此repository從 (https://github.com/huihut/interview) fork而來。
C/C++ 面試知識總結,只為複習、分享。部分知識點與圖片來自網絡,侵刪。
勘誤新增請 Issue、PR,建議、討論請 #issues/12,排版使用 中文文案排版指北
使用建議:
Ctrl + F:快速查找定位知識點TOC 導航:jawil/GayHub 插件快速目錄跳轉
- 修飾變量,說明該變量不可以被改變;
- 修飾指針,分為指向常量的指針和指針常量;
- 常量引用,經常用於形參類型,即避免了拷貝,又避免了函數對值的修改;
- 修飾成員函數,說明該成員函數內不能修改成員變量。
const 使用
// 類
class A
{
private:
const int a; // 常對象成員,只能在初始化列表賦值
public:
// 構造函數
A() { };
A(int x) : a(x) { }; // 初始化列表
// const可用於對重載函數的區分
int getValue(); // 普通成員函數
int getValue() const; // 常成員函數,不得修改類中的任何數據成員的值
};
void function()
{
// 對象
A b; // 普通對象,可以調用全部成員函數
const A a; // 常對象,只能調用常成員函數、更新常成員變量
const A *p = &a; // 常指針
const A &q = a; // 常引用
// 指針
char greeting[] = "Hello";
char* p1 = greeting; // 指針變量,指向字符數組變量
const char* p2 = greeting; // 指針變量,指向字符數組常量
char* const p3 = greeting; // 常指針,指向字符數組變量
const char* const p4 = greeting; // 常指針,指向字符數組常量
}
// 函數
void function1(const int Var); // 傳遞過來的參數在函數內不可變
void function2(const char* Var); // 參數指針所指內容為常量
void function3(char* const Var); // 參數指針為常指針
void function4(const int& Var); // 引用參數在函數內為常量
// 函數返回值
const int function5(); // 返回一個常數
const int* function6(); // 返回一個指向常量的指針變量,使用:const int *p = function6();
int* const function7(); // 返回一個指向變量的常指針,使用:int* const p = function7();- 修飾普通變量,修改變量的存儲區域和生命周期,使變量存儲在靜態區,在 main 函數運行前就分配了空間,如果有初始值就用初始值初始化它,如果沒有初始值系統用默認值初始化它。
- 修飾普通函數,表明函數的作用範圍,僅在定義該函數的文件內才能使用。在多人開發項目時,為了防止與他人命令函數重名,可以將函數定位為 static。
- 修飾成員變量,修飾成員變量使所有的對象只保存一個該變量,而且不需要生成對象就可以訪問該成員。
- 修飾成員函數,修飾成員函數使得不需要生成對象就可以訪問該函數,但是在 static 函數內不能訪問非靜態成員。
- 一個簡單的例子 http://bit.ly/2OxlrWt
this指針是一個隱含於每一個非靜態成員函數中的特殊指針。它指向正在被該成員函數操作的那個對象。- 當對一個對象調用成員函數時,編譯程序先將對象的地址賦給
this指針,然後調用成員函數,每次成員函數存取數據成員時,由隱含使用this指針。 - 當一個成員函數被調用時,自動向它傳遞一個隱含的參數,該參數是一個指向這個成員函數所在的對象的指針。
this指針被隱含地聲明為:ClassName *const this,這意味著不能給this指針賦值;在ClassName類的const成員函數中,this指針的類型為:const ClassName* const,這說明不能對this指針所指向的這種對象是不可修改的(即不能對這種對象的數據成員進行賦值操作);this並不是一個常規變量,而是個右值,所以不能取得this的地址(不能&this)。- 在以下場景中,經常需要顯式引用
this指針:- 為實現對象的鏈式引用;
- 為避免對同一對象進行賦值操作;
- 在實現一些數據結構時,如
list。
- 相當於把內聯函數裏面的內容寫在調用內聯函數處;
- 相當於不用執行進入函數的步驟,直接執行函數體;
- 相當於宏,卻比宏多了類型檢查,真正具有函數特性;
- 不能包含循環、遞歸、switch 等複雜操作;
- 在類聲明中定義的函數,除了虛函數的其他函數都會自動隱式地當成內聯函數。
inline 使用
// 聲明1(加 inline,建議使用)
inline int functionName(int first, int secend,...);
// 聲明2(不加 inline)
int functionName(int first, int secend,...);
// 定義
inline int functionName(int first, int secend,...) {/****/};
// 類內定義,隱式內聯
class A {
int doA() { return 0; } // 隱式內聯
}
// 類外定義,需要顯式內聯
class A {
int doA();
}
inline int A::doA() { return 0; } // 需要顯式內聯- 將 inline 函數體複制到 inline 函數調用點處;
- 為所用 inline 函數中的局部變量分配內存空間;
- 將 inline 函數的的輸入參數和返回值映射到調用方法的局部變量空間中;
- 如果 inline 函數有多個返回點,將其轉變為 inline 函數代碼塊末尾的分支(使用 GOTO)。
優點
- 內聯函數同宏函數一樣將在被調用處進行代碼展開,省去了參數壓棧、棧幀開辟與回收,結果返回等,從而提高程序運行速度。
- 內聯函數相比宏函數來說,在代碼展開時,會做安全檢查或自動類型轉換(同普通函數),而宏定義則不會。
- 在類中聲明同時定義的成員函數,自動轉化為內聯函數,因此內聯函數可以訪問類的成員變量,宏定義則不能。
- 內聯函數在運行時可調試,而宏定義不可以。
缺點
- 代碼膨脹。內聯是以代碼膨脹(複制)為代價,消除函數調用帶來的開銷。如果執行函數體內代碼的時間,相比於函數調用的開銷較大,那麼效率的收獲會很少。另一方面,每一處內聯函數的調用都要複制代碼,將使程序的總代碼量增大,消耗更多的內存空間。
- inline 函數無法隨著函數庫升級而升級。inline函數的改變需要重新編譯,不像 non-inline 可以直接鏈接。
- 是否內聯,程序員不可控。內聯函數只是對編譯器的建議,是否對函數內聯,決定權在於編譯器。
Are "inline virtual" member functions ever actually "inlined"?
- 虛函數可以是內聯函數,內聯是可以修飾虛函數的,但是當虛函數表現多態性的時候不能內聯。
- 內聯是在編譯器建議編譯器內聯,而虛函數的多態性在運行期,編譯器無法知道運行期調用哪個代碼,因此虛函數表現為多態性時(運行期)不可以內聯。
inline virtual唯一可以內聯的時候是:編譯器知道所調用的對象是哪個類(如Base::who()),這只有在編譯器具有實際對象而不是對象的指針或引用時才會發生。
虛函數內聯使用
#include <iostream>
using namespace std;
class Base
{
public:
inline virtual void who()
{
cout << "I am Base\n";
}
virtual ~Base() {}
};
class Derived : public Base
{
public:
inline void who() // 不寫inline時隱式內聯
{
cout << "I am Derived\n";
}
};
int main()
{
// 此處的虛函數 who(),是通過類(Base)的具體對象(b)來調用的,編譯期間就能確定了,所以它可以是內聯的,但最終是否內聯取決於編譯器。
Base b;
b.who();
// 此處的虛函數是通過指針調用的,呈現多態性,需要在運行時期間才能確定,所以不能為內聯。
Base *ptr = new Derived();
ptr->who();
// 因為Base有虛析構函數(virtual ~Base() {}),所以 delete 時,會先調用派生類(Derived)析構函數,再調用基類(Base)析構函數,防止內存泄漏。
delete ptr;
ptr = nullptr;
system("pause");
return 0;
} 斷言,是宏,而非函數。assert 宏的原型定義在 <assert.h>(C)、<cassert>(C++)中,其作用是如果它的條件返回錯誤,則終止程序執行。可以通過定義 NDEBUG 來關閉 assert,但是需要在源代碼的開頭,include <assert.h> 之前。
assert() 使用
#define NDEBUG // 加上這行,則 assert 不可用
#include <assert.h>
assert( p != NULL ); // assert 不可用- sizeof 對數組,得到整個數組所占空間大小。
- sizeof 對指針,得到指針本身所占空間大小。
設定結構體、聯合以及類成員變量以 n 字節方式對齊
#pragma pack(n) 使用
#pragma pack(push) // 保存對齊狀態
#pragma pack(4) // 設定為 4 字節對齊
struct test
{
char m1;
double m4;
int m3;
};
#pragma pack(pop) // 恢複對齊狀態Bit mode: 2; // mode 占 2 位類可以將其(非靜態)數據成員定義為位域(bit-field),在一個位域中含有一定數量的二進制位。當一個程序需要向其他程序或硬件設備傳遞二進制數據時,通常會用到位域。
- 位域在內存中的布局是與機器有關的
- 位域的類型必須是整型或枚舉類型,帶符號類型中的位域的行為將因具體實現而定
- 取地址運算符(&)不能作用於位域,任何指針都無法指向類的位域
volatile int i = 10; - volatile 關鍵字是一種類型修飾符,用它聲明的類型變量表示可以被某些編譯器未知的因素(操作系統、硬件、其它線程等)更改。所以使用 volatile 告訴編譯器不應對這樣的對象進行優化。
- volatile 關鍵字聲明的變量,每次訪問時都必須從內存中取出值(沒有被 volatile 修飾的變量,可能由於編譯器的優化,從 CPU 寄存器中取值)
- const 可以是 volatile (如只讀的狀態寄存器)
- 指針可以是 volatile
- 被 extern 限定的函數或變量是 extern 類型的
- 被
extern "C"修飾的變量和函數是按照 C 語言方式編譯和連接的
extern "C" 的作用是讓 C++ 編譯器將 extern "C" 聲明的代碼當作 C 語言代碼處理,可以避免 C++ 因符號修飾導致代碼不能和C語言庫中的符號進行鏈接的問題。
extern "C" 使用
#ifdef __cplusplus
extern "C" {
#endif
void *memset(void *, int, size_t);
#ifdef __cplusplus
}
#endif// c
typedef struct Student {
int age;
} S;等價於
// c
struct Student {
int age;
};
typedef struct Student S;此時 S 等價於 struct Student,但兩個標識符名稱空間不相同。
另外還可以定義與 struct Student 不沖突的 void Student() {}。
由於編譯器定位符號的規則(搜索規則)改變,導致不同於C語言。
一、如果在類標識符空間定義了 struct Student {...};,使用 Student me; 時,編譯器將搜索全局標識符表,Student 未找到,則在類標識符內搜索。
即表現為可以使用 Student 也可以使用 struct Student,如下:
// cpp
struct Student {
int age;
};
void f( Student me ); // 正確,"struct" 關鍵字可省略二、若定義了與 Student 同名函數之後,則 Student 只代表函數,不代表結構體,如下:
typedef struct Student {
int age;
} S;
void Student() {} // 正確,定義後 "Student" 只代表此函數
//void S() {} // 錯誤,符號 "S" 已經被定義為一個 "struct Student" 的別名
int main() {
Student();
struct Student me; // 或者 "S me";
return 0;
}總的來說,struct 更適合看成是一個數據結構的實現體,class 更適合看成是一個對象的實現體。
- 最本質的一個區別就是默認的訪問控制
- 默認的繼承訪問權限。struct 是 public 的,class 是 private 的。
- struct 作為數據結構的實現體,它默認的數據訪問控制是 public 的,而 class 作為對象的實現體,它默認的成員變量訪問控制是 private 的。
聯合(union)是一種節省空間的特殊的類,一個 union 可以有多個數據成員,但是在任意時刻只有一個數據成員可以有值。當某個成員被賦值後其他成員變為未定義狀態。聯合有如下特點:
- 默認訪問控制符為 public
- 可以含有構造函數、析構函數
- 不能含有引用類型的成員
- 不能繼承自其他類,不能作為基類
- 不能含有虛函數
- 匿名 union 在定義所在作用域可直接訪問 union 成員
- 匿名 union 不能包含 protected 成員或 private 成員
- 全局匿名聯合必須是靜態(static)的
union 使用
#include<iostream>
union UnionTest {
UnionTest() : i(10) {};
int i;
double d;
};
static union {
int i;
double d;
};
int main() {
UnionTest u;
union {
int i;
double d;
};
std::cout << u.i << std::endl; // 輸出 UnionTest 聯合的 10
::i = 20;
std::cout << ::i << std::endl; // 輸出全局靜態匿名聯合的 20
i = 30;
std::cout << i << std::endl; // 輸出局部匿名聯合的 30
return 0;
}explicit 修飾的構造函數可用來防止隱式轉換
explicit 使用
class Test1
{
public:
Test1(int n) // 普通構造函數
{
num=n;
}
private:
int num;
};
class Test2
{
public:
explicit Test2(int n) // explicit(顯式)構造函數
{
num=n;
}
private:
int num;
};
int main()
{
Test1 t1=12; // 隱式調用其構造函數,成功
Test2 t2=12; // 編譯錯誤,不能隱式調用其構造函數
Test2 t2(12); // 顯式調用成功
return 0;
}- 能訪問私有成員
- 破壞封裝性
- 友元關系不可傳遞
- 友元關系的單向性
- 友元聲明的形式及數量不受限制
一條 using 聲明 語句一次只引入命名空間的一個成員。它使得我們可以清楚知道程序中所引用的到底是哪個名字。如:
using namespace_name::name;在 C++11 中,派生類能夠重用其直接基類定義的構造函數。
class Derived : Base {
public:
using Base::Base;
/* ... */
};如上 using 聲明,對於基類的每個構造函數,編譯器都生成一個與之對應(形參列表完全相同)的派生類構造函數。生成如下類型構造函數:
derived(parms) : base(args) { }using 指示 使得某個特定命名空間中所有名字都可見,這樣我們就無需再為它們添加任何前綴限定符了。如:
using namespace_name name;一般說來,使用 using 命令比使用 using 編譯命令更安全,這是由於它只導入了制定的名稱。如果該名稱與局部名稱發生沖突,編譯器將發出指示。using編譯命令導入所有的名稱,包括可能並不需要的名稱。如果與局部名稱發生沖突,則局部名稱將覆蓋名稱空間版本,而編譯器並不會發出警告。另外,名稱空間的開放性意味著名稱空間的名稱可能分散在多個地方,這使得難以准確知道添加了哪些名稱。
using 使用
盡量少使用 using 指示
using namespace std;應該多使用 using 聲明
int x;
std::cin >> x ;
std::cout << x << std::endl;或者
using std::cin;
using std::cout;
using std::endl;
int x;
cin >> x;
cout << x << endl;- 全局作用域符(
::name):用於類型名稱(類、類成員、成員函數、變量等)前,表示作用域為全局命名空間 - 類作用域符(
class::name):用於表示指定類型的作用域範圍是具體某個類的 - 命名空間作用域符(
namespace::name):用於表示指定類型的作用域範圍是具體某個命名空間的
:: 使用
int count = 0; // 全局(::)的 count
class A {
public:
static int count; // 類 A 的 count(A::count)
};
int main() {
::count = 1; // 設置全局的 count 的值為 1
A::count = 2; // 設置類 A 的 count 為 2
int count = 0; // 局部的 count
count = 3; // 設置局部的 count 的值為 3
return 0;
}enum class open_modes { input, output, append };enum color { red, yellow, green };
enum { floatPrec = 6, doublePrec = 10 };decltype 關鍵字用於檢查實體的聲明類型或表達式的類型及值分類。語法:
decltype ( expression )decltype 使用
// 尾置返回允許我們在參數列表之後聲明返回類型
template <typename It>
auto fcn(It beg, It end) -> decltype(*beg)
{
// 處理序列
return *beg; // 返回序列中一個元素的引用
}
// 為了使用模板參數成員,必須用 typename
template <typename It>
auto fcn2(It beg, It end) -> typename remove_reference<decltype(*beg)>::type
{
// 處理序列
return *beg; // 返回序列中一個元素的拷貝
}常規引用,一般表示對象的身份。
右值引用就是必須綁定到右值(一個臨時對象、將要銷毀的對象)的引用,一般表示對象的值。
右值引用可實現轉移語義(Move Sementics)和精確傳遞(Perfect Forwarding),它的主要目的有兩個方面:
- 消除兩個對象交互時不必要的對象拷貝,節省運算存儲資源,提高效率。
- 能夠更簡潔明確地定義泛型函數。
X& &、X& &&、X&& &可折疊成X&X&& &&可折疊成X&&
- 宏定義可以實現類似於函數的功能,但是它終歸不是函數,而宏定義中括弧中的「參數」也不是真的參數,在宏展開的時候對 「參數」 進行的是一對一的替換。
好處
- 更高效:少了一次調用默認構造函數的過程。
- 有些場合必須要用初始化列表:
- 常量成員,因為常量只能初始化不能賦值,所以必須放在初始化列表裏面
- 引用類型,引用必須在定義的時候初始化,並且不能重新賦值,所以也要寫在初始化列表裏面
- 沒有默認構造函數的類類型,因為使用初始化列表可以不必調用默認構造函數來初始化,而是直接調用拷貝構造函數初始化。
用花括號初始化器列表列表初始化一個對象,其中對應構造函數接受一個 std::initializer_list 參數.
initializer_list 使用
#include <iostream>
#include <vector>
#include <initializer_list>
template <class T>
struct S {
std::vector<T> v;
S(std::initializer_list<T> l) : v(l) {
std::cout << "constructed with a " << l.size() << "-element list\n";
}
void append(std::initializer_list<T> l) {
v.insert(v.end(), l.begin(), l.end());
}
std::pair<const T*, std::size_t> c_arr() const {
return {&v[0], v.size()}; // 在 return 語句中複制列表初始化
// 這不使用 std::initializer_list
}
};
template <typename T>
void templated_fn(T) {}
int main()
{
S<int> s = {1, 2, 3, 4, 5}; // 複制初始化
s.append({6, 7, 8}); // 函數調用中的列表初始化
std::cout << "The vector size is now " << s.c_arr().second << " ints:\n";
for (auto n : s.v)
std::cout << n << ' ';
std::cout << '\n';
std::cout << "Range-for over brace-init-list: \n";
for (int x : {-1, -2, -3}) // auto 的規則令此帶範圍 for 工作
std::cout << x << ' ';
std::cout << '\n';
auto al = {10, 11, 12}; // auto 的特殊規則
std::cout << "The list bound to auto has size() = " << al.size() << '\n';
// templated_fn({1, 2, 3}); // 編譯錯誤!「 {1, 2, 3} 」不是表達式,
// 它無類型,故 T 無法推導
templated_fn<std::initializer_list<int>>({1, 2, 3}); // OK
templated_fn<std::vector<int>>({1, 2, 3}); // 也 OK
}面向對象程序設計(Object-oriented programming,OOP)是種具有對象概念的程序編程典範,同時也是一種程序開發的抽象方針。

面向對象三大特征 —— 封裝、繼承、多態
- 把客觀事物封裝成抽象的類,並且類可以把自己的數據和方法只讓可信的類或者對象操作,對不可信的進行信息隱藏。
- 關鍵字:public, protected, friendly, private。不寫默認為 friendly。
| 關鍵字 | 當前類 | 包內 | 子孫類 | 包外 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| friendly | √ | √ | × | × |
| private | √ | × | × | × |
- 基類(父類)——> 派生類(子類)
- 多態,即多種狀態,在面向對象語言中,接口的多種不同的實現方式即為多態。
- C++ 多態有兩種:靜態多態(早綁定)、動態多態(晚綁定)。靜態多態是通過函數重載實現的;動態多態是通過虛函數實現的。
- 多態是以封裝和繼承為基礎的。
函數重載
class A
{
public:
void do(int a);
void do(int a, int b);
};- 虛函數:用 virtual 修飾成員函數,使其成為虛函數
注意:
- 普通函數(非類成員函數)不能是虛函數
- 靜態函數(static)不能是虛函數
- 構造函數不能是虛函數(因為在調用構造函數時,虛表指針並沒有在對象的內存空間中,必須要構造函數調用完成後才會形成虛表指針)
- 內聯函數不能是表現多態性時的虛函數,解釋見:虛函數(virtual)可以是內聯函數(inline)嗎?
動態多態使用
class Shape // 形狀類
{
public:
virtual double calcArea()
{
...
}
virtual ~Shape();
};
class Circle : public Shape // 圓形類
{
public:
virtual double calcArea();
...
};
class Rect : public Shape // 矩形類
{
public:
virtual double calcArea();
...
};
int main()
{
Shape * shape1 = new Circle(4.0);
Shape * shape2 = new Rect(5.0, 6.0);
shape1->calcArea(); // 調用圓形類裏面的方法
shape2->calcArea(); // 調用矩形類裏面的方法
delete shape1;
shape1 = nullptr;
delete shape2;
shape2 = nullptr;
return 0;
}虛析構函數是為了解決基類的指針指向派生類對象,並用基類的指針刪除派生類對象。
虛析構函數使用
class Shape
{
public:
Shape(); // 構造函數不能是虛函數
virtual double calcArea();
virtual ~Shape(); // 虛析構函數
};
class Circle : public Shape // 圓形類
{
public:
virtual double calcArea();
...
};
int main()
{
Shape * shape1 = new Circle(4.0);
shape1->calcArea();
delete shape1; // 因為Shape有虛析構函數,所以delete釋放內存時,先調用子類析構函數,再調用基類析構函數,防止內存泄漏。
shape1 = NULL;
return 0;
}純虛函數是一種特殊的虛函數,在基類中不能對虛函數給出有意義的實現,而把它聲明為純虛函數,它的實現留給該基類的派生類去做。
virtual int A() = 0;- 類裏如果聲明了虛函數,這個函數是實現的,哪怕是空實現,它的作用就是為了能讓這個函數在它的子類裏面可以被覆蓋,這樣的話,這樣編譯器就可以使用後期綁定來達到多態了。純虛函數只是一個接口,是個函數的聲明而已,它要留到子類裏去實現。
- 虛函數在子類裏面也可以不重載的;但純虛函數必須在子類去實現。
- 虛函數的類用於 「實作繼承」,繼承接口的同時也繼承了父類的實現。當然大家也可以完成自己的實現。純虛函數關注的是接口的統一性,實現由子類完成。
- 帶純虛函數的類叫虛基類,這種基類不能直接生成對象,而只有被繼承,並重寫其虛函數後,才能使用。這樣的類也叫抽象類。抽象類和大家口頭常說的虛基類還是有區別的,在 C# 中用 abstract 定義抽象類,而在 C++ 中有抽象類的概念,但是沒有這個關鍵字。抽象類被繼承後,子類可以繼續是抽象類,也可以是普通類,而虛基類,是含有純虛函數的類,它如果被繼承,那麼子類就必須實現虛基類裏面的所有純虛函數,其子類不能是抽象類。
- 虛函數指針:在含有虛函數類的對象中,指向虛函數表,在運行時確定。
- 虛函數表:在程序只讀數據段(
.rodata section,見:目標文件存儲結構),存放虛函數指針,如果派生類實現了基類的某個虛函數,則在虛表中覆蓋原本基類的那個虛函數指針,在編譯時根據類的聲明創建。
虛繼承用於解決多繼承條件下的菱形繼承問題(浪費存儲空間、存在二義性)。
底層實現原理與編譯器相關,一般通過虛基類指針和虛基類表實現,每個虛繼承的子類都有一個虛基類指針(占用一個指針的存儲空間,4字節)和虛基類表(不占用類對象的存儲空間)(需要強調的是,虛基類依舊會在子類裏面存在拷貝,只是僅僅最多存在一份而已,並不是不在子類裏面了);當虛繼承的子類被當做父類繼承時,虛基類指針也會被繼承。
實際上,vbptr 指的是虛基類表指針(virtual base table pointer),該指針指向了一個虛基類表(virtual table),虛表中記錄了虛基類與本類的偏移地址;通過偏移地址,這樣就找到了虛基類成員,而虛繼承也不用像普通多繼承那樣維持著公共基類(虛基類)的兩份同樣的拷貝,節省了存儲空間。
- 相同之處:都利用了虛指針(均占用類的存儲空間)和虛表(均不占用類的存儲空間)
- 不同之處:
- 虛繼承
- 虛基類依舊存在繼承類中,只占用存儲空間
- 虛基類表存儲的是虛基類相對直接繼承類的偏移
- 虛函數
- 虛函數不占用存儲空間
- 虛函數表存儲的是虛函數地址
- 虛繼承
- 模板類中可以使用虛函數
- 一個類(無論是普通類還是類模板)的成員模板(本身是模板的成員函數)不能是虛函數
- 抽象類:含有純虛函數的類
- 接口類:僅含有純虛函數的抽象類
- 聚合類:用戶可以直接訪問其成員,並且具有特殊的初始化語法形式。滿足如下特點:
- 所有成員都是 public
- 沒有有定於任何構造函數
- 沒有類內初始化
- 沒有基類,也沒有 virtual 函數
- malloc:申請指定字節數的內存。申請到的內存中的初始值不確定。
- calloc:為指定長度的對象,分配能容納其指定個數的內存。申請到的內存的每一位(bit)都初始化為 0。
- realloc:更改以前分配的內存長度(增加或減少)。當增加長度時,可能需將以前分配區的內容移到另一個足夠大的區域,而新增區域內的初始值則不確定。
- alloca:在棧上申請內存。程序在出棧的時候,會自動釋放內存。但是需要注意的是,alloca 不具可移植性, 而且在沒有傳統堆棧的機器上很難實現。alloca 不宜使用在必須廣泛移植的程序中。C99 中支持變長數組 (VLA),可以用來替代 alloca。
用於分配、釋放內存
malloc、free 使用
申請內存,確認是否申請成功
char *str = (char*) malloc(100);
assert(str != nullptr);釋放內存後指針置空
free(p);
p = nullptr;- new / new[]:完成兩件事,先底層調用 malloc 分了配內存,然後調用構造函數(創建對象)。
- delete/delete[]:也完成兩件事,先調用析構函數(清理資源),然後底層調用 free 釋放空間。
- new 在申請內存時會自動計算所需字節數,而 malloc 則需我們自己輸入申請內存空間的字節數。
new、delete 使用
申請內存,確認是否申請成功
int main()
{
T* t = new T(); // 先內存分配 ,再構造函數
delete t; // 先析構函數,再內存釋放
return 0;
}定位 new(placement new)允許我們向 new 傳遞額外的參數。
new (palce_address) type
new (palce_address) type (initializers)
new (palce_address) type [size]
new (palce_address) type [size] { braced initializer list }palce_address是個指針initializers提供一個(可能為空的)以逗號分隔的初始值列表
Is it legal (and moral) for a member function to say delete this?
合法,但:
- 必須保證 this 對象是通過
new(不是new[]、不是 placement new、不是棧上、不是全局、不是其他對象成員)分配的 - 必須保證調用
delete this的成員函數是最後一個調用 this 的成員函數 - 必須保證成員函數的
delete this後面沒有調用 this 了 - 必須保證
delete this後沒有人使用了
方法:將析構函數設置為私有
原因:C++ 是靜態綁定語言,編譯器管理棧上對象的生命周期,編譯器在為類對象分配棧空間時,會先檢查類的析構函數的訪問性。若析構函數不可訪問,則不能在棧上創建對象。
方法:將 new 和 delete 重載為私有
原因:在堆上生成對象,使用 new 關鍵詞操作,其過程分為兩階段:第一階段,使用 new 在堆上尋找可用內存,分配給對象;第二階段,調用構造函數生成對象。將 new 操作設置為私有,那麼第一階段就無法完成,就不能夠在堆上生成對象。
頭文件:#include <memory>
std::auto_ptr<std::string> ps (new std::string(str));- shared_ptr
- unique_ptr
- weak_ptr
- auto_ptr(被 C++11 棄用)
- Class shared_ptr 實現共享式擁有(shared ownership)概念。多個智能指針指向相同對象,該對象和其相關資源會在 「最後一個 reference 被銷毀」 時被釋放。為了在結構較複雜的情景中執行上述工作,標准庫提供 weak_ptr、bad_weak_ptr 和 enable_shared_from_this 等輔助類。
- Class unique_ptr 實現獨占式擁有(exclusive ownership)或嚴格擁有(strict ownership)概念,保證同一時間內只有一個智能指針可以指向該對象。你可以移交擁有權。它對於避免內存泄漏(resource leak)——如 new 後忘記 delete ——特別有用。
多個智能指針可以共享同一個對象,對象的最末一個擁有著有責任銷毀對象,並清理與該對象相關的所有資源。
- 支持定制型刪除器(custom deleter),可防範 Cross-DLL 問題(對象在動態鏈接庫(DLL)中被 new 創建,卻在另一個 DLL 內被 delete 銷毀)、自動解除互斥鎖
weak_ptr 允許你共享但不擁有某對象,一旦最末一個擁有該對象的智能指針失去了所有權,任何 weak_ptr 都會自動成空(empty)。因此,在 default 和 copy 構造函數之外,weak_ptr 只提供 「接受一個 shared_ptr」 的構造函數。
- 可打破環狀引用(cycles of references,兩個其實已經沒有被使用的對象彼此互指,使之看似還在 「被使用」 的狀態)的問題
unique_ptr 是 C++11 才開始提供的類型,是一種在異常時可以幫助避免資源泄漏的智能指針。采用獨占式擁有,意味著可以確保一個對象和其相應的資源同一時間只被一個 pointer 擁有。一旦擁有著被銷毀或編程 empty,或開始擁有另一個對象,先前擁有的那個對象就會被銷毀,其任何相應資源亦會被釋放。
- unique_ptr 用於取代 auto_ptr
被 c++11 棄用,原因是缺乏語言特性如 「針對構造和賦值」 的 std::move 語義,以及其他瑕疵。
- auto_ptr 可以賦值拷貝,複制拷貝後所有權轉移;unqiue_ptr 無拷貝賦值語義,但實現了
move語義; - auto_ptr 對象不能管理數組(析構調用
delete),unique_ptr 可以管理數組(析構調用delete[]);
- 用於非多態類型的轉換
- 不執行運行時類型檢查(轉換安全性不如 dynamic_cast)
- 通常用於轉換數值數據類型(如 float -> int)
- 可以在整個類層次結構中移動指針,子類轉化為父類安全(向上轉換),父類轉化為子類不安全(因為子類可能有不在父類的字段或方法)
向上轉換是一種隱式轉換。
- 用於多態類型的轉換
- 執行行運行時類型檢查
- 只適用於指針或引用
- 對不明確的指針的轉換將失敗(返回 nullptr),但不引發異常
- 可以在整個類層次結構中移動指針,包括向上轉換、向下轉換
- 用於刪除 const、volatile 和 __unaligned 特性(如將 const int 類型轉換為 int 類型 )
- 用於位的簡單重新解釋
- 濫用 reinterpret_cast 運算符可能很容易帶來風險。 除非所需轉換本身是低級別的,否則應使用其他強制轉換運算符之一。
- 允許將任何指針轉換為任何其他指針類型(如
char*到int*或One_class*到Unrelated_class*之類的轉換,但其本身並不安全) - 也允許將任何整數類型轉換為任何指針類型以及反向轉換。
- reinterpret_cast 運算符不能丟掉 const、volatile 或 __unaligned 特性。
- reinterpret_cast 的一個實際用途是在哈希函數中,即,通過讓兩個不同的值幾乎不以相同的索引結尾的方式將值映射到索引。
- 由於強制轉換為引用類型失敗,dynamic_cast 運算符引發 bad_cast 異常。
bad_cast 使用
try {
Circle& ref_circle = dynamic_cast<Circle&>(ref_shape);
}
catch (bad_cast b) {
cout << "Caught: " << b.what();
} - 用於多態類型的轉換
- typeid 運算符允許在運行時確定對象的類型
- type_id 返回一個 type_info 對象的引用
- 如果想通過基類的指針獲得派生類的數據類型,基類必須帶有虛函數
- 只能獲取對象的實際類型
- type_info 類描述編譯器在程序中生成的類型信息。 此類的對象可以有效存儲指向類型的名稱的指針。 type_info 類還可存儲適合比較兩個類型是否相等或比較其排列順序的編碼值。 類型的編碼規則和排列順序是未指定的,並且可能因程序而異。
- 頭文件:
typeinfo
typeid、type_info 使用
class Flyable // 能飛的
{
public:
virtual void takeoff() = 0; // 起飛
virtual void land() = 0; // 降落
};
class Bird : public Flyable // 鳥
{
public:
void foraging() {...} // 覓食
virtual void takeoff() {...}
virtual void land() {...}
};
class Plane : public Flyable // 飛機
{
public:
void carry() {...} // 運輸
virtual void take off() {...}
virtual void land() {...}
};
class type_info
{
public:
const char* name() const;
bool operator == (const type_info & rhs) const;
bool operator != (const type_info & rhs) const;
int before(const type_info & rhs) const;
virtual ~type_info();
private:
...
};
class doSomething(Flyable *obj) // 做些事情
{
obj->takeoff();
cout << typeid(*obj).name() << endl; // 輸出傳入對象類型("class Bird" or "class Plane")
if(typeid(*obj) == typeid(Bird)) // 判斷對象類型
{
Bird *bird = dynamic_cast<Bird *>(obj); // 對象轉化
bird->foraging();
}
obj->land();
};- 視 C++ 為一個語言聯邦(C、Object-Oriented C++、Template C++、STL)
- 寧可以編譯器替換預處理器(盡量以
const、enum、inline替換#define) - 盡可能使用 const
- 確定對象被使用前已先被初始化(構造時賦值(copy 構造函數)比 default 構造後賦值(copy assignment)效率高)
- 了解 C++ 默默編寫並調用哪些函數(編譯器暗自為 class 創建 default 構造函數、copy 構造函數、copy assignment 操作符、析構函數)
- 若不想使用編譯器自動生成的函數,就應該明確拒絕(將不想使用的成員函數聲明為 private,並且不予實現)
- 為多態基類聲明 virtual 析構函數(如果 class 帶有任何 virtual 函數,它就應該擁有一個 virtual 析構函數)
- 別讓異常逃離析構函數(析構函數應該吞下不傳播異常,或者結束程序,而不是吐出異常;如果要處理異常應該在非析構的普通函數處理)
- 絕不在構造和析構過程中調用 virtual 函數(因為這類調用從不下降至 derived class)
- 令
operator=返回一個reference to *this(用於連鎖賦值) - 在
operator=中處理 「自我賦值」 - 賦值對象時應確保複制 「對象內的所有成員變量」 及 「所有 base class 成分」(調用基類複制構造函數)
- 以對象管理資源(資源在構造函數獲得,在析構函數釋放,建議使用智能指針,資源取得時機便是初始化時機(Resource Acquisition Is Initialization,RAII))
- 在資源管理類中小心 copying 行為(普遍的 RAII class copying 行為是:抑制 copying、引用計數、深度拷貝、轉移底部資源擁有權(類似 auto_ptr))
- 在資源管理類中提供對原始資源(raw resources)的訪問(對原始資源的訪問可能經過顯式轉換或隱式轉換,一般而言顯示轉換比較安全,隱式轉換對客戶比較方便)
- 成對使用 new 和 delete 時要采取相同形式(
new中使用[]則delete [],new中不使用[]則delete) - 以獨立語句將 newed 對象存儲於(置入)智能指針(如果不這樣做,可能會因為編譯器優化,導致難以察覺的資源泄漏)
- 讓接口容易被正確使用,不易被誤用(促進正常使用的辦法:接口的一致性、內置類型的行為兼容;阻止誤用的辦法:建立新類型,限制類型上的操作,約束對象值、消除客戶的資源管理責任)
- 設計 class 猶如設計 type,需要考慮對象創建、銷毀、初始化、賦值、值傳遞、合法值、繼承關系、轉換、一般化等等。
- 寧以 pass-by-reference-to-const 替換 pass-by-value (前者通常更高效、避免切割問題(slicing problem),但不適用於內置類型、STL迭代器、函數對象)
- 必須返回對象時,別妄想返回其 reference(絕不返回 pointer 或 reference 指向一個 local stack 對象,或返回 reference 指向一個 heap-allocated 對象,或返回 pointer 或 reference 指向一個 local static 對象而有可能同時需要多個這樣的對象。)
- 將成員變量聲明為 private(為了封裝、一致性、對其讀寫精確控制等)
- 寧以 non-member、non-friend 替換 member 函數(可增加封裝性、包裹彈性(packaging flexibility)、機能擴充性)
- 若所有參數(包括被this指針所指的那個隱喻參數)皆須要類型轉換,請為此采用 non-member 函數
- 考慮寫一個不拋異常的 swap 函數
- 盡可能延後變量定義式的出現時間(可增加程序清晰度並改善程序效率)
- 盡量少做轉型動作(舊式:
(T)expression、T(expression);新式:const_cast<T>(expression)、dynamic_cast<T>(expression)、reinterpret_cast<T>(expression)、static_cast<T>(expression)、;盡量避免轉型、注重效率避免 dynamic_casts、盡量設計成無需轉型、可把轉型封裝成函數、寧可用新式轉型) - 避免使用 handles(包括 引用、指針、迭代器)指向對象內部(以增加封裝性、使 const 成員函數的行為更像 const、降低 「虛吊號碼牌」(dangling handles,如懸空指針等)的可能性)
- 為 「異常安全」 而努力是值得的(異常安全函數(Exception-safe functions)即使發生異常也不會泄露資源或允許任何數據結構敗壞,分為三種可能的保證:基本型、強列型、不拋異常型)
- 透徹了解 inlining 的裏裏外外(inlining 在大多數 C++ 程序中是編譯期的行為;inline 函數是否真正 inline,取決於編譯器;大部分編譯器拒絕太過複雜(如帶有循環或遞歸)的函數 inlining,而所有對 virtual 函數的調用(除非是最平淡無奇的)也都會使 inlining 落空;inline 造成的代碼膨脹可能帶來效率損失;inline 函數無法隨著程序庫的升級而升級)
- 將文件間的編譯依存關系降至最低(如果使用 object references 或 object pointers 可以完成任務,就不要使用 objects;如果能過夠,盡量以 class 聲明式替換 class 定義式;為聲明式和定義式提供不同的頭文件)
- 確定你的 public 繼承塑模出 is-a 關系(適用於 base classes 身上的每一件事情一定適用於 derived classes 身上,因為每一個 derived class 對象也都是一個 base class 對象)
- 避免遮掩繼承而來的名字(可使用 using 聲明式或轉交函數(forwarding functions)來讓被遮掩的名字再見天日)
- 區分接口繼承和實現繼承(在 public 繼承之下,derived classes 總是繼承 base class 的接口;pure virtual 函數只具體指定接口繼承;非純 impure virtual 函數具體指定接口繼承及缺省實現繼承;non-virtual 函數具體指定接口繼承以及強制性實現繼承)
- 考慮 virtual 函數以外的其他選擇(如 Template Method 設計模式的 non-virtual interface(NVI)手法,將 virtual 函數替換為 「函數指針成員變量」,以
tr1::function成員變量替換 virtual 函數,將繼承體系內的 virtual 函數替換為另一個繼承體系內的 virtual 函數) - 絕不重新定義繼承而來的 non-virtual 函數
- 絕不重新定義繼承而來的缺省參數值,因為缺省參數值是靜態綁定(statically bound),而 virtual 函數卻是動態綁定(dynamically bound)

| 容器 | 底層數據結構 | 時間複雜度 | 有無序 | 可不可重複 | 其他 |
|---|---|---|---|---|---|
| array | 數組 | 隨機讀改 O(1) | 無序 | 可重複 | 支持快速隨機訪問 |
| vector | 數組 | 隨機讀改、尾部插入、尾部刪除 O(1) 頭部插入、頭部刪除 O(n) |
無序 | 可重複 | 支持快速隨機訪問 |
| list | 雙向鏈表 | 插入、刪除 O(1) 隨機讀改 O(n) |
無序 | 可重複 | 支持快速增刪 |
| deque | 雙端隊列 | 頭尾插入、頭尾刪除 O(1) | 無序 | 可重複 | 一個中央控制器 + 多個緩沖區,支持首尾快速增刪,支持隨機訪問 |
| stack | deque / list | 頂部插入、頂部刪除 O(1) | 無序 | 可重複 | deque 或 list 封閉頭端開口,不用 vector 的原因應該是容量大小有限制,擴容耗時 |
| queue | deque / list | 尾部插入、頭部刪除 O(1) | 無序 | 可重複 | deque 或 list 封閉頭端開口,不用 vector 的原因應該是容量大小有限制,擴容耗時 |
| priority_queue | vector + max-heap | 插入、刪除 O(log2n) | 有序 | 可重複 | vector容器+heap處理規則 |
| set | 紅黑樹 | 插入、刪除、查找 O(log2n) | 有序 | 不可重複 | |
| multiset | 紅黑樹 | 插入、刪除、查找 O(log2n) | 有序 | 可重複 | |
| map | 紅黑樹 | 插入、刪除、查找 O(log2n) | 有序 | 不可重複 | |
| multimap | 紅黑樹 | 插入、刪除、查找 O(log2n) | 有序 | 可重複 | |
| hash_set | 哈希表 | 插入、刪除、查找 O(1) 最差 O(n) | 無序 | 不可重複 | |
| hash_multiset | 哈希表 | 插入、刪除、查找 O(1) 最差 O(n) | 無序 | 可重複 | |
| hash_map | 哈希表 | 插入、刪除、查找 O(1) 最差 O(n) | 無序 | 不可重複 | |
| hash_multimap | 哈希表 | 插入、刪除、查找 O(1) 最差 O(n) | 無序 | 可重複 |
| 算法 | 底層算法 | 時間複雜度 | 可不可重複 |
|---|---|---|---|
| find | 順序查找 | O(n) | 可重複 |
| sort | 內省排序 | O(n*log2n) | 可重複 |
順序棧數據結構和圖片
typedef struct {
ElemType *elem;
int top;
int size;
int increment;
} SqSrack;
隊列數據結構
typedef struct {
ElemType * elem;
int front;
int rear;
int maxSize;
}SqQueue;非循環隊列圖片

SqQueue.rear++
循環隊列圖片

SqQueue.rear = (SqQueue.rear + 1) % SqQueue.maxSize
順序表數據結構和圖片
typedef struct {
ElemType *elem;
int length;
int size;
int increment;
} SqList;
鏈式數據結構
typedef struct LNode {
ElemType data;
struct LNode *next;
} LNode, *LinkList; 鏈隊列圖片

單鏈表圖片

雙向鏈表圖片

循環鏈表圖片

哈希函數:H(key): K -> D , key ∈ K
- 直接定址法
- 除留餘數法
- 數字分析法
- 折疊法
- 平方取中法
- 鏈地址法:key 相同的用單鏈表鏈接
- 開放定址法
- 線性探測法:key 相同 -> 放到 key 的下一個位置,
Hi = (H(key) + i) % m - 二次探測法:key 相同 -> 放到
Di = 1^2, -1^2, ..., ±(k)^2,(k<=m/2) - 隨機探測法:
H = (H(key) + 偽隨機數) % m
- 線性探測法:key 相同 -> 放到 key 的下一個位置,
線性探測的哈希表數據結構和圖片
typedef char KeyType;
typedef struct {
KeyType key;
}RcdType;
typedef struct {
RcdType *rcd;
int size;
int count;
bool *tag;
}HashTable;
函數直接或間接地調用自身
- 分治法
- 問題的分解
- 問題規模的分解
- 折半查找(遞歸)
- 歸並查找(遞歸)
- 快速排序(遞歸)
- 迭代:反複利用變量舊值推出新值
- 折半查找(迭代)
- 歸並查找(迭代)
廣義表的頭尾鏈表存儲表示和圖片
// 廣義表的頭尾鏈表存儲表示
typedef enum {ATOM, LIST} ElemTag;
// ATOM==0:原子,LIST==1:子表
typedef struct GLNode {
ElemTag tag;
// 公共部分,用於區分原子結點和表結點
union {
// 原子結點和表結點的聯合部分
AtomType atom;
// atom 是原子結點的值域,AtomType 由用戶定義
struct {
struct GLNode *hp, *tp;
} ptr;
// ptr 是表結點的指針域,prt.hp 和 ptr.tp 分別指向表頭和表尾
} a;
} *GList, GLNode;
擴展線性鏈表存儲表示和圖片
// 廣義表的擴展線性鏈表存儲表示
typedef enum {ATOM, LIST} ElemTag;
// ATOM==0:原子,LIST==1:子表
typedef struct GLNode1 {
ElemTag tag;
// 公共部分,用於區分原子結點和表結點
union {
// 原子結點和表結點的聯合部分
AtomType atom; // 原子結點的值域
struct GLNode1 *hp; // 表結點的表頭指針
} a;
struct GLNode1 *tp;
// 相當於線性鏈表的 next,指向下一個元素結點
} *GList1, GLNode1;
- 非空二叉樹第 i 層最多 2(i-1) 個結點 (i >= 1)
- 深度為 k 的二叉樹最多 2k - 1 個結點 (k >= 1)
- 度為 0 的結點數為 n0,度為 2 的結點數為 n2,則 n0 = n2 + 1
- 有 n 個結點的完全二叉樹深度 k = ⌊ log2(n) ⌋ + 1
- 對於含 n 個結點的完全二叉樹中編號為 i (1 <= i <= n) 的結點
- 若 i = 1,為根,否則雙親為 ⌊ i / 2 ⌋
- 若 2i > n,則 i 結點沒有左孩子,否則孩子編號為 2i
- 若 2i + 1 > n,則 i 結點沒有右孩子,否則孩子編號為 2i + 1
二叉樹數據結構
typedef struct BiTNode
{
TElemType data;
struct BiTNode *lchild, *rchild;
}BiTNode, *BiTree;二叉樹順序存儲圖片

二叉樹鏈式存儲圖片

- 先序遍曆
- 中序遍曆
- 後續遍曆
- 層次遍曆
- 滿二叉樹
- 完全二叉樹(堆)
- 大頂堆:根 >= 左 && 根 >= 右
- 小頂堆:根 <= 左 && 根 <= 右
- 二叉查找樹(二叉排序樹):左 < 根 < 右
- 平衡二叉樹(AVL樹):| 左子樹樹高 - 右子樹樹高 | <= 1
- 最小失衡樹:平衡二叉樹插入新結點導致失衡的子樹:調整:
- LL型:根的左孩子右旋
- RR型:根的右孩子左旋
- LR型:根的左孩子左旋,再右旋
- RL型:右孩子的左子樹,先右旋,再左旋
- 雙親表示法
- 雙親孩子表示法
- 孩子兄弟表示法
一種不相交的子集所構成的集合 S = {S1, S2, ..., Sn}
- | 左子樹樹高 - 右子樹樹高 | <= 1
- 平衡二叉樹必定是二叉搜索樹,反之則不一定
- 最小二叉平衡樹的節點的公式:
F(n)=F(n-1)+F(n-2)+1(1 是根節點,F(n-1) 是左子樹的節點數量,F(n-2) 是右子樹的節點數量)
平衡二叉樹圖片

平衡二叉樹插入新結點導致失衡的子樹
調整:
- LL 型:根的左孩子右旋
- RR 型:根的右孩子左旋
- LR 型:根的左孩子左旋,再右旋
- RL 型:右孩子的左子樹,先右旋,再左旋
- 節點是紅色或黑色。
- 根是黑色。
- 所有葉子都是黑色(葉子是 NIL 節點)。
- 每個紅色節點必須有兩個黑色的子節點。(從每個葉子到根的所有路徑上不能有兩個連續的紅色節點。)(新增節點的父節點必須相同)
- 從任一節點到其每個葉子的所有簡單路徑都包含相同數目的黑色節點。(新增節點必須為紅)
- 變色
- 左旋
- 右旋
- 關聯數組:如 STL 中的 map、set
- 紅黑樹的深度比較大,而 B 樹和 B+ 樹的深度則相對要小一些
- B+ 樹則將數據都保存在葉子節點,同時通過鏈表的形式將他們連接在一起。
B 樹、B+ 樹圖片

- 一般化的二叉查找樹(binary search tree)
- 「矮胖」,內部(非葉子)節點可以擁有可變數量的子節點(數量範圍預先定義好)
- 大部分文件系統、數據庫系統都采用B樹、B+樹作為索引結構
- B+樹中只有葉子節點會帶有指向記錄的指針(ROWID),而B樹則所有節點都帶有,在內部節點出現的索引項不會再出現在葉子節點中。
- B+樹中所有葉子節點都是通過指針連接在一起,而B樹不會。
對於在內部節點的數據,可直接得到,不必根據葉子節點來定位。
- 非葉子節點不會帶上 ROWID,這樣,一個塊中可以容納更多的索引項,一是可以降低樹的高度。二是一個內部節點可以定位更多的葉子節點。
- 葉子節點之間通過指針來連接,範圍掃描將十分簡單,而對於B樹來說,則需要在葉子節點和內部節點不停的往返移動。
B 樹、B+ 樹區別來自:differences-between-b-trees-and-b-trees、B樹和B+樹的區別
八叉樹圖片
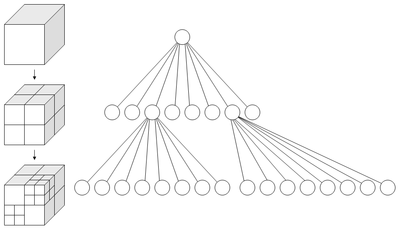
八叉樹(octree),或稱八元樹,是一種用於描述三維空間(劃分空間)的樹狀數據結構。八叉樹的每個節點表示一個正方體的體積元素,每個節點有八個子節點,這八個子節點所表示的體積元素加在一起就等於父節點的體積。一般中心點作為節點的分叉中心。
- 三維計算機圖形
- 最鄰近搜索
| 排序算法 | 平均時間複雜度 | 最差時間複雜度 | 空間複雜度 | 數據對象穩定性 |
|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n2) | O(1) | 穩定 |
| 選擇排序 | O(n2) | O(n2) | O(1) | 數組不穩定、鏈表穩定 |
| 插入排序 | O(n2) | O(n2) | O(1) | 穩定 |
| 快速排序 | O(n*log2n) | O(n2) | O(log2n) | 不穩定 |
| 堆排序 | O(n*log2n) | O(n*log2n) | O(1) | 不穩定 |
| 歸並排序 | O(n*log2n) | O(n*log2n) | O(n) | 穩定 |
| 希爾排序 | O(n*log2n) | O(n2) | O(1) | 不穩定 |
| 計數排序 | O(n+m) | O(n+m) | O(n+m) | 穩定 |
| 桶排序 | O(n) | O(n) | O(m) | 穩定 |
| 基數排序 | O(k*n) | O(n2) | 穩定 |
- 均按從小到大排列
- k:代表數值中的 「數位」 個數
- n:代表數據規模
- m:代表數據的最大值減最小值
- 來自:wikipedia . 排序算法
| 查找算法 | 平均時間複雜度 | 空間複雜度 | 查找條件 |
|---|---|---|---|
| 順序查找 | O(n) | O(1) | 無序或有序 |
| 二分查找(折半查找) | O(log2n) | O(1) | 有序 |
| 插值查找 | O(log2(log2n)) | O(1) | 有序 |
| 斐波那契查找 | O(log2n) | O(1) | 有序 |
| 哈希查找 | O(1) | O(n) | 無序或有序 |
| 二叉查找樹(二叉搜索樹查找) | O(log2n) | ||
| 紅黑樹 | O(log2n) | ||
| 2-3樹 | O(log2n - log3n) | ||
| B樹/B+樹 | O(log2n) |
| 圖搜索算法 | 數據結構 | 遍曆時間複雜度 | 空間複雜度 |
|---|---|---|---|
| BFS廣度優先搜索 | 鄰接矩陣 鄰接鏈表 |
O(|v|2) O(|v|+|E|) |
O(|v|2) O(|v|+|E|) |
| DFS深度優先搜索 | 鄰接矩陣 鄰接鏈表 |
O(|v|2) O(|v|+|E|) |
O(|v|2) O(|v|+|E|) |
| 算法 | 思想 | 應用 |
|---|---|---|
| 分治法 | 把一個複雜的問題分成兩個或更多的相同或相似的子問題,直到最後子問題可以簡單的直接求解,原問題的解即子問題的解的合並 | 循環賽日程安排問題、排序算法(快速排序、歸並排序) |
| 動態規劃 | 通過把原問題分解為相對簡單的子問題的方式求解複雜問題的方法,適用於有重疊子問題和最優子結構性質的問題 | 背包問題、斐波那契數列 |
| 貪心法 | 一種在每一步選擇中都采取在當前狀態下最好或最優(即最有利)的選擇,從而希望導致結果是最好或最優的算法 | 旅行推銷員問題(最短路徑問題)、最小生成樹、哈夫曼編碼 |
- Chessboard Coverage Problem(棋盤覆蓋問題)
- Knapsack Problem(背包問題)
- Neumann Neighbor Problem(馮諾依曼鄰居問題)
- Round Robin Problem(循環賽日程安排問題)
- Tubing Problem(輸油管道問題)
對於有線程系統:
- 進程是資源分配的獨立單位
- 線程是資源調度的獨立單位
對於無線程系統:
- 進程是資源調度、分配的獨立單位
- 管道(PIPE)
- 有名管道:一種半雙工的通信方式,它允許無親緣關系進程間的通信
- 優點:可以實現任意關系的進程間的通信
- 缺點:
- 長期存於系統中,使用不當容易出錯
- 緩沖區有限
- 無名管道:一種半雙工的通信方式,只能在具有親緣關系的進程間使用(父子進程)
- 優點:簡單方便
- 缺點:
- 局限於單向通信
- 只能創建在它的進程以及其有親緣關系的進程之間
- 緩沖區有限
- 有名管道:一種半雙工的通信方式,它允許無親緣關系進程間的通信
- 信號量(Semaphore):一個計數器,可以用來控制多個線程對共享資源的訪問
- 優點:可以同步進程
- 缺點:信號量有限
- 信號(Signal):一種比較複雜的通信方式,用於通知接收進程某個事件已經發生
- 消息隊列(Message Queue):是消息的鏈表,存放在內核中並由消息隊列標識符標識
- 優點:可以實現任意進程間的通信,並通過系統調用函數來實現消息發送和接收之間的同步,無需考慮同步問題,方便
- 缺點:信息的複制需要額外消耗 CPU 的時間,不適宜於信息量大或操作頻繁的場合
- 共享內存(Shared Memory):映射一段能被其他進程所訪問的內存,這段共享內存由一個進程創建,但多個進程都可以訪問
- 優點:無須複制,快捷,信息量大
- 缺點:
- 通信是通過將共享空間緩沖區直接附加到進程的虛擬地址空間中來實現的,因此進程間的讀寫操作的同步問題
- 利用內存緩沖區直接交換信息,內存的實體存在於計算機中,只能同一個計算機系統中的諸多進程共享,不方便網絡通信
- 套接字(Socket):可用於不同及其間的進程通信
- 優點:
- 傳輸數據為字節級,傳輸數據可自定義,數據量小效率高
- 傳輸數據時間短,性能高
- 適合於客戶端和服務器端之間信息實時交互
- 可以加密,數據安全性強
- 缺點:需對傳輸的數據進行解析,轉化成應用級的數據。
- 優點:
- 鎖機制:包括互斥鎖/量(mutex)、讀寫鎖(reader-writer lock)、自旋鎖(spin lock)、條件變量(condition)
- 互斥鎖/量(mutex):提供了以排他方式防止數據結構被並發修改的方法。
- 讀寫鎖(reader-writer lock):允許多個線程同時讀共享數據,而對寫操作是互斥的。
- 自旋鎖(spin lock)與互斥鎖類似,都是為了保護共享資源。互斥鎖是當資源被占用,申請者進入睡眠狀態;而自旋鎖則循環檢測保持著是否已經釋放鎖。
- 條件變量(condition):可以以原子的方式阻塞進程,直到某個特定條件為真為止。對條件的測試是在互斥鎖的保護下進行的。條件變量始終與互斥鎖一起使用。
- 信號量機制(Semaphore)
- 無名線程信號量
- 命名線程信號量
- 信號機制(Signal):類似進程間的信號處理
- 屏障(barrier):屏障允許每個線程等待,直到所有的合作線程都達到某一點,然後從該點繼續執行。
線程間的通信目的主要是用於線程同步,所以線程沒有像進程通信中的用於數據交換的通信機制
進程之間的通信方式以及優缺點來源於:進程線程面試題總結
- 私有:地址空間、堆、全局變量、棧、寄存器
- 共享:代碼段,公共數據,進程目錄,進程 ID
- 私有:線程棧,寄存器,程序寄存器
- 共享:堆,地址空間,全局變量,靜態變量
| 對比維度 | 多進程 | 多線程 | 總結 |
|---|---|---|---|
| 數據共享、同步 | 數據共享複雜,需要用 IPC;數據是分開的,同步簡單 | 因為共享進程數據,數據共享簡單,但也是因為這個原因導致同步複雜 | 各有優勢 |
| 內存、CPU | 占用內存多,切換複雜,CPU 利用率低 | 占用內存少,切換簡單,CPU 利用率高 | 線程占優 |
| 創建銷毀、切換 | 創建銷毀、切換複雜,速度慢 | 創建銷毀、切換簡單,速度很快 | 線程占優 |
| 編程、調試 | 編程簡單,調試簡單 | 編程複雜,調試複雜 | 進程占優 |
| 可靠性 | 進程間不會互相影響 | 一個線程掛掉將導致整個進程掛掉 | 進程占優 |
| 分布式 | 適應於多核、多機分布式;如果一台機器不夠,擴展到多台機器比較簡單 | 適應於多核分布式 | 進程占優 |
| 優劣 | 多進程 | 多線程 |
|---|---|---|
| 優點 | 編程、調試簡單,可靠性較高 | 創建、銷毀、切換速度快,內存、資源占用小 |
| 缺點 | 創建、銷毀、切換速度慢,內存、資源占用大 | 編程、調試複雜,可靠性較差 |
- 需要頻繁創建銷毀的優先用線程
- 需要進行大量計算的優先使用線程
- 強相關的處理用線程,弱相關的處理用進程
- 可能要擴展到多機分布的用進程,多核分布的用線程
- 都滿足需求的情況下,用你最熟悉、最拿手的方式
多進程與多線程間的對比、優劣與選擇來自:多線程還是多進程的選擇及區別
在現代操作系統裏,同一時間可能有多個內核執行流在執行,因此內核其實象多進程多線程編程一樣也需要一些同步機制來同步各執行單元對共享數據的訪問。尤其是在多處理器系統上,更需要一些同步機制來同步不同處理器上的執行單元對共享的數據的訪問。
- 原子操作
- 信號量(semaphore)
- 讀寫信號量(rw_semaphore)
- 自旋鎖(spinlock)
- 大內核鎖(BKL,Big Kernel Lock)
- 讀寫鎖(rwlock)
- 大讀者鎖(brlock-Big Reader Lock)
- 讀-拷貝修改(RCU,Read-Copy Update)
- 順序鎖(seqlock)
- 系統資源不足
- 資源分配不當
- 進程運行推進順序不合適
- 互斥
- 請求和保持
- 不剝奪
- 環路
- 打破互斥條件:改造獨占性資源為虛擬資源,大部分資源已無法改造。
- 打破不可搶占條件:當一進程占有一獨占性資源後又申請一獨占性資源而無法滿足,則退出原占有的資源。
- 打破占有且申請條件:采用資源預先分配策略,即進程運行前申請全部資源,滿足則運行,不然就等待,這樣就不會占有且申請。
- 打破循環等待條件:實現資源有序分配策略,對所有設備實現分類編號,所有進程只能采用按序號遞增的形式申請資源。
- 有序資源分配法
- 銀行家算法
- Windows:FCB 表 + FAT + 位圖
- Unix:inode + 混合索引 + 成組鏈接
主機字節序又叫 CPU 字節序,其不是由操作系統決定的,而是由 CPU 指令集架構決定的。主機字節序分為兩種:
- 大端字節序(Big Endian):高序字節存儲在低位地址,低序字節存儲在高位地址
- 小端字節序(Little Endian):高序字節存儲在高位地址,低序字節存儲在低位地址
32 位整數 0x12345678 是從起始位置為 0x00 的地址開始存放,則:
| 內存地址 | 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|---|
| 大端 | 12 | 34 | 56 | 78 |
| 小端 | 78 | 56 | 34 | 12 |
大端小端圖片


判斷大端小端
可以這樣判斷自己 CPU 字節序是大端還是小端:
#include <iostream>
using namespace std;
int main()
{
int i = 0x12345678;
if (*((char*)&i) == 0x12)
cout << "大端" << endl;
else
cout << "小端" << endl;
return 0;
}- x86(Intel、AMD)、MOS Technology 6502、Z80、VAX、PDP-11 等處理器為小端序;
- Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除 V9 外)等處理器為大端序;
- ARM(默認小端序)、PowerPC(除 PowerPC 970 外)、DEC Alpha、SPARC V9、MIPS、PA-RISC 及 IA64 的字節序是可配置的。
網絡字節順序是 TCP/IP 中規定好的一種數據表示格式,它與具體的 CPU 類型、操作系統等無關,從而可以保重數據在不同主機之間傳輸時能夠被正確解釋。
網絡字節順序采用:大端(Big Endian)排列方式。
在地址映射過程中,若在頁面中發現所要訪問的頁面不在內存中,則產生缺頁中斷。當發生缺頁中斷時,如果操作系統內存中沒有空閑頁面,則操作系統必須在內存選擇一個頁面將其移出內存,以便為即將調入的頁面讓出空間。而用來選擇淘汰哪一頁的規則叫做頁面置換算法。
- 全局置換:在整個內存空間置換
- 局部置換:在本進程中進行置換
全局:
- 工作集算法
- 缺頁率置換算法
局部:
- 最佳置換算法(OPT)
- 先進先出置換算法(FIFO)
- 最近最久未使用(LRU)算法
- 時鍾(Clock)置換算法
計算機經網絡體系結構:

| 分層 | 作用 | 協議 |
|---|---|---|
| 物理層 | 通過媒介傳輸比特,確定機械及電氣規範(比特 Bit) | RJ45、CLOCK、IEEE802.3(中繼器,集線器) |
| 數據鏈路層 | 將比特組裝成幀和點到點的傳遞(幀 Frame) | PPP、FR、HDLC、VLAN、MAC(網橋,交換機) |
| 網絡層 | 負責數據包從源到宿的傳遞和網際互連(包 Packet) | IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGRP(路由器) |
| 運輸層 | 提供端到端的可靠報文傳遞和錯誤恢複( 段Segment) | TCP、UDP、SPX |
| 會話層 | 建立、管理和終止會話(會話協議數據單元 SPDU) | NFS、SQL、NETBIOS、RPC |
| 表示層 | 對數據進行翻譯、加密和壓縮(表示協議數據單元 PPDU) | JPEG、MPEG、ASII |
| 應用層 | 允許訪問OSI環境的手段(應用協議數據單元 APDU) | FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS |
- 傳輸數據的單位 ———— 比特
- 數據傳輸系統:源系統(源點、發送器) --> 傳輸系統 --> 目的系統(接收器、終點)
通道:
- 單向通道(單工通道):只有一個方向通信,沒有反方向交互,如廣播
- 雙向交替通行(半雙工通信):通信雙方都可發消息,但不能同時發送或接收
- 雙向同時通信(全雙工通信):通信雙方可以同時發送和接收信息
通道複用技術:
- 頻分複用(FDM,Frequency Division Multiplexing):不同用戶在不同頻帶,所用用戶在同樣時間占用不同帶寬資源
- 時分複用(TDM,Time Division Multiplexing):不同用戶在同一時間段的不同時間片,所有用戶在不同時間占用同樣的頻帶寬度
- 波分複用(WDM,Wavelength Division Multiplexing):光的頻分複用
- 碼分複用(CDM,Code Division Multiplexing):不同用戶使用不同的碼,可以在同樣時間使用同樣頻帶通信
主要信道:
- 點對點信道
- 廣播信道
- 數據單元 ———— 幀
三個基本問題:
- 封裝成幀:把網絡層的 IP 數據報封裝成幀,
SOH - 數據部分 - EOT - 透明傳輸:不管數據部分什麼字符,都能傳輸出去;可以通過字節填充方法解決(沖突字符前加轉義字符)
- 差錯檢測:降低誤碼率(BER,Bit Error Rate),廣泛使用循環冗餘檢測(CRC,Cyclic Redundancy Check)
點對點協議(Point-to-Point Protocol):
- 點對點協議(Point-to-Point Protocol):用戶計算機和 ISP 通信時所使用的協議
廣播通信:
- 硬件地址(物理地址、MAC 地址)
- 單播(unicast)幀(一對一):收到的幀的 MAC 地址與本站的硬件地址相同
- 廣播(broadcast)幀(一對全體):發送給本局域網上所有站點的幀
- 多播(multicast)幀(一對多):發送給本局域網上一部分站點的幀
- IP(Internet Protocol,網際協議)是為計算機網絡相互連接進行通信而設計的協議。
- ARP(Address Resolution Protocol,地址解析協議)
- ICMP(Internet Control Message Protocol,網際控制報文協議)
- IGMP(Internet Group Management Protocol,網際組管理協議)
IP 地址分類:
IP 地址 ::= {<網絡號>,<主機號>}
| IP 地址類別 | 網絡號 | 網絡範圍 | 主機號 | IP 地址範圍 |
|---|---|---|---|---|
| A 類 | 8bit,第一位固定為 0 | 0 —— 127 | 24bit | 1.0.0.0 —— 127.255.255.255 |
| B 類 | 16bit,前兩位固定為 10 | 128.0 —— 191.255 | 16bit | 128.0.0.0 —— 191.255.255.255 |
| C 類 | 24bit,前三位固定為 110 | 192.0.0 —— 223.255.255 | 8bit | 192.0.0.0 —— 223.255.255.255 |
| D 類 | 前四位固定為 1110,後面為多播地址 | |||
| E 類 | 前五位固定為 11110,後面保留為今後所用 |
IP 數據報格式:

ICMP 報文格式:

應用:
- PING(Packet InterNet Groper,分組網間探測)測試兩個主機之間的連通性
- TTL(Time To Live,生存時間)該字段指定 IP 包被路由器丟棄之前允許通過的最大網段數量
- RIP(Routing Information Protocol,路由信息協議)
- OSPF(Open Sortest Path First,開放最短路徑優先)
- BGP(Border Gateway Protocol,邊界網關協議)
- IGMP(Internet Group Management Protocol,網際組管理協議)
- 多播路由選擇協議
- VPN(Virtual Private Network,虛擬專用網)
- NAT(Network Address Translation,網絡地址轉換)
- 網絡 ID(Network ID, Network number):就是目標地址的網絡 ID。
- 子網掩碼(subnet mask):用來判斷 IP 所屬網絡
- 下一跳地址/接口(Next hop / interface):就是數據在發送到目標地址的旅途中下一站的地址。其中 interface 指向 next hop(即為下一個 route)。一個自治系統(AS, Autonomous system)中的 route 應該包含區域內所有的子網絡,而默認網關(Network id:
0.0.0.0, Netmask:0.0.0.0)指向自治系統的出口。
根據應用和執行的不同,路由表可能含有如下附加信息:
- 花費(Cost):就是數據發送過程中通過路徑所需要的花費。
- 路由的服務質量
- 路由中需要過濾的出/入連接列表
協議:
- TCP(Transmission Control Protocol,傳輸控制協議)
- UDP(User Datagram Protocol,用戶數據報協議)
端口:
| 應用程序 | FTP | TELNET | SMTP | DNS | TFTP | HTTP | HTTPS | SNMP |
|---|---|---|---|---|---|---|---|---|
| 端口號 | 21 | 23 | 25 | 53 | 69 | 80 | 443 | 161 |
- TCP(Transmission Control Protocol,傳輸控制協議)是一種面向連接的、可靠的、基於字節流的傳輸層通信協議,其傳輸的單位是報文段。
特征:
- 面向連接
- 只能點對點(一對一)通信
- 可靠交互
- 全雙工通信
- 面向字節流
TCP 如何保證可靠傳輸:
- 確認和超時重傳
- 數據合理分片和排序
- 流量控制
- 擁塞控制
- 數據校驗
TCP 報文結構

TCP 首部

TCP:狀態控制碼(Code,Control Flag),占 6 比特,含義如下:
- URG:緊急比特(urgent),當
URG=1時,表明緊急指針字段有效,代表該封包為緊急封包。它告訴系統此報文段中有緊急數據,應盡快傳送(相當於高優先級的數據), 且上圖中的 Urgent Pointer 字段也會被啟用。 - ACK:確認比特(Acknowledge)。只有當
ACK=1時確認號字段才有效,代表這個封包為確認封包。當ACK=0時,確認號無效。 - PSH:(Push function)若為 1 時,代表要求對方立即傳送緩沖區內的其他對應封包,而無需等緩沖滿了才送。
- RST:複位比特(Reset),當
RST=1時,表明 TCP 連接中出現嚴重差錯(如由於主機崩潰或其他原因),必須釋放連接,然後再重新建立運輸連接。 - SYN:同步比特(Synchronous),SYN 置為 1,就表示這是一個連接請求或連接接受報文,通常帶有 SYN 標志的封包表示『主動』要連接到對方的意思。
- FIN:終止比特(Final),用來釋放一個連接。當
FIN=1時,表明此報文段的發送端的數據已發送完畢,並要求釋放運輸連接。
- UDP(User Datagram Protocol,用戶數據報協議)是 OSI(Open System Interconnection 開放式系統互聯) 參考模型中一種無連接的傳輸層協議,提供面向事務的簡單不可靠信息傳送服務,其傳輸的單位是用戶數據報。
特征:
- 無連接
- 盡最大努力交付
- 面向報文
- 沒有擁塞控制
- 支持一對一、一對多、多對一、多對多的交互通信
- 首部開銷小
UDP 報文結構

UDP 首部

TCP/UDP 圖片來源於:https://github.com/JerryC8080/understand-tcp-udp
- TCP 面向連接,UDP 是無連接的;
- TCP 提供可靠的服務,也就是說,通過 TCP 連接傳送的數據,無差錯,不丟失,不重複,且按序到達;UDP 盡最大努力交付,即不保證可靠交付
- TCP 的邏輯通信信道是全雙工的可靠信道;UDP 則是不可靠信道
- 每一條 TCP 連接只能是點到點的;UDP 支持一對一,一對多,多對一和多對多的交互通信
- TCP 面向字節流(可能出現黏包問題),實際上是 TCP 把數據看成一連串無結構的字節流;UDP 是面向報文的(不會出現黏包問題)
- UDP 沒有擁塞控制,因此網絡出現擁塞不會使源主機的發送速率降低(對實時應用很有用,如 IP 電話,實時視頻會議等)
- TCP 首部開銷20字節;UDP 的首部開銷小,只有 8 個字節
TCP 是一個基於字節流的傳輸服務(UDP 基於報文的),「流」 意味著 TCP 所傳輸的數據是沒有邊界的。所以可能會出現兩個數據包黏在一起的情況。
- 發送定長包。如果每個消息的大小都是一樣的,那麼在接收對等方只要累計接收數據,直到數據等於一個定長的數值就將它作為一個消息。
- 包頭加上包體長度。包頭是定長的 4 個字節,說明了包體的長度。接收對等方先接收包頭長度,依據包頭長度來接收包體。
- 在數據包之間設置邊界,如添加特殊符號
\r\n標記。FTP 協議正是這麼做的。但問題在於如果數據正文中也含有\r\n,則會誤判為消息的邊界。 - 使用更加複雜的應用層協議。
流量控制(flow control)就是讓發送方的發送速率不要太快,要讓接收方來得及接收。
利用可變窗口進行流量控制

擁塞控制就是防止過多的數據注入到網絡中,這樣可以使網絡中的路由器或鏈路不致過載。
- 慢開始( slow-start )
- 擁塞避免( congestion avoidance )
- 快重傳( fast retransmit )
- 快恢複( fast recovery )
TCP的擁塞控制圖



因為 TCP 三次握手建立連接、四次揮手釋放連接很重要,所以附上《計算機網絡(第 7 版)-謝希仁》書中對此章的詳細描述:https://github.com/huihut/interview/blob/master/images/TCP-transport-connection-management.png

【TCP 建立連接全過程解釋】
- 客戶端發送 SYN 給服務器,說明客戶端請求建立連接;
- 服務端收到客戶端發的 SYN,並回複 SYN+ACK 給客戶端(同意建立連接);
- 客戶端收到服務端的 SYN+ACK 後,回複 ACK 給服務端(表示客戶端收到了服務端發的同意報文);
- 服務端收到客戶端的 ACK,連接已建立,可以數據傳輸。
【答案一】因為信道不可靠,而 TCP 想在不可靠信道上建立可靠地傳輸,那麼三次通信是理論上的最小值。(而 UDP 則不需建立可靠傳輸,因此 UDP 不需要三次握手。)
【答案二】因為雙方都需要確認對方收到了自己發送的序列號,確認過程最少要進行三次通信。
【答案三】為了防止已失效的連接請求報文段突然又傳送到了服務端,因而產生錯誤。

【TCP 釋放連接全過程解釋】
- 客戶端發送 FIN 給服務器,說明客戶端不必發送數據給服務器了(請求釋放從客戶端到服務器的連接);
- 服務器接收到客戶端發的 FIN,並回複 ACK 給客戶端(同意釋放從客戶端到服務器的連接);
- 客戶端收到服務端回複的 ACK,此時從客戶端到服務器的連接已釋放(但服務端到客戶端的連接還未釋放,並且客戶端還可以接收數據);
- 服務端繼續發送之前沒發完的數據給客戶端;
- 服務端發送 FIN+ACK 給客戶端,說明服務端發送完了數據(請求釋放從服務端到客戶端的連接,就算沒收到客戶端的回複,過段時間也會自動釋放);
- 客戶端收到服務端的 FIN+ACK,並回複 ACK 給客戶端(同意釋放從服務端到客戶端的連接);
- 服務端收到客戶端的 ACK 後,釋放從服務端到客戶端的連接。
【問題一】TCP 為什麼要進行四次揮手? / 為什麼 TCP 建立連接需要三次,而釋放連接則需要四次?
【答案一】因為 TCP 是全雙工模式,客戶端請求關閉連接後,客戶端向服務端的連接關閉(一二次揮手),服務端繼續傳輸之前沒傳完的數據給客戶端(數據傳輸),服務端向客戶端的連接關閉(三四次揮手)。所以 TCP 釋放連接時服務器的 ACK 和 FIN 是分開發送的(中間隔著數據傳輸),而 TCP 建立連接時服務器的 ACK 和 SYN 是一起發送的(第二次握手),所以 TCP 建立連接需要三次,而釋放連接則需要四次。
【問題二】為什麼 TCP 連接時可以 ACK 和 SYN 一起發送,而釋放時則 ACK 和 FIN 分開發送呢?(ACK 和 FIN 分開是指第二次和第三次揮手)
【答案二】因為客戶端請求釋放時,服務器可能還有數據需要傳輸給客戶端,因此服務端要先響應客戶端 FIN 請求(服務端發送 ACK),然後數據傳輸,傳輸完成後,服務端再提出 FIN 請求(服務端發送 FIN);而連接時則沒有中間的數據傳輸,因此連接時可以 ACK 和 SYN 一起發送。
【問題三】為什麼客戶端釋放最後需要 TIME-WAIT 等待 2MSL 呢?
【答案三】
- 為了保證客戶端發送的最後一個 ACK 報文能夠到達服務端。若未成功到達,則服務端超時重傳 FIN+ACK 報文段,客戶端再重傳 ACK,並重新計時。
- 防止已失效的連接請求報文段出現在本連接中。TIME-WAIT 持續 2MSL 可使本連接持續的時間內所產生的所有報文段都從網絡中消失,這樣可使下次連接中不會出現舊的連接報文段。
TCP 有限狀態機圖片

- DNS(Domain Name System,域名系統)是互聯網的一項服務。它作為將域名和 IP 地址相互映射的一個分布式數據庫,能夠使人更方便地訪問互聯網。DNS 使用 TCP 和 UDP 端口 53。當前,對於每一級域名長度的限制是 63 個字符,域名總長度則不能超過 253 個字符。
域名:
域名 ::= {<三級域名>.<二級域名>.<頂級域名>},如:blog.huihut.com
- FTP(File Transfer Protocol,文件傳輸協議)是用於在網絡上進行文件傳輸的一套標准協議,使用客戶/服務器模式,使用 TCP 數據報,提供交互式訪問,雙向傳輸。
- TFTP(Trivial File Transfer Protocol,簡單文件傳輸協議)一個小且易實現的文件傳輸協議,也使用客戶-服務器方式,使用UDP數據報,只支持文件傳輸而不支持交互,沒有列目錄,不能對用戶進行身份鑒定
-
TELNET 協議是 TCP/IP 協議族中的一員,是 Internet 遠程登陸服務的標准協議和主要方式。它為用戶提供了在本地計算機上完成遠程主機工作的能力。
-
HTTP(HyperText Transfer Protocol,超文本傳輸協議)是用於從 WWW(World Wide Web,萬維網)服務器傳輸超文本到本地瀏覽器的傳送協議。
-
SMTP(Simple Mail Transfer Protocol,簡單郵件傳輸協議)是一組用於由源地址到目的地址傳送郵件的規則,由它來控制信件的中轉方式。SMTP 協議屬於 TCP/IP 協議簇,它幫助每台計算機在發送或中轉信件時找到下一個目的地。
-
Socket 建立網絡通信連接至少要一對端口號(Socket)。Socket 本質是編程接口(API),對 TCP/IP 的封裝,TCP/IP 也要提供可供程序員做網絡開發所用的接口,這就是 Socket 編程接口。
- WWW(World Wide Web,環球信息網,萬維網)是一個由許多互相鏈接的超文本組成的系統,通過互聯網訪問
- URL(Uniform Resource Locator,統一資源定位符)是因特網上標准的資源的地址(Address)
標准格式:
協議類型:[//服務器地址[:端口號]][/資源層級UNIX文件路徑]文件名[?查詢][#片段ID]
完整格式:
協議類型:[//[訪問資源需要的憑證信息@]服務器地址[:端口號]][/資源層級UNIX文件路徑]文件名[?查詢][#片段ID]
其中【訪問憑證信息@;:端口號;?查詢;#片段ID】都屬於選填項
如:https://github.com/huihut/interview#cc
HTTP(HyperText Transfer Protocol,超文本傳輸協議)是一種用於分布式、協作式和超媒體信息系統的應用層協議。HTTP 是萬維網的數據通信的基礎。
請求方法
| 方法 | 意義 |
|---|---|
| OPTIONS | 請求一些選項信息,允許客戶端查看服務器的性能 |
| GET | 請求指定的頁面信息,並返回實體主體 |
| HEAD | 類似於 get 請求,只不過返回的響應中沒有具體的內容,用於獲取報頭 |
| POST | 向指定資源提交數據進行處理請求(例如提交表單或者上傳文件)。數據被包含在請求體中。POST請求可能會導致新的資源的建立和/或已有資源的修改 |
| PUT | 從客戶端向服務器傳送的數據取代指定的文檔的內容 |
| DELETE | 請求服務器刪除指定的頁面 |
| TRACE | 回顯服務器收到的請求,主要用於測試或診斷 |
狀態碼(Status-Code)
- 1xx:表示通知信息,如請求收到了或正在進行處理
- 100 Continue:繼續,客戶端應繼續其請求
- 101 Switching Protocols 切換協議。服務器根據客戶端的請求切換協議。只能切換到更高級的協議,例如,切換到 HTTP 的新版本協議
- 2xx:表示成功,如接收或知道了
- 200 OK: 請求成功
- 3xx:表示重定向,如要完成請求還必須采取進一步的行動
- 301 Moved Permanently: 永久移動。請求的資源已被永久的移動到新 URL,返回信息會包括新的 URL,瀏覽器會自動定向到新 URL。今後任何新的請求都應使用新的 URL 代替
- 4xx:表示客戶的差錯,如請求中有錯誤的語法或不能完成
- 400 Bad Request: 客戶端請求的語法錯誤,服務器無法理解
- 401 Unauthorized: 請求要求用戶的身份認證
- 403 Forbidden: 服務器理解請求客戶端的請求,但是拒絕執行此請求(權限不夠)
- 404 Not Found: 服務器無法根據客戶端的請求找到資源(網頁)。通過此代碼,網站設計人員可設置 「您所請求的資源無法找到」 的個性頁面
- 408 Request Timeout: 服務器等待客戶端發送的請求時間過長,超時
- 5xx:表示服務器的差錯,如服務器失效無法完成請求
- 500 Internal Server Error: 服務器內部錯誤,無法完成請求
- 503 Service Unavailable: 由於超載或系統維護,服務器暫時的無法處理客戶端的請求。延時的長度可包含在服務器的 Retry-After 頭信息中
- 504 Gateway Timeout: 充當網關或代理的服務器,未及時從遠端服務器獲取請求
更多狀態碼:菜鳥教程 . HTTP狀態碼
- SMTP(Simple Main Transfer Protocol,簡單郵件傳輸協議)是在 Internet 傳輸 Email 的標准,是一個相對簡單的基於文本的協議。在其之上指定了一條消息的一個或多個接收者(在大多數情況下被確認是存在的),然後消息文本會被傳輸。可以很簡單地通過 Telnet 程序來測試一個 SMTP 服務器。SMTP 使用 TCP 端口 25。
- DHCP(Dynamic Host Configuration Protocol,動態主機設置協議)是一個局域網的網絡協議,使用 UDP 協議工作,主要有兩個用途:
- 用於內部網絡或網絡服務供應商自動分配 IP 地址給用戶
- 用於內部網絡管理員作為對所有電腦作中央管理的手段
- SNMP(Simple Network Management Protocol,簡單網絡管理協議)構成了互聯網工程工作小組(IETF,Internet Engineering Task Force)定義的 Internet 協議族的一部分。該協議能夠支持網絡管理系統,用以監測連接到網絡上的設備是否有任何引起管理上關注的情況。

ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);- read 函數是負責從 fd 中讀取內容。
- 當讀成功時,read 返回實際所讀的字節數。
- 如果返回的值是 0 表示已經讀到文件的結束了,小於 0 表示出現了錯誤。
- 如果錯誤為 EINTR 說明讀是由中斷引起的;如果是 ECONNREST 表示網絡連接出了問題。
- write 函數將 buf 中的 nbytes 字節內容寫入文件描述符 fd。
- 成功時返回寫的字節數。失敗時返回 -1,並設置 errno 變量。
- 在網絡程序中,當我們向套接字文件描述符寫時有倆種可能。
- (1)write 的返回值大於 0,表示寫了部分或者是全部的數據。
- (2)返回的值小於 0,此時出現了錯誤。
- 如果錯誤為 EINTR 表示在寫的時候出現了中斷錯誤;如果為 EPIPE 表示網絡連接出現了問題(對方已經關閉了連接)。
我們知道 TCP 建立連接要進行 「三次握手」,即交換三個分組。大致流程如下:
- 客戶端向服務器發送一個 SYN J
- 服務器向客戶端響應一個 SYN K,並對 SYN J 進行確認 ACK J+1
- 客戶端再想服務器發一個確認 ACK K+1
只有就完了三次握手,但是這個三次握手發生在 Socket 的那幾個函數中呢?請看下圖:

從圖中可以看出:
- 當客戶端調用 connect 時,觸發了連接請求,向服務器發送了 SYN J 包,這時 connect 進入阻塞狀態;
- 服務器監聽到連接請求,即收到 SYN J 包,調用 accept 函數接收請求向客戶端發送 SYN K ,ACK J+1,這時 accept 進入阻塞狀態;
- 客戶端收到服務器的 SYN K ,ACK J+1 之後,這時 connect 返回,並對 SYN K 進行確認;
- 服務器收到 ACK K+1 時,accept 返回,至此三次握手完畢,連接建立。
上面介紹了 socket 中 TCP 的三次握手建立過程,及其涉及的 socket 函數。現在我們介紹 socket 中的四次握手釋放連接的過程,請看下圖:

圖示過程如下:
- 某個應用進程首先調用 close 主動關閉連接,這時 TCP 發送一個 FIN M;
- 另一端接收到 FIN M 之後,執行被動關閉,對這個 FIN 進行確認。它的接收也作為文件結束符傳遞給應用進程,因為 FIN 的接收意味著應用進程在相應的連接上再也接收不到額外數據;
- 一段時間之後,接收到文件結束符的應用進程調用 close 關閉它的 socket。這導致它的 TCP 也發送一個 FIN N;
- 接收到這個 FIN 的源發送端 TCP 對它進行確認。
這樣每個方向上都有一個 FIN 和 ACK。
- 數據庫事務四大特性:原子性、一致性、分離性、持久性
- 數據庫索引:順序索引、B+ 樹索引、hash 索引 MySQL 索引背後的數據結構及算法原理
- SQL 約束 (Constraints)
- 第一範式(1NF):屬性(字段)是最小單位不可再分
- 第二範式(2NF):滿足 1NF,每個非主屬性完全依賴於主鍵(消除 1NF 非主屬性對碼的部分函數依賴)
- 第三範式(3NF):滿足 2NF,任何非主屬性不依賴於其他非主屬性(消除 2NF 主屬性對碼的傳遞函數依賴)
- 鮑依斯-科得範式(BCNF):滿足 3NF,任何非主屬性不能對主鍵子集依賴(消除 3NF 主屬性對碼的部分和傳遞函數依賴)
- 第四範式(4NF):滿足 3NF,屬性之間不能有非平凡且非函數依賴的多值依賴(消除 3NF 非平凡且非函數依賴的多值依賴)
各大設計模式例子參考:CSDN專欄 . C++ 設計模式 系列博文
- 單一職責原則(SRP,Single Responsibility Principle)
- 裏氏替換原則(LSP,Liskov Substitution Principle)
- 依賴倒置原則(DIP,Dependence Inversion Principle)
- 接口隔離原則(ISP,Interface Segregation Principle)
- 迪米特法則(LoD,Law of Demeter)
- 開放封閉原則(OCP,Open Close Principle)
一般應用程序內存空間有如下區域:
- 棧:由操作系統自動分配釋放,存放函數的參數值、局部變量等的值,用於維護函數調用的上下文
- 堆:一般由程序員分配釋放,若程序員不釋放,程序結束時可能由操作系統回收,用來容納應用程序動態分配的內存區域
- 可執行文件映像:存儲著可執行文件在內存中的映像,由裝載器裝載是將可執行文件的內存讀取或映射到這裏
- 保留區:保留區並不是一個單一的內存區域,而是對內存中受到保護而禁止訪問的內存區域的總稱,如通常 C 語言講無效指針賦值為 0(NULL),因此 0 地址正常情況下不可能有效的訪問數據
棧保存了一個函數調用所需要的維護信息,常被稱為堆棧幀(Stack Frame)或活動記錄(Activate Record),一般包含以下幾方面:
- 函數的返回地址和參數
- 臨時變量:包括函數的非靜態局部變量以及編譯器自動生成的其他臨時變量
- 保存上下文:包括函數調用前後需要保持不變的寄存器
堆分配算法:
- 空閑鏈表(Free List)
- 位圖(Bitmap)
- 對象池
典型的非法指針解引用造成的錯誤。當指針指向一個不允許讀寫的內存地址,而程序卻試圖利用指針來讀或寫該地址時,會出現這個錯誤。
普遍原因:
- 將指針初始化為 NULL,之後沒有給它一個合理的值就開始使用指針
- 沒用初始化棧中的指針,指針的值一般會是隨機數,之後就直接開始使用指針
| 平台 | 可執行文件 | 目標文件 | 動態庫/共享對象 | 靜態庫 |
|---|---|---|---|---|
| Windows | exe | obj | dll | lib |
| Unix/Linux | ELF、out | o | so | a |
| Mac | Mach-O | o | dylib、tbd、framework | a、framework |
- 預編譯(預編譯器處理如
#include、#define等預編譯指令,生成.i或.ii文件) - 編譯(編譯器進行詞法分析、語法分析、語義分析、中間代碼生成、目標代碼生成、優化,生成
.s文件) - 彙編(彙編器把彙編碼翻譯成機器碼,生成
.o文件) - 鏈接(連接器進行地址和空間分配、符號決議、重定位,生成
.out文件)
現在版本 GCC 把預編譯和編譯合成一步,預編譯編譯程序 cc1、彙編器 as、連接器 ld
MSVC 編譯環境,編譯器 cl、連接器 link、可執行文件查看器 dumpbin
編譯器編譯源代碼後生成的文件叫做目標文件。目標文件從結構上講,它是已經編譯後的可執行文件格式,只是還沒有經過鏈接的過程,其中可能有些符號或有些地址還沒有被調整。
可執行文件(Windows 的
.exe和 Linux 的ELF)、動態鏈接庫(Windows 的.dll和 Linux 的.so)、靜態鏈接庫(Windows 的.lib和 Linux 的.a)都是按照可執行文件格式存儲(Windows 按照 PE-COFF,Linux 按照 ELF)
- Windows 的 PE(Portable Executable),或稱為 PE-COFF,
.obj格式 - Linux 的 ELF(Executable Linkable Format),
.o格式 - Intel/Microsoft 的 OMF(Object Module Format)
- Unix 的
a.out格式 - MS-DOS 的
.COM格式
PE 和 ELF 都是 COFF(Common File Format)的變種
| 段 | 功能 |
|---|---|
| File Header | 文件頭,描述整個文件的文件屬性(包括文件是否可執行、是靜態鏈接或動態連接及入口地址、目標硬件、目標操作系統等) |
| .text section | 代碼段,執行語句編譯成的機器代碼 |
| .data section | 數據段,已初始化的全局變量和局部靜態變量 |
| .bss section | BSS 段(Block Started by Symbol),未初始化的全局變量和局部靜態變量(因為默認值為 0,所以只是在此預留位置,不占空間) |
| .rodata section | 只讀數據段,存放只讀數據,一般是程序裏面的只讀變量(如 const 修飾的變量)和字符串常量 |
| .comment section | 注釋信息段,存放編譯器版本信息 |
| .note.GNU-stack section | 堆棧提示段 |
其他段略
在鏈接中,目標文件之間相互拼合實際上是目標文件之間對地址的引用,即對函數和變量的地址的引用。我們將函數和變量統稱為符號(Symbol),函數名或變量名就是符號名(Symbol Name)。
如下符號表(Symbol Table):
| Symbol(符號名) | Symbol Value (地址) |
|---|---|
| main | 0x100 |
| Add | 0x123 |
| ... | ... |
Linux 下的共享庫就是普通的 ELF 共享對象。
共享庫版本更新應該保證二進制接口 ABI(Application Binary Interface)的兼容
libname.so.x.y.z
- x:主版本號,不同主版本號的庫之間不兼容,需要重新編譯
- y:次版本號,高版本號向後兼容低版本號
- z:發布版本號,不對接口進行更改,完全兼容
大部分包括 Linux 在內的開源系統遵循 FHS(File Hierarchy Standard)的標准,這標准規定了系統文件如何存放,包括各個目錄結構、組織和作用。
/lib:存放系統最關鍵和最基礎的共享庫,如動態鏈接器、C 語言運行庫、數學庫等/usr/lib:存放非系統運行時所需要的關鍵性的庫,主要是開發庫/usr/local/lib:存放跟操作系統本身並不十分相關的庫,主要是一些第三方應用程序的庫
動態鏈接器會在
/lib、/usr/lib和由/etc/ld.so.conf配置文件指定的,目錄中查找共享庫
LD_LIBRARY_PATH:臨時改變某個應用程序的共享庫查找路徑,而不會影響其他應用程序LD_PRELOAD:指定預先裝載的一些共享庫甚至是目標文件LD_DEBUG:打開動態鏈接器的調試功能
使用 CLion 編寫共享庫
創建一個名為 MySharedLib 的共享庫
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(MySharedLib)
set(CMAKE_CXX_STANDARD 11)
add_library(MySharedLib SHARED library.cpp library.h)library.h
#ifndef MYSHAREDLIB_LIBRARY_H
#define MYSHAREDLIB_LIBRARY_H
// 打印 Hello World!
void hello();
// 使用可變模版參數求和
template <typename T>
T sum(T t)
{
return t;
}
template <typename T, typename ...Types>
T sum(T first, Types ... rest)
{
return first + sum<T>(rest...);
}
#endiflibrary.cpp
#include <iostream>
#include "library.h"
void hello() {
std::cout << "Hello, World!" << std::endl;
}使用 CLion 調用共享庫
創建一個名為 TestSharedLib 的可執行項目
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(TestSharedLib)
# C++11 編譯
set(CMAKE_CXX_STANDARD 11)
# 頭文件路徑
set(INC_DIR /home/xx/code/clion/MySharedLib)
# 庫文件路徑
set(LIB_DIR /home/xx/code/clion/MySharedLib/cmake-build-debug)
include_directories(${INC_DIR})
link_directories(${LIB_DIR})
link_libraries(MySharedLib)
add_executable(TestSharedLib main.cpp)
# 鏈接 MySharedLib 庫
target_link_libraries(TestSharedLib MySharedLib)main.cpp
#include <iostream>
#include "library.h"
using std::cout;
using std::endl;
int main() {
hello();
cout << "1 + 2 = " << sum(1,2) << endl;
cout << "1 + 2 + 3 = " << sum(1,2,3) << endl;
return 0;
}執行結果
Hello, World!
1 + 2 = 3
1 + 2 + 3 = 6
- GUI(Graphical User Interface)應用,鏈接器選項:
/SUBSYSTEM:WINDOWS - CUI(Console User Interface)應用,鏈接器選項:
/SUBSYSTEM:CONSOLE
_tWinMain 與 _tmain 函數聲明
Int WINAPI _tWinMain(
HINSTANCE hInstanceExe,
HINSTANCE,
PTSTR pszCmdLine,
int nCmdShow);
int _tmain(
int argc,
TCHAR *argv[],
TCHAR *envp[]);| 應用程序類型 | 入口點函數 | 嵌入可執行文件的啟動函數 |
|---|---|---|
| 處理ANSI字符(串)的GUI應用程序 | _tWinMain(WinMain) | WinMainCRTSartup |
| 處理Unicode字符(串)的GUI應用程序 | _tWinMain(wWinMain) | wWinMainCRTSartup |
| 處理ANSI字符(串)的CUI應用程序 | _tmain(Main) | mainCRTSartup |
| 處理Unicode字符(串)的CUI應用程序 | _tmain(wMain) | wmainCRTSartup |
| 動態鏈接庫(Dynamic-Link Library) | DllMain | _DllMainCRTStartup |
知識點來自《Windows核心編程(第五版)》
- 擴展了應用程序的特性
- 簡化了項目管理
- 有助於節省內存
- 促進了資源的共享
- 促進了本地化
- 有助於解決平台間的差異
- 可以用於特殊目的
- 創建 DLL,事實上是在創建可供一個可執行模塊調用的函數
- 當一個模塊提供一個內存分配函數(malloc、new)的時候,它必須同時提供另一個內存釋放函數(free、delete)
- 在使用 C 和 C++ 混編的時候,要使用 extern "C" 修飾符
- 一個 DLL 可以導出函數、變量(避免導出)、C++ 類(導出導入需要同編譯器,否則避免導出)
- DLL 模塊:cpp 文件中的 __declspec(dllexport) 寫在 include 頭文件之前
- 調用 DLL 的可執行模塊:cpp 文件的 __declspec(dllimport) 之前不應該定義 MYLIBAPI
- 包含可執行文件的目錄
- Windows 的系統目錄,可以通過 GetSystemDirectory 得到
- 16 位的系統目錄,即 Windows 目錄中的 System 子目錄
- Windows 目錄,可以通過 GetWindowsDirectory 得到
- 進程的當前目錄
- PATH 環境變量中所列出的目錄
DllMain 函數
BOOL WINAPI DllMain(HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
switch(fdwReason)
{
case DLL_PROCESS_ATTACH:
// 第一次將一個DLL映射到進程地址空間時調用
// The DLL is being mapped into the process' address space.
break;
case DLL_THREAD_ATTACH:
// 當進程創建一個線程的時候,用於告訴DLL執行與線程相關的初始化(非主線程執行)
// A thread is bing created.
break;
case DLL_THREAD_DETACH:
// 系統調用 ExitThread 線程退出前,即將終止的線程通過告訴DLL執行與線程相關的清理
// A thread is exiting cleanly.
break;
case DLL_PROCESS_DETACH:
// 將一個DLL從進程的地址空間時調用
// The DLL is being unmapped from the process' address space.
break;
}
return (TRUE); // Used only for DLL_PROCESS_ATTACH
}LoadLibrary、LoadLibraryExA、LoadPackagedLibrary、FreeLibrary、FreeLibraryAndExitThread 函數聲明
// 載入庫
HMODULE WINAPI LoadLibrary(
_In_ LPCTSTR lpFileName
);
HMODULE LoadLibraryExA(
LPCSTR lpLibFileName,
HANDLE hFile,
DWORD dwFlags
);
// 若要在通用 Windows 平台(UWP)應用中加載 Win32 DLL,需要調用 LoadPackagedLibrary,而不是 LoadLibrary 或 LoadLibraryEx
HMODULE LoadPackagedLibrary(
LPCWSTR lpwLibFileName,
DWORD Reserved
);
// 卸載庫
BOOL WINAPI FreeLibrary(
_In_ HMODULE hModule
);
// 卸載庫和退出線程
VOID WINAPI FreeLibraryAndExitThread(
_In_ HMODULE hModule,
_In_ DWORD dwExitCode
);GetProcAddress 函數聲明
FARPROC GetProcAddress(
HMODULE hInstDll,
PCSTR pszSymbolName // 只能接受 ANSI 字符串,不能是 Unicode
);在 VS 的開發人員命令提示符 使用 DumpBin.exe 可查看 DLL 庫的導出段(導出的變量、函數、類名的符號)、相對虛擬地址(RVA,relative virtual address)。如:
DUMPBIN -exports D:\mydll.dll


{kind=link}
DLL 庫的編寫(導出一個 DLL 模塊)
DLL 頭文件// MyLib.h
#ifdef MYLIBAPI
// MYLIBAPI 應該在全部 DLL 源文件的 include "Mylib.h" 之前被定義
// 全部函數/變量正在被導出
#else
// 這個頭文件被一個exe源代碼模塊包含,意味著全部函數/變量被導入
#define MYLIBAPI extern "C" __declspec(dllimport)
#endif
// 這裏定義任何的數據結構和符號
// 定義導出的變量(避免導出變量)
MYLIBAPI int g_nResult;
// 定義導出函數原型
MYLIBAPI int Add(int nLeft, int nRight);DLL 源文件
// MyLibFile1.cpp
// 包含標准Windows和C運行時頭文件
#include <windows.h>
// DLL源碼文件導出的函數和變量
#define MYLIBAPI extern "C" __declspec(dllexport)
// 包含導出的數據結構、符號、函數、變量
#include "MyLib.h"
// 將此DLL源代碼文件的代碼放在此處
int g_nResult;
int Add(int nLeft, int nRight)
{
g_nResult = nLeft + nRight;
return g_nResult;
}DLL 庫的使用(運行時動態鏈接 DLL)
// A simple program that uses LoadLibrary and
// GetProcAddress to access myPuts from Myputs.dll.
#include <windows.h>
#include <stdio.h>
typedef int (__cdecl *MYPROC)(LPWSTR);
int main( void )
{
HINSTANCE hinstLib;
MYPROC ProcAdd;
BOOL fFreeResult, fRunTimeLinkSuccess = FALSE;
// Get a handle to the DLL module.
hinstLib = LoadLibrary(TEXT("MyPuts.dll"));
// If the handle is valid, try to get the function address.
if (hinstLib != NULL)
{
ProcAdd = (MYPROC) GetProcAddress(hinstLib, "myPuts");
// If the function address is valid, call the function.
if (NULL != ProcAdd)
{
fRunTimeLinkSuccess = TRUE;
(ProcAdd) (L"Message sent to the DLL function\n");
}
// Free the DLL module.
fFreeResult = FreeLibrary(hinstLib);
}
// If unable to call the DLL function, use an alternative.
if (! fRunTimeLinkSuccess)
printf("Message printed from executable\n");
return 0;
}- 操作系統創建進程,把控制權交給程序的入口(往往是運行庫中的某個入口函數)
- 入口函數對運行庫和程序運行環境進行初始化(包括堆、I/O、線程、全局變量構造等等)。
- 入口函數初始化後,調用 main 函數,正式開始執行程序主體部分。
- main 函數執行完畢後,返回到入口函數進行清理工作(包括全局變量析構、堆銷毀、關閉I/O等),然後進行系統調用結束進程。
一個程序的 I/O 指代程序與外界的交互,包括文件、管程、網絡、命令行、信號等。更廣義地講,I/O 指代操作系統理解為 「文件」 的事物。
_start -> __libc_start_main -> exit -> _exit
其中 main(argc, argv, __environ) 函數在 __libc_start_main 裏執行。
int mainCRTStartup(void)
執行如下操作:
- 初始化和 OS 版本有關的全局變量。
- 初始化堆。
- 初始化 I/O。
- 獲取命令行參數和環境變量。
- 初始化 C 庫的一些數據。
- 調用 main 並記錄返回值。
- 檢查錯誤並將 main 的返回值返回。
大致包含如下功能:
- 啟動與退出:包括入口函數及入口函數所依賴的其他函數等。
- 標准函數:有 C 語言標准規定的C語言標准庫所擁有的函數實現。
- I/O:I/O 功能的封裝和實現。
- 堆:堆的封裝和實現。
- 語言實現:語言中一些特殊功能的實現。
- 調試:實現調試功能的代碼。
包含:
- 標准輸入輸出(stdio.h)
- 文件操作(stdio.h)
- 字符操作(ctype.h)
- 字符串操作(string.h)
- 數學函數(math.h)
- 資源管理(stdlib.h)
- 格式轉換(stdlib.h)
- 時間/日期(time.h)
- 斷言(assert.h)
- 各種類型上的常數(limits.h & float.h)
- 變長參數(stdarg.h)
- 非局部跳轉(setjmp.h)
- 《C++ Primer》
- 《Effective C++》
- 《More Effective C++》
- 《深度探索 C++ 對象模型》
- 《深入理解 C++11》
- 《STL 源碼剖析》
- 《劍指 Offer》
- 《編程珠璣》
- 《程序員面試寶典》
- 《深入理解計算機系統》
- 《Windows 核心編程》
- 《Unix 環境高級編程》
- 《Unix 網絡編程》
- 《TCP/IP 詳解》
- 《程序員的自我修養》