
💻 🛳 🚀
Code. Ship. Scale.
Flyte is a workflow automation platform for complex, mission-critical data, and ML processes at scale

![]()
![]()





Home Page
·
Quickstart
·
Documentation
·
Live Roadmap
·
Changelogs
·
Components
Support:
Slack,
Twitter &
Discussions
Flyte is a structured programming and distributed processing platform that enables highly concurrent, scalable, and maintainable workflows for Machine Learning and Data Processing. It is a fabric that connects disparate computation backends using a type-safe data dependency graph. It records all changes to a pipeline, making it possible to rewind time. It also stores
a history of all executions and provides an intuitive UI, CLI, and REST/gRPC API to interact with the computation.
Flyte is more than a workflow engine -- it uses workflow as a core concept, and task (a single unit of execution) as a top-level concept. Multiple tasks arranged in a data
producer-consumer order creates a workflow.
Workflows and Tasks can be written in any language, with out-of-the-box support for Python, Java and Scala.
Flyte was designed to manage the complexity that arises in Data and ML teams and ensure they keep up their high velocity of delivering business impacting features. One way it achieves this is by separating
the control-plane from the user-plane. Thus, every organization can offer Flyte as a service to their end-users where the service is managed by folks who are more infrastructure-focused, while the users use the intuitive interface of Flytekit.
- Kubernetes-native workflow automation platform
- Ergonomic SDKs in Python, Java, and Scala
- Versioned, auditable, and reproducible pipelines
- Data-aware and strongly-typed
- Resource-aware and deployments at scale
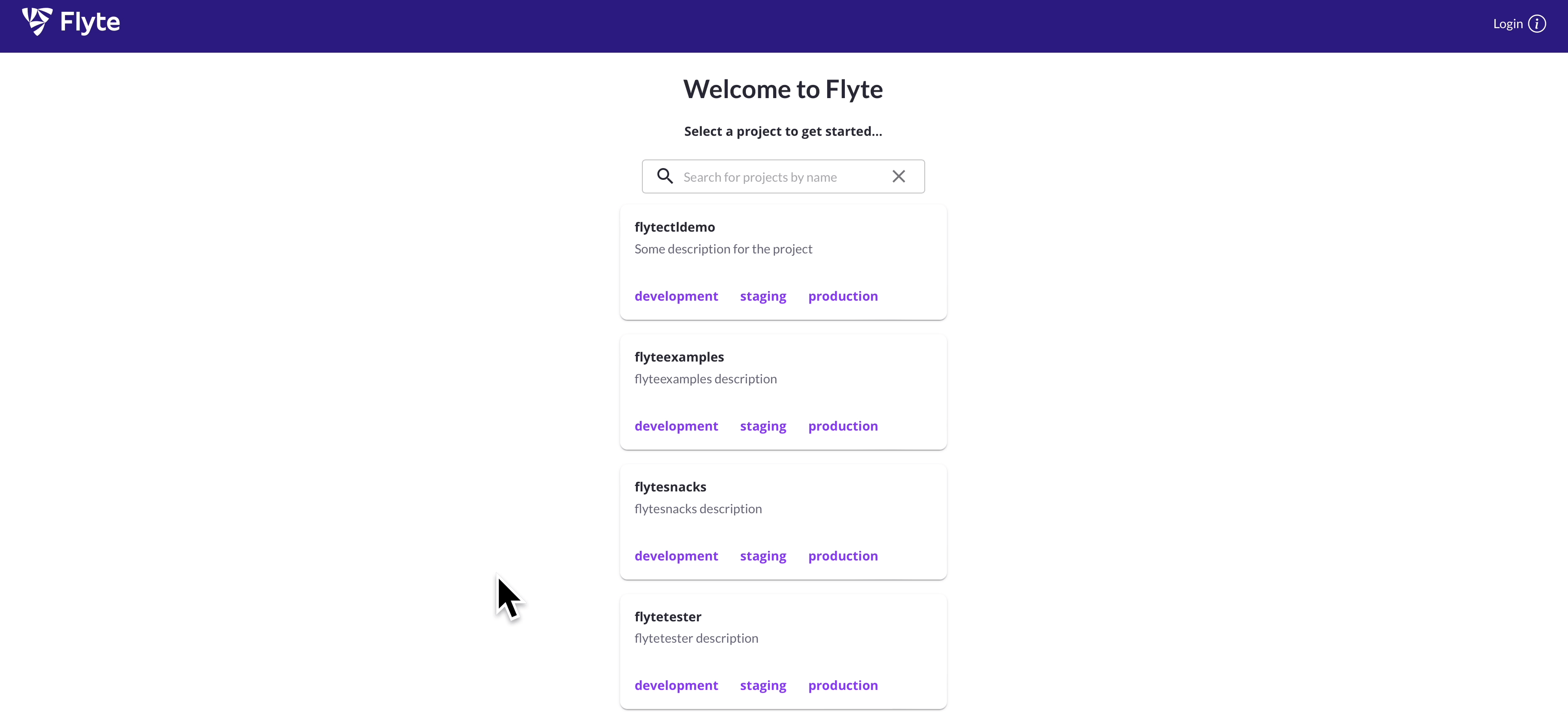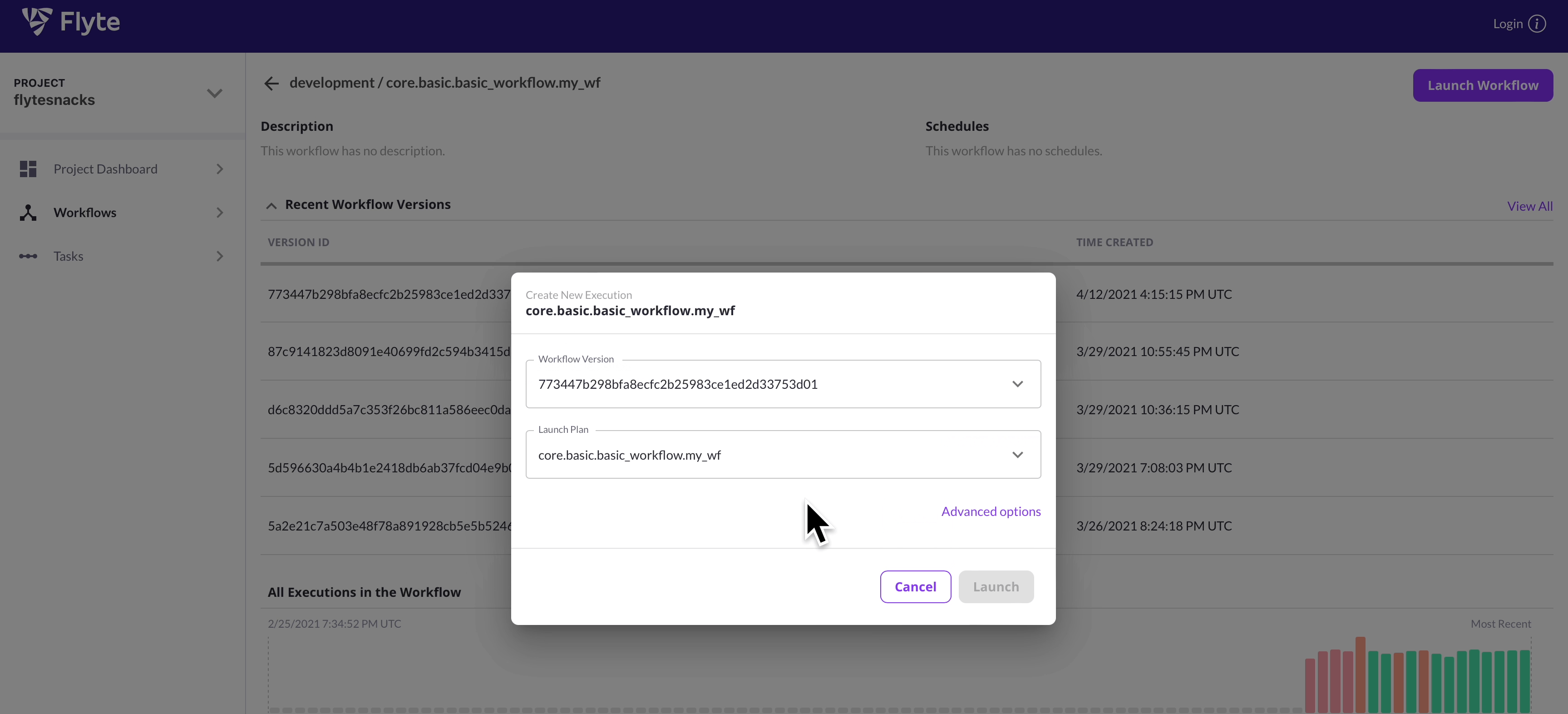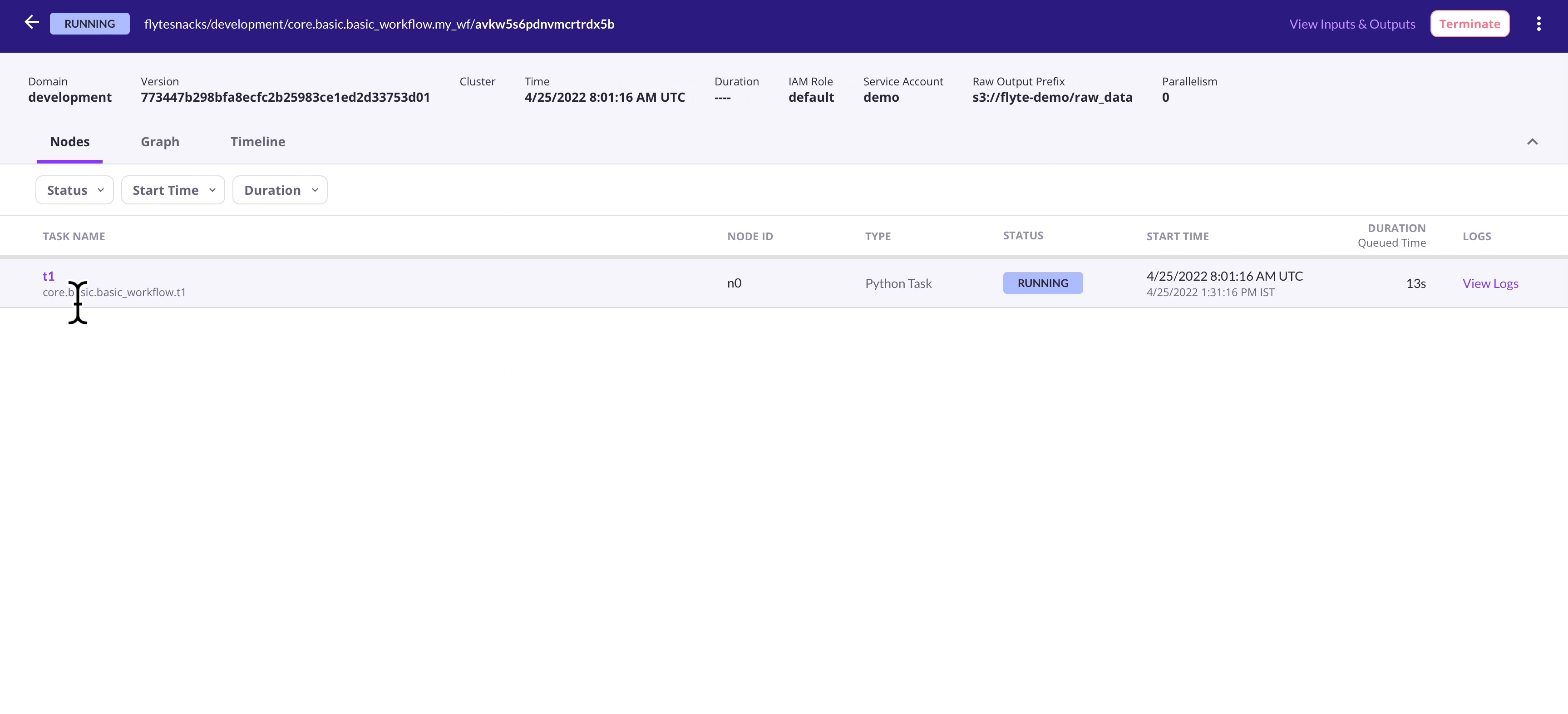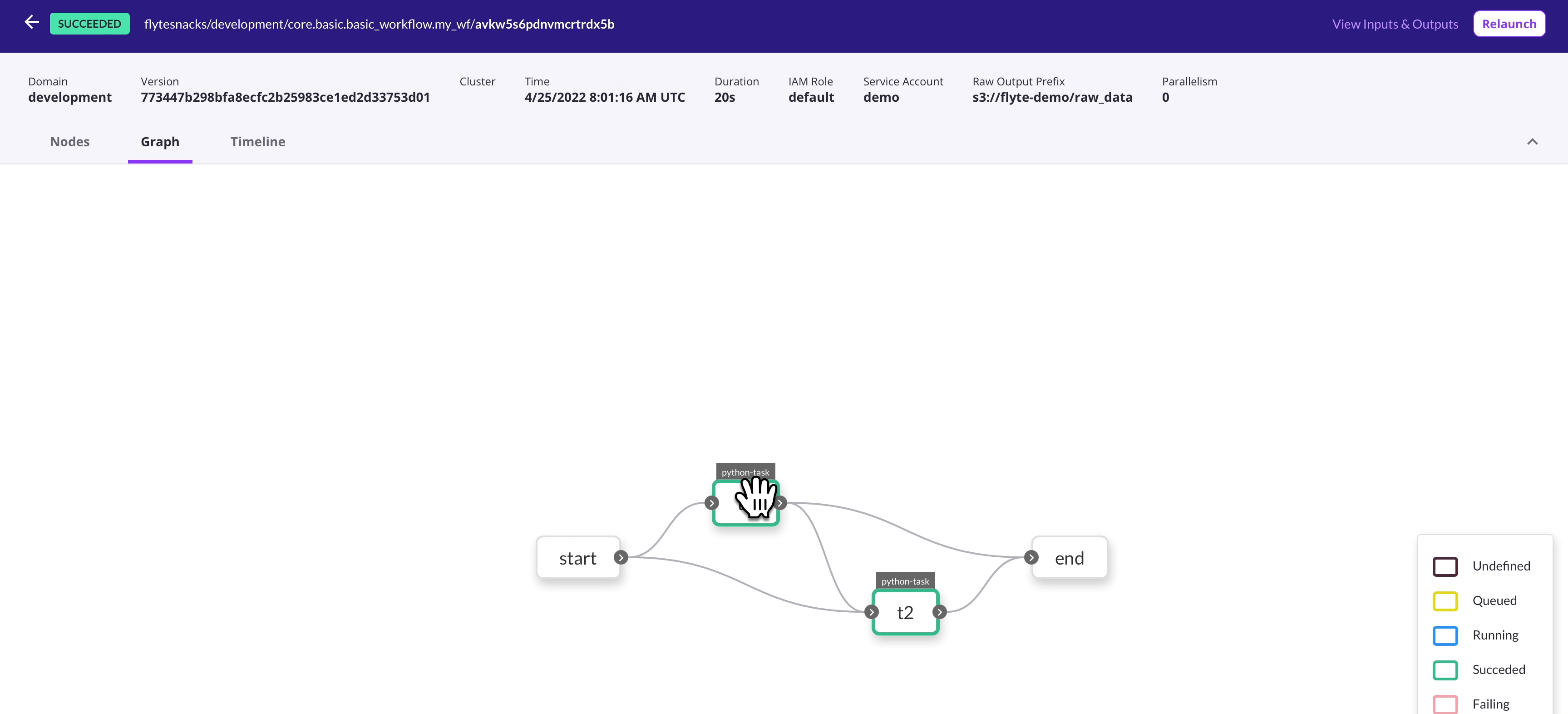 |
|---|
| ✨ Flyte UI ✨ |
- appliedAI Initiative
- Blackshark.ai
- Freenome
- Gojek
- Intel
- LatchBio
- Level 5 Global Autonomous (Woven Planet)
- Lyft
- MethaneSAT
- Pachama
- RunX.dev
- Spotify
- Striveworks
- Union.ai
- USU Group
- Wolt
Live roadmap for the project can be found @Github Live Roadmap.
- Used at Scale in production by 500+ on one deployment. Used in production at multiple firms. Proved to scale to more than 1 million executions, and 40+ million containers
- Data Aware and Resource Aware (Allows organizations to separate concerns - users can use the API, platforms/infra teams can manage the deployments and scaling)
- Enables collaboration across your organization by:
- Executing distributed data pipelines/workflows
- Making it easy to stitch together workflows from different teams and domain experts and share them across teams
- Comparing results of training workflows over time and across pipelines
- Simplifying the complexity of multi-step, multi-owner workflows
- Get Started quickly -- start locally and scale to the cloud instantly
- gRPC / REST interface to define and execute tasks and workflows
- Typesafe construction of pipelines -- each task has an interface characterized by its input and output, so illegal construction of pipelines fails during declaration, rather than at runtime
- Supports multiple data types for machine learning and data processing pipelines, such as Blobs (images, arbitrary files), Directories, Schema (columnar structured data), collections, maps, etc.
- Memoization and Lineage tracking
- Provides logging and observability
- Workflow features:
- Start with one task, convert to a pipeline, attach multiple schedules, trigger using a programmatic API, or on-demand
- Parallel step execution
- Extensible backend to add customized plugin experience (with simplified user experience)
- Branching
- Workflow of workflows - subworkflows (a workflow can be embedded within one node of the top-level workflow)
- Distributed remote external workflows (a remote workflow can be triggered and statically verified at compile time)
- Array Tasks (map a function over a large dataset -- ensures controlled execution of thousands of containers)
- Dynamic workflows creation and execution with runtime type safety
- Flytekit plugins with first-class support in Python
- Arbitrary Flytekit-less containers tasks (RawContainer)
- Guaranteed reproducibility of pipelines via:
- Multi-cloud support (AWS, GCP, and others)
- No single point of failure, and is resilient by design
- Automated notifications to Slack, Email, and Pagerduty
- Multi K8s cluster support
- Out of the box support to run Spark jobs on K8s, Hive queries, etc.
- Snappy Console & Golang CLI (Flytectl)
- Written in Golang and optimized for jobs that run for a long period of time.
- Grafana templates (user/system observability)
- Deploy with Helm and Kustomize
- Containers
- K8s Pods
- AWS Batch ArrayJobs
- K8s Pod Arrays
- K8s Spark (native Pyspark and Java/Scala)
- AWS Athena
- Qubole Hive
- Presto Queries
- Distributed Pytorch (K8s Native) -- Pytorch Operator
- Sagemaker (builtin algorithms & custom models)
- Distributed Tensorflow (K8s Native)
- Papermill notebook execution (Python and Spark)
- Type safe and data checking for Pandas dataframe using Pandera
- Versioned datastores using DoltHub and Dolt
- Use SQLAlchemy to query any relational database
- Build your own plugins that use library containers
- Snowflake queries
| Repo | Language | Purpose | Status |
|---|---|---|---|
| flyte | Kustomize,RST | deployment, documentation, issues | Production-grade |
| flyteidl | Protobuf | gRPC/REST API, Workflow language spec | Production-grade |
| flytepropeller | Go | execution engine | Production-grade |
| flyteadmin | Go | control plane | Production-grade |
| flytekit | Python | python SDK and tools | Production-grade |
| flyteconsole | Typescript | Flyte UI | Production-grade |
| datacatalog | Go | manage input & output artifacts | Production-grade |
| flyteplugins | Go | Flyte Backend plugins | Production-grade |
| flytecopilot | Go | Sidecar to manage input/output for sdk-less | Production-grade |
| flytestdlib | Go | standard library | Production-grade |
| flytesnacks | Python | examples, tips, and tricks | Maintained |
| flytekit-java | Java/Scala | Java & scala SDK for authoring Flyte workflows | Incubating |
| flytectl | Go | A standalone Flyte CLI | Production-grade |
| homebrew-tap | Ruby | Tap for downloadable flyte tools (cli etc) | Production-grade |
| bazel-rules | skylark/py | Use Bazel to build Flyte workflows and tasks | Incubating |
We run a suite of tests to ensure that basic functionality and a subset of the integrations work across a variety of release versions. Those tests are run in a cluster where specific versions of the Flyte components (such as flyteconsole, flyteadmin, datacatalog, and flytepropeller) are installed, including the released versions and also the latest versions in the case of the nighly runs.
The table below has different release versions as the columns and the result of each test suite as rows:
| workflow group | nightly | v1.0.1 | v1.0.0 | v0.19.4 |
|---|---|---|---|---|
| core | ||||
| integrations-hive | ||||
| integrations-k8s-spark | ||||
| integrations-kfpytorch | ||||
| integrations-pod | ||||
| integrations-pandera_examples | ||||
| integrations-papermilltasks | ||||
| integrations-greatexpectations | ||||
| integrations-sagemaker-pytorch | ||||
| integrations-sagemaker-training |
Flyte is a community-driven and community-owned software. It is managed using a steering committee and encourages collaboration. The community has a long roadmap for Flyte, but there might be interesting ideas, extensions, or additions that you may want to propose. This is usually done by starting with:
- Github Issue: we maintain issues for all repos in the main flyte repo.
- Writing down your proposal using a documented RFC process.
RFCs are encouraged for larger changes. You are welcome to hop into our Slack and talk to the community if you want to test the waters before proposing.
Here are some resources to help you learn more about Flyte.
- 📣 Flyte OSS Community Sync Every other Tuesday, 9:00 am - 10:00 am PT. Check out the calendar, and register to stay up-to-date with our meeting times. Or join us on Zoom.
- Upcoming meeting agenda, previous meeting notes, and a backlog of topics are captured in this document.
- If you'd like to revisit any previous community sync meetings, you can access the video recordings on Flyte's YouTube channel.
Ask us anything Flyte, Weekly on Wednesdays:
- Red Eye Flyte: 7:00-7:30 am PT (Invite and Zoom Link)
- Mid-Day Office Hours: 1:30-2:00 pm PT (Invite and Zoom Link)
- Late Night MLOps: 9:00-9:30 pm PT (Invite and Zoom link)
Find answers to the FAQs at Knowledge Base: our minified StackOverflow and magnified Slack.
SandraGH5-playlist Videos and recordings can be found on Flyte's YouTube channel under the Conference Talks and Podcasts playlist.
2019
- Kubecon 2019 - Flyte: Cloud Native Machine Learning and Data Processing Platform video | deck
- Kubecon 2019 - Running LargeScale Stateful workloads on Kubernetes at Lyft video
- re:invent 2019 - Implementing ML workflows with Kubernetes and Amazon Sagemaker video
- Cloud-native machine learning at Lyft with AWS Batch and Amazon EKS video
2020
- OSS + ELC NA 2020 splash
- Datacouncil video | splash
- FB AI@Scale Making MLOps & DataOps a reality
- GAIC 2020
2021
- OSPOCon 2021:
- Building and Growing an Open Source Community for an Incubating Project video
- Enforcing Data Quality in Data Processing and ML Pipelines with Flyte and Pandera video
- Self-serve Feature Engineering Platform Using Flyte and Feast video
- Efficient Data Parallel Distributed Training with Flyte, Spark & Horovod video
- KubeCon+CloudNativeCon North America 2021 - How Spotify Leverages Flyte To Coordinate Financial Analytics Company-Wide session
- PyData Global 2021 - Robust, End-to-end Online Machine Learning Applications with Flytekit, Pandera and Streamlit video
- ODSC West Reconnect - Deep Dive Into Flyte workshop
2022
- DataCouncil Austin - Type-Safe Data Processing and Machine Learning Pipelines with Flyte and Pandera video
- Data @Scale Spring 2022 - Making Data Quality an integral part of developing Machine Learning and Data Products video
- KCD Chennai 2022 - MLOps with Flyte: Remove the Barriers to Successfully Implement Machine Learning for Production Workloads video
- Scipy 2022 - Reliable, Reproducible, Recoverable & Auditable Machine Learning for Production Workloads with Flyte video
- MLOps Coffee Session - Why You Need More Than Airflow
- Kelsey Hightower Twitter Space - Machine Learning in Production
- Contributor.fyi - Flyte with Ketan Umare
- TWIML&AI - Scalable and Maintainable ML Workflows at Lyft - Flyte
- Software Engineering Daily - Flyte: Lyft Data Processing Platform
- MLOps Coffee session - Flyte: an open-source tool for scalable, extensible, and portable workflows
- Open Data Science - West Warm Up session with Ketan Umare - Creator of Flyte
A big thank you to the community for making Flyte possible!


























































































































































































































































