Don't use AVX-512 for small inputs in Memmove due to throttle issues #84577
Conversation
|
Tagging subscribers to this area: @JulieLeeMSFT, @jakobbotsch, @kunalspathak Issue DetailsI noticed that my PR #84348 regressed TE benchmarks
I assume that our hardware for these benchmarks matches the official TE hardware which is I still enabled PS: CoreCLR GC uses AVX-512 in VXSort to sort card tables and I think I saw perf improvements if I disabled AVX-512 there too. cc @dotnet/avx512-contrib
|
|
Codegen example this PR changes: bool Foo(Span<byte> src, Span<byte> dst) => src.Slice(0, 70).TryCopyTo(dst);; Method Prog:Foo(System.Span`1[ubyte],System.Span`1[ubyte]):bool:this
G_M65161_IG01:
sub rsp, 40
vzeroupper
;; size=7 bbWeight=1 PerfScore 1.25
G_M65161_IG02:
cmp dword ptr [rdx+08H], 70
jb SHORT G_M65161_IG06
mov rax, bword ptr [rdx]
mov rdx, bword ptr [r8]
mov ecx, dword ptr [r8+08H]
xor r8d, r8d
cmp ecx, 70
jb SHORT G_M65161_IG04
;; size=24 bbWeight=1 PerfScore 11.50
G_M65161_IG03:
- vmovdqu32 zmm0, zmmword ptr[rax]
- vmovdqu xmm1, xmmword ptr [rax+36H]
- vmovdqu32 zmmword ptr[rdx], zmm0
- vmovdqu xmmword ptr [rdx+36H], xmm1
+ vmovdqu ymm0, ymmword ptr [rax]
+ vmovdqu ymm1, ymmword ptr [rax+20H]
+ vmovdqu xmm2, xmmword ptr [rax+36H]
+ vmovdqu ymmword ptr [rdx], ymm0
+ vmovdqu ymmword ptr [rdx+20H], ymm1
+ vmovdqu xmmword ptr [rdx+36H], xmm2
mov r8d, 1
;; size=28 bbWeight=0.50 PerfScore 6.12
G_M65161_IG04:
mov eax, r8d
;; size=3 bbWeight=1 PerfScore 0.25
G_M65161_IG05:
add rsp, 40
ret
;; size=5 bbWeight=1 PerfScore 1.25
G_M65161_IG06:
call [System.ThrowHelper:ThrowArgumentOutOfRangeException()]
int3
;; size=7 bbWeight=0 PerfScore 0.00
; Total bytes of code: 74 |
 BruceForstall
left a comment
BruceForstall
left a comment
There was a problem hiding this comment.
This seems good for now. I wonder if we'll have to be more fine-grained in our performance tuning, e.g., even tuning the JIT dynamically by CPU part instead of only by ABI, as we do now.
|
Maybe we should set our defaults on what hardware we expect to see the most "in the wild"? E.g., here is a list of Azure hardware: https://azure.microsoft.com/en-in/pricing/details/virtual-machines/series |
|
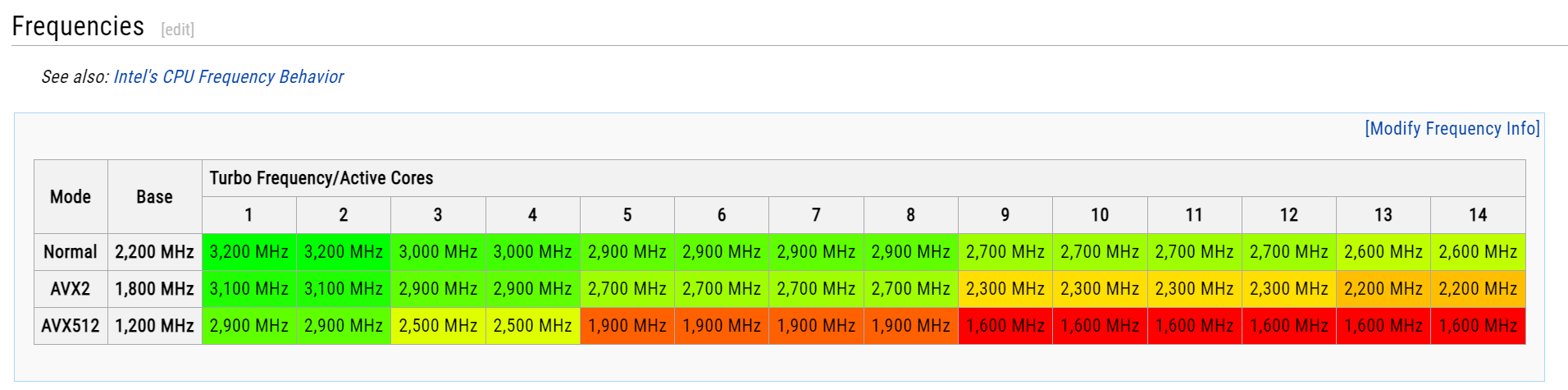
Is due to frequency scaling on early AVX512 chips (TE chips are from 2017). Cloudflare did a write up on it https://blog.cloudflare.com/on-the-dangers-of-intels-frequency-scaling/ Xeon Gold 5120 - Intel (2017): Turbo Frequency/Active Cores https://en.wikichip.org/wiki/intel/xeon_gold/5120
The chips are 6 years old though |
|
Is there any way to check that a chip is modern enough? I assume just checking processors we have in Azure is not enough or we really need to make an allow-list 😐 |
|
Btw, I think I saw improvements in TE when I also disabled AVX1-AVX2 and it matches Ben's picture. But I connected that with the fact we mostly work with small inputs.. |
Not outside model/stepping/revision checks, which we've avoided doing so far. Throttling is a general concern, even for For |
|
It would be nice if we could somehow identify sections in the JIT code where we are making optimization decisions assuming throttling will occur, which might change in the future, or perhaps which isn't a problem at all for newer chips. It would also be nice if we could measure across a variety of hardware and make decisions based on actual performance, what hardware is most available (especially in Azure), etc. |
Agree with @tannergooding, you can only reasonably do this with checking CPUID information. https://github.com/travisdowns/avx-turbo does a wonderful job at measuring the scaling effect to the extent that it exists. While the quoted results have not been updated in a while, various PRs/Issue (including my own) report results for modern processors: Just to be a little more helpful, the way I parse these results/gists is by comparing the measured frequency for
Granted, 4505Mhz < 4684Mhz, but this is the worst it gets, on the earliest processors where Intel fixed their game, for the worst offender instructions (power-wise). To me this looks like a non-issue from a specific generation onward. |
|
Thanks for the inputs Everyone!! Since this PR unblocks the TE regression I'm going to merge it and since we have a plan to enable AVX-512 in other places I guess we'll have to come up with some univeral heuristic or something like that. Presumably the issue is still here but this PR just narrows the range where we use AVX-512 ( |
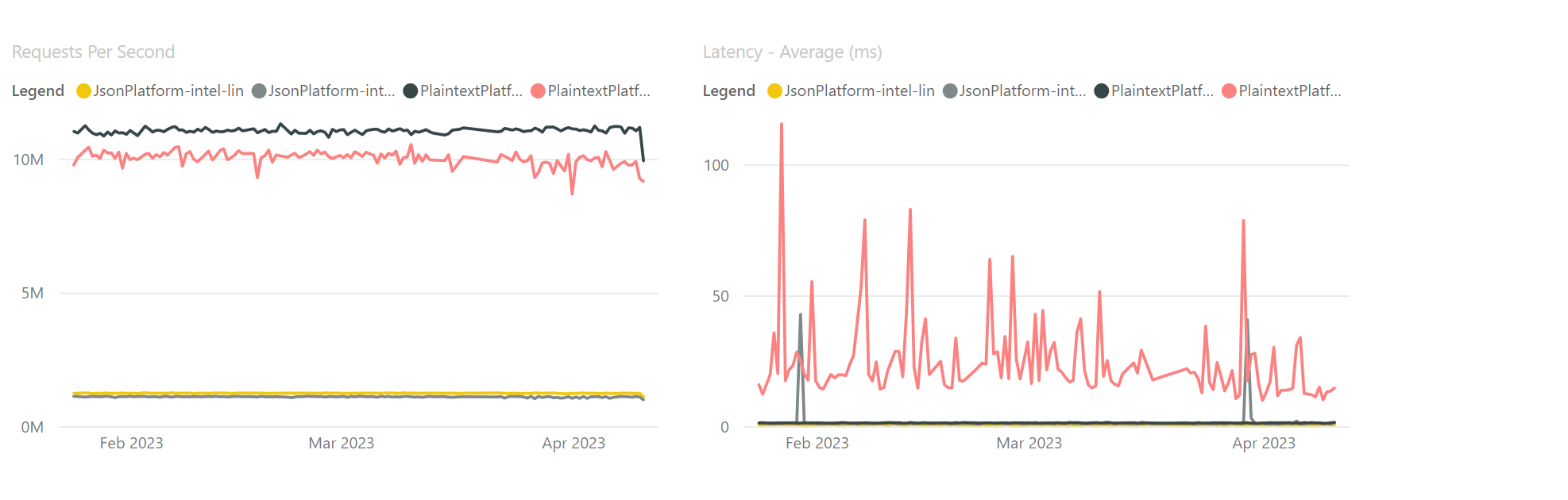
I noticed that my PR #84348 regressed TE benchmarks
I assume that our hardware for these benchmarks matches the official TE hardware which is
CPU Intel Xeon Gold 5120- a Q3'17 SkylakeX where, presumably, AVX-512 first appeared. Presumably, most AVX-512 instructions have high power licenses on that CPU and can lead to throttle on extensive use. I validated that my change fixes RPS issue on that hardware, but I'm not sure it's the right fix, should we somehow check that the current CPU is modern enough to freely use AVX-512? As far as I know, LLVM switched to "prefer 256bit vectors" because of the same issue - https://reviews.llvm.org/D67259 (Although, if e.g.-mcpu=znver4set - it will use 512)I still enabled
129..256range for unrolling because without AVX-512 we'll fallback to memmove call - I validated that this PR fixes the RPS issue and it's back to normal (even makes code faster than the base in my local runs)PS: CoreCLR GC uses AVX-512 in VXSort to sort card tables and I think I saw perf improvements when I disabled AVX-512 there too.
cc @dotnet/avx512-contrib