NIFI-4239 - Adding CaptureChangePostgreSQL processor to capture data changes (INSERT/UPDATE/DELETE) from PostgreSQL tables via Logical Replication API #6053
Conversation
|
@joewitt @mattyb149 @exceptionfactory Hey guys, this is the new PR for NIFI-4239 (CaptureChangePostgreSQL processor). Sorry for the mess in #5710 =/ Please, run the workflow. Thanks! |
|
Now,after two year's!!! We will go on? I believe!!!! |
There was a problem hiding this comment.
Thanks for updating and preparing the new PR @davyam. Other reviewers are probably in a better position to evaluate some of the functionality, but I provided a few comments on style and functionality.
At a high-level, on particular question concerns the use of JSON as the output format, and one message per FlowFile. For high-volume processing, the ability to combine multiple records in a single FlowFile allows for much higher throughput. As mentioned in the detailed comments, adding support for a RecordWriter service would also make the output much more flexible, supporting JSON as well as other types.
| <dependency> | ||
| <groupId>org.slf4j</groupId> | ||
| <artifactId>slf4j-simple</artifactId> | ||
| <scope>test</scope> | ||
| </dependency> | ||
| <dependency> | ||
| <groupId>junit</groupId> | ||
| <artifactId>junit</artifactId> | ||
| <scope>test</scope> | ||
| </dependency> |
There was a problem hiding this comment.
These dependencies can be removed since there are included by default in the root Maven configuration.
| message.put("originLSN", buffer.getLong(1)); | ||
|
|
||
| buffer.position(9); | ||
| byte[] bytes_O = new byte[buffer.remaining()]; |
There was a problem hiding this comment.
Use of the underscore character should be avoided in variable names.
| byte[] bytes_O = new byte[buffer.remaining()]; | |
| byte[] origin = new byte[buffer.remaining()]; |
| buffer.position(0); | ||
| byte[] bytes_R = new byte[buffer.capacity()]; | ||
| buffer.get(bytes_R); | ||
| String string_R = new String(bytes_R, StandardCharsets.UTF_8); |
There was a problem hiding this comment.
| String string_R = new String(bytes_R, StandardCharsets.UTF_8); | |
| String relationDefinition = new String(bytes_R, StandardCharsets.UTF_8); |
| position += 4; | ||
|
|
||
| buffer.position(0); | ||
| byte[] bytes_Y = new byte[buffer.capacity()]; |
There was a problem hiding this comment.
| byte[] bytes_Y = new byte[buffer.capacity()]; | |
| byte[] type = new byte[buffer.capacity()]; |
| buffer.position(0); | ||
| byte[] bytes_Y = new byte[buffer.capacity()]; | ||
| buffer.get(bytes_Y); | ||
| String string_Y = new String(bytes_Y, StandardCharsets.UTF_8); |
There was a problem hiding this comment.
| String string_Y = new String(bytes_Y, StandardCharsets.UTF_8); | |
| String typeDefinition = new String(bytes_Y, StandardCharsets.UTF_8); |
| if (this.replicationReader == null || this.replicationReader.getReplicationStream() == null) { | ||
| setup(context); | ||
| } |
There was a problem hiding this comment.
This null check and call to setup() does not appear to be thread safe. Did you consider annotating the setup() method with OnScheduled instead of this approach?
| continue; | ||
| } | ||
|
|
||
| String data = this.replicationReader.convertMessageToJSON(message); |
There was a problem hiding this comment.
Rather than hard-coding this implementation to JSON, this would be a good opportunity to introduce a RecordWriter Service property. That would support writing messages as JSON, or any number of other supported Record formats. Using a record-oriented approach would also make the flow design much more efficient, allowing multiple messages to be packed into a single FlowFile.
| session.transfer(listFlowFiles, REL_SUCCESS); | ||
|
|
||
| this.lastLSN = this.replicationReader.getLastReceiveLSN(); | ||
|
|
||
| // Feedback is sent after the flowfiles transfer completes. | ||
| this.replicationReader.sendFeedback(this.lastLSN); | ||
|
|
||
| updateState(context.getStateManager()); |
There was a problem hiding this comment.
The current ProcessSession implementation does not actually transfer FlowFiles until the Session is committed. It looks like this should be adjusted to use ProcessSession.commitAsync() with a callback to send feedback and update the state after a successful commit.
| @OnShutdown | ||
| public void onShutdown(ProcessContext context) { | ||
| try { | ||
| // In case we get shutdown while still running, save off the current state, | ||
| // disconnect, and shut down gracefully. | ||
| stop(context.getStateManager()); | ||
| } catch (CDCException ioe) { | ||
| throw new ProcessException(ioe); | ||
| } | ||
| } |
There was a problem hiding this comment.
Is there a reason for this method in addition to OnStopped? As indicated in the documentation, it is not guaranteed that this method will be called, and in general OnStopped should be sufficient since it is doing the same thing.
| } | ||
| } | ||
|
|
||
| private static class DriverShim implements Driver { |
There was a problem hiding this comment.
Is there a particular reason for using this DriverShim wrapper?
|
@exceptionfactory thanks for review! I'll check all suggestions and apply the necessary adjustments as soon as possible. About the RecordWriter Service, you're right, there are many benefits, but we see that isn't essential for now. There are a lot of processors that don't use services yet. So, as this improvement requires lots of change, we'll leave that for a future processor's version. |
Thanks for the reply @davyam. Although record-oriented support may not be required in some cases, introducing this processor without support for a RecordWriter would lock in support for the JSON-specific output. Understanding that it requires some changes, and that a lot of work has already gone into this component, it is also important to consider community maintainability. Components designed for more narrow use cases are difficult to maintain over time, so that's why it can be more difficult to introduce new components. Generating large numbers of small FlowFiles leads to poor flow performance, so that's why it is more important to implement that capability initially, as opposed to introducing it later. If you need some assistance on integration with record handling, perhaps this could be an opportunity for additional collaboration on this PR. |
@exceptionfactory I understand. OK, I'll analyze the effort required to use the RecordWriter Service. |
|
I have a problem. I have a clean nifi running through docker, JVM memory settings Initially, docker stat displays: But as soon as I start the process for a table weighing 370 MB, docker stat displays: And also I'm starting to get the error: Java heap space Here are the settings of my process: |




| <dependency> | ||
| <groupId>org.postgresql</groupId> | ||
| <artifactId>postgresql</artifactId> | ||
| <version>42.3.3</version> | ||
| </dependency> |
There was a problem hiding this comment.
Reviewing this dependency, given that the processor has a property for the driver location, either this dependency should be marked as provided, or the property can be removed. It seems best to avoid including this library in the NAR to support more runtime flexibility.
There was a problem hiding this comment.
Agreed, I think we should keep the property and remove this JAR from the NAR so we can support maximum compatibility across past, present, and future versions of PostgreSQL without having to maintain/update the version of the JDBC driver across releases.
Hey, @djshura2008 you are using a previous CaptureChangePostgreSQL processor version, maybe from PR 4065. I know that because we don't have anymore the "Take a initial snapshot?" property. Since then, a lot of improvements was done, so please repeat the tests with the last version. Thanks for your support. |
Okay, but how do you take an initial snapshot of database and immediately start the cdc process? |
There were several problems with the snapshot (delay, memory, etc.). Then, we decided to remove this option when the code was refactored. Our goal is to capture the changes. But you still can do that with a backup/dump/copy before start the processor. |
|
Hi @davyam - May I know that when we can expect the "CaptureChangePostgreSQL" processor in actual released version of Nifi. We have some requirement where we need to use this feature of Nifi. Thank you. |
Hi @MaheshKungaria, we expect to complete the improvements requested by reviewers until the end of the year. So, we believe that in the NiFi v1.19 our processor will be there. |
|
Thanks for the confirmation @davyam |
|
Hi @davyam - We need Nifi CapctureChangePostgreSQL processor for one of our requirement and we checked version 1.19 doesn't have it. May I know by when we can get a stable processor of CapctureChangePostgreSQL |
|
Hey @MaheshKungaria if it's urgent for you: I build the processor, so you can try it out by putting the nar file into your lib folder. |
|
Hey guys, we are a little late, I know, other personal activities get in the way, but I'm still working on the improvements. ASAP we will have the CapctureChangePostgreSQL processor in NiFi. Best regards |
|
Hi @davyam: We need Nifi CapctureChangePostgreSQL processor for one of our requirements. I have gone by above comments, I understand you are busy in other activities as well. But can you please share any tentative date by when we can get a stable processor of CapctureChangePostgreSQL |
@shilpaprotiviti if the processor is so urgent for you: I build and uploaded the NAR directly here. So, you can download and use the processor. :) |
Thanks @janis-ax for your support! |
|
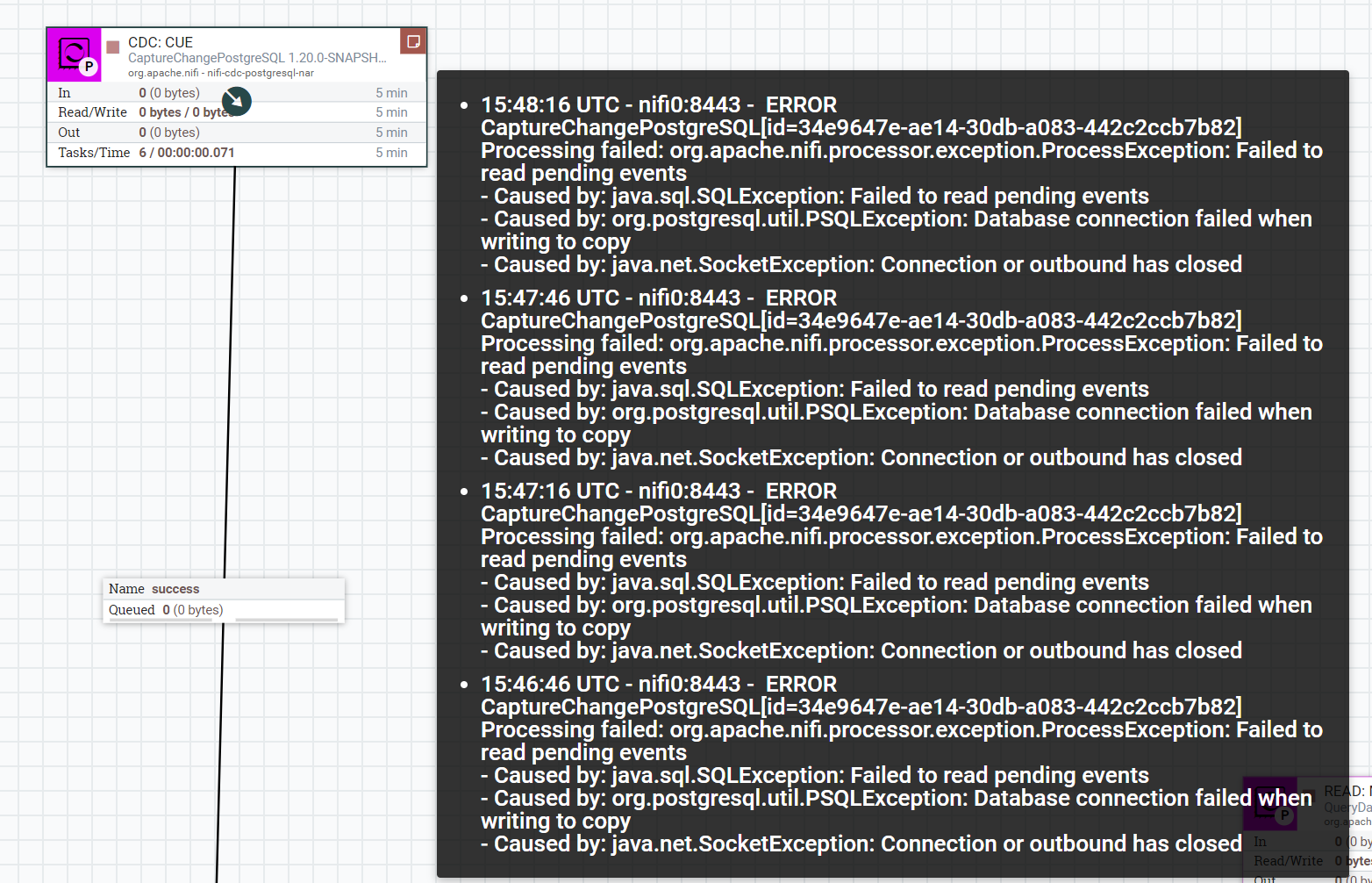
@davyam thanks for all your work on this. I am using the NAR that @janis-ax helped build and I keep losing connection to my server. This usually happens after the processor has been running for a while with no active changes. When I stop, re-enter the DB server password, and start the server then the error goes away. Do you know what could be going on or how I can resolve this? Also, should we expect a stable official version any time soon?
|

|
Hello @martinson,
this is happening because of the logical process of logical replication on
postgresql... If you see on DEBEZIUM Kafka connect, have same problem...
The workaround is create a table with only one row and send a update on row
changing datetime for example...
This is happening generally on PostgreSQL RDS... Is this your case ?
You can send that update in the minute-by-minute solution table, for
example.
…--
*Gerdan Rezende dos Santos*∴
Cloudera, Hortonworks, PostgreSQL - Support, Training & Services
+55 (61) 996 451 525
On Fri, May 19, 2023 at 12:51 PM Martinson Ofori ***@***.***> wrote:
@davyam <https://github.com/davyam> thanks for all your work on this.
I am using the NAR that @janis-ax <https://github.com/janis-ax> helped
build and I keep losing connection to my server. This usually happens after
the processor has been running for a while with no active changes. When I
stop, re-enter the DB server password, and start the server then the error
goes away.
Do you know what could be going on or how I can resolve this? Also, should
we expect a stable official version any time soon?
[image: image]
<https://user-images.githubusercontent.com/48808182/239577713-74cd0165-bb7d-4269-b80b-284d1759f1cc.png>
—
Reply to this email directly, view it on GitHub
<#6053 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AD5RGGZ4OOHMAWKZIM4JVZ3XG6JIZANCNFSM5WGR6OMA>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
{kind=link}
Thank you @gerdansantos , tried this yesterday and had a few issues but couldn't spend more time due to some other production issues I have. In principle, I think this solution should work. I will test and feedback with some more concrete result sometime early tomorrow. Thanks. |
By the way, I agree with this. After testing this for some time, enhancements can definitely be made to improve the performance and scalability of this processor. The current one-record-per-FlowFile approach is very slow for bulk operations; say delete/update say 100K+ records. Some sort of batching strategy here could be particularly useful for high-volume database operations, helping to maximize throughput and address potential performance issues as @exceptionfactory has mentioned. |
|
This pull request has generated a lot of helpful feedback and interest, but given the current fundamental issues with lack of event batching and some design concerns with event decoding, there are some significant areas to address. Additional discussion can be continued on the associated Jira issue NIFI-4239. The Jira issue is a better place to continue the discussion until this pull request can be revisited or restarted. Given the lack of code changes in the last year, I am closing this pull request for now. This pull request can be reopened when ready, or a new pull request that addresses the current issues is another option. |
NIFI-4239 - Adding CaptureChangePostgreSQL processor to capture data changes from PostgreSQL tables via Logical Replication API
Authors:
Davy Machado machado.davy@gmail.com
Gerdan Santos gerdan@gmail.com
Thank you for submitting a contribution to Apache NiFi.
Please provide a short description of the PR here:
Description of PR
The CaptureChangePostgreSQL processor retrieves Change Data Capture (CDC) events from a PostgreSQL database. Works for PostgreSQL version 10+. Events include INSERT, UPDATE, and DELETE operations and are output as individual flow files ordered by the time at which the operation occurred. This processor uses a Logical Replication Connection to stream data and a SQL Connection to query system views.
This new pull request builds upon the PR #5710.
In order to streamline the review of the contribution we ask you
to ensure the following steps have been taken:
For all changes:
Is there a JIRA ticket associated with this PR? Is it referenced
in the commit message?
Does your PR title start with NIFI-XXXX where XXXX is the JIRA number you are trying to resolve? Pay particular attention to the hyphen "-" character.
Has your PR been rebased against the latest commit within the target branch (typically
main)?Is your initial contribution a single, squashed commit? Additional commits in response to PR reviewer feedback should be made on this branch and pushed to allow change tracking. Do not
squashor use--forcewhen pushing to allow for clean monitoring of changes.For code changes:
mvn -Pcontrib-check clean installat the rootnififolder?LICENSEfile, including the mainLICENSEfile undernifi-assembly?NOTICEfile, including the mainNOTICEfile found undernifi-assembly?.displayNamein addition to .name (programmatic access) for each of the new properties?For documentation related changes:
Note:
Please ensure that once the PR is submitted, you check GitHub Actions CI for build issues and submit an update to your PR as soon as possible.