This tool provides functionality to automatically read pdf's that were previously created without text recognition, extract the text and pass this data to the actions that will process the data that.
Framework:
Server:
Clone the project
git clone https://github.com/generalsle1n/OCROperatorGo to the project directory
cd OCROperator\OCROperatorInstall dependencies
dotnet restoreStart the server
dotnet runPublish the project with the following settings
- Config:
Release - TargetFramework:
.Net 6 - Deployment:
SelfContained - Singlefile:
false - ReadyToRun:
false - Remove not used Code:
false
sc.exe create "OCROperator" binpath="C:\Path\To\OCROperator.exe"- Add an Microsoft Busines Central Action
- Add more watchers (Database, Mailbox, eg.)
Used mostly Interfaces to allowes multiple classes that can define actions over an user controlled config file
If you have any feedback, please open an issue or an pull request 😀
This tool searchs asynchron for pdf and metadata that are specifid in an watcher config. If the tool finds some the tools process the pdf with the ocr enginge tesseract to get the text and then the file with the text is transferd to an action which can do any stuff with the pdf (Upload to an ticketsystem, erp, crm or so on) Currently it only works in connection with papercut mf, because papercut generate an metadata json which is processed
Currently there is only one Watcher implemented:
This watchers looks in an folder for the pdf
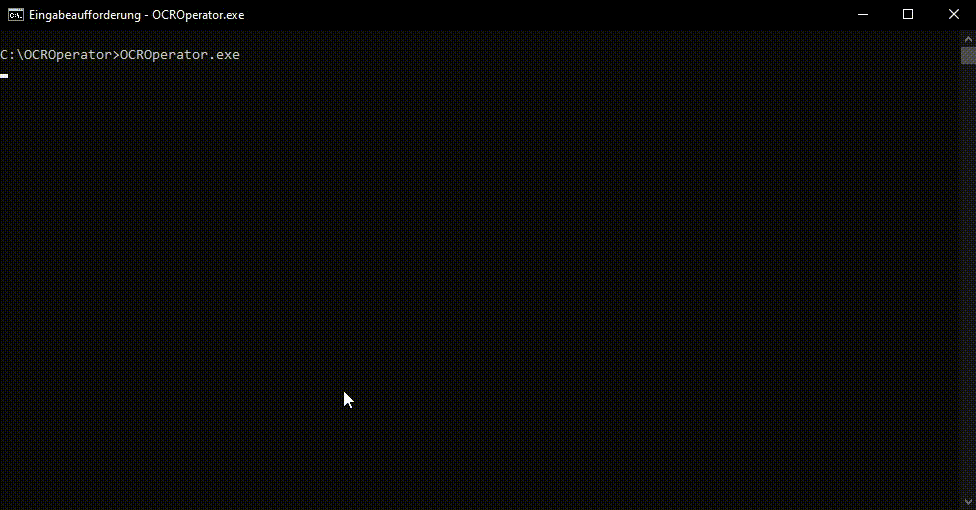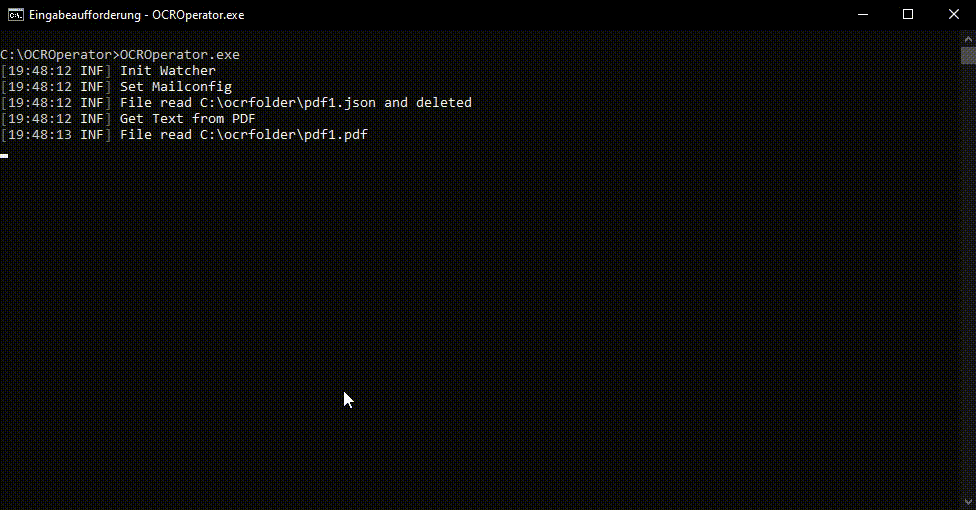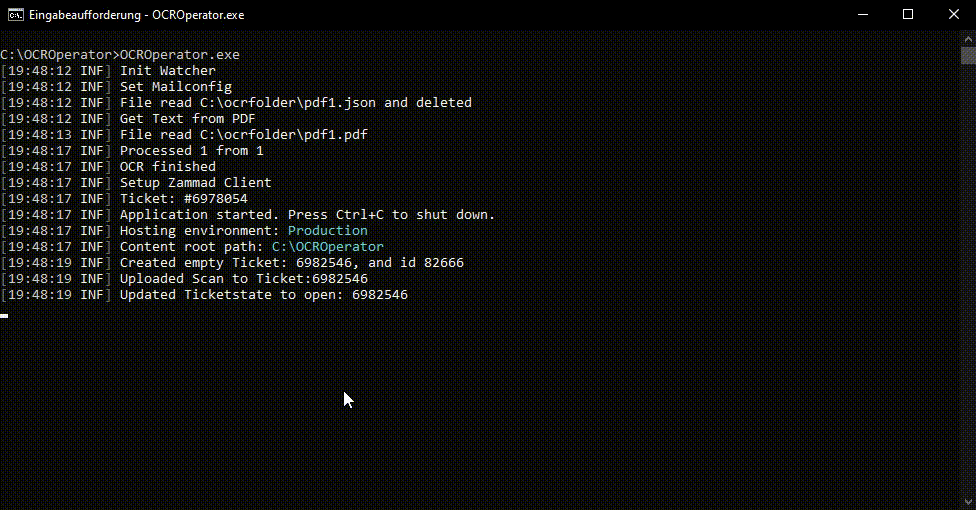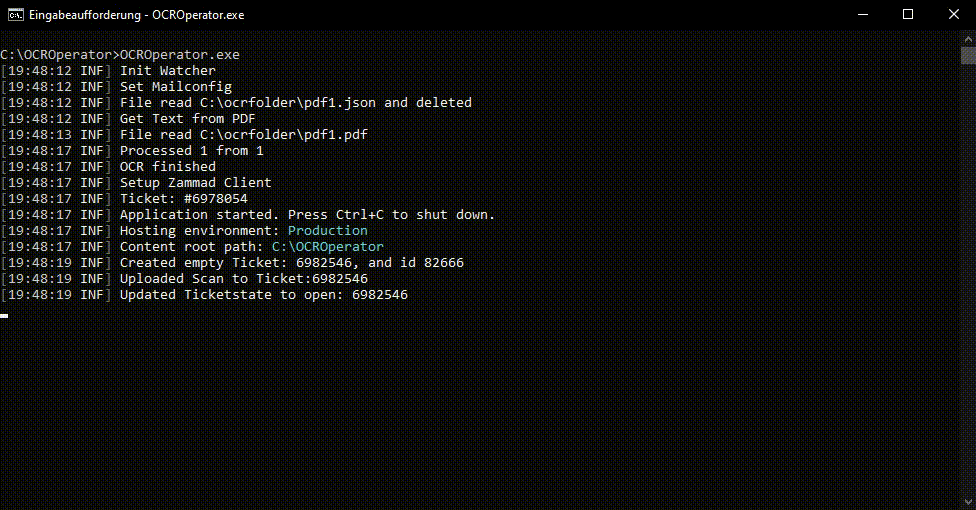
This action trys to extract an ticketnumber and then upload the pdf to this ticket. If no ticket is found then it create an empty ticket
The setting is splitted by an ;
- Zammad URL
- API Token
- UserID (In the example the 1)
So the string must look like: https://zammadserver.com;SECRET;1
This actions send the extracted text to the user mail that is specifid in the metadata json from papercut. The mail settings are specifid via the mailfactory solution
Yeah sure --> If you think its good and create an pull request to merge it
Currently its not planned, but if you want to implement it just open an pull request too
To run this project, you will need to add the following config variables to your appsettings.json file. All important settings are in "Watchers" There is an example config in the repo
Destination: The Path where the watcher should look to get the pdf string
SuffixMetadata: The suffix pattern to look for the metadata string
ActionType: The binary Type for the action, possible values: string
- OCROperator.Models.Interface.Action.FileToFixedEmail
- OCROperator.Models.Interface.Action.FileToUserEmail
- OCROperator.Models.Interface.Action.FileToZammad
ActionSettings: Enter the custom settings for the action int
Type: The binary Type for the watcher , possible values: string
- OCROperator.Models.Interface.FileSystem
Language: Enter the OCR Langaue, possible values: string
- deu (German)
- eng (English)
- spa (spanish)
HoldPDF: Decide if the pdf after the process is fisnihed should be hold and not deleted bool
SMTPServer: Enter the name of the smtp server which should be used
Port: Enter the port for the smtp server
GenerateFrom: The from mail, which should be used
- Main PDF Processing Framework: iText7
- Main PDF Processing Framework: iText7 PDF2Image
- Logging Framework: Serilog
- Logging Framework: Serilog Hosting Extension
- Logging Framework: Serilog Console Extension
- Logging Framework: Serilog File Extension
- OCR Engine: Tesseract
- OCR Engine: Tesseract Wrapper
- Zammad API Wrapper