enh(asciidoc) support unconstrained syntax #2870
Conversation
src/languages/asciidoc.js
Outdated
| // inline unconstrained strong | ||
| { | ||
| className: 'strong', | ||
| begin: /\*{2}/, |
There was a problem hiding this comment.
Is it not possible to escape an * here?
There was a problem hiding this comment.
you can escape but I'm not sure I quite understand the existing rule:
// allow escaped asterisk followed by word char
contains: [
{
begin: '\\\\*\\w',
relevance: 0
}
]The following should not be highlighted:
this is a \*strong* word.
this is a str*\*on**g word.
But the last example is pretty uncommon (and fragile). In this case, it would be better to use substitution:
:stars: **
this is a str{stars}on{stars}g word.
Since the AsciiDoc specification is underway, I would ignore these edge cases for now because I'm not even sure what is the expected result.
Here's a few examples, with the input and the rendered result:
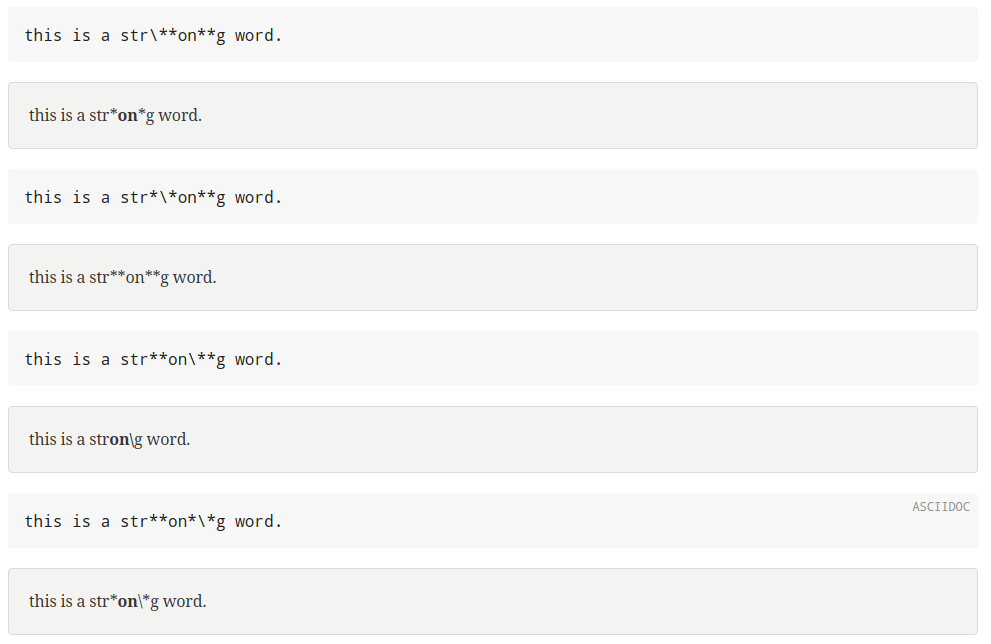
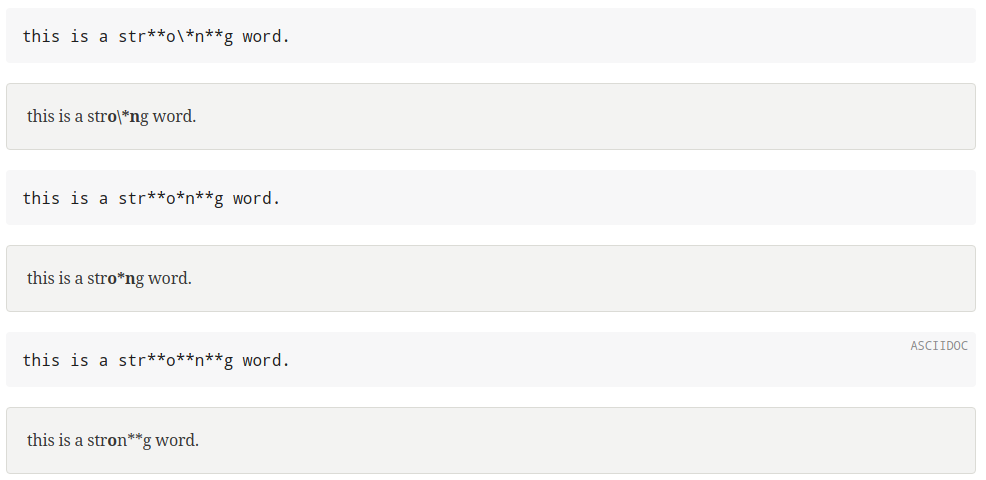
As you can see it won't be easy to implement the current behavior...
@mojavelinux thoughts? maybe that's the reason why you didn't include unconstrained syntax in the first place 😉
There was a problem hiding this comment.
I'm not sure I quite understand the existing rule:
It's simply allowing \* inside of bold so that it doesn't trigger "end bold". I'm not sure why the requirement of "one character after"... that might be specific to asciidoc. I brought it up since we already handle this for unconstrained so it seems we should also for constrained unless for some reason it's only really used in one type but not the other.
with the input and the rendered result:
We're less interested in the rendered result. We are not a rendering engine. We're trying to highlight the semantics of the language. So strong might not be strong at all, it might be red or blue. We aren't trying to accurately flag what should be strong though, but it's best to remember we'r'e highlighting, not rendering - we're never adding or removing any text.
this is a str**o**n**g word.
This would be broken with your current PR as the **g word whatever would be bold (if we can find two linebreaks anywhere else). I wonder if perhaps we don't need to handle \n and \n\n separately if they have entirely different behavior?
How does it know everything after the 3rd ** isn't bold?
this is a \*strong* word.
We'd need to add a general rule to eat a \* sequence then when it's found to avoid triggering any of the other rules. This should be a test case no doubt.
We should really start here with which cases are reasonable to handle, add markup tests. Then see if we can make those tests green. :)
There was a problem hiding this comment.
The markup tests should include the negative/edge cases too, to make sure we properly handle them, etc...
There was a problem hiding this comment.
We should really start here with which cases are reasonable to handle, add markup tests. Then see if we can make those tests green. :)
💯 I will add tests.
We're less interested in the rendered result. We are not a rendering engine.
I know, it was just easier to share every variations.
The markup tests should include the negative/edge cases too, to make sure we properly handle them, etc...
👍
src/languages/asciidoc.js
Outdated
| { | ||
| className: 'strong', | ||
| begin: /\*{2}/, | ||
| end: /(\n{2}|\*{2})/ | ||
| }, |
There was a problem hiding this comment.
Also I think we're going to need a variant here for the \n possibility, it's too "wide"... it can match too much, making it not worthy of relevance. ** is used in many languages as a math operation.
| { | |
| className: 'strong', | |
| begin: /\*{2}/, | |
| end: /(\n{2}|\*{2})/ | |
| }, | |
| { | |
| className: 'strong', | |
| begin: /\*{2}/, | |
| variants: [ | |
| { end: /\n{2}/, relevance: 0 }, | |
| { end: /\*{2}/ } | |
| ] | |
| }, |
There was a problem hiding this comment.
Hmmm, although now that I think of it ** anything ** is also VERY broad... can these be used without text? ALl your examples show them surrounding text immediately if so we should add that as a condition here with a look ahead:
begin: /\*{2}(?=\w+)/
Thoughts?
There was a problem hiding this comment.
since it's unconstrained, you can have spaces, a single newline...:
A sentence ** with words, and more words!
using bold style :)**.

There was a problem hiding this comment.
Yes, I glanced at your link now and roughly understand they are different. Here I'm speaking only of auto-detect... we don't just need to know how to highlight Asciidoc but we also have to avoid confusing it with say Javascript... so every rule (that's too generic) needs to have it's relevance tuned or eliminated to avoid false positives. For example a JS snippet with tons of ** math formulas might be flagged as Asciidoc... and that should be avoided if possible.
But lets focus on getting them working first I guess. :)
545a1b5 to
3be39c8
Compare
src/languages/asciidoc.js
Outdated
| begin: '(?<!\\\\)\\B\\*(?![\\*\\s])', | ||
| end: '(\\n{2}|\\*)', | ||
| begin: /(?<!\\)\B\*\w/, | ||
| end: /\*/, |
There was a problem hiding this comment.
Nope, can't use look-behind, not supported by all browsers yet. Sorry. You could look at making this a chain (with starts) or rebase onto #2834 (beforeMatch) and use the syntactic sugar to the same end. But none of this is true look-behind... we can only look-forward at this time. So in order to do something like this you'll need to match/consume the prior character (ie. another mode can't have already consumed it).
There was a problem hiding this comment.
or rebase onto #2834 and use the syntactic sugar to the same end.
That's what I'd recommend if you know how. I don't think that stuff is going to make it into 10.4, but it should make it into 10.5 and will make a lot of things like this a lot nicer.
There was a problem hiding this comment.
Or like I suggested earlier capture the \* pattern as it's own previous rule (to prevent this rule from firing).
There was a problem hiding this comment.
Or like I suggested earlier capture the * pattern as it's own previous rule (to prevent this rule from firing).
👍
There was a problem hiding this comment.
Please note that I'm only updating strong rules.
Monospaced and emphasis are quite similar but first I want to make strong rules right (then apply the same rules to other formatting marks).
36caecf to
1a36281
Compare
src/languages/asciidoc.js
Outdated
| begin: '\\B\\*(?![\\*\\s])', | ||
| end: '(\\n{2}|\\*)', | ||
| // must not be preceded by the escape character \ | ||
| begin: /\B\*(\w\n?\w)+(?!\n\n)/, |
There was a problem hiding this comment.
This looks strange. What is the exact intentional of this rule and the negative look-ahead? Trying to prevent *...* from wrapping across paragraphs? IE:
*bob*
vs
*bob was
a wild man*
There was a problem hiding this comment.
You are correct, an empty line (two consecutive newline characters) indicates a new paragraph.
not bold
*bob was
a wild man
bold
*bob was
a wild man*
The last example is equivalent to:
*bob was a wild man*
There was a problem hiding this comment.
One note here then I'll shut up until you ping me. We also have a Slack now if that might interest you. (see top of README).
begin: /\B\*(\w\n?\w)+(?!\n\n)/,
This is probably way to narrow (and on the other end grabbing way to much). I presume that other things can exist inside bold - like links, italics, other inline parts of the grammar. So this rule would fail to take any of that into account (from what I can see). Plus if you keep extending it to match more and more you run the risk of it matching things that aren't really the "begin" and "end" - which means because this rule ate them, nothing else can match them. IE, optimally begin and end should "eat"/match as little as possible. Usually (for begin) this is accomplished with look-ahead.
What you really want here (I think) is:
begin: /\B\*/,
unlessMiddleContains: /\n\n/ // sadly, this doesn't exist
contains: [ // ... ],
end : /\*/We have illegal, but that will just abort. We can't "backtrack". So usually what you do (in simpler cases is try to cover the WHOLE expression with a lookahead):
begin: concat(/\B\*/, lookahead(contentWithoutAsteriskOrPairOfNewlinesEndingInAsterisk)),
contains: [ //... ],
end : /\*/IE, your begin does all the work... I'm just not sure what that regex might look like off the top of my head. :-)
Maybe something like (multi-line):
/\*(([^*\n\\]|\\[^\n])+\n)+([^*\n\\]|\\[^\n])*\*/It might be simple to have a separate rule for single-line vs trying to cram it into a single regex.
There was a problem hiding this comment.
begin: /\B\*(\w\n?\w)+(?!\n\n)/,Also since you have no way to pin this I'm pretty sure it will just rewind:
*this is bold
but you'd think
that it should not be...
[I believe] the regex will rush forward to think, see the new paragraph (not a match!) and then just rewind to bold\n, which is a match, so the bold rule is a match.
|
Hey @joshgoebel thanks for your prompt reviews! |
|
I was hoping to maybe prevent you from traveling down some dead-end roads but if you just want to explore on your own and then ping me later, that's fine. One concern I always have is that it's possible to do many things with our engine that we don't actually encourage and there is a certain line where you start "parsing" code instead of merely pattern matching it. And we try not to cross into that territory. I worry getting the rules perfect around a single You picked a non-trivial problem for starters. :-) |
You are probably right.
I adopted a new strategy!
I like challenges 🥇
At least now we have tests so we can quickly assert what is working and what is not 😆 |
src/languages/asciidoc.js
Outdated
| { | ||
| className: 'strong', | ||
| // must not precede or follow a word character | ||
| begin: /\B\*\w+\*\B/, |
There was a problem hiding this comment.
Too tight. " is not \w.
I know they say that *"bob loves jemma"*.Why not [^\n]*?
There was a problem hiding this comment.
I'm not sure these single expressions aren't going to cut it... we'll need separate begin and end tags to handle things like (emphasis inside bold):
Does *Bob _love_ Gemma*?Which we should handle (we do for Markdown). Or even the proper handling of \* inside bold, which we supported previously. Generally we try not to merge a PR that removes features unless there are no other options.
There was a problem hiding this comment.
In generally anytime you try and match the middle it's hard. In case like this you'd want to be super flexible, like I suggest earlier... for example if we're matching a single line bold:
// doesn't match all sorts of things, `"` just to name one.
begin: /\B\*\w+\*\B/,
// matches everything except a new line, the one thing we know isn't allowed
begin: /\B\*[^\n]+?\*\B/,But again you'd have to split this into begin end still:
begin: /\B\*(?=[^\n]+?\*\B)/, // look-ahead to make sure it closes
contains: OTHER_STUFF,
end: /\*\B/Of course this gets harder since the lookahead regex also has to correctly handle escapes, like \*...
There was a problem hiding this comment.
Of course this gets harder since the lookahead regex also has to correctly handle escapes, like *...
Yes that's why I thought it would be simpler to match everything in begin... 😒
we'll need separate begin and end tags to handle things like (emphasis inside bold)
Unless I missed something, it currently does not work.
It would be nice to support it but we should probably to do it in another pull request.
There was a problem hiding this comment.
Or even the proper handling of * inside bold, which we supported previously.
I removed it because I don't see why we need it:
This stuff sure is *gr*e*e*dy*!
This stuff sure is *gr*e*e*dy*!
I'm not convinced yet we can solve the * problem 100%,
I don't think it will be possible unless we create a parser, that's why I'm pruning uncommon syntax and/or syntax with undefined behavior.
I think it's important that This is not \*strong*! works.
Please note that This is *str\*ong*! will produce: This is *str\*ong*!
There was a problem hiding this comment.
We should probably port tests from Asciidoctor: https://github.com/asciidoctor/asciidoctor/blob/master/test/substitutions_test.rb
\**Git**Hub
Result: *Git*Hub
\*a few strong words*
Result: *a few strong words*
As you can see \* inside bold is not tested.
There was a problem hiding this comment.
Or even the proper handling of * inside bold, which we supported previously.
I was referring to \*, sorry for not being clearer. Someone went to the trouble of supporting it before making me reason perhaps it's more important than you think. :-) Obviously * inside bold doesn't require special treatment if it isn't triggering the end of the bold rule or causing any issues.
Yes that's why I thought it would be simpler to match everything in begin...
Which is the right idea sort of but you have to cover the whole expression and do it with a look-ahead... so that the actual MATCH portion of begin and end is "" and "". But that's not the largest issue - see my points below on regressions.
I don't think it will be possible unless we create a parser
The regex I gave you was working for simple cases, did you try it or play around with it in regex101? See the attached snap...
It would be nice to support it but we should probably to do it in another pull request.
Oh I'm not trying to say accomplish everything in this PR (far from it!), but I'm also not wanting to merge anything that I know is still broken or is going to make future work harder. So regarding broken lets go back to my prior example:
Does *Bob _love_ Gemma*?
This probably sort of works thanks to _ being in \w... So my apologies for not using a better example:
Does *Bob -love- Gemma*? (broken -)
Does *Bob "love" Gemma*? (broken ")
Does *Bob love Gemma? Truly?* (broken ?)
Your PR would break all these that worked previously, would it not? It's possible that I could be persuaded to drop \* for the short-term, but even if that were true I still think there is work to be done here before this would be mergeable. Go back and look at my comments regarding [^\n] vs \w, etc... if we resolved these type issues we might have something workable here.
There was a problem hiding this comment.
I was referring to *, sorry for not being clearer. Someone went to the trouble of supporting it before making me reason perhaps it's more important than you think. :-) Obviously * inside bold doesn't require special treatment if it isn't triggering the end of the bold rule or causing any issues.
Let me check with Dan (who wrote the regular expression 8 years ago). Maybe at the time constrained formatting was not greedy... or maybe I'm missing something!
The regex I gave you was working for simple cases, did you try it or play around with it in regex101? See the attached snap...
Not yet, I will give it a try tonight.
So regarding broken lets go back to my prior example...
This probably sort of works thanks to _ being in \w... So my apologies for not using a better example...
Your PR would break all these that worked previously, would it not?
Let me try these examples on master but I'm pretty sure they do not work as expected today.
But rest assured, I plan to make them work but one step at a time 😉
Go back and look at my comments regarding [^\n] vs \w, etc... if we resolved these type issues we might have something workable here.
👍
src/languages/asciidoc.js
Outdated
| { | ||
| className: 'strong', | ||
| // must not precede or follow a word character | ||
| begin: /\B\*\w+\*\B/, |
There was a problem hiding this comment.
In generally anytime you try and match the middle it's hard. In case like this you'd want to be super flexible, like I suggest earlier... for example if we're matching a single line bold:
// doesn't match all sorts of things, `"` just to name one.
begin: /\B\*\w+\*\B/,
// matches everything except a new line, the one thing we know isn't allowed
begin: /\B\*[^\n]+?\*\B/,But again you'd have to split this into begin end still:
begin: /\B\*(?=[^\n]+?\*\B)/, // look-ahead to make sure it closes
contains: OTHER_STUFF,
end: /\*\B/Of course this gets harder since the lookahead regex also has to correctly handle escapes, like \*...
src/languages/asciidoc.js
Outdated
| // inline unconstrained strong (multi-line) | ||
| { | ||
| className: 'strong', | ||
| begin: /\*{2}(\s\S+)*\*{2}/, |
There was a problem hiding this comment.
This of course as the same issues with begin/end... we need access to contains so we can properly highlight markup that appears inside of bold.
Simple is good, but I think it only works so well because you've just covered the very basic cases. I'm not convinced yet we can solve the IE matching: And a second variant for: ie: begin: concat(/\*/, lookahead(gnarly_regex)),
contains: [
escape, emphasis, etc.
]
end: /\*/The begin look-ahead does the validation, but yet begin only actually matches/returns You can play around on https://regex101.com/. It's super useful for stuff like this. |
|
Made it a bit easier to see with named groups:
|
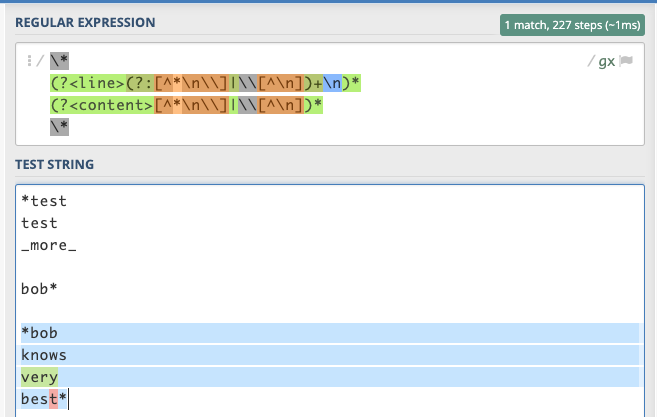
|
So if we just want to focus on minimum to merge I think we need to focus on: We need more tests cases and those rules need to be widened so as to not fail with simple textual content in between the If you only want to exclude one or two thigns focus on negative matching, not positive so for example I think the first rule would be solved with: Would it not? |
src/languages/asciidoc.js
Outdated
| function unpack_hex_range(str) { | ||
| return str.replace(HEX_RANGE_RX, function (_, p1, p2) { | ||
| return `\\u${p1}${p2 ? `-\\u${p2}` : ''}` | ||
| }) | ||
| } | ||
|
|
||
| // Unicode property aliases (P_<name> constant is equivalent to \p{<name>}) | ||
| const P_L = 'A-Za-z' + (unpack_hex_range('00AA00B500BA00C0-00D600D8-00F600F8-02C102C6-02D102E0-02E402EC02EE0370-037403760377037A-037D037F03860388-038A038C038E-03A103A3-03F503F7-0481048A-052F0531-055605590561-058705D0-05EA05F0-05F20620-064A066E066F0671-06D306D506E506E606EE06EF06FA-06FC06FF07100712-072F074D-07A507B107CA-07EA07F407F507FA0800-0815081A082408280840-085808A0-08B20904-0939093D09500958-09610971-09800985-098C098F09900993-09A809AA-09B009B209B6-09B909BD09CE09DC09DD09DF-09E109F009F10A05-0A0A0A0F0A100A13-0A280A2A-0A300A320A330A350A360A380A390A59-0A5C0A5E0A72-0A740A85-0A8D0A8F-0A910A93-0AA80AAA-0AB00AB20AB30AB5-0AB90ABD0AD00AE00AE10B05-0B0C0B0F0B100B13-0B280B2A-0B300B320B330B35-0B390B3D0B5C0B5D0B5F-0B610B710B830B85-0B8A0B8E-0B900B92-0B950B990B9A0B9C0B9E0B9F0BA30BA40BA8-0BAA0BAE-0BB90BD00C05-0C0C0C0E-0C100C12-0C280C2A-0C390C3D0C580C590C600C610C85-0C8C0C8E-0C900C92-0CA80CAA-0CB30CB5-0CB90CBD0CDE0CE00CE10CF10CF20D05-0D0C0D0E-0D100D12-0D3A0D3D0D4E0D600D610D7A-0D7F0D85-0D960D9A-0DB10DB3-0DBB0DBD0DC0-0DC60E01-0E300E320E330E40-0E460E810E820E840E870E880E8A0E8D0E94-0E970E99-0E9F0EA1-0EA30EA50EA70EAA0EAB0EAD-0EB00EB20EB30EBD0EC0-0EC40EC60EDC-0EDF0F000F40-0F470F49-0F6C0F88-0F8C1000-102A103F1050-1055105A-105D106110651066106E-10701075-1081108E10A0-10C510C710CD10D0-10FA10FC-1248124A-124D1250-12561258125A-125D1260-1288128A-128D1290-12B012B2-12B512B8-12BE12C012C2-12C512C8-12D612D8-13101312-13151318-135A1380-138F13A0-13F41401-166C166F-167F1681-169A16A0-16EA16F1-16F81700-170C170E-17111720-17311740-17511760-176C176E-17701780-17B317D717DC1820-18771880-18A818AA18B0-18F51900-191E1950-196D1970-19741980-19AB19C1-19C71A00-1A161A20-1A541AA71B05-1B331B45-1B4B1B83-1BA01BAE1BAF1BBA-1BE51C00-1C231C4D-1C4F1C5A-1C7D1CE9-1CEC1CEE-1CF11CF51CF61D00-1DBF1E00-1F151F18-1F1D1F20-1F451F48-1F4D1F50-1F571F591F5B1F5D1F5F-1F7D1F80-1FB41FB6-1FBC1FBE1FC2-1FC41FC6-1FCC1FD0-1FD31FD6-1FDB1FE0-1FEC1FF2-1FF41FF6-1FFC2071207F2090-209C21022107210A-211321152119-211D212421262128212A-212D212F-2139213C-213F2145-2149214E218321842C00-2C2E2C30-2C5E2C60-2CE42CEB-2CEE2CF22CF32D00-2D252D272D2D2D30-2D672D6F2D80-2D962DA0-2DA62DA8-2DAE2DB0-2DB62DB8-2DBE2DC0-2DC62DC8-2DCE2DD0-2DD62DD8-2DDE2E2F300530063031-3035303B303C3041-3096309D-309F30A1-30FA30FC-30FF3105-312D3131-318E31A0-31BA31F0-31FF3400-4DB54E00-9FCCA000-A48CA4D0-A4FDA500-A60CA610-A61FA62AA62BA640-A66EA67F-A69DA6A0-A6E5A717-A71FA722-A788A78B-A78EA790-A7ADA7B0A7B1A7F7-A801A803-A805A807-A80AA80C-A822A840-A873A882-A8B3A8F2-A8F7A8FBA90A-A925A930-A946A960-A97CA984-A9B2A9CFA9E0-A9E4A9E6-A9EFA9FA-A9FEAA00-AA28AA40-AA42AA44-AA4BAA60-AA76AA7AAA7E-AAAFAAB1AAB5AAB6AAB9-AABDAAC0AAC2AADB-AADDAAE0-AAEAAAF2-AAF4AB01-AB06AB09-AB0EAB11-AB16AB20-AB26AB28-AB2EAB30-AB5AAB5C-AB5FAB64AB65ABC0-ABE2AC00-D7A3D7B0-D7C6D7CB-D7FBF900-FA6DFA70-FAD9FB00-FB06FB13-FB17FB1DFB1F-FB28FB2A-FB36FB38-FB3CFB3EFB40FB41FB43FB44FB46-FBB1FBD3-FD3DFD50-FD8FFD92-FDC7FDF0-FDFBFE70-FE74FE76-FEFCFF21-FF3AFF41-FF5AFF66-FFBEFFC2-FFC7FFCA-FFCFFFD2-FFD7FFDA-FFDC')) | ||
| const P_Nl = unpack_hex_range('16EE-16F02160-21822185-218830073021-30293038-303AA6E6-A6EF') | ||
| const P_Nd = '0-9' + (unpack_hex_range('0660-066906F0-06F907C0-07C90966-096F09E6-09EF0A66-0A6F0AE6-0AEF0B66-0B6F0BE6-0BEF0C66-0C6F0CE6-0CEF0D66-0D6F0DE6-0DEF0E50-0E590ED0-0ED90F20-0F291040-10491090-109917E0-17E91810-18191946-194F19D0-19D91A80-1A891A90-1A991B50-1B591BB0-1BB91C40-1C491C50-1C59A620-A629A8D0-A8D9A900-A909A9D0-A9D9A9F0-A9F9AA50-AA59ABF0-ABF9FF10-FF19')) | ||
| const P_Pc = unpack_hex_range('005F203F20402054FE33FE34FE4D-FE4FFF3F') |
There was a problem hiding this comment.
Oh wow. Two big steps forward one small step back. :-) This might be a bit much. :-)
Context: #2756
We're still up in the air on UTF8 but if we're headed there we should do it properly, not with this kind of hack.
There was a problem hiding this comment.
You could leave a TODO comment if you wanted.
There was a problem hiding this comment.
OK, I will use \w and remove the associated test case.
We are using these unicode ranges in Asciidoctor.js to translate \p{Word} (Ruby).
There was a problem hiding this comment.
Yeah, we have access to the /u flag in JS and if we're going to start matching \p stuff that's what we should be using, but right now there are some performance concerns. If you know anything about it and wanted to contribute to that thread help would be welcome. :-)
src/languages/asciidoc.js
Outdated
| className: 'strong', | ||
| // must not precede or follow a word character | ||
| begin: /\B\*\w+\*\B/, | ||
| begin: `\\B\\*(\\S|\\S${CC_ANY}*?\\S)\\*(?!${CG_WORD})`, |
There was a problem hiding this comment.
Can we pull out all the UTF-8 and just let this be \W for now? (vs ! CG_WORD)
src/languages/asciidoc.js
Outdated
| // must ignore until the next formatting marks | ||
| // this rule is not 100% compliant with Asciidoctor but we are entering undefined behavior territory... | ||
| { | ||
| begin: /\\\\\*{2}[^\n]*\*{2}/ |
There was a problem hiding this comment.
Wait does this syntax literally mean "it's marked as bold, but ignore it and don't make it bold"?
There was a problem hiding this comment.
Also shouldn't this be CC_ANY?
There was a problem hiding this comment.
Oh and you don't need to turn them all into strings either, just use regex.concat.
There was a problem hiding this comment.
Wait does this syntax literally mean "it's marked as bold, but ignore it and don't make it bold"?
It's another guard when unconstrained bold is escaped using \\. Take a look at the test case:
\\**--anything goes **
I've also added an even more complex test case:
\\**--anything goes ** with * a **lot** of stars**
Also shouldn't this be CC_ANY?
Yes
Oh and you don't need to turn them all into strings either, just use regex.concat.
Oh really? Could you please provide an example, I've never seen regex.concat 🤯
There was a problem hiding this comment.
It's in lib/regex.js... just utility functions. There are a few.
There was a problem hiding this comment.
It's another guard when unconstrained bold is escaped using \. Take a look at the test case:
OK if really it's like a paired "don't apply any highlighting on the inside", ie "anything goes"... (kind of like a comment in a programming language) but why are there 3 variants of it? :-) Asciidoc is strange. :)
2b13bf1 to
0f1f719
Compare
src/languages/asciidoc.js
Outdated
| { | ||
| className: 'strong', | ||
| // must not precede or follow a word character | ||
| begin: /\B\*(\w\n?)*\*(?!\w)/, |
There was a problem hiding this comment.
I'm so confused about constrains vs unconstrained... shouldn't this work:
*does bob
-really-
know best?*
I'm wondering if perhaps this is really just the same as the ** except for the before/end conditions? If so then that regex would probably work here also I think?
There was a problem hiding this comment.
I'm so confused about constrains vs unconstrained... shouldn't this work:
*does bob
-really-
know best?*
The above should produce bold.
I'm wondering if perhaps this is really just the same as the ** except for the before/end conditions? If so then that regex would probably work here also I think?
Close but not quite the same: https://asciidoctor.org/docs/user-manual/#when-should-i-use-unconstrained-quotes
Consider the following questions:
Is there a letter, number, underscore directly outside the formatting marks (on either side)?
Is there a colon, semi-colon, or closing curly bracket directly before the starting formatting mark?
Is there a space directly inside of the formatting mark?
If you answered “yes” to any of these questions, you need to switch to unconstrained (double formatting) quotes.
See: https://github.com/asciidoctor/asciidoctor/blob/dd843d59b1e49f29d68386bfdf0438ce11b42577/lib/asciidoctor.rb#L447-L449
Please keep in mind that we are also doing some work in https://github.com/asciidoctor/asciidoctor/blob/dd843d59b1e49f29d68386bfdf0438ce11b42577/lib/asciidoctor/substitutors.rb#L75
There was a problem hiding this comment.
I'm also using a less greedy regular expression than Asciidoctor because we want to stop when the paragraph ends.
There was a problem hiding this comment.
The above should produce bold.
But your rule doesn't match the -, or am I missing something?
Close but not quite the same
Unless I'm missing something all I read there relates directly to what qualifies the beginning and ending of the match though, yes? Matching the "middle" content could use the same (or similar) wider rule so that it wouldn't get hung up on details like - or punctuation, etc. So really we're trying to structure the regex into 3 segments:
- beginning
- middle (it seems this should be as WIDE as possible)
- end
It seems for both * and ** the middle rules are the same, no? Only the begin and end conditions change?
There was a problem hiding this comment.
But your rule doesn't match the -, or am I missing something?
Oh yes, you're right, sorry I didn't understand.
I've added this case and updated the regular expression accordingly.
Unless I'm missing something all I read there relates directly to what qualifies the beginning and ending of the match though, yes?
No, this rule is about what is inside the formatting marks: "Is there a space directly inside of the formatting mark?"
this is * a bold move*
this is ** a bold move**
Only the second sentence will produce bold.
So really we're trying to structure the regex into 3 segments:
I guess since the formatting marks are delimiters, so:
- beginning: delimiter
- middle: some content
- end: delimiter
In theory, that should be easy but in practice it's not because "*" can be used in different context:
****
sidebar
****
* foo
* bar
** baz
Read the footnotes*.
E = mc*2*
E = *mc*2
Use `/*` and `*/` for multiline comments.
The last example is not correctly interpreted by Asciidoctor 😅
Anyway, we should be careful about "as WIDE as possible".
23060fe to
a5c1993
Compare
c12d1c2 to
069e63e
Compare
c3a1a4f to
632195d
Compare
Co-authored-by: Josh Goebel <me@joshgoebel.com>
@joshgoebel Done. Once it's merged, I will also open a follow-up pull request to apply the same unconstrained rules to emphasis and monospaced. |
Changes
resolves #2869
Checklist
CHANGES.mdAUTHORS.txt, under Contributors