Have you ever tried to look for a visa sponsor job vacancy? Or looking for a job overall nowadays is a little bit overwhelming because of the number of different places you have to go to find a list of vacancies.
This project goals is to unify and provide a simple normalized and unified database of job vacancies from several data sources (datasets for historical purposes and APIs to more up-to-date jobs). The final data schema is a star-schema model to ease querying through the jobs list, whereas the job listing is the fact and the company, skills and provider are the dimensions of our data model.
Below we have a detailed listing of our data sources, data model and each technology of the stack I used in this project.
This project is based on several DAGs (Directed Acyclic Graphs) that are executed on Apache Airflow, moreover I used Airflow to orchestrate all ETL processes and maintain their correct frequency along with a PostgreSQL database.
So, the first thing you need to do is to configure your airflow home to this project. Don't forget to leverage the plugins configuration too. Otherwise the operators I created will not be found by Airflow.
At a first glance this project was prepared to use a Redshift cluster. If you opt to do this, you'll need to adapt
some queries within the plugins/helpers/sql_queries.py (check this commit to learn more: 1c041cfdef684f3e1a384ece3744939e7150f85 ).
Then, create (if not already created) your Redshift cluster. I provided a few scripts to help spining up a Redshift
cluster using the AWS API, directly from the command line. Before diving into them, make a copy of the dwh.cfg.example
as dwh.cfg and fill all the keys (except the HOST under CLUSTER section). Then you just need to:
- Start the cluster provisioning by running:
python aws/create_cluster.py
- Wait a few minutes and check if the cluster status is available by running:
python aws/check_cluster_available.py- You should run this script until the cluster is available. Because this script is responsible of updating our
dwh.cfgwith theHOSTaddress
- When the cluster is already available, your dwh.cfg would be rewrited with its
HOSTaddress. Then you just need to copy that configuration over to the Airflow Connections. There's a script to do that:python aws/register_airflow_connections.py
- (optional, after work) And for the sake of our AWS bills (keep'em low), there´s also a script to destroy the cluster:
python aws/destroy_cluster.py(but this one is for later)
After doing that, before activating the DAGs you have to configure the following Airflow connections:
We will use Docker to provision our local environment and to ease the production deployment process too (if required).
The Docker image we will use is the puckel/docker-airflow
Inside the root folder of this project run the following command (it will build and compose the containers):
docker build -t puckel/docker-airflow . && docker-compose -f docker-compose-LocalExecutor.yml up -d
If you hit on the wall with the python aws/register_airflow_connections.py below we have a table with a dictionary
of connections used by this ETL system. Excluding the Redshift and the Amazon Web Services Credentials,
the other configurations should be done as the other fields column states:
| Service | Conn ID | Conn Type | Other fields |
|---|---|---|---|
| PostgreSQL | pgsql |
Postgres |
This one you should figure out by yourself. (It's your database credentials!) |
| Amazon Web Services Credentials | aws_credentials |
Amazon Web Services |
On the login field you fill with your API Key. And in the password field you fill with your API Secret. |
| GitHub Jobs API | github_jobs |
HTTP |
Schema = https and Host = jobs.github.com |
| Landing.jobs API | landing_jobs |
HTTP |
Schema = https and Host = landing.jobs |
| Stackoverflow Jobs RSS Feed | stackoverflow_jobs |
HTTP |
Schema = https and Host = stackoverflow.com |
| Algolia Search Provider | algolia |
HTTP |
Login = your algolia application id and Password = your admin API key |
| Angel.co user | angel_co |
HTTP |
Login = your email and Password = your password |
Our DAGs are divided by their source. One DAG per source is convenient because each data sources has a different data format. Altought they share operators, keeping control of which sources still working is easier if we have separate visualization per source of the DAGs runs.
- Id:
dice_com_jobs_dag - Source Type: CSV Dataset
- Data Source: https://data.world/promptcloud/us-jobs-on-dice-com
- A dataset of 22.000 USA tech job posts crawled from the dice.com jobs site.
- It contains the job title, description, company and skills (tags).
Basically this DAG takes care of parsing the CSV from a S3 Bucket and staging it on our Redshift cluster to then upsert the dimensions and facts data. It runs only once as this dataset will not be updated anymore, it's for historical comparison purpose only.

- Id:
jobtechdev_se_historical_jobs_dag - Source Type: JSON Dataset
- Data Source: https://jobtechdev.se/api/jobs/historical/
- A historical dataset of nordic job vacancies with anonymized data. It has 4.4 million job posts starting from 2006 until 2017.
- Altought this is a very large dataset it only contains informations about the job title, description and company. No skills were provided.
Basically this DAG takes care of parsing the JSON from a S3 Bucket and staging it on our Redshift cluster. As this historical dataset may be updated we parse it yearly, starting from 2006 and ending in 2017.

- Id:
landing_jobs_api_dag - Source Type: JSON API
- Source: https://landing.jobs/api/v1
- Landing.jobs is one of the most used jobs websites for jobs across the Europe (the majority of the jobs posts is from Europe). At this time they have around 420 jobs available to fetch from their API.
- The Landing Jobs API is very straight forward, as it has a well structured data model the only thing that is missing in the job endpoint was the company name inside the job vacancy payload.
- So, for this source we have the job title, description, salary, relocation flag, skills (tags). Missing only the company name.
- Almost forgot to mention that the results are paginated. So we will limit the number of pages we'll download.
Basically this DAG takes care of fetching the API results within a range of pages available. As this is a very dynamic source, this DAG runs everyday at midnight to fetch new jobs from Landing.jobs.

- Id:
github_jobs_api_dag - Source Type: JSON API
- Source: https://jobs.github.com/api
- The Github Jobs API is very simple, it was just get the page you want to fetch and appends a
.jsonsuffix, then it will returns only data formatted in JSON. - Altought GitHub is the largest developer community, this source is the one with less jobs to fetch. Around 280 jobs found in their API.
- It provides the job title, description and company name. But there is no normalized data regarding the skills required in the job.
- The Github Jobs API is very simple, it was just get the page you want to fetch and appends a
This DAG takes care of requesting the landing.jobs API and fetch a limited range of jobs. It is ran everyday at midnight so we have fresh jobs posting every day.

- Id:
stackoverflow_jobs_rss_feed_dag - Source Type: RSS Feed (XML)
- Source: https://stackoverflow.com/jobs/feed
- The Stackoverflow RSS feed is the one that has more jobs available to fetch (1000 jobs to be more precise).
- It is also the most complete: has the job title, description, the company information and also the skills required in the job.
This DAG takes of requesting the Stackoverflow Jobs RSS Feed. This is a single page request, but it returns 1000 jobs per time. So I configured to run this DAG daily too.
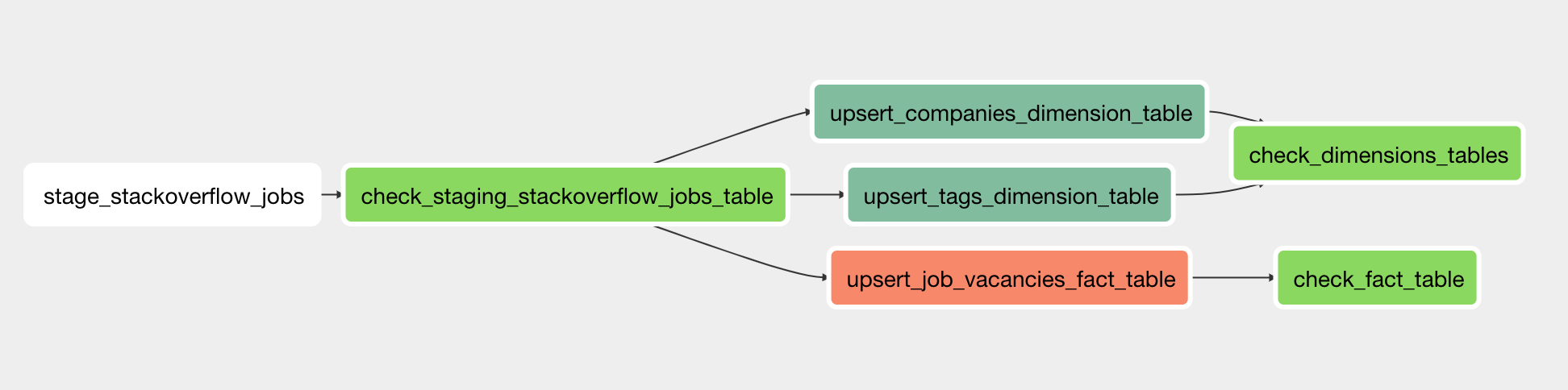
- Id:
angel_co_jobs_dag - Source Type: HTML Crawling (selenium)
This DAG uses selenium to crawl the angel.co website and store all the HTML that contains job vacancies.
- Id:
algoliasearch_index_jobs_dag - Source Type: Warehouse (Database)
This DAG takes care of fetching all inserted jobs within the job_vacancies table and index it on the instant search engine
called Algolia.
The purpose of this project is to assemble a dataset to ease query for jobs of a determined set of skills or company. For that we don't need normalized informations. Instead we adopted a star schema because of it's scalability in terms of reading and querying.
To simplify our job listing we'll have only a single fact table with the job vacancies and two other tables to aggregate data on companies and tags:
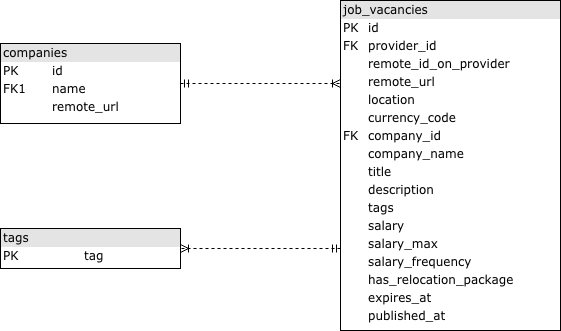
- Table name:
companies - Type: dimension table
| Column | Type | Description |
|---|---|---|
id |
VARCHAR(500) NOT NULL |
The id of the company (a slugified version of its name). |
name |
VARCHAR(500) |
The name of the company |
remote_url |
VARCHAR(500) DEFAULT NULL |
The url of the site of this company (if found on source) |
- Table name:
tags - Type: dimension table
| Column | Type | Description |
|---|---|---|
tag |
VARCHAR(255) NOT NULL |
The tag found on the job |
- Table name:
job_vacancies - Type: fact table
| Column | Type | Description |
|---|---|---|
id |
VARCHAR(255) NOT NULL |
The primary key of this table. Identifies the job vacancy |
provider_id |
VARCHAR(255) NOT NULL |
The provider id means from which data sources it came from. Currently we have these sources: jobtechdevse (dataset), dice_com (dataset), github_jobs (api), landing_jobs (api), stackoverflow_jobs (api) |
remote_id_on_provider |
VARCHAR(500) |
The identification of this job on the provider |
remote_url |
VARCHAR(500) |
The URL for the job posting (if exists) |
location |
VARCHAR(255) |
The location (city) of the job |
currency_code |
VARCHAR(3) DEFAULT NULL |
The currency code of this job's salary |
company_id |
VARCHAR(500) |
The company identification, mainly it`s a slugified version of the company's name |
company_name |
VARCHAR(500) |
The company name |
title |
VARCHAR(1000) |
The title of the job post |
description |
VARCHAR(65535) |
The description of the job post |
tags |
VARCHAR(65535) DEFAULT NULL |
The tags are the skills required in this job. Separated by comma. |
salary |
NUMERIC(18,2) DEFAULT NULL |
The salary base for the job role |
salary_max |
NUMERIC(18,2) DEFAULT NULL |
The maximum salary that the company is willing to pay |
salary_frequency |
VARCHAR(50) DEFAULT NULL |
The frequency of the salary. Usually anually (if has salary on the job post). |
has_relocation_package |
INT4 DEFAULT NULL |
Indicates wether this job vacancy offers relocation package for the candidate. (this does not means visa sponsorship) |
expires_at |
TIMESTAMP DEFAULT NULL |
When this job vacancy post will expire? |
published_at |
TIMESTAMP |
The date this job was posted. |
The developed ETL processes here consider the size of the datasets as it is. Altought if the data increased 100x the APIs sources won't be affected because they have fetching limitations and run daily (so we incrementally follow the data inrease).
For our file datasets, the Dice.com should be divided to run yearly if it was updated as it is for the JSON Jobtechdev.se dataset.
And at last, but not least, the choosen database (Redshift) can handle large amounts of read queries because it distributed our data and copies it across all nodes of the cluster to make it highly available. Maybe we will need to just increase the number of nodes, but this is done with a few clicks on the AWS dashboard.
- Create a DAG to crawl the Angel.co - probably needs to use selenium (can use as inspiration/benchmark:
https://github.com/muladzevitali/AngelList)
- Modify the
puckel/docker-airflowto leverage thechromedriverinstallation to work with theseleniumpossibly by making aDockerfile - Create the
angels_co_jobs_dagthat will use selenium to crawl their site and store the jobs informations - Create a DAG to load the crawled
jobsto the Algolia Search Provider, a free API to query those jobs - On
angel_co.pythe'published_at': None,Needs to be reviewed. published_at is mandatory for this table - Refactor the angels.co DAG to use the airflow credentials management to store the angels.co email/password
- Refactor the angels.co DAG scrape task to save the scraped divs to S3 disk
- Refactor the angels.co DAG crawl task to traverse the scraped files saved to the S3 disk
- Fix the angel.co parser, moreover, the salary_* is not being parsed as it should. It is coming with the currency symbol. We have to get rid of the currency symbol and cast it to double
- Somehow identify the currency that is being used to describe the salary of the job (maybe with the currency symbol itself?)
- Modify the
- Test and make the Algolia DAG work
- Create a simple web application to navigate/search in the data of these crawled jobs
- Normalize the job location information
- Check the viability to fetch/save the company size too