El objetivo de este proyecto consiste en realizar la clasificación de rostros, siendo capaz de percibir aquellos que son reales frente a otros generados mediante aprendizaje automático.
Para ello, se realiza una serie de pruebas, variando los descriptores de caracterísiticas de las imágenes, los clasificadores e incluso, el uso de una región de interés (ROI).
El conjunto de datos usado es una variante del que podemos encontrar en Kaggle, Real and Fake Face Detection, la cuál ha sido reducida la resolución de los 600px originales a 160px para facilitar el entrenamiento.
El conjunto de datos posee imágenes de caras reales (1081 muestras) y falsas (980 muestras). A su vez, los rostros falsos se categorizan de tres maneras: fácil (240 muestras), normal (480 muestras) y difícil (240 muestras).
En este proyecto, se usaron 4 formas de descriptores y embeddings : HOG, LBP, Facenet y VGG-Face.
El histograma de gradientes orientados es un descriptor que cuenta las veces en las que hay un cierto gradiente orientado el localizaciones específicas de una imagen.
En nuestro caso, este descriptor realiza una descripción de la imagen con 32 características.

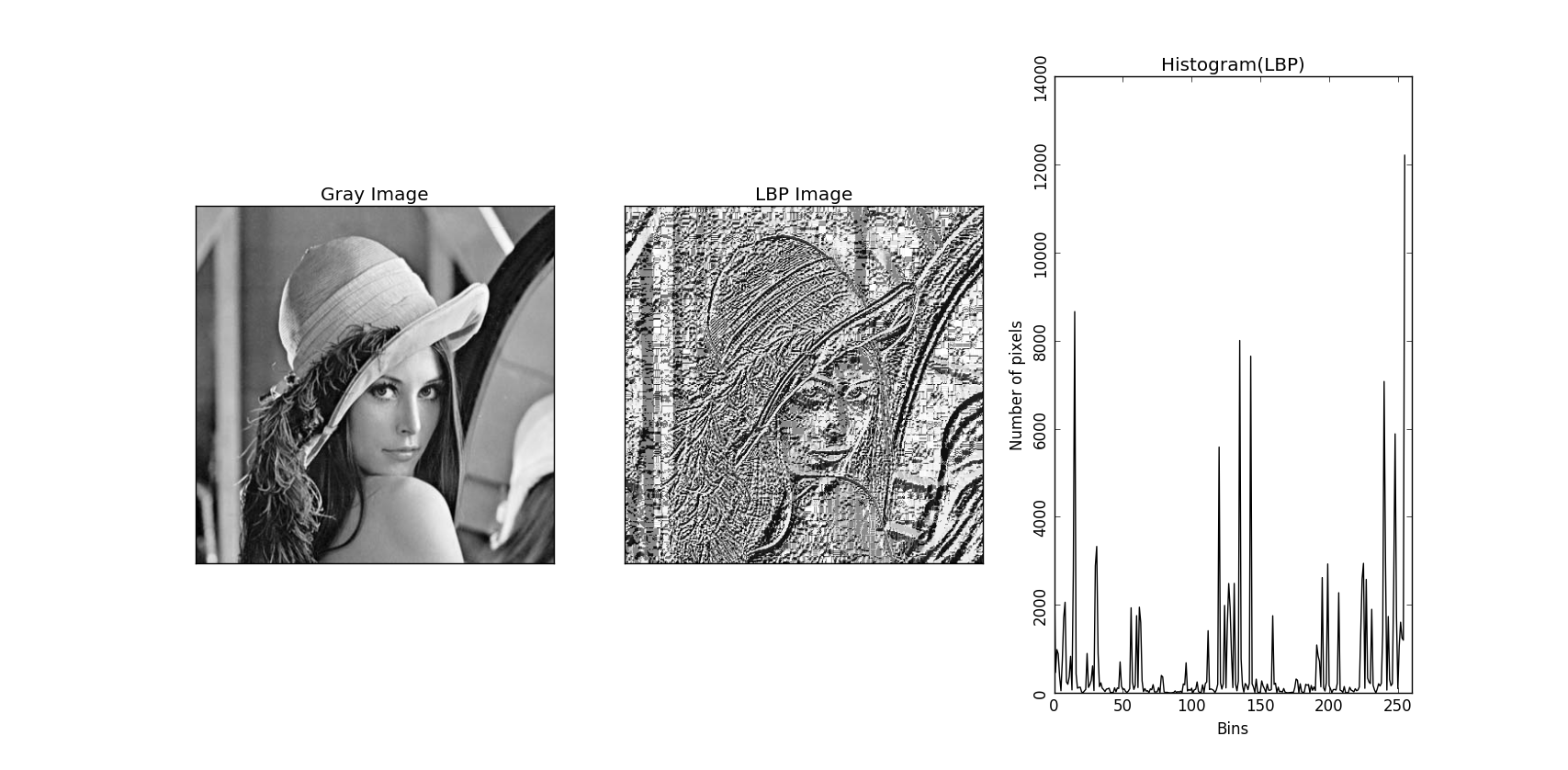
El descriptor de patrones locales binarios consiste en dividir la imagen en celdas, realziar comparaciones entre los píxeles vecinos de cada celda. A continuación, si el valor del pixel central es mayor que el de sus vecinos, se escribe un 1 y, en caso contrario, un 0. Con esta codificación, se contruye un histograma.
En nuestro caso, este descriptor realiza una descripción de la imagen con 531 características.
Facenet es una red convolucional profunda que genera unos embeddings a partir de las caras detectadas en las imágenes.
En nuestro caso, este descriptor realiza una descripción de la imagen con 128 características.

VGG-Face es una red convolucional profunda que, a diferencia de Facenet, tiene una mayor dimensionalidad.
En nuestro caso, este descriptor realiza una descripción de la imagen con 2622 características.

Las SVM o Máquinas de vectores de soporte. A grandes rasgos, SVM construye unos hiperplanos de alta dimensionalidad que separe las clases involucradas en el proceso.

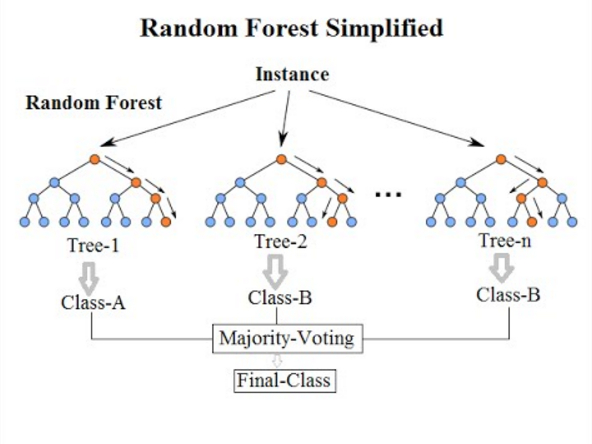
Los Random Forest o Bosques aleatorios consisten en la combinación de árboles predictores, de los cuáles cada uno obtiene una parte distinta del conjunto de entrenamiento para clasificar y, al final, se realiza una votación, en la que se decide el resultado de las predicciones.
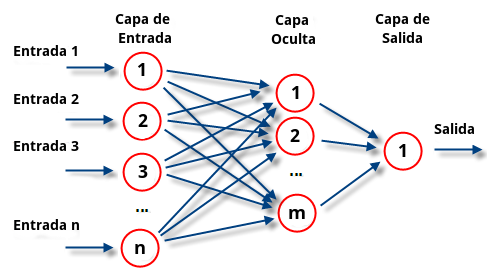
MLP o Perceptrón multicapa consiste en una red neuronal de múltiples capas que permiten superar el déficit que tiene el perceptrón para resolver: clases no linealmente separables. Este cuenta con una capa de entrada, una capa oculta y una de salida.
También conocido como validación cruzada de K iteraciones, es una técnica que permite garantizar que las particiones de entrenamiento y test del conjunto de datos sea independientes.
En este proyecto hacemos uso de K-fold con K = 5.
En una serie de pruebas, se genera una versión alternativa del conjunto de datos (presente en /roi_dataset) que trata de obtener únicamente la región de la cara, eliminándose así cosas como los detalles del fondo.
Para este fin, se usa el CascadeClassifier de OpenCV. Además, OpenCV proporciona un modelo por defecto a usar para caras frontales, el fichero haarcascade_frontalface_default.xml, evitando la necesidad de entrenar uno propio.
Con todas las técnicas y recursos mencionados anteriormente, se realizan un total de 12 pruebas (sin contar el baseline).
Dichas pruebas son:
-
HOG + SVM (Baseline)
-
HOG + Random Forest
-
HOG + MLP
-
LBP + SVM
-
LBP + Random Forest
-
LBP + MLP
-
Facenet + SVM
-
Facenet + Random Forest
-
Facenet + SVM + ROI
-
Facenet + Random Forest + ROI
-
Facenet + MLP
-
VGG-Face + SVM + ROI
-
VGG-Face + Random Forest + ROI
| Precision (%) | Recall (%) | Accuracy (%) | Time (s) | |
|---|---|---|---|---|
| HOG + SVM (Baseline) | 59.8 | 53.7 | 56.3 | 7.792 |
| HOG + Random Forest | 57.6 | 62.7 | 55.8 | 11.849 |
| HOG + MLP | 58.9 | 61.5 | 56.9 | 543.912 |
| Precision (%) | Recall (%) | Accuracy (%) | Time (s) | |
|---|---|---|---|---|
| LBP + SVM | 59.3 | 56.2 | 56.4 | 35.582 |
| LBP + Random Forest | 60.7 | 70.2 | 60.2 | 29.915 |
| LBP + MLP | 59.8 | 64.5 | 58.2 | 1413.396 |
| Precision (%) | Recall (%) | Accuracy (%) | Time (s) | |
|---|---|---|---|---|
| Facenet + SVM | 62.0 | 61.6 | 59.6 | 23.195 |
| Facenet + Random Forest | 58.8 | 70.6 | 58.3 | 21.402 |
| Facenet + SVM + ROI | 57.9 | 56.1 | 55.1 | 12.987 |
| Facenet + Random Forest + ROI | 55.9 | 66.7 | 54.5 | 21.964 |
| Facenet + MLP | 61.3 | 67.1 | 60.1 | 907.388 |
| Precision (%) | Recall (%) | Accuracy (%) | Time (s) | |
|---|---|---|---|---|
| VGG-Face + SVM + ROI | 61.9 | 58.7 | 58.9 | 184.388 |
| VGG-Face + Random Forest + ROI | 59.0 | 68.2 | 58.0 | 93.691 |
Mediante los resultados obtenidos, se puede comprobar que en este proyecto, el mejor resultado obtenido viene por parte del uso de LBP como descriptor y Random forest como clasificador ya que, aparte de poseer el accuracy más alto, también posee un buen precision y recall con respecto a otras opciones.
La opción ganadora presenta un 3.9 % de mejora presente al baseline. No obstante, hay que tener en cuenta que no se realizó ningún de tratamiento de las tres categorías de imágenes existentes: fácil, normal y difícil.
Otra nota interesante a contemplar en este proyecto es la relativa buena eficacia en general de Random forest en la mayoría de pruebas.
Como ampliación de este proyecto, sería interesante usar las categorías previamente mencionadas, además de hacer un estudio más exhaustivo sobre otras regiones de interés, como podría ser los ojos o la boca. Además, se podrían emplear más técnicas de preprocesamiento y reducción de dimensionalidad, como podría ser PCA o t-SNE, o, en lugar de convertir la imagen a escala de grises, usar algún filtro más elaborado.