This project was carried out in June 2019 as part of a Hackathon marking 40 years for Talpiot training program. The project was supervised by the workshop for public knowledge, and was aimed to develop useful tools and insights regarding protocols of the Israeli Knesset Committees (documented in Hebrew), with the major task of automatically clustering and labeling protocols by topic. The goal was motivated by the belief that most of the parliamentary activity is carried on in the committees, and is difficult to regularly follow and understand (e.g. compared to the very structured information of bills votes).
- Eliana Ruby
- Ido Greenberg
- Tomer Loterman
- Noam Bresler
- Yonatan Schwammenthal
- Ofek Zicher
Generally speaking, we threw a bunch of things at the wall to see what stuck. Some things turned out more promising than others, and most of them found at least some interesting results. We're putting a brief explanation of everything we tried and what problems we ran into, in the hopes that someone else might want to continue what we started.
- Data Exploration
- Language parsing with yap
- Topic modeling with LDA
- Document classification with word2vec and Google Translate
- Measure of MK participation by topic
The available data include 37K protocols of few hundreds committees in 9 Knessets in 2004-2018, as can be seen here. Additional metadata such as committees names and categories are available, and it is accordingly shown that the data are dominated by protocols of few committees of type "constant primary".
Further study of the data showed troubling inconsistencies in committees names, protocols dates and protocols introduction sections, making the data harder to work with. Yet, some interesting information was extracted as demonstrated in the example below.
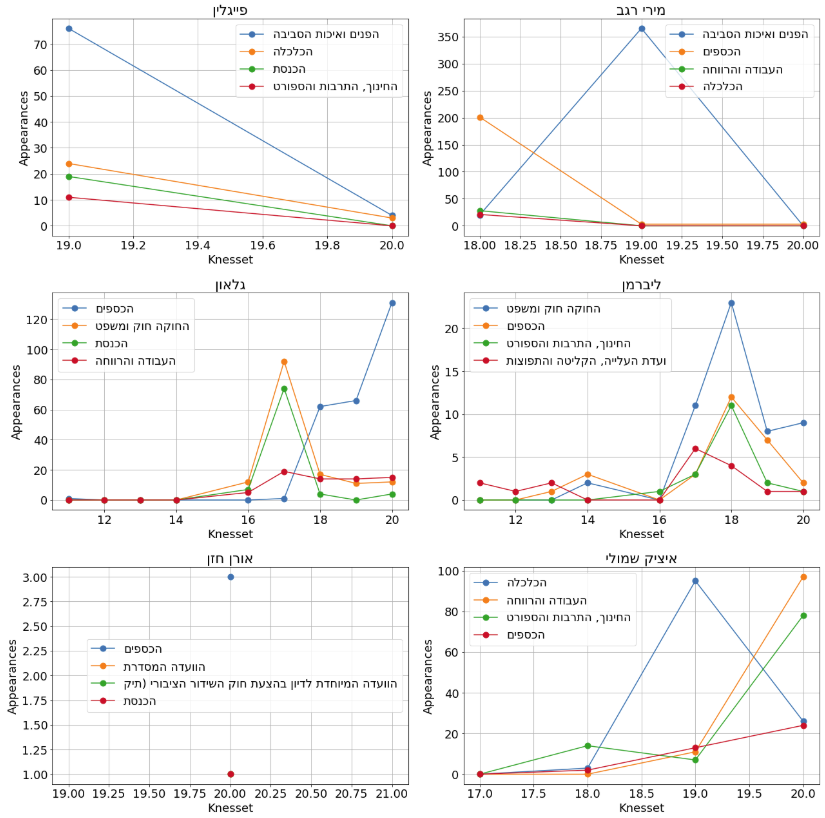 |
|---|
| Activity of a few Knesset Members over the years. For each member, the number of protocols in which he spoke was counted. Only top 4 committees are shown per member. Note that the accuracy of the data summarized in the figures is not guaranteed. |
The preprocessing of the textual data was implemented using the excellent software of YAP for Hebrew parsing, and included tokenization, tagging and filtering of parts-of-speech, and lemmatization of words.
In the constrained timeline of the hackathon, and since the POS-tagging of sentences is a quite slow process, some of the clustering merely used the simple tokenize() function here.
A back of the envelope calculation we did concluded that on a single core machine, it would take 1000-2000 hours to process the whole comittee dataset using YAP. This may sound like a lot, but multiple cpu machines are quite common today, so this operation may be done over a weekend on, for example, a 20 core machine.
If you wish to use the YAP engine, go over the following steps:
We rcommend using the YAP api, which will run on your machine after installation using:
./yap api -cpus NUM_OF_CPUS
LDA is a generative statistical topic model. Here's basically how it works:
- The model gets a bunch of documents,
- Each document is modeled as a collection of words (aka a Bag of Words model). Note: this requires some preprocessing to turn documents into lists of words (aka tokens).
- The model thinks of topics as soft clusters of words - basically, a topic is an object that spits out words with various probabilities. (For example, the topic "Animals" will spit out "dog", "cat", and "zoo" with a high probability, and it will spit out "book", "umbrella", and "parachute" with a lower probability.
- The model thinks of documents as soft clusters of topics - a document is something that is made up of different topics (for example, a document could be 30% about animals, 50% about food and 20% about German philosophy).
- Given a collection of documents, the model infers what the topic clusters are by seeing what words come up often in the same documents.
For a more in-depth explanation, check out this article.
In order to use LDA, you'll have to do the following steps:
- Preprocessing:
- tokenization (separating the document into a list of words)
- stopwords (getting rid of words junk words like "and" or "hi" that show up a lot but aren't indicative of anything)
- filtering by parts of speech - this is a really good way of getting rid of junk words. using just the nouns or just nouns and verbs usually makes for better models.
- lemmatization - converting all conjugations (הטיות) of words to a base form. (For example: turning "סטודנטים", "הסטודנט", and "סטודנטית" into "סטודנט". This is also really important for the model, because it combines a bunch of words that are basically duplicates into just one word.
- Training the model - after preprocessing all your data, you feed it to the model and see what happens. We used gensim, but sklearn also has a good one.
- Evaluating the model - after training the model, you can have a look at what came out. We used pyLDAvis, which is how you get the awesome visualizations you can see in our notebooks. Other than generally checking to see whether the model makes sense, you can also use gensim to check the topic coherence (we did this in our code). Generally, a topic coherence above 0.6 is considered good (we got to about 0.5).
- Inference - after building the model, you can give it documents and see what topics they belong to.
For a more in-depth explanation and usage guide, check out this article.
Problems we ran into:
- Like we mentioned in the part about language parsing, YAP is kinda slow so we couldn't process all our data. You can train the model on a subset of data (which we tried by only running it on the titles), but then it's less good. Also, if you want to use the model for inference on new documents, you have to do the same preprocessing on the new documents so that the model can make sense of them.
- Even without having to preprocess everything, the running time is still annoyingly long. In fact, not preprocessing the data makes the problem worse, because then it has to deal with more words which makes the running time go up linearly. (We tried running it on just the Science and Technology committee, and got results that were kind of okay?
Bottom line: This could actually work pretty well if we had more time and computing power to work with. Hopefully someone can take our code and use it to do that.
Since available NLP software for Hebrew pales in comparison to the tools available for English, a possible shortcut to cutting-edge NLP in Hebrew might be translation of the text from Hebrew to English. Fortunately, even though the technological challenge of translation is difficult by itself, several relevant tools are available in this case.
We showed that it is possible to efficiently translate committees protocols using the corresponding API of Google Translate, and demonstrated the use of Word2Vec representation of the translated text for clustering. While the time did not permit any further applications, we believe that this approach may have large potential for future use. For example: only by averaging word vectors for each document in the corpus, we saw some example of simillar documents having smaller Mean Squarred Errors (or any other metric/s) from each other, and vice-versa. Theres also an approach of finding/training a hebrew vectorizer (Word2Vec is a model trained on Wikipedia), but we did not dive into that.
This section expands a bit on on the data exploration presented at the beggining. Essenstially the committee dataset contains the text spoken by each committee member, which enables us to track not only the MK binary participation / lack therof in a committee, but also a more complex measure of his presenct. One such naive measure is the amount of words/chars contained in said MK speach per committee. This direction was started but never completed due to lack of time.