Arrow X Datasets Blog #1283
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| @@ -0,0 +1,152 @@ | ||||||||||||||||||||||||||||||
| --- | ||||||||||||||||||||||||||||||
| title: "Data Analytics with Apache Arrow and Hugging Face Datasets" | ||||||||||||||||||||||||||||||
| thumbnail: /blog/assets/arrow-datasets/bla.png | ||||||||||||||||||||||||||||||
| authors: | ||||||||||||||||||||||||||||||
| - user: cakiki | ||||||||||||||||||||||||||||||
| - user: lhoestq | ||||||||||||||||||||||||||||||
| - user: mariosasko | ||||||||||||||||||||||||||||||
| --- | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| # Data Analytics with Apache Arrow and Hugging Face Datasets | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| <!-- {blog_metadata} --> | ||||||||||||||||||||||||||||||
| <!-- {authors} --> | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| Hugging Face Datasets is a library that was designed to complement machine learning training workflows. It enables users to share, download, process, and format datasets to get them ready for training with any of the major machine learning frameworks, across all data modalities: audio, video, text, and tabular. In the Hugging Face ecosystem, the 🤗 `datasets` library is typically the first entrypoint of a machine learning project: it is therefore especially crucial it be performant and efficient. | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| |  | | ||||||||||||||||||||||||||||||
| |:--:| | ||||||||||||||||||||||||||||||
| | <i>Hugging Face libraries mapped to the steps of a typical machine learning workflow. Source: <a href="https://github.com/nlp-with-transformers" rel="noopener" target="_blank" >Natural Language Processing with Transformers</a></i>| | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| One of the many strengths of 🤗 `datasets` is its ability to [quickly and efficiently](https://huggingface.co/docs/datasets/about_arrow) handle data that is too large fit into system memory. This is made possible by using the Apache [Arrow Columnar Format](https://arrow.apache.org/docs/format/Columnar.html) as its underlying memory model. This post will showcase the synergies between the two projects, and how using the Arrow ecosystem can supercharge your library, giving you access to more features than you initially bargained for. This post will show you how you can use 🤗 `datasets` for out-of-core data analytics to better understand your data, ahead of using it to train a model. | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ## Apache Arrow | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| According to the [official website](https://arrow.apache.org/), Apache Arrow is: (1) a column-oriented **standardized memory format**, (2) a set of **libraries** that implement said format and various utilities around it, and (3) an **ecosystem** of projects using them. 🤗 `datasets` is one of many projects of this ecosystem and leverages the Arrow memory format through the use of the [PyArrow library ](https://arrow.apache.org/docs/python/index.html): the official Python API of Apache Arrow. The Arrow format is further described as a: | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| > language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware like CPUs and GPUs. The Arrow memory format also supports zero-copy reads for lightning-fast data access without serialization overhead. | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| Let's unpack this: | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| - **language indepedent**: the data representation in memory is the same, no matter the programming language or library. | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
| - **columnar**: data is contiguous in memory and grouped by column, as opposed to by row. | ||||||||||||||||||||||||||||||
| - **efficient analytic operations**: the data is formatted in such a way that allows vectorized operations like [SIMD](https://en.wikipedia.org/wiki/Single_instruction,_multiple_data). | ||||||||||||||||||||||||||||||
| - **zero-copy reads with serialization overhead**: once data is in memory, moving it between different libraries (e.g. from `pandas` to `polars`), threads, or even different languages (e.g. from `python` to `rust`) is free. | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| Further features of Arrow that make it especially useful in machine learning worflows include: | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| - **Constant-time random access**: indexing into a specific row is a constant time operation | ||||||||||||||||||||||||||||||
| - **Efficient sequential scans**: the columnar memory layout makes for efficient iterating over the dataset | ||||||||||||||||||||||||||||||
| - **Data can be memory-mapped**: larger-than-memory datasets can be serialized onto disk and memory-mapped from there. | ||||||||||||||||||||||||||||||
| As a user, you typically won't need interact with Arrow directly, but rather use [libaries which use Arrow](https://arrow.apache.org/powered_by/) to represent tabular data in memory. However, as we'll see later in this post, even if the Arrow internals are abstracted away, being aware of them can give users access to more functionality than afforded by a given library. | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| <!-- | 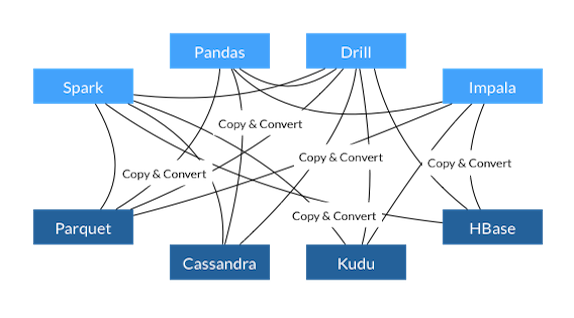 | 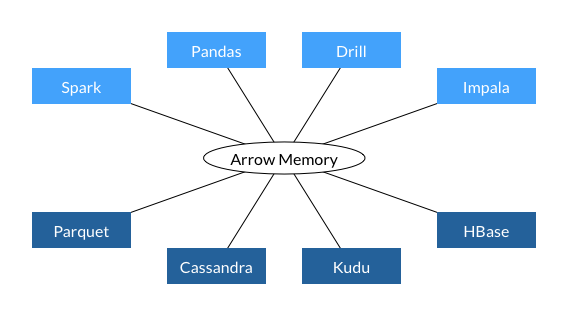 | ||||||||||||||||||||||||||||||
| |:--:|:--:| | ||||||||||||||||||||||||||||||
| |<i>TODO</i>|<i>TODO</i>| | ||||||||||||||||||||||||||||||
| <div align="center"> Source: <a href="https://arrow.apache.org/overview/" rel="noopener" target="_blank" >Apache Arrow Overview</a></div> --> | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ### Hugging Face Datasets | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| A Hugging Face `datasets.Dataset` object is at its core a dataframe-like structure called an Arrow Table: a 2-dimensional data structure with a schema and named columns. When you load a dataset for the first time, it is serialized in batches into one ore more `.arrow` memory files in your cache directory, then finally mmapped from those files on disk. To peek behind the scenes of this process let's begin by downloading the dataset we'll be using, a subset of [the Stack](https://huggingface.co/datasets/bigcode/the-stack-dedup), a dataset that was used to train the [StarCoder](https://huggingface.co/bigcode/starcoder) family of code large language models. | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ```python | ||||||||||||||||||||||||||||||
| from datasets import load_dataset | ||||||||||||||||||||||||||||||
| dset = load_dataset("cakiki/stack-smol-xxl", split="train") # ~107GB of disk space required to run this | ||||||||||||||||||||||||||||||
| print(type(dset)) | ||||||||||||||||||||||||||||||
| print(type(dset.data.table)) # dset.data.table is the underlying Arrow Table | ||||||||||||||||||||||||||||||
| print([shard["filename"].split("/")[-1] for shard in dset.cache_files]) | ||||||||||||||||||||||||||||||
| print(len(dset.cache_files), "cache files") | ||||||||||||||||||||||||||||||
| >>> <class 'datasets.arrow_dataset.Dataset'> | ||||||||||||||||||||||||||||||
| >>> <class 'pyarrow.lib.Table'> | ||||||||||||||||||||||||||||||
| >>> ['parquet-train-00000-of-00144.arrow', 'parquet-train-00001-of-00144.arrow', ... ] # These are the serialized files on disk. (Output trimmed) | ||||||||||||||||||||||||||||||
| >>> 144 cache files | ||||||||||||||||||||||||||||||
| ``` | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| Caching onto disk is not limited to loading data, but also transforming it. Indeed, as we'll see in a second, when you operate on a dataset, be it through filtering, mapping, or structural transformations, these operations are also cached to disk and only need to run once. Before we move on to the next section, let's quickly inspect the code dataset we just loaded: | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ```python | ||||||||||||||||||||||||||||||
| print(f'{dset.num_rows:,}', "rows") | ||||||||||||||||||||||||||||||
| print(dset.num_columns, "columns") | ||||||||||||||||||||||||||||||
| print(dset.dataset_size / 1024**3, " GB") | ||||||||||||||||||||||||||||||
| print(dset[1200000]) | ||||||||||||||||||||||||||||||
| print(dset[:4]) | ||||||||||||||||||||||||||||||
| >>> 11,658,586 rows | ||||||||||||||||||||||||||||||
| >>> 29 columns | ||||||||||||||||||||||||||||||
| >>> 73.18686429131776 GB | ||||||||||||||||||||||||||||||
| >>> {'hexsha': '7a4d22966630185a027c6ee50494472b3c1b3fa4', 'size': 10253, 'ext': 'jl', 'lang': 'Julia', 'max_stars_repo_path': 'src/cwv.jl' ...} # Indexing into a dataset returns the correspdonding row as a dictionary. | ||||||||||||||||||||||||||||||
| >>> {'hexsha': ['0a84ade1a79baf9000df6f66818fc3a568c24173', '0a84b588e484c6829ab1a6706db302acd8514288', '0a89bca33bdfce1f07390d394915f18e0d901651', '0a96a3eeaa089f8582180f803252e3739ab2661d'], 'size': [10354, 999, 43147, 597], 'ext': ['css', 'css', 'css', 'css'], 'lang': ['CSS', 'CSS', 'CSS', 'CSS'], ...} # By default, slicing a dataset returns a dictionary of the columns as lists of regular python objects. Makes sense since arrow is a columnar format. (Output trimmed) | ||||||||||||||||||||||||||||||
| ``` | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ### Hugging Face Dataset Formats | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| As you just saw, accessing data by slicing returns a dictionary where each column is a list of python objects, and accessing a single row returns a dictionary of the corresponding row. This dictionary format is the default way data is returned when accessing data in the datasets library. This allows users to write pure Python `.map()` and `.filter()` operations that operate on python objects. | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ## Mapping Compute Primitives | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ```python | ||||||||||||||||||||||||||||||
| dset.set_format("arrow") | ||||||||||||||||||||||||||||||
| print(dset[:4]) | ||||||||||||||||||||||||||||||
| >>> | ||||||||||||||||||||||||||||||
| pyarrow.Table | ||||||||||||||||||||||||||||||
| hexsha: string | ||||||||||||||||||||||||||||||
| size: int64 | ||||||||||||||||||||||||||||||
| ... | ||||||||||||||||||||||||||||||
| ---- | ||||||||||||||||||||||||||||||
| hexsha: [["0a84ade1a79baf9000df6f66818fc3a568c24173","0a84b588e484c6829ab1a6706db302acd8514288","0a89bca33bdfce1f07390d394915f18e0d901651","0a96a3eeaa089f8582180f803252e3739ab2661d"]] | ||||||||||||||||||||||||||||||
| size: [[10354,999,43147,597]] | ||||||||||||||||||||||||||||||
| ext: [["css","css","css","css"]] | ||||||||||||||||||||||||||||||
| lang: [["CSS","CSS","CSS","CSS"]] | ||||||||||||||||||||||||||||||
| ... | ||||||||||||||||||||||||||||||
| ``` | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ```python | ||||||||||||||||||||||||||||||
| print(pc.unique(dset['lang']).to_pylist()) | ||||||||||||||||||||||||||||||
| >>> ['CSS', 'Prolog', 'C', 'FORTRAN', 'Solidity', 'Kotlin', 'Literate Agda', 'Julia', 'Java Server Pages', 'Isabelle', 'Idris', 'Lean', 'PowerShell', 'Go', 'Erlang', 'F#', 'Ada', 'Pascal', 'Perl', 'R', 'Protocol Buffer', 'CMake', 'SAS', 'Ruby', 'Rust', 'RMarkdown', 'C#', 'Smalltalk', 'Haskell', 'Maple', 'Mathematica', 'OCaml', 'Makefile', 'Lua', 'Literate CoffeeScript', 'Literate Haskell', 'reStructuredText', 'Racket', 'Standard ML', 'SystemVerilog', 'TeX', 'Awk', 'Assembly', 'Alloy', 'Agda', 'Emacs Lisp', 'Dart', 'Cuda', 'Bluespec', 'Augeas', 'Batchfile', 'Tcsh', 'Stan', 'Scala', 'Tcl', 'Stata', 'AppleScript', 'Shell', 'Clojure', 'Scheme', 'ANTLR', 'SPARQL', 'SQL', 'GLSL', 'Elm', 'Dockerfile', 'C++', 'CoffeeScript', 'Common Lisp', 'Elixir', 'Groovy', 'HTML', 'Java', 'JavaScript', 'Markdown', 'PHP', 'Python', 'TypeScript', 'Verilog', 'Visual Basic', 'VHDL', 'Thrift', 'Matlab', 'Yacc', 'Zig', 'XSLT', 'JSON', 'YAML'] | ||||||||||||||||||||||||||||||
| CPU times: user 137 ms, sys: 1.65 ms, total: 138 ms | ||||||||||||||||||||||||||||||
| Wall time: 136 ms | ||||||||||||||||||||||||||||||
| ``` | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ```python | ||||||||||||||||||||||||||||||
| mapped_result = dset.map(lambda table: table.group_by("lang").aggregate([("size", "mean"),("max_stars_count", "mean")]), batched=True, batch_size=100_000, num_proc=10) | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
| print(mapped_result) | ||||||||||||||||||||||||||||||
| >>> Dataset({ | ||||||||||||||||||||||||||||||
| features: ['size_mean', 'max_stars_count_mean', 'lang'], | ||||||||||||||||||||||||||||||
| num_rows: 207 | ||||||||||||||||||||||||||||||
| }) | ||||||||||||||||||||||||||||||
| CPU times: user 765 ms, sys: 237 ms, total: 1 s | ||||||||||||||||||||||||||||||
| Wall time: 1.35 s | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
| ``` | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ```python | ||||||||||||||||||||||||||||||
| reduced_result = mapped_result.map(lambda table: table.group_by("lang").aggregate([("size_mean", "mean"),("max_stars_count_mean", "mean")]), batched=True, batch_size=None) | ||||||||||||||||||||||||||||||
| print(reduced_result.to_pandas().sort_values("size_mean_mean", ascending=False).head(15)) | ||||||||||||||||||||||||||||||
| >>> | ||||||||||||||||||||||||||||||
| ``` | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| | | size_mean_mean | max_stars_count_mean_mean | lang | | ||||||||||||||||||||||||||||||
| |---:|-----------------:|----------------------------:|:------------| | ||||||||||||||||||||||||||||||
| | 30 | 63950.9 | 62.9083 | Mathematica | | ||||||||||||||||||||||||||||||
| | 82 | 38485.2 | 2032.26 | Matlab | | ||||||||||||||||||||||||||||||
| | 86 | 19765.3 | 173.915 | JSON | | ||||||||||||||||||||||||||||||
| | 80 | 18590.4 | 28.0008 | VHDL | | ||||||||||||||||||||||||||||||
| | 9 | 17811.9 | 33.3281 | Isabelle | | ||||||||||||||||||||||||||||||
| | 68 | 16470.2 | 118.346 | Common Lisp | | ||||||||||||||||||||||||||||||
| | 83 | 15776.3 | 55.9424 | Yacc | | ||||||||||||||||||||||||||||||
| | 71 | 15283.2 | 294.813 | HTML | | ||||||||||||||||||||||||||||||
| | 17 | 14399.4 | 60.4394 | Pascal | | ||||||||||||||||||||||||||||||
| | 22 | 13275 | 22.6699 | SAS | | ||||||||||||||||||||||||||||||
| | 85 | 13040.5 | 170.301 | XSLT | | ||||||||||||||||||||||||||||||
| | 55 | 13016.3 | 34.9036 | Stata | | ||||||||||||||||||||||||||||||
| | 62 | 12458.2 | 339.297 | SQL | | ||||||||||||||||||||||||||||||
| | 29 | 11677.5 | 112.621 | Maple | | ||||||||||||||||||||||||||||||
| | 84 | 11385.5 | 349.611 | Zig | | ||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ```python | ||||||||||||||||||||||||||||||
| python = dset.map(lambda table: table.filter(pc.field("lang") == "Python"), batched=True, batch_size=500_000, num_proc=10) | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
| print(f'{python.num_rows:,}', "rows") | ||||||||||||||||||||||||||||||
| >>> 250,000 rows | ||||||||||||||||||||||||||||||
| CPU times: user 818 ms, sys: 255 ms, total: 1.07 s | ||||||||||||||||||||||||||||||
| Wall time: 3.46 s | ||||||||||||||||||||||||||||||
| ``` | ||||||||||||||||||||||||||||||
|
Comment on lines
+171
to
+177
There was a problem hiding this comment.
Suggested change
There was a problem hiding this comment. Maybe we can use the standard lib for measuring time instead of the magic commands so that this code works in the (standard) REPL |
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
| ## Further Resources | ||||||||||||||||||||||||||||||
cakiki marked this conversation as resolved.
Show resolved
Hide resolved
|
||||||||||||||||||||||||||||||
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Uh oh!
There was an error while loading. Please reload this page.