


This page aims to document Python protocols and usage (e.g. cloud, desktop).
Looking for Javascript/Typescript instructions?
Universal Intelligence (aka UIN) aims to make AI development accessible to everyone through a simple interface, which can optionally be customized to grow with you as you learn, up to production readiness.
It provides both a standard protocol, and a library of components implementating the protocol for you to get started —on any platform 

🧩 AI made simple. Bluera Inc.
Learn more by clicking the most appropriate option for you:
I'm new to building agentic apps
Welcome! Before jumping into what this project is, let's start with the basics.
Agentics apps are applications which use AI. They typically use pretrained models, or agents, to interact with the user and/or achieve tasks.
Models are artificial brains, or neural networks in coding terms. 🧠
They can think, but they can't act without being given the appropriate tools for the job. They are trained to produce a specific output, given a specific input. These can be of any type (often called modalities —eg. text, audio, image, video).
Tools are scripted tasks, or functions in coding terms. 🔧
They can't think, but they can be used to achieve a pre-defined task (eg. executing a script, making an API call, interacting with a database).
Agents are robots, or simply put, models and tools connected together. 🤖
🤖 = 🧠 + [🔧, 🔧,..]
They can think and act. They typically use a model to decompose a task into a list of actions, and use the appropriate tools to perform these actions.
UIN is a protocol aiming to standardize, simplify and modularize these fundamental AI components (ie. models, tools and agents), for them to be accessible to any developer, and distributed on any platform.
It provides three specifications: Universal Model, Universal Tool, and Universal Agent.
UIN also provides a set of ready-made components and playgrounds for you to get familiar with the protocol and start building in seconds.
Universal Intelligence can be used across all platforms (cloud, desktop, web, mobile).
I have experience in building agentic apps
Universal Intelligence standardizes, simplifies and modularizes the usage and distribution of artifical intelligence, for it to be accessible by any developers, and distributed on any platform.
It aims to be a framework-less agentic protocol, removing the need for proprietary frameworks (eg. Langchain, Google ADK, Autogen, CrewAI) to build simple, portable and composable intelligent applications.
It does so by standardizing the fundamental building blocks used to make an intelligent application (models, tools, agents), which agentic frameworks typically (re)define and build upon —and by ensuring these blocks can communicate and run on any hardware (model, size, and precision dynamically set; agents share resources).
It provides three specifications: Universal Model, Universal Tool, and Universal Agent.
This project also provides a set of community-built components and playgrounds, implementing the UIN specification, for you to get familiar with the protocol and start building in seconds.
Universal Intelligence protocols and components can be used across all platforms (cloud, desktop, web, mobile).
How do they compare?
Agent frameworks (like Langchain, Google ADK, Autogen, CrewAI), each orchestrate their own versions of so-called building blocks. Some of them implement the building blocks themselves, others have them built by the community.
UIN hopes to standardize those building blocks and remove the need for a framework to run/orchestrate them. It also adds a few cool features to these blocks like portability. For example, UIN models are designed to automatically detect the current hardware (cuda, mps, webgpu), its available memory, and run the appropriate quantization and engine for it (eg. transformers, llama.cpp, mlx, web-llm). It allows developers not to have to implement different stacks to support different devices when running models locally, and (maybe more importantly) not to have to know or care about hardware compatibility, so long as they don't try to run a rocket on a gameboy 🙂
Get familiar with the composable building blocks, using the default community components.
# Choose relevant install for your device
pip install "universal-intelligence[community,mps]" # Apple
pip install "universal-intelligence[community,cuda]" # NVIDIA
# Log into Hugging Face CLI so you can download models
huggingface-cli loginfrom universal_intelligence import Model # (or in the cloud) RemoteModel
model = Model() # (or in the cloud) RemoteModel(credentials='openrouter-api-key')
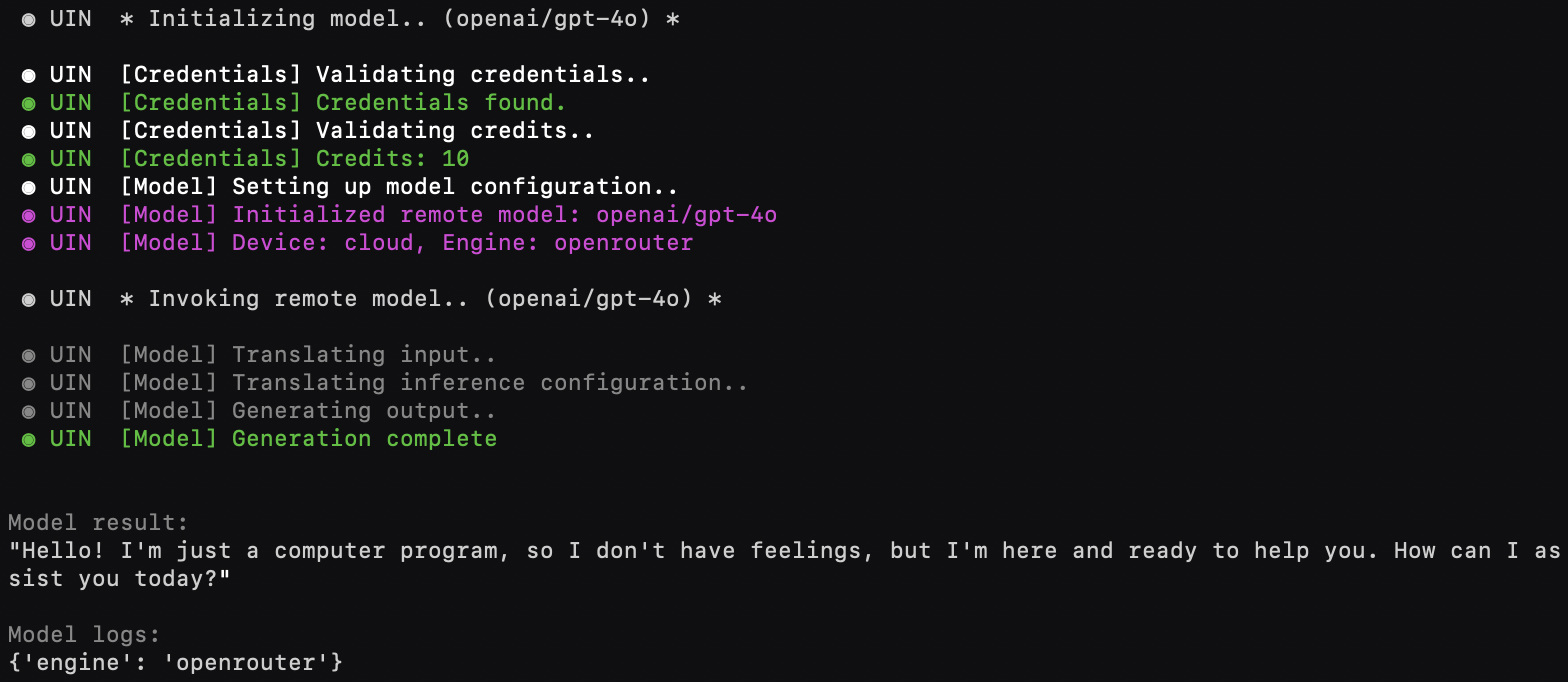
result, logs = model.process("Hello, how are you?")Models may run locally or in the cloud.
See Documentation>Community Components>Remote Models for details.
Preview:
- Local Model
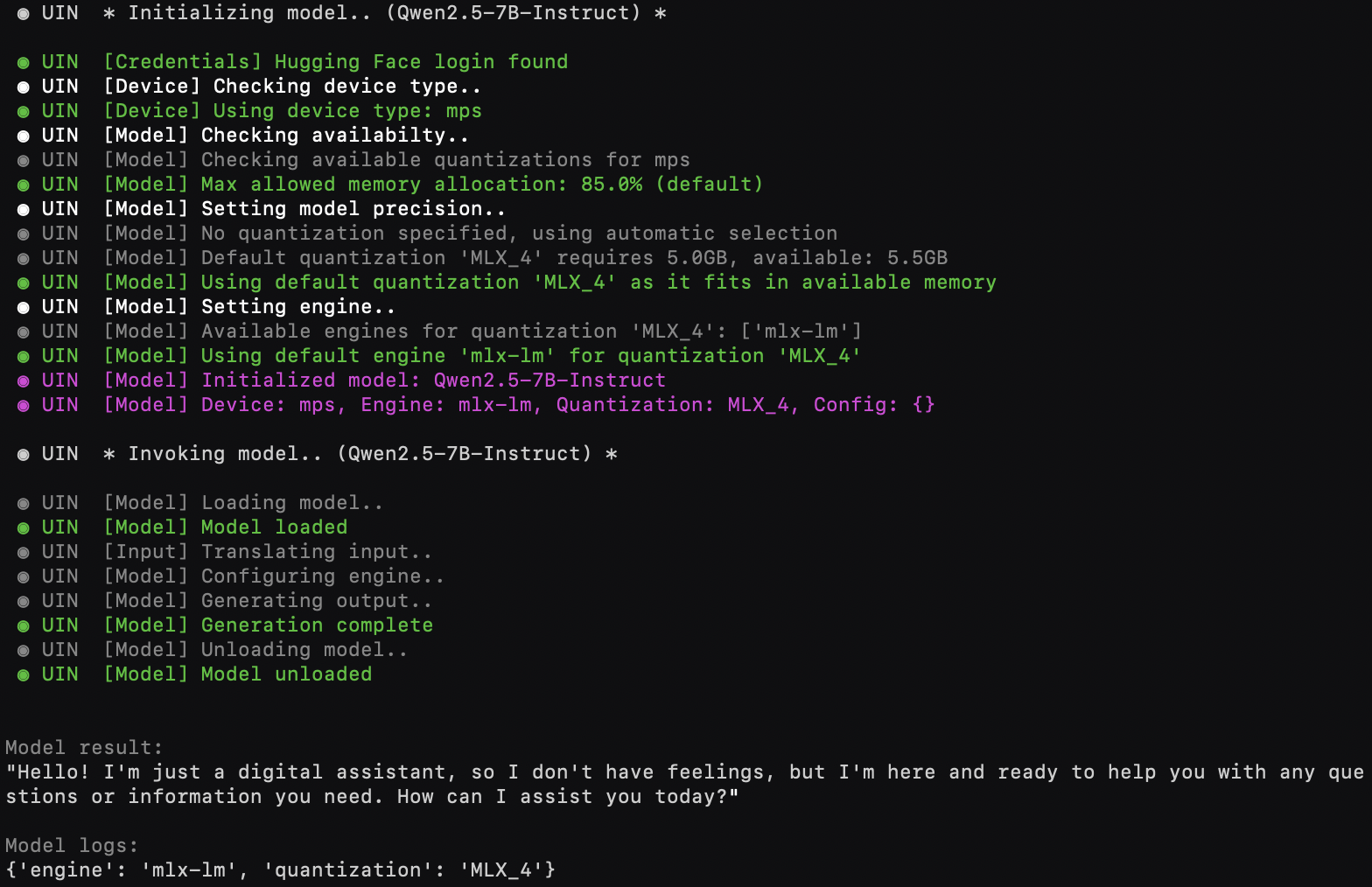
- Remote Model (cloud-based)
from universal_intelligence import Tool
tool = Tool()
result, logs = tool.print_text("This needs to be printed")Preview:

from universal_intelligence import Model, Tool, Agent, OtherAgent
agent = Agent(
# model=Model(), # customize or share 🧠 across [🤖,🤖,🤖,..]
# expand_tools=[Tool()], # expand 🔧 set
# expand_team=[OtherAgent()] # expand 🤖 team
)
result, logs = agent.process("Please print 'Hello World' to the console", extra_tools=[Tool()])Preview:
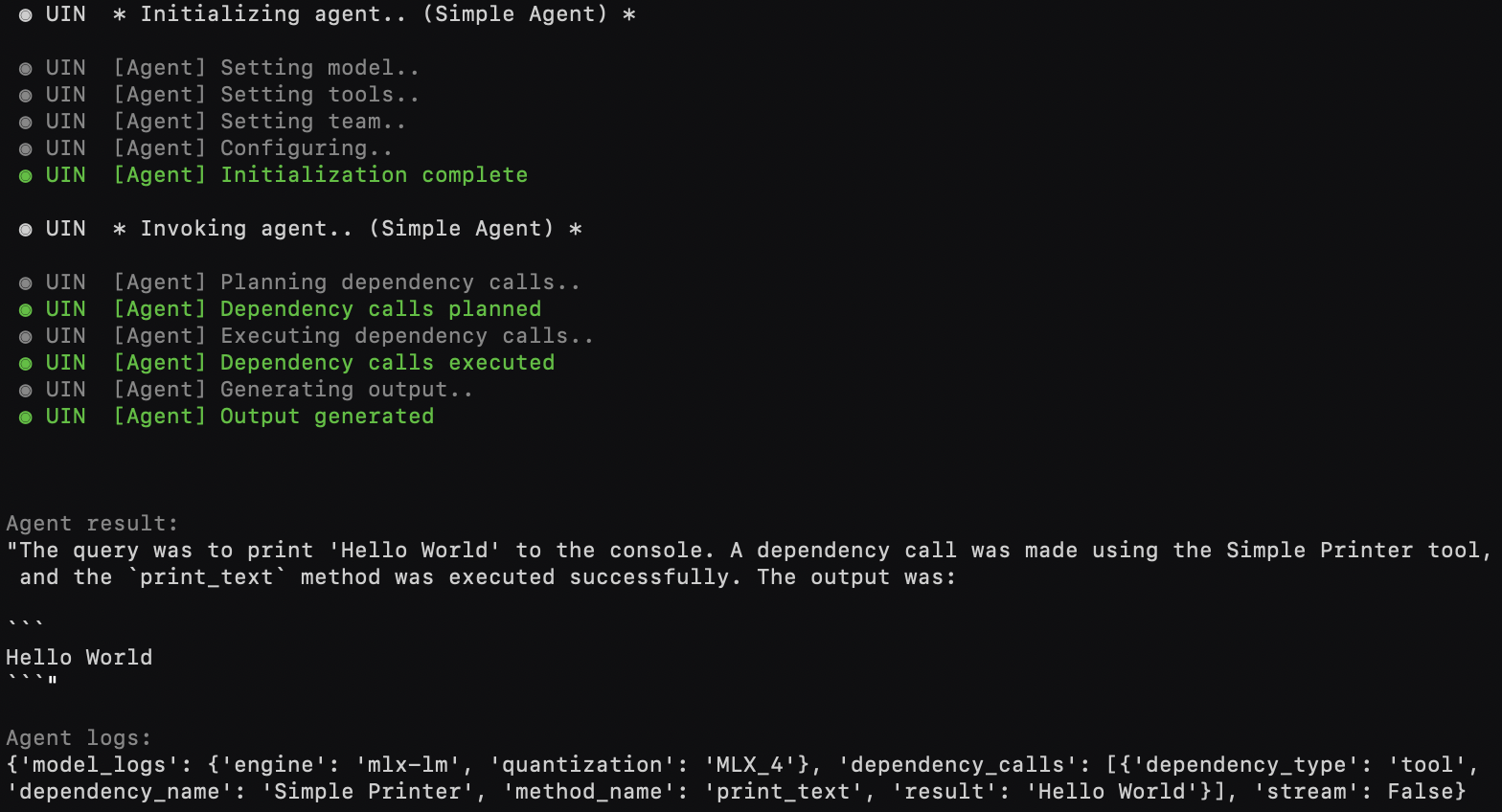
A ready-made playground is available to help familiarize yourself with the protocols and components.
python -m playground.example Protocol Specifications
A ⚪ Universal Model is a standardized, self-contained and configurable interface able to run a given model, irrespective of the consumer hardware and without requiring domain expertise.
It embeddeds a model (i.e. hosted, fetched, or local), one or more engines (e.g. transformers, lama.cpp, mlx-lm, web-llm), runtime dependencies for each device type (e.g. CUDA, MPS), and exposes a standard interface.
While configurable, every aspect is preset for the user, based on automatic device detection and dynamic model precision, in order to abstract complexity and provide a simplified and portable interface.
Providers: In the intent of preseting a
Universal Modelfor non-technical mass adoption, we recommend defaulting to 4 bit quantization.
A ⚪ Universal Tool is a standardized tool interface, usable by any Universal Agent.
Tools allow interacting with other systems (e.g. API, database) or performing scripted tasks.
When
Universal Toolsrequire accessing remote services, we recommend standardizing those remote interfaces as well using MCP Servers, for greater portability. Many MCP servers have already been shared with the community and are ready to use, see available MCP servers for details.
A ⚪ Universal Agent is a standardized, configurable and composable agent, powered by a Universal Model, Universal Tools and other Universal Agents.
While configurable, every aspect is preset for the user, in order to abstract complexity and provide a simplified and portable interface.
Through standardization, Universal Agent can seemlessly and dynamically integrate with other Universal Intelligence components to achieve any task, and/or share hardware recources (i.e. sharing a common Universal Model) —allowing it to generalize and scale at virtually no cost.
When
Universal Agentsrequire accessing remote agents, we recommend leveraging Google's A2A Protocols, for greater compatibility.
In simple terms:
Universal Model = 🧠
Universal Tool = 🔧
Universal Agent = 🤖
🤖 = 🧠 + [🔧, 🔧,..] + [🤖, 🤖,..]
from <provider> import UniversalModel as Model
model = Model()
output, logs = model.process('How are you today?') # 'Feeling great! How about you?'Automatically optimized for any supported device 🔥
Simple does not mean limited. Most advanted configuration options remain available.
Those are defined by and specific to the universal model provider.
We encourage providers to use industry standard Hugging Face Transformers specifications, irrespective of the backend internally used for the detected device and translated accordingly, allowing for greater portability and adoption.
from <provider> import UniversalModel as Model
model = Model(
credentials='<token>', # (or) object containing credentials eg. { id: 'example', passkey: 'example' }
engine='transformers', # (or) ordered by priority ['transformers', 'llama.cpp']
quantization='BNB_4', # (or) ordered by priority ['Q4_K_M', 'Q8_0'] (or) auto in range {'default': 'Q4_K_M', 'min_precision': '4bit', 'max_precision': '8bit'}
max_memory_allocation=0.8, # maximum allowed memory allocation in percentage
configuration={
# (example)
# "processor": {
# e.g. Tokenizer https://huggingface.co/docs/transformers/fast_tokenizers
#
# model_max_length: 4096,
# model_input_names: ['token_type_ids', 'attention_mask']
# ...
# },
# "model": {
# e.g. AutoModel https://huggingface.co/docs/transformers/models
#
# torch_dtype: "auto"
# device_map: "auto"
# ...
# }
},
verbose=True # or string describing log level
)
output, logs = model.process(
input=[
{
"role": "system",
"content": "You are a helpful model to recall schedules."
},
{
"role": "user",
"content": "What did I do in May?"
},
], # multimodal
context=["May: Went to the Cinema", "June: Listened to Music"], # multimodal
configuration={
# (example)
# e.g. AutoModel Generate https://huggingface.co/docs/transformers/llm_tutorial
#
# max_new_tokens: 2000,
# use_cache: True,
# temperature: 1.0
# ...
},
remember=True, # remember this interaction
stream=False, # stream output asynchronously
keep_alive=True # keep model loaded after processing the request
) # 'In May, you went to the Cinema.'from <provider> import UniversalModel as Model
model = Model()
# Optional
model.load() # loads the model in memory (otherwise automatically loaded/unloaded on execution of `.process()`)
model.loaded() # checks if model is loaded
model.unload() # unloads the model from memory (otherwise automatically loaded/unloaded on execution of `.process()`)
model.reset() # resets remembered chat history
model.configuration() # gets current model configuration
# Class Optional
Model.contract() # Contract
Model.compatibility() # Compatibility from <provider> import UniversalTool as Tool
tool = Tool(
# configuration={ "any": "configuration" },
# verbose=False
)
result, logs = tool.example_task(example_argument=data)from <provider> import UniversalTool as Tool
# Class Optional
Tool.contract() # Contract
Tool.requirements() # Configuration Requirements from <provider> import UniversalAgent as Agent
agent = Agent(
# (optionally composable)
#
# model=Model(),
# expand_tools=[Tool()],
# expand_team=[OtherAgent()]
)
output, logs = agent.process('What happened on Friday?') # > (tool call) > 'Friday was your birthday!'Modular, and automatically optimized for any supported device 🔥
Most advanted configuration options remain available.
Those are defined by and specific to the universal model provider.
We encourage providers to use industry standard Hugging Face Transformers specifications, irrespective of the backend internally used for the detected device and translated accordingly, allowing for greater portability and adoption.
from <provider.agent> import UniversalAgent as Agent
from <provider.other_agent> import UniversalAgent as OtherAgent
from <provider.model> import UniversalModel as Model
from <provider.tool> import UniversalTool as Tool # e.g. API, database
# This is where the magic happens ✨
# Standardization of all layers make agents composable and generalized.
# They can now utilize any 3rd party tools or agents on the fly to achieve any tasks.
# Additionally, the models powering each agent can now be hot-swapped so that
# a team of agents shares the same intelligence(s), thus removing hardware overhead,
# and scaling at virtually no cost.
agent = Agent(
credentials='<token>', # (or) object containing credentials eg. { id: 'example', passkey: 'example' }
model=Model(), # see Universal Model API for customizations
expand_tools=[Tool()], # see Universal Tool API for customizations
expand_team=[OtherAgent()], # see Universal Agent API for customizations
configuration={
# agent configuration (eg. guardrails, behavior, tracing)
},
verbose=True # or string describing log level
)
output, logs = agent.process(
input=[
{
"role": "system",
"content": "You are a helpful model to recall schedules and set events."
},
{
"role": "user",
"content": "Can you schedule what we did in May again for the next month?"
},
], # multimodal
context=['May: Went to the Cinema', 'June: Listened to Music'], # multimodal
configuration={
# (example)
# e.g. AutoModel Generate https://huggingface.co/docs/transformers/llm_tutorial
#
# max_new_tokens: 2000,
# use_cache: True,
# temperature: 1.0
# ...
},
remember=True, # remember this interaction
stream=False, # stream output asynchronously
extra_tools=[Tool()], # extra tools available for this inference; call `agent.connect()` link during initiation to persist them
extra_team=[OtherAgent()], # extra agents available for this inference; call `agent.connect()` link during initiation to persist them
keep_alive=True # keep model loaded after processing the request
)
# > "In May, you went to the Cinema. Let me check the location for you."
# > (tool call: database)
# > "It was in Hollywood. Let me schedule a reminder for next month."
# > (agent call: scheduler)
# > "Alright you are all set! Hollywood cinema is now scheduled again in July."from <provider.agent> import UniversalAgent as Agent
from <provider.other_agent> import UniversalAgent as OtherAgent
from <provider.model> import UniversalModel as Model
from <provider.tool> import UniversalTool as Tool # e.g. API, database
agent = Agent()
other_agent = OtherAgent()
tool = Tool()
# Optional
agent.load() # loads the agent's model in memory (otherwise automatically loaded/unloaded on execution of `.process()`)
agent.loaded() # checks if agent is loaded
agent.unload() # unloads the agent's model from memory (otherwise automatically loaded/unloaded on execution of `.process()`)
agent.reset() # resets remembered chat history
agent.connect(tools=[tool], agents=[other_agent]) # connects additionnal tools/agents
agent.disconnect(tools=[tool], agents=[other_agent]) # disconnects tools/agents
# Class Optional
Agent.contract() # Contract
Agent.requirements() # Configuration Requirements
Agent.compatibility() # Compatibility A self-contained environment for running AI models with standardized interfaces.
| Method | Parameters | Return Type | Description |
|---|---|---|---|
__init__ |
• credentials: str | Dict = None: Authentication information (e.g. authentication token (or) object containing credentials such as { id: 'example', passkey: 'example' })• engine: str | List[str] = None: Engine used (e.g., 'transformers', 'llama.cpp', (or) ordered by priority ['transformers', 'llama.cpp']). Prefer setting quantizations over engines for broader portability.• quantization: str | List[str] | QuantizationSettings = None: Quantization specification (e.g., 'Q4_K_M', (or) ordered by priority ['Q4_K_M', 'Q8_0'] (or) auto in range {'default': 'Q4_K_M', 'min_precision': '4bit', 'max_precision': '8bit'})• max_memory_allocation: float = None: Maximum allowed memory allocation in percentage• configuration: Dict = None: Configuration for model and processor settings• verbose: bool | str = "DEFAULT": Enable/Disable logs, or set a specific log level |
None |
Initialize a Universal Model |
process |
• input: Any | List[Message]: Input or input messages• context: List[Any] = None: Context items (multimodal supported)• configuration: Dict = None: Runtime configuration• remember: bool = False: Whether to remember this interaction. Please be mindful of the available context length of the underlaying model.• stream: bool = False: Stream output asynchronously• keep_alive: bool = None: Keep model loaded for faster consecutive interactions |
Tuple[Any, Dict] |
Process input through the model and return output and logs. The output is typically the model's response and the logs contain processing metadata |
load |
None | None |
Load model into memory |
loaded |
None | bool |
Check if model is currently loaded in memory |
unload |
None | None |
Unload model from memory |
reset |
None | None |
Reset model chat history |
configuration |
None | Dict |
Get current model configuration |
(class).contract |
None | Contract |
Model description and interface specification |
(class).compatibility |
None | List[Compatibility] |
Model compatibility specification |
A standardized interface for tools that can be used by models and agents.
| Method | Parameters | Return Type | Description |
|---|---|---|---|
__init__ |
• configuration: Dict = None: Tool configuration including credentials |
None |
Initialize a Universal Tool |
(class).contract |
None | Contract |
Tool description and interface specification |
(class).requirements |
None | List[Requirement] |
Tool configuration requirements |
Additional methods are defined by the specific tool implementation and documented in the tool's contract.
Any tool specific method must return a tuple[Any, dict], respectively (result, logs).
An AI agent powered by Universal Models and Tools with standardized interfaces.
| Method | Parameters | Return Type | Description |
|---|---|---|---|
__init__ |
• credentials: str | Dict = None: Authentication information (e.g. authentication token (or) object containing credentials such as { id: 'example', passkey: 'example' })• model: UniversalModel = None: Model powering this agent• expand_tools: List[UniversalTool] = None: Tools to connect• expand_team: List[UniversalAgent] = None: Other agents to connect• configuration: Dict = None: Agent configuration (eg. guardrails, behavior, tracing)• verbose: bool | str = "DEFAULT": Enable/Disable logs, or set a specific log level |
None |
Initialize a Universal Agent |
process |
• input: Any | List[Message]: Input or input messages• context: List[Any] = None: Context items (multimodal)• configuration: Dict = None: Runtime configuration• remember: bool = False: Remember this interaction. Please be mindful of the available context length of the underlaying model.• stream: bool = False: Stream output asynchronously• extra_tools: List[UniversalTool] = None: Additional tools• extra_team: List[UniversalAgent] = None: Additional agents• keep_alive: bool = None: Keep underlaying model loaded for faster consecutive interactions |
Tuple[Any, Dict] |
Process input through the agent and return output and logs. The output is typically the agent's response and the logs contain processing metadata including tool/agent calls |
load |
None | None |
Load agent's model into memory |
loaded |
None | bool |
Check if the agent's model is currently loaded in memory |
unload |
None | None |
Unload agent's model from memory |
reset |
None | None |
Reset agent's chat history |
connect |
• tools: List[UniversalTool] = None: Tools to connect• agents: List[UniversalAgent] = None: Agents to connect |
None |
Connect additional tools and agents |
disconnect |
• tools: List[UniversalTool] = None: Tools to disconnect• agents: List[UniversalAgent] = None: Agents to disconnect |
None |
Disconnect tools and agents |
(class).contract |
None | Contract |
Agent description and interface specification |
(class).requirements |
None | List[Requirement] |
Agent configuration requirements |
(class).compatibility |
None | List[Compatibility] |
Agent compatibility specification |
| Field | Type | Description |
|---|---|---|
role |
str |
The role of the message sender (e.g., "system", "user") |
content |
Any |
The content of the message (multimodal supported) |
| Field | Type | Description |
|---|---|---|
maxLength |
Optional[int] |
Maximum length constraint |
minLength |
Optional[int] |
Maximum length constraint |
pattern |
Optional[str] |
Pattern constraint |
nested |
Optional[List[Argument]] |
Nested argument definitions for complex types |
properties |
Optional[Dict[str, Schema]] |
Property definitions for object types |
items |
Optional[Schema] |
Schema for array items |
Expandable as needed
| Field | Type | Description |
|---|---|---|
name |
str |
Name of the argument |
type |
str |
Type of the argument |
schema |
Optional[Schema] |
Schema constraints |
description |
str |
Description of the argument |
required |
bool |
Whether the argument is required |
| Field | Type | Description |
|---|---|---|
type |
str |
Type of the output |
description |
str |
Description of the output |
required |
bool |
Whether the output is required |
| Field | Type | Description |
|---|---|---|
name |
str |
Name of the method |
description |
str |
Description of the method |
arguments |
List[Argument] |
List of method arguments |
outputs |
List[Output] |
List of method outputs |
asynchronous |
Optional[bool] |
Whether the method is asynchronous (default: False) |
| Field | Type | Description |
|---|---|---|
name |
str |
Name of the contract |
description |
str |
Description of the contract |
methods |
List[Method] |
List of available methods |
When describing a Universal Model, we encourage providers to document core information such as parameter counts and context sizes.
| Field | Type | Description |
|---|---|---|
name |
str |
Name of the requirement |
type |
str |
Type of the requirement |
schema |
Schema |
Schema constraints |
description |
str |
Description of the requirement |
required |
bool |
Whether the requirement is required |
| Field | Type | Description |
|---|---|---|
engine |
str |
Supported engine |
quantization |
str |
Supported quantization |
devices |
List[str] |
List of supported devices |
memory |
float |
Required memory in GB |
dependencies |
List[str] |
Required software dependencies |
precision |
int |
Precision in bits |
| Field | Type | Description |
|---|---|---|
default |
Optional[str] |
Default quantization to use (e.g., 'Q4_K_M'), otherwise using defaults set in sources.yaml |
min_precision |
Optional[str] |
Minimum precision requirement (e.g., '4bit'). Default: Lowest between 4 bit and the default's precision if explicitly provided. |
max_precision |
Optional[str] |
Maximum precision requirement (e.g., '8bit'). Default: 8 bit or the default's precision if explicitly provided. |
Expandable as needed
Abstract classes and types for Universal Intelligence components are made available by the package if you wish to develop and publish your own.
# Install abstracts
pip install universal-intelligencefrom universal_intelligence.core import AbstractUniversalModel, AbstractUniversalTool, AbstractUniversalAgent, types
class UniversalModel(AbstractUniversalModel):
# ...
pass
class UniversalTool(AbstractUniversalTool):
# ...
pass
class UniversalAgent(AbstractUniversalAgent):
# ...
passIf you wish to contribute to community based components, mixins are made available to allow quickly bootstrapping new Universal Models.
See Community>Development section below for additional information.
Community Components
The universal-intelligence package provides several community-built models, agents, and tools that you can use out of the box.
# Install with device optimizations
pip install "universal-intelligence[community,mps]" # Apple
pip install "universal-intelligence[community,cuda]" # NVIDIASome components may require additional dependencies. These can be installed on demand.
# Install MCP specific dependencies
pip install "universal-intelligence[community,mps,mcp]" # Apple
pip install "universal-intelligence[community,cuda,mcp]" # NVIDIASome of the community components interface with gated models, in which case you may have to accept the model's terms on Hugging Face and log into that approved account.
You may do so in your terminal using
huggingface-cli loginor in your code:
from huggingface_hub import login login()
You can get familiar with the library using our ready-made playground
python -m playground.example from universal_intelligence.community.models.local.default import UniversalModel as Model
model = Model()
output, logs = model.process("How are you doing today?")View Universal Intelligence Protocols for additional information.
from universal_intelligence.community.models.remote.default import UniversalModel as Model
model = Model(credentials='your-openrouter-api-key-here')
output, logs = model.process("How are you doing today?")View Universal Intelligence Protocols for additional information.
from universal_intelligence.community.tools.simple_printer import UniversalTool as Tool
tool = Tool()
result, logs = tool.print_text("This needs to be printed")View Universal Intelligence Protocols for additional information.
from universal_intelligence.community.agents.default import UniversalAgent as Agent
agent = Agent(
# model=Model(), # customize or share 🧠 across [🤖,🤖,🤖,..]
# expand_tools=[Tool()], # expand 🔧 set
# expand_team=[OtherAgent()] # expand 🤖 team
)
result, logs = agent.process("Please print 'Hello World' to the console", extra_tools=[Tool()])View Universal Intelligence Protocols for additional information.
Import path:
universal_intelligence.community.models.local.<import>(eg. universal_intelligence.community.models.local.default)
| I/O | Name | Import | Description | Supported Configurations |
|---|---|---|---|---|
| Text/Text | Qwen2.5-7B-Instruct (default) | defaultor qwen2_5_7b_instruct |
Small powerful model by Alibaba Cloud | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-32B-Instruct | qwen2_5_32b_instruct |
Large powerful model by Alibaba Cloud | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-14B-Instruct | qwen2_5_14b_instruct |
Medium powerful model by Alibaba Cloud | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-14B-Instruct-1M | qwen2_5_14b_instruct_1m |
Medium powerful model with 1M context by Alibaba Cloud | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-7B-Instruct-1M | qwen2_5_7b_instruct_1m |
Small powerful model with 1M context by Alibaba Cloud | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-3B-Instruct | qwen2_5_3b_instruct |
Compact powerful model by Alibaba Cloud | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-1.5B-Instruct | qwen2_5_1d5b_instruct |
Ultra-compact powerful model by Alibaba Cloud | Supported Configurations Default: cuda:bfloat16:transformersmps:MLX_8:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | gemma-3-27b-it | gemma3_27b_it |
Large powerful model by Google | Supported Configurations Default: cuda:Q4_K_M:llama.cppmps:Q4_K_M:llama.cppcpu:Q4_K_M:llama.cpp |
| Text/Text | gemma-3-12b-it | gemma3_12b_it |
Medium powerful model by Google | Supported Configurations Default: cuda:Q4_K_M:llama.cppmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | gemma-3-4b-it | gemma3_4b_it |
Small powerful model by Google | Supported Configurations Default: cuda:Q4_K_M:llama.cppmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | gemma-3-1b-it | gemma3_1b_it |
Ultra-compact powerful model by Google | Supported Configurations Default: cuda:bfloat16:transformersmps:bfloat16:transformerscpu:bfloat16:transformers |
| Text/Text | falcon-3-10b-instruct | falcon3_10b_instruct |
Medium powerful model by TII | Supported Configurations Default: cuda:AWQ_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | falcon-3-7b-instruct | falcon3_7b_instruct |
Small powerful model by TII | Supported Configurations Default: cuda:Q4_K_M:llama.cppmps:Q4_K_M:llama.cppcpu:Q4_K_M:llama.cpp |
| Text/Text | falcon-3-3b-instruct | falcon3_3b_instruct |
Compact powerful model by TII | Supported Configurations Default: cuda:bfloat16:transformersmps:bfloat16:transformerscpu:bfloat16:transformers |
| Text/Text | Llama-3.3-70B-Instruct | llama3_3_70b_instruct |
Large powerful model by Meta | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Llama-3.1-8B-Instruct | llama3_1_8b_instruct |
Small powerful model by Meta | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Llama-3.2-3B-Instruct | llama3_2_3b_instruct |
Compact powerful model by Meta | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Llama-3.2-1B-Instruct | llama3_2_1b_instruct |
Ultra-compact powerful model by Meta | Supported Configurations Default: cuda:bfloat16:transformersmps:bfloat16:transformerscpu:Q4_K_M:llama.cpp |
| Text/Text | phi-4 | phi4 |
Small powerful model by Microsoft | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | phi-4-mini-instruct | phi4_mini_instruct |
Compact powerful model by Microsoft | Supported Configurations Default: cuda:Q4_K_M:llama.cppmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | smollm2-1.7b-instruct | smollm2_1d7b_instruct |
Small powerful model by SmolLM | Supported Configurations Default: cuda:bfloat16:transformersmps:MLX_8:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | smollm2-360m-instruct | smollm2_360m_instruct |
Ultra-compact powerful model by SmolLM | Supported Configurations Default: cuda:bfloat16:transformersmps:MLX_8:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | smollm2-135m-instruct | smollm2_135m_instruct |
Ultra-compact powerful model by SmolLM | Supported Configurations Default: cuda:bfloat16:transformersmps:MLX_8:mlxcpu:bfloat16:transformers |
| Text/Text | mistral-7b-instruct-v0.3 | mistral_7b_instruct_v0d3 |
Small powerful model by Mistral | Supported Configurations Default: cuda:Q4_K_M:llama.cppmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | mistral-nemo-instruct-2407 | mistral_nemo_instruct_2407 |
Small powerful model by Mistral | Supported Configurations Default: cuda:AWQ_4:transformersmps:MLX_3:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | OpenR1-Qwen-7B | openr1_qwen_7b |
Medium powerful model by Open R1 | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | QwQ-32B | qwq_32b |
Large powerful model by Qwen | Supported Configurations Default: cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
Import path:
universal_intelligence.community.models.remote.<import>(eg. universal_intelligence.community.models.remote.default)
| I/O | Name | Import | Description | Provider |
|---|---|---|---|---|
| Text/Text | openrouter/auto | default (default) |
Your prompt will be processed by a meta-model and routed to one of dozens of models (see below), optimizing for the best possible output. To see which model was used, visit Activity, or read the model attribute of the response. Your response will be priced at the same rate as the routed model. The meta-model is powered by Not Diamond. Learn more in our docs. Requests will be routed to the following models:- openai/gpt-4o-2024-08-06- openai/gpt-4o-2024-05-13- openai/gpt-4o-mini-2024-07-18- openai/chatgpt-4o-latest- openai/o1-preview-2024-09-12- openai/o1-mini-2024-09-12- anthropic/claude-3.5-sonnet- anthropic/claude-3.5-haiku- anthropic/claude-3-opus- anthropic/claude-2.1- google/gemini-pro-1.5- google/gemini-flash-1.5- mistralai/mistral-large-2407- mistralai/mistral-nemo- deepseek/deepseek-r1- meta-llama/llama-3.1-70b-instruct- meta-llama/llama-3.1-405b-instruct- mistralai/mixtral-8x22b-instruct- cohere/command-r-plus- cohere/command-r |
openrouter |
| Text/Text | 01-ai/yi-large | yi_large |
The Yi Large model was designed by 01.AI with the following usecases in mind: knowledge search, data classification, human-like chat bots, and customer service. It stands out for its multilingual proficiency, particularly in Spanish, Chinese, Japanese, German, and French. Check out the launch announcement to learn more. | openrouter |
| Text/Text | aetherwiing/mn-starcannon-12b | mn_starcannon_12b |
Starcannon 12B v2 is a creative roleplay and story writing model, based on Mistral Nemo, using nothingiisreal/mn-celeste-12b as a base, with intervitens/mini-magnum-12b-v1.1 merged in using the TIES method. Although more similar to Magnum overall, the model remains very creative, with a pleasant writing style. It is recommended for people wanting more variety than Magnum, and yet more verbose prose than Celeste. | openrouter |
| Text/Text | agentica-org/deepcoder-14b-preview:free | deepcoder_14b_preview__free |
DeepCoder-14B-Preview is a 14B parameter code generation model fine-tuned from DeepSeek-R1-Distill-Qwen-14B using reinforcement learning with GRPO+ and iterative context lengthening. It is optimized for long-context program synthesis and achieves strong performance across coding benchmarks, including 60.6% on LiveCodeBench v5, competitive with models like o3-Mini | openrouter |
| Text/Text | ai21/jamba-1.6-large | jamba_1_6_large |
AI21 Jamba Large 1.6 is a high-performance hybrid foundation model combining State Space Models (Mamba) with Transformer attention mechanisms. Developed by AI21, it excels in extremely long-context handling (256K tokens), demonstrates superior inference efficiency (up to 2.5x faster than comparable models), and supports structured JSON output and tool-use capabilities. It has 94 billion active parameters (398 billion total), optimized quantization support (ExpertsInt8), and multilingual proficiency in languages such as English, Spanish, French, Portuguese, Italian, Dutch, German, Arabic, and Hebrew. Usage of this model is subject to the Jamba Open Model License. | openrouter |
| Text/Text | ai21/jamba-1.6-mini | jamba_1_6_mini |
AI21 Jamba Mini 1.6 is a hybrid foundation model combining State Space Models (Mamba) with Transformer attention mechanisms. With 12 billion active parameters (52 billion total), this model excels in extremely long-context tasks (up to 256K tokens) and achieves superior inference efficiency, outperforming comparable open models on tasks such as retrieval-augmented generation (RAG) and grounded question answering. Jamba Mini 1.6 supports multilingual tasks across English, Spanish, French, Portuguese, Italian, Dutch, German, Arabic, and Hebrew, along with structured JSON output and tool-use capabilities. Usage of this model is subject to the Jamba Open Model License. | openrouter |
| Text/Text | ai21/jamba-instruct | jamba_instruct |
The Jamba-Instruct model, introduced by AI21 Labs, is an instruction-tuned variant of their hybrid SSM-Transformer Jamba model, specifically optimized for enterprise applications.- 256K Context Window: It can process extensive information, equivalent to a 400-page novel, which is beneficial for tasks involving large documents such as financial reports or legal documents- Safety and Accuracy: Jamba-Instruct is designed with enhanced safety features to ensure secure deployment in enterprise environments, reducing the risk and cost of implementation Read their announcement to learn more. Jamba has a knowledge cutoff of February 2024. | openrouter |
| Text/Text | aion-labs/aion-1.0 | aion_1_0 |
Aion-1.0 is a multi-model system designed for high performance across various tasks, including reasoning and coding. It is built on DeepSeek-R1, augmented with additional models and techniques such as Tree of Thoughts (ToT) and Mixture of Experts (MoE). It is Aion Lab's most powerful reasoning model. | openrouter |
| Text/Text | aion-labs/aion-1.0-mini | aion_1_0_mini |
Aion-1.0-Mini 32B parameter model is a distilled version of the DeepSeek-R1 model, designed for strong performance in reasoning domains such as mathematics, coding, and logic. It is a modified variant of a FuseAI model that outperforms R1-Distill-Qwen-32B and R1-Distill-Llama-70B, with benchmark results available on its Hugging Face page, independently replicated for verification. | openrouter |
| Text/Text | aion-labs/aion-rp-llama-3.1-8b | aion_rp_llama_3_1_8b |
Aion-RP-Llama-3.1-8B ranks the highest in the character evaluation portion of the RPBench-Auto benchmark, a roleplaying-specific variant of Arena-Hard-Auto, where LLMs evaluate each other's responses. It is a fine-tuned base model rather than an instruct model, designed to produce more natural and varied writing. | openrouter |
| Text/Text | alfredpros/codellama-7b-instruct-solidity | codellama_7b_instruct_solidity |
A finetuned 7 billion parameters Code LLaMA - Instruct model to generate Solidity smart contract using 4-bit QLoRA finetuning provided by PEFT library. | openrouter |
| Text/Text | all-hands/openhands-lm-32b-v0.1 | openhands_lm_32b_v0_1 |
OpenHands LM v0.1 is a 32B open-source coding model fine-tuned from Qwen2.5-Coder-32B-Instruct using reinforcement learning techniques outlined in SWE-Gym. It is optimized for autonomous software development agents and achieves strong performance on SWE-Bench Verified, with a 37.2% resolve rate. The model supports a 128K token context window, making it well-suited for long-horizon code reasoning and large codebase tasks. OpenHands LM is designed for local deployment and runs on consumer-grade GPUs such as a single 3090. It enables fully offline agent workflows without dependency on proprietary APIs. This release is intended as a research preview, and future updates aim to improve generalizability, reduce repetition, and offer smaller variants. | openrouter |
| Text/Text | allenai/olmo-7b-instruct | olmo_7b_instruct |
OLMo 7B Instruct by the Allen Institute for AI is a model finetuned for question answering. It demonstrates notable performance across multiple benchmarks including TruthfulQA and ToxiGen.Open Source: The model, its code, checkpoints, logs are released under the Apache 2.0 license.- Core repo (training, inference, fine-tuning etc.)- Evaluation code- Further fine-tuning code- Paper- Technical blog post- W&B Logs | openrouter |
| Text/Text | alpindale/goliath-120b | goliath_120b |
A large LLM created by combining two fine-tuned Llama 70B models into one 120B model. Combines Xwin and Euryale. Credits to- @chargoddard for developing the framework used to merge the model - mergekit.- @Undi95 for helping with the merge ratios.#merge | openrouter |
| Text/Text | alpindale/magnum-72b | magnum_72b |
From the maker of Goliath, Magnum 72B is the first in a new family of models designed to achieve the prose quality of the Claude 3 models, notably Opus & Sonnet. The model is based on Qwen2 72B and trained with 55 million tokens of highly curated roleplay (RP) data. | openrouter |
| Text/Text | amazon/nova-lite-v1 | nova_lite_v1 |
Amazon Nova Lite 1.0 is a very low-cost multimodal model from Amazon that focused on fast processing of image, video, and text inputs to generate text output. Amazon Nova Lite can handle real-time customer interactions, document analysis, and visual question-answering tasks with high accuracy. With an input context of 300K tokens, it can analyze multiple images or up to 30 minutes of video in a single input. | openrouter |
| Text/Text | amazon/nova-micro-v1 | nova_micro_v1 |
Amazon Nova Micro 1.0 is a text-only model that delivers the lowest latency responses in the Amazon Nova family of models at a very low cost. With a context length of 128K tokens and optimized for speed and cost, Amazon Nova Micro excels at tasks such as text summarization, translation, content classification, interactive chat, and brainstorming. It has simple mathematical reasoning and coding abilities. | openrouter |
| Text/Text | amazon/nova-pro-v1 | nova_pro_v1 |
Amazon Nova Pro 1.0 is a capable multimodal model from Amazon focused on providing a combination of accuracy, speed, and cost for a wide range of tasks. As of December 2024, it achieves state-of-the-art performance on key benchmarks including visual question answering (TextVQA) and video understanding (VATEX). Amazon Nova Pro demonstrates strong capabilities in processing both visual and textual information and at analyzing financial documents.NOTE: Video input is not supported at this time. | openrouter |
| Text/Text | anthracite-org/magnum-v2-72b | magnum_v2_72b |
From the maker of Goliath, Magnum 72B is the seventh in a family of models designed to achieve the prose quality of the Claude 3 models, notably Opus & Sonnet. The model is based on Qwen2 72B and trained with 55 million tokens of highly curated roleplay (RP) data. | openrouter |
| Text/Text | anthracite-org/magnum-v4-72b | magnum_v4_72b |
This is a series of models designed to replicate the prose quality of the Claude 3 models, specifically Sonnet(https://openrouter.ai/anthropic/claude-3.5-sonnet) and Opus(https://openrouter.ai/anthropic/claude-3-opus). The model is fine-tuned on top of Qwen2.5 72B. | openrouter |
| Text/Text | anthropic/claude-2 | claude_2 |
Claude 2 delivers advancements in key capabilities for enterprises—including an industry-leading 200K token context window, significant reductions in rates of model hallucination, system prompts and a new beta feature: tool use. | openrouter |
| Text/Text | anthropic/claude-2.0 | claude_2_0 |
Anthropic's flagship model. Superior performance on tasks that require complex reasoning. Supports hundreds of pages of text. | openrouter |
| Text/Text | anthropic/claude-2.0:beta | claude_2_0__beta |
Anthropic's flagship model. Superior performance on tasks that require complex reasoning. Supports hundreds of pages of text. | openrouter |
| Text/Text | anthropic/claude-2.1 | claude_2_1 |
Claude 2 delivers advancements in key capabilities for enterprises—including an industry-leading 200K token context window, significant reductions in rates of model hallucination, system prompts and a new beta feature: tool use. | openrouter |
| Text/Text | anthropic/claude-2.1:beta | claude_2_1__beta |
Claude 2 delivers advancements in key capabilities for enterprises—including an industry-leading 200K token context window, significant reductions in rates of model hallucination, system prompts and a new beta feature: tool use. | openrouter |
| Text/Text | anthropic/claude-2:beta | claude_2__beta |
Claude 2 delivers advancements in key capabilities for enterprises—including an industry-leading 200K token context window, significant reductions in rates of model hallucination, system prompts and a new beta feature: tool use. | openrouter |
| Text/Text | anthropic/claude-3-haiku | claude_3_haiku |
Claude 3 Haiku is Anthropic's fastest and most compact model for near-instant responsiveness. Quick and accurate targeted performance. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-haiku:beta | claude_3_haiku__beta |
Claude 3 Haiku is Anthropic's fastest and most compact model for near-instant responsiveness. Quick and accurate targeted performance. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-opus | claude_3_opus |
Claude 3 Opus is Anthropic's most powerful model for highly complex tasks. It boasts top-level performance, intelligence, fluency, and understanding. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-opus:beta | claude_3_opus__beta |
Claude 3 Opus is Anthropic's most powerful model for highly complex tasks. It boasts top-level performance, intelligence, fluency, and understanding. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-sonnet | claude_3_sonnet |
Claude 3 Sonnet is an ideal balance of intelligence and speed for enterprise workloads. Maximum utility at a lower price, dependable, balanced for scaled deployments. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-sonnet:beta | claude_3_sonnet__beta |
Claude 3 Sonnet is an ideal balance of intelligence and speed for enterprise workloads. Maximum utility at a lower price, dependable, balanced for scaled deployments. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3.5-haiku | claude_3_5_haiku |
Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Engineered to excel in real-time applications, it delivers quick response times that are essential for dynamic tasks such as chat interactions and immediate coding suggestions. This makes it highly suitable for environments that demand both speed and precision, such as software development, customer service bots, and data management systems. This model is currently pointing to Claude 3.5 Haiku (2024-10-22). | openrouter |
| Text/Text | anthropic/claude-3.5-haiku-20241022 | claude_3_5_haiku_20241022 |
Claude 3.5 Haiku features enhancements across all skill sets including coding, tool use, and reasoning. As the fastest model in the Anthropic lineup, it offers rapid response times suitable for applications that require high interactivity and low latency, such as user-facing chatbots and on-the-fly code completions. It also excels in specialized tasks like data extraction and real-time content moderation, making it a versatile tool for a broad range of industries. It does not support image inputs. See the launch announcement and benchmark results here | openrouter |
| Text/Text | anthropic/claude-3.5-haiku-20241022:beta | claude_3_5_haiku_20241022__beta |
Claude 3.5 Haiku features enhancements across all skill sets including coding, tool use, and reasoning. As the fastest model in the Anthropic lineup, it offers rapid response times suitable for applications that require high interactivity and low latency, such as user-facing chatbots and on-the-fly code completions. It also excels in specialized tasks like data extraction and real-time content moderation, making it a versatile tool for a broad range of industries. It does not support image inputs. See the launch announcement and benchmark results here | openrouter |
| Text/Text | anthropic/claude-3.5-haiku:beta | claude_3_5_haiku__beta |
Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Engineered to excel in real-time applications, it delivers quick response times that are essential for dynamic tasks such as chat interactions and immediate coding suggestions. This makes it highly suitable for environments that demand both speed and precision, such as software development, customer service bots, and data management systems. This model is currently pointing to Claude 3.5 Haiku (2024-10-22). | openrouter |
| Text/Text | anthropic/claude-3.5-sonnet | claude_3_5_sonnet |
New Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:- Coding: Scores ~49% on SWE-Bench Verified, higher than the last best score, and without any fancy prompt scaffolding- Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights- Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone- Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems)#multimodal | openrouter |
| Text/Text | anthropic/claude-3.5-sonnet-20240620 | claude_3_5_sonnet_20240620 |
Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:- Coding: Autonomously writes, edits, and runs code with reasoning and troubleshooting- Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights- Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone- Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems) For the latest version (2024-10-23), check out Claude 3.5 Sonnet.#multimodal | openrouter |
| Text/Text | anthropic/claude-3.5-sonnet-20240620:beta | claude_3_5_sonnet_20240620__beta |
Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:- Coding: Autonomously writes, edits, and runs code with reasoning and troubleshooting- Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights- Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone- Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems) For the latest version (2024-10-23), check out Claude 3.5 Sonnet.#multimodal | openrouter |
| Text/Text | anthropic/claude-3.5-sonnet:beta | claude_3_5_sonnet__beta |
New Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:- Coding: Scores ~49% on SWE-Bench Verified, higher than the last best score, and without any fancy prompt scaffolding- Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights- Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone- Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems)#multimodal | openrouter |
| Text/Text | anthropic/claude-3.7-sonnet | claude_3_7_sonnet |
Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. It introduces a hybrid reasoning approach, allowing users to choose between rapid responses and extended, step-by-step processing for complex tasks. The model demonstrates notable improvements in coding, particularly in front-end development and full-stack updates, and excels in agentic workflows, where it can autonomously navigate multi-step processes. Claude 3.7 Sonnet maintains performance parity with its predecessor in standard mode while offering an extended reasoning mode for enhanced accuracy in math, coding, and instruction-following tasks. Read more at the blog post here | openrouter |
| Text/Text | anthropic/claude-3.7-sonnet:beta | claude_3_7_sonnet__beta |
Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. It introduces a hybrid reasoning approach, allowing users to choose between rapid responses and extended, step-by-step processing for complex tasks. The model demonstrates notable improvements in coding, particularly in front-end development and full-stack updates, and excels in agentic workflows, where it can autonomously navigate multi-step processes. Claude 3.7 Sonnet maintains performance parity with its predecessor in standard mode while offering an extended reasoning mode for enhanced accuracy in math, coding, and instruction-following tasks. Read more at the blog post here | openrouter |
| Text/Text | anthropic/claude-3.7-sonnet:thinking | claude_3_7_sonnet__thinking |
Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. It introduces a hybrid reasoning approach, allowing users to choose between rapid responses and extended, step-by-step processing for complex tasks. The model demonstrates notable improvements in coding, particularly in front-end development and full-stack updates, and excels in agentic workflows, where it can autonomously navigate multi-step processes. Claude 3.7 Sonnet maintains performance parity with its predecessor in standard mode while offering an extended reasoning mode for enhanced accuracy in math, coding, and instruction-following tasks. Read more at the blog post here | openrouter |
| Text/Text | arcee-ai/arcee-blitz | arcee_blitz |
Arcee Blitz is a 24 B‑parameter dense model distilled from DeepSeek and built on Mistral architecture for 'everyday' chat. The distillation‑plus‑refinement pipeline trims compute while keeping DeepSeek‑style reasoning, so Blitz punches above its weight on MMLU, GSM‑8K and BBH compared with other mid‑size open models. With a default 128 k context window and competitive throughput, it serves as a cost‑efficient workhorse for summarization, brainstorming and light code help. Internally, Arcee uses Blitz as the default writer in Conductor pipelines when the heavier Virtuoso line is not required. Users therefore get near‑70 B quality at ~⅓ the latency and price. | openrouter |
| Text/Text | arcee-ai/caller-large | caller_large |
Caller Large is Arcee's specialist 'function‑calling' SLM built to orchestrate external tools and APIs. Instead of maximizing next‑token accuracy, training focuses on structured JSON outputs, parameter extraction and multi‑step tool chains, making Caller a natural choice for retrieval‑augmented generation, robotic process automation or data‑pull chatbots. It incorporates a routing head that decides when (and how) to invoke a tool versus answering directly, reducing hallucinated calls. The model is already the backbone of Arcee Conductor's auto‑tool mode, where it parses user intent, emits clean function signatures and hands control back once the tool response is ready. Developers thus gain an OpenAI‑style function‑calling UX without handing requests to a frontier‑scale model. | openrouter |
| Text/Text | arcee-ai/coder-large | coder_large |
Coder‑Large is a 32 B‑parameter offspring of Qwen 2.5‑Instruct that has been further trained on permissively‑licensed GitHub, CodeSearchNet and synthetic bug‑fix corpora. It supports a 32k context window, enabling multi‑file refactoring or long diff review in a single call, and understands 30‑plus programming languages with special attention to TypeScript, Go and Terraform. Internal benchmarks show 5–8 pt gains over CodeLlama‑34 B‑Python on HumanEval and competitive BugFix scores thanks to a reinforcement pass that rewards compilable output. The model emits structured explanations alongside code blocks by default, making it suitable for educational tooling as well as production copilot scenarios. Cost‑wise, Together AI prices it well below proprietary incumbents, so teams can scale interactive coding without runaway spend. | openrouter |
| Text/Text | arcee-ai/maestro-reasoning | maestro_reasoning |
Maestro Reasoning is Arcee's flagship analysis model: a 32 B‑parameter derivative of Qwen 2.5‑32 B tuned with DPO and chain‑of‑thought RL for step‑by‑step logic. Compared to the earlier 7 B preview, the production 32 B release widens the context window to 128 k tokens and doubles pass‑rate on MATH and GSM‑8K, while also lifting code completion accuracy. Its instruction style encourages structured 'thought → answer' traces that can be parsed or hidden according to user preference. That transparency pairs well with audit‑focused industries like finance or healthcare where seeing the reasoning path matters. In Arcee Conductor, Maestro is automatically selected for complex, multi‑constraint queries that smaller SLMs bounce. | openrouter |
| Text/Text | arcee-ai/virtuoso-large | virtuoso_large |
Virtuoso‑Large is Arcee's top‑tier general‑purpose LLM at 72 B parameters, tuned to tackle cross‑domain reasoning, creative writing and enterprise QA. Unlike many 70 B peers, it retains the 128 k context inherited from Qwen 2.5, letting it ingest books, codebases or financial filings wholesale. Training blended DeepSeek R1 distillation, multi‑epoch supervised fine‑tuning and a final DPO/RLHF alignment stage, yielding strong performance on BIG‑Bench‑Hard, GSM‑8K and long‑context Needle‑In‑Haystack tests. Enterprises use Virtuoso‑Large as the 'fallback' brain in Conductor pipelines when other SLMs flag low confidence. Despite its size, aggressive KV‑cache optimizations keep first‑token latency in the low‑second range on 8× H100 nodes, making it a practical production‑grade powerhouse. | openrouter |
| Text/Text | arcee-ai/virtuoso-medium-v2 | virtuoso_medium_v2 |
Virtuoso‑Medium‑v2 is a 32 B model distilled from DeepSeek‑v3 logits and merged back onto a Qwen 2.5 backbone, yielding a sharper, more factual successor to the original Virtuoso Medium. The team harvested ~1.1 B logit tokens and applied 'fusion‑merging' plus DPO alignment, which pushed scores past Arcee‑Nova 2024 and many 40 B‑plus peers on MMLU‑Pro, MATH and HumanEval. With a 128 k context and aggressive quantization options (from BF16 down to 4‑bit GGUF), it balances capability with deployability on single‑GPU nodes. Typical use cases include enterprise chat assistants, technical writing aids and medium‑complexity code drafting where Virtuoso‑Large would be overkill. | openrouter |
| Text/Text | arliai/qwq-32b-arliai-rpr-v1:free | qwq_32b_arliai_rpr_v1__free |
QwQ-32B-ArliAI-RpR-v1 is a 32B parameter model fine-tuned from Qwen/QwQ-32B using a curated creative writing and roleplay dataset originally developed for the RPMax series. It is designed to maintain coherence and reasoning across long multi-turn conversations by introducing explicit reasoning steps per dialogue turn, generated and refined using the base model itself. The model was trained using RS-QLORA+ on 8K sequence lengths and supports up to 128K context windows (with practical performance around 32K). It is optimized for creative roleplay and dialogue generation, with an emphasis on minimizing cross-context repetition while preserving stylistic diversity. | openrouter |
| Text/Text | cognitivecomputations/dolphin-mixtral-8x22b | dolphin_mixtral_8x22b |
Dolphin 2.9 is designed for instruction following, conversational, and coding. This model is a finetune of Mixtral 8x22B Instruct. It features a 64k context length and was fine-tuned with a 16k sequence length using ChatML templates. This model is a successor to Dolphin Mixtral 8x7B. The model is uncensored and is stripped of alignment and bias. It requires an external alignment layer for ethical use. Users are cautioned to use this highly compliant model responsibly, as detailed in a blog post about uncensored models at erichartford.com/uncensored-models.#moe #uncensored | openrouter |
| Text/Text | cognitivecomputations/dolphin3.0-mistral-24b:free | dolphin3_0_mistral_24b__free |
Dolphin 3.0 is the next generation of the Dolphin series of instruct-tuned models. Designed to be the ultimate general purpose local model, enabling coding, math, agentic, function calling, and general use cases. Dolphin aims to be a general purpose instruct model, similar to the models behind ChatGPT, Claude, Gemini. Part of the Dolphin 3.0 Collection Curated and trained by Eric Hartford, Ben Gitter, BlouseJury and Cognitive Computations | openrouter |
| Text/Text | cognitivecomputations/dolphin3.0-r1-mistral-24b:free | dolphin3_0_r1_mistral_24b__free |
Dolphin 3.0 R1 is the next generation of the Dolphin series of instruct-tuned models. Designed to be the ultimate general purpose local model, enabling coding, math, agentic, function calling, and general use cases. The R1 version has been trained for 3 epochs to reason using 800k reasoning traces from the Dolphin-R1 dataset. Dolphin aims to be a general purpose reasoning instruct model, similar to the models behind ChatGPT, Claude, Gemini. Part of the Dolphin 3.0 Collection Curated and trained by Eric Hartford, Ben Gitter, BlouseJury and Cognitive Computations | openrouter |
| Text/Text | cohere/command | command |
Command is an instruction-following conversational model that performs language tasks with high quality, more reliably and with a longer context than our base generative models. Use of this model is subject to Cohere's Usage Policy and SaaS Agreement. | openrouter |
| Text/Text | cohere/command-a | command_a |
Command A is an open-weights 111B parameter model with a 256k context window focused on delivering great performance across agentic, multilingual, and coding use cases. Compared to other leading proprietary and open-weights models Command A delivers maximum performance with minimum hardware costs, excelling on business-critical agentic and multilingual tasks. | openrouter |
| Text/Text | cohere/command-r | command_r |
Command-R is a 35B parameter model that performs conversational language tasks at a higher quality, more reliably, and with a longer context than previous models. It can be used for complex workflows like code generation, retrieval augmented generation (RAG), tool use, and agents. Read the launch post here. Use of this model is subject to Cohere's Usage Policy and SaaS Agreement. | openrouter |
| Text/Text | cohere/command-r-03-2024 | command_r_03_2024 |
Command-R is a 35B parameter model that performs conversational language tasks at a higher quality, more reliably, and with a longer context than previous models. It can be used for complex workflows like code generation, retrieval augmented generation (RAG), tool use, and agents. Read the launch post here. Use of this model is subject to Cohere's Usage Policy and SaaS Agreement. | openrouter |
| Text/Text | cohere/command-r-08-2024 | command_r_08_2024 |
command-r-08-2024 is an update of the Command R with improved performance for multilingual retrieval-augmented generation (RAG) and tool use. More broadly, it is better at math, code and reasoning and is competitive with the previous version of the larger Command R+ model. Read the launch post here. Use of this model is subject to Cohere's Usage Policy and SaaS Agreement. | openrouter |
| Text/Text | cohere/command-r-plus | command_r_plus |
Command R+ is a new, 104B-parameter LLM from Cohere. It's useful for roleplay, general consumer usecases, and Retrieval Augmented Generation (RAG). It offers multilingual support for ten key languages to facilitate global business operations. See benchmarks and the launch post here. Use of this model is subject to Cohere's Usage Policy and SaaS Agreement. | openrouter |
| Text/Text | cohere/command-r-plus-04-2024 | command_r_plus_04_2024 |
Command R+ is a new, 104B-parameter LLM from Cohere. It's useful for roleplay, general consumer usecases, and Retrieval Augmented Generation (RAG). It offers multilingual support for ten key languages to facilitate global business operations. See benchmarks and the launch post here. Use of this model is subject to Cohere's Usage Policy and SaaS Agreement. | openrouter |
| Text/Text | cohere/command-r-plus-08-2024 | command_r_plus_08_2024 |
command-r-plus-08-2024 is an update of the Command R+ with roughly 50% higher throughput and 25% lower latencies as compared to the previous Command R+ version, while keeping the hardware footprint the same. Read the launch post here. Use of this model is subject to Cohere's Usage Policy and SaaS Agreement. | openrouter |
| Text/Text | cohere/command-r7b-12-2024 | command_r7b_12_2024 |
Command R7B (12-2024) is a small, fast update of the Command R+ model, delivered in December 2024. It excels at RAG, tool use, agents, and similar tasks requiring complex reasoning and multiple steps. Use of this model is subject to Cohere's Usage Policy and SaaS Agreement. | openrouter |
| Text/Text | deepseek/deepseek-chat | deepseek_chat |
DeepSeek-V3 is the latest model from the DeepSeek team, building upon the instruction following and coding abilities of the previous versions. Pre-trained on nearly 15 trillion tokens, the reported evaluations reveal that the model outperforms other open-source models and rivals leading closed-source models. For model details, please visit the DeepSeek-V3 repo for more information, or see the launch announcement. | openrouter |
| Text/Text | deepseek/deepseek-chat-v3-0324 | deepseek_chat_v3_0324 |
DeepSeek V3, a 685B-parameter, mixture-of-experts model, is the latest iteration of the flagship chat model family from the DeepSeek team. It succeeds the DeepSeek V3 model and performs really well on a variety of tasks. | openrouter |
| Text/Text | deepseek/deepseek-chat-v3-0324:free | deepseek_chat_v3_0324__free |
DeepSeek V3, a 685B-parameter, mixture-of-experts model, is the latest iteration of the flagship chat model family from the DeepSeek team. It succeeds the DeepSeek V3 model and performs really well on a variety of tasks. | openrouter |
| Text/Text | deepseek/deepseek-chat:free | deepseek_chat__free |
DeepSeek-V3 is the latest model from the DeepSeek team, building upon the instruction following and coding abilities of the previous versions. Pre-trained on nearly 15 trillion tokens, the reported evaluations reveal that the model outperforms other open-source models and rivals leading closed-source models. For model details, please visit the DeepSeek-V3 repo for more information, or see the launch announcement. | openrouter |
| Text/Text | deepseek/deepseek-coder | deepseek_coder |
DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model. It is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. The original V1 model was trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. It was pre-trained on project-level code corpus by employing a extra fill-in-the-blank task. | openrouter |
| Text/Text | deepseek/deepseek-prover-v2 | deepseek_prover_v2 |
DeepSeek Prover V2 is a 671B parameter model, speculated to be geared towards logic and mathematics. Likely an upgrade from DeepSeek-Prover-V1.5 Not much is known about the model yet, as DeepSeek released it on Hugging Face without an announcement or description. | openrouter |
| Text/Text | deepseek/deepseek-prover-v2:free | deepseek_prover_v2__free |
DeepSeek Prover V2 is a 671B parameter model, speculated to be geared towards logic and mathematics. Likely an upgrade from DeepSeek-Prover-V1.5 Not much is known about the model yet, as DeepSeek released it on Hugging Face without an announcement or description. | openrouter |
| Text/Text | deepseek/deepseek-r1 | deepseek_r1 |
DeepSeek R1 is here: Performance on par with OpenAI o1, but open-sourced and with fully open reasoning tokens. It's 671B parameters in size, with 37B active in an inference pass. Fully open-source model & technical report. MIT licensed: Distill & commercialize freely! | openrouter |
| Text/Text | deepseek/deepseek-r1-distill-llama-70b | deepseek_r1_distill_llama_70b |
DeepSeek R1 Distill Llama 70B is a distilled large language model based on Llama-3.3-70B-Instruct, using outputs from DeepSeek R1. The model combines advanced distillation techniques to achieve high performance across multiple benchmarks, including:- AIME 2024 pass@1: 70.0- MATH-500 pass@1: 94.5- CodeForces Rating: 1633 The model leverages fine-tuning from DeepSeek R1's outputs, enabling competitive performance comparable to larger frontier models. | openrouter |
| Text/Text | deepseek/deepseek-r1-distill-llama-70b:free | deepseek_r1_distill_llama_70b__free |
DeepSeek R1 Distill Llama 70B is a distilled large language model based on Llama-3.3-70B-Instruct, using outputs from DeepSeek R1. The model combines advanced distillation techniques to achieve high performance across multiple benchmarks, including:- AIME 2024 pass@1: 70.0- MATH-500 pass@1: 94.5- CodeForces Rating: 1633 The model leverages fine-tuning from DeepSeek R1's outputs, enabling competitive performance comparable to larger frontier models. | openrouter |
| Text/Text | deepseek/deepseek-r1-distill-llama-8b | deepseek_r1_distill_llama_8b |
DeepSeek R1 Distill Llama 8B is a distilled large language model based on Llama-3.1-8B-Instruct, using outputs from DeepSeek R1. The model combines advanced distillation techniques to achieve high performance across multiple benchmarks, including:- AIME 2024 pass@1: 50.4- MATH-500 pass@1: 89.1- CodeForces Rating: 1205 The model leverages fine-tuning from DeepSeek R1's outputs, enabling competitive performance comparable to larger frontier models. Hugging Face: - Llama-3.1-8B - DeepSeek-R1-Distill-Llama-8B | |
| Text/Text | deepseek/deepseek-r1-distill-qwen-1.5b | deepseek_r1_distill_qwen_1_5b |
DeepSeek R1 Distill Qwen 1.5B is a distilled large language model based on Qwen 2.5 Math 1.5B, using outputs from DeepSeek R1. It's a very small and efficient model which outperforms GPT 4o 0513 on Math Benchmarks. Other benchmark results include:- AIME 2024 pass@1: 28.9- AIME 2024 cons@64: 52.7- MATH-500 pass@1: 83.9 The model leverages fine-tuning from DeepSeek R1's outputs, enabling competitive performance comparable to larger frontier models. | openrouter |
| Text/Text | deepseek/deepseek-r1-distill-qwen-14b | deepseek_r1_distill_qwen_14b |
DeepSeek R1 Distill Qwen 14B is a distilled large language model based on Qwen 2.5 14B, using outputs from DeepSeek R1. It outperforms OpenAI's o1-mini across various benchmarks, achieving new state-of-the-art results for dense models. Other benchmark results include:- AIME 2024 pass@1: 69.7- MATH-500 pass@1: 93.9- CodeForces Rating: 1481 The model leverages fine-tuning from DeepSeek R1's outputs, enabling competitive performance comparable to larger frontier models. | openrouter |
| Text/Text | deepseek/deepseek-r1-distill-qwen-14b:free | deepseek_r1_distill_qwen_14b__free |
DeepSeek R1 Distill Qwen 14B is a distilled large language model based on Qwen 2.5 14B, using outputs from DeepSeek R1. It outperforms OpenAI's o1-mini across various benchmarks, achieving new state-of-the-art results for dense models. Other benchmark results include:- AIME 2024 pass@1: 69.7- MATH-500 pass@1: 93.9- CodeForces Rating: 1481 The model leverages fine-tuning from DeepSeek R1's outputs, enabling competitive performance comparable to larger frontier models. | openrouter |
| Text/Text | deepseek/deepseek-r1-distill-qwen-32b | deepseek_r1_distill_qwen_32b |
DeepSeek R1 Distill Qwen 32B is a distilled large language model based on Qwen 2.5 32B, using outputs from DeepSeek R1. It outperforms OpenAI's o1-mini across various benchmarks, achieving new state-of-the-art results for dense models. Other benchmark results include:- AIME 2024 pass@1: 72.6- MATH-500 pass@1: 94.3- CodeForces Rating: 1691 The model leverages fine-tuning from DeepSeek R1's outputs, enabling competitive performance comparable to larger frontier models. | openrouter |
| Text/Text | deepseek/deepseek-r1-distill-qwen-32b:free | deepseek_r1_distill_qwen_32b__free |
DeepSeek R1 Distill Qwen 32B is a distilled large language model based on Qwen 2.5 32B, using outputs from DeepSeek R1. It outperforms OpenAI's o1-mini across various benchmarks, achieving new state-of-the-art results for dense models. Other benchmark results include:- AIME 2024 pass@1: 72.6- MATH-500 pass@1: 94.3- CodeForces Rating: 1691 The model leverages fine-tuning from DeepSeek R1's outputs, enabling competitive performance comparable to larger frontier models. | openrouter |
| Text/Text | deepseek/deepseek-r1-zero:free | deepseek_r1_zero__free |
DeepSeek-R1-Zero is a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step. It's 671B parameters in size, with 37B active in an inference pass. It demonstrates remarkable performance on reasoning. With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors. DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. See DeepSeek R1 for the SFT model. | openrouter |
| Text/Text | deepseek/deepseek-r1:free | deepseek_r1__free |
DeepSeek R1 is here: Performance on par with OpenAI o1, but open-sourced and with fully open reasoning tokens. It's 671B parameters in size, with 37B active in an inference pass. Fully open-source model & technical report. MIT licensed: Distill & commercialize freely! | openrouter |
| Text/Text | deepseek/deepseek-v3-base:free | deepseek_v3_base__free |
Note that this is a base model mostly meant for testing, you need to provide detailed prompts for the model to return useful responses. DeepSeek-V3 Base is a 671B parameter open Mixture-of-Experts (MoE) language model with 37B active parameters per forward pass and a context length of 128K tokens. Trained on 14.8T tokens using FP8 mixed precision, it achieves high training efficiency and stability, with strong performance across language, reasoning, math, and coding tasks. DeepSeek-V3 Base is the pre-trained model behind DeepSeek V3 | openrouter |
| Text/Text | eleutherai/llemma_7b | llemma_7b |
Llemma 7B is a language model for mathematics. It was initialized with Code Llama 7B weights, and trained on the Proof-Pile-2 for 200B tokens. Llemma models are particularly strong at chain-of-thought mathematical reasoning and using computational tools for mathematics, such as Python and formal theorem provers. | openrouter |
| Text/Text | eva-unit-01/eva-llama-3.33-70b | eva_llama_3_33_70b |
EVA Llama 3.33 70b is a roleplay and storywriting specialist model. It is a full-parameter finetune of Llama-3.3-70B-Instruct on mixture of synthetic and natural data. It uses Celeste 70B 0.1 data mixture, greatly expanding it to improve versatility, creativity and 'flavor' of the resulting model This model was built with Llama by Meta. | openrouter |
| Text/Text | eva-unit-01/eva-qwen-2.5-32b | eva_qwen_2_5_32b |
EVA Qwen2.5 32B is a roleplaying/storywriting specialist model. It's a full-parameter finetune of Qwen2.5-32B on mixture of synthetic and natural data. It uses Celeste 70B 0.1 data mixture, greatly expanding it to improve versatility, creativity and 'flavor' of the resulting model. | openrouter |
| Text/Text | eva-unit-01/eva-qwen-2.5-72b | eva_qwen_2_5_72b |
EVA Qwen2.5 72B is a roleplay and storywriting specialist model. It's a full-parameter finetune of Qwen2.5-72B on mixture of synthetic and natural data. It uses Celeste 70B 0.1 data mixture, greatly expanding it to improve versatility, creativity and 'flavor' of the resulting model. | openrouter |
| Text/Text | featherless/qwerky-72b:free | qwerky_72b__free |
Qwerky-72B is a linear-attention RWKV variant of the Qwen 2.5 72B model, optimized to significantly reduce computational cost at scale. Leveraging linear attention, it achieves substantial inference speedups (>1000x) while retaining competitive accuracy on common benchmarks like ARC, HellaSwag, Lambada, and MMLU. It inherits knowledge and language support from Qwen 2.5, supporting approximately 30 languages, making it suitable for efficient inference in large-context applications. | openrouter |
| Text/Text | google/gemini-2.0-flash-001 | gemini_2_0_flash_001 |
Gemini Flash 2.0 offers a significantly faster time to first token (TTFT) compared to Gemini Flash 1.5, while maintaining quality on par with larger models like Gemini Pro 1.5. It introduces notable enhancements in multimodal understanding, coding capabilities, complex instruction following, and function calling. These advancements come together to deliver more seamless and robust agentic experiences. | openrouter |
| Text/Text | google/gemini-2.0-flash-exp:free | gemini_2_0_flash_exp__free |
Gemini Flash 2.0 offers a significantly faster time to first token (TTFT) compared to Gemini Flash 1.5, while maintaining quality on par with larger models like Gemini Pro 1.5. It introduces notable enhancements in multimodal understanding, coding capabilities, complex instruction following, and function calling. These advancements come together to deliver more seamless and robust agentic experiences. | openrouter |
| Text/Text | google/gemini-2.0-flash-lite-001 | gemini_2_0_flash_lite_001 |
Gemini 2.0 Flash Lite offers a significantly faster time to first token (TTFT) compared to Gemini Flash 1.5, while maintaining quality on par with larger models like Gemini Pro 1.5, all at extremely economical token prices. | openrouter |
| Text/Text | google/gemini-2.5-flash-preview | gemini_2_5_flash_preview |
Gemini 2.5 Flash is Google's state-of-the-art workhorse model, specifically designed for advanced reasoning, coding, mathematics, and scientific tasks. It includes built-in 'thinking' capabilities, enabling it to provide responses with greater accuracy and nuanced context handling. Note: This model is available in two variants: thinking and non-thinking. The output pricing varies significantly depending on whether the thinking capability is active. If you select the standard variant (without the ':thinking' suffix), the model will explicitly avoid generating thinking tokens. To utilize the thinking capability and receive thinking tokens, you must choose the ':thinking' variant, which will then incur the higher thinking-output pricing. Additionally, Gemini 2.5 Flash is configurable through the 'max tokens for reasoning' parameter, as described in the documentation (https://openrouter.ai/docs/use-cases/reasoning-tokens#max-tokens-for-reasoning). | openrouter |
| Text/Text | google/gemini-2.5-flash-preview:thinking | gemini_2_5_flash_preview__thinking |
Gemini 2.5 Flash is Google's state-of-the-art workhorse model, specifically designed for advanced reasoning, coding, mathematics, and scientific tasks. It includes built-in 'thinking' capabilities, enabling it to provide responses with greater accuracy and nuanced context handling. Note: This model is available in two variants: thinking and non-thinking. The output pricing varies significantly depending on whether the thinking capability is active. If you select the standard variant (without the ':thinking' suffix), the model will explicitly avoid generating thinking tokens. To utilize the thinking capability and receive thinking tokens, you must choose the ':thinking' variant, which will then incur the higher thinking-output pricing. Additionally, Gemini 2.5 Flash is configurable through the 'max tokens for reasoning' parameter, as described in the documentation (https://openrouter.ai/docs/use-cases/reasoning-tokens#max-tokens-for-reasoning). | openrouter |
| Text/Text | google/gemini-2.5-pro-exp-03-25 | gemini_2_5_pro_exp_03_25 |
Gemini 2.5 Pro is Google's state-of-the-art AI model designed for advanced reasoning, coding, mathematics, and scientific tasks. It employs 'thinking' capabilities, enabling it to reason through responses with enhanced accuracy and nuanced context handling. Gemini 2.5 Pro achieves top-tier performance on multiple benchmarks, including first-place positioning on the LMArena leaderboard, reflecting superior human-preference alignment and complex problem-solving abilities. | openrouter |
| Text/Text | google/gemini-2.5-pro-preview | gemini_2_5_pro_preview |
Gemini 2.5 Pro is Google's state-of-the-art AI model designed for advanced reasoning, coding, mathematics, and scientific tasks. It employs 'thinking' capabilities, enabling it to reason through responses with enhanced accuracy and nuanced context handling. Gemini 2.5 Pro achieves top-tier performance on multiple benchmarks, including first-place positioning on the LMArena leaderboard, reflecting superior human-preference alignment and complex problem-solving abilities. | openrouter |
| Text/Text | google/gemini-flash-1.5 | gemini_flash_1_5 |
Gemini 1.5 Flash is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video. It's adept at processing visual and text inputs such as photographs, documents, infographics, and screenshots. Gemini 1.5 Flash is designed for high-volume, high-frequency tasks where cost and latency matter. On most common tasks, Flash achieves comparable quality to other Gemini Pro models at a significantly reduced cost. Flash is well-suited for applications like chat assistants and on-demand content generation where speed and scale matter. Usage of Gemini is subject to Google's Gemini Terms of Use.#multimodal | openrouter |
| Text/Text | google/gemini-flash-1.5-8b | gemini_flash_1_5_8b |
Gemini Flash 1.5 8B is optimized for speed and efficiency, offering enhanced performance in small prompt tasks like chat, transcription, and translation. With reduced latency, it is highly effective for real-time and large-scale operations. This model focuses on cost-effective solutions while maintaining high-quality results.Click here to learn more about this model. Usage of Gemini is subject to Google's Gemini Terms of Use. | openrouter |
| Text/Text | google/gemini-pro-1.5 | gemini_pro_1_5 |
Google's latest multimodal model, supports image and video[0] in text or chat prompts. Optimized for language tasks including:- Code generation- Text generation- Text editing- Problem solving- Recommendations- Information extraction- Data extraction or generation- AI agents Usage of Gemini is subject to Google's Gemini Terms of Use.* [0]: Video input is not available through OpenRouter at this time. | openrouter |
| Text/Text | google/gemma-2-27b-it | gemma_2_27b_it |
Gemma 2 27B by Google is an open model built from the same research and technology used to create the Gemini models. Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. See the launch announcement for more details. Usage of Gemma is subject to Google's Gemma Terms of Use. | openrouter |
| Text/Text | google/gemma-2-9b-it | gemma_2_9b_it |
Gemma 2 9B by Google is an advanced, open-source language model that sets a new standard for efficiency and performance in its size class. Designed for a wide variety of tasks, it empowers developers and researchers to build innovative applications, while maintaining accessibility, safety, and cost-effectiveness. See the launch announcement for more details. Usage of Gemma is subject to Google's Gemma Terms of Use. | openrouter |
| Text/Text | google/gemma-2-9b-it:free | gemma_2_9b_it__free |
Gemma 2 9B by Google is an advanced, open-source language model that sets a new standard for efficiency and performance in its size class. Designed for a wide variety of tasks, it empowers developers and researchers to build innovative applications, while maintaining accessibility, safety, and cost-effectiveness. See the launch announcement for more details. Usage of Gemma is subject to Google's Gemma Terms of Use. | openrouter |
| Text/Text | google/gemma-3-12b-it | gemma_3_12b_it |
Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Gemma 3 12B is the second largest in the family of Gemma 3 models after Gemma 3 27B | openrouter |
| Text/Text | google/gemma-3-12b-it:free | gemma_3_12b_it__free |
Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Gemma 3 12B is the second largest in the family of Gemma 3 models after Gemma 3 27B | openrouter |
| Text/Text | google/gemma-3-1b-it:free | gemma_3_1b_it__free |
Gemma 3 1B is the smallest of the new Gemma 3 family. It handles context windows up to 32k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Note: Gemma 3 1B is not multimodal. For the smallest multimodal Gemma 3 model, please see Gemma 3 4B | openrouter |
| Text/Text | google/gemma-3-27b-it | gemma_3_27b_it |
Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Gemma 3 27B is Google's latest open source model, successor to Gemma 2 | openrouter |
| Text/Text | google/gemma-3-27b-it:free | gemma_3_27b_it__free |
Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Gemma 3 27B is Google's latest open source model, successor to Gemma 2 | openrouter |
| Text/Text | google/gemma-3-4b-it | gemma_3_4b_it |
Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. | openrouter |
| Text/Text | google/gemma-3-4b-it:free | gemma_3_4b_it__free |
Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. | openrouter |
| Text/Text | google/learnlm-1.5-pro-experimental:free | learnlm_1_5_pro_experimental__free |
An experimental version of Gemini 1.5 Pro from Google. | openrouter |
| Text/Text | gryphe/mythomax-l2-13b | mythomax_l2_13b |
One of the highest performing and most popular fine-tunes of Llama 2 13B, with rich descriptions and roleplay. #merge | openrouter |
| Text/Text | inception/mercury-coder-small-beta | mercury_coder_small_beta |
Mercury Coder Small is the first diffusion large language model (dLLM). Applying a breakthrough discrete diffusion approach, the model runs 5-10x faster than even speed optimized models like Claude 3.5 Haiku and GPT-4o Mini while matching their performance. Mercury Coder Small's speed means that developers can stay in the flow while coding, enjoying rapid chat-based iteration and responsive code completion suggestions. On Copilot Arena, Mercury Coder ranks 1st in speed and ties for 2nd in quality. Read more in the blog post here. | openrouter |
| Text/Text | infermatic/mn-inferor-12b | mn_inferor_12b |
Inferor 12B is a merge of top roleplay models, expert on immersive narratives and storytelling. This model was merged using the Model Stock merge method using anthracite-org/magnum-v4-12b as a base. | openrouter |
| Text/Text | inflection/inflection-3-pi | inflection_3_pi |
Inflection 3 Pi powers Inflection's Pi chatbot, including backstory, emotional intelligence, productivity, and safety. It has access to recent news, and excels in scenarios like customer support and roleplay. Pi has been trained to mirror your tone and style, if you use more emojis, so will Pi! Try experimenting with various prompts and conversation styles. | openrouter |
| Text/Text | inflection/inflection-3-productivity | inflection_3_productivity |
Inflection 3 Productivity is optimized for following instructions. It is better for tasks requiring JSON output or precise adherence to provided guidelines. It has access to recent news. For emotional intelligence similar to Pi, see Inflect 3 Pi See Inflection's announcement for more details. | openrouter |
| Text/Text | jondurbin/airoboros-l2-70b | airoboros_l2_70b |
A Llama 2 70B fine-tune using synthetic data (the Airoboros dataset). Currently based on jondurbin/airoboros-l2-70b, but might get updated in the future. | openrouter |
| Text/Text | liquid/lfm-3b | lfm_3b |
Liquid's LFM 3B delivers incredible performance for its size. It positions itself as first place among 3B parameter transformers, hybrids, and RNN models It is also on par with Phi-3.5-mini on multiple benchmarks, while being 18.4% smaller. LFM-3B is the ideal choice for mobile and other edge text-based applications. See the launch announcement for benchmarks and more info. | openrouter |
| Text/Text | liquid/lfm-40b | lfm_40b |
Liquid's 40.3B Mixture of Experts (MoE) model. Liquid Foundation Models (LFMs) are large neural networks built with computational units rooted in dynamic systems. LFMs are general-purpose AI models that can be used to model any kind of sequential data, including video, audio, text, time series, and signals. See the launch announcement for benchmarks and more info. | openrouter |
| Text/Text | liquid/lfm-7b | lfm_7b |
LFM-7B, a new best-in-class language model. LFM-7B is designed for exceptional chat capabilities, including languages like Arabic and Japanese. Powered by the Liquid Foundation Model (LFM) architecture, it exhibits unique features like low memory footprint and fast inference speed. LFM-7B is the world's best-in-class multilingual language model in English, Arabic, and Japanese. See the launch announcement for benchmarks and more info. | openrouter |
| Text/Text | mancer/weaver | weaver |
An attempt to recreate Claude-style verbosity, but don't expect the same level of coherence or memory. Meant for use in roleplay/narrative situations. | openrouter |
| Text/Text | meta-llama/llama-2-70b-chat | llama_2_70b_chat |
The flagship, 70 billion parameter language model from Meta, fine tuned for chat completions. Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety. | openrouter |
| Text/Text | meta-llama/llama-3-70b-instruct | llama_3_70b_instruct |
Meta's latest class of model (Llama 3) launched with a variety of sizes & flavors. This 70B instruct-tuned version was optimized for high quality dialogue usecases. It has demonstrated strong performance compared to leading closed-source models in human evaluations. To read more about the model release, click here. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3-8b-instruct | llama_3_8b_instruct |
Meta's latest class of model (Llama 3) launched with a variety of sizes & flavors. This 8B instruct-tuned version was optimized for high quality dialogue usecases. It has demonstrated strong performance compared to leading closed-source models in human evaluations. To read more about the model release, click here. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.1-405b | llama_3_1_405b |
Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This is the base 405B pre-trained version. It has demonstrated strong performance compared to leading closed-source models in human evaluations. To read more about the model release, click here. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.1-405b-instruct | llama_3_1_405b_instruct |
The highly anticipated 400B class of Llama3 is here! Clocking in at 128k context with impressive eval scores, the Meta AI team continues to push the frontier of open-source LLMs. Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 405B instruct-tuned version is optimized for high quality dialogue usecases. It has demonstrated strong performance compared to leading closed-source models including GPT-4o and Claude 3.5 Sonnet in evaluations. To read more about the model release, click here. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.1-405b:free | llama_3_1_405b__free |
Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This is the base 405B pre-trained version. It has demonstrated strong performance compared to leading closed-source models in human evaluations. To read more about the model release, click here. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.1-70b-instruct | llama_3_1_70b_instruct |
Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 70B instruct-tuned version is optimized for high quality dialogue usecases. It has demonstrated strong performance compared to leading closed-source models in human evaluations. To read more about the model release, click here. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.1-8b-instruct | llama_3_1_8b_instruct |
Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 8B instruct-tuned version is fast and efficient. It has demonstrated strong performance compared to leading closed-source models in human evaluations. To read more about the model release, click here. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.1-8b-instruct:free | llama_3_1_8b_instruct__free |
Meta's latest class of model (Llama 3.1) launched with a variety of sizes & flavors. This 8B instruct-tuned version is fast and efficient. It has demonstrated strong performance compared to leading closed-source models in human evaluations. To read more about the model release, click here. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.2-1b-instruct | llama_3_2_1b_instruct |
Llama 3.2 1B is a 1-billion-parameter language model focused on efficiently performing natural language tasks, such as summarization, dialogue, and multilingual text analysis. Its smaller size allows it to operate efficiently in low-resource environments while maintaining strong task performance. Supporting eight core languages and fine-tunable for more, Llama 1.3B is ideal for businesses or developers seeking lightweight yet powerful AI solutions that can operate in diverse multilingual settings without the high computational demand of larger models. Click here for the original model card. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.2-1b-instruct:free | llama_3_2_1b_instruct__free |
Llama 3.2 1B is a 1-billion-parameter language model focused on efficiently performing natural language tasks, such as summarization, dialogue, and multilingual text analysis. Its smaller size allows it to operate efficiently in low-resource environments while maintaining strong task performance. Supporting eight core languages and fine-tunable for more, Llama 1.3B is ideal for businesses or developers seeking lightweight yet powerful AI solutions that can operate in diverse multilingual settings without the high computational demand of larger models. Click here for the original model card. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.2-3b-instruct | llama_3_2_3b_instruct |
Llama 3.2 3B is a 3-billion-parameter multilingual large language model, optimized for advanced natural language processing tasks like dialogue generation, reasoning, and summarization. Designed with the latest transformer architecture, it supports eight languages, including English, Spanish, and Hindi, and is adaptable for additional languages. Trained on 9 trillion tokens, the Llama 3.2 3B model excels in instruction-following, complex reasoning, and tool use. Its balanced performance makes it ideal for applications needing accuracy and efficiency in text generation across multilingual settings. Click here for the original model card. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.2-3b-instruct:free | llama_3_2_3b_instruct__free |
Llama 3.2 3B is a 3-billion-parameter multilingual large language model, optimized for advanced natural language processing tasks like dialogue generation, reasoning, and summarization. Designed with the latest transformer architecture, it supports eight languages, including English, Spanish, and Hindi, and is adaptable for additional languages. Trained on 9 trillion tokens, the Llama 3.2 3B model excels in instruction-following, complex reasoning, and tool use. Its balanced performance makes it ideal for applications needing accuracy and efficiency in text generation across multilingual settings. Click here for the original model card. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | meta-llama/llama-3.3-70b-instruct | llama_3_3_70b_instruct |
The Meta Llama 3.3 multilingual large language model (LLM) is a pretrained and instruction tuned generative model in 70B (text in/text out). The Llama 3.3 instruction tuned text only model is optimized for multilingual dialogue use cases and outperforms many of the available open source and closed chat models on common industry benchmarks. Supported languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.Model Card | openrouter |
| Text/Text | meta-llama/llama-3.3-70b-instruct:free | llama_3_3_70b_instruct__free |
The Meta Llama 3.3 multilingual large language model (LLM) is a pretrained and instruction tuned generative model in 70B (text in/text out). The Llama 3.3 instruction tuned text only model is optimized for multilingual dialogue use cases and outperforms many of the available open source and closed chat models on common industry benchmarks. Supported languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.Model Card | openrouter |
| Text/Text | meta-llama/llama-4-maverick | llama_4_maverick |
Llama 4 Maverick 17B Instruct (128E) is a high-capacity multimodal language model from Meta, built on a mixture-of-experts (MoE) architecture with 128 experts and 17 billion active parameters per forward pass (400B total). It supports multilingual text and image input, and produces multilingual text and code output across 12 supported languages. Optimized for vision-language tasks, Maverick is instruction-tuned for assistant-like behavior, image reasoning, and general-purpose multimodal interaction. Maverick features early fusion for native multimodality and a 1 million token context window. It was trained on a curated mixture of public, licensed, and Meta-platform data, covering ~22 trillion tokens, with a knowledge cutoff in August 2024. Released on April 5, 2025 under the Llama 4 Community License, Maverick is suited for research and commercial applications requiring advanced multimodal understanding and high model throughput. | openrouter |
| Text/Text | meta-llama/llama-4-maverick:free | llama_4_maverick__free |
Llama 4 Maverick 17B Instruct (128E) is a high-capacity multimodal language model from Meta, built on a mixture-of-experts (MoE) architecture with 128 experts and 17 billion active parameters per forward pass (400B total). It supports multilingual text and image input, and produces multilingual text and code output across 12 supported languages. Optimized for vision-language tasks, Maverick is instruction-tuned for assistant-like behavior, image reasoning, and general-purpose multimodal interaction. Maverick features early fusion for native multimodality and a 1 million token context window. It was trained on a curated mixture of public, licensed, and Meta-platform data, covering ~22 trillion tokens, with a knowledge cutoff in August 2024. Released on April 5, 2025 under the Llama 4 Community License, Maverick is suited for research and commercial applications requiring advanced multimodal understanding and high model throughput. | openrouter |
| Text/Text | meta-llama/llama-4-scout | llama_4_scout |
Llama 4 Scout 17B Instruct (16E) is a mixture-of-experts (MoE) language model developed by Meta, activating 17 billion parameters out of a total of 109B. It supports native multimodal input (text and image) and multilingual output (text and code) across 12 supported languages. Designed for assistant-style interaction and visual reasoning, Scout uses 16 experts per forward pass and features a context length of 10 million tokens, with a training corpus of ~40 trillion tokens. Built for high efficiency and local or commercial deployment, Llama 4 Scout incorporates early fusion for seamless modality integration. It is instruction-tuned for use in multilingual chat, captioning, and image understanding tasks. Released under the Llama 4 Community License, it was last trained on data up to August 2024 and launched publicly on April 5, 2025. | openrouter |
| Text/Text | meta-llama/llama-4-scout:free | llama_4_scout__free |
Llama 4 Scout 17B Instruct (16E) is a mixture-of-experts (MoE) language model developed by Meta, activating 17 billion parameters out of a total of 109B. It supports native multimodal input (text and image) and multilingual output (text and code) across 12 supported languages. Designed for assistant-style interaction and visual reasoning, Scout uses 16 experts per forward pass and features a context length of 10 million tokens, with a training corpus of ~40 trillion tokens. Built for high efficiency and local or commercial deployment, Llama 4 Scout incorporates early fusion for seamless modality integration. It is instruction-tuned for use in multilingual chat, captioning, and image understanding tasks. Released under the Llama 4 Community License, it was last trained on data up to August 2024 and launched publicly on April 5, 2025. | openrouter |
| Text/Text | meta-llama/llama-guard-2-8b | llama_guard_2_8b |
This safeguard model has 8B parameters and is based on the Llama 3 family. Just like is predecessor, LlamaGuard 1, it can do both prompt and response classification. LlamaGuard 2 acts as a normal LLM would, generating text that indicates whether the given input/output is safe/unsafe. If deemed unsafe, it will also share the content categories violated. For best results, please use raw prompt input or the /completions endpoint, instead of the chat API. It has demonstrated strong performance compared to leading closed-source models in human evaluations. To read more about the model release, click here. Usage of this model is subject to Meta's Acceptable Use Policy. |
openrouter |
| Text/Text | meta-llama/llama-guard-3-8b | llama_guard_3_8b |
Llama Guard 3 is a Llama-3.1-8B pretrained model, fine-tuned for content safety classification. Similar to previous versions, it can be used to classify content in both LLM inputs (prompt classification) and in LLM responses (response classification). It acts as an LLM – it generates text in its output that indicates whether a given prompt or response is safe or unsafe, and if unsafe, it also lists the content categories violated. Llama Guard 3 was aligned to safeguard against the MLCommons standardized hazards taxonomy and designed to support Llama 3.1 capabilities. Specifically, it provides content moderation in 8 languages, and was optimized to support safety and security for search and code interpreter tool calls. | openrouter |
| Text/Text | meta-llama/llama-guard-4-12b | llama_guard_4_12b |
Llama Guard 4 is a Llama 4 Scout-derived multimodal pretrained model, fine-tuned for content safety classification. Similar to previous versions, it can be used to classify content in both LLM inputs (prompt classification) and in LLM responses (response classification). It acts as an LLM—generating text in its output that indicates whether a given prompt or response is safe or unsafe, and if unsafe, it also lists the content categories violated. Llama Guard 4 was aligned to safeguard against the standardized MLCommons hazards taxonomy and designed to support multimodal Llama 4 capabilities. Specifically, it combines features from previous Llama Guard models, providing content moderation for English and multiple supported languages, along with enhanced capabilities to handle mixed text-and-image prompts, including multiple images. Additionally, Llama Guard 4 is integrated into the Llama Moderations API, extending robust safety classification to text and images. | openrouter |
| Text/Text | microsoft/mai-ds-r1:free | mai_ds_r1__free |
MAI-DS-R1 is a post-trained variant of DeepSeek-R1 developed by the Microsoft AI team to improve the model's responsiveness on previously blocked topics while enhancing its safety profile. Built on top of DeepSeek-R1's reasoning foundation, it integrates 110k examples from the Tulu-3 SFT dataset and 350k internally curated multilingual safety-alignment samples. The model retains strong reasoning, coding, and problem-solving capabilities, while unblocking a wide range of prompts previously restricted in R1. MAI-DS-R1 demonstrates improved performance on harm mitigation benchmarks and maintains competitive results across general reasoning tasks. It surpasses R1-1776 in satisfaction metrics for blocked queries and reduces leakage in harmful content categories. The model is based on a transformer MoE architecture and is suitable for general-purpose use cases, excluding high-stakes domains such as legal, medical, or autonomous systems. | openrouter |
| Text/Text | microsoft/phi-3-medium-128k-instruct | phi_3_medium_128k_instruct |
Phi-3 128K Medium is a powerful 14-billion parameter model designed for advanced language understanding, reasoning, and instruction following. Optimized through supervised fine-tuning and preference adjustments, it excels in tasks involving common sense, mathematics, logical reasoning, and code processing. At time of release, Phi-3 Medium demonstrated state-of-the-art performance among lightweight models. In the MMLU-Pro eval, the model even comes close to a Llama3 70B level of performance. For 4k context length, try Phi-3 Medium 4K. | openrouter |
| Text/Text | microsoft/phi-3-mini-128k-instruct | phi_3_mini_128k_instruct |
Phi-3 Mini is a powerful 3.8B parameter model designed for advanced language understanding, reasoning, and instruction following. Optimized through supervised fine-tuning and preference adjustments, it excels in tasks involving common sense, mathematics, logical reasoning, and code processing. At time of release, Phi-3 Medium demonstrated state-of-the-art performance among lightweight models. This model is static, trained on an offline dataset with an October 2023 cutoff date. | openrouter |
| Text/Text | microsoft/phi-3.5-mini-128k-instruct | phi_3_5_mini_128k_instruct |
Phi-3.5 models are lightweight, state-of-the-art open models. These models were trained with Phi-3 datasets that include both synthetic data and the filtered, publicly available websites data, with a focus on high quality and reasoning-dense properties. Phi-3.5 Mini uses 3.8B parameters, and is a dense decoder-only transformer model using the same tokenizer as Phi-3 Mini. The models underwent a rigorous enhancement process, incorporating both supervised fine-tuning, proximal policy optimization, and direct preference optimization to ensure precise instruction adherence and robust safety measures. When assessed against benchmarks that test common sense, language understanding, math, code, long context and logical reasoning, Phi-3.5 models showcased robust and state-of-the-art performance among models with less than 13 billion parameters. | openrouter |
| Text/Text | microsoft/phi-4 | phi_4 |
Microsoft Research Phi-4 is designed to perform well in complex reasoning tasks and can operate efficiently in situations with limited memory or where quick responses are needed. At 14 billion parameters, it was trained on a mix of high-quality synthetic datasets, data from curated websites, and academic materials. It has undergone careful improvement to follow instructions accurately and maintain strong safety standards. It works best with English language inputs. For more information, please see Phi-4 Technical Report | openrouter |
| Text/Text | microsoft/phi-4-multimodal-instruct | phi_4_multimodal_instruct |
Phi-4 Multimodal Instruct is a versatile 5.6B parameter foundation model that combines advanced reasoning and instruction-following capabilities across both text and visual inputs, providing accurate text outputs. The unified architecture enables efficient, low-latency inference, suitable for edge and mobile deployments. Phi-4 Multimodal Instruct supports text inputs in multiple languages including Arabic, Chinese, English, French, German, Japanese, Spanish, and more, with visual input optimized primarily for English. It delivers impressive performance on multimodal tasks involving mathematical, scientific, and document reasoning, providing developers and enterprises a powerful yet compact model for sophisticated interactive applications. For more information, see the Phi-4 Multimodal blog post. | openrouter |
| Text/Text | microsoft/phi-4-reasoning-plus | phi_4_reasoning_plus |
Phi-4-reasoning-plus is an enhanced 14B parameter model from Microsoft, fine-tuned from Phi-4 with additional reinforcement learning to boost accuracy on math, science, and code reasoning tasks. It uses the same dense decoder-only transformer architecture as Phi-4, but generates longer, more comprehensive outputs structured into a step-by-step reasoning trace and final answer. While it offers improved benchmark scores over Phi-4-reasoning across tasks like AIME, OmniMath, and HumanEvalPlus, its responses are typically ~50% longer, resulting in higher latency. Designed for English-only applications, it is well-suited for structured reasoning workflows where output quality takes priority over response speed. | openrouter |
| Text/Text | microsoft/phi-4-reasoning-plus:free | phi_4_reasoning_plus__free |
Phi-4-reasoning-plus is an enhanced 14B parameter model from Microsoft, fine-tuned from Phi-4 with additional reinforcement learning to boost accuracy on math, science, and code reasoning tasks. It uses the same dense decoder-only transformer architecture as Phi-4, but generates longer, more comprehensive outputs structured into a step-by-step reasoning trace and final answer. While it offers improved benchmark scores over Phi-4-reasoning across tasks like AIME, OmniMath, and HumanEvalPlus, its responses are typically ~50% longer, resulting in higher latency. Designed for English-only applications, it is well-suited for structured reasoning workflows where output quality takes priority over response speed. | openrouter |
| Text/Text | microsoft/phi-4-reasoning:free | phi_4_reasoning__free |
Phi-4-reasoning is a 14B parameter dense decoder-only transformer developed by Microsoft, fine-tuned from Phi-4 to enhance complex reasoning capabilities. It uses a combination of supervised fine-tuning on chain-of-thought traces and reinforcement learning, targeting math, science, and code reasoning tasks. With a 32k context window and high inference efficiency, it is optimized for structured responses in a two-part format: reasoning trace followed by a final solution. The model achieves strong results on specialized benchmarks such as AIME, OmniMath, and LiveCodeBench, outperforming many larger models in structured reasoning tasks. It is released under the MIT license and intended for use in latency-constrained, English-only environments requiring reliable step-by-step logic. Recommended usage includes ChatML prompts and structured reasoning format for best results. | openrouter |
| Text/Text | microsoft/wizardlm-2-8x22b | wizardlm_2_8x22b |
WizardLM-2 8x22B is Microsoft AI's most advanced Wizard model. It demonstrates highly competitive performance compared to leading proprietary models, and it consistently outperforms all existing state-of-the-art opensource models. It is an instruct finetune of Mixtral 8x22B. To read more about the model release, click here.#moe | openrouter |
| Text/Text | mistral/ministral-8b | ministral_8b |
Ministral 8B is a state-of-the-art language model optimized for on-device and edge computing. Designed for efficiency in knowledge-intensive tasks, commonsense reasoning, and function-calling, it features a specialized interleaved sliding-window attention mechanism, enabling faster and more memory-efficient inference. Ministral 8B excels in local, low-latency applications such as offline translation, smart assistants, autonomous robotics, and local analytics. The model supports up to 128k context length and can function as a performant intermediary in multi-step agentic workflows, efficiently handling tasks like input parsing, API calls, and task routing. It consistently outperforms comparable models like Mistral 7B across benchmarks, making it particularly suitable for compute-efficient, privacy-focused scenarios. | openrouter |
| Text/Text | mistralai/codestral-2501 | codestral_2501 |
Mistral's cutting-edge language model for coding. Codestral specializes in low-latency, high-frequency tasks such as fill-in-the-middle (FIM), code correction and test generation. Learn more on their blog post: https://mistral.ai/news/codestral-2501/ | openrouter |
| Text/Text | mistralai/codestral-mamba | codestral_mamba |
A 7.3B parameter Mamba-based model designed for code and reasoning tasks.- Linear time inference, allowing for theoretically infinite sequence lengths- 256k token context window- Optimized for quick responses, especially beneficial for code productivity- Performs comparably to state-of-the-art transformer models in code and reasoning tasks- Available under the Apache 2.0 license for free use, modification, and distribution | openrouter |
| Text/Text | mistralai/ministral-3b | ministral_3b |
Ministral 3B is a 3B parameter model optimized for on-device and edge computing. It excels in knowledge, commonsense reasoning, and function-calling, outperforming larger models like Mistral 7B on most benchmarks. Supporting up to 128k context length, it's ideal for orchestrating agentic workflows and specialist tasks with efficient inference. | openrouter |
| Text/Text | mistralai/ministral-8b | ministral_8b |
Ministral 8B is an 8B parameter model featuring a unique interleaved sliding-window attention pattern for faster, memory-efficient inference. Designed for edge use cases, it supports up to 128k context length and excels in knowledge and reasoning tasks. It outperforms peers in the sub-10B category, making it perfect for low-latency, privacy-first applications. | openrouter |
| Text/Text | mistralai/mistral-7b-instruct | mistral_7b_instruct |
A high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length.Mistral 7B Instruct has multiple version variants, and this is intended to be the latest version. | openrouter |
| Text/Text | mistralai/mistral-7b-instruct-v0.1 | mistral_7b_instruct_v0_1 |
A 7.3B parameter model that outperforms Llama 2 13B on all benchmarks, with optimizations for speed and context length. | openrouter |
| Text/Text | mistralai/mistral-7b-instruct-v0.2 | mistral_7b_instruct_v0_2 |
A high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length. An improved version of Mistral 7B Instruct, with the following changes:- 32k context window (vs 8k context in v0.1)- Rope-theta = 1e6- No Sliding-Window Attention | openrouter |
| Text/Text | mistralai/mistral-7b-instruct-v0.3 | mistral_7b_instruct_v0_3 |
A high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length. An improved version of Mistral 7B Instruct v0.2, with the following changes:- Extended vocabulary to 32768- Supports v3 Tokenizer- Supports function calling NOTE: Support for function calling depends on the provider. | openrouter |
| Text/Text | mistralai/mistral-7b-instruct:free | mistral_7b_instruct__free |
A high-performing, industry-standard 7.3B parameter model, with optimizations for speed and context length.Mistral 7B Instruct has multiple version variants, and this is intended to be the latest version. | openrouter |
| Text/Text | mistralai/mistral-large | mistral_large |
This is Mistral AI's flagship model, Mistral Large 2 (version mistral-large-2407). It's a proprietary weights-available model and excels at reasoning, code, JSON, chat, and more. Read the launch announcement here. It supports dozens of languages including French, German, Spanish, Italian, Portuguese, Arabic, Hindi, Russian, Chinese, Japanese, and Korean, along with 80+ coding languages including Python, Java, C, C++, JavaScript, and Bash. Its long context window allows precise information recall from large documents. |
openrouter |
| Text/Text | mistralai/mistral-large-2407 | mistral_large_2407 |
This is Mistral AI's flagship model, Mistral Large 2 (version mistral-large-2407). It's a proprietary weights-available model and excels at reasoning, code, JSON, chat, and more. Read the launch announcement here. It supports dozens of languages including French, German, Spanish, Italian, Portuguese, Arabic, Hindi, Russian, Chinese, Japanese, and Korean, along with 80+ coding languages including Python, Java, C, C++, JavaScript, and Bash. Its long context window allows precise information recall from large documents. | openrouter |
| Text/Text | mistralai/mistral-large-2411 | mistral_large_2411 |
Mistral Large 2 2411 is an update of Mistral Large 2 released together with Pixtral Large 2411 It provides a significant upgrade on the previous Mistral Large 24.07, with notable improvements in long context understanding, a new system prompt, and more accurate function calling. | openrouter |
| Text/Text | mistralai/mistral-medium | mistral_medium |
This is Mistral AI's closed-source, medium-sided model. It's powered by a closed-source prototype and excels at reasoning, code, JSON, chat, and more. In benchmarks, it compares with many of the flagship models of other companies. | openrouter |
| Text/Text | mistralai/mistral-medium-3 | mistral_medium_3 |
Mistral Medium 3 is a high-performance enterprise-grade language model designed to deliver frontier-level capabilities at significantly reduced operational cost. It balances state-of-the-art reasoning and multimodal performance with 8× lower cost compared to traditional large models, making it suitable for scalable deployments across professional and industrial use cases. The model excels in domains such as coding, STEM reasoning, and enterprise adaptation. It supports hybrid, on-prem, and in-VPC deployments and is optimized for integration into custom workflows. Mistral Medium 3 offers competitive accuracy relative to larger models like Claude Sonnet 3.5/3.7, Llama 4 Maverick, and Command R+, while maintaining broad compatibility across cloud environments. | openrouter |
| Text/Text | mistralai/mistral-nemo | mistral_nemo |
A 12B parameter model with a 128k token context length built by Mistral in collaboration with NVIDIA. The model is multilingual, supporting English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi. It supports function calling and is released under the Apache 2.0 license. | openrouter |
| Text/Text | mistralai/mistral-nemo:free | mistral_nemo__free |
A 12B parameter model with a 128k token context length built by Mistral in collaboration with NVIDIA. The model is multilingual, supporting English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi. It supports function calling and is released under the Apache 2.0 license. | openrouter |
| Text/Text | mistralai/mistral-saba | mistral_saba |
Mistral Saba is a 24B-parameter language model specifically designed for the Middle East and South Asia, delivering accurate and contextually relevant responses while maintaining efficient performance. Trained on curated regional datasets, it supports multiple Indian-origin languages—including Tamil and Malayalam—alongside Arabic. This makes it a versatile option for a range of regional and multilingual applications. Read more at the blog post here | openrouter |
| Text/Text | mistralai/mistral-small | mistral_small |
With 22 billion parameters, Mistral Small v24.09 offers a convenient mid-point between (Mistral NeMo 12B)[/mistralai/mistral-nemo] and (Mistral Large 2)[/mistralai/mistral-large], providing a cost-effective solution that can be deployed across various platforms and environments. It has better reasoning, exhibits more capabilities, can produce and reason about code, and is multiligual, supporting English, French, German, Italian, and Spanish. | openrouter |
| Text/Text | mistralai/mistral-small-24b-instruct-2501 | mistral_small_24b_instruct_2501 |
Mistral Small 3 is a 24B-parameter language model optimized for low-latency performance across common AI tasks. Released under the Apache 2.0 license, it features both pre-trained and instruction-tuned versions designed for efficient local deployment. The model achieves 81% accuracy on the MMLU benchmark and performs competitively with larger models like Llama 3.3 70B and Qwen 32B, while operating at three times the speed on equivalent hardware. Read the blog post about the model here. | openrouter |
| Text/Text | mistralai/mistral-small-24b-instruct-2501:free | mistral_small_24b_instruct_2501__free |
Mistral Small 3 is a 24B-parameter language model optimized for low-latency performance across common AI tasks. Released under the Apache 2.0 license, it features both pre-trained and instruction-tuned versions designed for efficient local deployment. The model achieves 81% accuracy on the MMLU benchmark and performs competitively with larger models like Llama 3.3 70B and Qwen 32B, while operating at three times the speed on equivalent hardware. Read the blog post about the model here. | openrouter |
| Text/Text | mistralai/mistral-small-3.1-24b-instruct | mistral_small_3_1_24b_instruct |
Mistral Small 3.1 24B Instruct is an upgraded variant of Mistral Small 3 (2501), featuring 24 billion parameters with advanced multimodal capabilities. It provides state-of-the-art performance in text-based reasoning and vision tasks, including image analysis, programming, mathematical reasoning, and multilingual support across dozens of languages. Equipped with an extensive 128k token context window and optimized for efficient local inference, it supports use cases such as conversational agents, function calling, long-document comprehension, and privacy-sensitive deployments. | openrouter |
| Text/Text | mistralai/mistral-small-3.1-24b-instruct:free | mistral_small_3_1_24b_instruct__free |
Mistral Small 3.1 24B Instruct is an upgraded variant of Mistral Small 3 (2501), featuring 24 billion parameters with advanced multimodal capabilities. It provides state-of-the-art performance in text-based reasoning and vision tasks, including image analysis, programming, mathematical reasoning, and multilingual support across dozens of languages. Equipped with an extensive 128k token context window and optimized for efficient local inference, it supports use cases such as conversational agents, function calling, long-document comprehension, and privacy-sensitive deployments. | openrouter |
| Text/Text | mistralai/mistral-tiny | mistral_tiny |
Note: This model is being deprecated. Recommended replacement is the newer Ministral 8B This model is currently powered by Mistral-7B-v0.2, and incorporates a 'better' fine-tuning than Mistral 7B, inspired by community work. It's best used for large batch processing tasks where cost is a significant factor but reasoning capabilities are not crucial. | openrouter |
| Text/Text | mistralai/mixtral-8x22b-instruct | mixtral_8x22b_instruct |
Mistral's official instruct fine-tuned version of Mixtral 8x22B. It uses 39B active parameters out of 141B, offering unparalleled cost efficiency for its size. Its strengths include:- strong math, coding, and reasoning- large context length (64k)- fluency in English, French, Italian, German, and Spanish See benchmarks on the launch announcement here.#moe | openrouter |
| Text/Text | mistralai/mixtral-8x7b-instruct | mixtral_8x7b_instruct |
Mixtral 8x7B Instruct is a pretrained generative Sparse Mixture of Experts, by Mistral AI, for chat and instruction use. Incorporates 8 experts (feed-forward networks) for a total of 47 billion parameters. Instruct model fine-tuned by Mistral. #moe | openrouter |
| Text/Text | moonshotai/moonlight-16b-a3b-instruct:free | moonlight_16b_a3b_instruct__free |
Moonlight-16B-A3B-Instruct is a 16B-parameter Mixture-of-Experts (MoE) language model developed by Moonshot AI. It is optimized for instruction-following tasks with 3B activated parameters per inference. The model advances the Pareto frontier in performance per FLOP across English, coding, math, and Chinese benchmarks. It outperforms comparable models like Llama3-3B and Deepseek-v2-Lite while maintaining efficient deployment capabilities through Hugging Face integration and compatibility with popular inference engines like vLLM12. | openrouter |
| Text/Text | neversleep/llama-3-lumimaid-70b | llama_3_lumimaid_70b |
The NeverSleep team is back, with a Llama 3 70B finetune trained on their curated roleplay data. Striking a balance between eRP and RP, Lumimaid was designed to be serious, yet uncensored when necessary. To enhance it's overall intelligence and chat capability, roughly 40% of the training data was not roleplay. This provides a breadth of knowledge to access, while still keeping roleplay as the primary strength. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | neversleep/llama-3-lumimaid-8b | llama_3_lumimaid_8b |
The NeverSleep team is back, with a Llama 3 8B finetune trained on their curated roleplay data. Striking a balance between eRP and RP, Lumimaid was designed to be serious, yet uncensored when necessary. To enhance it's overall intelligence and chat capability, roughly 40% of the training data was not roleplay. This provides a breadth of knowledge to access, while still keeping roleplay as the primary strength. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | neversleep/llama-3-lumimaid-8b:extended | llama_3_lumimaid_8b__extended |
The NeverSleep team is back, with a Llama 3 8B finetune trained on their curated roleplay data. Striking a balance between eRP and RP, Lumimaid was designed to be serious, yet uncensored when necessary. To enhance it's overall intelligence and chat capability, roughly 40% of the training data was not roleplay. This provides a breadth of knowledge to access, while still keeping roleplay as the primary strength. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | neversleep/llama-3.1-lumimaid-70b | llama_3_1_lumimaid_70b |
Lumimaid v0.2 70B is a finetune of Llama 3.1 70B with a 'HUGE step up dataset wise' compared to Lumimaid v0.1. Sloppy chats output were purged. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | neversleep/llama-3.1-lumimaid-8b | llama_3_1_lumimaid_8b |
Lumimaid v0.2 8B is a finetune of Llama 3.1 8B with a 'HUGE step up dataset wise' compared to Lumimaid v0.1. Sloppy chats output were purged. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | neversleep/noromaid-20b | noromaid_20b |
A collab between IkariDev and Undi. This merge is suitable for RP, ERP, and general knowledge.#merge #uncensored | openrouter |
| Text/Text | nothingiisreal/mn-celeste-12b | mn_celeste_12b |
A specialized story writing and roleplaying model based on Mistral's NeMo 12B Instruct. Fine-tuned on curated datasets including Reddit Writing Prompts and Opus Instruct 25K. This model excels at creative writing, offering improved NSFW capabilities, with smarter and more active narration. It demonstrates remarkable versatility in both SFW and NSFW scenarios, with strong Out of Character (OOC) steering capabilities, allowing fine-tuned control over narrative direction and character behavior. Check out the model's HuggingFace page for details on what parameters and prompts work best! | openrouter |
| Text/Text | nousresearch/deephermes-3-llama-3-8b-preview:free | deephermes_3_llama_3_8b_preview__free |
DeepHermes 3 Preview is the latest version of our flagship Hermes series of LLMs by Nous Research, and one of the first models in the world to unify Reasoning (long chains of thought that improve answer accuracy) and normal LLM response modes into one model. We have also improved LLM annotation, judgement, and function calling. DeepHermes 3 Preview is one of the first LLM models to unify both 'intuitive', traditional mode responses and long chain of thought reasoning responses into a single model, toggled by a system prompt. | openrouter |
| Text/Text | nousresearch/deephermes-3-mistral-24b-preview:free | deephermes_3_mistral_24b_preview__free |
DeepHermes 3 (Mistral 24B Preview) is an instruction-tuned language model by Nous Research based on Mistral-Small-24B, designed for chat, function calling, and advanced multi-turn reasoning. It introduces a dual-mode system that toggles between intuitive chat responses and structured 'deep reasoning' mode using special system prompts. Fine-tuned via distillation from R1, it supports structured output (JSON mode) and function call syntax for agent-based applications. DeepHermes 3 supports a reasoning toggle via system prompt, allowing users to switch between fast, intuitive responses and deliberate, multi-step reasoning. When activated with the following specific system instruction, the model enters a 'deep thinking' mode—generating extended chains of thought wrapped in <think></think> tags before delivering a final answer. System Prompt: You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside tags, and then provide your solution or response to the problem. |
openrouter |
| Text/Text | nousresearch/hermes-2-pro-llama-3-8b | hermes_2_pro_llama_3_8b |
Hermes 2 Pro is an upgraded, retrained version of Nous Hermes 2, consisting of an updated and cleaned version of the OpenHermes 2.5 Dataset, as well as a newly introduced Function Calling and JSON Mode dataset developed in-house. | openrouter |
| Text/Text | nousresearch/hermes-3-llama-3.1-405b | hermes_3_llama_3_1_405b |
Hermes 3 is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coherence, and improvements across the board. Hermes 3 405B is a frontier-level, full-parameter finetune of the Llama-3.1 405B foundation model, focused on aligning LLMs to the user, with powerful steering capabilities and control given to the end user. The Hermes 3 series builds and expands on the Hermes 2 set of capabilities, including more powerful and reliable function calling and structured output capabilities, generalist assistant capabilities, and improved code generation skills. Hermes 3 is competitive, if not superior, to Llama-3.1 Instruct models at general capabilities, with varying strengths and weaknesses attributable between the two. | openrouter |
| Text/Text | nousresearch/hermes-3-llama-3.1-70b | hermes_3_llama_3_1_70b |
Hermes 3 is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coherence, and improvements across the board. Hermes 3 70B is a competitive, if not superior finetune of the Llama-3.1 70B foundation model, focused on aligning LLMs to the user, with powerful steering capabilities and control given to the end user. The Hermes 3 series builds and expands on the Hermes 2 set of capabilities, including more powerful and reliable function calling and structured output capabilities, generalist assistant capabilities, and improved code generation skills. | openrouter |
| Text/Text | nousresearch/nous-hermes-2-mixtral-8x7b-dpo | nous_hermes_2_mixtral_8x7b_dpo |
Nous Hermes 2 Mixtral 8x7B DPO is the new flagship Nous Research model trained over the Mixtral 8x7B MoE LLM. The model was trained on over 1,000,000 entries of primarily GPT-4 generated data, as well as other high quality data from open datasets across the AI landscape, achieving state of the art performance on a variety of tasks.#moe | openrouter |
| Text/Text | nvidia/llama-3.1-nemotron-70b-instruct | llama_3_1_nemotron_70b_instruct |
NVIDIA's Llama 3.1 Nemotron 70B is a language model designed for generating precise and useful responses. Leveraging Llama 3.1 70B architecture and Reinforcement Learning from Human Feedback (RLHF), it excels in automatic alignment benchmarks. This model is tailored for applications requiring high accuracy in helpfulness and response generation, suitable for diverse user queries across multiple domains. Usage of this model is subject to Meta's Acceptable Use Policy. | openrouter |
| Text/Text | nvidia/llama-3.1-nemotron-ultra-253b-v1:free | llama_3_1_nemotron_ultra_253b_v1__free |
Llama-3.1-Nemotron-Ultra-253B-v1 is a large language model (LLM) optimized for advanced reasoning, human-interactive chat, retrieval-augmented generation (RAG), and tool-calling tasks. Derived from Meta's Llama-3.1-405B-Instruct, it has been significantly customized using Neural Architecture Search (NAS), resulting in enhanced efficiency, reduced memory usage, and improved inference latency. The model supports a context length of up to 128K tokens and can operate efficiently on an 8x NVIDIA H100 node. Note: you must include detailed thinking on in the system prompt to enable reasoning. Please see Usage Recommendations for more. |
openrouter |
| Text/Text | nvidia/llama-3.3-nemotron-super-49b-v1 | llama_3_3_nemotron_super_49b_v1 |
Llama-3.3-Nemotron-Super-49B-v1 is a large language model (LLM) optimized for advanced reasoning, conversational interactions, retrieval-augmented generation (RAG), and tool-calling tasks. Derived from Meta's Llama-3.3-70B-Instruct, it employs a Neural Architecture Search (NAS) approach, significantly enhancing efficiency and reducing memory requirements. This allows the model to support a context length of up to 128K tokens and fit efficiently on single high-performance GPUs, such as NVIDIA H200. Note: you must include detailed thinking on in the system prompt to enable reasoning. Please see Usage Recommendations for more. |
openrouter |
| Text/Text | nvidia/llama-3.3-nemotron-super-49b-v1:free | llama_3_3_nemotron_super_49b_v1__free |
Llama-3.3-Nemotron-Super-49B-v1 is a large language model (LLM) optimized for advanced reasoning, conversational interactions, retrieval-augmented generation (RAG), and tool-calling tasks. Derived from Meta's Llama-3.3-70B-Instruct, it employs a Neural Architecture Search (NAS) approach, significantly enhancing efficiency and reducing memory requirements. This allows the model to support a context length of up to 128K tokens and fit efficiently on single high-performance GPUs, such as NVIDIA H200. Note: you must include detailed thinking on in the system prompt to enable reasoning. Please see Usage Recommendations for more. |
openrouter |
| Text/Text | open-r1/olympiccoder-32b:free | olympiccoder_32b__free |
OlympicCoder-32B is a high-performing open-source model fine-tuned using the CodeForces-CoTs dataset, containing approximately 100,000 chain-of-thought programming samples. It excels at complex competitive programming benchmarks, such as IOI 2024 and Codeforces-style challenges, frequently surpassing state-of-the-art closed-source models. OlympicCoder-32B provides advanced reasoning, coherent multi-step problem-solving, and robust code generation capabilities, demonstrating significant potential for olympiad-level competitive programming applications. | openrouter |
| Text/Text | openai/chatgpt-4o-latest | chatgpt_4o_latest |
OpenAI ChatGPT 4o is continually updated by OpenAI to point to the current version of GPT-4o used by ChatGPT. It therefore differs slightly from the API version of GPT-4o in that it has additional RLHF. It is intended for research and evaluation. OpenAI notes that this model is not suited for production use-cases as it may be removed or redirected to another model in the future. | openrouter |
| Text/Text | openai/gpt-3.5-turbo | gpt_3_5_turbo |
GPT-3.5 Turbo is OpenAI's fastest model. It can understand and generate natural language or code, and is optimized for chat and traditional completion tasks. Training data up to Sep 2021. | openrouter |
| Text/Text | openai/gpt-3.5-turbo-0125 | gpt_3_5_turbo_0125 |
The latest GPT-3.5 Turbo model with improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Training data: up to Sep 2021. This version has a higher accuracy at responding in requested formats and a fix for a bug which caused a text encoding issue for non-English language function calls. | openrouter |
| Text/Text | openai/gpt-3.5-turbo-0613 | gpt_3_5_turbo_0613 |
GPT-3.5 Turbo is OpenAI's fastest model. It can understand and generate natural language or code, and is optimized for chat and traditional completion tasks. Training data up to Sep 2021. | openrouter |
| Text/Text | openai/gpt-3.5-turbo-1106 | gpt_3_5_turbo_1106 |
An older GPT-3.5 Turbo model with improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Training data: up to Sep 2021. | openrouter |
| Text/Text | openai/gpt-3.5-turbo-16k | gpt_3_5_turbo_16k |
This model offers four times the context length of gpt-3.5-turbo, allowing it to support approximately 20 pages of text in a single request at a higher cost. Training data: up to Sep 2021. | openrouter |
| Text/Text | openai/gpt-3.5-turbo-instruct | gpt_3_5_turbo_instruct |
This model is a variant of GPT-3.5 Turbo tuned for instructional prompts and omitting chat-related optimizations. Training data: up to Sep 2021. | openrouter |
| Text/Text | openai/gpt-4 | gpt_4 |
OpenAI's flagship model, GPT-4 is a large-scale multimodal language model capable of solving difficult problems with greater accuracy than previous models due to its broader general knowledge and advanced reasoning capabilities. Training data: up to Sep 2021. | openrouter |
| Text/Text | openai/gpt-4-0314 | gpt_4_0314 |
GPT-4-0314 is the first version of GPT-4 released, with a context length of 8,192 tokens, and was supported until June 14. Training data: up to Sep 2021. | openrouter |
| Text/Text | openai/gpt-4-32k | gpt_4_32k |
GPT-4-32k is an extended version of GPT-4, with the same capabilities but quadrupled context length, allowing for processing up to 40 pages of text in a single pass. This is particularly beneficial for handling longer content like interacting with PDFs without an external vector database. Training data: up to Sep 2021. | openrouter |
| Text/Text | openai/gpt-4-32k-0314 | gpt_4_32k_0314 |
GPT-4-32k is an extended version of GPT-4, with the same capabilities but quadrupled context length, allowing for processing up to 40 pages of text in a single pass. This is particularly beneficial for handling longer content like interacting with PDFs without an external vector database. Training data: up to Sep 2021. | openrouter |
| Text/Text | openai/gpt-4-turbo | gpt_4_turbo |
The latest GPT-4 Turbo model with vision capabilities. Vision requests can now use JSON mode and function calling. Training data: up to December 2023. | openrouter |
| Text/Text | openai/gpt-4-turbo-preview | gpt_4_turbo_preview |
The preview GPT-4 model with improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Training data: up to Dec 2023.Note: heavily rate limited by OpenAI while in preview. | openrouter |
| Text/Text | openai/gpt-4.1 | gpt_4_1 |
GPT-4.1 is a flagship large language model optimized for advanced instruction following, real-world software engineering, and long-context reasoning. It supports a 1 million token context window and outperforms GPT-4o and GPT-4.5 across coding (54.6% SWE-bench Verified), instruction compliance (87.4% IFEval), and multimodal understanding benchmarks. It is tuned for precise code diffs, agent reliability, and high recall in large document contexts, making it ideal for agents, IDE tooling, and enterprise knowledge retrieval. | openrouter |
| Text/Text | openai/gpt-4.1-mini | gpt_4_1_mini |
GPT-4.1 Mini is a mid-sized model delivering performance competitive with GPT-4o at substantially lower latency and cost. It retains a 1 million token context window and scores 45.1% on hard instruction evals, 35.8% on MultiChallenge, and 84.1% on IFEval. Mini also shows strong coding ability (e.g., 31.6% on Aider's polyglot diff benchmark) and vision understanding, making it suitable for interactive applications with tight performance constraints. | openrouter |
| Text/Text | openai/gpt-4.1-nano | gpt_4_1_nano |
For tasks that demand low latency, GPT‑4.1 nano is the fastest and cheapest model in the GPT-4.1 series. It delivers exceptional performance at a small size with its 1 million token context window, and scores 80.1% on MMLU, 50.3% on GPQA, and 9.8% on Aider polyglot coding – even higher than GPT‑4o mini. It's ideal for tasks like classification or autocompletion. | openrouter |
| Text/Text | openai/gpt-4.5-preview | gpt_4_5_preview |
GPT-4.5 (Preview) is a research preview of OpenAI's latest language model, designed to advance capabilities in reasoning, creativity, and multi-turn conversation. It builds on previous iterations with improvements in world knowledge, contextual coherence, and the ability to follow user intent more effectively. The model demonstrates enhanced performance in tasks that require open-ended thinking, problem-solving, and communication. Early testing suggests it is better at generating nuanced responses, maintaining long-context coherence, and reducing hallucinations compared to earlier versions. This research preview is intended to help evaluate GPT-4.5's strengths and limitations in real-world use cases as OpenAI continues to refine and develop future models. Read more at the blog post here. | openrouter |
| Text/Text | openai/gpt-4o | gpt_4o |
GPT-4o ('o' for 'omni') is OpenAI's latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of GPT-4 Turbo while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities. For benchmarking against other models, it was briefly called 'im-also-a-good-gpt2-chatbot'#multimodal | openrouter |
| Text/Text | openai/gpt-4o-2024-05-13 | gpt_4o_2024_05_13 |
GPT-4o ('o' for 'omni') is OpenAI's latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of GPT-4 Turbo while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities. For benchmarking against other models, it was briefly called 'im-also-a-good-gpt2-chatbot'#multimodal | openrouter |
| Text/Text | openai/gpt-4o-2024-08-06 | gpt_4o_2024_08_06 |
The 2024-08-06 version of GPT-4o offers improved performance in structured outputs, with the ability to supply a JSON schema in the respone_format. Read more here. GPT-4o ('o' for 'omni') is OpenAI's latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of GPT-4 Turbo while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities. For benchmarking against other models, it was briefly called 'im-also-a-good-gpt2-chatbot' | openrouter |
| Text/Text | openai/gpt-4o-2024-11-20 | gpt_4o_2024_11_20 |
The 2024-11-20 version of GPT-4o offers a leveled-up creative writing ability with more natural, engaging, and tailored writing to improve relevance & readability. It's also better at working with uploaded files, providing deeper insights & more thorough responses. GPT-4o ('o' for 'omni') is OpenAI's latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of GPT-4 Turbo while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities. | openrouter |
| Text/Text | openai/gpt-4o-mini | gpt_4o_mini |
GPT-4o mini is OpenAI's newest model after GPT-4 Omni, supporting both text and image inputs with text outputs. As their most advanced small model, it is many multiples more affordable than other recent frontier models, and more than 60% cheaper than GPT-3.5 Turbo. It maintains SOTA intelligence, while being significantly more cost-effective. GPT-4o mini achieves an 82% score on MMLU and presently ranks higher than GPT-4 on chat preferences common leaderboards. Check out the launch announcement to learn more.#multimodal | openrouter |
| Text/Text | openai/gpt-4o-mini-2024-07-18 | gpt_4o_mini_2024_07_18 |
GPT-4o mini is OpenAI's newest model after GPT-4 Omni, supporting both text and image inputs with text outputs. As their most advanced small model, it is many multiples more affordable than other recent frontier models, and more than 60% cheaper than GPT-3.5 Turbo. It maintains SOTA intelligence, while being significantly more cost-effective. GPT-4o mini achieves an 82% score on MMLU and presently ranks higher than GPT-4 on chat preferences common leaderboards. Check out the launch announcement to learn more.#multimodal | openrouter |
| Text/Text | openai/gpt-4o-mini-search-preview | gpt_4o_mini_search_preview |
GPT-4o mini Search Preview is a specialized model for web search in Chat Completions. It is trained to understand and execute web search queries. | openrouter |
| Text/Text | openai/gpt-4o-search-preview | gpt_4o_search_preview |
GPT-4o Search Previewis a specialized model for web search in Chat Completions. It is trained to understand and execute web search queries. | openrouter |
| Text/Text | openai/gpt-4o:extended | gpt_4o__extended |
GPT-4o ('o' for 'omni') is OpenAI's latest AI model, supporting both text and image inputs with text outputs. It maintains the intelligence level of GPT-4 Turbo while being twice as fast and 50% more cost-effective. GPT-4o also offers improved performance in processing non-English languages and enhanced visual capabilities. For benchmarking against other models, it was briefly called 'im-also-a-good-gpt2-chatbot'#multimodal | openrouter |
| Text/Text | openai/o1 | o1 |
The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding. The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. The o1 models are optimized for math, science, programming, and other STEM-related tasks. They consistently exhibit PhD-level accuracy on benchmarks in physics, chemistry, and biology. Learn more in the launch announcement. | openrouter |
| Text/Text | openai/o1-mini | o1_mini |
The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding. The o1 models are optimized for math, science, programming, and other STEM-related tasks. They consistently exhibit PhD-level accuracy on benchmarks in physics, chemistry, and biology. Learn more in the launch announcement. Note: This model is currently experimental and not suitable for production use-cases, and may be heavily rate-limited. | openrouter |
| Text/Text | openai/o1-mini-2024-09-12 | o1_mini_2024_09_12 |
The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding. The o1 models are optimized for math, science, programming, and other STEM-related tasks. They consistently exhibit PhD-level accuracy on benchmarks in physics, chemistry, and biology. Learn more in the launch announcement. Note: This model is currently experimental and not suitable for production use-cases, and may be heavily rate-limited. | openrouter |
| Text/Text | openai/o1-preview | o1_preview |
The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding. The o1 models are optimized for math, science, programming, and other STEM-related tasks. They consistently exhibit PhD-level accuracy on benchmarks in physics, chemistry, and biology. Learn more in the launch announcement. Note: This model is currently experimental and not suitable for production use-cases, and may be heavily rate-limited. | openrouter |
| Text/Text | openai/o1-preview-2024-09-12 | o1_preview_2024_09_12 |
The latest and strongest model family from OpenAI, o1 is designed to spend more time thinking before responding. The o1 models are optimized for math, science, programming, and other STEM-related tasks. They consistently exhibit PhD-level accuracy on benchmarks in physics, chemistry, and biology. Learn more in the launch announcement. Note: This model is currently experimental and not suitable for production use-cases, and may be heavily rate-limited. | openrouter |
| Text/Text | openai/o1-pro | o1_pro |
The o1 series of models are trained with reinforcement learning to think before they answer and perform complex reasoning. The o1-pro model uses more compute to think harder and provide consistently better answers. | openrouter |
| Text/Text | openai/o3 | o3 |
o3 is a well-rounded and powerful model across domains. It sets a new standard for math, science, coding, and visual reasoning tasks. It also excels at technical writing and instruction-following. Use it to think through multi-step problems that involve analysis across text, code, and images. Note that BYOK is required for this model. Set up here: https://openrouter.ai/settings/integrations | openrouter |
| Text/Text | openai/o3-mini | o3_mini |
OpenAI o3-mini is a cost-efficient language model optimized for STEM reasoning tasks, particularly excelling in science, mathematics, and coding. This model supports the reasoning_effort parameter, which can be set to 'high', 'medium', or 'low' to control the thinking time of the model. The default is 'medium'. OpenRouter also offers the model slug openai/o3-mini-high to default the parameter to 'high'. The model features three adjustable reasoning effort levels and supports key developer capabilities including function calling, structured outputs, and streaming, though it does not include vision processing capabilities. The model demonstrates significant improvements over its predecessor, with expert testers preferring its responses 56% of the time and noting a 39% reduction in major errors on complex questions. With medium reasoning effort settings, o3-mini matches the performance of the larger o1 model on challenging reasoning evaluations like AIME and GPQA, while maintaining lower latency and cost. |
openrouter |
| Text/Text | openai/o3-mini-high | o3_mini_high |
OpenAI o3-mini-high is the same model as o3-mini with reasoning_effort set to high. o3-mini is a cost-efficient language model optimized for STEM reasoning tasks, particularly excelling in science, mathematics, and coding. The model features three adjustable reasoning effort levels and supports key developer capabilities including function calling, structured outputs, and streaming, though it does not include vision processing capabilities. The model demonstrates significant improvements over its predecessor, with expert testers preferring its responses 56% of the time and noting a 39% reduction in major errors on complex questions. With medium reasoning effort settings, o3-mini matches the performance of the larger o1 model on challenging reasoning evaluations like AIME and GPQA, while maintaining lower latency and cost. | openrouter |
| Text/Text | openai/o4-mini | o4_mini |
OpenAI o4-mini is a compact reasoning model in the o-series, optimized for fast, cost-efficient performance while retaining strong multimodal and agentic capabilities. It supports tool use and demonstrates competitive reasoning and coding performance across benchmarks like AIME (99.5% with Python) and SWE-bench, outperforming its predecessor o3-mini and even approaching o3 in some domains. Despite its smaller size, o4-mini exhibits high accuracy in STEM tasks, visual problem solving (e.g., MathVista, MMMU), and code editing. It is especially well-suited for high-throughput scenarios where latency or cost is critical. Thanks to its efficient architecture and refined reinforcement learning training, o4-mini can chain tools, generate structured outputs, and solve multi-step tasks with minimal delay—often in under a minute. | openrouter |
| Text/Text | openai/o4-mini-high | o4_mini_high |
OpenAI o4-mini-high is the same model as o4-mini with reasoning_effort set to high. OpenAI o4-mini is a compact reasoning model in the o-series, optimized for fast, cost-efficient performance while retaining strong multimodal and agentic capabilities. It supports tool use and demonstrates competitive reasoning and coding performance across benchmarks like AIME (99.5% with Python) and SWE-bench, outperforming its predecessor o3-mini and even approaching o3 in some domains. Despite its smaller size, o4-mini exhibits high accuracy in STEM tasks, visual problem solving (e.g., MathVista, MMMU), and code editing. It is especially well-suited for high-throughput scenarios where latency or cost is critical. Thanks to its efficient architecture and refined reinforcement learning training, o4-mini can chain tools, generate structured outputs, and solve multi-step tasks with minimal delay—often in under a minute. | openrouter |
| Text/Text | openrouter/auto | auto |
Your prompt will be processed by a meta-model and routed to one of dozens of models (see below), optimizing for the best possible output. To see which model was used, visit Activity, or read the model attribute of the response. Your response will be priced at the same rate as the routed model. The meta-model is powered by Not Diamond. Learn more in our docs. Requests will be routed to the following models:- openai/gpt-4o-2024-08-06- openai/gpt-4o-2024-05-13- openai/gpt-4o-mini-2024-07-18- openai/chatgpt-4o-latest- openai/o1-preview-2024-09-12- openai/o1-mini-2024-09-12- anthropic/claude-3.5-sonnet- anthropic/claude-3.5-haiku- anthropic/claude-3-opus- anthropic/claude-2.1- google/gemini-pro-1.5- google/gemini-flash-1.5- mistralai/mistral-large-2407- mistralai/mistral-nemo- deepseek/deepseek-r1- meta-llama/llama-3.1-70b-instruct- meta-llama/llama-3.1-405b-instruct- mistralai/mixtral-8x22b-instruct- cohere/command-r-plus- cohere/command-r |
openrouter |
| Text/Text | perplexity/llama-3.1-sonar-large-128k-online | llama_3_1_sonar_large_128k_online |
Llama 3.1 Sonar is Perplexity's latest model family. It surpasses their earlier Sonar models in cost-efficiency, speed, and performance. This is the online version of the offline chat model. It is focused on delivering helpful, up-to-date, and factual responses. #online | openrouter |
| Text/Text | perplexity/llama-3.1-sonar-small-128k-online | llama_3_1_sonar_small_128k_online |
Llama 3.1 Sonar is Perplexity's latest model family. It surpasses their earlier Sonar models in cost-efficiency, speed, and performance. This is the online version of the offline chat model. It is focused on delivering helpful, up-to-date, and factual responses. #online | openrouter |
| Text/Text | perplexity/r1-1776 | r1_1776 |
R1 1776 is a version of DeepSeek-R1 that has been post-trained to remove censorship constraints related to topics restricted by the Chinese government. The model retains its original reasoning capabilities while providing direct responses to a wider range of queries. R1 1776 is an offline chat model that does not use the perplexity search subsystem. The model was tested on a multilingual dataset of over 1,000 examples covering sensitive topics to measure its likelihood of refusal or overly filtered responses. Evaluation Results Its performance on math and reasoning benchmarks remains similar to the base R1 model. Reasoning Performance Read more on the Blog Post | openrouter |
| Text/Text | perplexity/sonar | sonar |
Sonar is lightweight, affordable, fast, and simple to use — now featuring citations and the ability to customize sources. It is designed for companies seeking to integrate lightweight question-and-answer features optimized for speed. | openrouter |
| Text/Text | perplexity/sonar-deep-research | sonar_deep_research |
Sonar Deep Research is a research-focused model designed for multi-step retrieval, synthesis, and reasoning across complex topics. It autonomously searches, reads, and evaluates sources, refining its approach as it gathers information. This enables comprehensive report generation across domains like finance, technology, health, and current events. Notes on Pricing (Source) - Input tokens comprise of Prompt tokens (user prompt) + Citation tokens (these are processed tokens from running searches)- Deep Research runs multiple searches to conduct exhaustive research. Searches are priced at $5/1000 searches. A request that does 30 searches will cost $0.15 in this step.- Reasoning is a distinct step in Deep Research since it does extensive automated reasoning through all the material it gathers during its research phase. Reasoning tokens here are a bit different than the CoTs in the answer - these are tokens that we use to reason through the research material prior to generating the outputs via the CoTs. Reasoning tokens are priced at $3/1M tokens | openrouter |
| Text/Text | perplexity/sonar-pro | sonar_pro |
Note: Sonar Pro pricing includes Perplexity search pricing. See details here For enterprises seeking more advanced capabilities, the Sonar Pro API can handle in-depth, multi-step queries with added extensibility, like double the number of citations per search as Sonar on average. Plus, with a larger context window, it can handle longer and more nuanced searches and follow-up questions. | openrouter |
| Text/Text | perplexity/sonar-reasoning | sonar_reasoning |
Sonar Reasoning is a reasoning model provided by Perplexity based on DeepSeek R1. It allows developers to utilize long chain of thought with built-in web search. Sonar Reasoning is uncensored and hosted in US datacenters. | openrouter |
| Text/Text | perplexity/sonar-reasoning-pro | sonar_reasoning_pro |
Note: Sonar Pro pricing includes Perplexity search pricing. See details here Sonar Reasoning Pro is a premier reasoning model powered by DeepSeek R1 with Chain of Thought (CoT). Designed for advanced use cases, it supports in-depth, multi-step queries with a larger context window and can surface more citations per search, enabling more comprehensive and extensible responses. | openrouter |
| Text/Text | pygmalionai/mythalion-13b | mythalion_13b |
A blend of the new Pygmalion-13b and MythoMax. #merge | openrouter |
| Text/Text | qwen/qwen-2-72b-instruct | qwen_2_72b_instruct |
Qwen2 72B is a transformer-based model that excels in language understanding, multilingual capabilities, coding, mathematics, and reasoning. It features SwiGLU activation, attention QKV bias, and group query attention. It is pretrained on extensive data with supervised finetuning and direct preference optimization. For more details, see this blog post and GitHub repo. Usage of this model is subject to Tongyi Qianwen LICENSE AGREEMENT. | openrouter |
| Text/Text | qwen/qwen-2.5-72b-instruct | qwen_2_5_72b_instruct |
Qwen2.5 72B is the latest series of Qwen large language models. Qwen2.5 brings the following improvements upon Qwen2:- Significantly more knowledge and has greatly improved capabilities in coding and mathematics, thanks to our specialized expert models in these domains.- Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON. More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.- Long-context Support up to 128K tokens and can generate up to 8K tokens.- Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more. Usage of this model is subject to Tongyi Qianwen LICENSE AGREEMENT. | openrouter |
| Text/Text | qwen/qwen-2.5-72b-instruct:free | qwen_2_5_72b_instruct__free |
Qwen2.5 72B is the latest series of Qwen large language models. Qwen2.5 brings the following improvements upon Qwen2:- Significantly more knowledge and has greatly improved capabilities in coding and mathematics, thanks to our specialized expert models in these domains.- Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON. More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.- Long-context Support up to 128K tokens and can generate up to 8K tokens.- Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more. Usage of this model is subject to Tongyi Qianwen LICENSE AGREEMENT. | openrouter |
| Text/Text | qwen/qwen-2.5-7b-instruct | qwen_2_5_7b_instruct |
Qwen2.5 7B is the latest series of Qwen large language models. Qwen2.5 brings the following improvements upon Qwen2:- Significantly more knowledge and has greatly improved capabilities in coding and mathematics, thanks to our specialized expert models in these domains.- Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON. More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.- Long-context Support up to 128K tokens and can generate up to 8K tokens.- Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more. Usage of this model is subject to Tongyi Qianwen LICENSE AGREEMENT. | openrouter |
| Text/Text | qwen/qwen-2.5-7b-instruct:free | qwen_2_5_7b_instruct__free |
Qwen2.5 7B is the latest series of Qwen large language models. Qwen2.5 brings the following improvements upon Qwen2:- Significantly more knowledge and has greatly improved capabilities in coding and mathematics, thanks to our specialized expert models in these domains.- Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON. More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.- Long-context Support up to 128K tokens and can generate up to 8K tokens.- Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more. Usage of this model is subject to Tongyi Qianwen LICENSE AGREEMENT. | openrouter |
| Text/Text | qwen/qwen-2.5-coder-32b-instruct | qwen_2_5_coder_32b_instruct |
Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). Qwen2.5-Coder brings the following improvements upon CodeQwen1.5:- Significantly improvements in code generation, code reasoning and code fixing. - A more comprehensive foundation for real-world applications such as Code Agents. Not only enhancing coding capabilities but also maintaining its strengths in mathematics and general competencies. To read more about its evaluation results, check out Qwen 2.5 Coder's blog. | openrouter |
| Text/Text | qwen/qwen-2.5-coder-32b-instruct:free | qwen_2_5_coder_32b_instruct__free |
Qwen2.5-Coder is the latest series of Code-Specific Qwen large language models (formerly known as CodeQwen). Qwen2.5-Coder brings the following improvements upon CodeQwen1.5:- Significantly improvements in code generation, code reasoning and code fixing. - A more comprehensive foundation for real-world applications such as Code Agents. Not only enhancing coding capabilities but also maintaining its strengths in mathematics and general competencies. To read more about its evaluation results, check out Qwen 2.5 Coder's blog. | openrouter |
| Text/Text | qwen/qwen-2.5-vl-7b-instruct | qwen_2_5_vl_7b_instruct |
Qwen2.5 VL 7B is a multimodal LLM from the Qwen Team with the following key enhancements:- SoTA understanding of images of various resolution & ratio: Qwen2.5-VL achieves state-of-the-art performance on visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, MTVQA, etc.- Understanding videos of 20min+: Qwen2.5-VL can understand videos over 20 minutes for high-quality video-based question answering, dialog, content creation, etc.- Agent that can operate your mobiles, robots, etc.: with the abilities of complex reasoning and decision making, Qwen2.5-VL can be integrated with devices like mobile phones, robots, etc., for automatic operation based on visual environment and text instructions.- Multilingual Support: to serve global users, besides English and Chinese, Qwen2.5-VL now supports the understanding of texts in different languages inside images, including most European languages, Japanese, Korean, Arabic, Vietnamese, etc. For more details, see this blog post and GitHub repo. Usage of this model is subject to Tongyi Qianwen LICENSE AGREEMENT. | openrouter |
| Text/Text | qwen/qwen-2.5-vl-7b-instruct:free | qwen_2_5_vl_7b_instruct__free |
Qwen2.5 VL 7B is a multimodal LLM from the Qwen Team with the following key enhancements:- SoTA understanding of images of various resolution & ratio: Qwen2.5-VL achieves state-of-the-art performance on visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, MTVQA, etc.- Understanding videos of 20min+: Qwen2.5-VL can understand videos over 20 minutes for high-quality video-based question answering, dialog, content creation, etc.- Agent that can operate your mobiles, robots, etc.: with the abilities of complex reasoning and decision making, Qwen2.5-VL can be integrated with devices like mobile phones, robots, etc., for automatic operation based on visual environment and text instructions.- Multilingual Support: to serve global users, besides English and Chinese, Qwen2.5-VL now supports the understanding of texts in different languages inside images, including most European languages, Japanese, Korean, Arabic, Vietnamese, etc. For more details, see this blog post and GitHub repo. Usage of this model is subject to Tongyi Qianwen LICENSE AGREEMENT. | openrouter |
| Text/Text | qwen/qwen-max | qwen_max |
Qwen-Max, based on Qwen2.5, provides the best inference performance among Qwen models, especially for complex multi-step tasks. It's a large-scale MoE model that has been pretrained on over 20 trillion tokens and further post-trained with curated Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) methodologies. The parameter count is unknown. | openrouter |
| Text/Text | qwen/qwen-plus | qwen_plus |
Qwen-Plus, based on the Qwen2.5 foundation model, is a 131K context model with a balanced performance, speed, and cost combination. | openrouter |
| Text/Text | qwen/qwen-turbo | qwen_turbo |
Qwen-Turbo, based on Qwen2.5, is a 1M context model that provides fast speed and low cost, suitable for simple tasks. | openrouter |
| Text/Text | qwen/qwen-vl-max | qwen_vl_max |
Qwen VL Max is a visual understanding model with 7500 tokens context length. It excels in delivering optimal performance for a broader spectrum of complex tasks. | openrouter |
| Text/Text | qwen/qwen-vl-plus | qwen_vl_plus |
Qwen's Enhanced Large Visual Language Model. Significantly upgraded for detailed recognition capabilities and text recognition abilities, supporting ultra-high pixel resolutions up to millions of pixels and extreme aspect ratios for image input. It delivers significant performance across a broad range of visual tasks. | openrouter |
| Text/Text | qwen/qwen2.5-coder-7b-instruct | qwen2_5_coder_7b_instruct |
Qwen2.5-Coder-7B-Instruct is a 7B parameter instruction-tuned language model optimized for code-related tasks such as code generation, reasoning, and bug fixing. Based on the Qwen2.5 architecture, it incorporates enhancements like RoPE, SwiGLU, RMSNorm, and GQA attention with support for up to 128K tokens using YaRN-based extrapolation. It is trained on a large corpus of source code, synthetic data, and text-code grounding, providing robust performance across programming languages and agentic coding workflows. This model is part of the Qwen2.5-Coder family and offers strong compatibility with tools like vLLM for efficient deployment. Released under the Apache 2.0 license. | openrouter |
| Text/Text | qwen/qwen2.5-vl-3b-instruct:free | qwen2_5_vl_3b_instruct__free |
Qwen2.5 VL 3B is a multimodal LLM from the Qwen Team with the following key enhancements:- SoTA understanding of images of various resolution & ratio: Qwen2.5-VL achieves state-of-the-art performance on visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, MTVQA, etc.- Agent that can operate your mobiles, robots, etc.: with the abilities of complex reasoning and decision making, Qwen2.5-VL can be integrated with devices like mobile phones, robots, etc., for automatic operation based on visual environment and text instructions.- Multilingual Support: to serve global users, besides English and Chinese, Qwen2.5-VL now supports the understanding of texts in different languages inside images, including most European languages, Japanese, Korean, Arabic, Vietnamese, etc. For more details, see this blog post and GitHub repo. Usage of this model is subject to Tongyi Qianwen LICENSE AGREEMENT. | openrouter |
| Text/Text | qwen/qwen2.5-vl-72b-instruct | qwen2_5_vl_72b_instruct |
Qwen2.5-VL is proficient in recognizing common objects such as flowers, birds, fish, and insects. It is also highly capable of analyzing texts, charts, icons, graphics, and layouts within images. | openrouter |
| Text/Text | qwen/qwen2.5-vl-72b-instruct:free | qwen2_5_vl_72b_instruct__free |
Qwen2.5-VL is proficient in recognizing common objects such as flowers, birds, fish, and insects. It is also highly capable of analyzing texts, charts, icons, graphics, and layouts within images. | openrouter |
| Text/Text | qwen/qwen3-0.6b-04-28:free | qwen3_0_6b_04_28__free |
Qwen3-0.6B is a lightweight, 0.6 billion parameter language model in the Qwen3 series, offering support for both general-purpose dialogue and structured reasoning through a dual-mode (thinking/non-thinking) architecture. Despite its small size, it supports long contexts up to 32,768 tokens and provides multilingual, tool-use, and instruction-following capabilities. | openrouter |
| Text/Text | qwen/qwen3-1.7b:free | qwen3_1_7b__free |
Qwen3-1.7B is a compact, 1.7 billion parameter dense language model from the Qwen3 series, featuring dual-mode operation for both efficient dialogue (non-thinking) and advanced reasoning (thinking). Despite its small size, it supports 32,768-token contexts and delivers strong multilingual, instruction-following, and agentic capabilities, including tool use and structured output. | openrouter |
| Text/Text | qwen/qwen3-14b | qwen3_14b |
Qwen3-14B is a dense 14.8B parameter causal language model from the Qwen3 series, designed for both complex reasoning and efficient dialogue. It supports seamless switching between a 'thinking' mode for tasks like math, programming, and logical inference, and a 'non-thinking' mode for general-purpose conversation. The model is fine-tuned for instruction-following, agent tool use, creative writing, and multilingual tasks across 100+ languages and dialects. It natively handles 32K token contexts and can extend to 131K tokens using YaRN-based scaling. | openrouter |
| Text/Text | qwen/qwen3-14b:free | qwen3_14b__free |
Qwen3-14B is a dense 14.8B parameter causal language model from the Qwen3 series, designed for both complex reasoning and efficient dialogue. It supports seamless switching between a 'thinking' mode for tasks like math, programming, and logical inference, and a 'non-thinking' mode for general-purpose conversation. The model is fine-tuned for instruction-following, agent tool use, creative writing, and multilingual tasks across 100+ languages and dialects. It natively handles 32K token contexts and can extend to 131K tokens using YaRN-based scaling. | openrouter |
| Text/Text | qwen/qwen3-235b-a22b | qwen3_235b_a22b |
Qwen3-235B-A22B is a 235B parameter mixture-of-experts (MoE) model developed by Qwen, activating 22B parameters per forward pass. It supports seamless switching between a 'thinking' mode for complex reasoning, math, and code tasks, and a 'non-thinking' mode for general conversational efficiency. The model demonstrates strong reasoning ability, multilingual support (100+ languages and dialects), advanced instruction-following, and agent tool-calling capabilities. It natively handles a 32K token context window and extends up to 131K tokens using YaRN-based scaling. | openrouter |
| Text/Text | qwen/qwen3-235b-a22b:free | qwen3_235b_a22b__free |
Qwen3-235B-A22B is a 235B parameter mixture-of-experts (MoE) model developed by Qwen, activating 22B parameters per forward pass. It supports seamless switching between a 'thinking' mode for complex reasoning, math, and code tasks, and a 'non-thinking' mode for general conversational efficiency. The model demonstrates strong reasoning ability, multilingual support (100+ languages and dialects), advanced instruction-following, and agent tool-calling capabilities. It natively handles a 32K token context window and extends up to 131K tokens using YaRN-based scaling. | openrouter |
| Text/Text | qwen/qwen3-30b-a3b | qwen3_30b_a3b |
Qwen3, the latest generation in the Qwen large language model series, features both dense and mixture-of-experts (MoE) architectures to excel in reasoning, multilingual support, and advanced agent tasks. Its unique ability to switch seamlessly between a thinking mode for complex reasoning and a non-thinking mode for efficient dialogue ensures versatile, high-quality performance. Significantly outperforming prior models like QwQ and Qwen2.5, Qwen3 delivers superior mathematics, coding, commonsense reasoning, creative writing, and interactive dialogue capabilities. The Qwen3-30B-A3B variant includes 30.5 billion parameters (3.3 billion activated), 48 layers, 128 experts (8 activated per task), and supports up to 131K token contexts with YaRN, setting a new standard among open-source models. | openrouter |
| Text/Text | qwen/qwen3-30b-a3b:free | qwen3_30b_a3b__free |
Qwen3, the latest generation in the Qwen large language model series, features both dense and mixture-of-experts (MoE) architectures to excel in reasoning, multilingual support, and advanced agent tasks. Its unique ability to switch seamlessly between a thinking mode for complex reasoning and a non-thinking mode for efficient dialogue ensures versatile, high-quality performance. Significantly outperforming prior models like QwQ and Qwen2.5, Qwen3 delivers superior mathematics, coding, commonsense reasoning, creative writing, and interactive dialogue capabilities. The Qwen3-30B-A3B variant includes 30.5 billion parameters (3.3 billion activated), 48 layers, 128 experts (8 activated per task), and supports up to 131K token contexts with YaRN, setting a new standard among open-source models. | openrouter |
| Text/Text | qwen/qwen3-32b | qwen3_32b |
Qwen3-32B is a dense 32.8B parameter causal language model from the Qwen3 series, optimized for both complex reasoning and efficient dialogue. It supports seamless switching between a 'thinking' mode for tasks like math, coding, and logical inference, and a 'non-thinking' mode for faster, general-purpose conversation. The model demonstrates strong performance in instruction-following, agent tool use, creative writing, and multilingual tasks across 100+ languages and dialects. It natively handles 32K token contexts and can extend to 131K tokens using YaRN-based scaling. | openrouter |
| Text/Text | qwen/qwen3-32b:free | qwen3_32b__free |
Qwen3-32B is a dense 32.8B parameter causal language model from the Qwen3 series, optimized for both complex reasoning and efficient dialogue. It supports seamless switching between a 'thinking' mode for tasks like math, coding, and logical inference, and a 'non-thinking' mode for faster, general-purpose conversation. The model demonstrates strong performance in instruction-following, agent tool use, creative writing, and multilingual tasks across 100+ languages and dialects. It natively handles 32K token contexts and can extend to 131K tokens using YaRN-based scaling. | openrouter |
| Text/Text | qwen/qwen3-4b:free | qwen3_4b__free |
Qwen3-4B is a 4 billion parameter dense language model from the Qwen3 series, designed to support both general-purpose and reasoning-intensive tasks. It introduces a dual-mode architecture—thinking and non-thinking—allowing dynamic switching between high-precision logical reasoning and efficient dialogue generation. This makes it well-suited for multi-turn chat, instruction following, and complex agent workflows. | openrouter |
| Text/Text | qwen/qwen3-8b | qwen3_8b |
Qwen3-8B is a dense 8.2B parameter causal language model from the Qwen3 series, designed for both reasoning-heavy tasks and efficient dialogue. It supports seamless switching between 'thinking' mode for math, coding, and logical inference, and 'non-thinking' mode for general conversation. The model is fine-tuned for instruction-following, agent integration, creative writing, and multilingual use across 100+ languages and dialects. It natively supports a 32K token context window and can extend to 131K tokens with YaRN scaling. | openrouter |
| Text/Text | qwen/qwen3-8b:free | qwen3_8b__free |
Qwen3-8B is a dense 8.2B parameter causal language model from the Qwen3 series, designed for both reasoning-heavy tasks and efficient dialogue. It supports seamless switching between 'thinking' mode for math, coding, and logical inference, and 'non-thinking' mode for general conversation. The model is fine-tuned for instruction-following, agent integration, creative writing, and multilingual use across 100+ languages and dialects. It natively supports a 32K token context window and can extend to 131K tokens with YaRN scaling. | openrouter |
| Text/Text | qwen/qwq-32b | qwq_32b |
QwQ is the reasoning model of the Qwen series. Compared with conventional instruction-tuned models, QwQ, which is capable of thinking and reasoning, can achieve significantly enhanced performance in downstream tasks, especially hard problems. QwQ-32B is the medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini. | openrouter |
| Text/Text | qwen/qwq-32b-preview | qwq_32b_preview |
QwQ-32B-Preview is an experimental research model focused on AI reasoning capabilities developed by the Qwen Team. As a preview release, it demonstrates promising analytical abilities while having several important limitations: 1. Language Mixing and Code-Switching: The model may mix languages or switch between them unexpectedly, affecting response clarity. 2. Recursive Reasoning Loops: The model may enter circular reasoning patterns, leading to lengthy responses without a conclusive answer. 3. Safety and Ethical Considerations: The model requires enhanced safety measures to ensure reliable and secure performance, and users should exercise caution when deploying it. 4. Performance and Benchmark Limitations: The model excels in math and coding but has room for improvement in other areas, such as common sense reasoning and nuanced language understanding. | openrouter |
| Text/Text | qwen/qwq-32b-preview:free | qwq_32b_preview__free |
QwQ-32B-Preview is an experimental research model focused on AI reasoning capabilities developed by the Qwen Team. As a preview release, it demonstrates promising analytical abilities while having several important limitations: 1. Language Mixing and Code-Switching: The model may mix languages or switch between them unexpectedly, affecting response clarity. 2. Recursive Reasoning Loops: The model may enter circular reasoning patterns, leading to lengthy responses without a conclusive answer. 3. Safety and Ethical Considerations: The model requires enhanced safety measures to ensure reliable and secure performance, and users should exercise caution when deploying it. 4. Performance and Benchmark Limitations: The model excels in math and coding but has room for improvement in other areas, such as common sense reasoning and nuanced language understanding. | openrouter |
| Text/Text | qwen/qwq-32b:free | qwq_32b__free |
QwQ is the reasoning model of the Qwen series. Compared with conventional instruction-tuned models, QwQ, which is capable of thinking and reasoning, can achieve significantly enhanced performance in downstream tasks, especially hard problems. QwQ-32B is the medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini. | openrouter |
| Text/Text | raifle/sorcererlm-8x22b | sorcererlm_8x22b |
SorcererLM is an advanced RP and storytelling model, built as a Low-rank 16-bit LoRA fine-tuned on WizardLM-2 8x22B.- Advanced reasoning and emotional intelligence for engaging and immersive interactions- Vivid writing capabilities enriched with spatial and contextual awareness- Enhanced narrative depth, promoting creative and dynamic storytelling | openrouter |
| Text/Text | rekaai/reka-flash-3:free | reka_flash_3__free |
Reka Flash 3 is a general-purpose, instruction-tuned large language model with 21 billion parameters, developed by Reka. It excels at general chat, coding tasks, instruction-following, and function calling. Featuring a 32K context length and optimized through reinforcement learning (RLOO), it provides competitive performance comparable to proprietary models within a smaller parameter footprint. Ideal for low-latency, local, or on-device deployments, Reka Flash 3 is compact, supports efficient quantization (down to 11GB at 4-bit precision), and employs explicit reasoning tags ('') to indicate its internal thought process. Reka Flash 3 is primarily an English model with limited multilingual understanding capabilities. The model weights are released under the Apache 2.0 license. | openrouter |
| Text/Text | sao10k/fimbulvetr-11b-v2 | fimbulvetr_11b_v2 |
Creative writing model, routed with permission. It's fast, it keeps the conversation going, and it stays in character. If you submit a raw prompt, you can use Alpaca or Vicuna formats. | openrouter |
| Text/Text | sao10k/l3-euryale-70b | l3_euryale_70b |
Euryale 70B v2.1 is a model focused on creative roleplay from Sao10k.- Better prompt adherence.- Better anatomy / spatial awareness.- Adapts much better to unique and custom formatting / reply formats.- Very creative, lots of unique swipes.- Is not restrictive during roleplays. | openrouter |
| Text/Text | sao10k/l3-lunaris-8b | l3_lunaris_8b |
Lunaris 8B is a versatile generalist and roleplaying model based on Llama 3. It's a strategic merge of multiple models, designed to balance creativity with improved logic and general knowledge. Created by Sao10k, this model aims to offer an improved experience over Stheno v3.2, with enhanced creativity and logical reasoning. For best results, use with Llama 3 Instruct context template, temperature 1.4, and min_p 0.1. | openrouter |
| Text/Text | sao10k/l3.1-euryale-70b | l3_1_euryale_70b |
Euryale L3.1 70B v2.2 is a model focused on creative roleplay from Sao10k. It is the successor of Euryale L3 70B v2.1. | openrouter |
| Text/Text | sao10k/l3.3-euryale-70b | l3_3_euryale_70b |
Euryale L3.3 70B is a model focused on creative roleplay from Sao10k. It is the successor of Euryale L3 70B v2.2. | openrouter |
| Text/Text | scb10x/llama3.1-typhoon2-70b-instruct | llama3_1_typhoon2_70b_instruct |
Llama3.1-Typhoon2-70B-Instruct is a Thai-English instruction-tuned language model with 70 billion parameters, built on Llama 3.1. It demonstrates strong performance across general instruction-following, math, coding, and tool-use tasks, with state-of-the-art results in Thai-specific benchmarks such as IFEval, MT-Bench, and Thai-English code-switching. The model excels in bilingual reasoning and function-calling scenarios, offering high accuracy across diverse domains. Comparative evaluations show consistent improvements over prior Thai LLMs and other Llama-based baselines. Full results and methodology are available in the technical report. | openrouter |
| Text/Text | scb10x/llama3.1-typhoon2-8b-instruct | llama3_1_typhoon2_8b_instruct |
Llama3.1-Typhoon2-8B-Instruct is a Thai-English instruction-tuned model with 8 billion parameters, built on Llama 3.1. It significantly improves over its base model in Thai reasoning, instruction-following, and function-calling tasks, while maintaining competitive English performance. The model is optimized for bilingual interaction and performs well on Thai-English code-switching, MT-Bench, IFEval, and tool-use benchmarks. Despite its smaller size, it demonstrates strong generalization across math, coding, and multilingual benchmarks, outperforming comparable 8B models across most Thai-specific tasks. Full benchmark results and methodology are available in the technical report. | openrouter |
| Text/Text | shisa-ai/shisa-v2-llama3.3-70b:free | shisa_v2_llama3_3_70b__free |
Shisa V2 Llama 3.3 70B is a bilingual Japanese-English chat model fine-tuned by Shisa.AI on Meta's Llama-3.3-70B-Instruct base. It prioritizes Japanese language performance while retaining strong English capabilities. The model was optimized entirely through post-training, using a refined mix of supervised fine-tuning (SFT) and DPO datasets including regenerated ShareGPT-style data, translation tasks, roleplaying conversations, and instruction-following prompts. Unlike earlier Shisa releases, this version avoids tokenizer modifications or extended pretraining. Shisa V2 70B achieves leading Japanese task performance across a wide range of custom and public benchmarks, including JA MT Bench, ELYZA 100, and Rakuda. It supports a 128K token context length and integrates smoothly with inference frameworks like vLLM and SGLang. While it inherits safety characteristics from its base model, no additional alignment was applied. The model is intended for high-performance bilingual chat, instruction following, and translation tasks across JA/EN. | openrouter |
| Text/Text | sophosympatheia/midnight-rose-70b | midnight_rose_70b |
A merge with a complex family tree, this model was crafted for roleplaying and storytelling. Midnight Rose is a successor to Rogue Rose and Aurora Nights and improves upon them both. It wants to produce lengthy output by default and is the best creative writing merge produced so far by sophosympatheia. Descending from earlier versions of Midnight Rose and Wizard Tulu Dolphin 70B, it inherits the best qualities of each. | openrouter |
| Text/Text | thedrummer/anubis-pro-105b-v1 | anubis_pro_105b_v1 |
Anubis Pro 105B v1 is an expanded and refined variant of Meta's Llama 3.3 70B, featuring 50% additional layers and further fine-tuning to leverage its increased capacity. Designed for advanced narrative, roleplay, and instructional tasks, it demonstrates enhanced emotional intelligence, creativity, nuanced character portrayal, and superior prompt adherence compared to smaller models. Its larger parameter count allows for deeper contextual understanding and extended reasoning capabilities, optimized for engaging, intelligent, and coherent interactions. | openrouter |
| Text/Text | thedrummer/rocinante-12b | rocinante_12b |
Rocinante 12B is designed for engaging storytelling and rich prose. Early testers have reported:- Expanded vocabulary with unique and expressive word choices- Enhanced creativity for vivid narratives- Adventure-filled and captivating stories | openrouter |
| Text/Text | thedrummer/skyfall-36b-v2 | skyfall_36b_v2 |
Skyfall 36B v2 is an enhanced iteration of Mistral Small 2501, specifically fine-tuned for improved creativity, nuanced writing, role-playing, and coherent storytelling. | openrouter |
| Text/Text | thedrummer/unslopnemo-12b | unslopnemo_12b |
UnslopNemo v4.1 is the latest addition from the creator of Rocinante, designed for adventure writing and role-play scenarios. | openrouter |
| Text/Text | thudm/glm-4-32b | glm_4_32b |
GLM-4-32B-0414 is a 32B bilingual (Chinese-English) open-weight language model optimized for code generation, function calling, and agent-style tasks. Pretrained on 15T of high-quality and reasoning-heavy data, it was further refined using human preference alignment, rejection sampling, and reinforcement learning. The model excels in complex reasoning, artifact generation, and structured output tasks, achieving performance comparable to GPT-4o and DeepSeek-V3-0324 across several benchmarks. | openrouter |
| Text/Text | thudm/glm-4-32b:free | glm_4_32b__free |
GLM-4-32B-0414 is a 32B bilingual (Chinese-English) open-weight language model optimized for code generation, function calling, and agent-style tasks. Pretrained on 15T of high-quality and reasoning-heavy data, it was further refined using human preference alignment, rejection sampling, and reinforcement learning. The model excels in complex reasoning, artifact generation, and structured output tasks, achieving performance comparable to GPT-4o and DeepSeek-V3-0324 across several benchmarks. | openrouter |
| Text/Text | thudm/glm-4-9b:free | glm_4_9b__free |
GLM-4-9B-0414 is a 9 billion parameter language model from the GLM-4 series developed by THUDM. Trained using the same reinforcement learning and alignment strategies as its larger 32B counterparts, GLM-4-9B-0414 achieves high performance relative to its size, making it suitable for resource-constrained deployments that still require robust language understanding and generation capabilities. | openrouter |
| Text/Text | thudm/glm-z1-32b | glm_z1_32b |
GLM-Z1-32B-0414 is an enhanced reasoning variant of GLM-4-32B, built for deep mathematical, logical, and code-oriented problem solving. It applies extended reinforcement learning—both task-specific and general pairwise preference-based—to improve performance on complex multi-step tasks. Compared to the base GLM-4-32B model, Z1 significantly boosts capabilities in structured reasoning and formal domains. The model supports enforced 'thinking' steps via prompt engineering and offers improved coherence for long-form outputs. It's optimized for use in agentic workflows, and includes support for long context (via YaRN), JSON tool calling, and fine-grained sampling configuration for stable inference. Ideal for use cases requiring deliberate, multi-step reasoning or formal derivations. | openrouter |
| Text/Text | thudm/glm-z1-32b:free | glm_z1_32b__free |
GLM-Z1-32B-0414 is an enhanced reasoning variant of GLM-4-32B, built for deep mathematical, logical, and code-oriented problem solving. It applies extended reinforcement learning—both task-specific and general pairwise preference-based—to improve performance on complex multi-step tasks. Compared to the base GLM-4-32B model, Z1 significantly boosts capabilities in structured reasoning and formal domains. The model supports enforced 'thinking' steps via prompt engineering and offers improved coherence for long-form outputs. It's optimized for use in agentic workflows, and includes support for long context (via YaRN), JSON tool calling, and fine-grained sampling configuration for stable inference. Ideal for use cases requiring deliberate, multi-step reasoning or formal derivations. | openrouter |
| Text/Text | thudm/glm-z1-9b:free | glm_z1_9b__free |
GLM-Z1-9B-0414 is a 9B-parameter language model developed by THUDM as part of the GLM-4 family. It incorporates techniques originally applied to larger GLM-Z1 models, including extended reinforcement learning, pairwise ranking alignment, and training on reasoning-intensive tasks such as mathematics, code, and logic. Despite its smaller size, it demonstrates strong performance on general-purpose reasoning tasks and outperforms many open-source models in its weight class. | openrouter |
| Text/Text | thudm/glm-z1-rumination-32b | glm_z1_rumination_32b |
THUDM: GLM Z1 Rumination 32B is a 32B-parameter deep reasoning model from the GLM-4-Z1 series, optimized for complex, open-ended tasks requiring prolonged deliberation. It builds upon glm-4-32b-0414 with additional reinforcement learning phases and multi-stage alignment strategies, introducing 'rumination' capabilities designed to emulate extended cognitive processing. This includes iterative reasoning, multi-hop analysis, and tool-augmented workflows such as search, retrieval, and citation-aware synthesis. The model excels in research-style writing, comparative analysis, and intricate question answering. It supports function calling for search and navigation primitives (search, click, open, finish), enabling use in agent-style pipelines. Rumination behavior is governed by multi-turn loops with rule-based reward shaping and delayed decision mechanisms, benchmarked against Deep Research frameworks such as OpenAI's internal alignment stacks. This variant is suitable for scenarios requiring depth over speed. |
openrouter |
| Text/Text | tngtech/deepseek-r1t-chimera:free | deepseek_r1t_chimera__free |
DeepSeek-R1T-Chimera is created by merging DeepSeek-R1 and DeepSeek-V3 (0324), combining the reasoning capabilities of R1 with the token efficiency improvements of V3. It is based on a DeepSeek-MoE Transformer architecture and is optimized for general text generation tasks. The model merges pretrained weights from both source models to balance performance across reasoning, efficiency, and instruction-following tasks. It is released under the MIT license and intended for research and commercial use. | openrouter |
| Text/Text | undi95/remm-slerp-l2-13b | remm_slerp_l2_13b |
A recreation trial of the original MythoMax-L2-B13 but with updated models. #merge | openrouter |
| Text/Text | undi95/toppy-m-7b | toppy_m_7b |
A wild 7B parameter model that merges several models using the new task_arithmetic merge method from mergekit. List of merged models:- NousResearch/Nous-Capybara-7B-V1.9- HuggingFaceH4/zephyr-7b-beta- lemonilia/AshhLimaRP-Mistral-7B- Vulkane/120-Days-of-Sodom-LoRA-Mistral-7b- Undi95/Mistral-pippa-sharegpt-7b-qlora#merge #uncensored | openrouter |
| Text/Text | x-ai/grok-2-1212 | grok_2_1212 |
Grok 2 1212 introduces significant enhancements to accuracy, instruction adherence, and multilingual support, making it a powerful and flexible choice for developers seeking a highly steerable, intelligent model. | openrouter |
| Text/Text | x-ai/grok-3-beta | grok_3_beta |
Grok 3 is the latest model from xAI. It's their flagship model that excels at enterprise use cases like data extraction, coding, and text summarization. Possesses deep domain knowledge in finance, healthcare, law, and science. Excels in structured tasks and benchmarks like GPQA, LCB, and MMLU-Pro where it outperforms Grok 3 Mini even on high thinking. Note: That there are two xAI endpoints for this model. By default when using this model we will always route you to the base endpoint. If you want the fast endpoint you can add provider: { sort: throughput}, to sort by throughput instead. |
openrouter |
| Text/Text | x-ai/grok-3-mini-beta | grok_3_mini_beta |
Grok 3 Mini is a lightweight, smaller thinking model. Unlike traditional models that generate answers immediately, Grok 3 Mini thinks before responding. It's ideal for reasoning-heavy tasks that don't demand extensive domain knowledge, and shines in math-specific and quantitative use cases, such as solving challenging puzzles or math problems. Transparent 'thinking' traces accessible. Defaults to low reasoning, can boost with setting reasoning: { effort: 'high' } Note: That there are two xAI endpoints for this model. By default when using this model we will always route you to the base endpoint. If you want the fast endpoint you can add provider: { sort: throughput}, to sort by throughput instead. |
openrouter |
| Text/Text | x-ai/grok-beta | grok_beta |
Grok Beta is xAI's experimental language model with state-of-the-art reasoning capabilities, best for complex and multi-step use cases. It is the successor of Grok 2 with enhanced context length. | openrouter |
{kind=link}
{kind=link}
Disclaimer: Descriptions provided by OpenRouter.
Import path:
universal_intelligence.community.tools.<import>(eg. universal_intelligence.community.tools.mcp_client)
| Name | Import | Description | Configuration Requirements |
|---|---|---|---|
| Simple Printer | simple_printer |
Prints a given text to the console | prefix: Optional[str]: Optional prefix for log messages |
| Simple Error Generator | simple_error_generator |
Raises an error with optional custom message | prefix: Optional[str]: Optional prefix for error messages |
| MCP Client | mcp_client |
Calls tools on a remote MCP server and manages server communication | server_command: str: Command to execute the MCP serverserver_args: Optional[List[str]]: Command line arguments for the MCP serverserver_env: Optional[Dict[str, str]]: Environment variables for the MCP server |
| API Caller | api_caller |
Makes HTTP requests to configured API endpoints | base_url: str: Base URL for the APIdefault_headers: Optional[Dict[str, str]]: Default headers to include in every requesttimeout: Optional[int]: Request timeout in seconds |
Import path:
universal_intelligence.community.agents.<import>(eg. universal_intelligence.community.agents.default)
| I/O | Name | Import | Description | Default Model | Default Tools | Default Team |
|---|---|---|---|---|---|---|
| Text/Text | Simple Agent (default) | defaultor simple_agent |
Simple Agent which can use provided Tools and Agents to complete a task | Qwen2.5-7B-Instructcuda:Q4_K_M:llama.cppmps:Q4_K_M:llama.cppcpu:Q4_K_M:llama.cpp |
None | None |
You are welcome to contribute to community components. Please find some introductory information below.
universal-intelligence/
├── playground/ # Playground code directory
│ ├── web/ # Example web playground
│ └── example.py # Example playground
├── universal_intelligence/ # Source code directory
│ ├── core/ # Core library for the Universal Intelligence specification
│ │ ├── universal_model.py # Universal Model base implementation
│ │ ├── universal_agent.py # Universal Agent base implementation
│ │ ├── universal_tool.py # Universal Tool base implementation
│ │ └── utils/ # Utility functions and helpers
│ ├── community/ # Community components
│ │ ├── models/ # Community-contributed models
│ │ ├── agents/ # Community-contributed agents
│ │ └── tools/ # Community-contributed tools
│ └── www/ # Web Implementation
│ ├── core/ # Core library for the Universal Intelligence web specification
│ │ ├── universalModel.ts # Universal Model web base implementation
│ │ ├── universalAgent.ts # Universal Agent web base implementation
│ │ ├── universalTool.ts # Universal Tool web base implementation
│ │ └── types.ts # Universal Intelligence web types
│ └── community/ # Web community components
│ ├── models/ # Web community-contributed models
│ ├── agents/ # Web community-contributed agents
│ └── tools/ # Web community-contributed tools
├── requirements*.txt # Project dependencies
├── *.{yaml,toml,json,*rc,ts} # Project configuration
├── CODE_OF_CONDUCT.md # Community rules information
├── SECURITY.md # Vulnerability report information
├── LICENSE # License information
├── README_WEB.md # Project web documentation
└── README.md # Project documentationFor faster deployment and easier maintenance, we recommend using/enhancing shared mixins to bootstrap new Universal Intelligence components. Those are made available at ./universal_intelligence/community/<component>/__utils__/mixins. Mixins let components provide their own configurations and while levering a shared implementation. You can find an example here: ./universal_intelligence/community/models/qwen2_5_7b_instruct/model.py.
Model weights can be found here: https://huggingface.co
Each Universal Intelligence component comes with its own test suite.
Installation:
# (optional) Create dedicated python environment using miniconda
conda init zsh
conda create -n universal-intelligence python=3.10.16 -y
conda activate universal-intelligence
# Install base dependencies
pip install -r requirements.txt
# Install community components dependencies
pip install -r requirements-community.txt
# Install optimizations for your currect device
pip install -r requirements-mps.txt # Apple devices
pip install -r requirements-cuda.txt # NVIDIA devices
# Install development dependencies
pip install -r requirements-dev.txt
# Install commit hook
pre-commit install
# (optional) if using the MCP tool, install dedicated MCP specific dependencies
pip install -r requirements-mcp.txtSome of the community components interface with gated models, in which case you may have to accept the model's terms on Hugging Face and log into that approved account.
You may do so in your terminal using
huggingface-cli loginor in your code:
from huggingface_hub import login login()
Testing:
# python -m universal_intelligence.community.<component>.<name>.test
# examples
python -m universal_intelligence.community.models.default.test
python -m universal_intelligence.community.tools.default.test
python -m universal_intelligence.community.agents.default.testPlease note that running tests may require downloading multiple configurations of the same components, and temporarily use storage space. Tests will be automatically filtered based on hardware requirements.
Clear downloaded models from storage:
# pip install huggingface_hub["cli"] # Install CLI
huggingface-cli delete-cache # Clear cacheTest utilities provide shared test suites for each component type.
Model test examples:
- Test Suite:
universal_intelligence/community/models/__utils__/test.py - Usage:
universal_intelligence/community/models/qwen2_5_7b_instruct/test.py
Agent test examples:
- Test Suite:
universal_intelligence/community/agents/__utils__/test.py - Usage:
universal_intelligence/community/agents/simple_agent/test.py
Tool test examples:
- Test Suite:
universal_intelligence/community/tools/__utils__/test.py - Usage:
universal_intelligence/community/tools/simple_printer/test.py
Linting will run as part of the pre-commit hook, however you may also run it manully using pre-commit run --all-files
Universal Intelligence protocols and components can be used across all platforms (cloud, desktop, web, mobile).
python(cloud, desktop)How to use on the web, or in web-native apps, with
javascript/typescript(cloud, desktop, web, mobile)
Thanks for our friends at Hugging Face for making open source AI a reality. ✨
This project is powered by these fantastic engines: transformers, llama.cpp, mlx-lm, web-llm, openrouter.
This software is open source, free for everyone, and lives on thanks to the community's support ☕
If you'd like to support to universal-intelligence here are a few ways to do so:
- ⭐ Consider leaving a star on this repository to support our team & help with visibility
- 👽 Tell your friends and collegues
- 📰 Support this project on social medias (e.g. LinkedIn, Youtube, Medium, Reddit)
- ✅ Adopt the
⚪ Universal Intelligencespecification - 💪 Use the Community Components
- 💡 Help surfacing/resolving issues
- 💭 Help shape the
⚪ Universal Intelligencespecification - 🔧 Help maintain, test, enhance and create Community Components
- ✉️ Email us security concerns
- ❤️ Sponsor this project on Github
- 🤝 Partner with Bluera
Apache 2.0 License - Bluera Inc.