Bluestein's algorithm #6
Conversation
src/algorithm/bluestein.rs
Outdated
| for (w, wi) in scratch_b.iter_mut().zip(self.w_twiddles.iter()) { | ||
| *w = *w * wi; | ||
| } | ||
| self.inner_fft_inv.process(&mut scratch_b, &mut scratch_a); |
There was a problem hiding this comment.
I have an optimization to recommend: You can compute an inverse FFT by:
- Conjugating the inputs
- Computing a forward FFT on the data from step 1
- Conjugating the output of step 2
Conjugating will be very easy, since you're already looping over both the inputs and outputs, and it means this algorithm would only need to store a forward FFT, not both a forward and inverse.
There was a problem hiding this comment.
It will also mean we don't need to take "inverse" in the constructor either, because we can grab it from the inner FFT.
There was a problem hiding this comment.
Good idea! I will do this and update the PR.
|
Sorry it took me a while to see this. I think this is a great addition. Apparently, bluestein's works with any inner size, not just powers of 2. For example, if we could somehow make a variant of radix4 to work with size-24 and size-12 as base cases instead of size-32 and size-16 it would process FFTs of size 3 * 2^n. For a FFT of size 17, 2*17 - 1 = 33. If we exclusively went with the "next power of two" rule, we'd be forced to use a size-64 FFT. But with that radix4 variant, we could use 48 instead. Something I discovered while working on the SIMD branch is that, for the most part, 3*2^n FFTs are just as fast as 2^n FFTs, so it would represent a clear improvement in performance. That doesn't need to be done for this PR, but if you're excited to keep working on RustFFT, that might be an area to explore (: |
src/algorithm/bluestein.rs
Outdated
| fn perform_fft(&self, input: &mut [Complex<T>], output: &mut [Complex<T>]) { | ||
| assert_eq!(self.len(), input.len()); | ||
|
|
||
| let mut scratch_a = vec![Complex::zero(); self.inner_fft_fw.len()]; |
There was a problem hiding this comment.
Minor optimization: If we have to allocate in here, it might be wise to only do one allocation instead of two. IE, create a vec of twice the size, and use split_at_mut to get two slices.
Benefits would include less memory fragmentation, fewer allocator calls, improved memory locality. I don't know if it would actually be measurably faster though.
There was a problem hiding this comment.
Yes unfortunately it's not possible to avoid the allocation without changing the FFT trait so process() takes a &mut self.
But this is a good idea. I'm guessing that with overhead, the time to allocate a twice as long vector takes much less than twice the time.
This is a very interesting idea! I would gladly explore that. Doing it as a separate PR seems appropriate. BTW, I assume this is the new permanent home for RustFFT, so shouldn't issues be enabled for this repo? |
|
Thanks for pointing that out, I enabled issues |
|
I have now implemented all the suggested changes. I also updated the planner to use a mixed radix inner fft when that is possible and faster than a longer radix4. |

| } | ||
| self.inner_fft_inv.process(&mut scratch_b, &mut scratch_a); | ||
| self.inner_fft.process(&mut scratch_b, &mut scratch_a); |
There was a problem hiding this comment.
I have one final request: Could you leave a comment here pointing out that this is computing an inverse FFT, because we have conjugated the inputs and outputs?
There was a problem hiding this comment.
I updated this now and added comments on what is going on.
I also added conjugations so the first FFT is always a forward type, and the second always an inverse. It seems using an iFFT as the first step and an FFT as the second also produces correct results. I haven't investigated why that is, but that's not very intuitive so I prefer to do it the "normal" way.
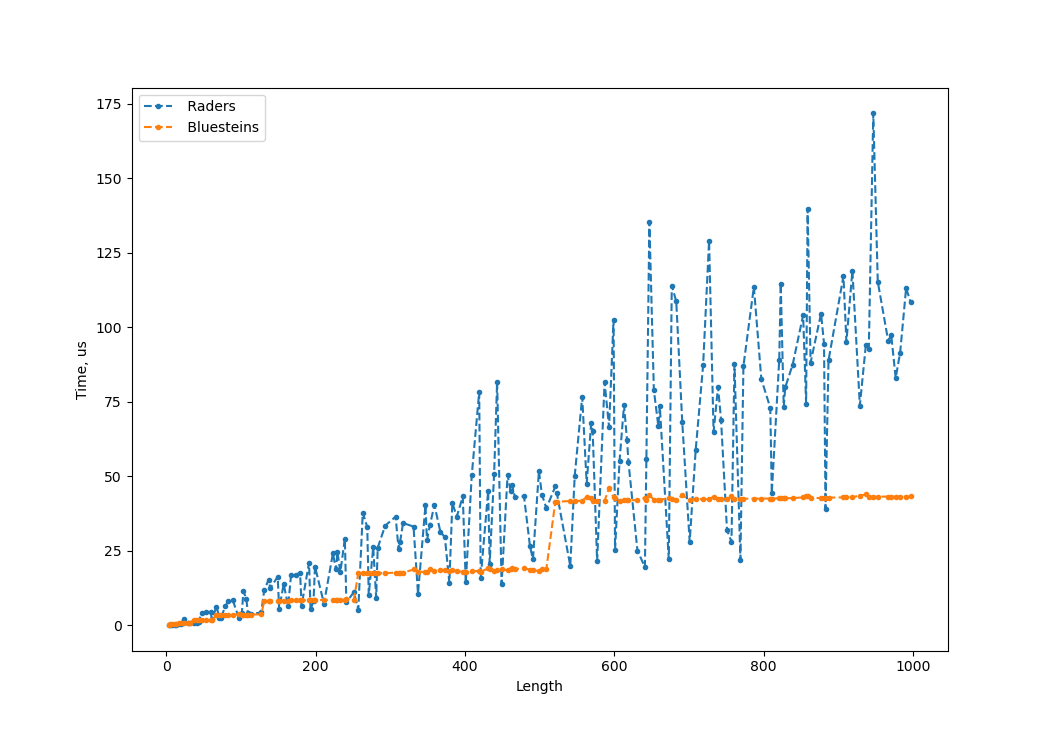
This PR adds an implementation of Bluesteins algorithm. This is often but not always faster than Raders algorithm.
The code is based on the implementation in "fourier" by @calebzulawski
https://github.com/calebzulawski/fourier/blob/master/fourier-algorithms/src/bluesteins.rs
This is useful for prime length FFTs, especially the ones where Rader's gets slow.
The planner has been modified to use Raders when the prime factors of (len-1)/2 are all 7 or less, and Bluesteins for other cases. This seems to give the fastest implementation for nearly all lengths, and all the ones where the difference is large are correct.
This graph shows the average time to compute a FFT for all prime lengths below 1000, for Rader and Bluestein:
The plot was made with this simple tool: https://github.com/HEnquist/fftbenching/tree/bluestein_vs_rader