- 하기 싫은
소일 거리대신 해줄 사람을 매칭 해주는 서비스 당근 알바,해주세요같은 앱을 소일거리 매칭으로 특화
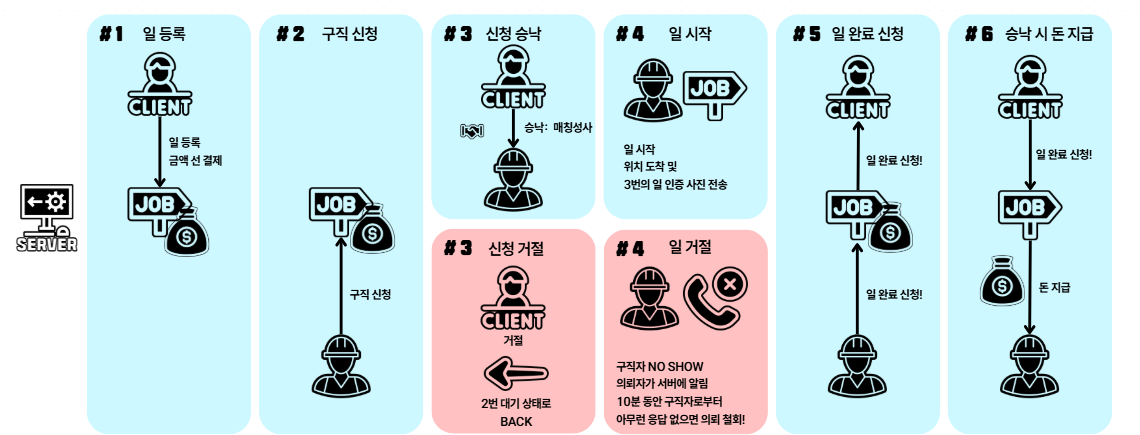
파란색: 사용자 모두 긍정적인 행동으로, 서비스를 이용 후 종료빨간색: 사용자 중 하나가 서비스 이용을 종료하는 행동을 취했을 때, 조치
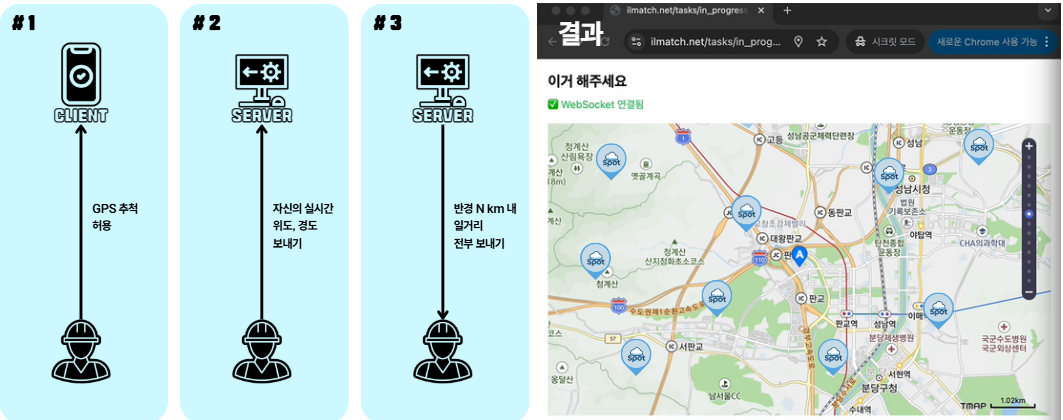

- 모든 API 요청은 계약 상대방에게
FCM 알림전송

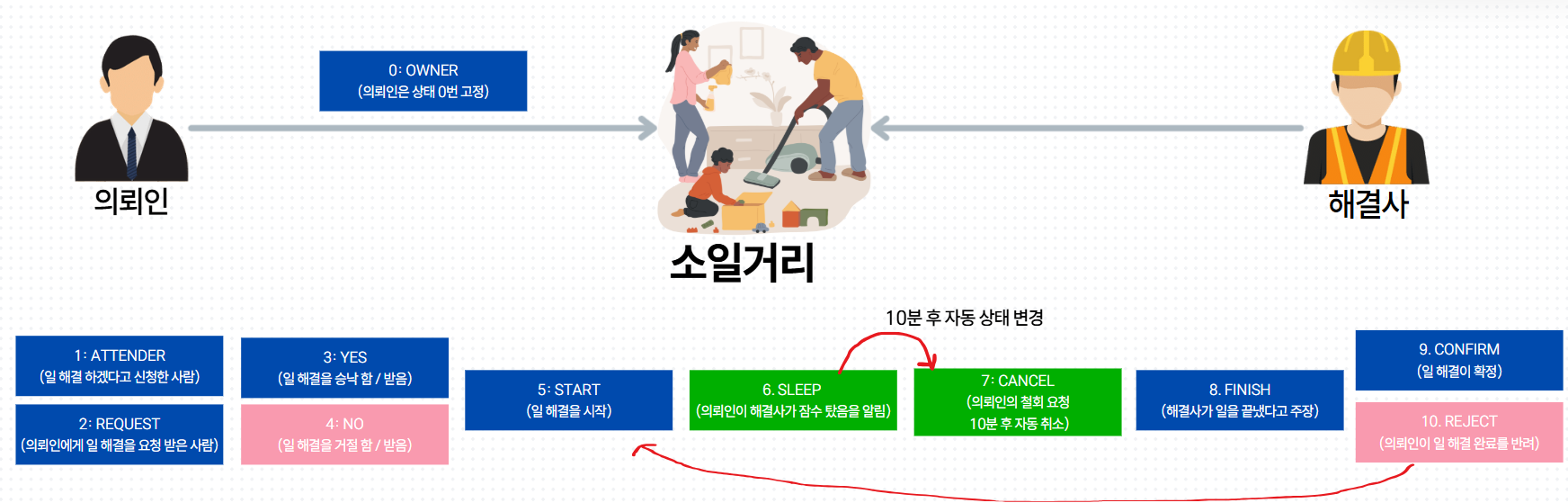
- 각 회원은 일거리에 대해서 자신만의 상태 (
MatchingStatus)를 가진다. 가질 수 있는 상태는 위와 같다.
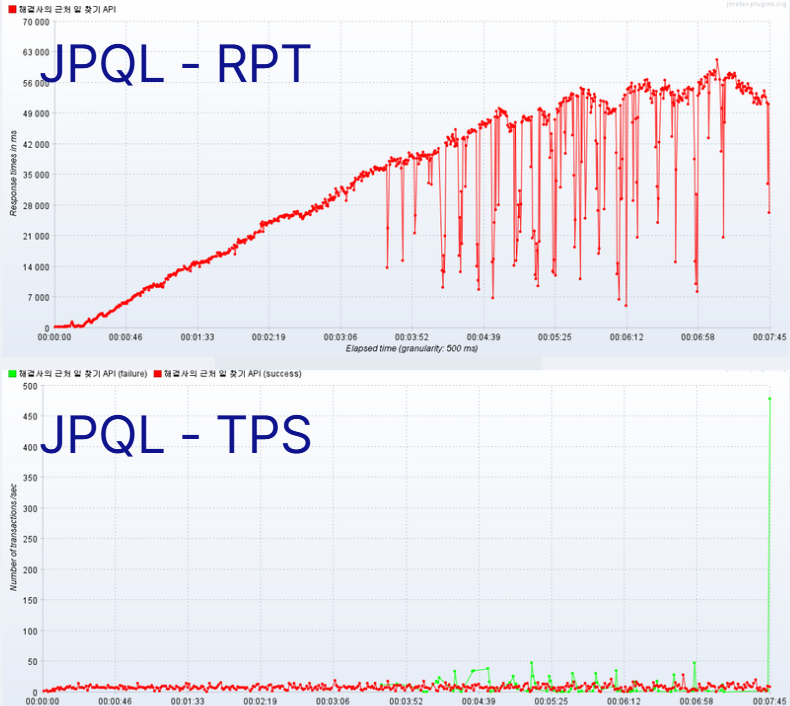
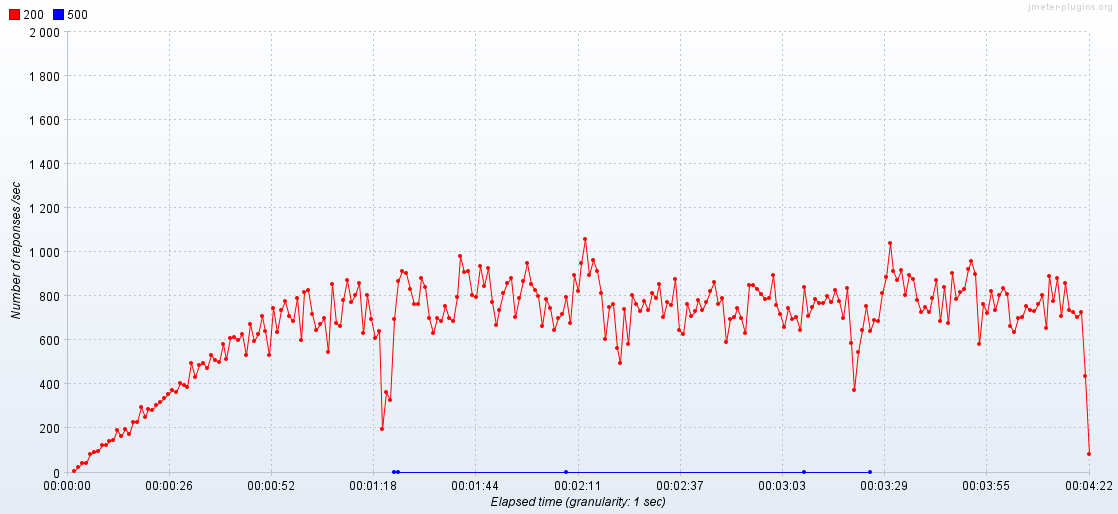
(v-user 3000명, 1000 RPS, ramp-up: 300, 10분 지속 기준)
평균 RPT: 3102ms ➜ 170ms 단축평균TPS: 200 상승
- 프론트에서 위도, 경도 전송
- Haver-sine 거리 공식 활용, table-full-scan으로 모든 일과의 거리 계산
- 페이지 네이션 적용 후 반환
전체 쿼리
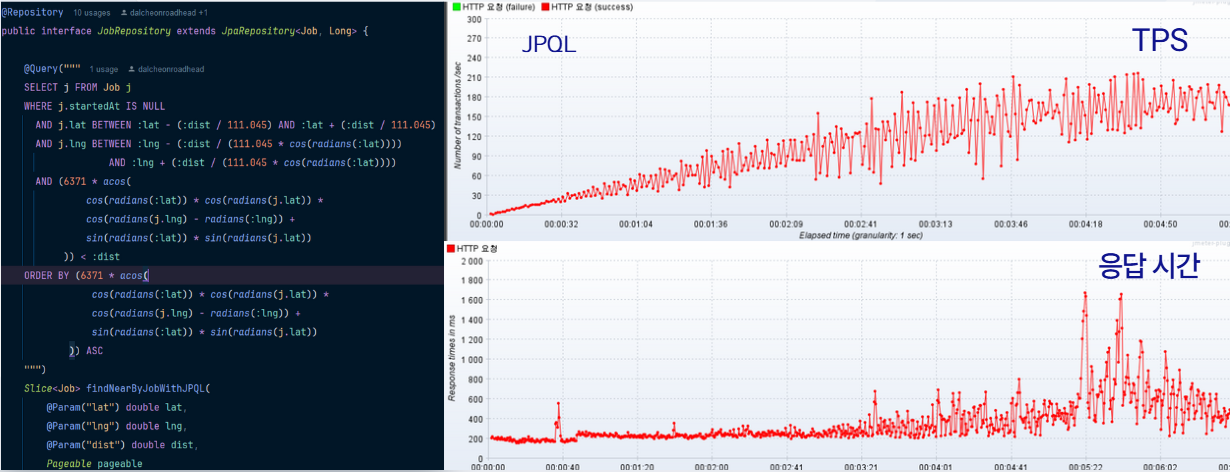
@Query("""
SELECT j FROM Job j
WHERE j.startedAt IS NULL
AND (6371 * acos(
cos(radians(:lat)) * cos(radians(j.lat)) *
cos(radians(j.lng) - radians(:lng)) +
sin(radians(:lat)) * sin(radians(j.lat))
)) < :dist
ORDER BY (6371 * acos(
cos(radians(:lat)) * cos(radians(j.lat)) *
cos(radians(j.lng) - radians(:lng)) +
sin(radians(:lat)) * sin(radians(j.lat))
)) ASC
""")
Slice<Job> findNearByJobWithJPQL(
@Param("lat") double lat,
@Param("lng") double lng,
@Param("dist") double dist,
Pageable pageable
);
대상 데이터: 회원 = 5000명, 일거리 = 5000개,Thread 수: 500,ramp-up: 300,지속: 6분 지속,페이지 머무르는 시간: 2초
- 첫 구현의 평균 RPT: 3102ms
- 부하 10분 이상 지속 시 응답 시간은 우상향을 유지
🌟결과: 평균 RPT 3102ms ➜ 403ms 단축
- 쿼리나 서버 로직을 최적화 하기 전에, 쿼리 전송 전략 최적화가 우선 되어야 한다 판단
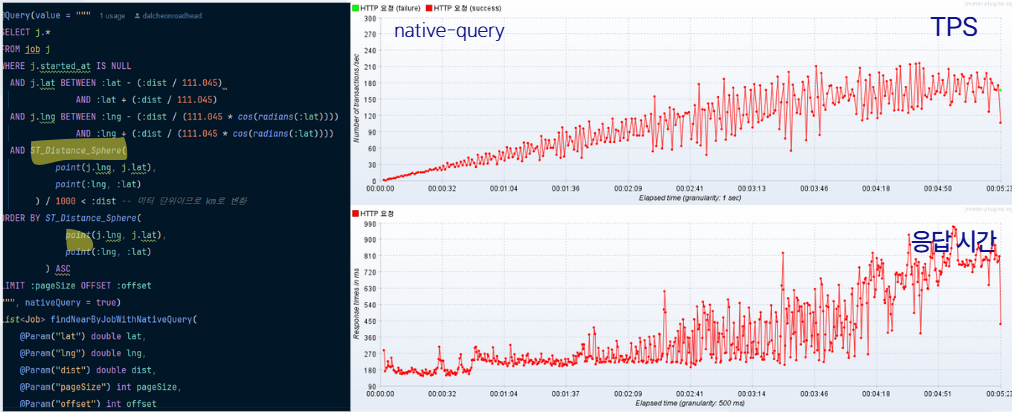
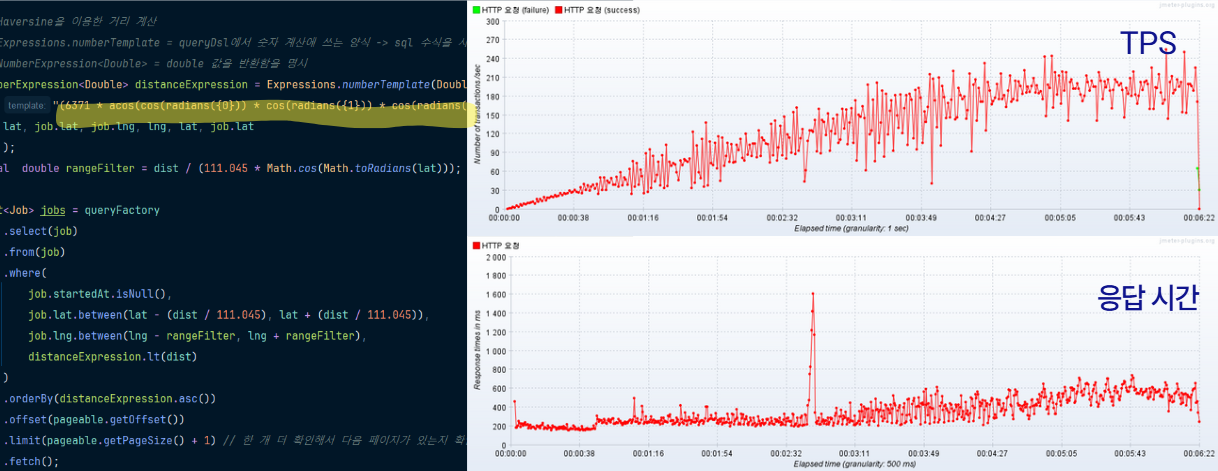
- JPQL, native-query, query-dsl로 구현 후 성능 테스트 재실시
- 테스트 결과
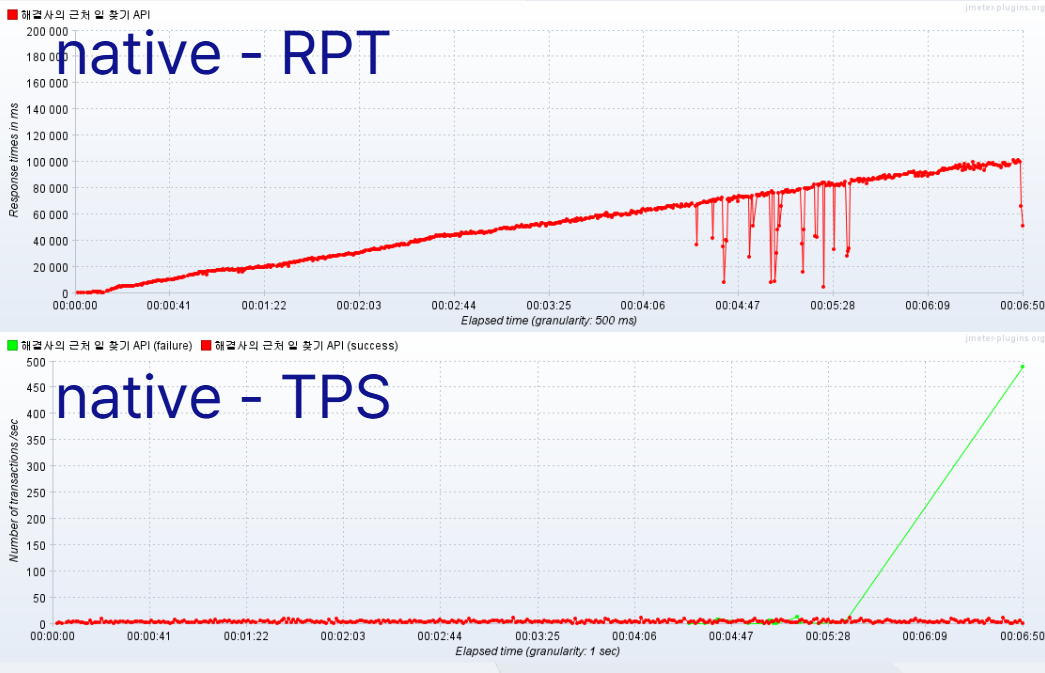
JPQL: 평균 RPT = 1040ms, 평균 TPS = 140, 지속 3분 후부터는 평균 RPT가 1.2초를 넘기며 우상향native-query: 평균 RPT = 710ms, 평균 TPS = 210, 모든 응답이 1초 이내로 들어옴query-dsl: 평균 RPT = 400ms 이하, 평균 TPS = 240
대상 데이터: 회원 = 200000명, 일거리 = 200000개,Thread 수: 500,ramp-up: 300,지속: 6분 지속,페이지 머무르는 시간: 2초
-
기존 쿼리가 ‘table full scan’ 을 타는터라 20만 데이터 추가 후 Timeout으로 인한 최대 오류율 30%, 평균 RPT 27000ms로 급증
-
위,경도 복합 인덱스를 만들어도, 옵티마이저가 table full scan을 선택해서 쿼리 개선이 안됨.
-
RDB에서 일 찾기 fullscan - O(N)➜찾은 일과 사용자 간의 거리계산 O(N)➜DTO MAPPING O(N)이라는 **O(3N)**의 시간 복잡도를 극복하지 못함. -
1차 고도화 했던 API는 RDB 데이터 양이 커지는 것과 RPT가 비례하는 모습을 보임.
-
querydsl의 경우 오류율은 없었음.
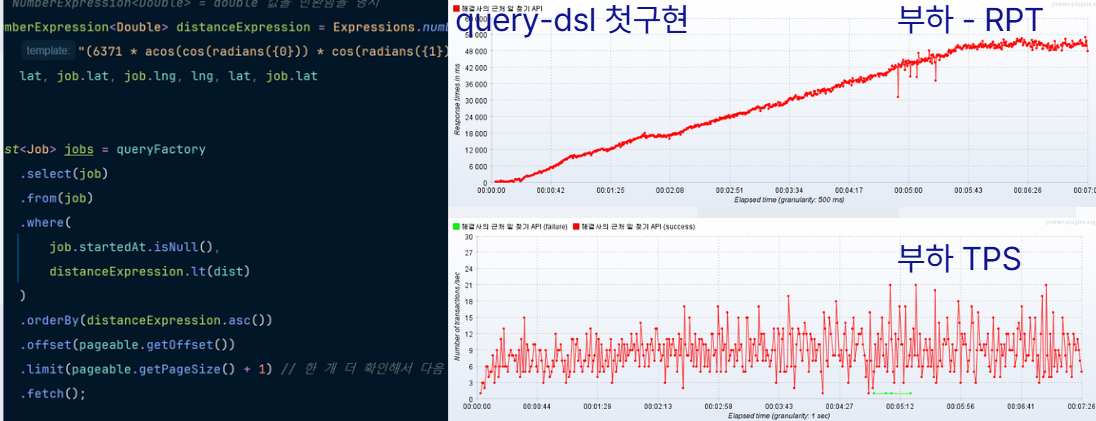
- 나머지 두 개 (1차 고도화 버전 native-query, jpql 활용 API) 또한 RPT가 데이터양과 비례에서 올라감.
- 3분이 지난 시점부터 에러율이 30% 수준으로 급증함.
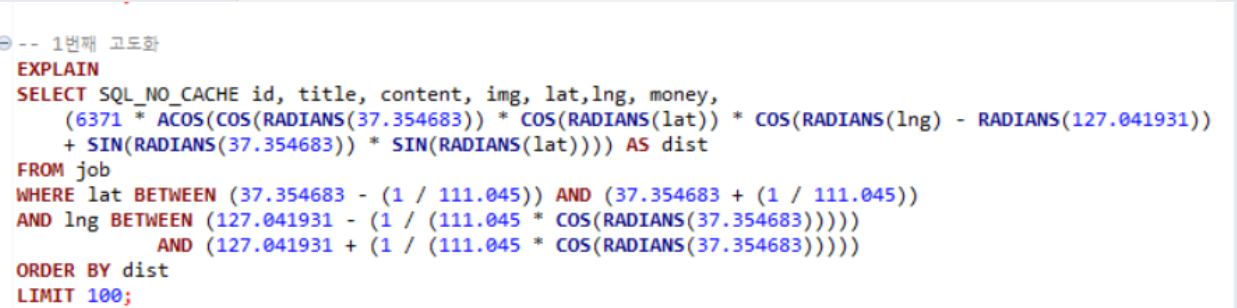
🗺️ Geo Hash원리를 쿼리로 구현 - 보조 인덱스 사용 유도 위함
- 위도, 경도를 복합 인덱스로 설정
- B-tree 인덱스를 활용하기 위해 위도, 경도와 Between문을 활용해 넓이 3KM 짜리 격자를 생성함. (Between 문에서 인덱스 활용한 1차 필터링 유도)
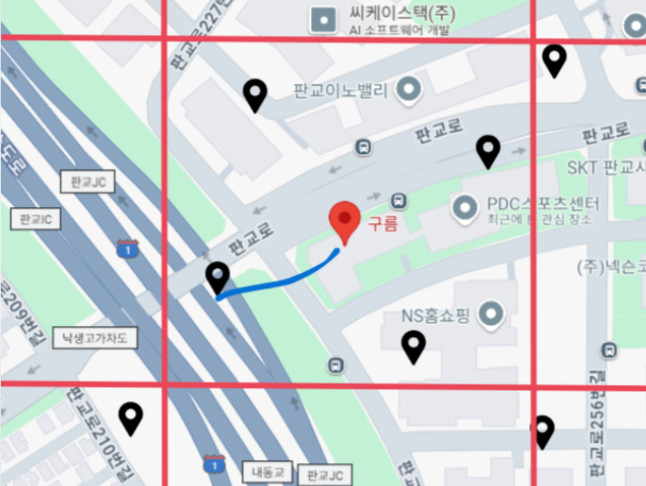
- 인덱싱을 활용해 O(M^2)이 아닌 O(logN + M) (N ➜ 데이터 접근, M ➜ 데이터 리드)를 바랬으나, 인덱싱을 활용하지 않고
FULL-SCAN을 탐.
Limit: 100 row(s) (cost=10612 rows=100)(actual time=314..314 rows=100 loops=1)
Sort: distance, limit input to 100 row(s) per chunk (cost=10612 rows=97706) (actual time=149..149 rows=0 loops=1)
Filter: (Haver-sine d 연산) (actual time=149..149 rows=0 loops=1)
Table scan on job (cost=10612 rows=97706) (actual time=0.0353..141 rows=100000 loops=1)
🧪 인덱스 강제 적용과 미적용 실행 계획 비교
- 왜 복합 인덱스를 타지 않는지 궁금
- 옵티마이저 강제 힌트를 적용해서, 실행 계획 확인
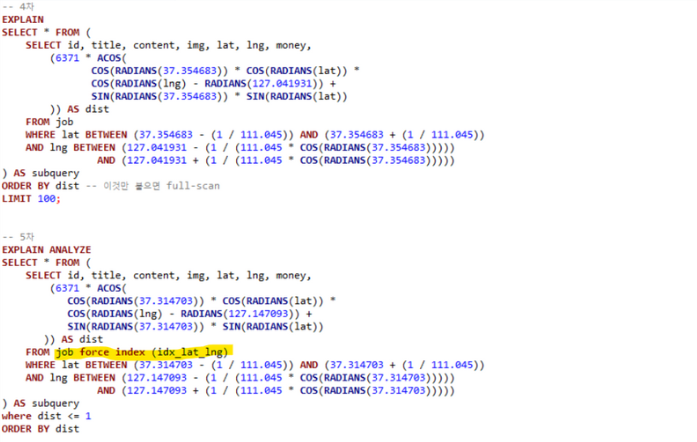

- 강제 인덱스 적용 결과, 미적용 시보다, COST는 4.5배 높지만, 실행 시간은 10배 단축됨을 확인
- 옵티마이저가 실행계획에서 랜덤 I/O 접근에 대한 비용을 과하게 잡고 있다고 판단
🧪 서브 쿼리 재활용, 미활용 실행계획 분석
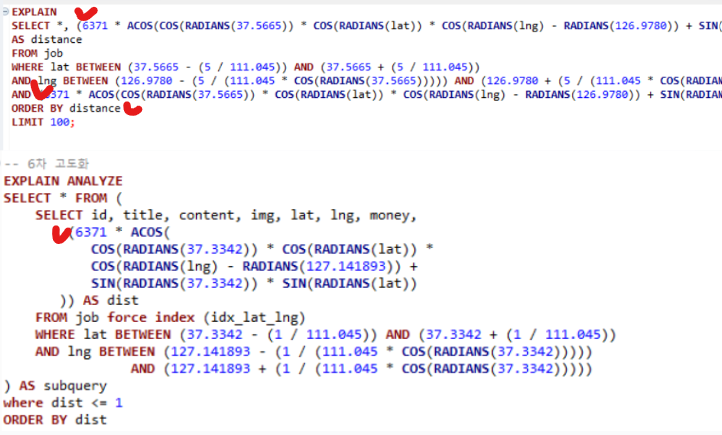
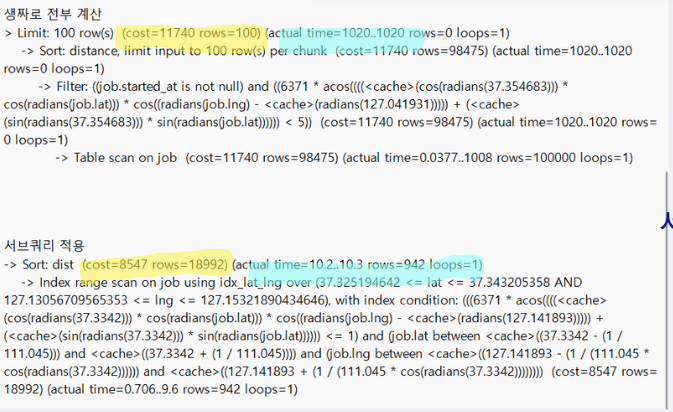
- 서브쿼리로 거리 계산 결과를 2번 재활용 하였더니, 실행 시간이 10배 빨라짐.
🌟결과:
쿼리 실행 시간: 1.2초➜ 0.0102초,평균 RPT: 27000ms ➜ 290ms평균 TPS: 100 ➜ 240
🛠️ 쿼리 튜닝
동적 옵티마이저 힌트 주입: 실행 계획을 미리 읽고, full-scan 건 수가 10만 건 이상이면 옵티마이저에 복합 인덱스 강제 적용 힌트 (미만이면 권장 적용)커버링 인덱스 생성: 복합 인덱스를 커버링 인덱스로 변경, 클러스터형 인덱스 랜덤 접근 I/O 시간 단축

- 서브 쿼리로 거리 계산문 재활용
- JPA ➜ JDBC 변환하여 영속성 캐싱 피하기
결과 사진
- 기존 1201ms의 쿼리를 10.2초의 쿼리로 단축
평균 RPT: 4000ms ➜ 290ms,평균 TPS: 100 ➜ 240
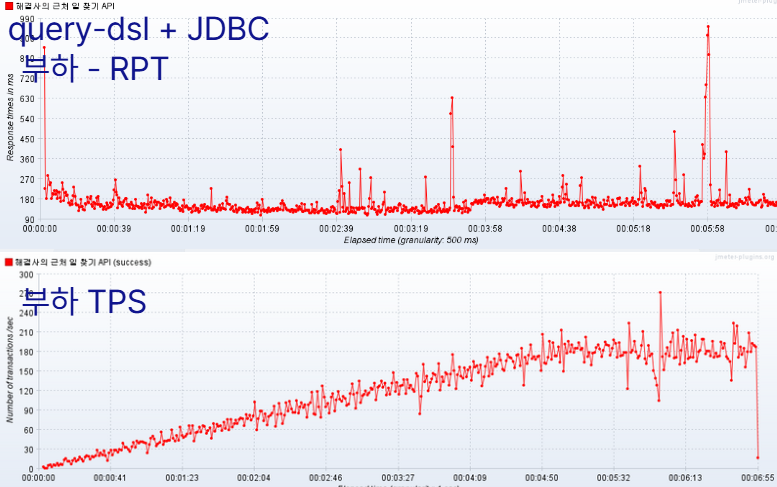
현직자 멘토링에서 다음 2가지를 지적 받음
- 강제 힌트 적용은 옵티마이저를 변형 시킬 수 있어 팀원 쿼리에도 영향을 주기에 안 좋은 개선 방향
- 속도를 위해 비즈니스 로직을 전부 쿼리에 넣는 행위는 관심사 분리를 역행하는 행위
쿼리에 대한 강제 튜닝 없이 2차 고도화 의 퍼포먼스와 동급, 그 이상을 목표로 고도화 진행
🧪 옵티마이저의 자연스러운 보조 인덱스(B+tree) 사용 시점 확인 실험
- 판교 PDC 건물을 기점으로 위, 경도 데이터 10만개를 밀집, 분산해서 DB에 넣는 행위를 30번 반복
- 힌트 없는 환경에서 언제 옵티마이저가 자연스럽게 B+tree Index를 선택하는지 확인
- 그 결과 전체의 2.33%인 데이터 (3000개) 에서만 Btween문 전에 인덱스를 활용함을 발견
🧪 R-tree 공간 객체 인덱스 적용 후 옵티마이저의 실행 계획 재확인
- 한 좌표에 10만 개의 데이터가 몰려 있는 Edge Case 가 아닌 한 전체 데이터 100%로 인덱스가 적용됨.
- COST는 강제 인덱싱 적용보다 6배 낮음, 실행 시간은 0.05초로 살짝 느렸으나, 서비스 적용엔 문제 없다 판단
- 해당 Edge Case의 경우, 300RPS만 넘겨도 DB가 다운된다.
🌟결과:
평균 RPT: 290ms ➜ 170ms평균 TPS: 240 ➜ 210
🛠️ 서버 로직 개선
- 쿼리문에 섞여있던 비즈니스 로직(사용자 - 일 거리 계산)을 서버로 분리, MapStruct + 병렬 스트림 조합 구현
- 결과 : RPT가 1초 안 쪽이긴 하지만, 2차 고도화보다 퍼포먼스가 5배 저하됨.
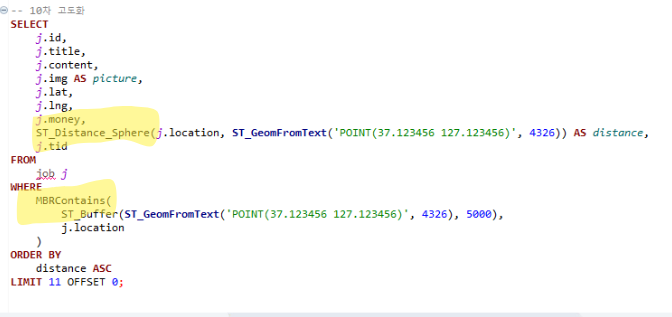
🛠️ **쿼리 튜닝 **
-
거리 계산, 반경 내 일거리 찾기에 mySQL의 공간 객체 함수 활용
-
Spatial Index 기반 R-tree 인덱스 적용
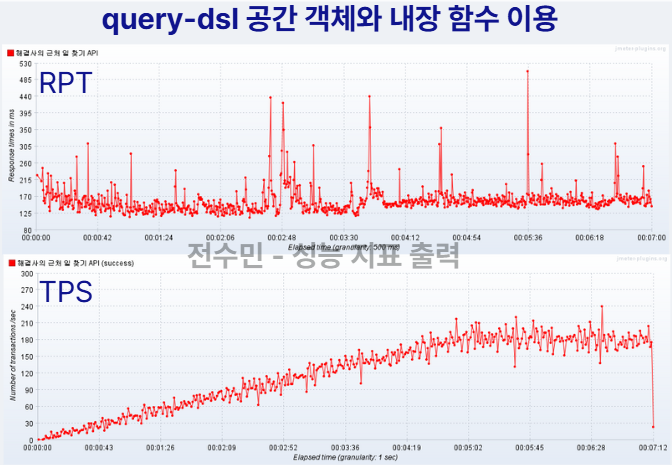
- 결과
RPT: 290ms ➜ 170msTPS: 240 ➜ 210
- R-tree 인덱스는 태생적으로 커버링 인덱스가 안됨. 따라서 O(logN)의 랜덤 I/O 접근 + O(M)의 데이터 Read 라는 태생적 시간 복잡도 한계를 벗어나지 못함
- 해당 한계를 넘어서서 RPT, TPS 성능을 높이면서도 오류율 0.0%를 유지할 방법 모색
🌟결과:
- 평균 RPT 170ms ➜ 91ms
- 평균 TPS 240ms ➜ 290ms
🛠️ 서버 개선
- AWS 기술 블로그를 보며, CQRS, DAX 등 디자인 패턴을 학습, 하지만 이런 패턴들은 MSA를 염두한 패턴이라 모놀리식에는 과하다 판단, 내장 캐싱 혹은 redis 까지만 써서, 해결 방법 모색
- L1 캐싱 (Spring 내장 Caffeine 활용) 으로 read/write-through 패턴 구현
- L2 캐싱(Redis)으로 read/write 패턴 구현
- L2 다운 시 L1이 백업할 수 있도록 조치
5000RPS를 버티며 오류율 0.0%, 시나리오 내의 모든 응답을 3초 내에 주는 서버를 만들자.
자세한 지표는 SPOT 시나리오 테스트 전체 과정 에서 볼 수 있습니다.
-
(0) 회원 중 의뢰인, 해결사 지정 후 JWT 토큰 발급 및 Jmeter에 주입
-
(1) 의뢰인이 일 등록하기 (
/api/job/register) -
(2) 해결사의 일 해결신청 (
/api/job/worker/request) -
(3) 의뢰인이 요청 승낙하기 (
/api/job/yes-or-no) ➜ 무조건 YES로 설정 -
(4) 해결사가 일 시작하기 (
/api/job/worker/start) -
(6) 해결사가 일 마침 신청하기 (
/api/job/worker/finish) -
(7) 의뢰인이 성공 혹은 반려 결정하기 (
/api/job/confirm-or-reject) ➜ 무조건 확정 -
(8) 실시간 클라이언트 활성 스레드 수


KEY WORD : 계단 식 RPS 증가, 병목 지점 및 오류 발생 지점 확인
CONFIG SETTING :
-
MAX RPS= 5000, -
RPS 증가 시점= 매 30초마다RPS 300씩 증가 -
병목지점에러율이 0% 초과할 경우응답 시간이 2초를 초과할 경우RPS > TPS인 경우
- 300 RPS로 시작하자마자 에러 발생 :
Socket Exception - Connection Reset - Hit per Second 지표를 보면 서버에 최초 300개의 요청조차 도달하지 못했음을 확인

Socket Exception이 클라이언트에서 TCP SOCET 연결 요청을 보냈지만, Tomcat Connection Pool이 가득 차 있어, 대기를 해도 지정한 시간안에 Connection을 받지 못해 발생하는 에러임을 확인- 설정 yaml 파일에서 max-count, accept-count를 각각 만 개와 천 개로 늘려서 대기큐와 max-count 개수를 맞춰줘도 해결되지 않음.
- yaml 파일 설정 변경을 아무리 해도, 위의 에러를 해결하지 못함. 따라서 테스트를 진행할 수 가 없는 상황
OS 및 WAS 모니터링
- Spring-actuator 의존성 추가 및 서버에서 처리 중인 요청 수, 전체 스레드 수, 활성 스레드 수 확인
- OS의 TCP 연결 대기큐 또한
netstat,eBPF툴을 활용해 확인 - 대기큐 크기는 10000, Tomcat 최대 스레드 수는 2000으로 했으나, 각각 128개, 200개 이상 동시 활성화되지 않음.
OS의 TCP 연결 분석
- 리눅스를 활용해, C 코드로 이루어진 OS의 TCP 연결 코드를 분석
- OS에서 3-way handshaking 과정에서 SYN+ATK를 끝낸 TCB를 저장하는 큐와 마지막 ACK까지 끝낸 TCB를 저장한느 큐가 따로 존재하고 있었음.
- 또한 각 두 개의 큐는 내부에서 사이즈를 규정하고 있었기에 yaml의 설정이 먹히지 않았음.
🌟결과: 300RPS -> 1800RPS 까지 견디는 서버 완성
- 각 OS 커널의 대기큐 크기를 최대치인 65535로 늘림
# 연결 요청 큐 크기 증가
sudo sysctl -w net.core.somaxconn=65535
# SYN 대기 큐 증가 (3-way handshake 동안 보류된 요청 큐)
sudo sysctl -w net.ipv4.tcp_max_syn_backlog=65535
# NIC 수신 대기 큐 증가
sudo sysctl -w net.core.netdev_max_backlog=65535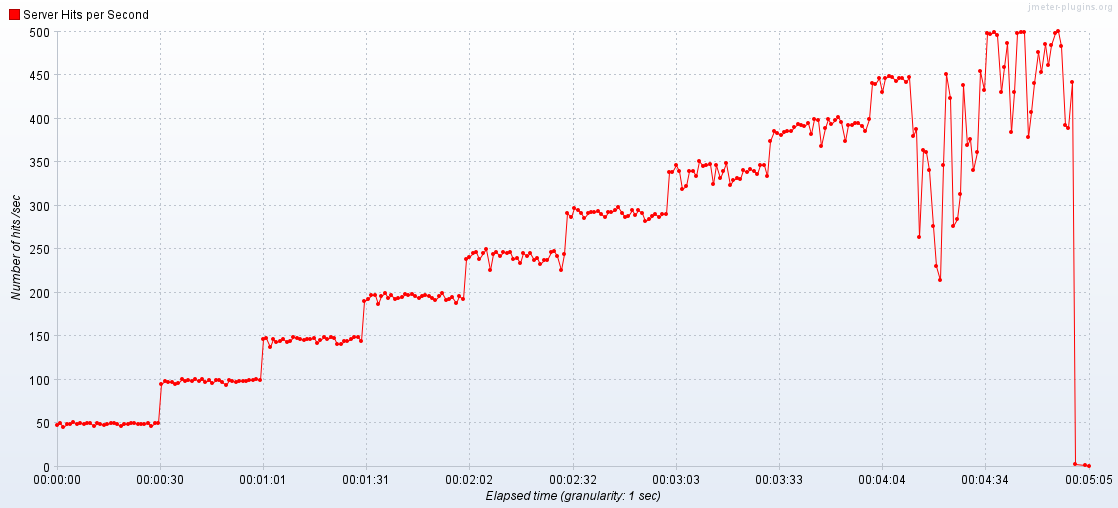
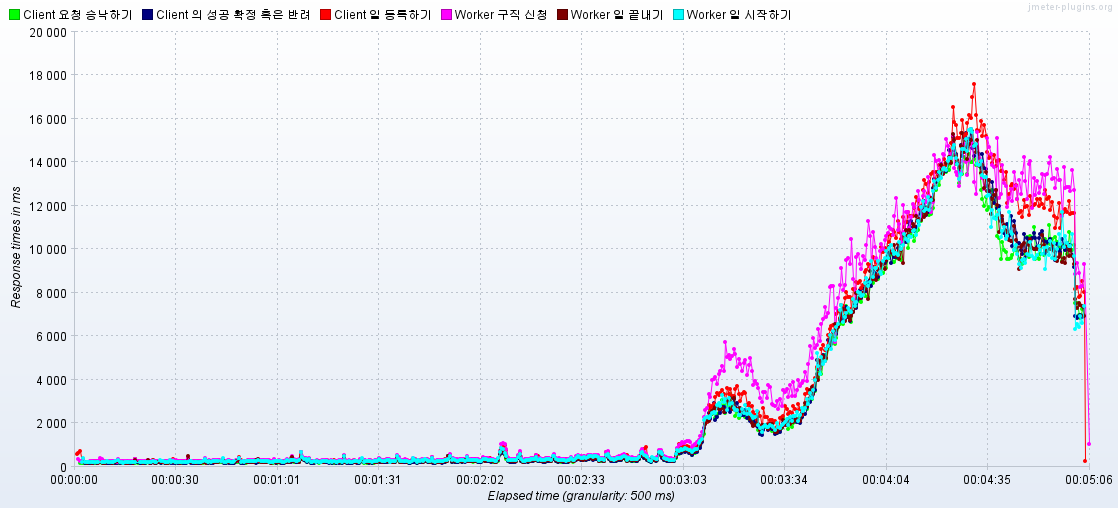
- 1800RPS -> 2100RPS로 상승 할 때, RPT가 6초 이상으로 치솟았으며, 다시 목표한 3초 이내로 들어오지 못함.
ExcutorRejectedException발생: SPRING 내부 백그라운드 쓰레드가 전부 활용 중이며, 그것을 기다리는 대기 큐도 꽉 차서, Spring이 비동기 임무 수행을 거절할 때, 나는 에러
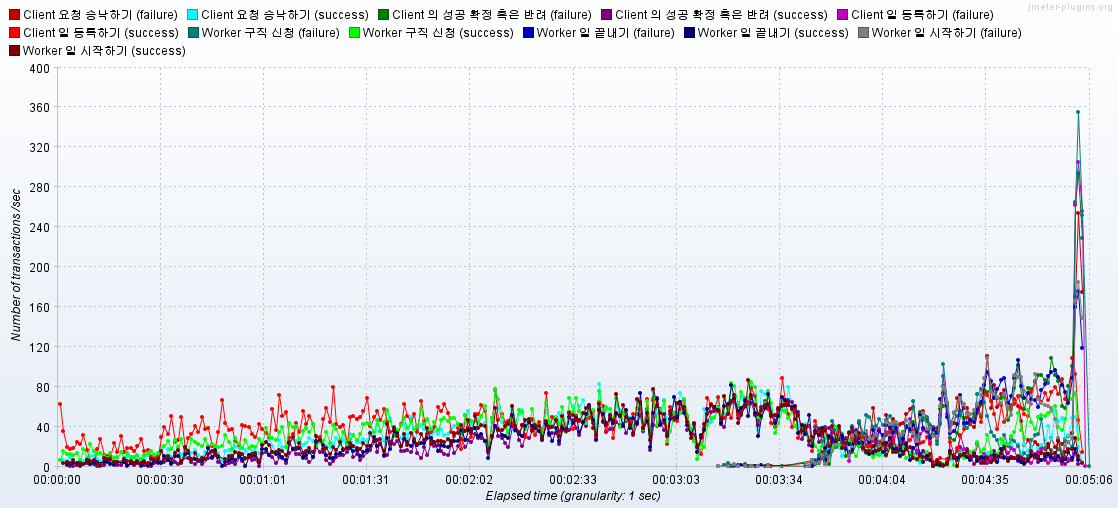
🌟결과: 오히려 에러율이 3분 16초에서 급증하며 종료됨
재시도 로직 구현
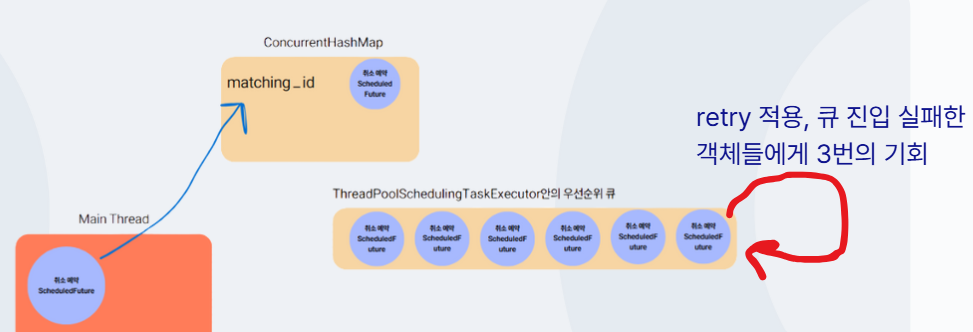
RETRY 전략은 지수 백오프로 구현

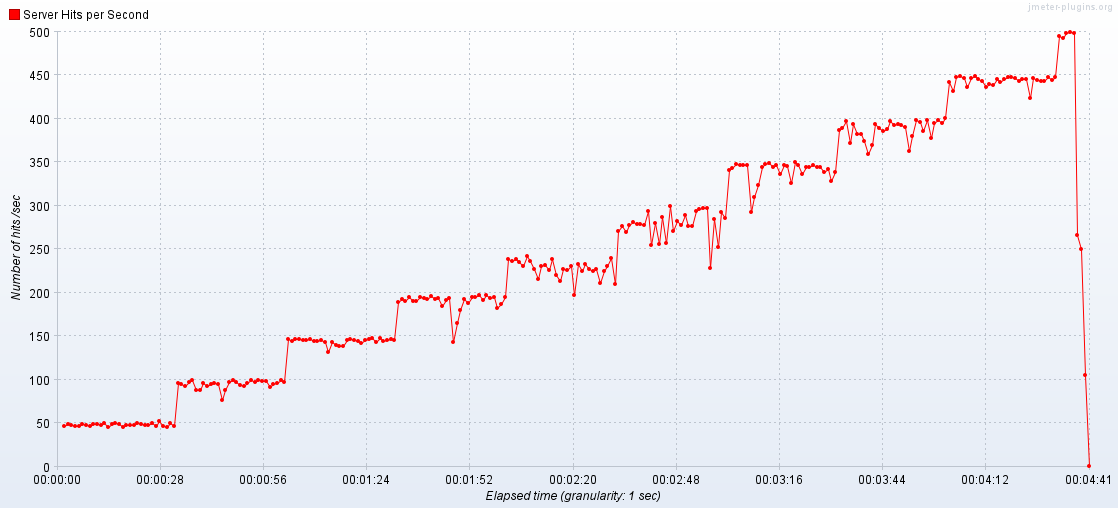
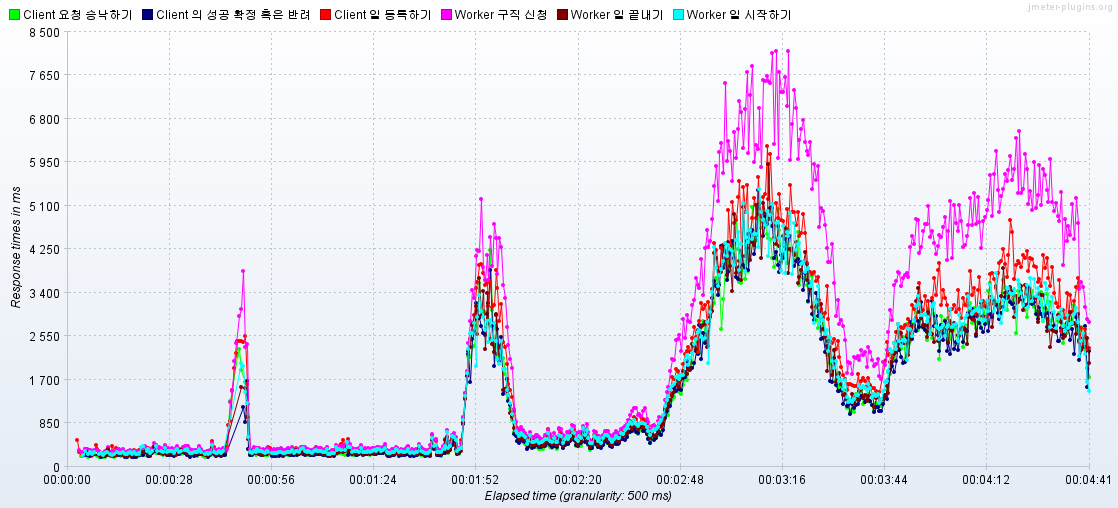
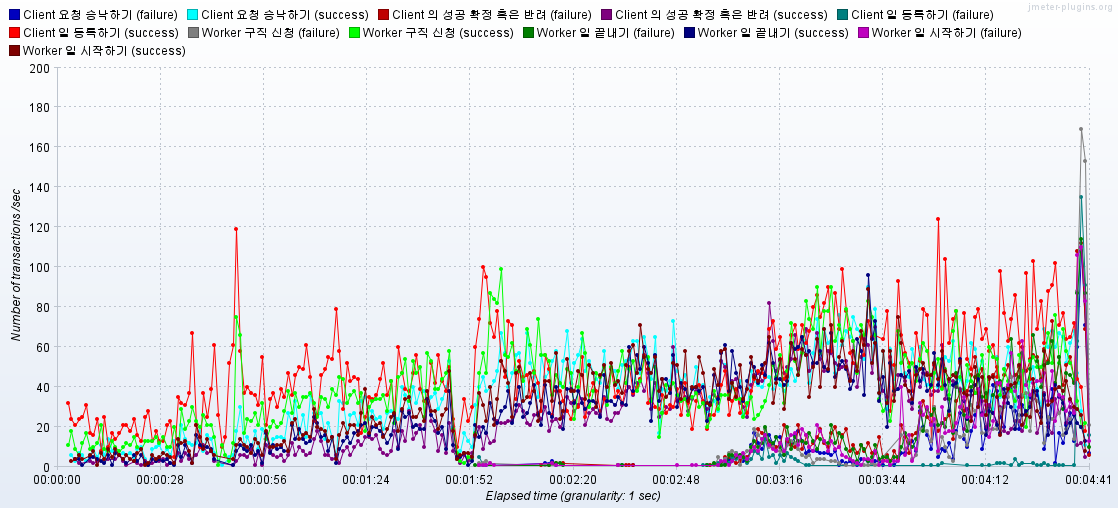
- 지수 백오프 전략 재시도 로직을 구성하였는데, 오히려 성능 지표가 떨어짐 (1800RPS -> 1200RPS)
🌟결과: 오류율 0.0% 1200RPS -> 3000RPS
- RPS가 급증한 후 10초 뒤에, 응답시간이 치솟는 현상을 통해, 지수 백오프 재시도 전략이 사실 트래픽을 분산하는 것이 아니라, 뒤로 미루는 것일 뿐이라 판단. 재시도 시점을 분산할 필요성을 느낌
- 스프링 내장 지수 백오프 전략 재시도 로직에 **
지수 변이**를 추가하여 재정의 - 2의 지수시간마다 반복하면서도, 0.1초 이내의 난수를 임의로 각 요청의 재시도마다 더해서 재시도 시점을 여러 개로 분산함.
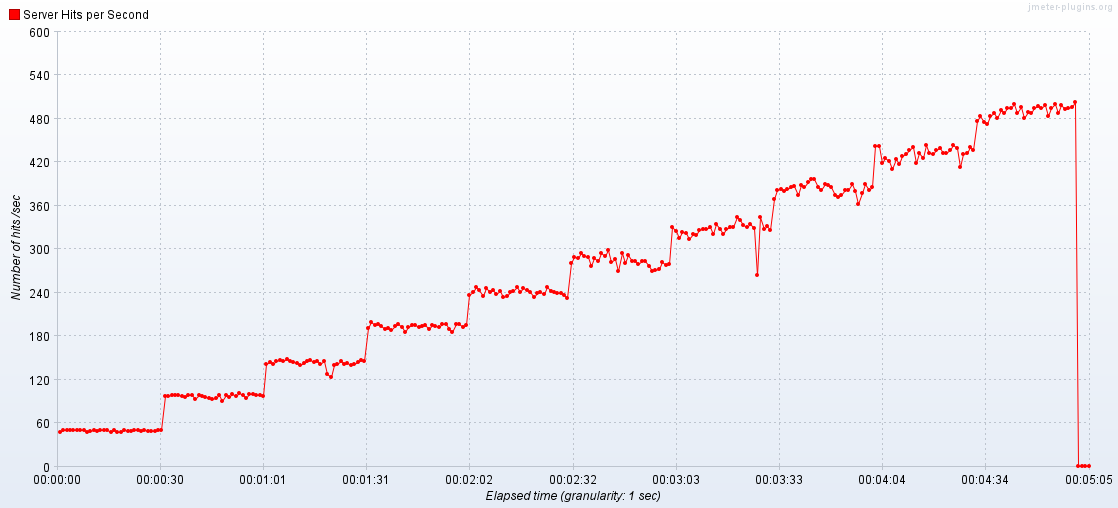
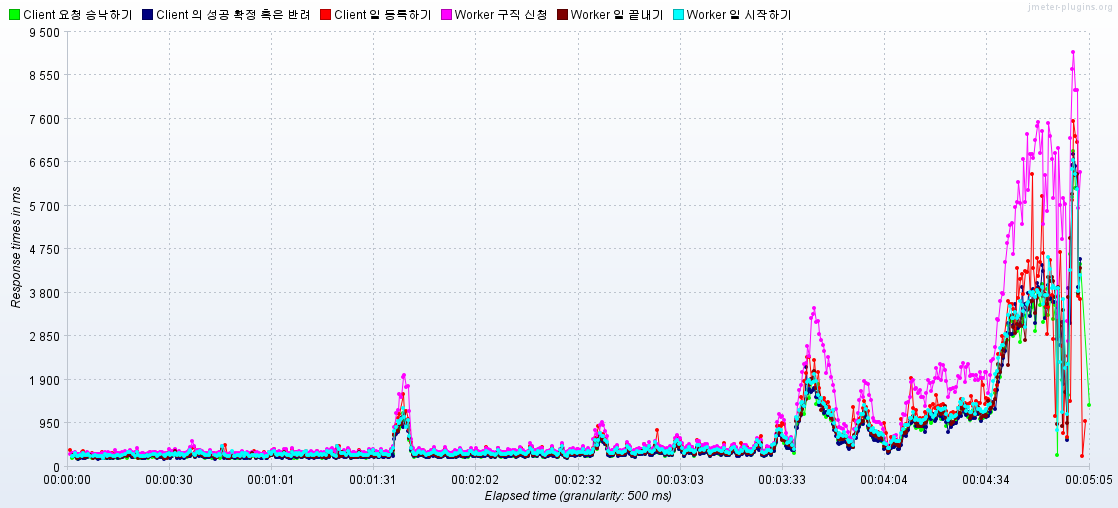
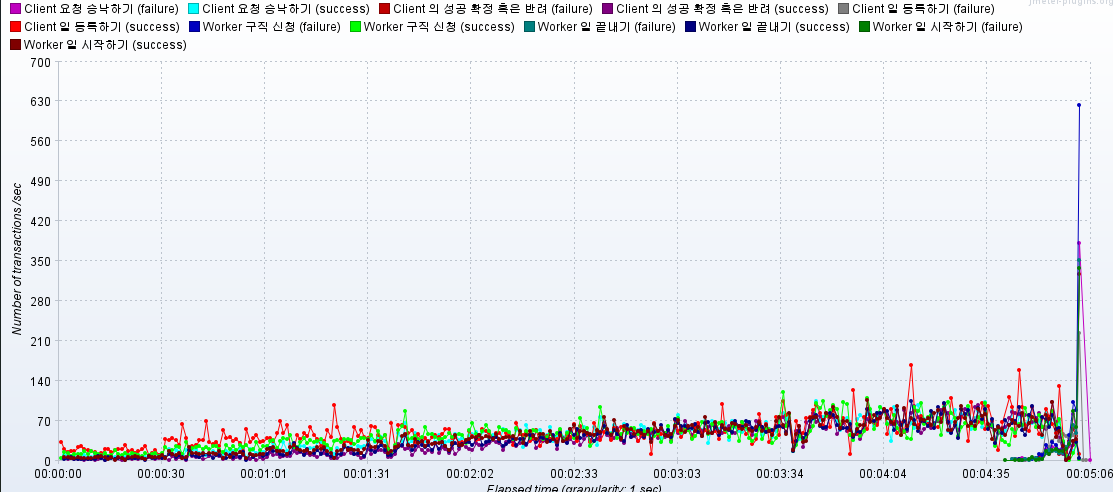
- 이후 5차 테스트에서는 3000RPS보다 요청 부하를 늘리려고 시도하자,
Socket Exception - Connection Rest과JDBC Exception - JDBC Time out에러가 지속적으로 나타남.
DB 유후 커넥션 수 변동
**톰캣 쓰레드 수 **
🌟결과:
