predict discrete problems
-
one of the classification models
-
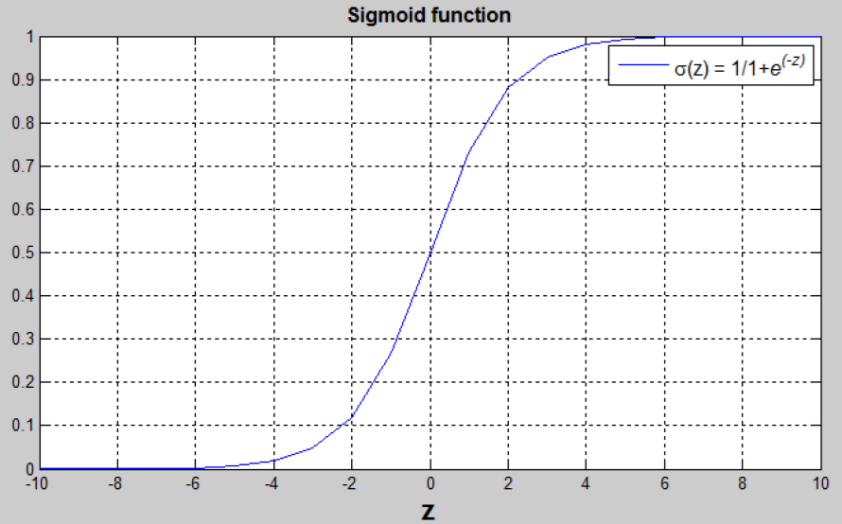
comes from LinearREgression, and nonlinearize y = wx+b to below function
-
y = 1 / 1 + e^-z , z = wx+b, y∈(0, 1)
-
if predict y > 0.5 => 1, else y => 0
-
params in logistic regression is the same as linear regression, w = coef_, b = intercept_


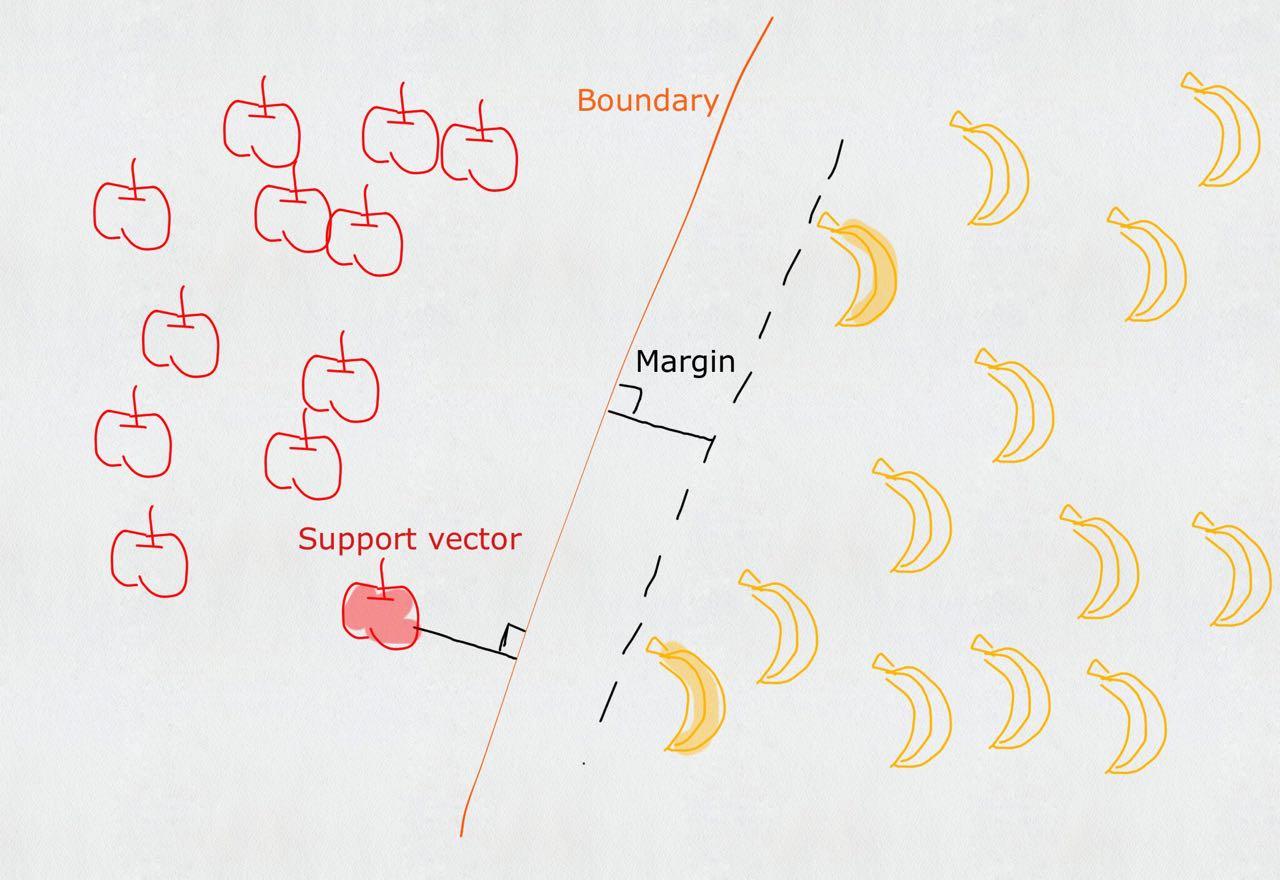
- Zhihu: reference





iris_data = pd.read_csv(DATA_FILE)
X = iris_data[FEATURE_COL].values
y = iris_data['Species'].map(SPECIES_LABEL_DICT).values
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=1/3,random_state=10)
model_dict = {
'kNN':KNeighborsClassifier(n_neighbors=10),
# 'linear_reg':LinearRegression(), # linear_reg is not a classification model, R2 the bigger the better
'logistic_reg':LogisticRegression(C=1e3),
'SVC':SVC(C=1e3)
}
for model_name, model in model_dict.items():
model.fit(X_train,y_train)
accuracy = model.score(X_test,y_test) # All the classification models give the accuracy
print('Model:{} - Accuracy:{}'.format(model_name,accuracy))
# Results:
# Model:kNN - Accuracy:1.0
# Model:linear_reg - R2:0.9063358327734319
# Model:logistic_reg - Accuracy:0.98
# Model:SVC - Accuracy:0.92

