knowledge of advanced mathematics is required.
- If you need a refresher on pandas, I recommend reviewing the notebook of this 3-part tutorial, and also 00_pandas.ipynb.
- Book: An Introduction to Statistical Learning (section 2.1, 14 pages)
- Video: Learning Paradigms (13 minutes)
- Codecademy's Python course: browser-based, tons of exercises
- DataQuest: browser-based, teaches Python in the context of data science
- Google's Python class: slightly more advanced, includes videos and downloadable exercises (with solutions)
- Python for Informatics: beginner-oriented book, includes slides and videos
- nbviewer: view notebooks online as static documents
- IPython documentation: focuses on the interpreter
- IPython Notebook tutorials: in-depth introduction
- GitHub's Mastering Markdown: short guide with lots of examples
- scikit-learn documentation: Dataset loading utilities
- Jake VanderPlas: Fast Numerical Computing with NumPy (slides, video)
- Scott Shell: An Introduction to NumPy (PDF)
- Nearest Neighbors (user guide), KNeighborsClassifier (class documentation)
- Logistic Regression (user guide), LogisticRegression (class documentation)
- Videos from An Introduction to Statistical Learning
- Classification Problems and K-Nearest Neighbors (Chapter 2)
- Introduction to Classification (Chapter 4)
- Logistic Regression and Maximum Likelihood (Chapter 4)
- Quora: What is an intuitive explanation of overfitting?
- Video: Estimating prediction error (12 minutes, starting at 2:34) by Hastie and Tibshirani
- Understanding the Bias-Variance Tradeoff
- Guiding questions when reading this article
- Video: Visualizing bias and variance (15 minutes) by Abu-Mostafa Linear regression:
- Longer notebook on linear regression by me
- Chapter 3 of An Introduction to Statistical Learning and related videos by Hastie and Tibshirani (Stanford)
- Quick reference guide to applying and interpreting linear regression by me
- Introduction to linear regression by Robert Nau (Duke)
- Three-part pandas tutorial by Greg Reda
- read_csv and read_table documentation
-
scikit-learn documentation: Cross-validation, Model evaluation
-
scikit-learn issue on GitHub: MSE is negative when returned by cross_val_score
-
Section 5.1 of An Introduction to Statistical Learning (11 pages) and related videos: K-fold and leave-one-out cross-validation (14 minutes), Cross-validation the right and wrong ways (10 minutes)
-
Scott Fortmann-Roe: Accurately Measuring Model Prediction Error
-
Machine Learning Mastery: An Introduction to Feature Selection
-
Harvard CS109: Cross-Validation: The Right and Wrong Way
-
Journal of Cheminformatics: Cross-validation pitfalls when selecting and assessing regression and classification models- scikit-learn documentation: Grid search, GridSearchCV, RandomizedSearchCV
-
Timed example: Comparing randomized search and grid search
-
scikit-learn workshop by Andreas Mueller: Video segment on randomized search (3 minutes), related notebook
-
Paper by Yoshua Bengio: Random Search for Hyper-Parameter Optimization
- Blog post: Simple guide to confusion matrix terminology by me
- Videos: Intuitive sensitivity and specificity (9 minutes) and The tradeoff between sensitivity and specificity (13 minutes) by Rahul Patwari
- Notebook: How to calculate "expected value" from a confusion matrix by treating it as a cost-benefit matrix (by Ed Podojil)
- Graphic: How classification threshold affects different evaluation metrics (from a blog post about Amazon Machine Learning)
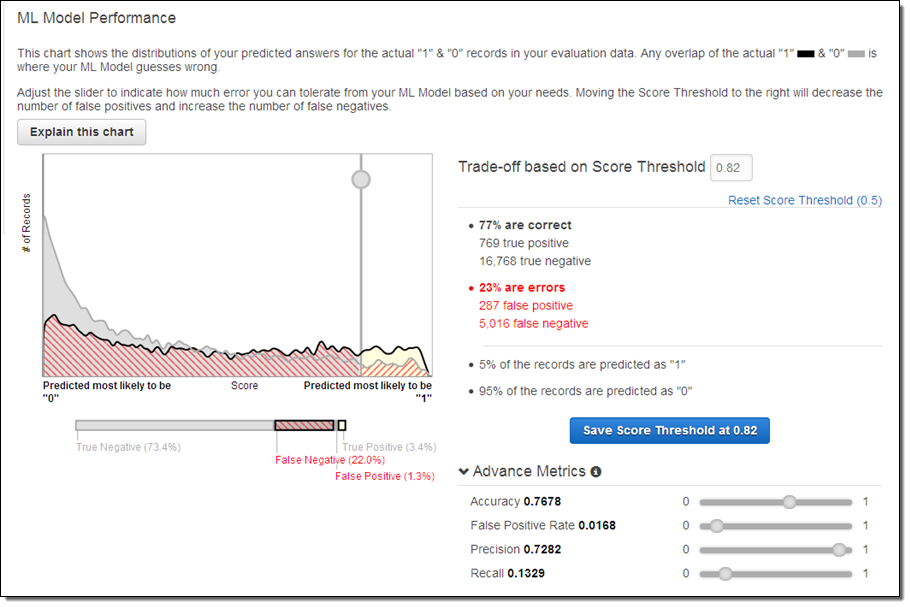{kind=link}
- Lesson notes: ROC Curves (from the University of Georgia)
- Video: ROC Curves and Area Under the Curve (14 minutes) by me, including transcript and screenshots and a visualization
- Video: ROC Curves (12 minutes) by Rahul Patwari
- Paper: An introduction to ROC analysis by Tom Fawcett
- Usage examples: Comparing different feature sets for detecting fraudulent Skype users, and comparing different classifiers on a number of popular datasets
- scikit-learn documentation: Model evaluation
- Guide: Comparing model evaluation procedures and metrics by me
- Video: Counterfactual evaluation of machine learning models (45 minutes) about how Stripe evaluates its fraud detection model, including slides