{kind=link}
Automatically encode videos to AV1 at the best quality-to-size ratio, using VMAF to find the optimal settings for each file.
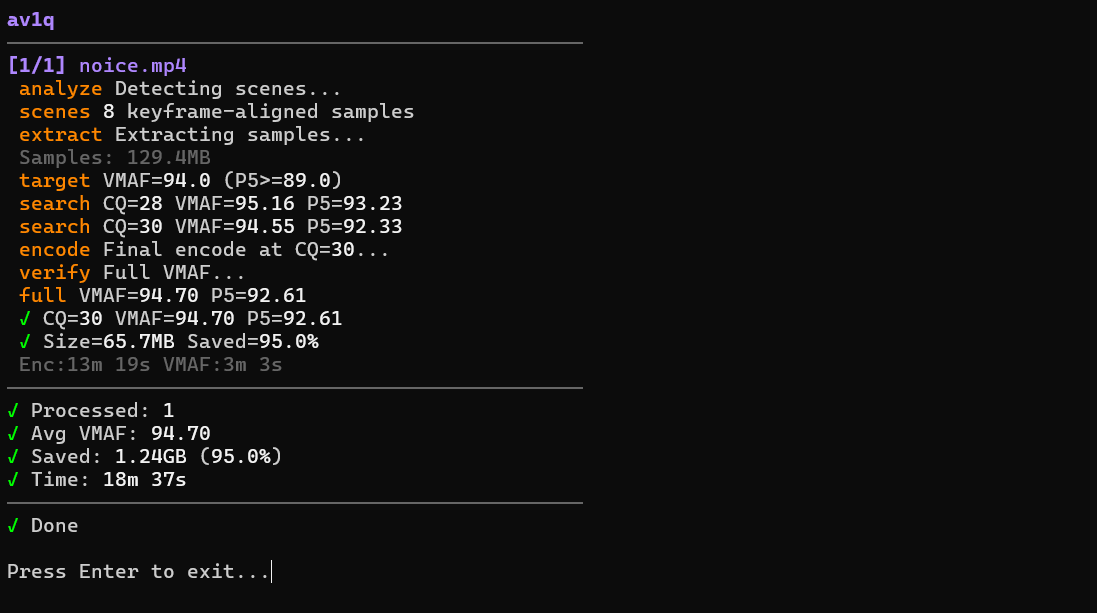
Drop videos into a folder, run the script, and each file gets encoded to AV1 at a quality level that hits a target VMAF score. Instead of guessing CRF values or doing manual test encodes, the tool figures it out for you.
- Detects scenes and extracts short representative samples from complex parts of the video
- Searches for the optimal CQ by encoding only the samples — not the full file — and measuring VMAF after each attempt
- Encodes the full video at the chosen CQ, then verifies the final VMAF score matches the target
- Refines in 1-2 passes if VMAF or the bitrate floor comes up short — using the measured quality/bitrate slopes to jump directly to the right CQ rather than stepping by one
- VMAF-targeted encoding — hits a perceptual quality target instead of using a fixed CRF
- Resolution-aware defaults — auto-selects VMAF targets (94 for HD, 93 for SD, 90 for 4K)
- Bitrate floors — per-resolution minimum bitrates (1 Mbps 720p, 1.5 Mbps 1080p, 2.5 Mbps 1440p, 4 Mbps 2160p, 8 Mbps 4320p) prevent VMAF-misleading low-bitrate encodes
- Scene-based sampling — fast quality estimation without encoding the whole file during search
- P5 quality reporting — measures and reports 5th-percentile worst-frame VMAF alongside the mean, so you can spot files whose worst moments lag
- HDR & color preservation — carries over color primaries, transfer, matrix, and range
- 10-bit output by default, film grain synthesis included
- Hardware-accelerated decoding — CUDA, D3D11VA (Windows), VideoToolbox (macOS), VAAPI (Linux)
- Optional auto-crop —
--auto-cropdetects letterbox/pillarbox bars inline before each encode (or use the standaloneav1q-crop.pyto pre-scan a library); confidence-gated so ambiguous detections aren't silently applied - File-based caching — skips re-analysis and re-measurement on subsequent runs
- Batch processing with recursive subdirectory support
- Cross-platform — Windows, macOS, Linux
- Python 3.8+
- ffmpeg and ffprobe in PATH, built with:
libsvtav1(SVT-AV1 encoder)libvmaf(VMAF quality metrics)
Most ffmpeg builds from gyan.dev (Windows) or BtbN (Linux/Windows) include both. On macOS: brew install ffmpeg.
- colorama for Windows terminal colors (
pip install colorama). Works without it.
Basic — processes all videos in ./Video Input, outputs to ./AV1 Output:
python av1q.py
Custom directories:
python av1q.py -i /path/to/videos -o /path/to/output
Override quality target and encoding speed:
python av1q.py --vmaf 95 --preset 6
Auto-crop letterboxed or pillarboxed videos — add --auto-crop:
python av1q.py --auto-crop
Before each encode, the script samples 8 short windows of the video, detects black bars, and applies the crop if the detection is confident. Results are cached as <file>.crop.json sidecars beside each source, so re-runs reuse them without re-scanning. Low-confidence detections (dark sources, mixed aspect ratios) are saved for manual review but not auto-applied. Pass --no-crops to ignore sidecars entirely.
For batch pre-scanning a whole library before encoding (so you can review borderline sidecars first), the companion av1q-crop.py does the same detection standalone and writes the same sidecar format:
python av1q-crop.py
python av1q.py
| Flag | Default | Description |
|---|---|---|
-i, --input |
./Video Input |
Input directory |
-o, --output |
./AV1 Output |
Output directory |
--vmaf |
Auto by resolution | Target VMAF score |
--preset |
4 |
SVT-AV1 preset (0-10, lower = slower + better) |
--min-cq |
18 |
Minimum CQ (highest quality bound) |
--max-cq |
38 |
Maximum CQ (lowest quality bound) |
--film-grain |
24 |
Film grain synthesis level (0-50) |
--samples |
8 |
Number of sample segments for estimation |
--no-10bit |
— | Disable forced 10-bit encoding |
--no-recurse |
— | Don't process subdirectories |
--overwrite |
— | Re-encode even if output exists |
--dry-run |
— | Find optimal CQ but skip final encoding |
--auto-crop |
— | Detect letterbox/pillarbox inline before each encode (skips files that already have a sidecar) |
--no-crops |
— | Ignore *.crop.json sidecars (auto-applied by default) |
The script uses an adaptive search (similar to Newton's method) to converge on the right CQ value in 2-4 iterations rather than brute-forcing every option:
- Analyze — scene detection identifies visually distinct segments; frame complexity analysis ranks them
- Sample — the most complex scenes are extracted as short clips and concatenated
- Search — the sample is encoded at a seed CQ derived from the source's bitrate headroom over the floor (higher headroom → lower starting CQ; falls back to 30 when unknown), VMAF is measured, and the next CQ is estimated from the slope of quality-vs-CQ. The search estimates a bitrate ceiling from measured data (using the +-6 CRF = 2x bitrate rule, refined with actual measurements) to avoid jumping past the bitrate floor. When the bitrate floor is the binding constraint rather than VMAF, the search switches to bitrate targeting mode — testing additional sample CQs to compute the exact decay rate for the content and interpolating to the CQ that hits the floor. Repeats until the target is bracketed
- Encode — full video is encoded at the best CQ found
- Verify & refine — full-file VMAF and bitrate are checked against their targets (P5, the 5th-percentile worst-frame score, is measured and reported but not used as a gate). If either is short, the next CQ is computed from the measured quality/bitrate slopes — converges in 1-2 iterations rather than stepping by one per constraint
- Calibrate — sample-vs-full deltas (bitrate ratio, VMAF offset, slope) are cached, so a re-run or resume of the same file aims at the right CQ on the first probe
Files that end up larger after encoding are automatically deleted.
MIT