forked from tensorflow/hub
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Add the "text cookbook": a catalog of available Hub resources in the …
…text domain. PiperOrigin-RevId: 258527937
- Loading branch information
1 parent
114b29e
commit ef5b393
Showing
1 changed file
with
95 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,95 @@ | ||
| # Text Cookbook | ||
|
|
||
| This page lists a set of known guides and tools solving problems in the text | ||
| domain with TensorFlow Hub. It is a starting place for anybody who wants to | ||
| solve typical ML problems using pre-trained ML components rather than starting | ||
| from scratch. | ||
|
|
||
| [TOC] | ||
|
|
||
| ## Classification tasks | ||
|
|
||
| When we want to predict a class for a given example, for example **sentiment**, | ||
| **toxicity**, **article category**, or any other characteristic. | ||
|
|
||
| {height="150"} | ||
|
|
||
| The tutorials below are solving the same task from different perspectives and | ||
| using different tools. | ||
|
|
||
| ### Estimator | ||
|
|
||
| [Text classification](https://www.tensorflow.org/hub/tutorials/text_classification_with_tf_hub) - | ||
| example for building an IMDB sentiment classifier with Estimator. Contains | ||
| multiple tips for improvement and a module comparison section. | ||
|
|
||
| ### Keras | ||
|
|
||
| [Text classification with Keras](https://www.tensorflow.org/beta/tutorials/keras/basic_text_classification_with_tfhub) - | ||
| example for building an IMDB sentiment classifier with Keras and TensorFlow | ||
| Datasets. | ||
|
|
||
|
|
||
| ### BERT | ||
| [Predicting Movie Review Sentiment with BERT on TF Hub](https://github.com/google-research/bert/blob/master/predicting_movie_reviews_with_bert_on_tf_hub.ipynb) - | ||
| shows how to use a BERT module for classification. Includes use of `bert` | ||
| library for tokenization and preprocessing. | ||
|
|
||
| ### Kaggle | ||
| [IMDB classification on Kaggle](https://github.com/tensorflow/hub/blob/master/examples/colab/text_classification_with_tf_hub_on_kaggle.ipynb) - shows how to easily interact with a Kaggle competition from a Colab, | ||
| including downloading the data and submitting the results. | ||
|
|
||
|
|
||
| | | Estimator | Keras | TF2 | TF Datasets | BERT | Kaggle APIs | | ||
| | --------- | --------- | ----- | --- | ----------- | ---- | ----------- | | ||
| | [Text classification](https://www.tensorflow.org/hub/tutorials/text_classification_with_tf_hub) |  | | | | | | | ||
| | [Text classification with Keras](https://www.tensorflow.org/beta/tutorials/keras/basic_text_classification_with_tfhub)| |  |  |  | | | | ||
| | [Predicting Movie Review Sentiment with BERT on TF Hub](https://github.com/google-research/bert/blob/master/predicting_movie_reviews_with_bert_on_tf_hub.ipynb)|  | | | |  | | | ||
| | [IMDB classification on Kaggle](https://github.com/tensorflow/hub/blob/master/examples/colab/text_classification_with_tf_hub_on_kaggle.ipynb)|  | | | | |  | | ||
|
|
||
|
|
||
| ## Semantic similarity | ||
|
|
||
| When we want to find out which sentences correlate with each other in zero-shot | ||
| setup (no training examples). | ||
|
|
||
| 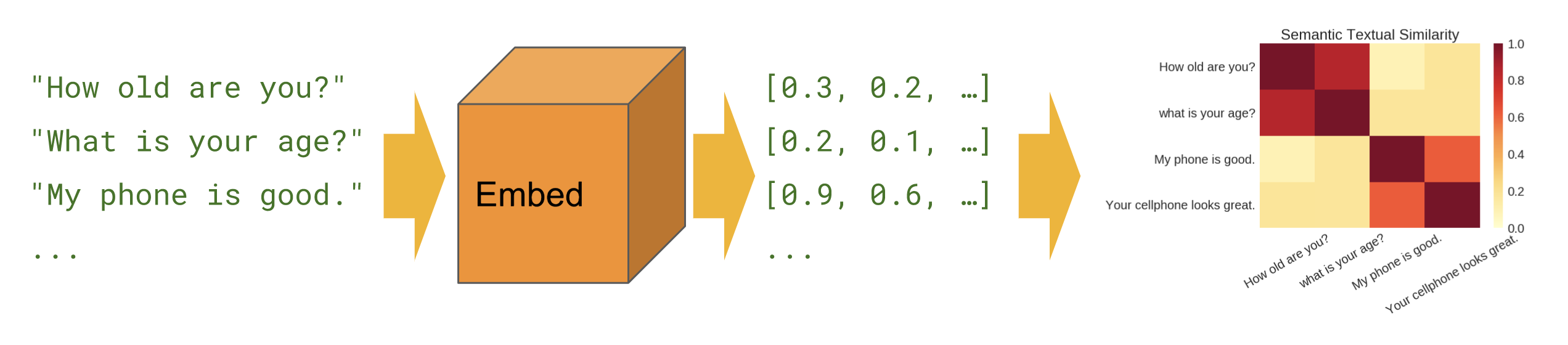{height="150"} | ||
|
|
||
| ### Basic | ||
| [Semantic similarity](https://github.com/tensorflow/hub/blob/master/examples/colab/semantic_similarity_with_tf_hub_universal_encoder.ipynb) - shows how to use the sentence encoder module to compute sentence | ||
| similarity. | ||
|
|
||
| ### Cross-lingual | ||
| [Cross-lingual semantic similarity](https://github.com/tensorflow/hub/blob/master/examples/colab/cross_lingual_similarity_with_tf_hub_multilingual_universal_encoder.ipynb) - shows how to use one of the cross-lingual sentence | ||
| encoders to compute sentence similarity across languages. | ||
|
|
||
| ### Semantic retrieval | ||
| [Semantic retrieval](https://github.com/tensorflow/hub/blob/master/examples/colab/retrieval_with_tf_hub_universal_encoder_qa.ipynb) - shows how to use Q/A sentence encoder to index a collection of documents | ||
| for retrieval based on semantic similarity. | ||
|
|
||
| ### SentencePiece input | ||
| [Semantic similarity with universal encoder lite](https://github.com/tensorflow/hub/blob/master/examples/colab/semantic_similarity_with_tf_hub_universal_encoder_lite.ipynb) - shows how to use sentence encoder modules that accept | ||
| [SentencePiece](https://github.com/google/sentencepiece) ids on input instead of | ||
| text. | ||
|
|
||
|
|
||
| ## Module creation | ||
| Instead of using only modules on [tfhub.dev](https://tfhub.dev), there are ways | ||
| to create own modules. This can be a useful tool for better ML codebase | ||
| modularity and for further sharing. | ||
|
|
||
| ### Wrapping existing pre-trained embeddings | ||
| [Text embedding module exporter](https://github.com/tensorflow/hub/blob/master/examples/text_embeddings/export.py) - | ||
| a tool to wrap an existing pre-trained embedding into a module. Shows how to | ||
| include text pre-processing ops into the module. This allows to create a | ||
| sentence embedding module from token embeddings. | ||
|
|
||
| [Text embedding module exporter v2](https://github.com/tensorflow/hub/blob/master/examples/text_embeddings_v2/export_v2.py) - | ||
| same as above, but compatible with TensorFlow 2 and eager execution. | ||
|
|
||
| ### Create trainable RNN module | ||
| [RNN model exporter](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/saved_model/integration_tests/export_text_rnn_model.py) - | ||
| shows how to create an uninitialized trainable LSTM based module compatible with | ||
| TensorFlow 2. The module exposes two signatures, one for training by directly | ||
| feeding in sentences, the other for decoding - constructing a statistically most | ||
| likely sentence. |