新人用户使用指南
容器:对于建模人员,可以认为容器是一个轻量的虚拟机,一个机器可以同时启动多个容器,容器之间资源是隔离的。在平台上运行的任务,最终都会以容器内进程的形式运行在实体机上。所有容器的/mnt目录下都是自己的个人工作目录,容器重启后环境消失。
镜像:可以将容器整个操作系统的文件和目录打包成镜像,只需要解压打包好的容器镜像,容器就被重现出来了。所以我们可以用这种方式打包运行ml任务的复杂环境。
任务模板:当我们要在平台例行化运行一个ml任务(例如xgb分类),可以先定义好这个任务用到的镜像,需要什么参数,分配多少资源等信息,形成一个任务模板。以后使用的时候只需选择模板并填写相应参数即可。
任务流(pipeline): 多个任务及其依赖关系形成的DAG图。任务的构建产物可以在任务间传递。
运行实例:任务流的一次运行。
notebook:开启一个jupyter-notebook,自动挂载个人工作目录。有jupyter、vscode两种模式
登录即注册,使用新的用户名及密码登录进平台,即自动注册新用户,之后用这个用户名及密码登录即可。

注册成功后,通过右上角的个人头像-用户中心,可查看新注册用户的个人信息,比如是否激活、用户角色等等。

另一种添加新用户的方法,是在项目空间-用户列表中直接添加新用户。

同样可以设定新用户的角色、用户名、密码、邮箱、是否激活等。

可以通过更改用户角色来控制用户权限,比如这里用户角色只有gamma

该用户登录时,看不到机器资源、存储资源、用户列表等重要信息。

管理员可以通过取消用户激活来限制用户登录。

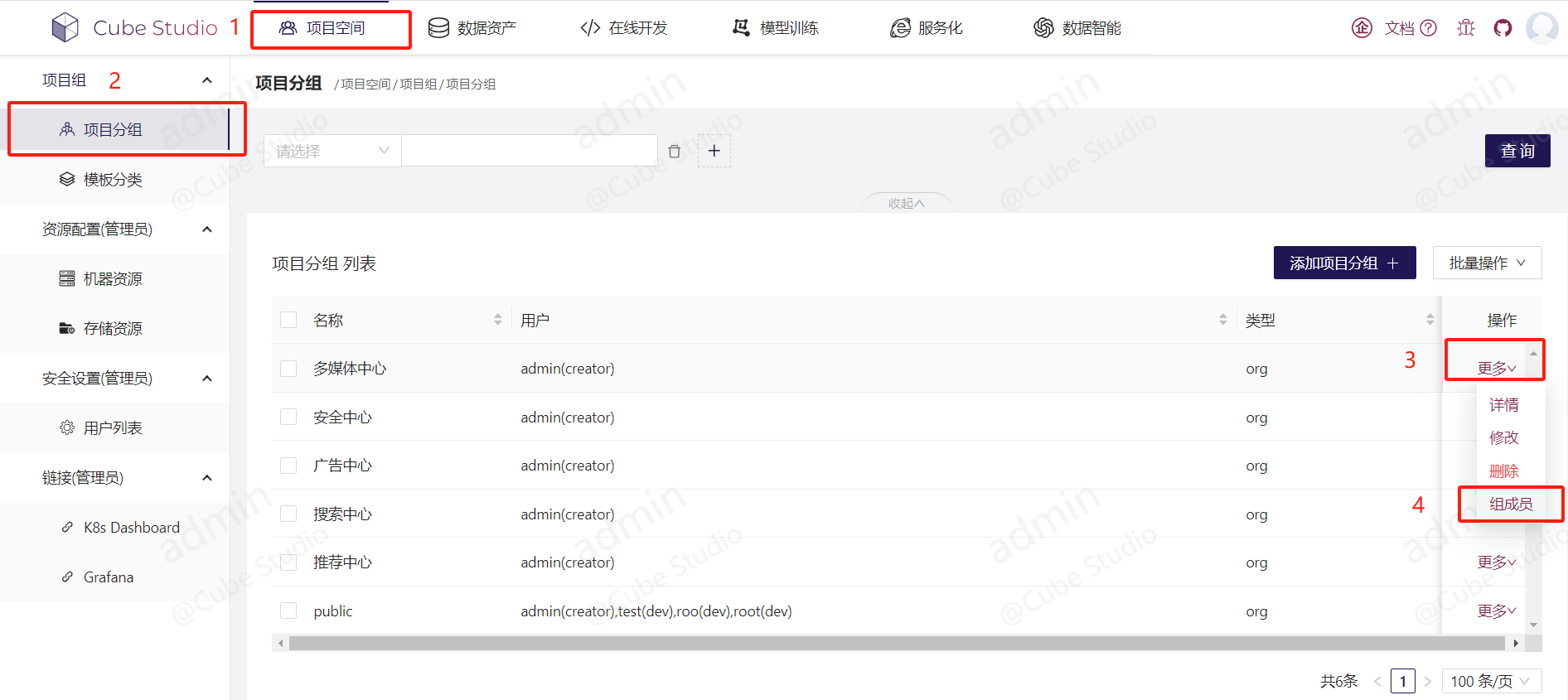
路径:项目空间->项目分组->更多->组成员,如果自己不在需要申请的项目组组成员列表中,可以联系项目组的creator将自己加入到项目组中
备注:
- 每个人自动都在public项目组中
- 可自行创建项目组
路径:项目空间->项目分组->更多->组成员->添加组成员,则creator角色的组成员可以添加其他用户进组。

添加组成员时,管理员可以选择该组成员的角色,控制组成员能接触的资源和pipeline等。

平台支持跨集群调度。需要管理员创建集群并配置到系统配置后,可通过项目组的“集群”字段控制项目组的调度集群
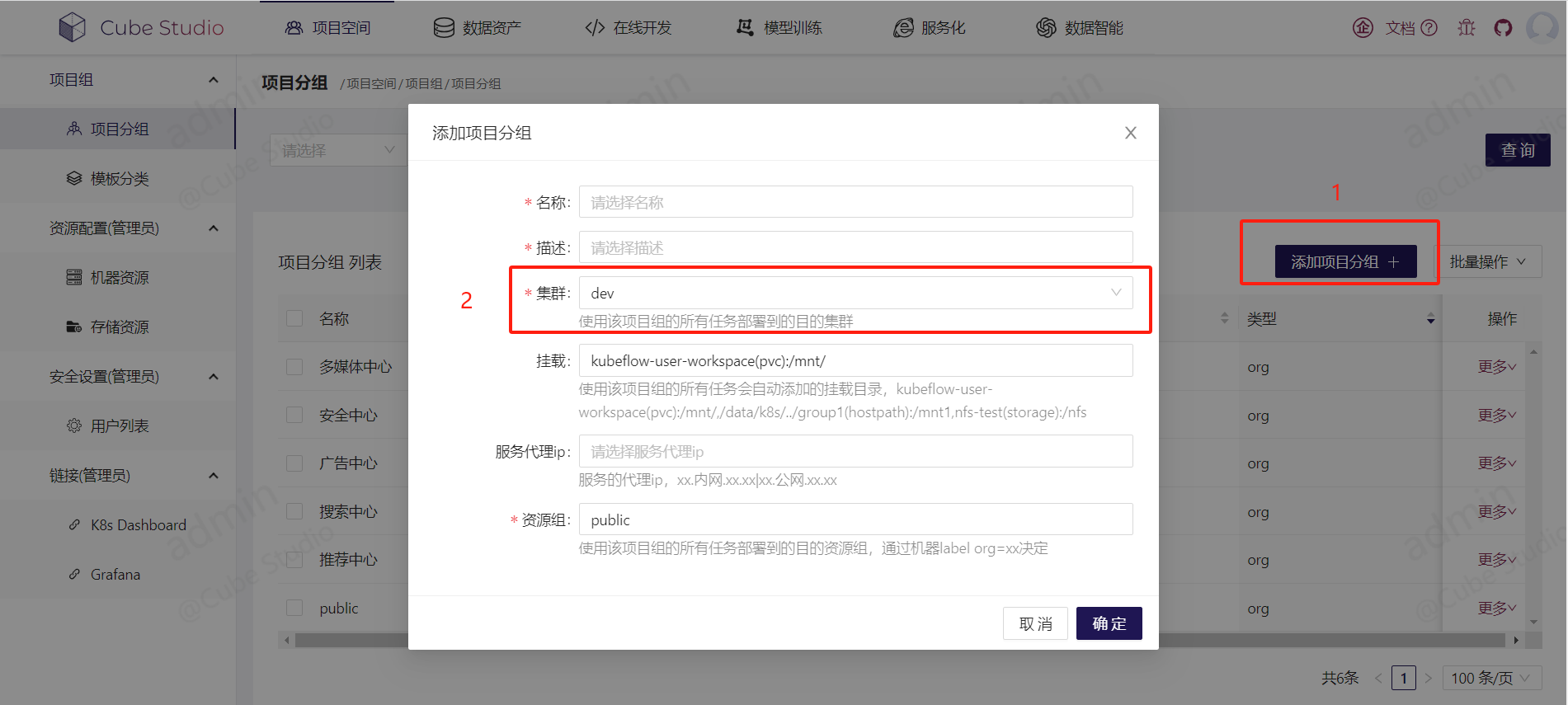
平台支持单集群中划分资源组。需要管理员配置不同机器所属的资源组后,可通过项目组的“资源组”字段控制项目组的调度机器。
项目组可以用来划分权限,同时也可以用来划分资源。一台调度机器只能划入一个资源组。如果我们单纯通过项目组来划分权限,而不划分资源,那么一个资源组就可以划入多个项目组,那么调度机器可以是不同项目组,不同机型,不同区域等划分方式,这种方式能提高我们机器的利用率,避免一个项目组不使用时,机器空闲。我们也可以用项目组划分权限的同时,划分资源,那么调度机器就只会属于一个项目组。
平台支持单集群中划分挂载。可以配置项目组下成员将自有分布式存储挂载到平台,以及项目组内共享目录等功能,可通过项目组的“挂载”字段控制项目组的挂载.
- 挂载pvc,会自动挂载pvc下面的个人用户子目录。默认挂载kubeflow-user-workspace的pvc。管理员可自行创建pvc进行挂载
- 挂载hostpath,不会自动挂载个人子目录,可以用来控制多人共享同一个公共目录
pvc和hostpath可以同时存在,实现既有个人子目录,又有公共目录。
示例:
{
"volume_mount": "kubeflow-user-workspace(pvc):/mnt/;data/aidata(hostpath):/aidata"
}
平台支持单集群中划分服务的代理ip,多用于边缘集群,或多网关情况下。可通过项目组的“服务代理ip”字段控制项目组的服务的代理ip.
- Jupyter (cpu/gpu)
- vscode(cpu/gpu)
- Matlab
- Rstudio
- 代码开发/调试,上传/下载,命令行,git工蜂/github,内网/外网,tensorboard,自主安装插件
路径:在线开发->notebook->添加notebook
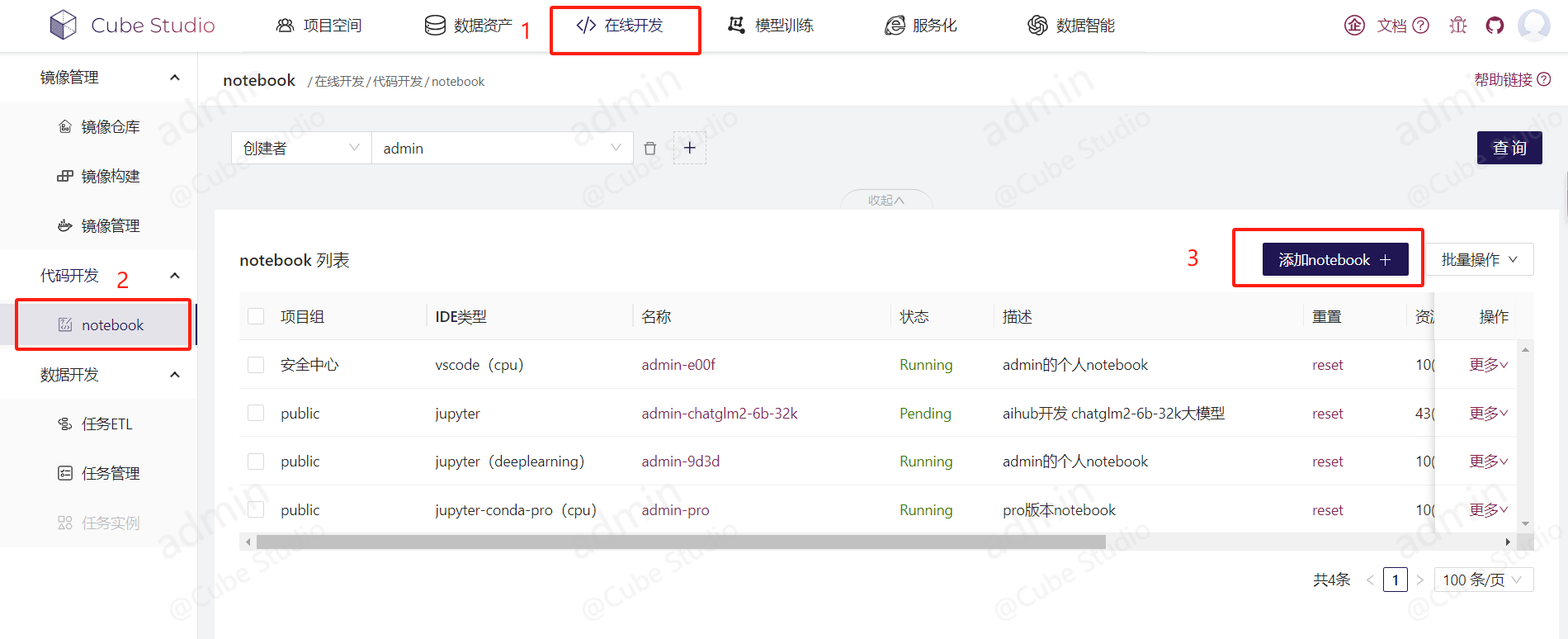
备注:
- Running状态下,方可进入,Pending状态不可
- 无法进去时,reset重新激活
- notebook会自动挂载一下目录
- a)个人工作目录到容器 /mnt/$username


使用pro版本的jupyter,在左侧目录树,进入到tensorboard对应的日志目录,再打开右侧的tensorboard按钮

在线开发->镜像构建->添加docker
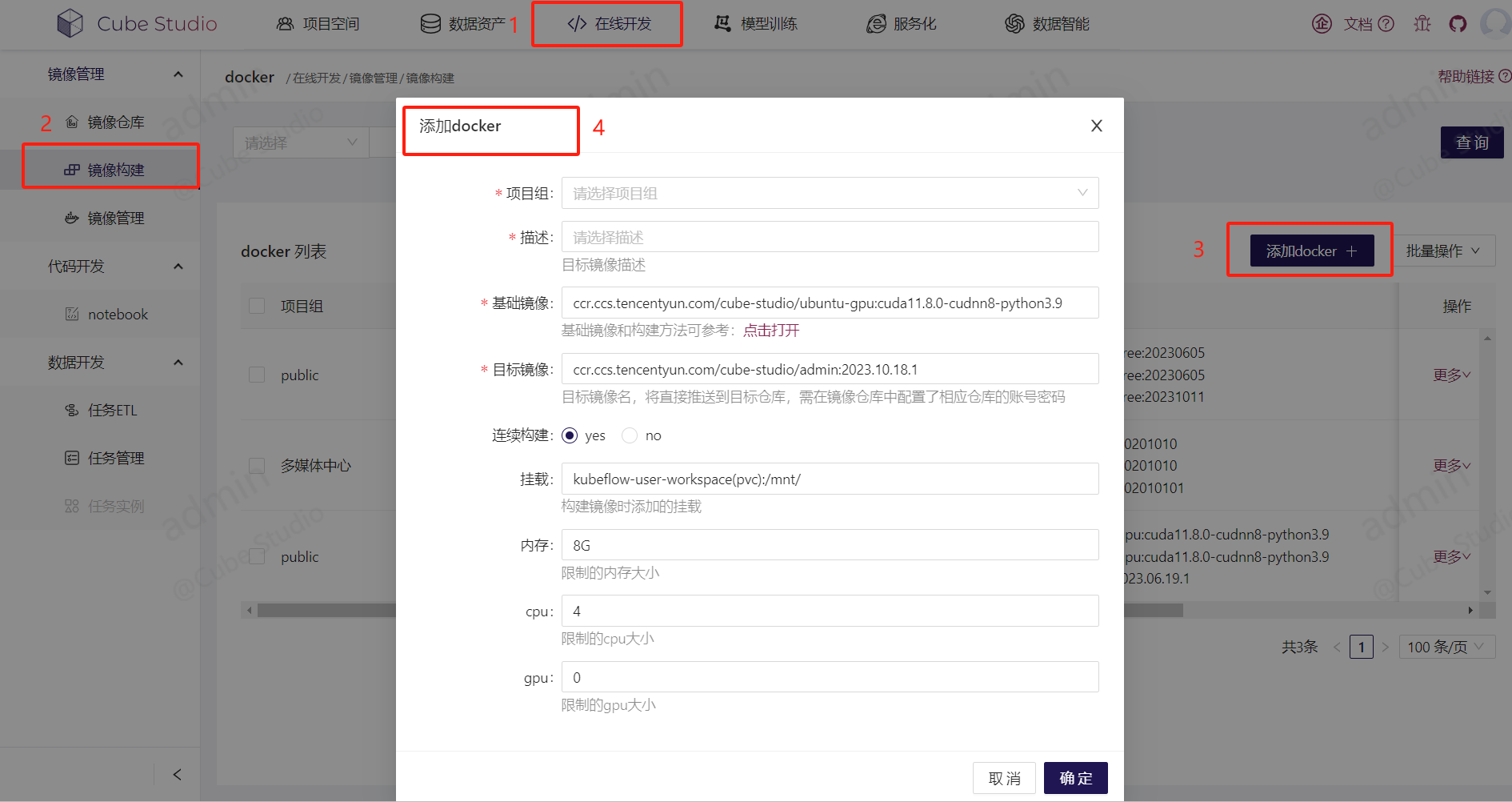
可配置基础镜像、目标镜像、挂载、内存等。
选择连续构建,可以在pod重启后,在断点处接着进行镜像构建。
路径:首页->新建流水线,或者 模型训练->任务流->添加任务流
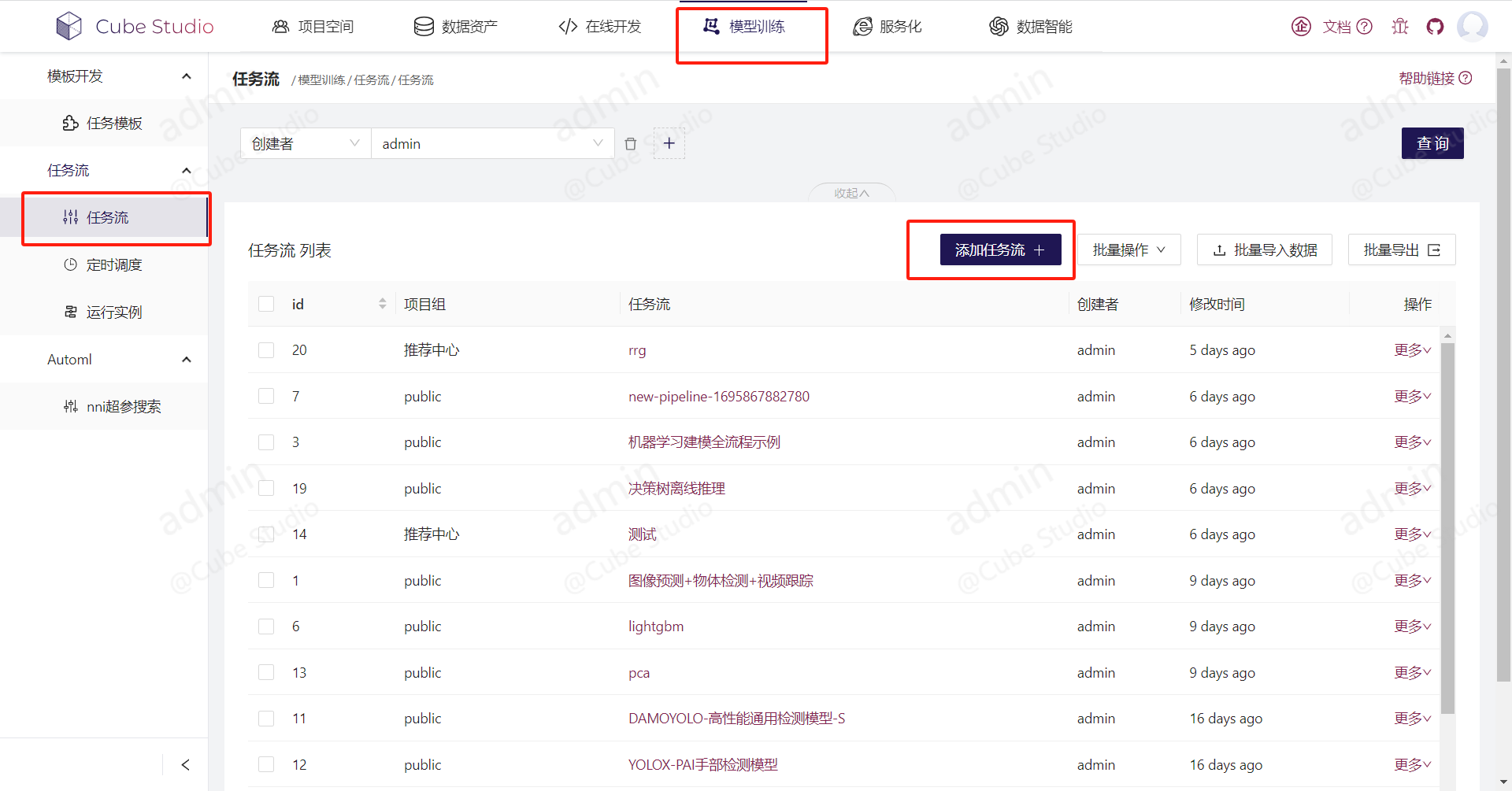
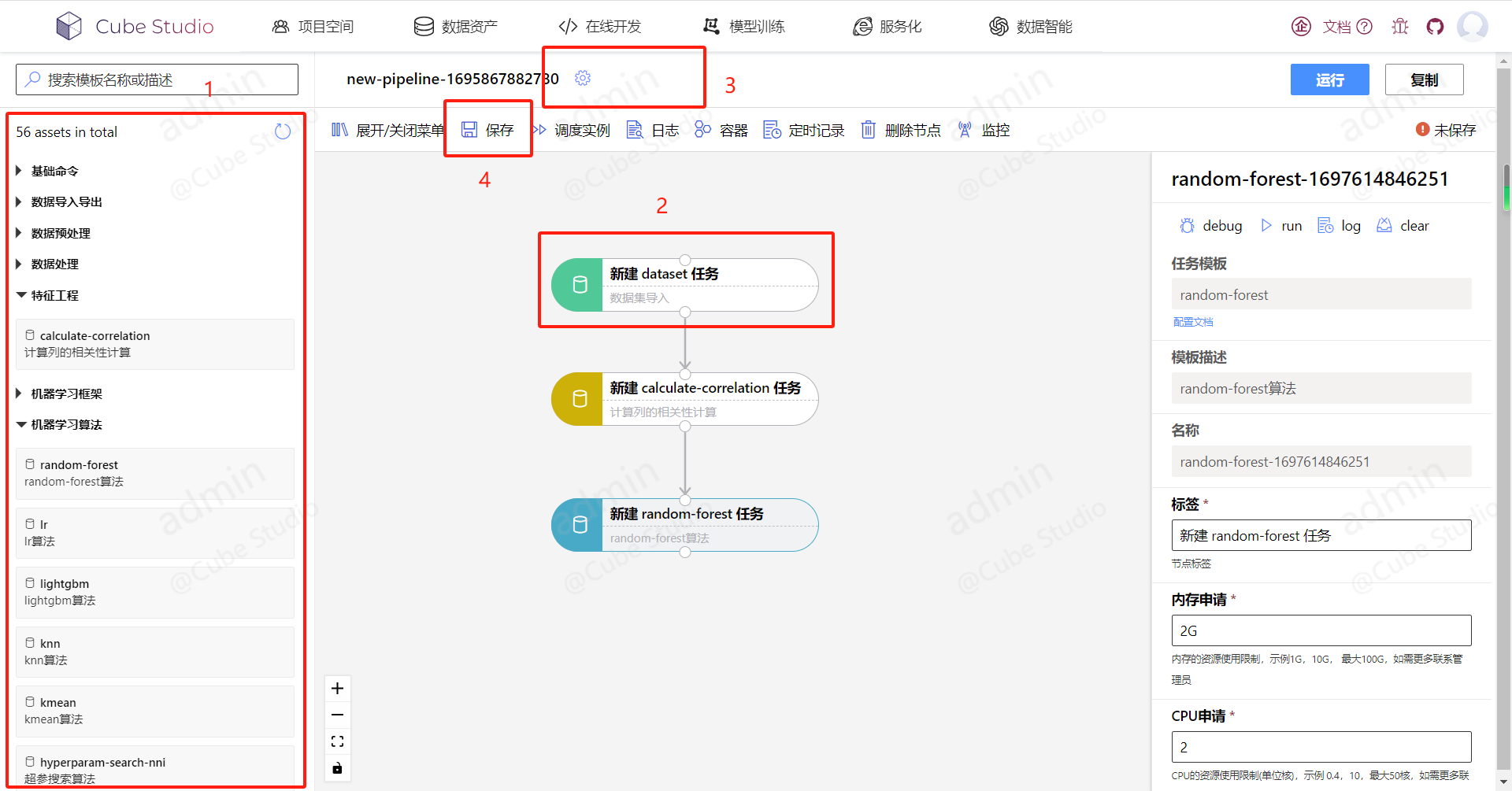
编排pipeline包括三步:
- 将右侧模板拖拉拽至面板,并按运行步骤连接好;
- 点击单个任务模板,设置任务参数;
- task公共参数:参考每个配置的描述
- task的模板参数:参考每个模板的链接教程文档
- 点击pipeline名称右边的设置按钮,设置pipeline参数,比如是否定时调度、调度周期等。
使用task的run按钮和log按钮可单独调试一个task
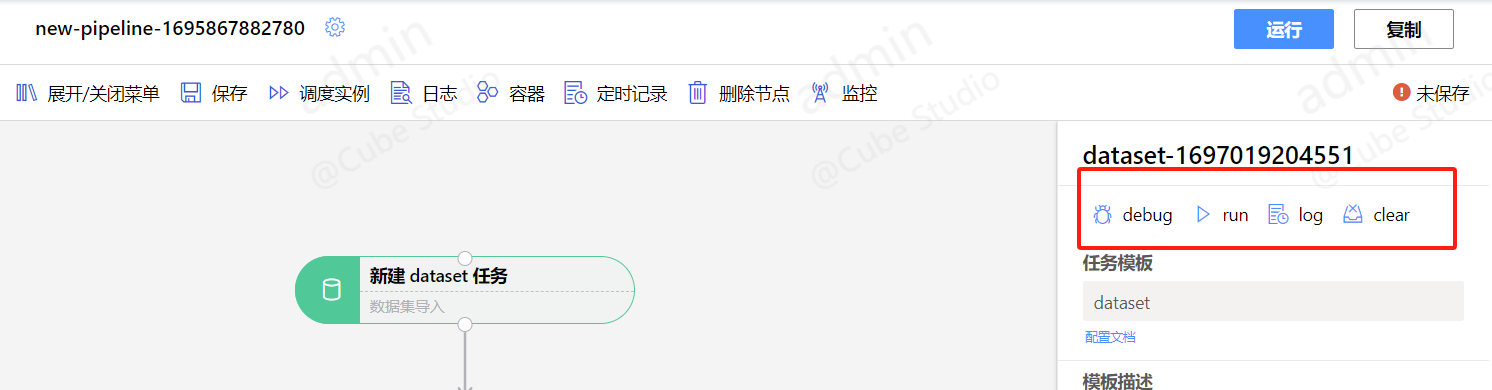
pipeline的运行按钮发起调度
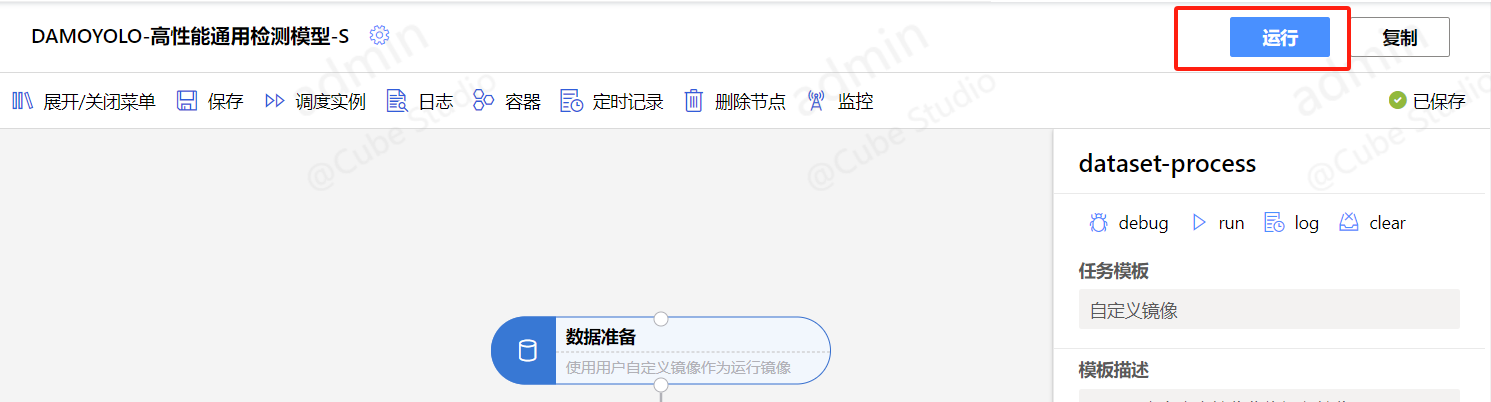
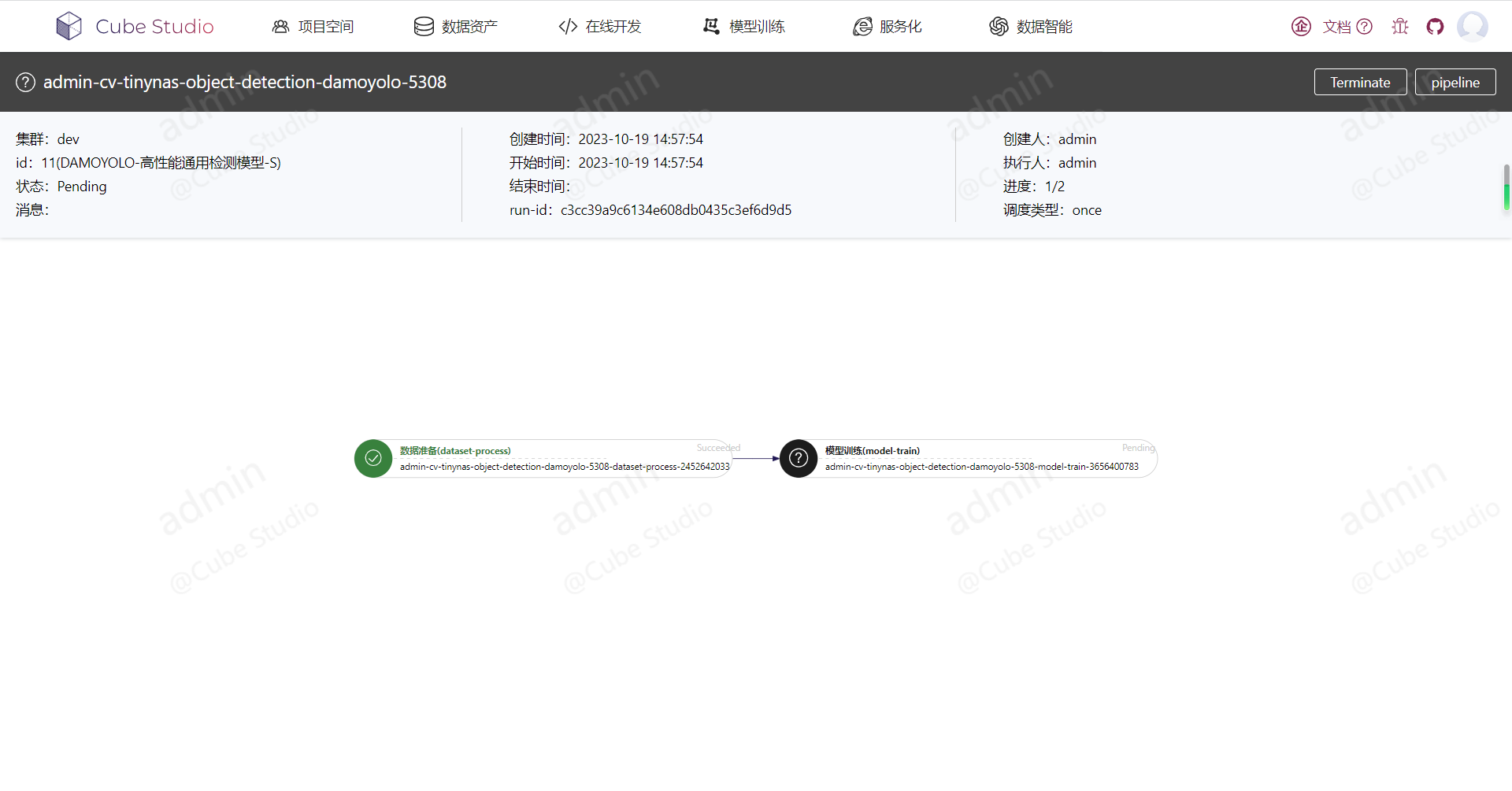
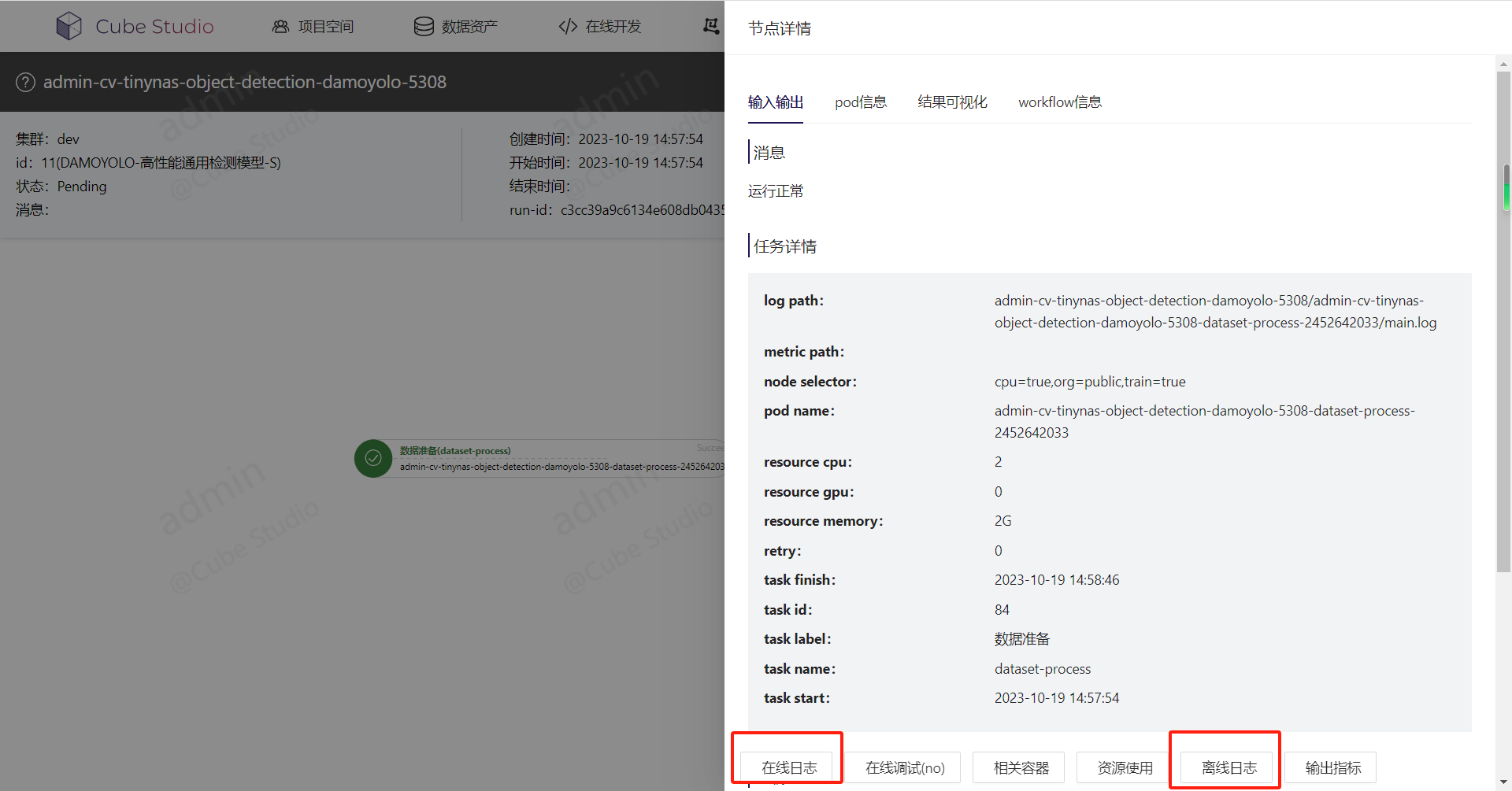

pod效果:

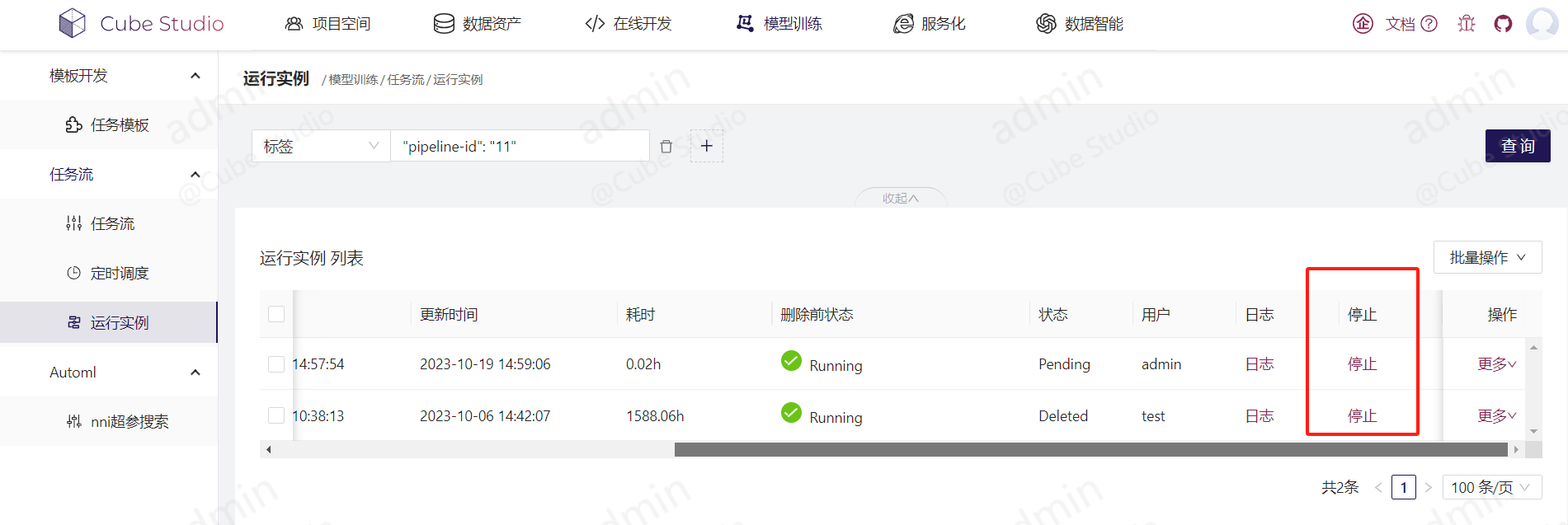
调度实例记录。停止可以清除调度容器
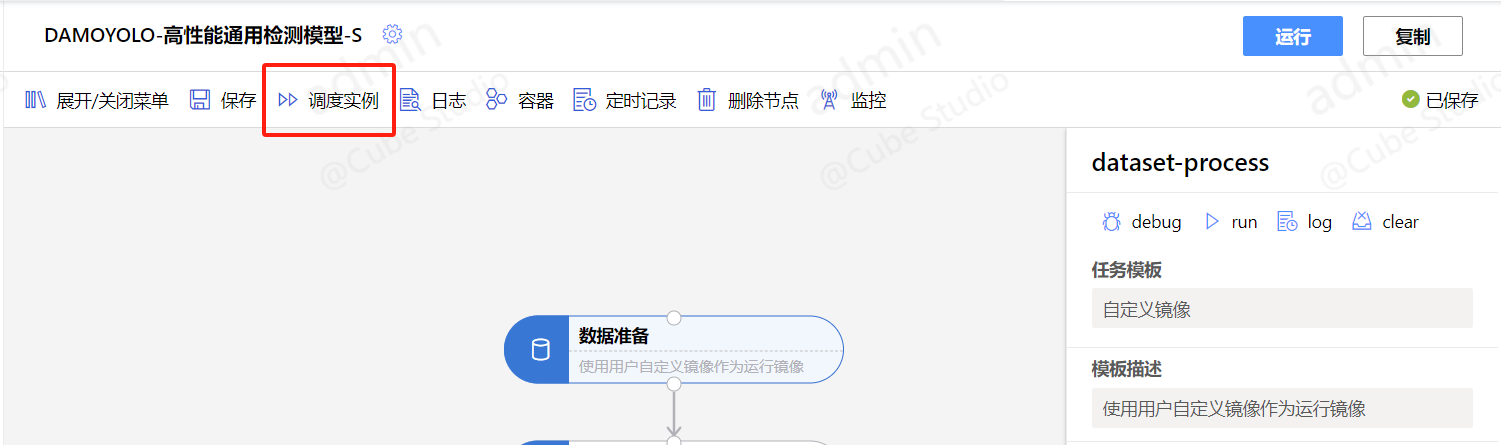
配置定时:pipeline编辑界面

查看路径:模型训练-定时调度
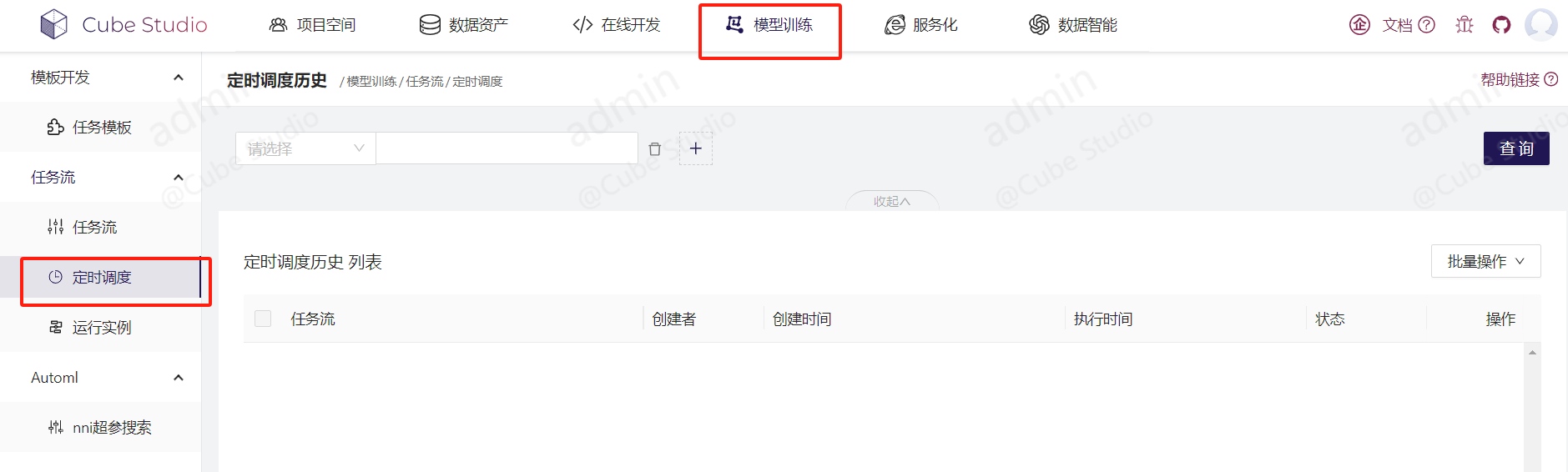
字段说明:执行时间为这个pipeline本次调度该发起的时间点
状态:comed,为调度配置已经产生。created为调度已经发起。
1、平台会根据pipeline的配置决定是否发起调度。
2、pipeline的“调度实例”中可以看到本地调度发起的pipeline的运行情况
3、pipeline的“日志”中可以看到最近一次发起的本地调度的日志
必须是标准的json。示例
{
"batch_size": {"_type":"choice", "_value": [16, 32, 64, 128]},
"hidden_size":{"_type":"choice","_value":[128, 256, 512, 1024]},
"lr":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]},
"momentum":{"_type":"uniform","_value":[0, 1]}
}
不同超参算法支持不同的超参空间
| choice | choice(nested) | randint | uniform | quniform | loguniform | qloguniform | normal | qnormal | lognormal | qlognormal |
|---|---|---|---|---|---|---|---|---|---|---|
| TPE Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Random Search Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Anneal Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Evolution Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| SMAC Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Batch Tuner | ✓ | |||||||||
| Grid Search Tuner | ✓ | ✓ | ✓ | |||||||
| Hyperband Advisor | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Metis Tuner | ✓ | ✓ | ✓ | ✓ | ||||||
| GP Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
启动超参搜索,会根据用户配置的超参搜索算法,选择好超参的可选值,并将选择值传递给用户的容器。例如上面的超参定义会在用户docker运行时传递下面的参数。所以用户不需要在启动命令或参数中添加这些变量,系统会自动添加,用户只需要在自己的业务代码中接收这些参数,并根据这些参数输出值就可以了。
--lr=0.021593113434583065 --num-layers=5 --optimizer=ftrl
业务方容器和代码启动接收超参进行迭代计算,通过主动上报结果来进行迭代。 示例如下,用户代码需要能接受超参可取值为输入参数,同时每次迭代通过nni.report_intermediate_result上报每次epoch的结果值,并使用nni.report_final_result上报每次实例的结果值。
import os
import argparse
import logging,random,time
import nni
from nni.utils import merge_parameter
logger = logging.getLogger('mnist_AutoML')
def main(args):
test_acc=random.randint(30,50)
for epoch in range(1, 11):
test_acc_epoch= random.randint(3,5)
time.sleep(3)
test_acc+=test_acc_epoch
# 上报当前迭代目标值
nni.report_intermediate_result(test_acc)
# 上报最总目标值
nni.report_final_result(test_acc)
def get_params():
# 必须接收超参数为输入参数
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch_size', type=int, default=64, help='input batch size for training (default: 64)')
args, _ = parser.parse_known_args()
return args
if __name__ == '__main__':
try:
# get parameters form tuner
tuner_params = nni.get_next_parameter()
params = vars(merge_parameter(get_params(), tuner_params))
print(tuner_params,params)
main(params)
except Exception as exception:
logger.exception(exception)
raise

可以参考:https://nni.readthedocs.io/zh/stable/Tutorial/WebUI.html
总览界面可以看到实验的id,和当前示例运行的状态


可以看每次trial的运行情况,计算出来的目标值

也可以看某次trial中每次epoch得到的结果值
1、开发你的服务化镜像,push到docker仓库内
2、注册你的服务
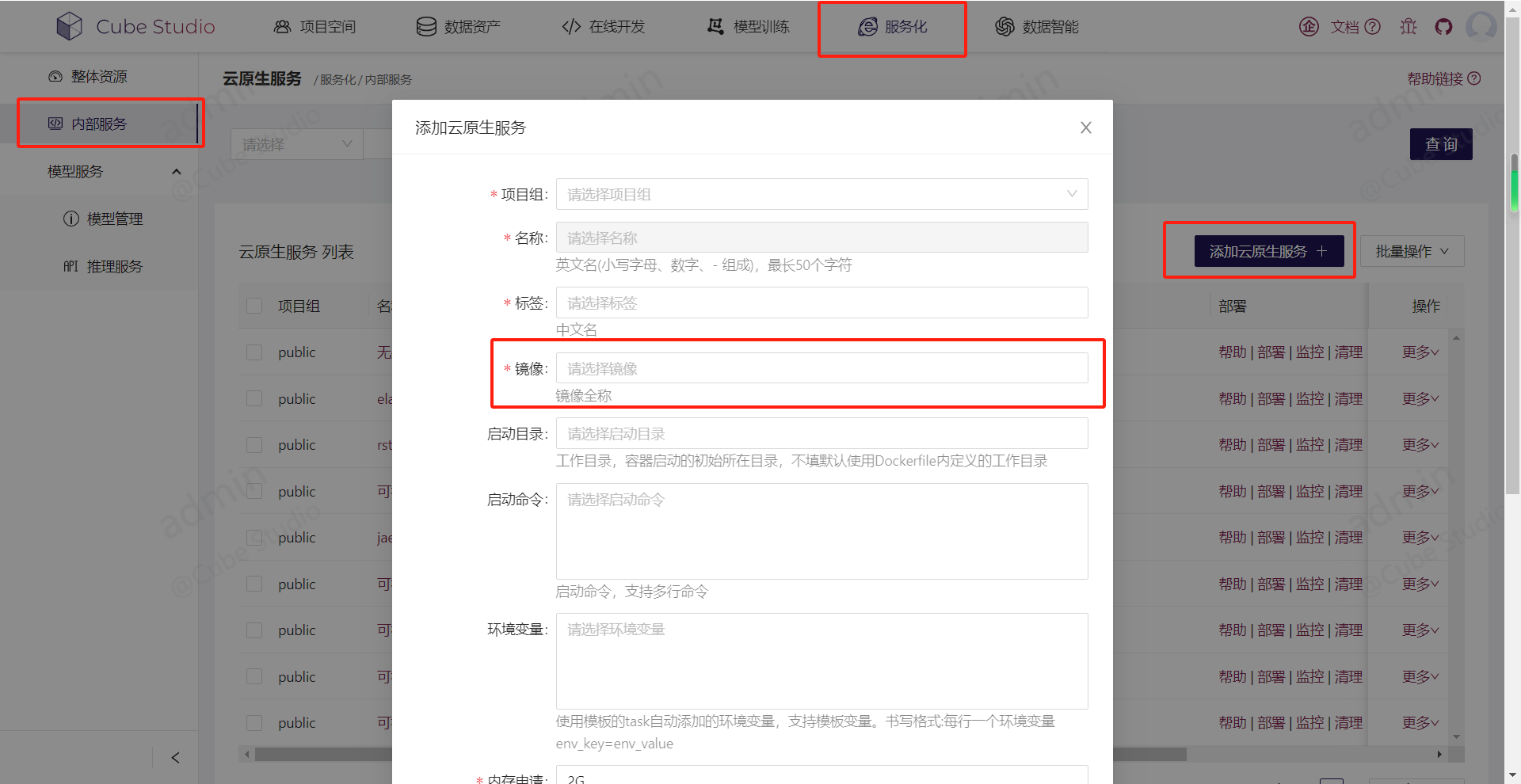
镜像:ccr.ccs.tencentyun.com/cube-studio/phpmyadmin
环境变量:
PMA_HOST=xx.xx.xx.xx
PMA_PORT=xx
PMA_USER=xx
PMA_PASSWORD=xx
端口:80
镜像:mongo-express:0.54.0
环境变量:
ME_CONFIG_MONGODB_SERVER=xx.xx.xx.xx
ME_CONFIG_MONGODB_PORT=xx
ME_CONFIG_MONGODB_ENABLE_ADMIN=true
ME_CONFIG_MONGODB_ADMINUSERNAME=xx
ME_CONFIG_MONGODB_ADMINPASSWORD=xx
ME_CONFIG_MONGODB_AUTH_DATABASE=xx
VCAP_APP_HOST=0.0.0.0
VCAP_APP_PORT=8081
ME_CONFIG_OPTIONS_EDITORTHEME=ambiance
端口:8081
镜像:ccr.ccs.tencentyun.com/cube-studio/patrikx3:latest
环境变量
REDIS_NAME=xx
REDIS_HOST=xx
REDIS_PORT=xx
REDIS_PASSWORD=xx
端口:7843
镜像:ccr.ccs.tencentyun.com/cube-studio/neo4j:4.4
环境变量
NEO4J_AUTH=neo4j/admin
端口:7474,7687
镜像:jaegertracing/all-in-one:1.29
端口:5775,16686
- 1、域名暴露需要平台配置泛域名,SERVICE_DOMAIN
- 2、ip暴露需要平台配置SERVICE_EXTERNAL_IP=[xx.xx.xx.xx],或者项目组中配置SERVICE_EXTERNAL_IP=xx.xx.xx.xx ip需为集群中节点的ip或者clb的ip
$服务名=$服务类型-$模型名-$模型版本(只取版本中的数字)

$k8s-deploymnet-name=$服务名

$k8s-hpa-name=$服务名
在最大最小副本数不一致时创建hpa

$k8s-service-name=$服务名 用于域名的代理
$k8s-service-name=$服务名-external 用户ip/L5的代理

自动配置域名需要泛域名支持。例如泛域名为domain = *.kfserving.woa.com
生产域名
http://$服务名.service.$domain
测试环境域名
http://test.$服务名.service.$domain
http://debug.$服务名.service.$domain
用户可通过host字段配置服务的访问域名,但是必须与泛域名结尾
多个服务可以配置相同的域名
多个服务(可以是相同模型或者不同模型间)配置相同的域名
1、分流属性字段控制分配多少流量到其他服务上,剩余流量归属于当前服务
2、流量镜像字段控制复制多少流量到其他服务上。但只会将当前服务的响应返回给客户端

1、同一个服务灰度升级,只需要修改服务的配置,重新部署,服务会自动滚动升级pod
2、不同服务进行灰度升级。比如同一个模型的不同版本之间,那么多个服务使用相同的域名,新部署的服务上线正常后,会自动下线同域名的旧服务。
弹性伸缩容的触发条件:可以使用自定义指标,可以使用其中一个指标或者多个指标,示例:cpu:50%,mem:%50,gpu:50%
系统携带的环境变量
KUBEFLOW_ENV=test
KUBEFLOW_MODEL_PATH=
KUBEFLOW_MODEL_VERSION=
KUBEFLOW_MODEL_IMAGES=
KUBEFLOW_MODEL_NAME=
KUBEFLOW_AREA=shanghai/guangzhou
K8S_NODE_NAME=
K8S_POD_NAMESPACE=
K8S_POD_IP=
K8S_HOST_IP=
K8S_POD_NAME=- 1、域名暴露需要平台配置泛域名,SERVICE_DOMAIN
- 2、ip暴露需要平台配置SERVICE_EXTERNAL_IP=[xx.xx.xx.xx],或者项目中配置SERVICE_EXTERNAL_IP=xx.xx.xx.xx ip需为集群中节点的ip或者clb的ip
