In this repository I present the code I used for the PANDA Kaggle competition. Please refer to the description of the competition for more insights. @chiamonni and @mawanda-jun worked on this repository.
The Prostate cANcer graDe Assessment (PANDA) Challenge requires participants to recognize 5 severity levels of prostate cancer in prostate biopsy, plus its absence (6 classes).
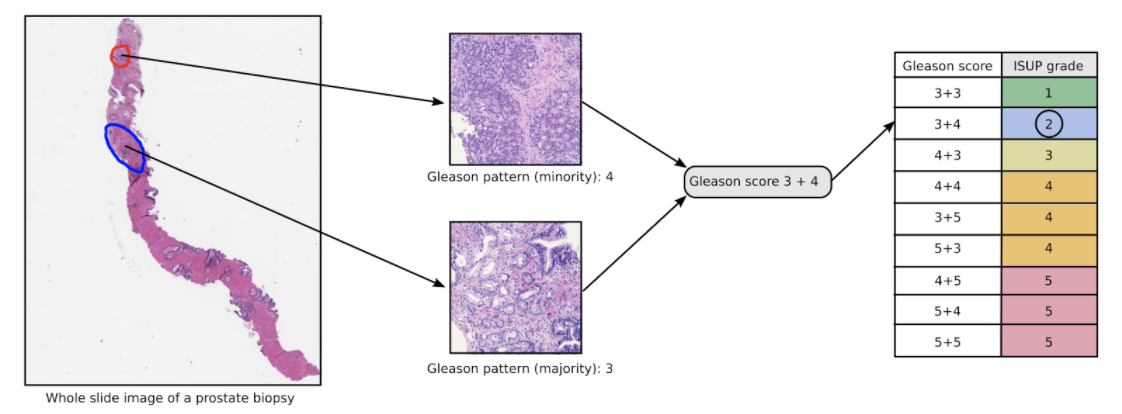
Therefore, this is a classification task.
The main challenges Kagglers faced where related to:
- dimensionality: images were quite large and sparse (~50K x ~50K px);
- uncertainty: labels were given by experts, which were sometimes interpreting the cancer gravity in different ways.

I decided to analyze each image and extract relevant "crops" to be stored directly on disk in order to reduce compute time while reading the images directly from disk. Therefore, I used the 4x reduced images (level 1 of original dataset) and extracted squared patches of 256px with the "akensert" method. Then, I stored the crops in an image with the slideshow of crops.

Each image came with a different number of crops. So, I realized a binned graph counting how many times a certain number of crops occured. The "akensert" method is the first metioned, the "cropped" one is a simple "strided" crop, in which I kept each square that was at least covered with 20% of non-zero pixels.

From the graph it is clear that the "akensert" method is more reliable (the curve is tighter) than the first I explored. In addition, I decided to select 26 random selected crops from each image:
- in the case they were less than 13 I doubled them, and filled the remaining with empty squares;
- in the case they were more, I randomly selected 26. I thought about this method as a regularization. In fact, the labels could have been assigned wrongly and selecting only a part of the crops could lead to a better generalization capability of my model. In addition, I forced my model to understand the gravity of the cancer from a part of the whole image in the 40% of the dataset, which I think helped it to generalize the proble better.
I found out that modifying the color of the images (with random contrast/saturation/ecc) augmentations was not giving me any particular advantage. In addition, I found out that simple flipping/rotation really helped me out in leveraging the differences between CV and LB. I also added a random occlusion augmentation, which covered each crop with a rectangle of ranging size of [0, 224) and really helped me in generalize the model performance w.r.t. the LB. As a side note, I think that those augmentations really helped my model perform so well in the private leader board (I gained +3% accuracy).
 An example of the resulting augmentations, with 8x8 crops.
An example of the resulting augmentations, with 8x8 crops.
For the network architecture I took inspiration from the method used from experts, that is:
- look closely to the tissue;
- characterize each tissue part with the most present gravity of cancer patterns;
- take the two most present ones and declare the cancer class.
Therefore, I created a siamese network which received each crops at a time with shared weights. The output of each siamese branch was then averaged with the others as a sort of polling, and then brought to the binned output. See the image below for further insight.

Since my computing resources were limited in memory (8GB VRAM, Nvidia 2070s) I was able to train this network with a ResNet18 semi-weakly pretrained model.
Since my model was performing so coherently among the CV and LB I decided not to do any cross validation. In fact, I simply trained the model with a 70/30 train/validation split of the whole training set.
The best hyper parameters I selected, within the trained weights, are under the folder good_experiments.
The aforementioned architecture resulted in:
- CV: 0.8504
- LB: 0.8503
- PB: 0.8966
Those results are quite interesting, since most of the competition participant used a EfficientNetB0 which is far bigger and more accurate in most of the benchmarks. I would have liked to train this particular architecture on a bigger machine, with more interesting architectures, hopefully with even better results.