P2P shuffling and queuing combined may cause high memory usage with dask.dataframe.merge #7496
Description
When P2P shuffling and queueing are used together in a workload where two dataframes are merged and both dataframes are generated by rootish tasks, they can cause unnecessarily high memory usage and spilling:
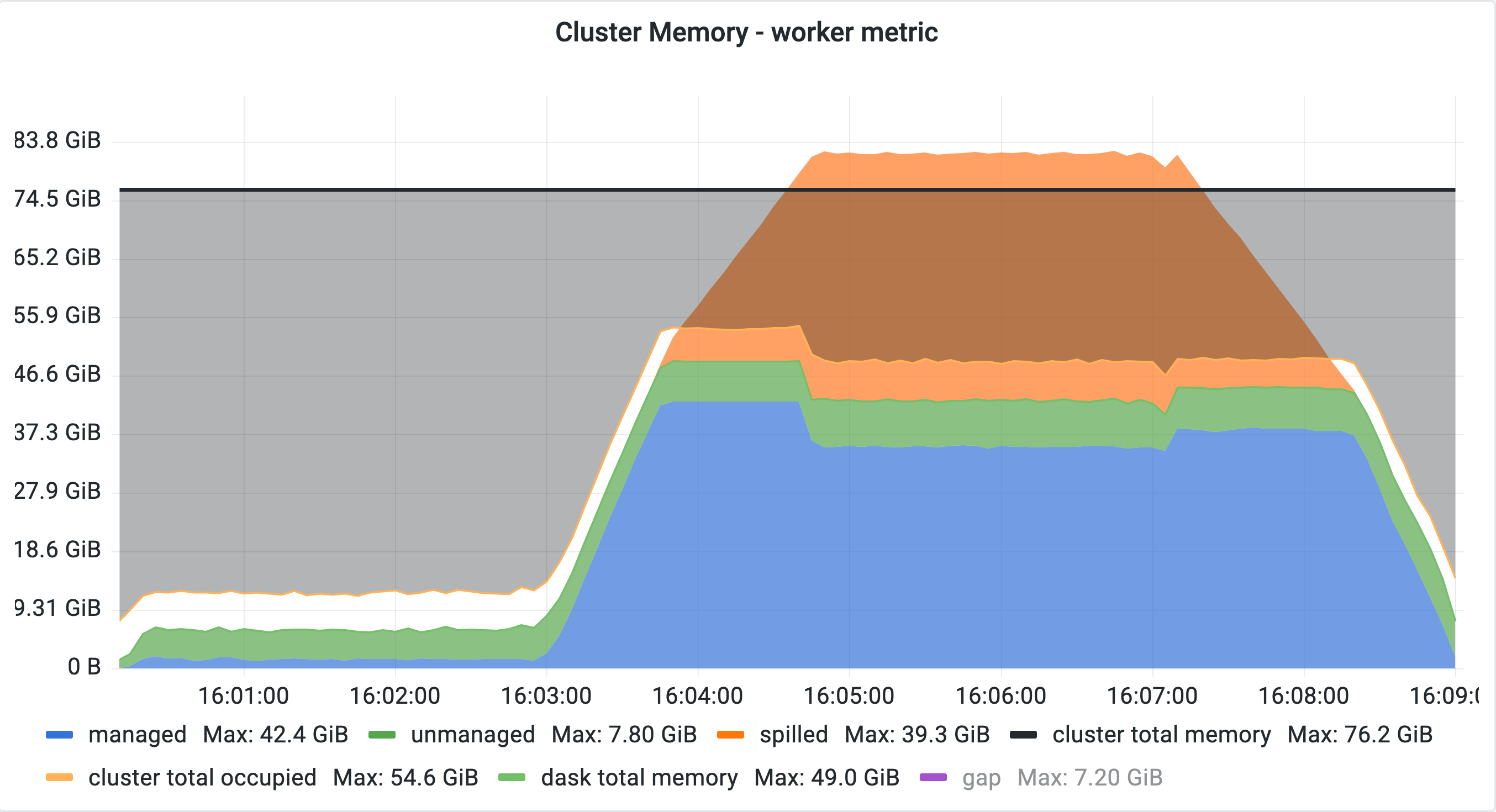
Queuing enabled:
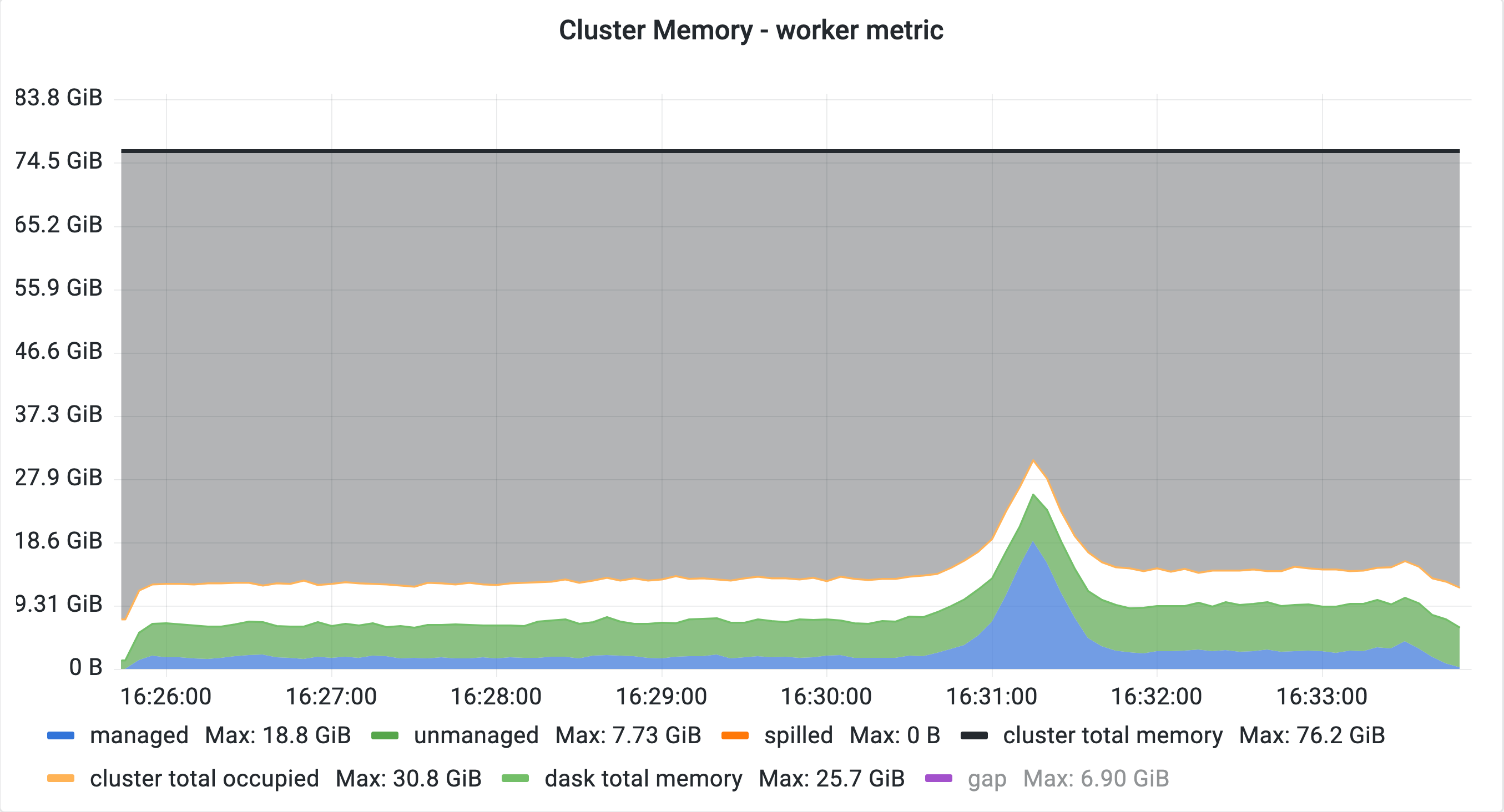
Queuing disabled:
What I expect to happen
We should first finish all transfers of one shuffle as well as its barrier, followed by a single unpack and then the transfers of the second shuffle and the second barrier as prescribed by the topological sort. Once both shuffle barriers are finished, the individual output pairs of the shuffle get read from disk, merged and handed to downstream tasks.
This is what we see without queueing.
What happens instead
All upstream tasks of both shuffles are queued. This causes the scheduler to finish one shuffle transfer followed by its barrier and immediately materialize all of its outputs. The scheduler is forced to ignore the topological sort since the inputs of the second transfer are still queued and therefore ignored while other tasks - the output tasks of the shuffle - are available for execution.
With larger-than-cluster-memory data, this can cause significant spilling, excessive disk I/O, and consequently longer runtime.
Reproducer
The plots above were generated by running test_join_big from coiled/benchmarks#645 with a size factor of 1x the cluster memory using a cluster of 10 workers. Any workload generating two dataframes using rootish tasks (e.g. by generating random partitions or reading from Parquet) and then merging those two should work.
from dask.datasets import timeseries
with dask.config.set(shuffle="p2p"):
df1_big = timeseries(
"2000-01-01",
"2001-01-01",
dtypes={str(i): float for i in range(100)}
)
df1_big["predicate"] = df1_big["0"] * 1e9
df1_big = df1_big.astype({"predicate": "int"})
df2_big = timeseries(
"2000-01-01",
"2001-01-01",
dtypes={str(i): float for i in range(100)}
)
df2_big["predicate"] = df2_big["0"] * 1e9
df2_big = df2_big.astype({"predicate": "int"})
join = dd.merge(df1_big, df2_big, on="predicate", how="inner")
await client.compute(join.size)