Description
18_ARMv8_高速缓存(三)多核与一致性要素
探究cache的coherency,还要从ARM的多核处理器的历史讲起,为什么会引入这个问题,这个问题给业界带来什么挑战,我作为一个软件工程师,在多核系统上应该如何开发?

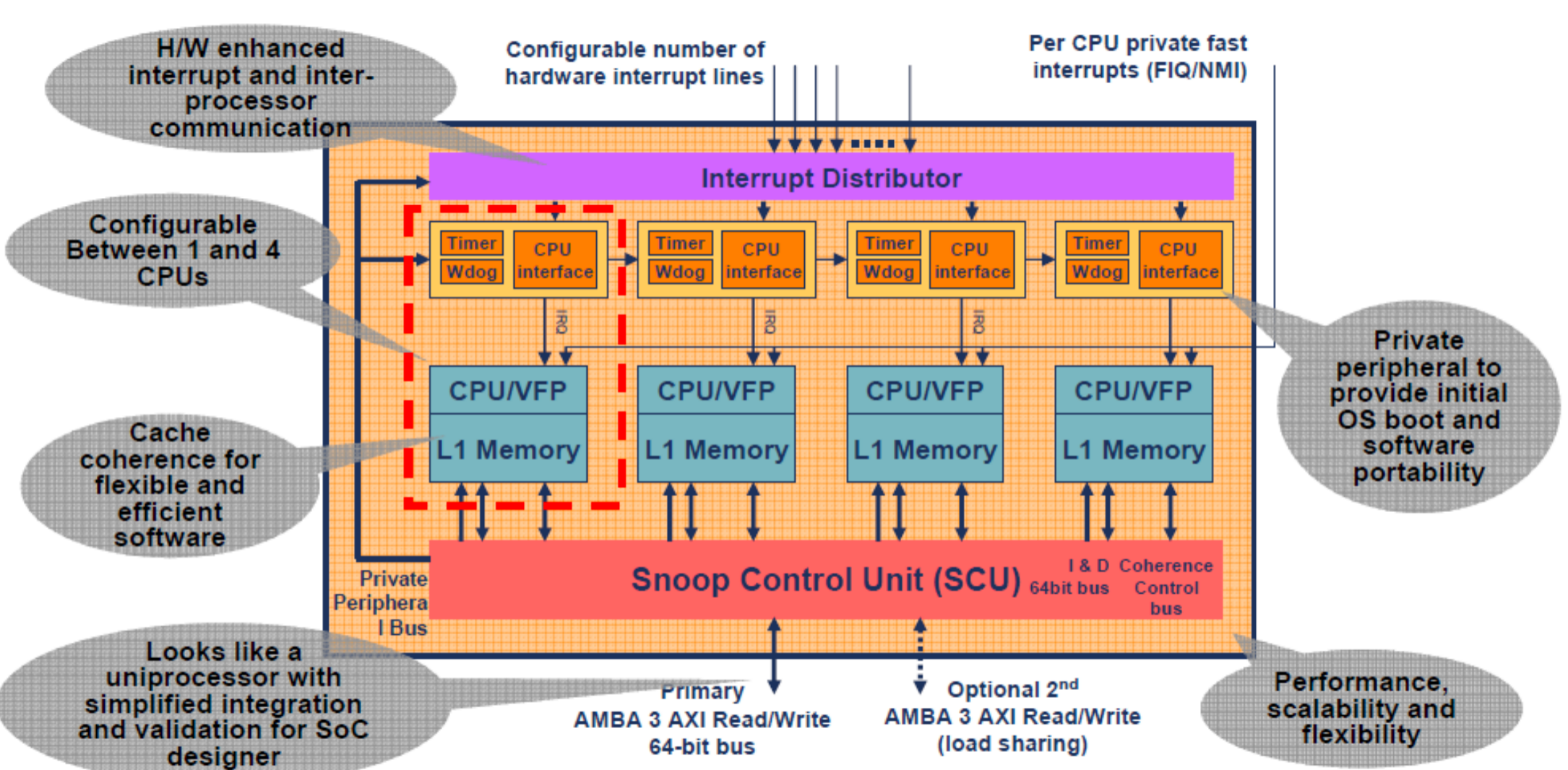
2004年ARM登上头版,宣布已经集成多核系统,实际上,2003年在学术界已经提出了这个架构的的模型了。2005年的时候ARM宣布帮助英伟达生产下一代的多核系统,如图所示。2006年Cortex-A8出世,不过Cortex- A8是一个单核的CPU,没有在多核层面的coherency的问题,不过在这个系统里面有DMA,会存在DMA和Cache之间的一致性问题;Cortex-A9的时候,加入了MPCore的设计,因此在core和core之间存在硬件一致性的问题,通常做法实现MESI总线协议(SCU,如下图),我们定义为多核之间的一致性问题;Cortex-A15中引入了大小核的概念,也就是把多个大核放在一起统称一个cluster,把所有的小核放在一起统称为一个cluster(簇),MESI总线协议可以保证在一个cluster内的一致性,而cluster和cluster之间的一致性需要另外引入硬件机制来保证,还有cluster和DMA、GPU之间也会引入一致性问题,ARM有现成的IP(CCI-400,CCI-500等),我们把cluster和cluster的一致性、cluster与gpu或者dma的一致性问题称为:系统之间的一致性性问题;
多核面向以下产品,这些产品多任务,且有着更高的性能。

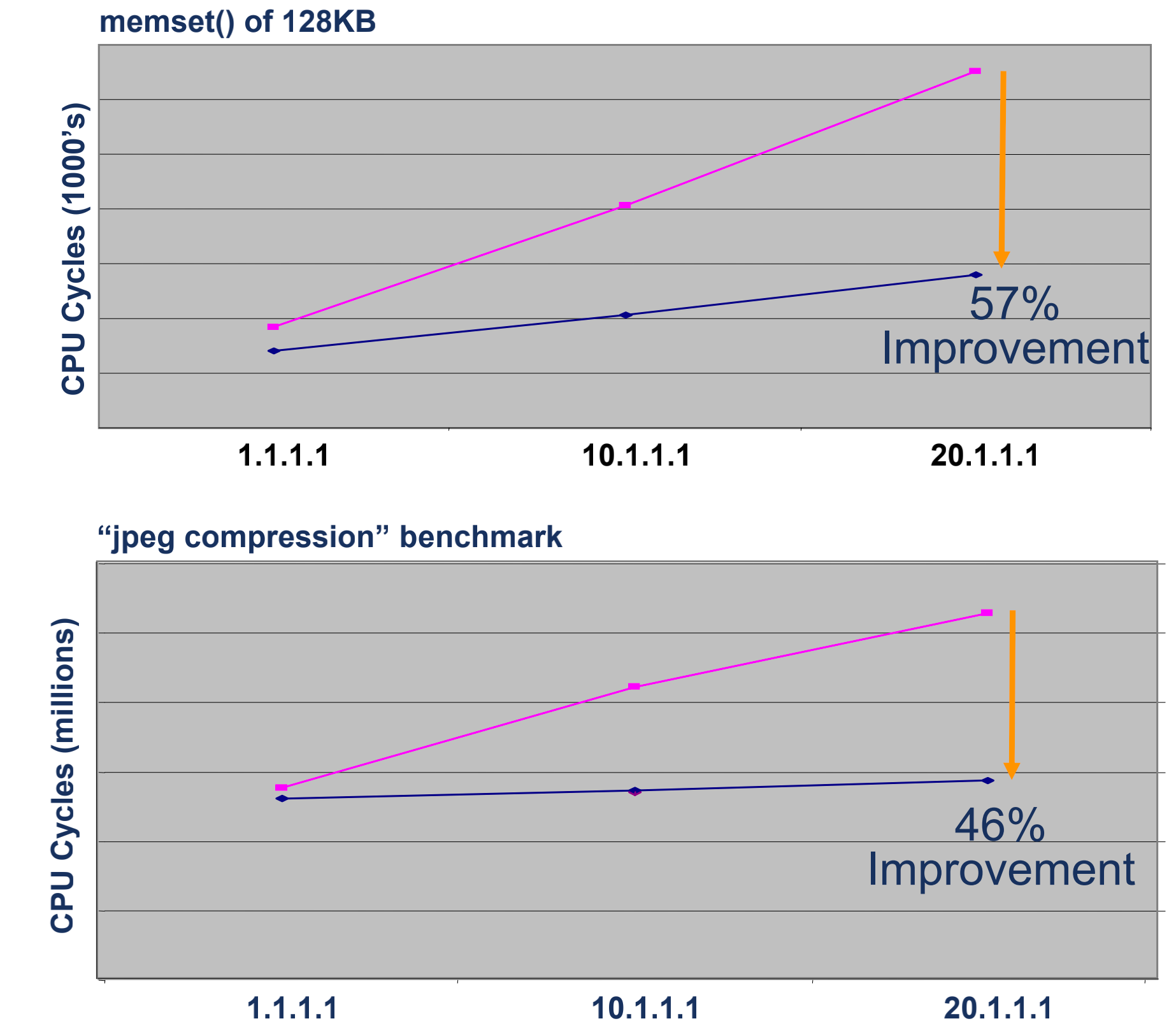
我们再来看一组数据,基于多核系统,在有cache和没有cache下的性能对比,红色是有L1 cache的,蓝色是没有L1 cache,分别进行memset和jpeg压缩,能看到cache在多核上的性能提高了52%左右。
题外话就这么多,不如这一节的正题,我们在这个部分需要了解,缓存一致性问题怎么演变过来的。
- 多核系统multiple-cores processors。
- 为什么需要cache一致性。
- cache coherency在业界有什么解决方案。
- MESI协议
note, 本章是【要素】更多的是理论和模型探讨,在高速缓存(四)会对ARMv8架构的一致性问题进行探究。
0.1 一致性解决方案
解决一致性问题通常有一些方案:
- 直接关闭cache (不可能)
- 要求软件编程者维护cache一致性 (最好)
- 要求硬件设计者维护cache一致性 (居中)
0.1.1 关闭cache(最差)
关闭cache不用想了,只要知道关闭cache不会存在一致性问题就好了。但为了解决一致性问题而关闭cache,得不偿失。在cache关闭情况下,每一次CPU都要主动从内存读写数据,这个一是性能降低,二是功耗也升高。
从软件硬件角度解决一致性问题是现在业界流行的方法。
0.1.2 硬件角度(中等)
处理器可以从硬件角度解决一致性问题,对于软件编程者来说这是一件很开心的事情,因为不需要自己维护cache了,减少了很大的工作量。可这样增加了硬件机制和复杂度。
系统层级
对于系统级别的一致性问题,我们上面也有提到,大部分SoC设计也采用了这样的方法,即把cluster和cluster通过ACE总线接入CCI-400/CCI-500的硬件模块上,软件设计可以无痛的不需要考虑系统级的一致性问题,大胆的使用DMA搬运数据。
核间层级
对于多核之间的一致性问题,在硬件上也可以解决,通常做法就是在多核内部实现一个MESI协议的控制器(Snoop Control Unit),这个控制器在硬件设计上有自己的状态机,会在总线上监听所有核心的状态。但并不是所有的处理器都会制作一个这样的硬件来维护一致性。
0.1.3 软件角度(最优)
从软件角度处理一致性问题,是现在综合成本最优的方案。在软件上,编程人员需要在合适的时候使用clean、invalidate和flush。缺点当然是会增加软件设计的复杂度,且debug和trace成本比较高,出问题比较隐晦,甚至需要一帧一帧的分析数据,这也可能是个随机错误,对!海森堡bug;另外,软件clean和invalidate还有flush都是让cache和内存打交道的行为,这样会增加功耗成本,频繁清理cache,并不是一个好的办法。因此,刷cache是一个非常依赖于开发者的经验,和QA团队测试力度的解决方案。
一致性的问题解决角度,大部分系统并不是完全依赖硬件或者软件,这对谁都不公平。So traded off,很多软件硬件各顶半边天,系统层级的交给硬件来解决,而cluster内部的一致性需要软件开发人员自己来维护。
1. 系统间的一致性
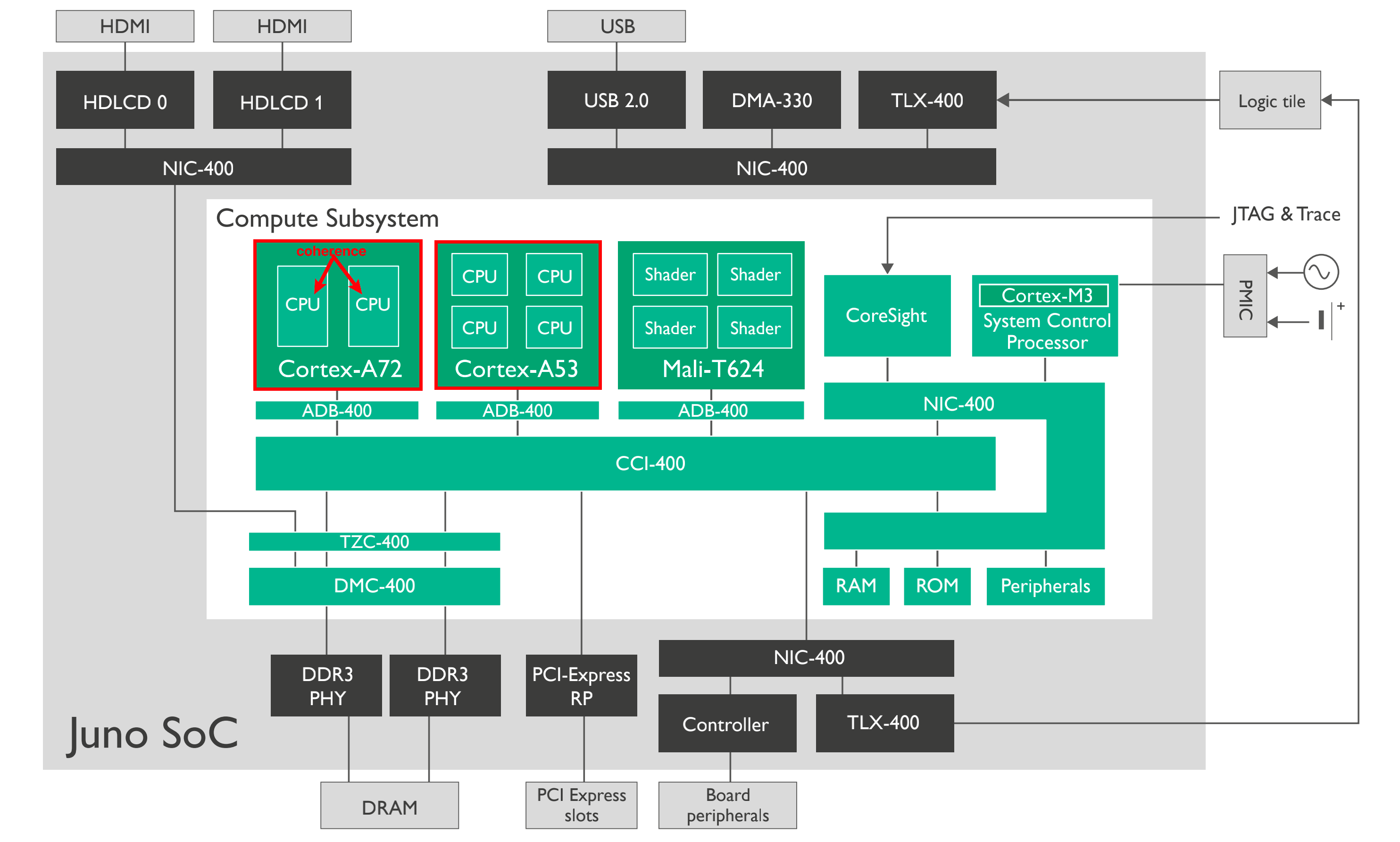
以下这个结构图来源于ARM 64 Bit Juno r2 ARM Development Platform 评估板,根据这个图,一共有5个我们比较关系的cluster:
-
cluster 1:
Cortex-A72,包含一个两个core0 和 core1,为方便表述我们用 a72.core0, a72.core1表述。每个a72.core都有一个48KB的L1 I-Cache,32KB的L1 D-Cache;共享L2 Cache 2MB1。
-
cluster 2:
Cortex-A52,包含4个core。a53.core0 - a53.core3表示。每个a53.core都有一个L1-32KB,L2 Cache 1MB1。
-
cluster 3:
Mali-T624, GPU,我们直接用mali.shader0 - mali.shader3 表示。L2 cache是128KB1。
-
cluster 4:
Cortex-M3,控制器,非多核结构,m3表示。
-
cluster 5:
DMA,用dma表示。
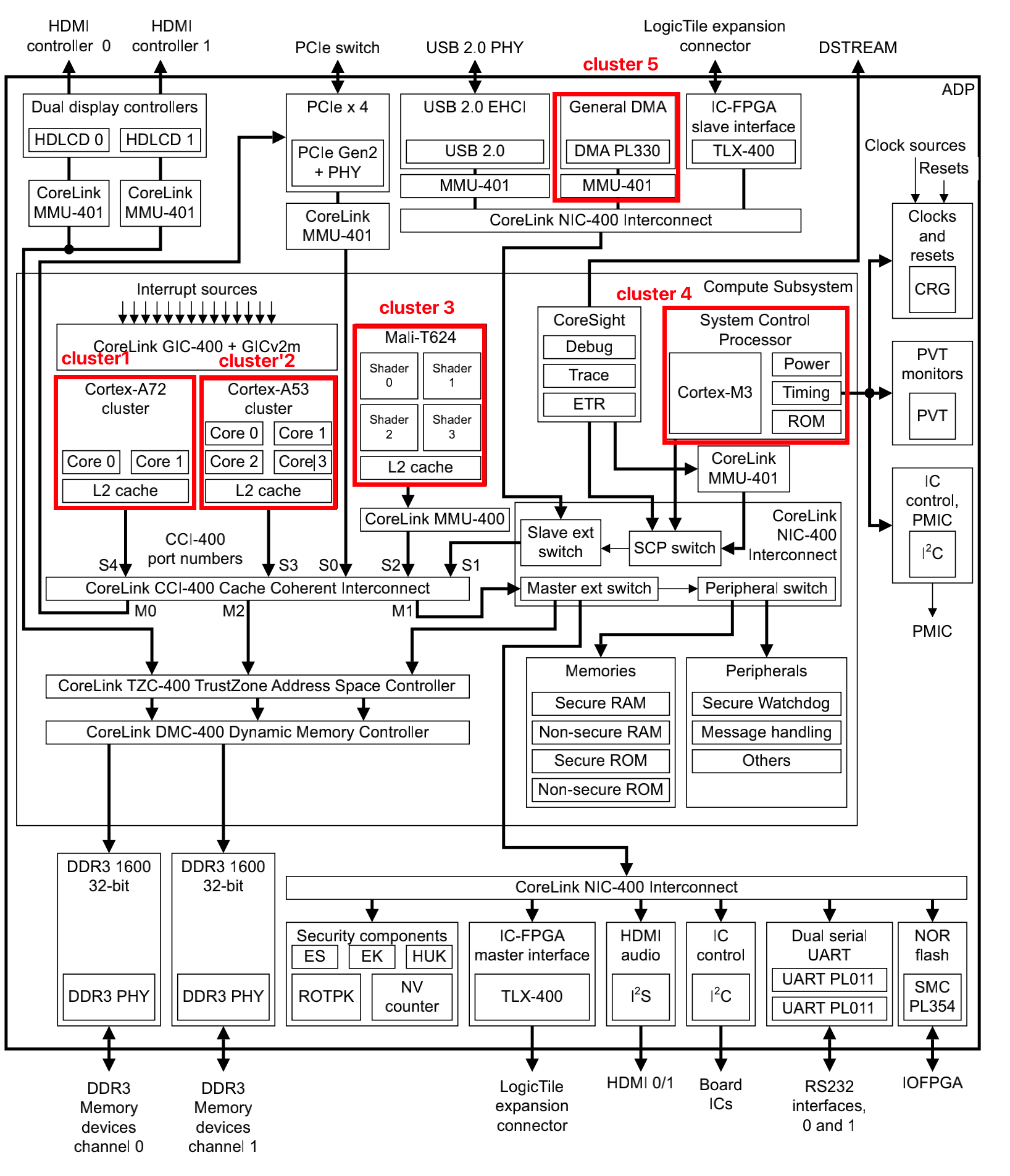
ARM的SoC越来越复杂,从multi-core演变为multi-cluster,每个cluster里面的core都有自己的L1 cache,每个cluster都有一个可以sharing的L2 cache。cluster通过ACE(AXI coherent Extension,AMBA 4中定义)连接到CCI-400(缓存一致性控制器)。在这个系统内部,除了CPU还有GPU,还有MCU,还有带DMA功能的外设,这些设备都有访问内存的功能,因此它们也必须通过ACE接口来连接到CCI-400上面,使整个系统层级的存储系统,保持一致性。
综上所述,一致性问题存在整个系统中,是由于cluster之间的隔离引起,为了保证一致性,在SoC设计的时候将这些clusters通过ACE连接到CCI-400控制器上,也就是说,系统间的一致性,是由CCI-400完成的,从软件工程师的角度,我们不需要维护系统的一致性。
1.1 举例 : non-coherent DMA
这有个DMA控制器的场景2,这个会影响CPU(cache)与memory的一致性。此时假设CPU的cache使用write-back策略,CPU更新了cache的数据,还没有clean到内存里,这个时候CPU想向外设依靠DMA write这个数据,DMA拿到的数据是一个和cache不一致的数据,这就造成了一致性问题;同样,内存从DMA read了数据并没有把数据刷到cache里面,CPU在不知情的情况下拿着旧数据做操作,这也会出现问题。我们可以
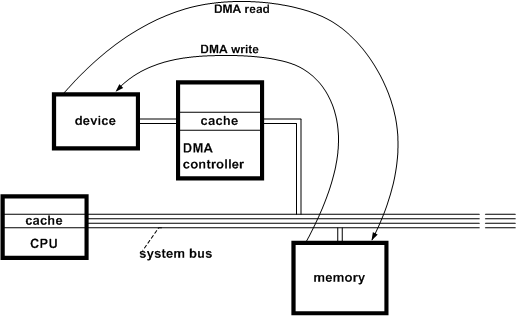
- DMA直接操作总线来读写内存地址,而CPU并不会感知到。
- 如果DMA修改了内存地址在CPU cache中有缓存的副本,CPU并不知道内存数据被修改了,依旧访问cache,这种情况错了。
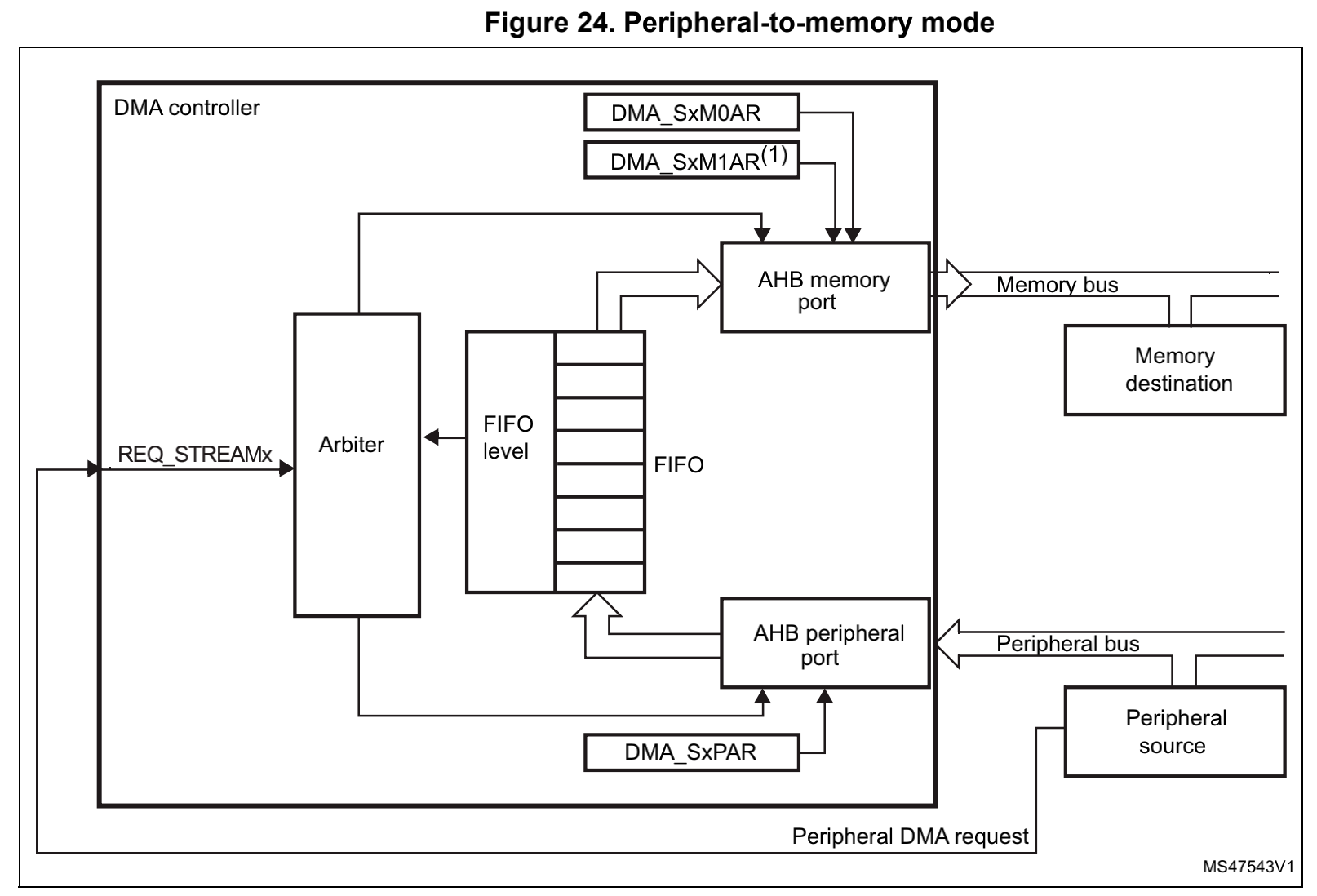
为了补充一下DMA的结构的知识,我们要知道DMA数据流向3,这个是stm32的DMA设计,其他设备应该都是大同小异的。DMA是内存和外设之间的一个桥梁,在DMA的内部也是使能了FIFO结构。
| 外设到内存 | 内存到外设 |
|---|---|
 |
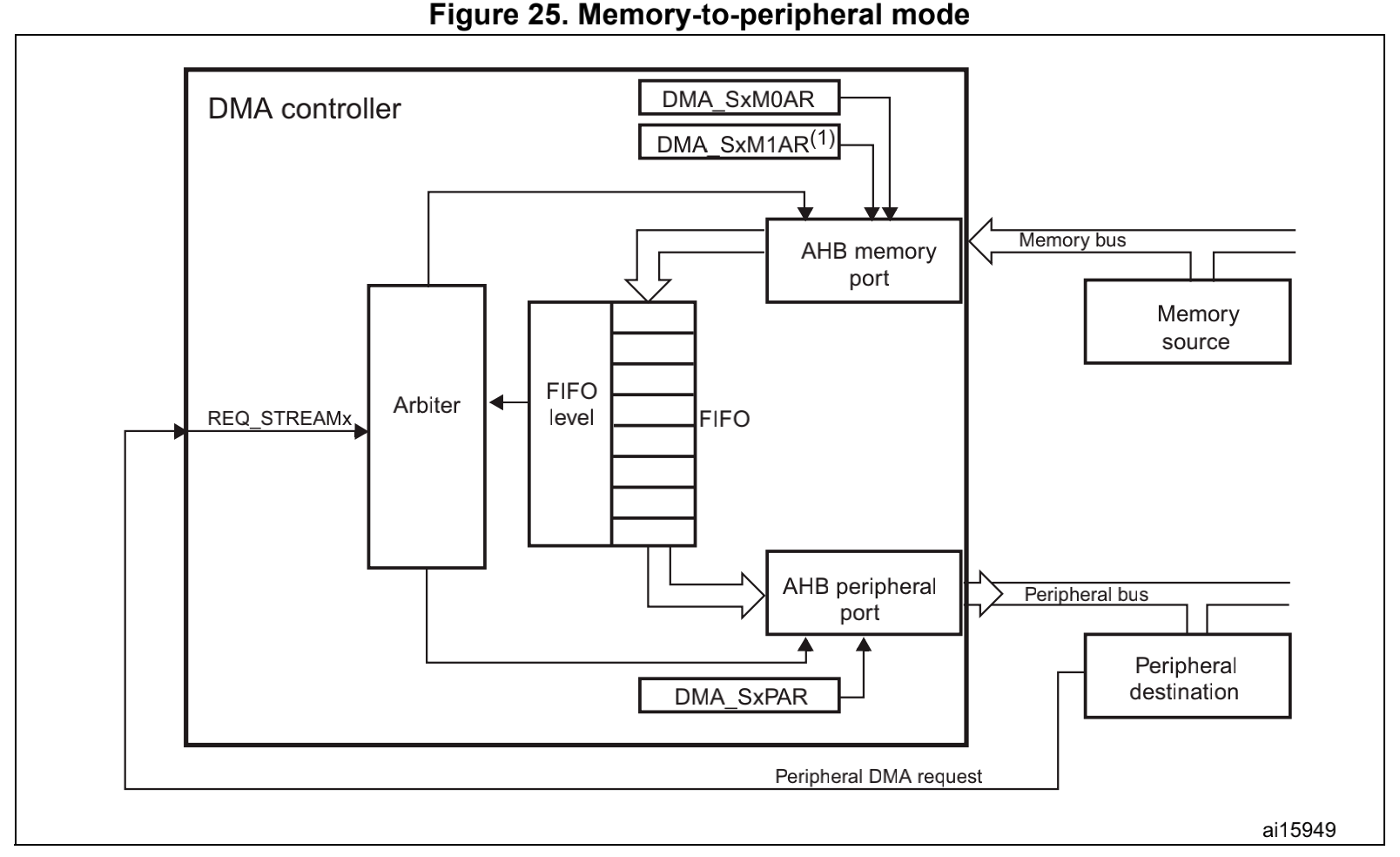 |
因此这里对于DMA缓冲区操作,我们可以根据数据流向分为两种情况:
- 从memory bus 到 peripheral
- 从peripheral到memory bus
1.1.1 内存到外设
我们来描述一下这个过程,CPU通过计算产生了一个数据(红色)会放在自己的cache line里面(L1和L2的cache假设一致性由SCU保证)。如果现在不对cache进行维护,CPU触发DMA搬运,那么外设得到的将是一个旧的数据而不是CPU最新的数据。在触发DMA搬运之前,我们需要维护cache和内存的一致性,因此使用cache clean操作,把数据刷入内存中,然后再启动DMA搬运。
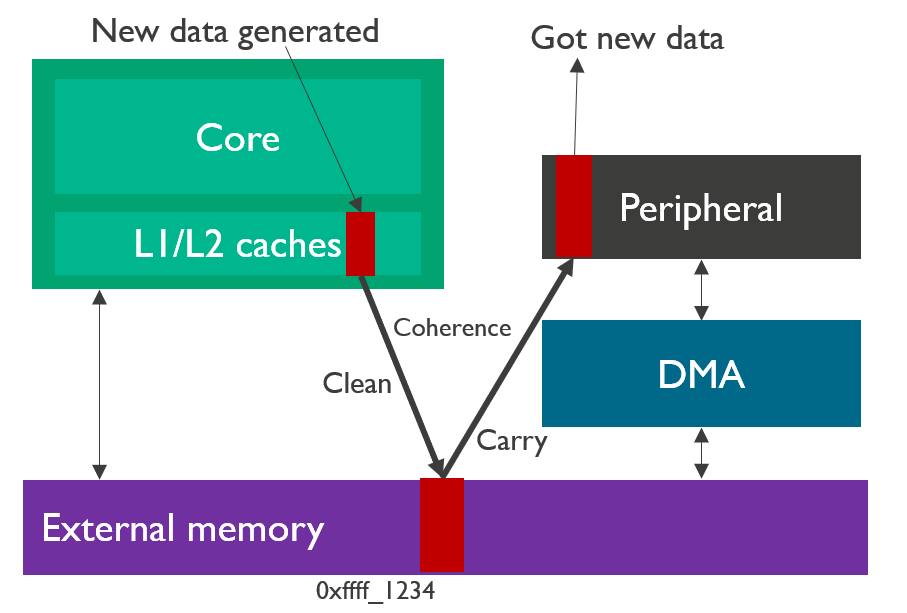
1.1.2 外设到内存
这个是上面内存到外设的逆过程。由一个外设产生的数据,数据通过DMA搬运到内存之中,如果这个时候不保证内存和cache之间的一致性,那么Core是看不到这个新数据的,也会产生一个错误的结果。因此这个时候需要进行cache维护,维护的方法就是我们让cache中的数据标记为无效,当CPU访问这个数据的时候,发现数据是无效的,就会主动从内存中load数据,这个时候CPU就会看到最新的数据了。
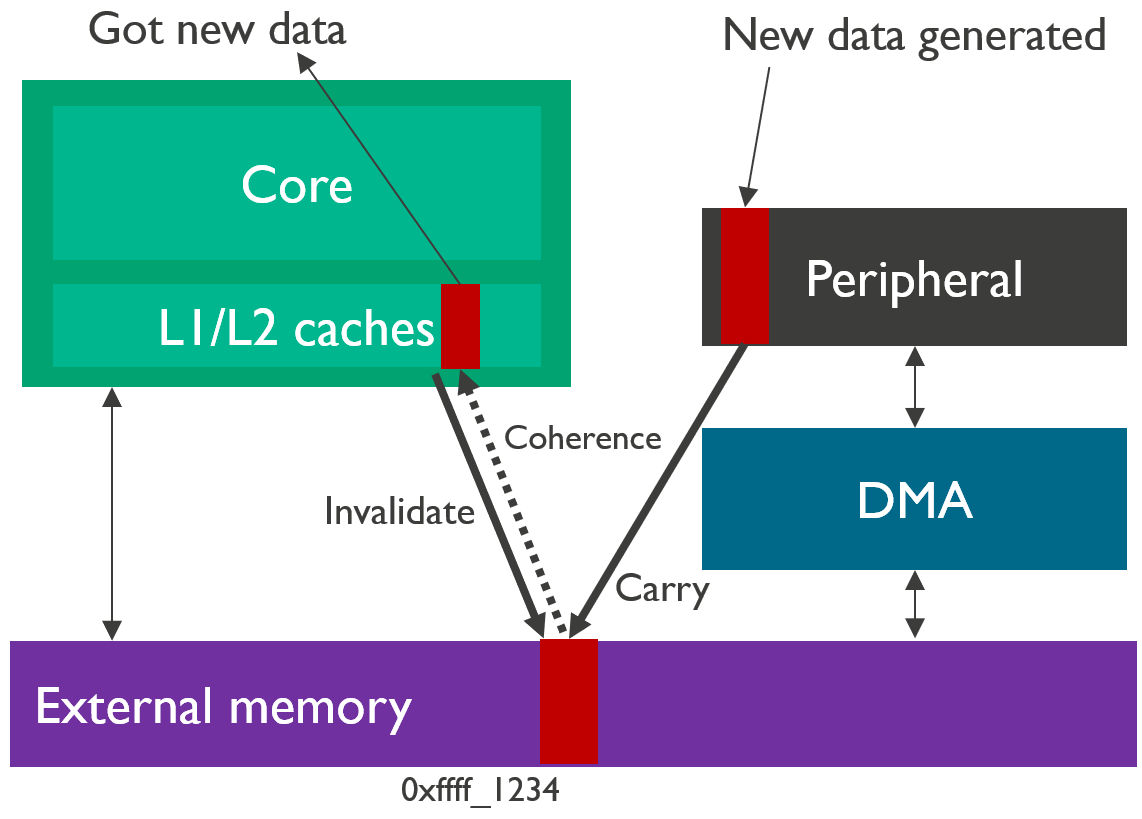
2. 多核间的一致性与cache伪共享
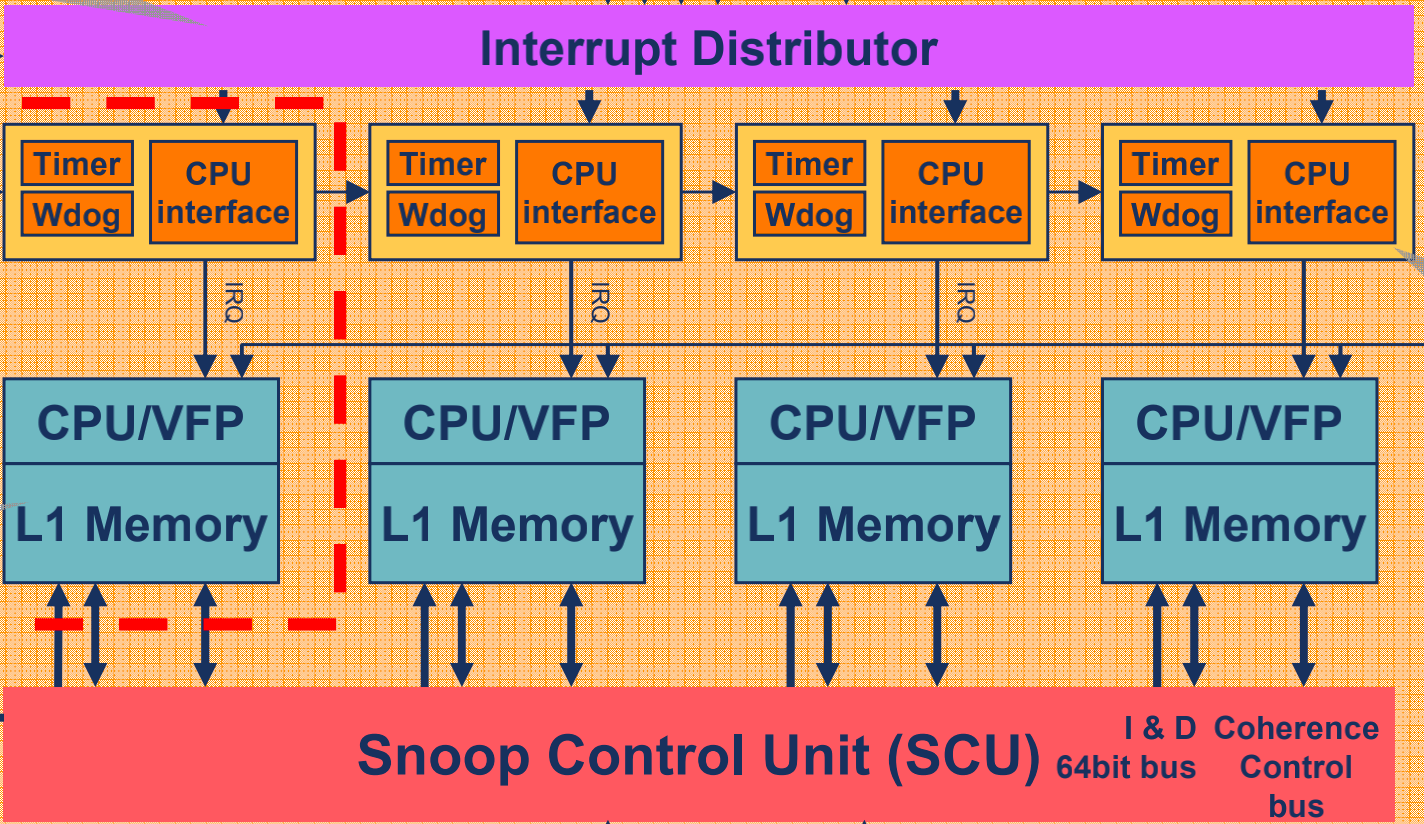
把上面的图简化为下面的图,图片来源1。多核之间一致性是属于cluster内部的,比如a72.core0和a72.core1之间的一致性问题,而不一致的地方发生在自己私有的L1 cache和共享的L2 cache上面。
2.1 MESI协议(硬件角度解决)
核间的cache保持一致性,如果依赖硬件机制的话,就是要增加SCU机制,而SCU机制使用的是MESI协议。这部分的确是设计SCU机制IP的人去做,而并非我们软件工程师的任务,但我觉得我们有必要来理解一下MESI协议的思想,当没有SCU这个机制的时候,实际上是需要我们软件工程师实现一个软件版本的精简的SCU的。MESI协议对我们理解cache的状态很有好处,所以这里也展开这个话题讨论一下(不会太细致,只是思想借鉴)。
2.1.1 snoop control unit
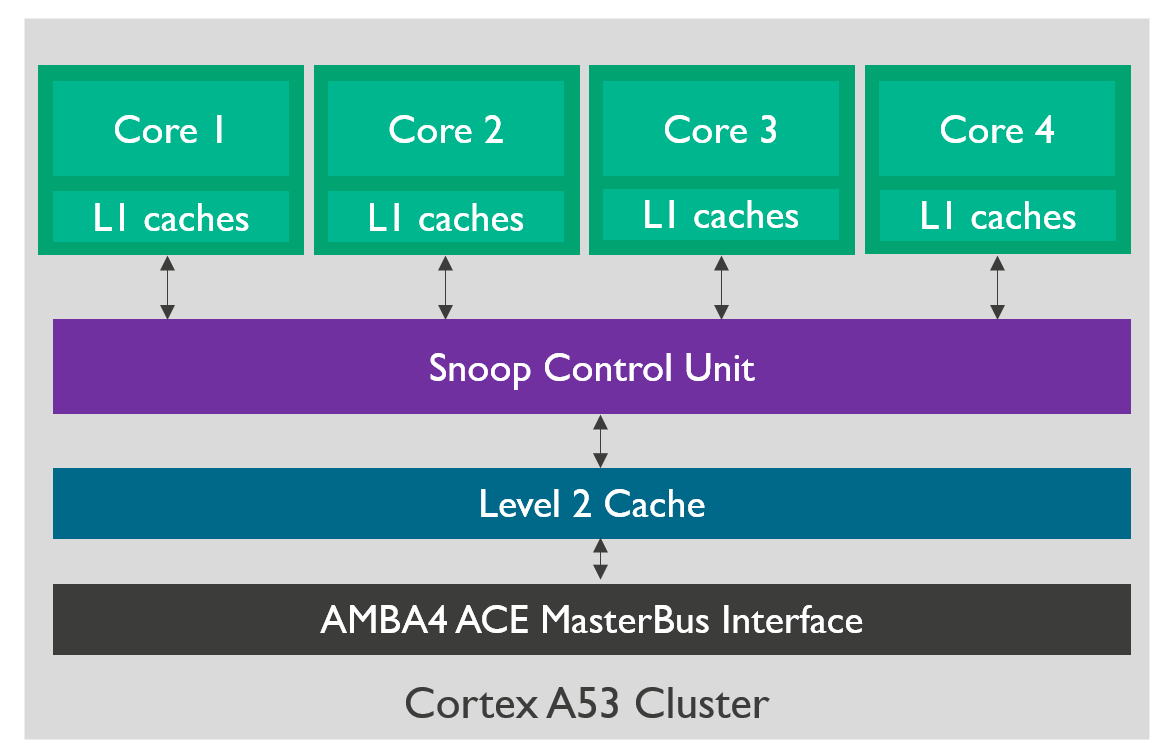
我们现在以A53 cluster为例4,展开Juno SoC上面的A53内部具体结构。A53里面分别有4个core,每个core都携带一个L1的i-cache和d-cache(在图中简化为caches),core和cache组成一个CPU;4个CPU和snoop control unit相连,SCU向北对每个cpu进行总线监听,向南和L2 cache连接,是L1 cache和 L2 cache的桥梁,SCU就是MESI协议的维护者。
2.1.2 MESI协议
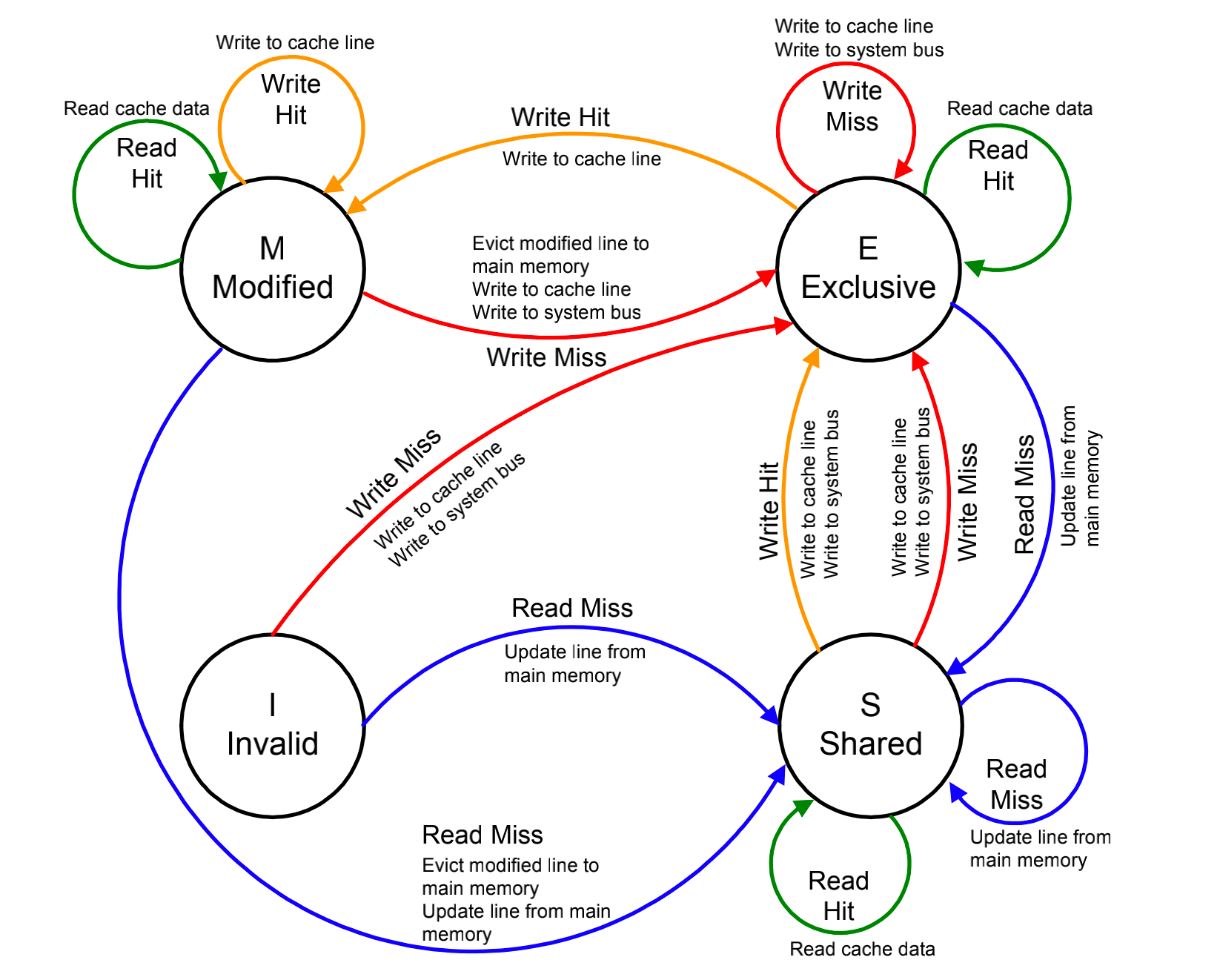
在每个cache line上面都有一个脏(dirty)和有效(valid)位,用来指示cacheline的状态,MESI协议正是利用这两个位做判断。从MESI的视角,将cacheline的数据状态分为了4类,修改,独占,共享和无效。
| 状态 | I | D | S | 解释 |
|---|---|---|---|---|
| Modified | 1 | 1 | 0 | 修改,这行数据有效,数据已经被修改,和内存数据不一致,数据只存在于私有cache中。 |
| Exclusive | 1 | 0 | 0 | 独占,这行数据有效,数据和外存中的数据一致,数据只存在于私有cache中。 |
| Shared | 1 | 0 | 1 | 共享,这行数据有效,数据和外存中的数据一致,多个私有cache中都有这个数据的副本。 |
| Invalid | 0 | 0 | 0 | 无效,这行数据无效。 |
Note, I,D,S, 代表着,invalid, dirty and shared bits
Note, I 为初始状态
CPU/SCU的一些行为会导致cache的line的状态机产生迁移,这些行为一部分是CPU的操作,也有一部分是SCU的操作,可分为:
| 操作类型 | 中文 | 解释 |
|---|---|---|
| Local Read/PrRd | 本地读 | 本地CPU读取cacheline数据 |
| Local Write/PrWr | 本地写 | 本地CPU更新cacheline数据 |
| Bus Read/BusRd | 总线读 | 总线监听到一个来自其他CPU读缓存的请求。 |
| Bus Write/BusWr | 总线写 | 总线监听到一个来自其他CPU写cacheline的请求。 |
| BusUpgr | 总线更新 | 总线监听到一个来自其他CPU的更新请求。 |
| Flush | 刷新 | 总线监听到一个来自其他CPU的要求把自己的数据刷到内存的请求。 |
| FlushOpt | 刷新到总线 | 总线监听到一个来自其他CPU的要求把自己私有cachline的内容发到其他cpu的操作。 |
busrd和buswr的操作总是要求目标cpu有应答操作。状态迁移如下5:
2.2 false sharing -> cache thrashing
我们在上一篇文章中有降到cache的thrashing的问题,那是在单核的情况下,由于cache的way的数量小于同一时刻运算vetor的数量,导致的cache数据频繁无缓存的访问。我们在这里再提一个MPCore下导致cache thrashing的问题,这是因引入了cache coherence机制SCU导致的。
我们定义全局结构体:
struct data {
long x;
long y;
long z;
....
} mdata;mdata两个数据被core 1和core 2频繁访问,假设我们mdata.x变量总是被core1访问,mdata.y被core2访问,如果我们使用了SCU硬件来维持core和core之间的一致性,那就会出现问题了,一致性机制会频繁的刷cache和外存,就导致了数据是被无缓存的访问,产生了thrashing的问题。根据SCU的协议的工作原理,每一次core切换访问的时候,都会向总先发sharing的请求,每次发现数据不一致都回被标记无效,结果每一次都需要从内存中读取最新的数据,这个就被称为伪共享的问题(false sharing)。
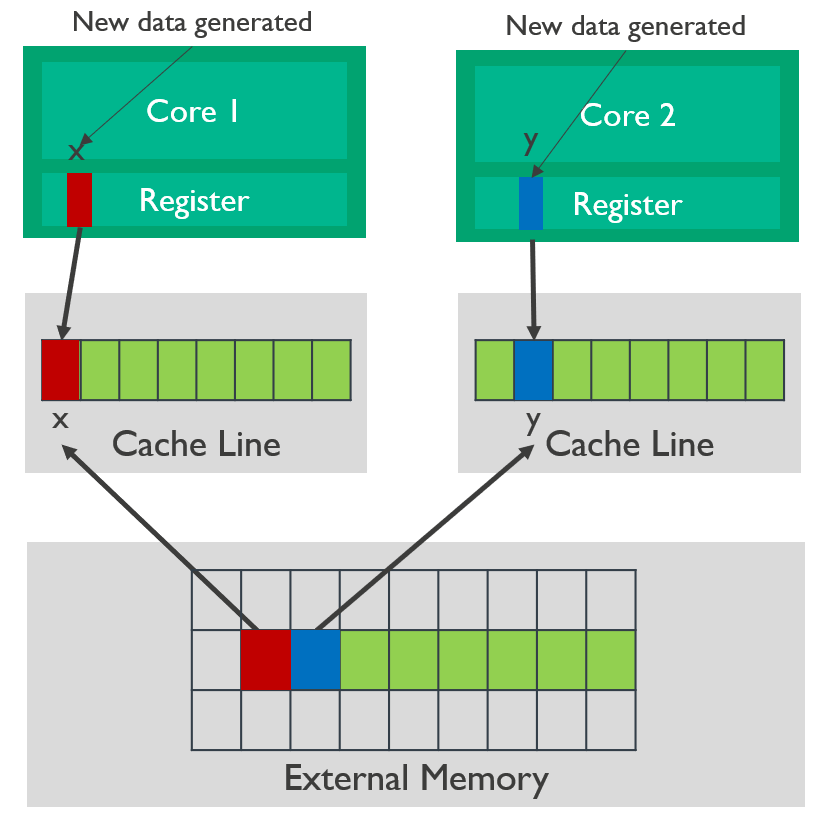
解决这个问题,本质是让多核访问的数据处于不同的cache line中,可以通过padding技术或者cache align,让数据结构和cache line对齐,并尽可能填充满一个L1 cache line的大小。
比如,例子1:
typedef struct counter_s {
uint64_t packets; // +8bytes = 8bytes
uint64_t bytes; // +8bytes = 16bytes
uint64_t failed_packets; // +8bytes = 24bytes
uint64_t filed_bytes; // +8bytes = 32bytes
uint64_t pad[4]; // +4*8 bytes = 64 bytes = sz_cacheline
} counter_t __attribute__(__aligned__((64)));例子2:
#define cacheline_aligned __attribute__((aligned_(L1_CACHE_BYTES)));
struct zone_padding {
char x[0];
} cacheline_aligned;
struct zone {
...
spinlock_t lock; // 放在第一个cacheline
struct zone_padding pad2;
spinlock_t lru_lock; // 放在第二个cacheline
....
} cacheline_aligned;2.3 non-aligned问题
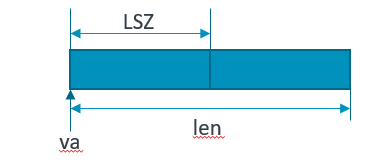
上面讲述了一些都是关于cache对齐的操作,那么如果在cacha没有对齐的情况下,那么使用cache的维护指令那么要十分的小心。我们来看一个最基本的场景,假设我们的buffer并没有cache line对齐,这里的例子是横跨了3个cache line:
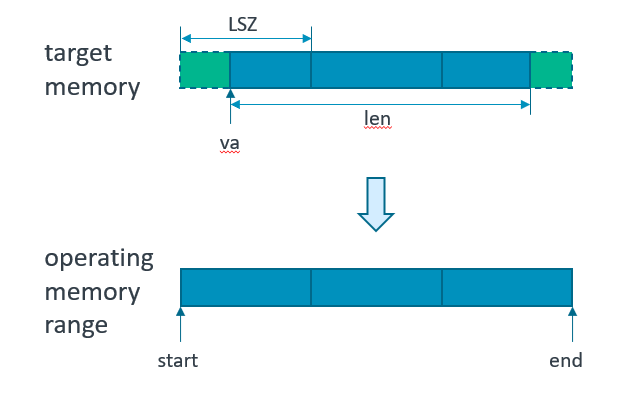
如果我们要做clean/invalidate/flush(va, len)这个三个操作,那么实际上会发生:
- start = ROUND_DOWN(va, LSZ);
- end = ROUND_UP(va + len, LSZ);
实际操作的地址,扩大到了,cacheline大小,而这样的情景就产生了一定的危险性——我们操作了别人的数据。
我们现在站在一个driver的角度,在结构上面driver是AXI总线外的一个模块,现在操作CPU想保持driver的buffer的一致性。对于输入driver的数组我们成为input buffer,对于从driver里面修改吐出的数据的buffer,我们称为output buffer。

我们从output和input buffer的角度来看一下cache维护引发的问题:
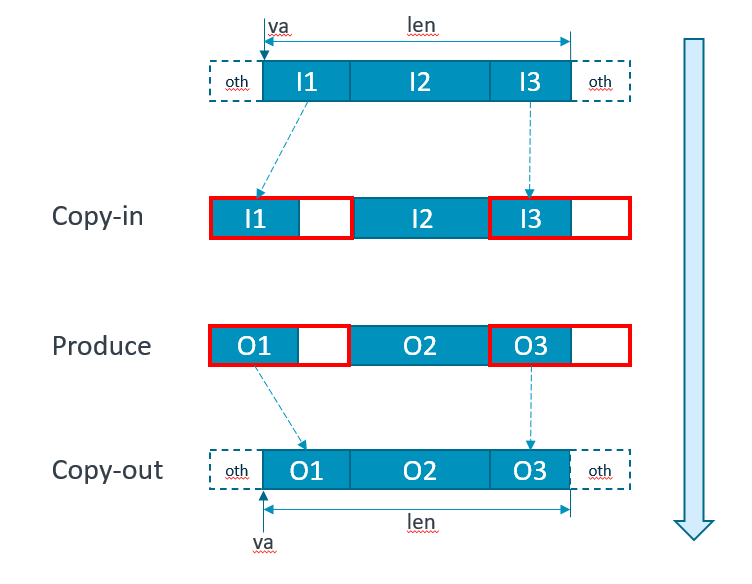
补救方法一:使用更复杂的cache维护操作
| Full line | incomplete line |
|---|---|
 |
 |
| input momory 1. cpu_write(va, len) 2. cache_clean(va, len) 3. driver_consume(va, len) 使用cpu直接对数组进行访问,接着使用cache_clean把数据从cache里面驱逐出去写入到内存中,最后driver看到的数据和cpu看到的一致,可以进行运算。 |
input momory 1. cpu_write(va, len) 2. cache_clean(va, len) 3. driver_consume(va, len) 和完整的line是一致的,但是这样做是有风险的,如果oth位置的数据被标记为脏位,使用clean的话会清除掉drity位,MESI的修改状态被破坏,成为独占或者共享,那么数据就丢了。 |
| output momory 1. driver_produce(va, len) 2. cache_invalidate(va, len) 3. cpu_read(va, len) driver先产生数据,cache对va这个地址标记为无效,cpu看到va地址无效之后,会从内存中重新load数据进cache,最后cpu从cache中拿到driver想要的数据。 |
output momory 1. cache_flush(va, len) 2. driver_produce(va, len) 3. cache_invalid(va, len) or cache_flush 4. cpu_read(va_len) 这样也是有风险的,比如在1之后cpu修改了oth;有一些脏数据flush,或者如果invalid数据会丢失 |
| inout momory 1. cpu_write(va, len) 2. cache_clean(va, len) 3. con_and_prod(va, len) 4. cache_invalidate(va, len) 5. cpu_read(va, len) |
inout momory 1. cpu_write(va, len) 2. cache_flush(va, len) 3. con_and_prod(va, len) 4. cache_invalidate(va, len) or flush() 5. cpu_read(va, len) 结合了input和output的风险。 |
补救方法二:手动cache line强制对齐
使用cache维护无论怎样都是存在风险的,如果不完整的line出现在了头部或者尾部,我们也可以这样做:
- 准备一个中间介质的对齐数据可以用 osal_malloc_aligned()分配。
- 把没有对齐的部分放在临时buffer的头部,尾部同样
- 运算完成之后再还原回来。
use scatter gather DMA buffer
Driverjust needs to handle the start and end mis-aligned cases for memory coherencyconsideration, while assuming the middle entries shall be full page orexclusive buffer.
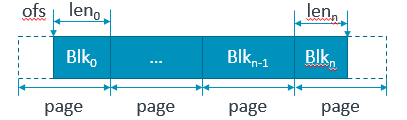
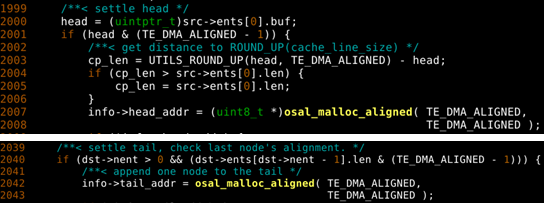
补救方法三:手动cache line强制对齐
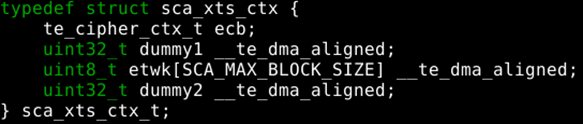
use stack/struct memory for DMA output
The output buffer MUST exclusively occupy one or more cache lines.

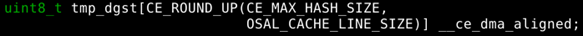
2.4 self-modifying software
一般情况下,i-cache和d-cache是分开的。i-cache仅仅具备只读属性。指令代码是不允许被修改的,但是这里有个特例,就是自修改代码(self-modifying)可能会存在修改代码区域的情况。自修改代码是一种代码行为,当代码执行时修改它自身的指令。如下用途:
- 防止被破解。隐藏重要代码,防止反编译。
- GDB调试的时候,可能采用自修改的方法来动态的修改程序。
手册6 3.2.3 Instruction cache validity 中介绍,ARM946E-S的处理器没有硬件处理的snooping单元。因此,如果写入自修改代码的时候,在指令cache中的数据会和外存不一致。还有一种可能性就是cacheable and non-cacheable的非对称共享内存,如果我们重新编写了保护的区域,代码可能存在一个应该处于noncachable的区域的cache中。在这种情况下,我们必须flush指令cache。
解决自修改代码引入的cache不一致的问题使用cache维护指令和内存屏障的指令联合使用。比如下面代码片段中,假设X0寄存器存储了代码段的地址,通过STR指令把新的指令数据W1写入X0寄存器来实现修改代码的功能。
str w1, [x0] // 通过STR修改代码指令
dc cavu, x0 // 使用DC指令清理操作,把X0寄存器中地址对应的cache中的数据writeback内存
dsb ish // 使用DSB指令保证其他观察者看到的cache的清理操作已经完成
ic ivau, x0 // 使X0寄存器中地址对应的cacheline失效
dsb ish // 使用dsb指令确保其他观察者看到失效操作已经完事
isb // 使用ISB指令让程序重新预取指令2.5 其他一致性问题
-
cache一致性引发的安全问题,攻击者利用cache一致性进行攻击。Are Coherence Protocol States Vulnerable to Information Leakage?7
-
Secvs NS, cacheable vs non-cacheable 引发的cache一致性问题8。
CPU state | Memory | DMA access | Result -----------+------------+------------+-----------+ non-secure | non-secure | non-secure | OK non-secure | non-secure | secure | NG non-secure | secure | - | NA secure | non-secure | non-secure | OK secure | non-secure | secure | NG (Same reason as the second case) secure | secure | non-secure | NA secure | secure | secure | OK
3. Ref
Footnotes
-
cd00225773-stm32f205xx-stm32f207xx-stm32f215xx-and-stm32f217xx-advanced-armbased-32bit-mcus-stmicroelectronics ↩
-
Intel® Stratix® 10 Hard Processor System Technical Reference Manual 3.3. Cortex-A53 MPCore Block Diagram ↩
-
TEACHING THE CACHE MEMORY COHERENCE WITH THE MESI PROTOCOL SIMULATOR ↩
-
can-coherency-issue-happen-between-secure-dma-and-non-secure-cpu-on-trustzone-sy ↩
-
Are Coherence Protocol States Vulnerable to Information Leakage? ↩
Metadata
Metadata
Assignees
Projects
Status