Real-time fraud detection pipeline for financial transactions using Kafka, Spark Structured Streaming, PostgreSQL, Isolation Forest, Grafana, and Streamlit.
This project simulates transactions, detects anomalies, stores them in a database, and provides both real-time dashboards (Grafana) and machine learning insights (Streamlit).
-
Kafka Producer: generates synthetic transactions with fraud flag,
is_fraud. Learn why synthetic data is mostly used in ML model training as opposed to real data here -
Spark Structured Streaming: two consumers (transaction_consumer & fraud_consumer).
-
PostgreSQL sink: stores transactions and flagged frauds.
-
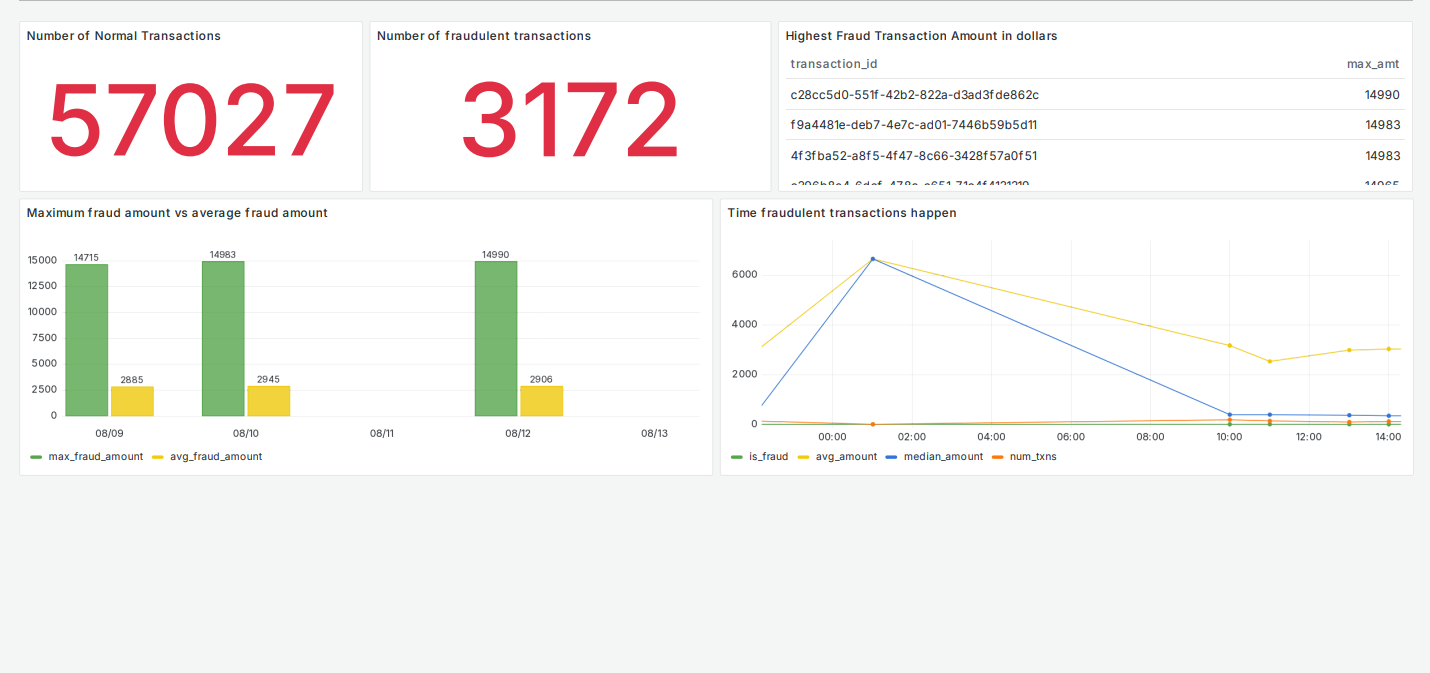
Grafana dashboards: real-time monitoring & SQL analytics.
-
Isolation Forest ML model: trained offline, saved to
jobs/isolation_forest.pkl. -
Streamlit app: visualizes model predictions & performance.
-
Docker Setup: services run end-to-end with
docker compose up.

git clone https://github.com/dkkinyua/FraudDetectionSystem.git
cd FraudDetectionSystempython3 -m venv myenv
source myenv/bin/activate # MacOS/ Linux
myenv\Scripts\activate # Windows/Powershell
pip install -r requirements.txtdocker compose up --buildThe services include:
trainer: which trains the model when runproducer: invokes the producer to write data in Kafka topictransaction-consumerandfraud-consumer: invokes the consumers to consume and write data to Postgres
The Apache Kafka used in this project is cloud-based, hosted on Redpanda. Visit their website to start configuring your Kafka cluster and topic free for 15 days with $100 credit.
streamlit run app.pyThis will run on localhost:8501 and will show the model's performance.
To access the Grafana dashboard, please follow this link


I have written a blog about this project, read it here
Do you have any questions or contributions? Please reach out to me in any of my social media platforms or open a PR request.