Structured outputs evaluation blog with dottxt - release early next week #2021
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,211 @@ | ||
| --- | ||
| title: "Improving Prompt Consistency with Structured Generations" | ||
| thumbnail: /blog/assets/evaluating-mmlu-leaderboard/thumbnail.png | ||
| authors: | ||
| - user: willkurt | ||
| guest: true | ||
| org: dottxt | ||
| - user: remi | ||
| guest: true | ||
| org: dottxt | ||
| - user: clefourrier | ||
| --- | ||
|
|
||
| # Improving Prompt Consistency with Structured Generations | ||
|
|
||
| Recently, the *Leaderboards and Evals* research team at Hugging Face did small experiments, which highlighted how fickle evaluation can be. For a given task, results are extremely sensitive to minuscule changes in prompt format! However, this is not what we want: a model prompted with the same amount of information as input should output similar results. | ||
|
|
||
| We discussed this with our friends at *Dottxt*, who had an idea - what if there was a way to increase consistency across prompt formats? | ||
|
|
||
| So, let's dig in! | ||
|
|
||
| ## Context: Evaluation Sensitivity to Format Changes | ||
|
|
||
| It has become increasingly clear that LLM benchmark performance is closely, and somewhat surprisingly, dependent on the *format* of the prompt itself, even though a number of methods have been introduced through the years to reduce prompt-related variance. For example, when we evaluate models in few-shot, we provide format examples to the model to force a specific pattern in output; when we compare the log-likelihood of plausible answers instead of allowing free-form generation, we attempt to constrain the answer space. | ||
|
|
||
| The *Leaderboards and Evals* team provided a demonstration of this by looking at 8 different prompt formats for a well known task, MMLU (looking at 4 subsets of the task). These prompt variations were provided to 5 different models (chosen because they were SOTA at the time for their size, and covered a variety of tokenization and languages). Scores were computed using a log-probability evaluation, where the most probable answer is considered the correct one, a classic metric for multi-choice tasks. | ||
|
|
||
| Let's look at the different formats in more detail, by using the first question of the `global_facts` subset of MMLU. | ||
|
|
||
| ``` | ||
|
|
||
| Question: “As of 2016, about what percentage of adults aged 18 years or older were overweight?” | ||
|
|
||
| Choices: [ "10%", "20%", "40%", "80%" ] | ||
|
|
||
| Correct choice: “40%” | ||
|
|
||
| ``` | ||
|
|
||
| <div> | ||
| <table><p> | ||
| <tbody> | ||
| <tr> <td colspan=3 text-align=center> Without choices in the prompt </td></tr> | ||
| <tr style=" vertical-align: top;"> | ||
| <td>As of 2016, about what percentage of adults aged 18 years or older were overweight?</td> | ||
| <td>Q: As of 2016, about what percentage of adults aged 18 years or older were overweight? <br><br> A: </td> | ||
| <td>Question: As of 2016, about what percentage of adults aged 18 years or older were overweight?<br><br> Answer: </td> | ||
| </tr> | ||
| <tr> <td colspan=3> </td></tr> | ||
| <tr> <td colspan=3> With choices in the prompt </td></tr> | ||
| <tr> | ||
| <td>Question: As of 2016, about what percentage of adults aged 18 years or older were overweight?<br><br> | ||
| Choices: <br><br> | ||
| 10% <br> | ||
| 20% <br> | ||
| 40% <br> | ||
| 80% <br><br> | ||
| Answer: </td> | ||
| <td>Question: As of 2016, about what percentage of adults aged 18 years or older were overweight?<br><br> | ||
| Choices: <br><br> | ||
| A. 10% <br> | ||
| B. 20% <br> | ||
| C. 40% <br> | ||
| D. 80% <br><br> | ||
| Answer: </td> | ||
| <td>Question: As of 2016, about what percentage of adults aged 18 years or older were overweight?<br><br> | ||
| Choices: <br><br> | ||
| (A) 10% <br> | ||
| (B) 20% <br> | ||
| (C) 40% <br> | ||
| (D) 80% <br><br> | ||
| Answer: </td> | ||
| </tr> | ||
| <tr> | ||
| <td> Log probs of 10%, 20%, 40%, 80% </td> | ||
| <td> Log probs of 10%, 20%, 40%, 80% vs A, B, C, D </td> | ||
| <td> Log probs of 10%, 20%, 40%, 80% vs (A), (B), (C), (D), </td> | ||
|
|
||
| </tbody> | ||
| </table><p> | ||
| </div> | ||
|
|
||
| Prompts either contain just the question, or some tags to indicate that we are in a question/answer format, and possibly the choices in the prompt. In all cases, evaluations compare the log-likelihood of the possible choices only. All these formats appear in the evaluation literature, and should contain virtually the same amount of information in each row. However, just below, you can see the wide variation in performance across these theoretically superficial changes! | ||
|
|
||
|
|
||
| 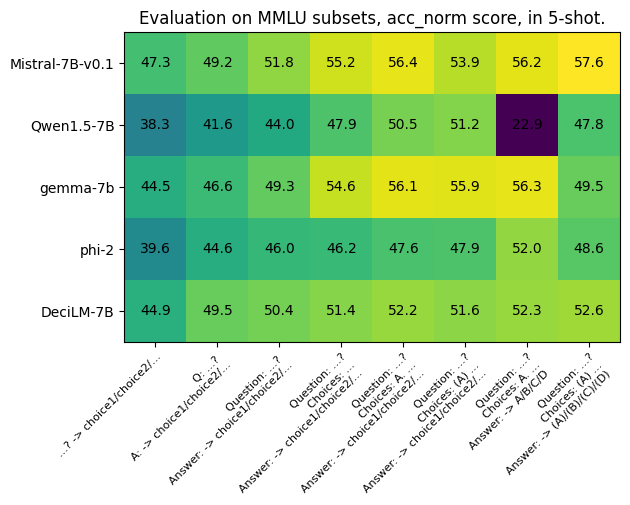 | ||
|
|
||
| Each model sees its performance vary by around 10 points, with the exception of the most extreme example, Qwen1.5-7B, dropping all the way to an accuracy of 22.9% with the 7th prompt variation (mostly due to a tokenizer issue), with essentially the same information it was able to achieve an accuracy of up to 51.2% with another prompt. | ||
|
|
||
| In isolation, a change in *score* is not necessarily a big deal so long as the *ranking* is consistent. However, as we can see in the next plot, ranking is impacted by these changes: | ||
|
|
||
| 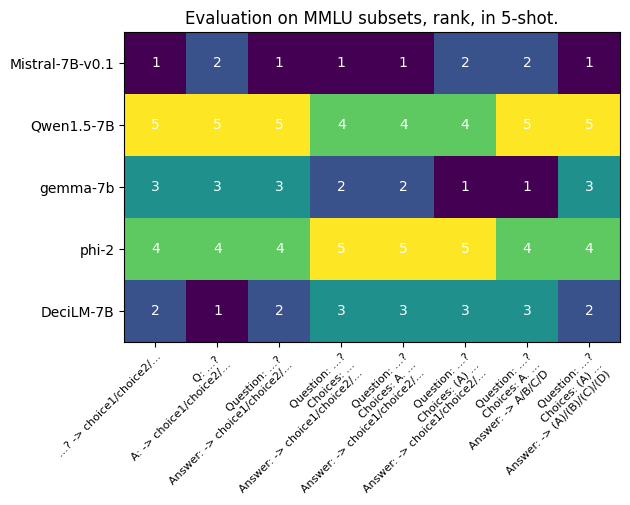 | ||
|
|
||
| No model is consistently ranked across prompts even though the only difference is their format, not the information itself. This means that if the authors of Gemma-7b wanted to show that their model was superior to Mistral-7B-v0.1, they could do so simply by choosing the correct prompt. | ||
|
|
||
| As almost no one reports their precise evaluation setup, this is what has historically happened in model reports, where authors chose to report the setup most advantageous to their model (which is why you’ll see extremely weird reported numbers of few-shots in some papers). | ||
|
|
||
| However, this is not the only source of variance in model scores. | ||
|
|
||
| In extended experiments, we compared evaluating the same models, with the same prompt formats, using the exact same few-shot samples shuffled differently before the prompt (A/B/C/D/E Prompt vs C/D/A/B/E Prompt, for example). The following figure shows the model scores delta between these two few-shot orderings: we observe a difference of up to 3 points in performance for the same model/prompt combination! | ||
|
|
||
| 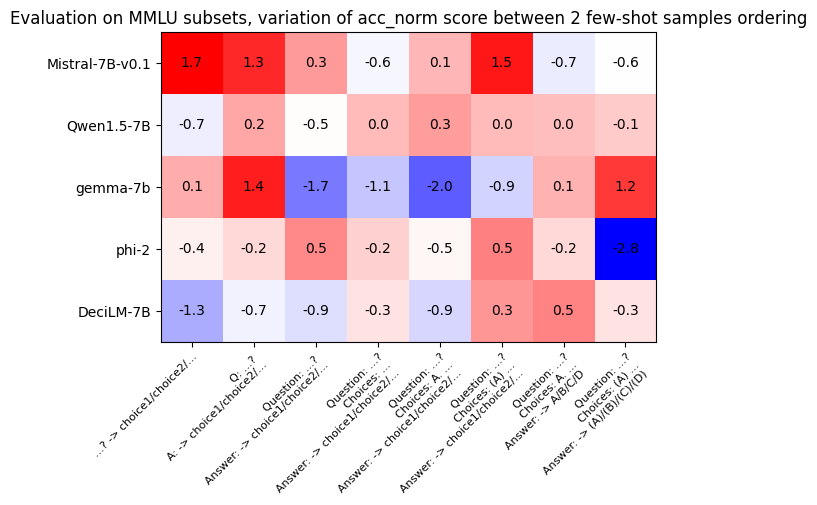 | ||
|
|
||
| If we want to be able to properly evaluate and compare different models we need a way to overcome this challenge. | ||
|
|
||
| Sclar, et al’s *[Quantifying Language Model’s Sensitivity to Spurious Features in Prompt Design](https://arxiv.org/abs/2310.11324)* also gives a good overview of this issue, and the authors introduce [FormatSpread](https://github.com/msclar/formatspread), a software tool that evaluates each model with multiple different variations of formats, then calculate the variance of that model's performance. Solutions such as this allow us to determine with more confidence which models are better than others, but they come at a high computation cost. | ||
|
|
||
| ## What if we focused on the output, not the input, to make results more consistent across these small changes to format? | ||
|
|
||
| While FormatSpread is a great attempt to make leaderboards more fair and honest, what we really want as practical users of LLMs is *prompt consistency*. That is, we would like to find some way to reduce this variance among prompts. | ||
|
There was a problem hiding this comment. Isn't this about the output instead, based on the section header? If we are considering both, then maybe we should clarify a bit. |
||
|
|
||
| At [.txt](http://dottxt.co/), we focus on improving and better understanding *structured generation,* which is when the output of a model is constrained to follow a specific structure. Our library, [Outlines](https://github.com/outlines-dev/outlines), allows us to structure the output of an LLM by defining a regular expression or a context-free grammar (we give examples below). | ||
|
|
||
| Our initial use case for structured generation was to make LLMs easier to interact with programmatically, by ensuring responses in well formatted JSON. However, we’ve continually been surprised by other benefits of structured generation we’ve uncovered. | ||
|
|
||
| When working on earlier research exploring the benefits of structured generation, we demonstrated that [structured generation consistently improves benchmark performance](http://blog.dottxt.co/performance-gsm8k.html), and came across an interesting edge case when exploring JSON structured prompts. | ||
|
|
||
| In most cases, changing the prompt format to JSON, even when using unstructured generation, leads to improved benchmark performance for almost all models. However, this was not the case for MetaMath-Tulpar-7b-v2-Slerp, where we found a dramatic decrease in accuracy when using prompts formatted in JSON. Even more surprising was that when using *structured generation* to constrain the output of the model, the dip in performance was negligible! | ||
|
|
||
| This led us to question whether or not structured generation could be exploited for *prompt consistency*. | ||
|
|
||
|  | ||
|
|
||
| ### Note on the experimental setup: Focusing on n-shot and shot order | ||
|
|
||
| While in the above experiments, Hugging Face’s *Leaderboard and Evals* research team explored changes to the format of the prompt itself, for the next experiments we’re going to restrict the changes. | ||
|
|
||
| To focus our exploration of prompt space, we’re going to look at varying just two properties of the prompt: | ||
|
|
||
| 1. Varying the number of “shots” or examples used in the prompt (n*-shot*) | ||
| 2. Varying the order of those shots (*shot order*, specified by a *shot seed*) | ||
|
|
||
| For point 2, with a given n-shot we are only shuffling the same *n* examples. This means that all shuffles of a 1-shot prompt are the same. This is done to avoid conflating the *format* of a prompt with the *information* it contains. Clearly a 5-shot prompt contains more information than a 1-shot prompt, but every shuffling of a 5-shot prompt contains the same examples, only in a different order. | ||
|
|
||
| ## Initial Exploration: GSM8K 1-8 shot prompting | ||
|
|
||
| In order to test this out further, we wanted to explore the behavior of two very similar but strong models in the 7B parameter space: Mistral-7Bv0.1 and Zephyr-7B-beta. The reason behind this choice is to not only study variance in individual outcomes, but to look at the *changes in relative ranking*. We use the GSM8K task which is a set of grade school math word problems. | ||
|
|
||
| Here is the basic format of a GSM8K 1-shot prompt with the implied structure highlighted. | ||
|
|
||
| 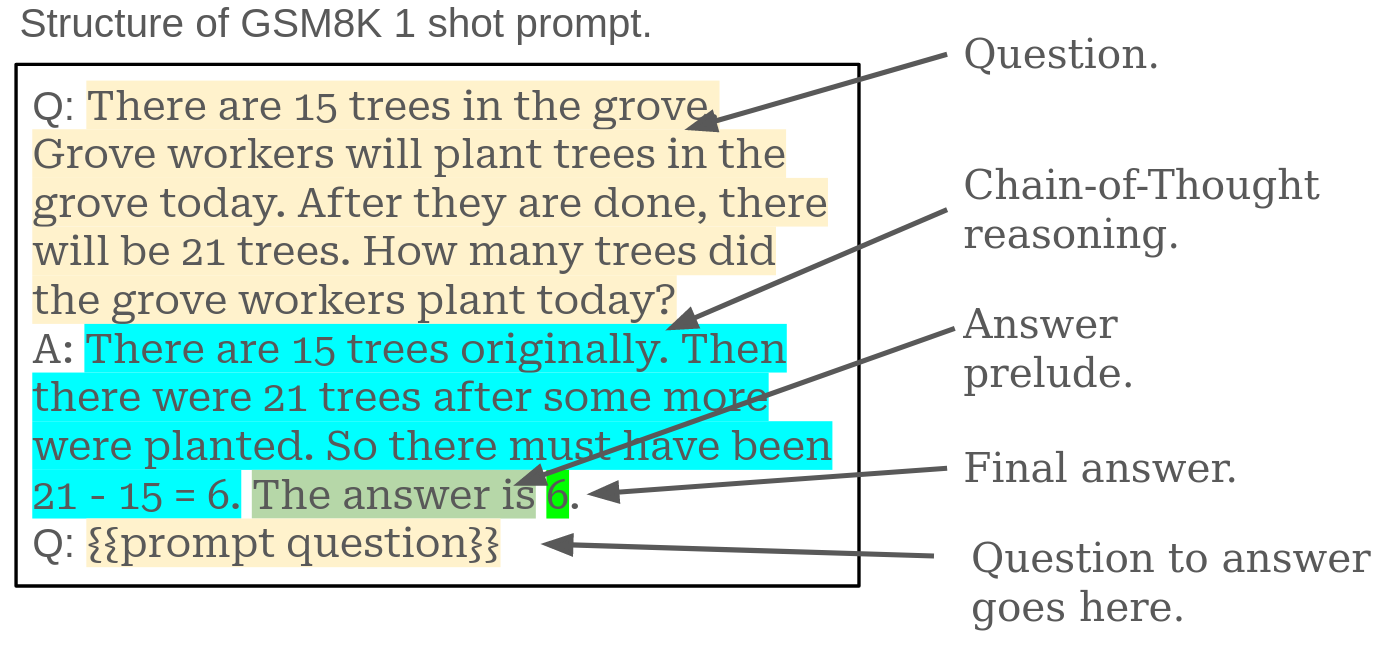 | ||
|
|
||
| In order to consistently generate correctly structured answers we create a regular expression that matches the structure we see inherent in the original prompt format. The following regex is used in Outlines to define the structure for generation: | ||
|
|
||
|  | ||
|
|
||
| We can see in the regex that we allow the model to reason for anywhere from 200 to 700 characters, then it must declare that “The answer is” and then reply with up to 10 digit number (that cannot start with 0). | ||
|
|
||
| It’s worth mentioning that the regex controlling the structure is similar, but not identical to, the regex used to parse out the answer. We’ve learned there’s an interesting bit of nuance in defining the structure since, like the prompt, it can impact performance. For example, notice that `{200,700}` in the regex. This means that the model has 200 to 700 characters to “reason” before answering. Changing these values can impact performance and leads to something we refer to as “thought control”, an area we’re hoping to write more about soon. | ||
|
|
||
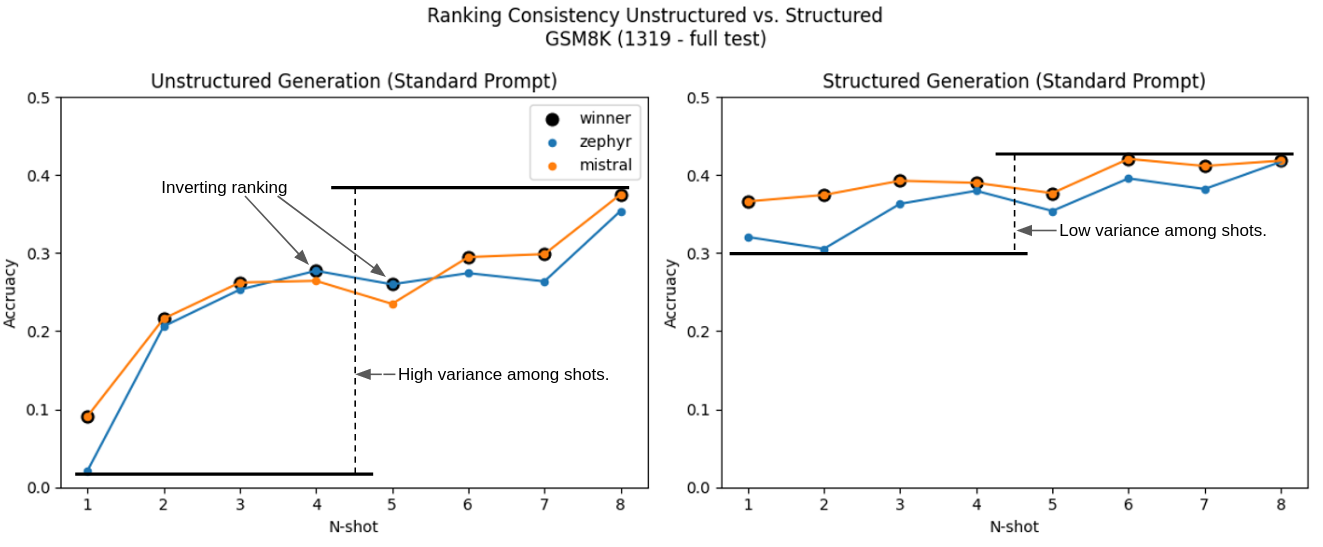
| Our first experiment was to continue exploring the GSM8K dataset and iterated on 1 through 8 shot prompting. The results, shown below, were very compelling. | ||
|
|
||
|  | ||
|
|
||
| There are two major features we see in this figure: variance in performance across the n-shot setups was majorly reduced and there were no instances where the ranking swapped (Mistral consistently leads over Zephyr). It’s also worth pointing out that 1-shot structured performance is substantially better than 1-shot unstructured performance, and on par with 5-shot. This leads to another area of research we’re terming “prompt efficiency”. | ||
|
|
||
| ## Diving Deeper: GPQA n-shot and shot order variations | ||
|
|
||
| For the next experiment we wanted to look at varying both n-shots as well as the order of the n-shots. Order was controlled by setting the seed used for shuffling the examples. As mentioned previously, only the first n-shots are shuffled to keep the information consistent between prompts, this means that all 1-shot prompts are the same across seeds. Here’s an example of the shot order for 4-shot: | ||
|
|
||
| | seed | 4-shot order | | ||
| | --- | --- | | ||
| | 42 | 2-1-3-0 | | ||
| | 1337 | 1-0-3-2 | | ||
| | 1981 | 3-2-0-1 | | ||
| | 1992 | 0-3-1-2 | | ||
| | 12345 | 1-0-2-3 | | ||
|
|
||
| Additionally, to explore how transferable these results were, we changed the task to [Graduate-Level Google-Proof Q&A Benchmark (GPQA)](https://arxiv.org/abs/2311.12022). GPQA is a hard knowledge multi-choice evaluation task. Below is the prompt format and highlighted structure. | ||
|
|
||
| 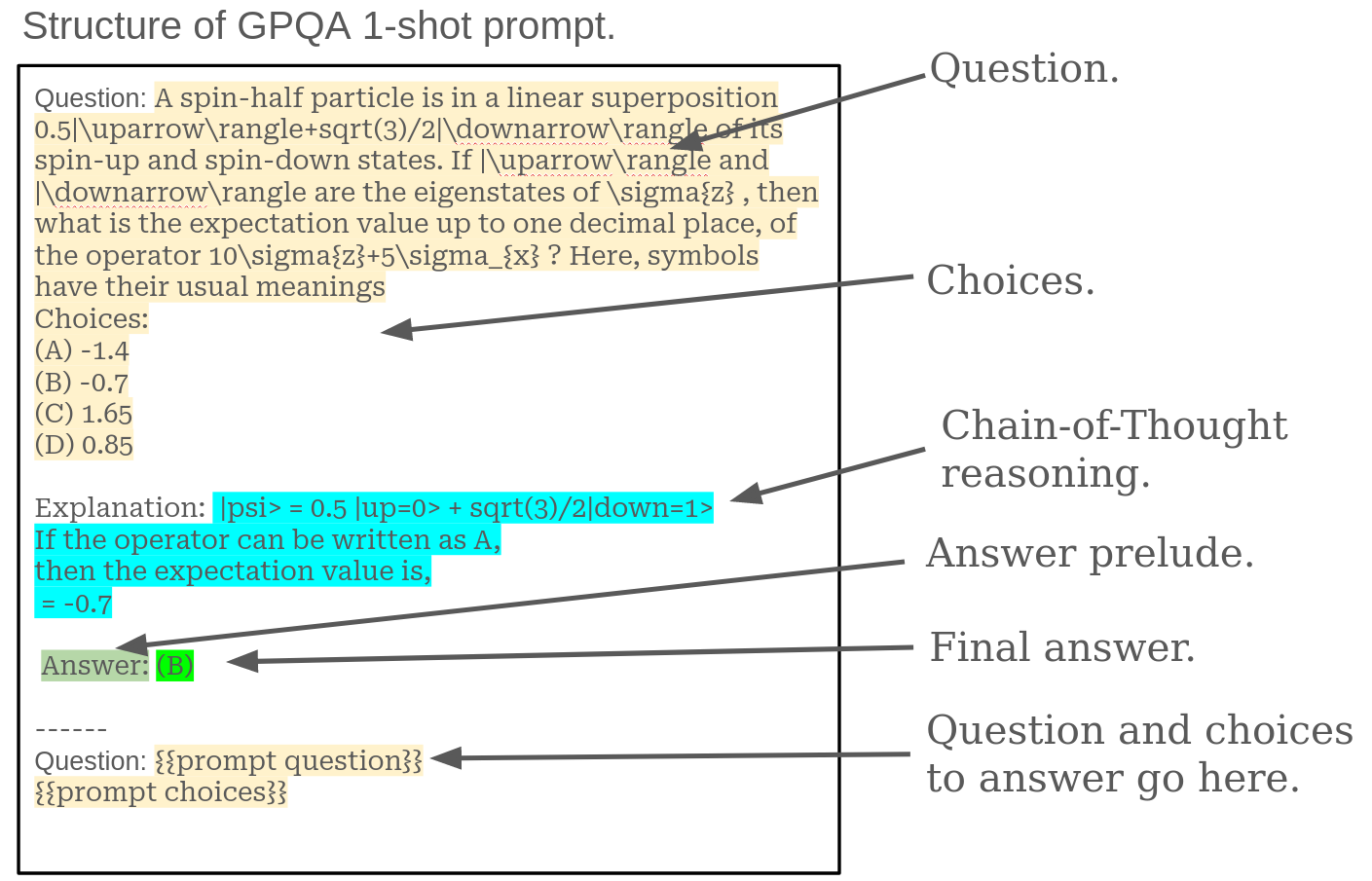 | ||
|
|
||
| For this next experiment we are specifically using the ‘diamond’ subset which represents curated and cleaned up high quality questions. Of the 198 questions in this dataset we reserve 8 for n-shot prompting (though only ever used the first 5), and then evaluated on the remaining 190 questions. | ||
|
|
||
| Visualized below we can see a grid representing the accuracy achieved for all the possible combinations for shot seed and *n*, for the two models, both without (left) and with (right) structured generation. | ||
|
|
||
| 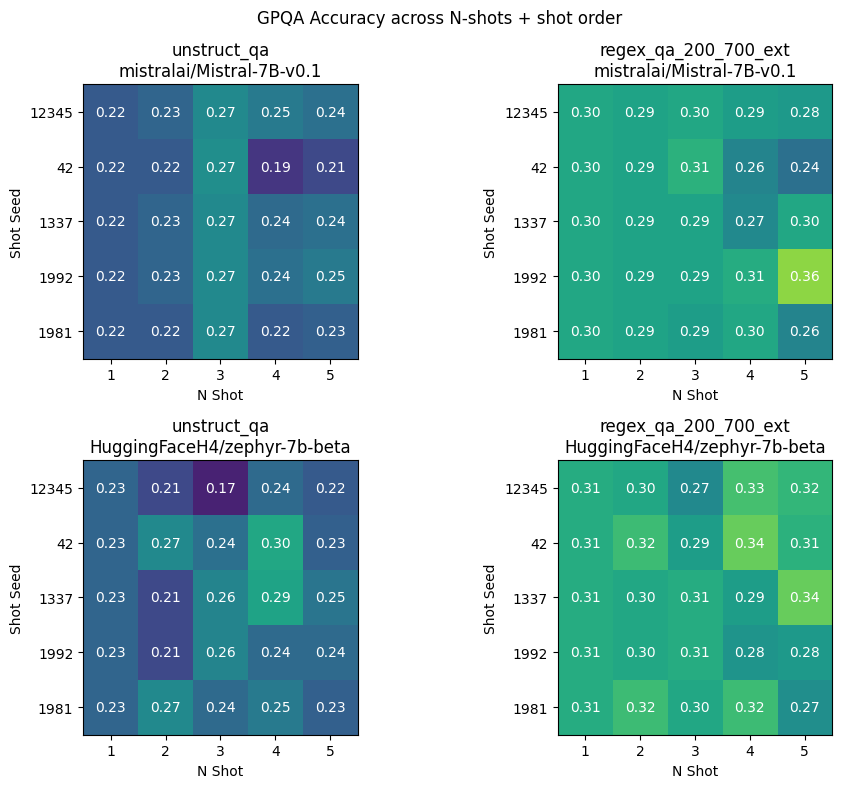 | ||
|
|
||
| One thing which immediately stands out is that the structured output tends to score higher than the unstructured output across the board. We see the mean of each grid for structured and unstructured below: | ||
|
|
||
| **Mean of results across prompt seed and n-shot** | ||
|
|
||
| | model | unstructured | structured | | ||
| | --- | --- | --- | | ||
| | Mistral-7B-v0.1 | 0.2360 | 0.2935 | | ||
| | Zephyr-7b-beta | 0.2387 | 0.3048 | | ||
|
|
||
| Additionally, across all the values in the grid we also find *reduced variance* when comparing the structured with unstructured generation. | ||
|
|
||
| **Standard deviation in results across prompt seed and n-shot** | ||
|
|
||
| | model | unstructured | structured | | ||
| | --- | --- | --- | | ||
| | Mistral-7B-v0.1 | 0.0213 | 0.0202 | | ||
| | Zephyr-7b-beta | 0.0273 | 0.0180 | | ||
|
|
||
| This reduction in variance across the grid is similar to the reduction in variance we saw when looking at just n-shot changes for GSM8K. | ||
|
|
||
| While increased expected performance and decreased variance are great properties to have, what we really want to understand is the impact on ranking. In the next plot we examine these grids in terms of which of the two models would be declared a winner: | ||
|
|
||
| - A: Zephyr-7b-beta | ||
| - B: Mistral-7B-v0.1 | ||
| - “-”: tie | ||
|
|
||
| 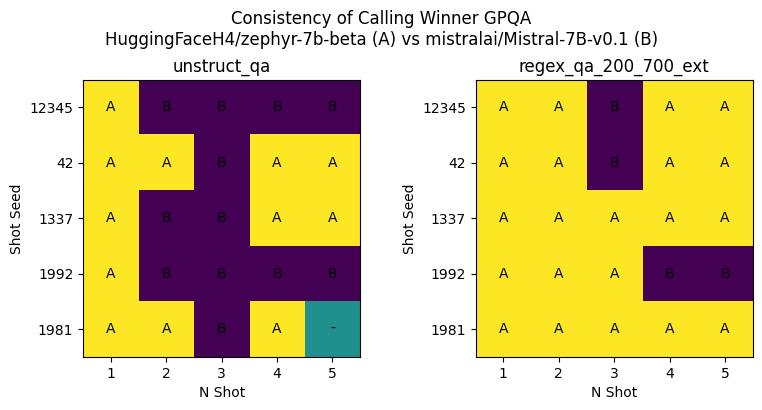 | ||
|
|
||
| As we can see from these images, there is a major improvement in the consistency of calling a winner when structured generation is applied. These results paint a consistent picture with the findings we had using GSM8K across various n-shot. | ||
|
|
||
| ## Conclusion and Future Work | ||
|
|
||
| While these results are incredibly promising, we still need to explore these results across more models and more tasks. What we’ve seen so far is that structured generation could prove to be an essential part of evaluation. Simultaneously *increasing* the expected score and *decreasing* the variance across prompt changes is a very promising result that deserves further research. | ||
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Uh oh!
There was an error while loading. Please reload this page.