Partitioned Distinct/DistinctCount #10499
Description
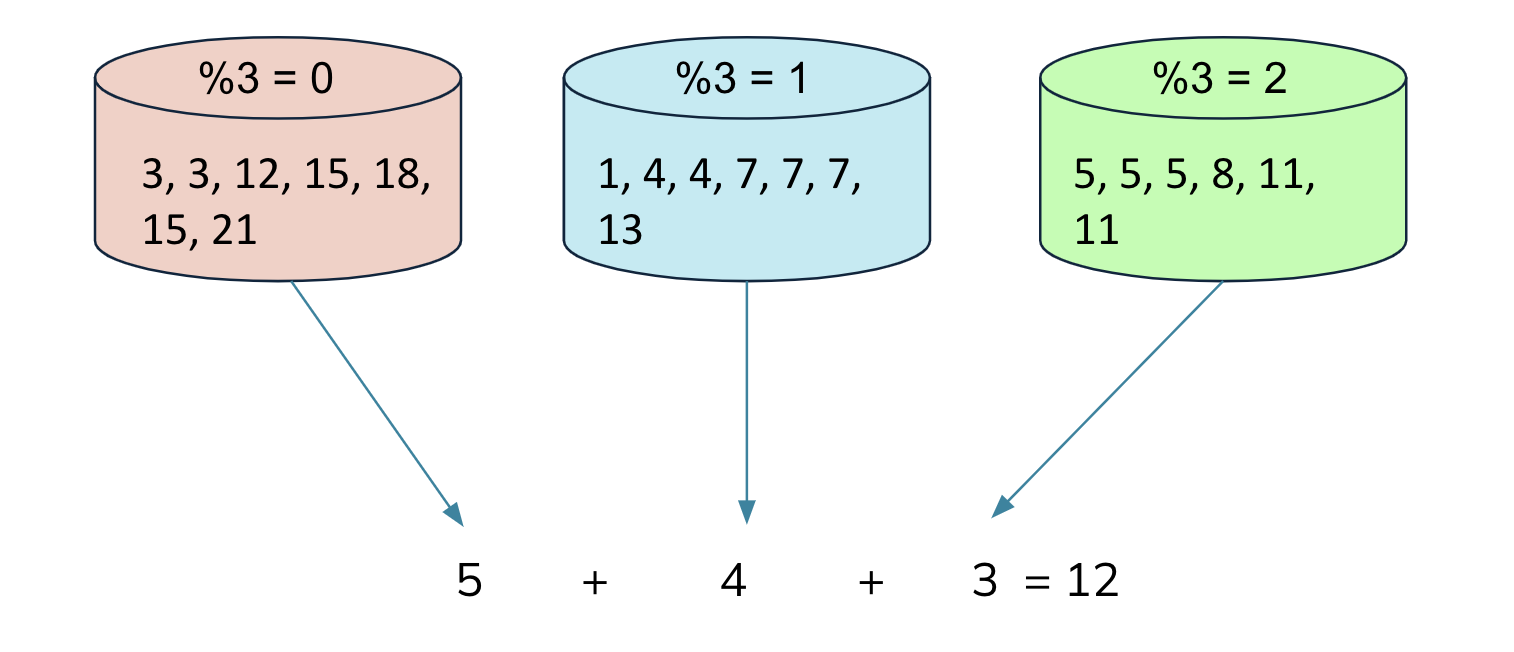
For high cardinality columns, the local/intermediate/global merging phase of distinct(count) can be pretty memory/cpu heavy as the merger will need to ser/de and merge multiple large sets from the responses. In this case, if the distinct(count) column is partitioned into disjoint sets, then the merger can simply concat (for distinct) or add (for distinctcount) the intermediate results. This change can significantly reduce the set ser/de, transmission, and merge time/memory footprint. Meanwhile, it can be applicable to different levels of the processing depending on the partition granularity.