Perf optimizations#278
Conversation
…age-lock to v2 (npm 7+)
…ix broken tests
…mparison; Update Uncertainty.equals to account for point behavior; Add Uncertainty tests
…ntersect) and queries (toDistinctList)
…age-lock to v2 (npm 7+)
…ix broken tests
…mparison; Update Uncertainty.equals to account for point behavior; Add Uncertainty tests
…ntersect) and queries (toDistinctList)
…/cql-execution into perf-optimizations
Codecov Report
@@ Coverage Diff @@
## master #278 +/- ##
==========================================
- Coverage 86.22% 86.21% -0.01%
==========================================
Files 50 51 +1
Lines 4400 4470 +70
Branches 1236 1257 +21
==========================================
+ Hits 3794 3854 +60
- Misses 319 322 +3
- Partials 287 294 +7
📣 We’re building smart automated test selection to slash your CI/CD build times. Learn more |
 cmoesel
left a comment
cmoesel
left a comment
There was a problem hiding this comment.
Wow, @birick1 -- those performance improvements are impressive! Using your example code (not featured here), I saw the execution go from 110 seconds (old code) to 0.5 seconds (this PR's code). I also appreciate the additional tweaks you made along the way.
I've made several comments on the changes, some of which will require changes, some of which won't. Hopefully I haven't asked for anything too difficult! Let me know what you think...
I have not yet tried integrating this into my existing CQL projects to see if it introduces regressions. In the past, that has sometimes turned up previously undetected issues -- so I do plan on doing that. I'll let you know how it goes.
| '@typescript-eslint/no-explicit-any': 'off', | ||
| '@typescript-eslint/no-unused-vars': ['error', { argsIgnorePattern: '^_' }], | ||
| indent: ['error', 2, { SwitchCase: 1 }], | ||
| 'linebreak-style': ['error', os.EOL === '\r\n' ? 'windows' : 'unix'], |
There was a problem hiding this comment.
I assume that you converted this from .json to .js so you can change the expected linebreak-style based on the OS. Looking at the linebreak-style documentation, they recommend a different solution. Did you consider this?
Although I think that what you've done here probably won't cause problems in practice (since Git will convert to LF by default when pushing) -- it feels a little strange to introduce variation in a rule whose whole purpose is to ensure consistency. And it does open up a window for someone w/ different Git settings to check-in commits that w/ CRLF. This comment also lists out a few other reasons you might want to normalize line endings.
What do you think?
There was a problem hiding this comment.
I ran into a lot of problems with this. Let me start at the beginning...
Assume the following:
- Clone repo on a Windows machine
- Use VS Code
- Use the most popular ESLint extension in VS Code: https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint
In this case, many files will be entirely redlined as below:
This isn't just an artifact of the extension. If I then run the "lint:fix" npm script, I'll get ~140 changed files, of whose changes I can't see:
So I was looking for a solution to those 2 problems that wouldn't introduce a regression on unix.
The simplest solution is to turn off line-break checking. That's easy to do, but obviously will have a regression in that tests are no longer performed.
If I change the setting to linebreak-style: ["error", "windows"], then everything works fine on the windows machine, but this will introduce a regression for users on unix after this change is committed.
I tried the .gitattributes option, and I couldn't get it to work. It might need to be present in the git repo before cloning to the Windows machine. If that's the case, then we'd need to ask all Windows users to wipe and re-clone the repo. Otherwise, the problems I mentioned above remain. I'm open to revisiting if someone knows how to get this to work on an existing repo (maybe I missed something?).
In the end, the simplest fix I could find that resolved the issue without some sort of regression was switching to .js and adding an OS check. That does rely on git's default behavior on commit, which I tested here on the checks on commit.
There was a problem hiding this comment.
I thought that I had seen a Git command that would normalize your line endings in-place, but now that I'm looking for it, I can't find it. Perhaps it does not exist after all. You may have to re-clone to get this working with gitattributes.
TBH, I'm not sure if we need to be concerned about asking all the Windows users to wipe and reclone... The issues you found have been like that for a while, and no one else has ever reported them. So I wonder how many active Windows cloners we have out there... For the ones we do have, they'd be no worse off than they already were.
I don't know how much this really matters. Let's get a couple of 2nd/3rd opinions. @mgramigna / @hossenlopp -- what are your thoughts on dynamically changing expected EOL in the lint config vs trying to leverage gitattributes (and requiring Windows users to reclone)?
There was a problem hiding this comment.
My personal opinion is slightly adverse to conditionally defining a lint rule based on the OS
There was a problem hiding this comment.
I'm going to agree. It's not hard to set git to enforce unix line endings on windows.
|
@birick1 - Just to follow up: I've run this code against my CDS Connect artifacts w/ over 10k test cases and they all continued to pass. I also tested this in a SMART-on-FHIR app we made w/ an embedded cql engine and it worked there as well. So that's good! No regressions detected. |
|
Thank you @cmoesel - I'll go through each and respond. In the meantime, I'm wondering if you saw any performance improvements in your regression tests? As a sanity check, the performance improvement should only show up for CQL dealing with large lists. |
|
@birick1 -- thanks for asking. I was going to say something, but nearly forgot. Actually, I saw performance degradation in my unit tests. These are about 12,000 tests -- most of which deal with very small amounts of data (exactly the records needed to exercise the logic and no more). With your branch, it was taking just over 8 minutes. With the main branch it was taking just under 7 minutes. I'll run it a couple more times just to confirm it wasn't a fluke. |
|
Update. I ran my 12000+ tests three times using a packed version of this PR module and 3 times using the latest CQL Execution release (2.4.2). PR #278
Release 2.4.2
The official release consistently outperformed this PR code, but it's probably worth noting that my 12000 unit tests are not a good reflection of real-world use. They contain minimal data for each patient and are run quickly in succession. In the real world, patients typically have a lot of data; so it probably makes sense to optimize for that. Still... I was surprised to see such a consistent difference in performance (in the wrong direction). |
|
Interesting. I suspect the list operation benefits are being outweighed by the conversion to/from Immutable objects. I didn't make it through all the comments above - will continue with them tomorrow. |
|
I responded to some more of the original comments, but still haven't made it through all. Will continue tomorrow. |
|
Made it through the original comments. Take a look. |
|
@cmoesel - Any objection if I add the curly ESLint rule? It enforces curly brackets after if statements. https://eslint.org/docs/latest/rules/curly It identified the violations mentioned above, found one extra violation in src/cql-patient, and works nicely with tooling. See screenshot:
|
…ipts to run in Windows env too
|
Thank you for reviewing @mgramigna. The general idea I had behind the abstraction in
Thinking about the comments, I would agree losing maintainability/clarity for possible future features is counter-productive. Moreover, the features I had in mind seem to have diminishing returns after the testing that's been done. To fix, I eliminated all code and helpers from @mgramigna and @cmoesel -> Please let me know what you think. I've also done the following:
|
…oKvp and toKvpParams in immutableUtil
|
I thought a bit more about what else I could do to simplify. Optimizing doIntersect, doExcept, and doUnion is not strictly needed (makes small perf difference in tests I have as most gain comes from doDistinct). So I returned those methods to their original implementations. With that done, there is no need to maintain the concept of a key-value pairing (or hash-value pairing), and there is no value in keeping The end result: only the 2 distinct methods in Will update the description of the pull request to reflect the narrowed scope. |
|
Original pull request description updated to current state. Separated the changes in this pull request into 3 categories to distinguish change types, and added a number of links for reference. |
|
Committed small update to change variable names to reflect they hold keys instead of kvps now. |
cmoesel
left a comment
There was a problem hiding this comment.
Thank you for considering our feedback, @birick1. I'm much more comfortable with this simplified version of the code. I think it's a great compromise and still accomplishes significant performance gains for our users.
I've noted a few things that I think should be tweaked, but it looks like we're real close.
You had asked me to re-test this against my suite of thousands of tests. Unfortunately, I'm still seeing performance degradation there. The "old" code runs in just over 6 minutes, and this PR's code runs in just over 9 minutes. @mgramigna, @hossenlopp, and I were talking about this and figured we probably have a few choices here:
- Deal with it. The degradation for some use cases is worth the significant boost for other cases.
- Try to determine the threshold where the immutable implementation starts paying off. Then modify the code so that lists w/ length < the threshold use the old approach and lists w/ length >= the threshold use the new approach.
- Introduce a configuration option (e.g.,
bigListOptimization) that allows the integrator to turn it on for environments that would benefit, but leave it off for other environments.
What are your thoughts on that?
| "build:test-data": "cd .\\test\\generator && .\\gradlew generateTestData && cd ..", | ||
| "build:spec-test-data": "node test\\spec-tests\\generate-cql.js && cd .\\test\\generator && .\\gradlew generateSpecTestData && cd ..", | ||
| "build:all": "npm run build && npm run build:browserify && npm run build:test-data && npm run build:spec-test-data", | ||
| "watch:test-data": "cd ./test/generator && ./gradlew watchTestData && cd ..", | ||
| "test": "TS_NODE_PROJECT=\"./tsconfig.test.json\" TS_NODE_FILES=true mocha --reporter spec --recursive", | ||
| "test:nyc": "TS_NODE_PROJECT=\"./tsconfig.test.json\" TS_NODE_FILES=true nyc --reporter=html npx mocha --reporter spec --recursive", | ||
| "test:watch": "TS_NODE_PROJECT=\"./tsconfig.test.json\" TS_NODE_FILES=true mocha --reporter spec --recursive --watch", | ||
| "watch:test-data": "cd .\\test\\generator && .\\gradlew watchTestData && cd ..", |
There was a problem hiding this comment.
Unfortunately, changing / to \\ breaks these scripts on Mac. IIRC, I thought you had found another approach that worked equally well on Windows and Mac?
There was a problem hiding this comment.
You may be thinking of cross-env as the solution that worked well for the environment variable setting on both Windows and Unix?
Technically I think run-script-os is the solution to this (or a solution to this, the only one I personally have seen used). That would make this really messy though IMO:
"build:test-data": "run-script-os",
"build:test-data:default": "cd ./test/generator && ./gradlew generateTestData && cd ..",
"build:test-data:win32": "cd .\\test\\generator && .\\gradlew generateTestData && cd .."
Best solution in my mind is to just use a Unix-based terminal, even when on Windows ;)
There was a problem hiding this comment.
@cmoesel - Indeed I tried a bunch of possible solutions and committed the wrong one. Will correct.
| if (!yList.some(y => equals(x, y))) { | ||
| yList.push(x); | ||
| } | ||
| export const toDistinctList = (list: unknown[]): unknown[] => { |
There was a problem hiding this comment.
Is this implementation the same as doDistinct in list.ts? They look exactly the same to my eye, but I might be missing something.
If they are the same, I think it would be best to remove this duplicate implementation and just refer to the one in list.ts instead (which is probably the more sensible location if we keep only one). I don't love the name doDistinct though, so it might be nice to rename it to toDistinctList while you're at it.
There was a problem hiding this comment.
They are the same. I think the typing could be tighter on the list implementation than the query implementation, but in using unknown types there's no distinction. Will update.
| case Code: | ||
| return Immutable.Map({ | ||
| code: toNormalizedKey(js.code), | ||
| system: toNormalizedKey(js.system), | ||
| __instance: js.constructor | ||
| }); |
There was a problem hiding this comment.
This ignores version and display. This would be OK if distinct used equivalence semantics, but according to the spec, distinct should use equality semantics (except for null) -- which means that version and display should be considered.
There was a problem hiding this comment.
I was convinced equality for codes was on code/system only. I traced the code and you are indeed correct. Will update.
| case RegExp: | ||
| return Immutable.Map({ | ||
| source: toNormalizedKey(js.source), | ||
| global: toNormalizedKey(js.global), | ||
| ignoreCase: toNormalizedKey(js.ignoreCase), | ||
| multiline: toNormalizedKey(js.multiline), | ||
| __instance: js.constructor | ||
| }); |
There was a problem hiding this comment.
Did RegExp actually come up somewhere? I just can't think of a CQL context that would ever result in a list of regular expressions.
There was a problem hiding this comment.
I don't have a specific use case for it. However, the intent with this normalization is to replicate the behavior for equality of RegExp in util/comparison.ts line 238.
case '[object RegExp]':
// Compare the components of the regular expression
return ['source', 'global', 'ignoreCase', 'multiline'].every(p => a[p] === b[p]);
| import { equals } from '../../src/util/comparison'; | ||
| import { toNormalizedKey } from '../../src/util/immutableUtil'; | ||
|
|
||
| describe('Memoizer Tests', () => { |
There was a problem hiding this comment.
| describe('Memoizer Tests', () => { | |
| describe('ImmutableUtil Tests', () => { |
| type Primitive = string | number | boolean | bigint | symbol | undefined | null; | ||
| export type NormalizedKey = Primitive | Immutable.Collection<NormalizedKey, unknown>; | ||
|
|
||
| export const toNormalizedKey = (js: any): NormalizedKey => { |
There was a problem hiding this comment.
Can you document this function to indicate what it does and why it is needed?
There was a problem hiding this comment.
Ha - I originally did and it was something along the lines of "Provide a normalized key", which didn't seem too useful :). Will try to add something that is helpful.
| '@typescript-eslint/no-explicit-any': 'off', | ||
| '@typescript-eslint/no-unused-vars': ['error', { argsIgnorePattern: '^_' }], | ||
| indent: ['error', 2, { SwitchCase: 1 }], | ||
| 'linebreak-style': ['error', os.EOL === '\r\n' ? 'windows' : 'unix'], |
There was a problem hiding this comment.
I still don't love switching this rule based on the OS, and based on previous comments, it seems that others agree.
That said, I've been looking at other projects of mine (as well as abacus's), and I don't see anyone else using the linebreak-style rule at all. It seems they generally just rely on the built-in git behavior. So I think I'd be comfortable reverting this file back to the .json version and removing the linebreak-style rule. Before we do that, however, I'd be interested in your opinion on removing it (@birick1), as well as @mgramigna's opinion. Since Matt's other projects don't use this rule, I imagine he is probably OK with it -- but it's worth asking.
There was a problem hiding this comment.
Removing the rule certainly makes life easier. Will change back to .json and remove the rule.
|
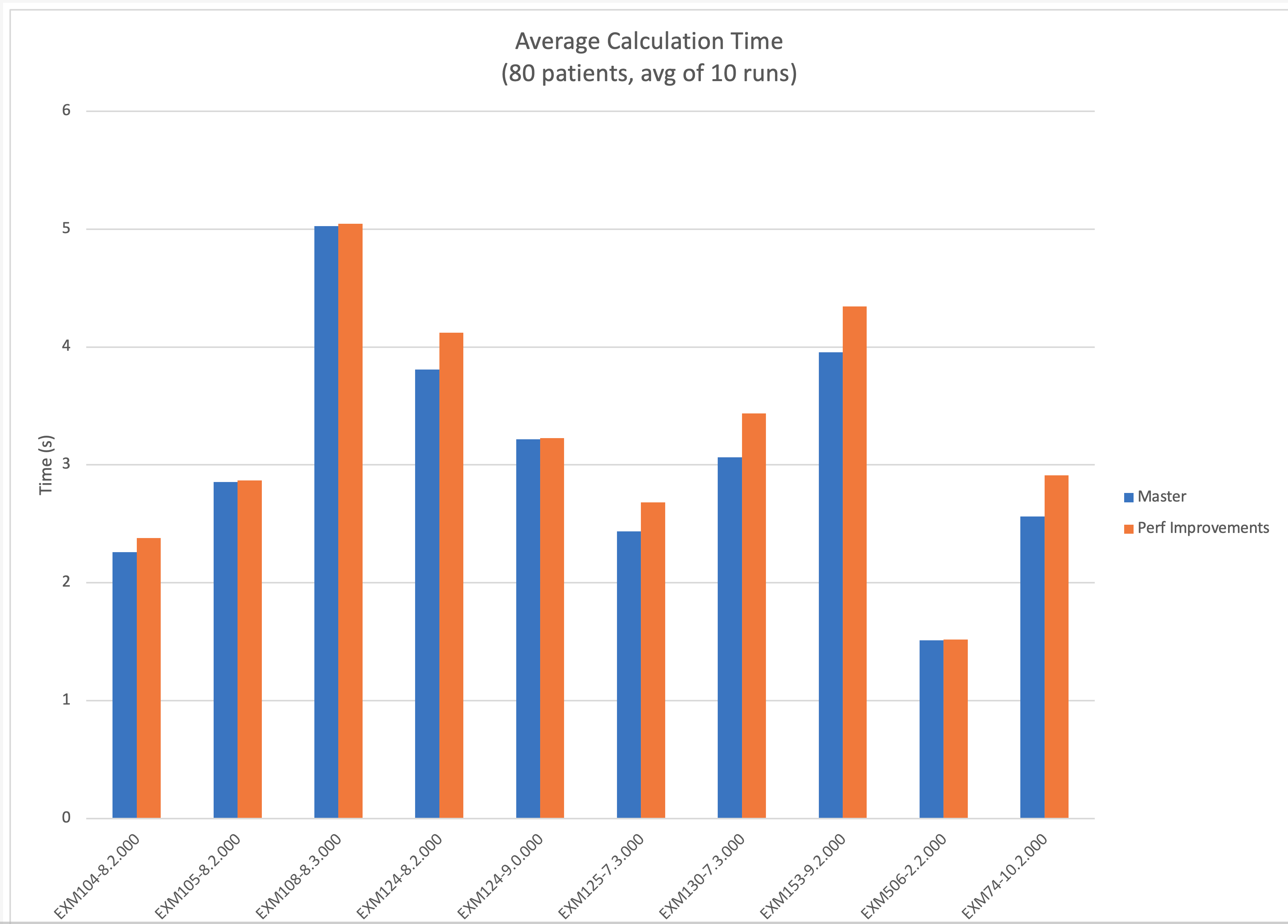
FWIW, I ran a very very basic and small test, and for realistic cases of eCQMs/patients in fqm-execution, the performance results are pretty much negligible between the two branches:
If I saw any actually significant differences, I'd run some more detailed tests, but I just wanted to make sure that this didn't degrade fqm-execution's performance at all. It doesn't seem to have done so |
…ts implementation; Rename
… keeping curly rule
|
Thank you @cmoesel and @mgramigna for the reviews. @cmoesel - I've added updates for all items except for the Regex item - take a look at comment.
I lean to option 1 for this pull request, but there is an argument to made for each option. @mgramigna - thank you for testing all those measures. For the measures I've tested, the performance is either in line with your results, or dramatically better (usually because of very large valuesets being used). |
|
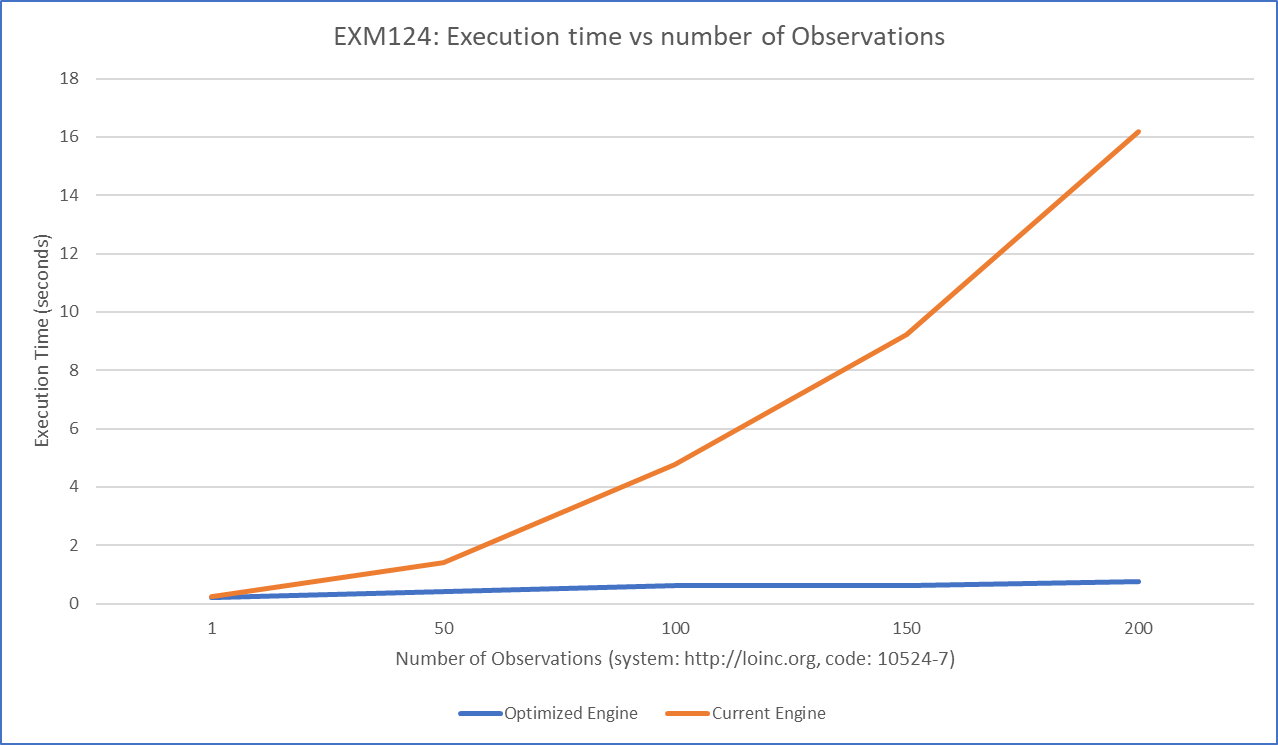
@cmoesel and @mgramigna - I'm including an example of how bad the performance of the measures might be that you've considered above, and how this pull request helps. In this example, from @mgramigna's chart, I'll focus on EXM124. The chart above showed the optimized engine being slightly slower than the current engine. Now, I'll demonstrate the reverse and show just how bad it can be. In this test, I'll focus only on the following query in the CQL: This is a straightforward query looking for observations with a value and status. The basic patient I tested with is Patient.zip and includes one Observation that should be a hit for this query. In this test, observations are added to the patient (that will also hit this query) and the performance noted between the current and optimized engine. Going from 1 observation to 200 will yield a performance curve for the engines as below (lower is better).
In fact, by the time the patient includes 1000 observations, the optimized engine will execute in less than 2 seconds, while the current engine will take over 7 minutes! At this point, the optimized engine is ~210x faster than the current engine. One could have picked any query in the measure, and performed a similar analysis while increasing the data included in the query - they will all generally have a similar curve. As the amount of data being queried increases, the optimization in this pull request becomes more pronounced. I also hope this helps quantify why I lean toward option 1 in the prior comment. |
|
Thanks, @birick1. Let's make a decision regarding the way forward. The basic options are:
@birick1 has indicated his preference for option 1. I'm comfortable with option 1, noting that if it impacts users negatively, we can always implement option 2 or 3 later. @mgramigna and @hossenlopp, what are your thoughts? If we agree on option 1, is there anything else that should hold up this PR? And should we merge it to |
|
Superseded by #307 |
Justification
The main motivation of this pull request is to introduce a targeted performance improvement to list operations. The list and query
distinctoperations are non-performant on large lists which do occur in real-world use. These performance issues are resolved by using normalized immutable objects (with the Immutable.js library) as keys (or hashes) optimized for value comparisons.In implementing the performance improvements, an issue was identified with the Uncertainty type where point equality with other types was not commutative. This could produce unexpected behavior based on the order in which Uncertain points were compared. This is corrected and tests added (thanks @hossenlopp / @cmoesel for constructor.name improvement suggestions).
Other issues and bug fixes related to Windows environment incompatibilities are noted below.
Code Changes
Performance Enhancements
doDistinct) and queries (toDistinctList). These performance improvements add a dependency to Immutable.js.immutableUtil.tsis added with a normalizer function used in the improved distinct methods.immutableUtil-test.tsto test normalization.Windows compatibility bug fixes
test,test:nyc, andtest:watchto use cross-env to run in Windows environments.build:test-data,build:spec-test-data, andwatch:test-datato run in Windowseslintrc.jsontoeslintrc.jswith a check on the operating system. Uses accepted answer (EOL check) from Stackoverflow.eslintignorewitheslintrc.js.messageListeners-test.ts.General issues
tsconfig.test.jsonin root did not work as intended with VS Code. Support projects with multiple tsconfig.json microsoft/vscode#3772 (comment)package-lock.jsonto v2Definitely a big THANK YOU to @cmoesel, @hossenlopp, and @mgramigna for the time and comments in improving this pull request.
Testing
Tests are included to validate the results of the new immutable code coincides with the prior implementation. However, unit tests don't seem to be the best place to include performance tests. I have run benchmarks against the engine using measures and found significant improvements when the measures use long lists (e.g long valuesets, large amounts of data, etc.). For measures that don't use large lists of some type, performance remains the same as before.
Pull requests into cql-execution require the following.
Submitter and reviewer should ✔ when done.
For items that are not-applicable, mark "N/A" and ✔.
CDS Connect and Bonnie are the main users of this repository.
It is strongly recommended to include a person from each of those projects as a reviewer.
Submitter:
npm run test:plusto run tests, lint, and prettier)cql4browsers.jsbuilt withnpm run build:browserifyif source changed.Reviewer:
Name: