Project to advances in pattern recognition and tecnical experiences
Principal Results: Metrics choosed of classification: I choosed to use as classification metrics, the [accuracy, precision, f1-score, recall, precision], which has the characteristic:
- accuracy: Describes how the model performs across all the classes
- precision: The precision measures the model's accuracy in classifying a sample as positive.
- recall: Quantifies the number of correct positive predictions made out of all positive predictions
- f1-score: Combines the precision and recall, and give a harmonic mean of them
This metrics are presented in each jupyter notebook.
- Using the Bag of Visual Words:
The results in this approach showed that the number of visual words is very important. When I utilized a small number, like 2 or 5, the confusion matrix dont´t
showed convergency.
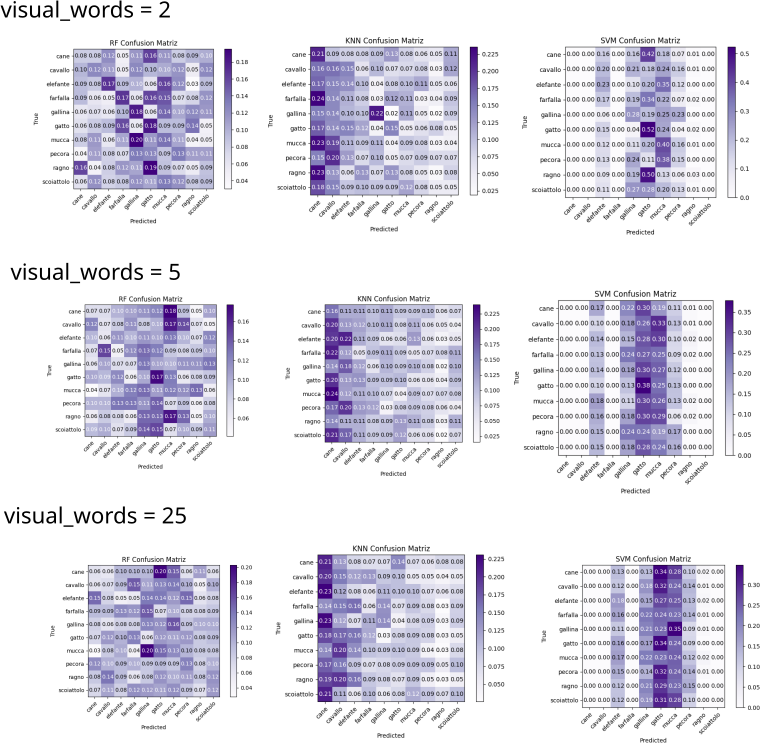 As the value was increased, an increase in performance was seen, with a lot of computational cost, but the models takes a long time to converge, having horrible
results in this approach.
As the value was increased, an increase in performance was seen, with a lot of computational cost, but the models takes a long time to converge, having horrible
results in this approach.
1.1 Possibilities to improve the results:
- Define the type of load the dataset, without uses append in the images, dividing in batches sizes
- Uses methods of data augumentation to improve the quantity of images
- Search another metods to extract the quantity of visual words, beacuase kmeans is very slowly
- Compare the extract of keyponitns using SIFT and HOG
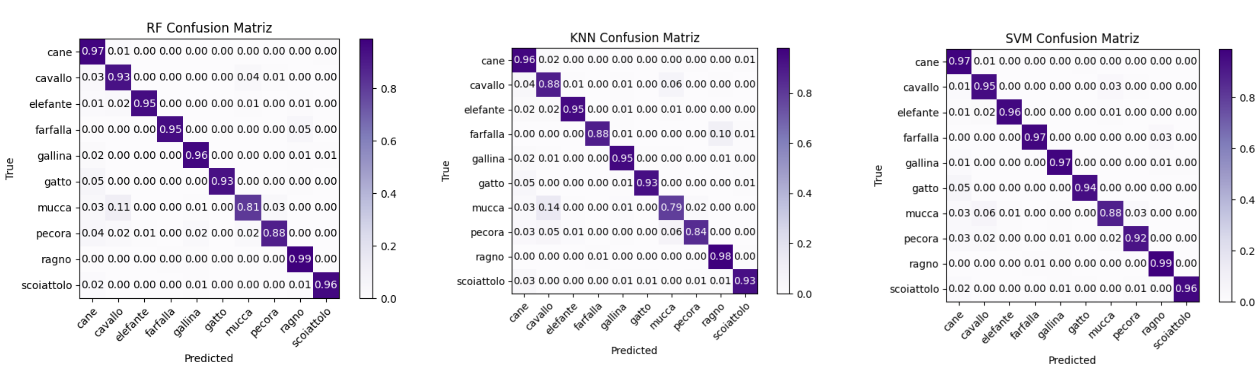
Due to this, feature extraction with vgg16 showed much better results.
- Using the vgg16 cnn as features exctator: The results of this case are great. Each class of dataset has a good metric
2.1 Possibilities to improve the results:
- Use more elaborated methods of data augmentation
- Alterate the space collors os images dataset
- Test more variations of hiperparameters
- Test anothers CNNs as feature extractor and compare
-
CLone the project
-
Install the poetry
-
Execute:
poetry installpoetry shell -
Now, you can open the jupyter notebook and execute