A startup called Sparkify wants to analyze the data they've been collecting on songs and user activity on their new music streaming app. The analytics team is particularly interested in understanding what songs users are listening to. They decide to implement a data warehouse on AWS cloud.
The data resides in S3. The ETL pipeline extracts the data from S3 and stages them in Redshift, transform them and load them into a star schema optimized for queries on song play analysis. This includes the following tables.
Stage Table
- StagEvents - load data directly from log data folder using COPY clouse
- artist, auth, firstName, gender, itemInSession, lastName, length, level,
- location, method, page, registration, sessionId, song, stats, ts, userAgent, userId
- StagSongs - load data directly from songs data folder using COPY clouse
- songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent
Fact Table
- songplays - records in log data associated with song plays i.e. records with page NextSong
- num_songs, artist_id, artist_latitude, artist_longitude, artist_location,
- artist_name, song_id, title, duration, year
Dimension Tables
- users - users in the app
- ser_id, first_name, last_name, gender, level
- songs - songs in music database
- song_id, title, artist_id, year, duration
- artists - artists in music database
- artist_id, name, location, latitude, longitude
- time - timestamps of records in songplays broken down into specific units
- start_time, hour, day, week, month, year, weekday
The song dataset is place in S3 bucket s3://udacity-dend/song_data. It is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song's track ID. For example, here are filepaths to two files in this dataset.
song_data/A/B/C/TRABCEI128F424C983.json
song_data/A/A/B/TRAABJL12903CDCF1A.json
And below is an example of what a single song file, TRAABJL12903CDCF1A.json, looks like
{"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
The log dataset is place in S3 bucket s3://udacity-dend/log_data.This dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations.
The log files in the dataset you'll be working with are partitioned by year and month. For example, here are filepaths to two files in this dataset.
log_data/2018/11/2018-11-12-events.json
log_data/2018/11/2018-11-13-events.json
And below is an example of what the data in a log file, 2018-11-12-events.json, looks like.
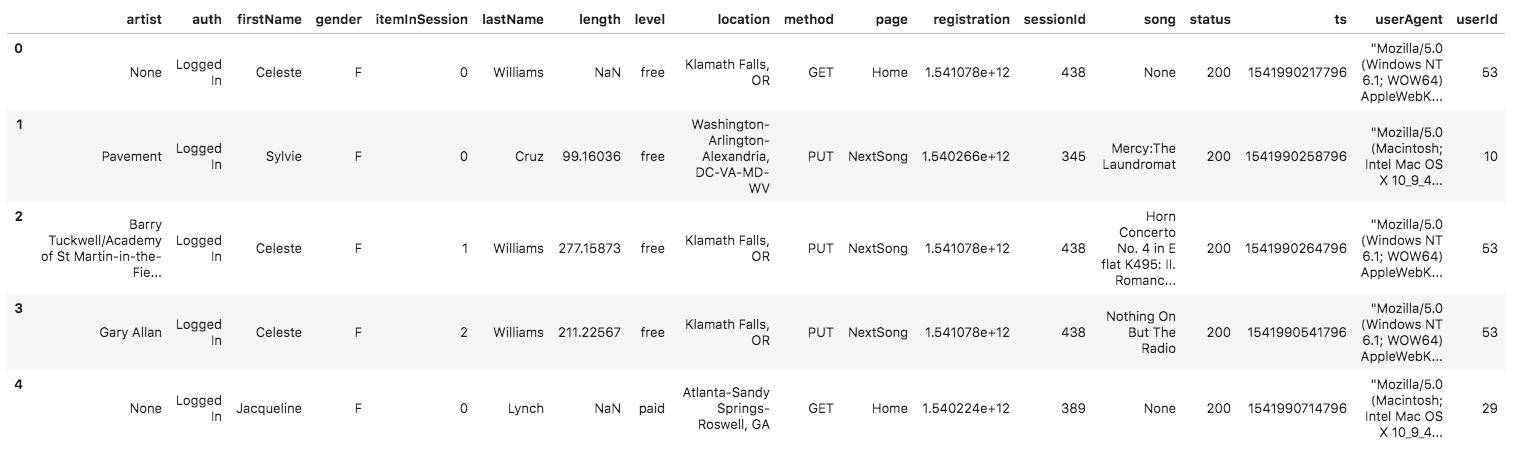
Because the json file contains a list of json records, for the COPY clause to work properly, a json path file represent the json schema is prepared in the S3 bucket s3://udacity-dend/log_json_path.json.
The database is implemented with PostgreSQL queries, and the data process part was completed using Python.
Run create_tables.py to create all the tables.
StagEvents and StagSongs
StagSongs table is loaded directly from song_data bucket with COPY clause. StagEvents table is loaded directly from log_data bucket. Since json file contains a list of json records, a json path is provided in a seperate bucket.
DimSongs and DimArtists tables
Use INSERT INTO target_table SELECT FROM source_table method to load data from StagSongs table.
DimTime table
Use EXTRACT method to extract hour, day and other parameters from ts column in StagEvents table.
DimUsers table
Use INSERT INTO target_table SELECT FROM source_table method to load data from StagEvents table.
FactSongPlays table
The log data only contain song name, artist name and song length. To get the songid and artistid, the StagEvents table is left joined with StagSongs table using song name, artist name and song length, and the results are inserted to FactSongPlays table.
dwh.cfg file contains all the parameters nessery for the cluster. Make sure you fill in your own RedShift cluster for HOST and IAM role for ARN. sql_queries.py file contains all the sql queries for create, insert and drop all the tables, it will be imported to create_tables.py and etl.py file. create_tables.py contains the code to create all the tables, and it can be run using python create_tables.py method in project folder. etl.py contains all the code for the etl process, and it can be run using python create_tables.py method in project folder. test.ipynb file can be run by jupyter notebook to query all the generated tables.
Implement new design to incrementally load data from S3 to Redshift.