Choose JVM options ergonomically #30684
Conversation
With this commit we add the possibility to define further JVM options (and system properties) based on the current environment. As a proof of concept, it chooses Netty's allocator ergonomically based on the maximum defined heap size.
|
Pinging @elastic/es-core-infra |
There was a problem hiding this comment.
I think it is pretty cute and it could be quite useful down the road.
I expect it'd be easier to get the properties if we started the launcher with the user defined jvm arguments but I expect that could cause funny issues down the road. Also it'd be silly to start the launcher with a huge heap. So I think your approach here is probably better than starting the launcher with the user defined jvm arguments. Though it is nice to think about it.
| } | ||
| } | ||
| } | ||
| return null; |
There was a problem hiding this comment.
Would it be possible to return what the default JVM heap is here instead of null? Seems like we still may want to make changes to JVM options for an unset heap.
Either that, or since we explicitly set it in our jvm.options, emit a warning or error that no heap has been specified (someone must have removed the option)
There was a problem hiding this comment.
The JVM chooses the heap size ergonomically when the heap size is not specified.
There was a problem hiding this comment.
The JVM chooses the heap size ergonomically when the heap size is not specified.
Do we have the ability to see what it would choose? If running on a small machine, for instance, we'd still want to disable Netty's pooled allocator if the JVM is going to automatically choose a 400mb heap
There was a problem hiding this comment.
It can be quite tricky because the ergonomics these days depend on other flags on the JVM (e.g., -XX:+UseCGroupMemoryLimitForHeap).
There was a problem hiding this comment.
We could try starting a JVM with all the flags specified and -XX:+PrintFlagsFinal -version and scrape the output for MaxHeapSize.
There was a problem hiding this comment.
One aspect that I like about that approach is that it is pretty lightweight (it just checks the provided arguments). Yes, it will not choose settings ergonomically if the user has manually removed the heap size setting from jvm.options. However, I think this is (a) not the common case as this is probably one of the most important JVM-related settings in Elasticsearch and (b) we'd lose the ability to provide an ergonomic choice but otherwise everything works as is.
Jason has mentioned a good approach to get around this limitation. I think it would work but I see the following potential risks:
- We start a
javaprocess with the very same settings as Elasticsearch so this will negatively affect our startup time to a small degree (I rantime java -Xms8G -Xmx8G -XX:+UnlockDiagnosticVMOptions -XX:+AlwaysPreTouch -XX:+PrintFlagsFinal -Xlog:gc\*,gc+age=trace,safepoint:file=/tmp/gc.log:utctime,pid,tags:filecount=32,filesize=64m -versionon several machines and measured between 0.5 and 3 seconds Wall clock time). We'd also output several GC log files (every JVM startup creates a new one) which might be confusing. - We use an
-XXflag (-XX:+PrintFlagsFinal) to parse output. In theory-XXmay disappear without any prior notice. Personally, I doubt though that this would happen with-XX:+PrintFlagsFinal. - We would need to parse output that is not under our control.
In the end both approaches have their advantages and disadvantages but if we contrast this with the requirement that the user specifies -Xmx in order for us to provide ergonomic choices I think the current approach is a reasonable compromise? I think though that it would be nice to emit a warning that ergonomic choices are turned off in case we cannot detect a heap size?
There was a problem hiding this comment.
@danielmitterdorfer The -version avoids actually starting a JVM so we can -XX:+AlwaysPreTouch with no impact.
There was a problem hiding this comment.
Thanks for the correction. I've corrected my comment accordingly.
There was a problem hiding this comment.
I think though that it would be nice to emit a warning that ergonomic choices are turned off in case we cannot detect a heap size?
I think this is a reasonable solution, right now since we ship a jvm.options it would require a user to go in and remove the settings that we have, so I don't think it will be a common case.
We don't remove the options and use -XX:+UseCGroupMemoryLimitForHeap for our docker image(s) do we?
There was a problem hiding this comment.
We don't remove the options and use
-XX:+UseCGroupMemoryLimitForHeapfor our docker image(s) do we?
We do not do that.
With this commit we switch to the unpooled allocator at 1GB heap size (value determined experimentally determined, see PR for more details). We are also explicit about the choice of the allocator in either case.
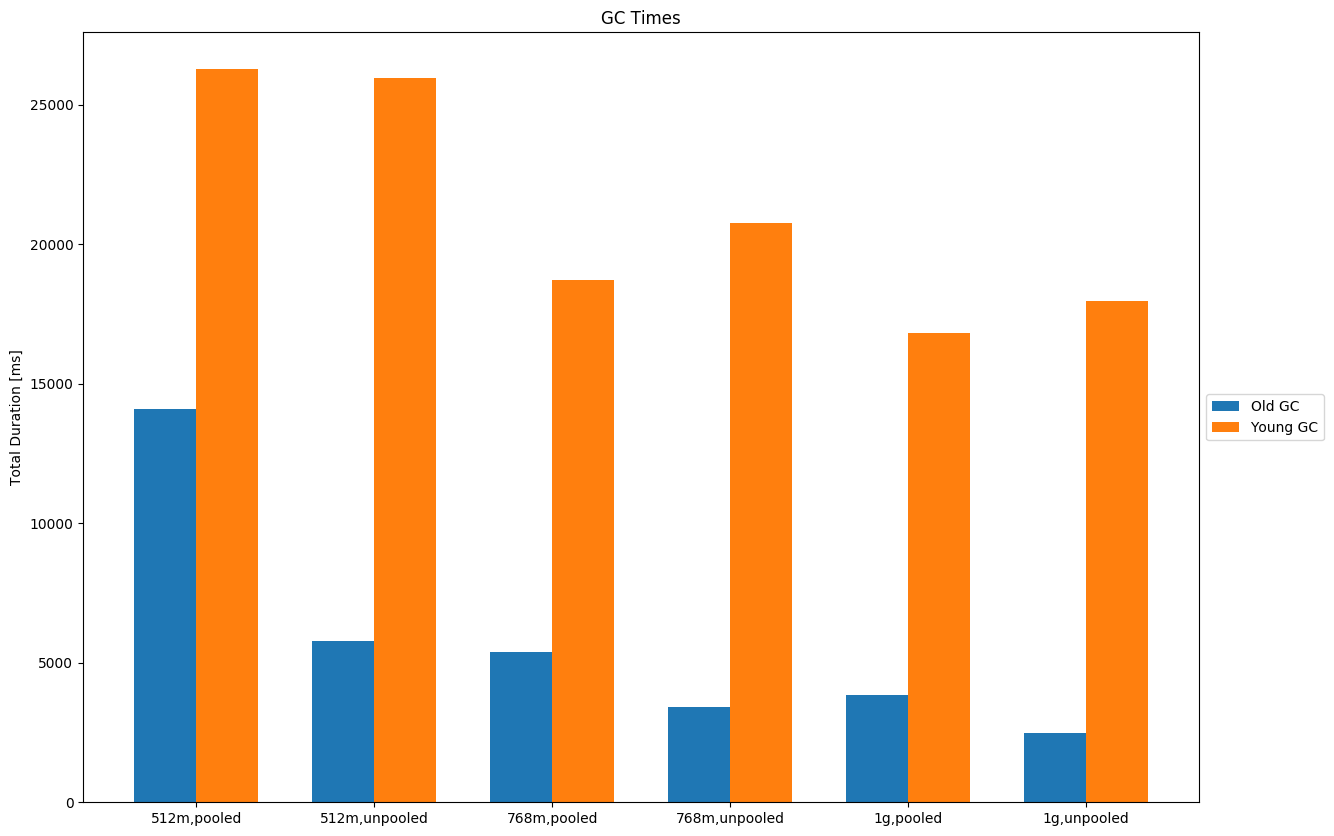
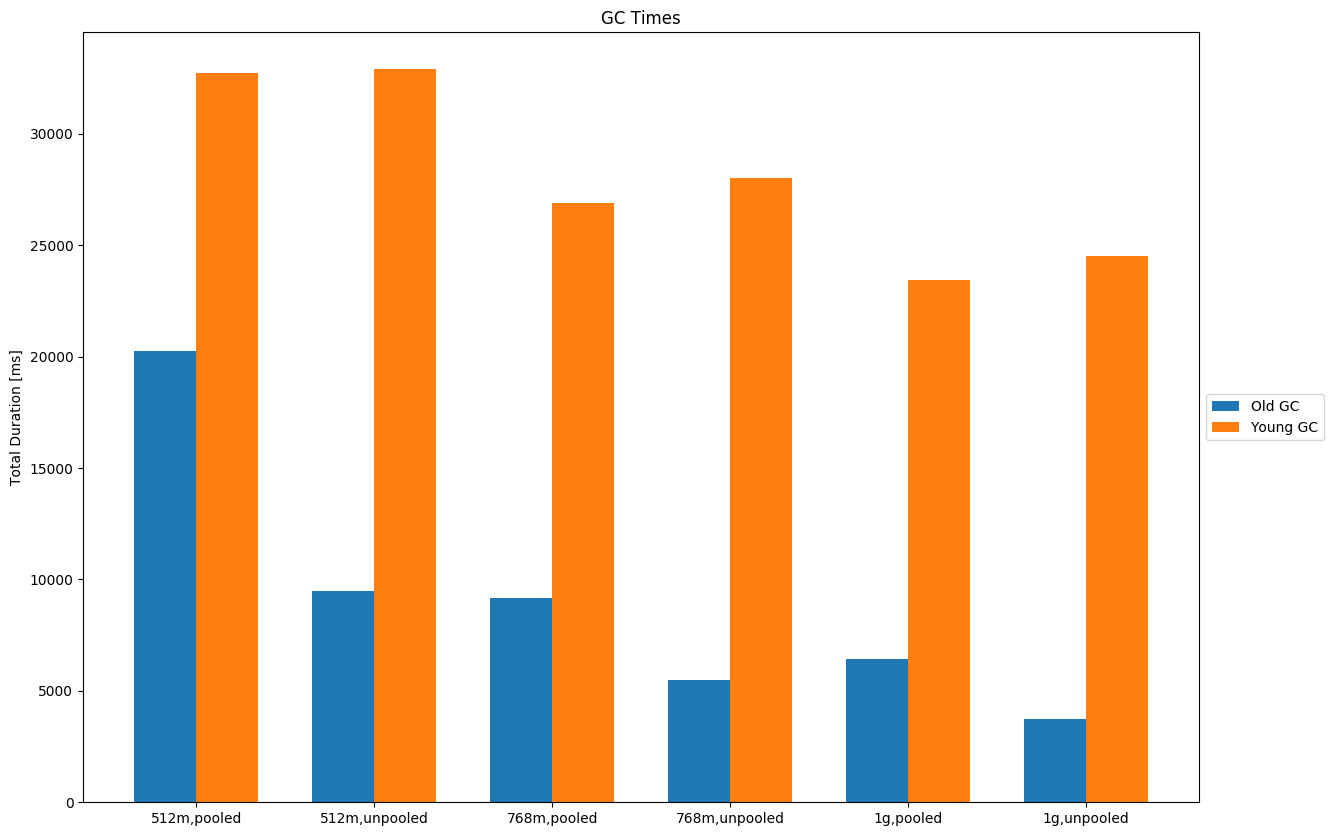
Benchmark ScenariosI ran benchmarks for the following data sets to determine at which point we should switch the allocator (click on the links below for a thorough description of the data set and an example document): I ran those for one node, three nodes (one replica) and one node with X-Pack Security enabled. Heap size was 512MB, 768MB and 1G. All benchmarks are based on revision 37f67d9. ResultsRaw results can be downloaded from raw_results.zip. Here I just want to highlight some of the results. GC metricsOverall old GC decreases (sometimes significantly) at the expense of a slight increase in young GC times. This is expected because there is no pool that takes up space (in the old generation) but rather we allocate new objects for every request most of which are short lived. This is a rather typical case from geonames: One node:
Three nodes, one replica:
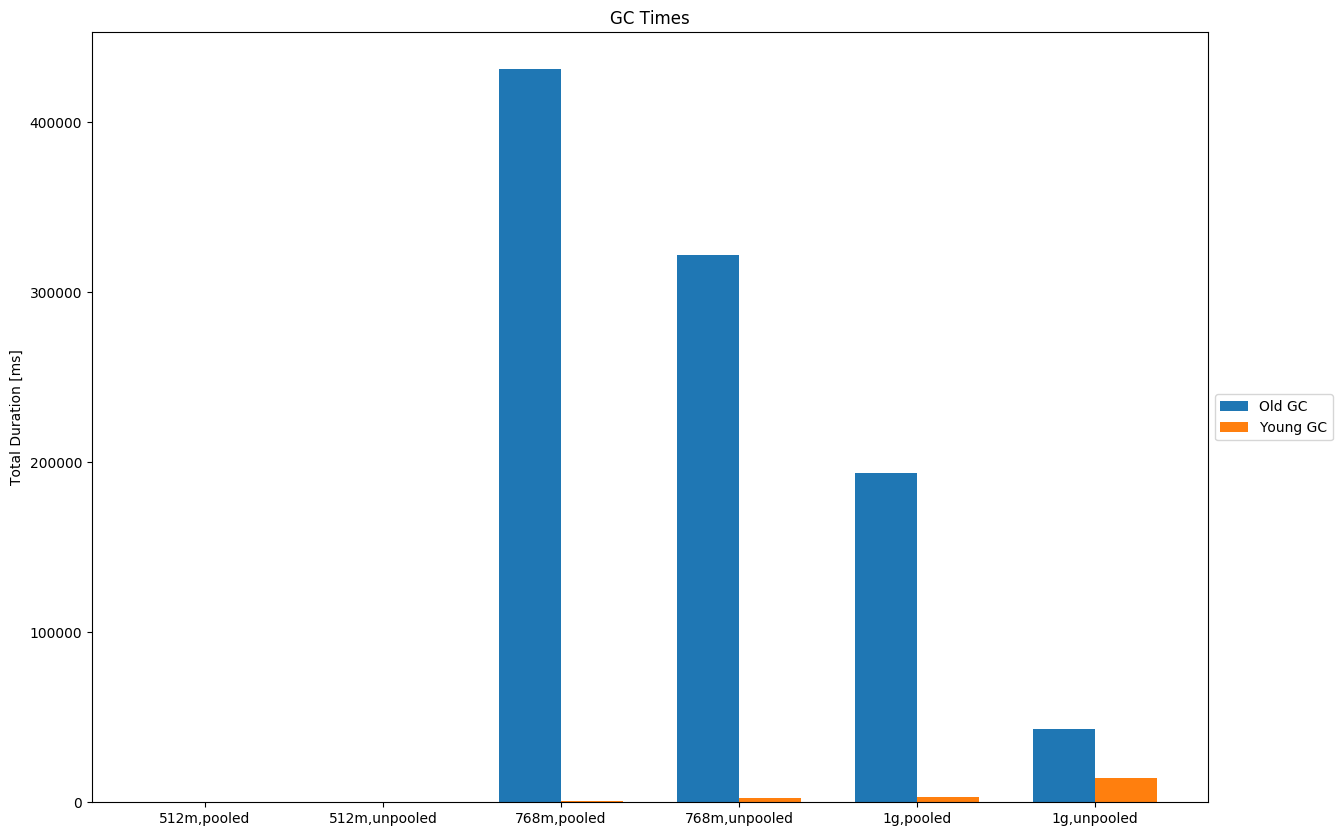
For other benchmarks (fulltext, i.e. PMC) we are able to use lower heap sizes when we switch to the unpooled allocator:
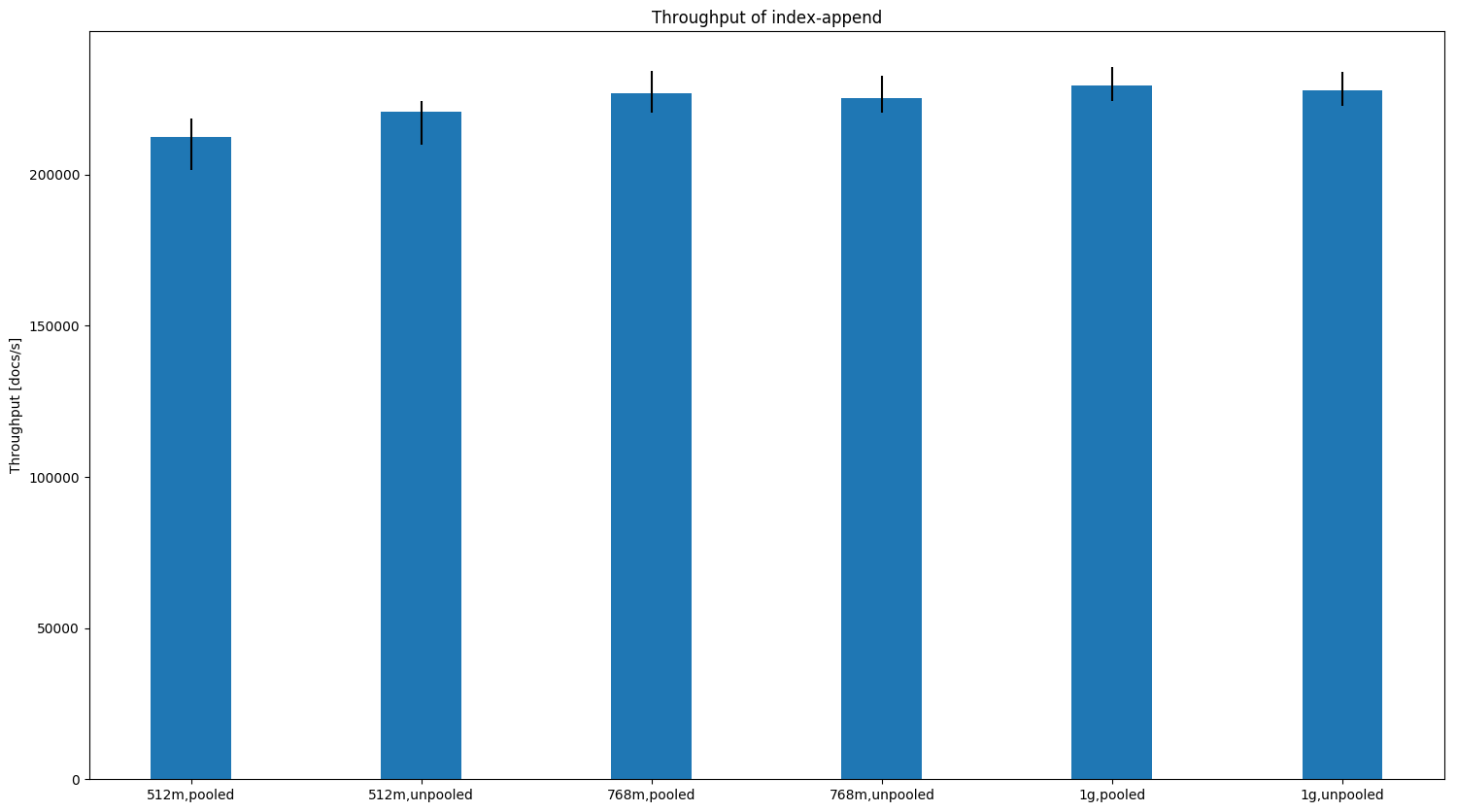
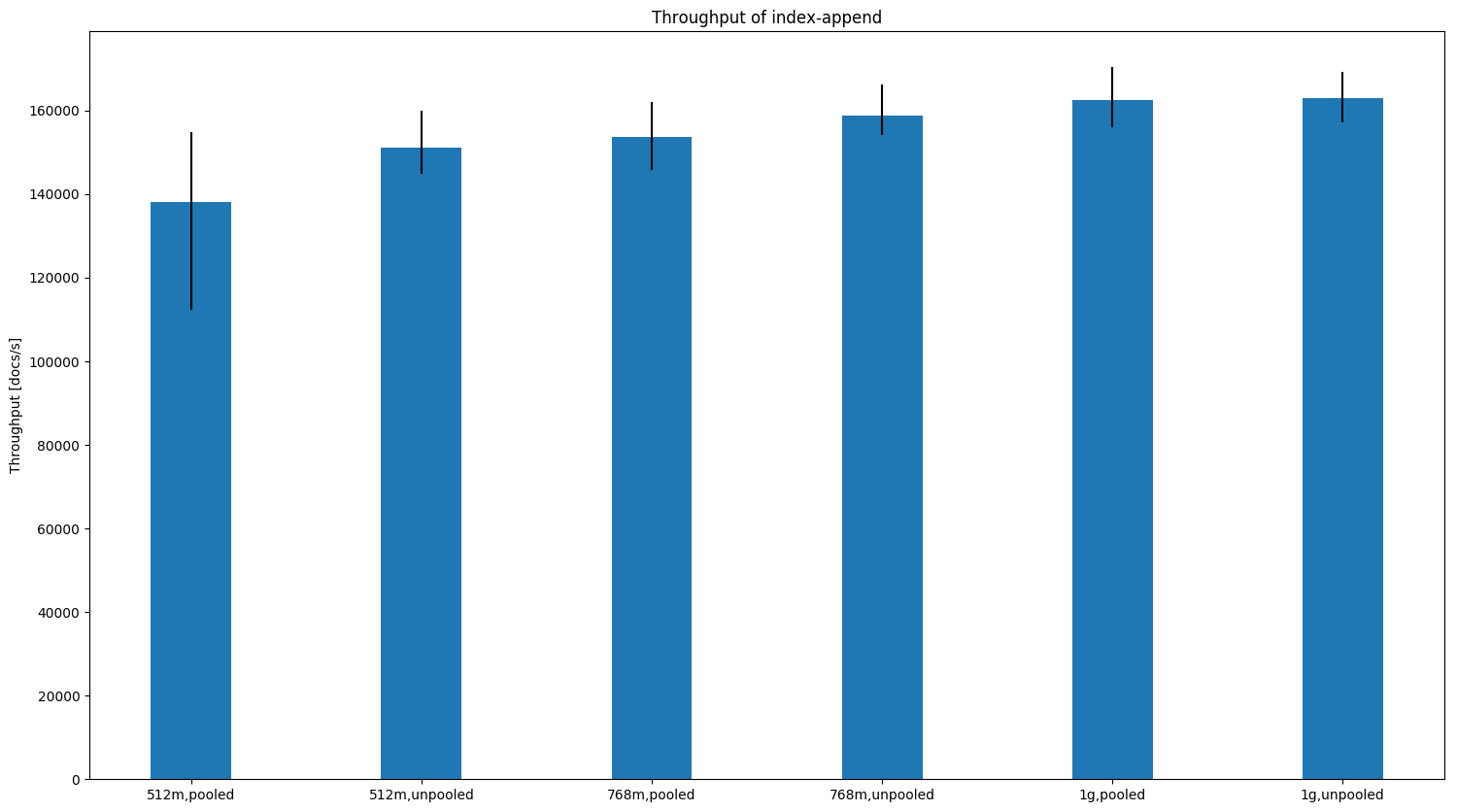
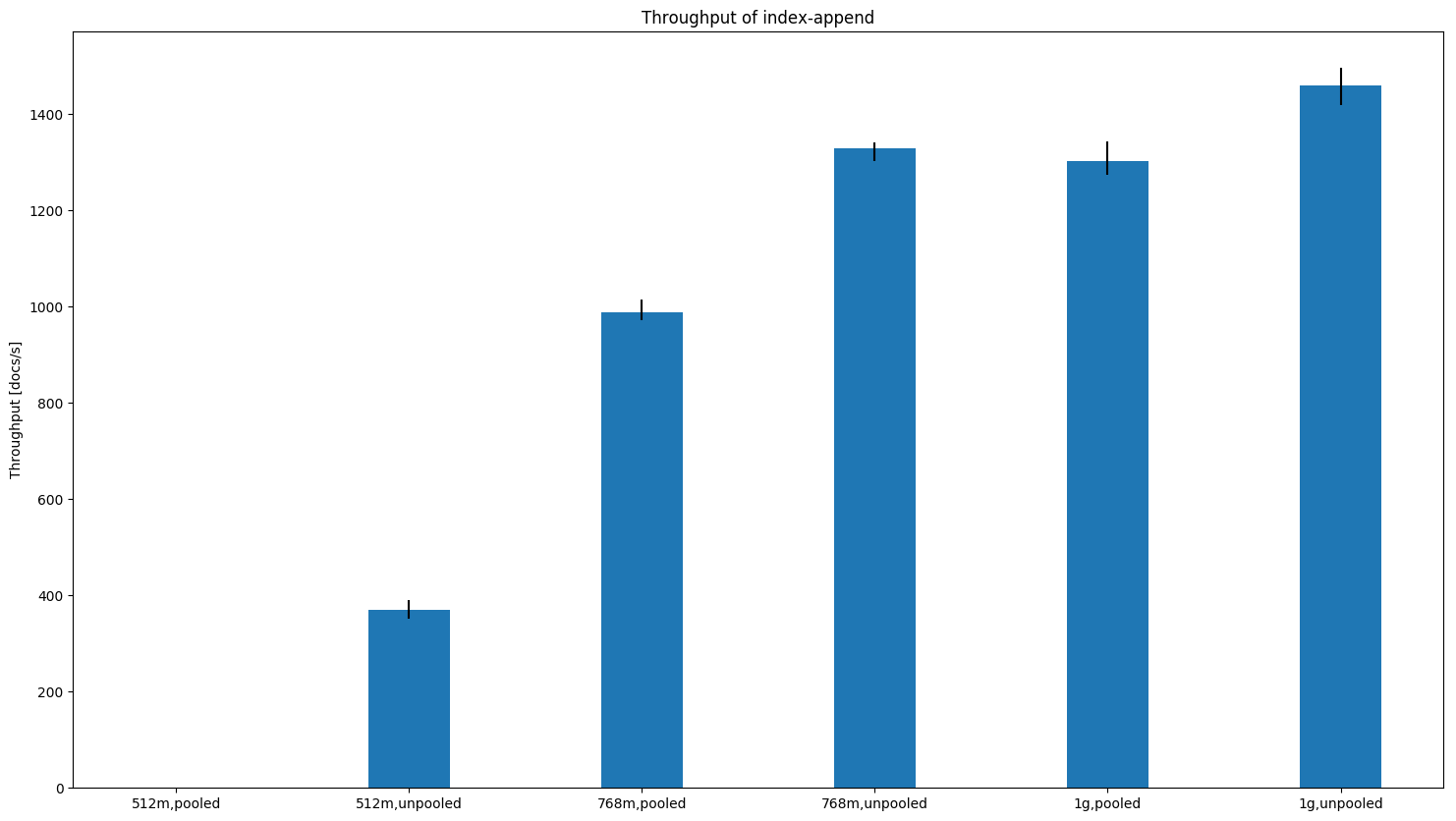
Note that the benchmark did not finish successfully for a 512MB heap in either case but with the unpooled allocator we were able to finish with 768MB. Indexing ThroughputThroughput increases in almost all cases except when we have rather small documents (i.e. geopoints). Here are several examples (the bars show the median; black lines indicate minimum and maximum): For small documents (one property with one geopoint per document) we see a slight decrease in indexing throughput for heap sizes > 512MB:
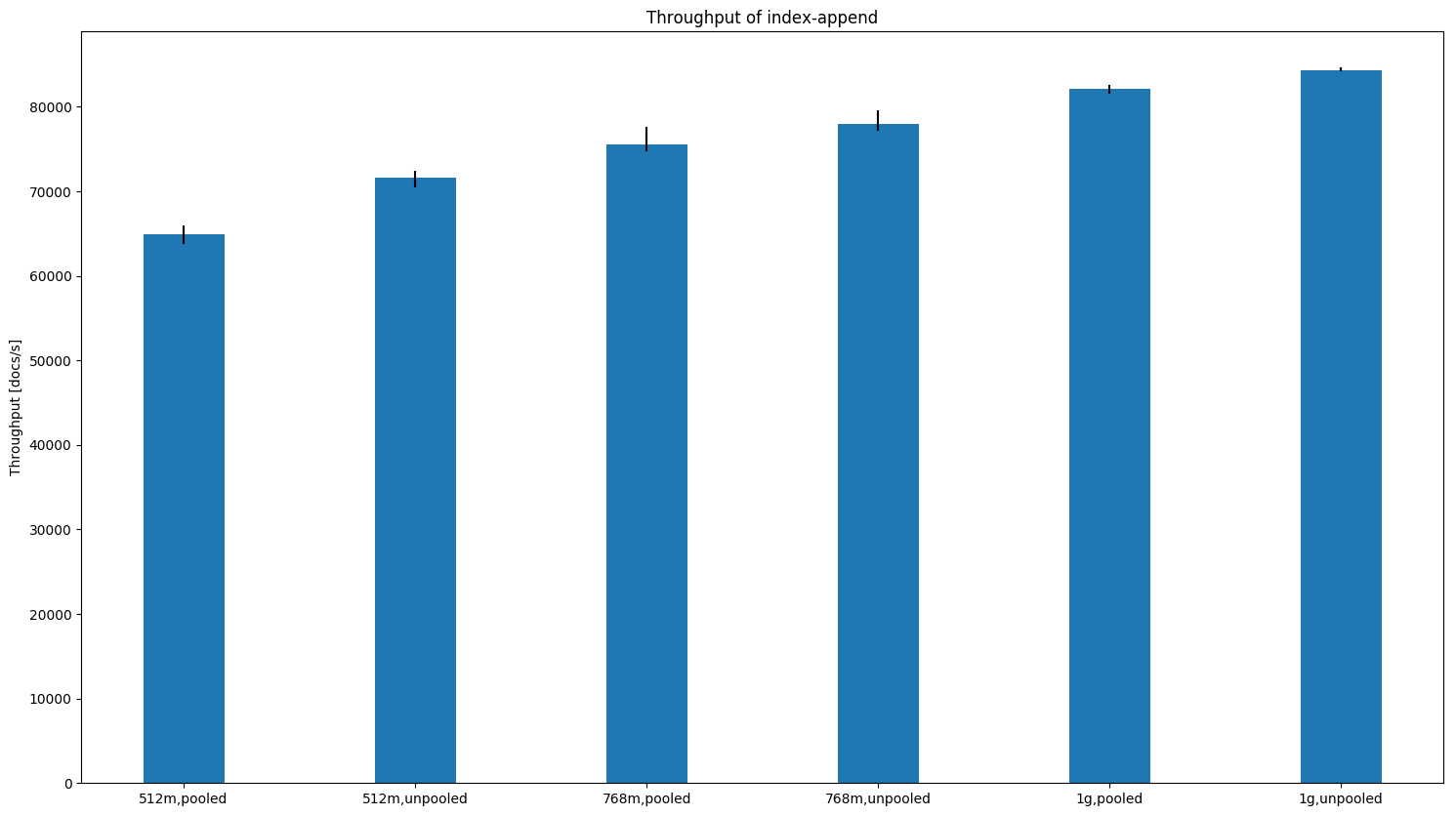
In other cases we typically see an increase in indexing throughput and less variation (i.e. the black line gets smaller). For HTTP logs the difference gets more pronounced the less heap size we have available (one node):
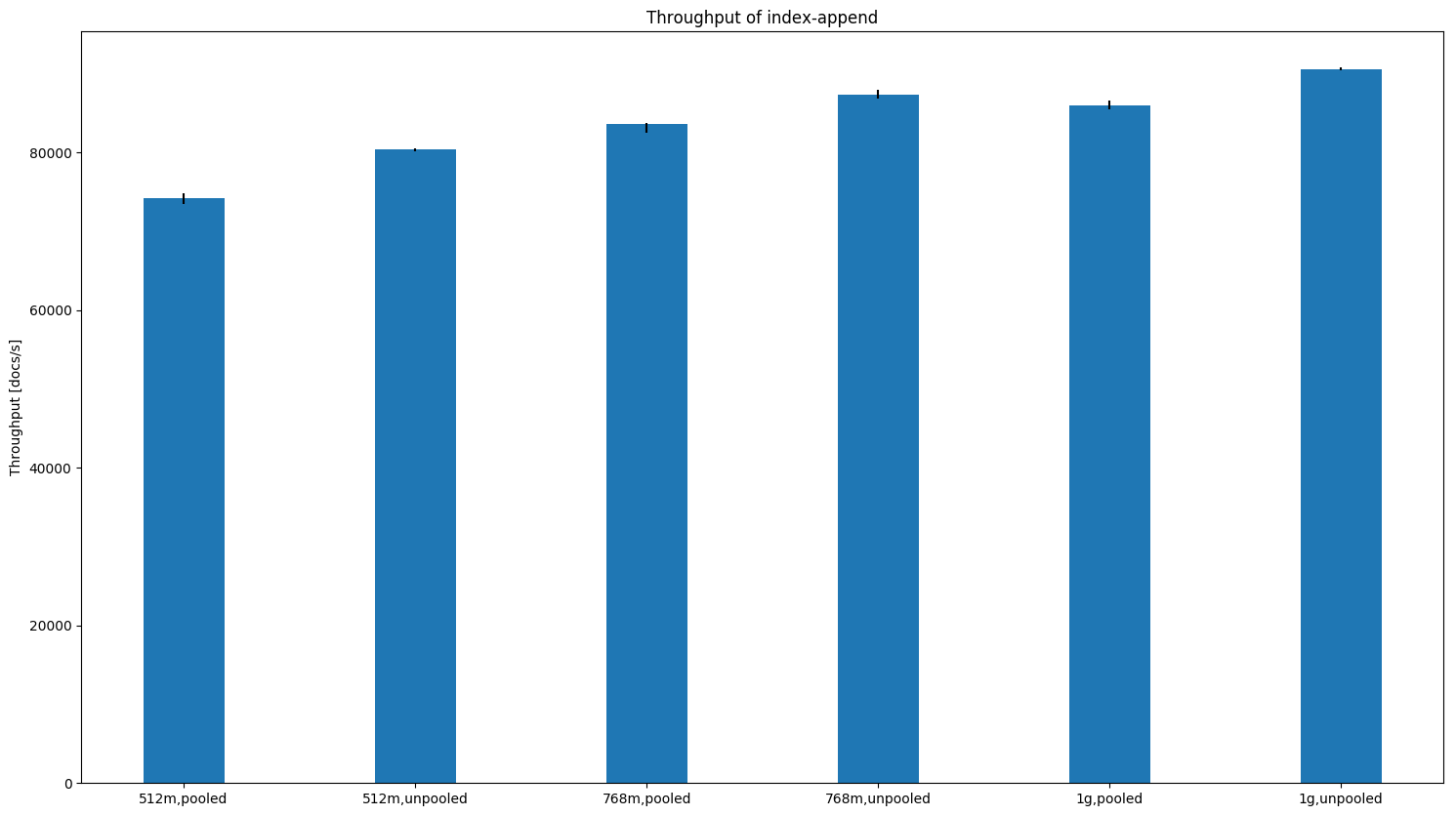
geonames (one node):
geonames (three nodes, one replica):
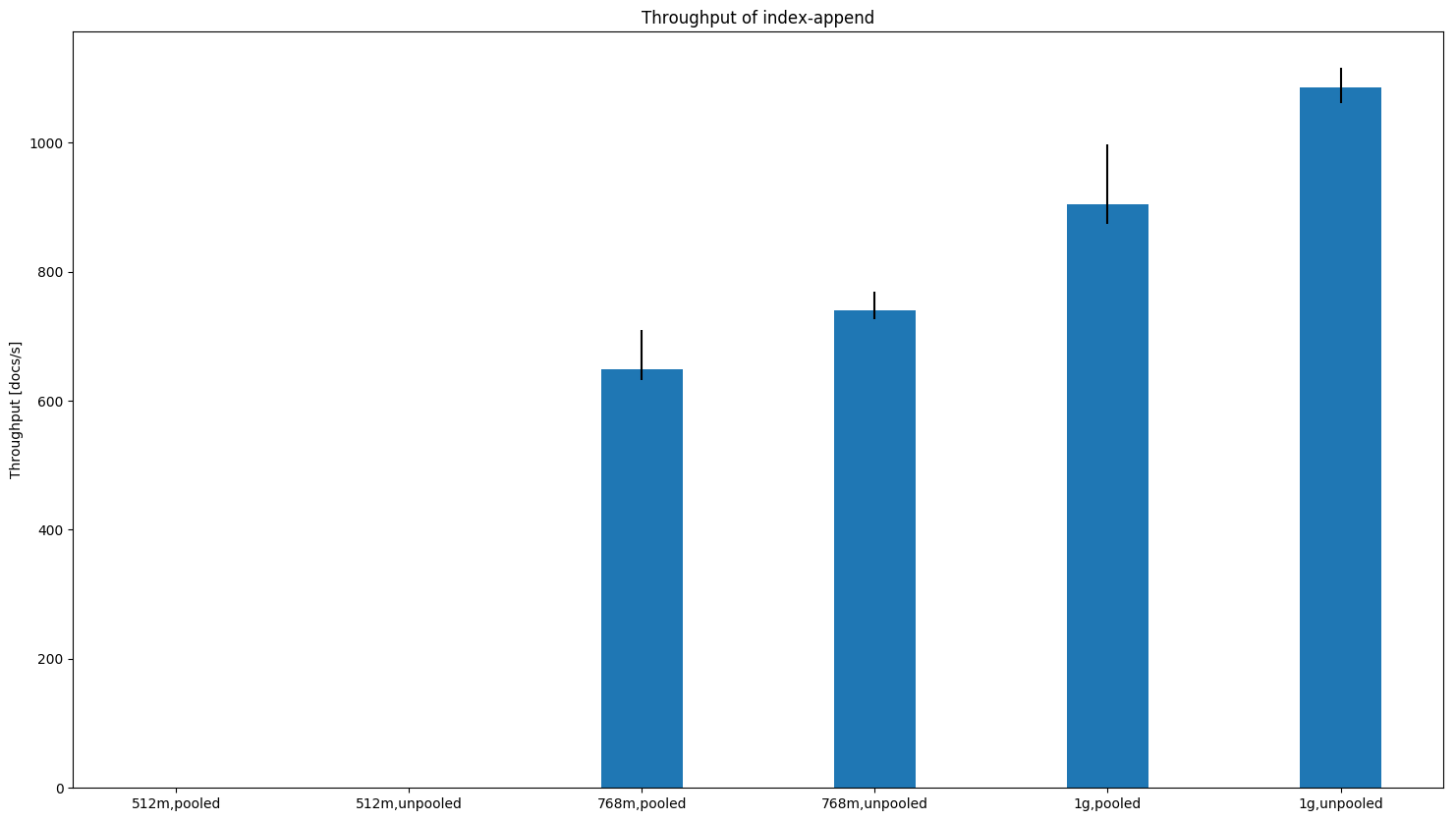
For PMC the difference is quite pronounced already for 1GB heaps: one node:
Again, we were not able to finish this benchmark for 512MB heap size but succeeded for 768MB heap size with the unpooled allocator. three nodes:
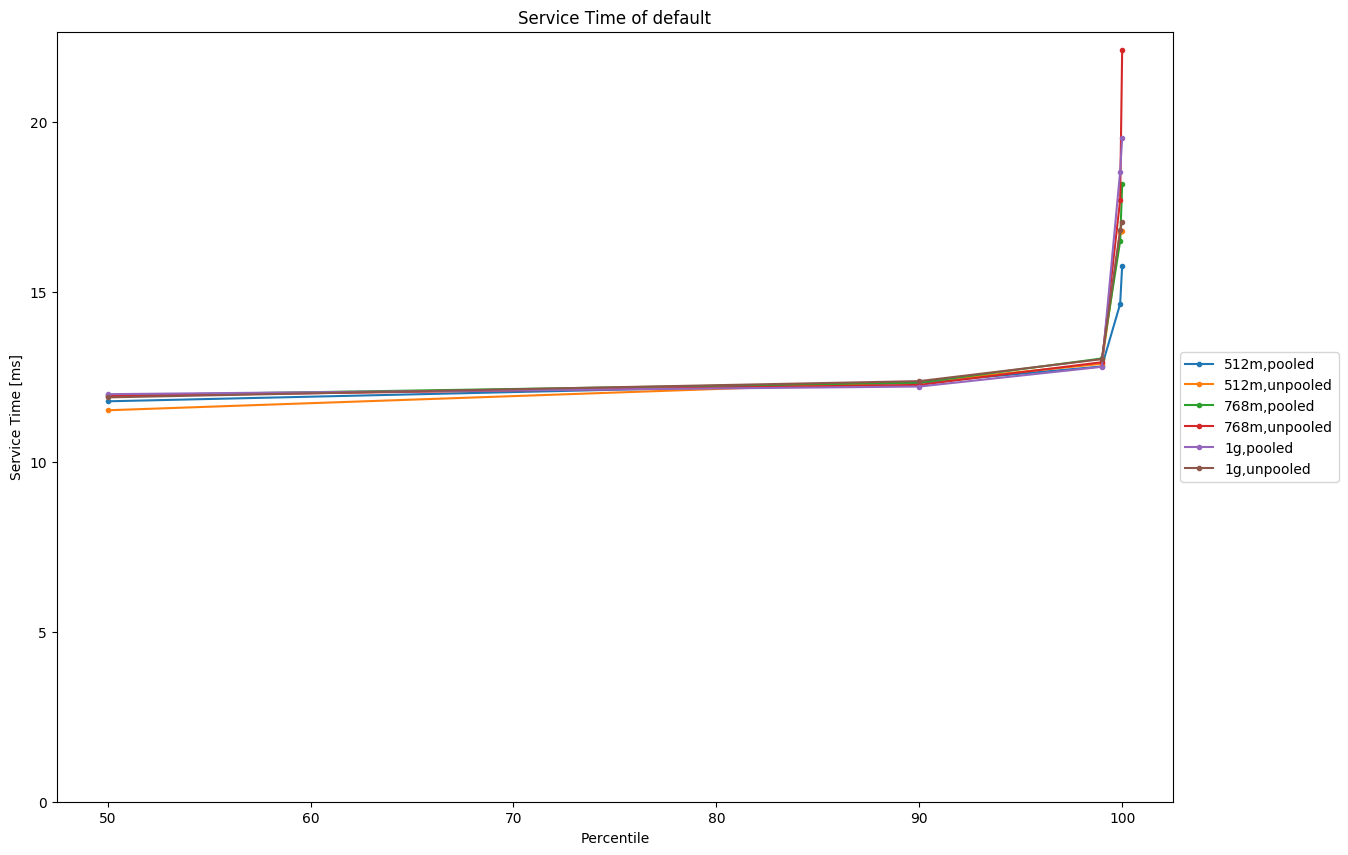
Query TimeIn almost all cases service time is roughly identical (within run-to-run variation): This is an ideal case showing the match-all query for geonames on one Elasticsearch node:
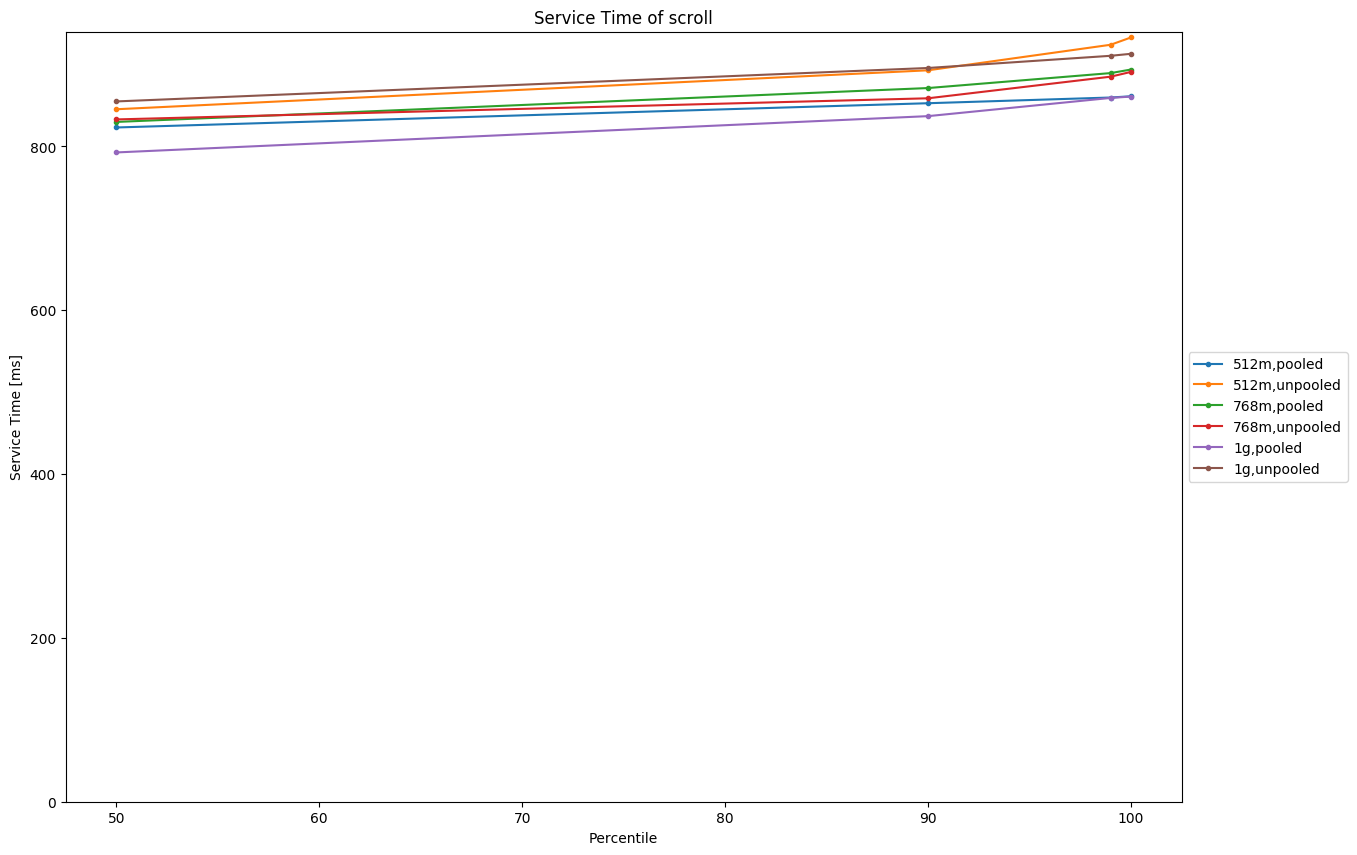
For scrolls we see a little bit higher variation in some cases (this is geonames with X-Pack):
Times also tend to be a little bit worse with the unpooled allocator at higher heap sizes (see the scroll picture above). ConclusionBased on the data it is not a hard and clear decision at which point we should switch but for the most part the situation has already improved in the 1GB case. The smaller heap sizes get, the more the unpooled allocator makes sense. I'd switch at 1GB heap size to the unpooled allocator (which is already reflected in the last commit) but if we want to be more conservative we could also switch at 768MB. @dakrone, @nik9000, @s1monw, @jasontedor are you still ok with my changes given those results? Also picking up the previous discussion on what to do when the user did not specify a heap size (i.e. |
|
I'm in. Seriously, though, you've proven to me that ergonomically picking some JVM options based on other provided options is a great idea. I'm fine with kicking this optimization in at 1GB because it looks like it mostly helps. I wonder:
|
|
Thanks for your feedback. To your thoughts:
If a user sets some value explicitly, this effectively disables our ergonomic choice. I think this makes sense because it allows us to provide sensible defaults but still enables users to tune things on their own. (paraphrasing you below)
IMHO apart from the choice of the garbage collector, the heap size is the single most important choice that you can make in the JVM configuration. For a small tool it might be ok to not specify the heap size but for server software like Elasticsearch I don't think it is a good idea to leave the heap size unspecified. Why?
So if we want to change behavior I'd tend to refuse to start rather than picking something for the user. If we intend to do this, I think we should do this in a separate PR though? |
Right! But thinking about this informs my thinking about how we should handle the other ergonomic choices when the user doesn't specify the heap size. If we don't plan to start if the user doesn't specify the heap size then we don't have to handle it at all. Given that we plan to talk more about heap choices in the future, I think your choice not to set any ergonomic options if heap size isn't specified is fine for this PR. I think we should get this in. |
|
Thanks all for your feedback. I've merged this now to master and will check how our benchmark behave over the next few days as well. |
With this commit we add the possibility to define further JVM options
(and system properties) based on the current environment. As a proof of
concept, it chooses Netty's allocator ergonomically based on the maximum
defined heap size.
This PR is work in progress and just up for the curious. Especially, we need to
run experiments to decide at which heap size to switch the allocator from
pooled to unpooled.