The Unreasonable Effectiveness of Deep Features as a Perceptual Metric (Apr 2018 CVPR) #5
Description
0. Article Information and Links
- Paper link: http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhang_The_Unreasonable_Effectiveness_CVPR_2018_paper.pdf
- Release date: YYYY/MM/DD
- Number of citations (as of 2020/MM/DD):
- Implementation code: Official PyTorch 1.0 Implementation on GitHub
- Supplemental links (e.g. results):
- Publication: Conference YYYY
1. What do the authors try to accomplish?
Create a tool that judges image similarity closer to humans than traditional math-based approaches such as SSIM
2. What's great compared to previous research?
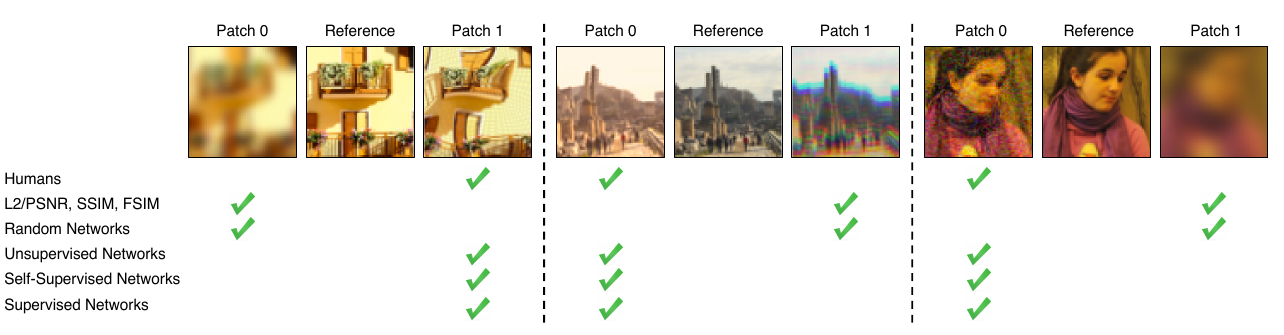
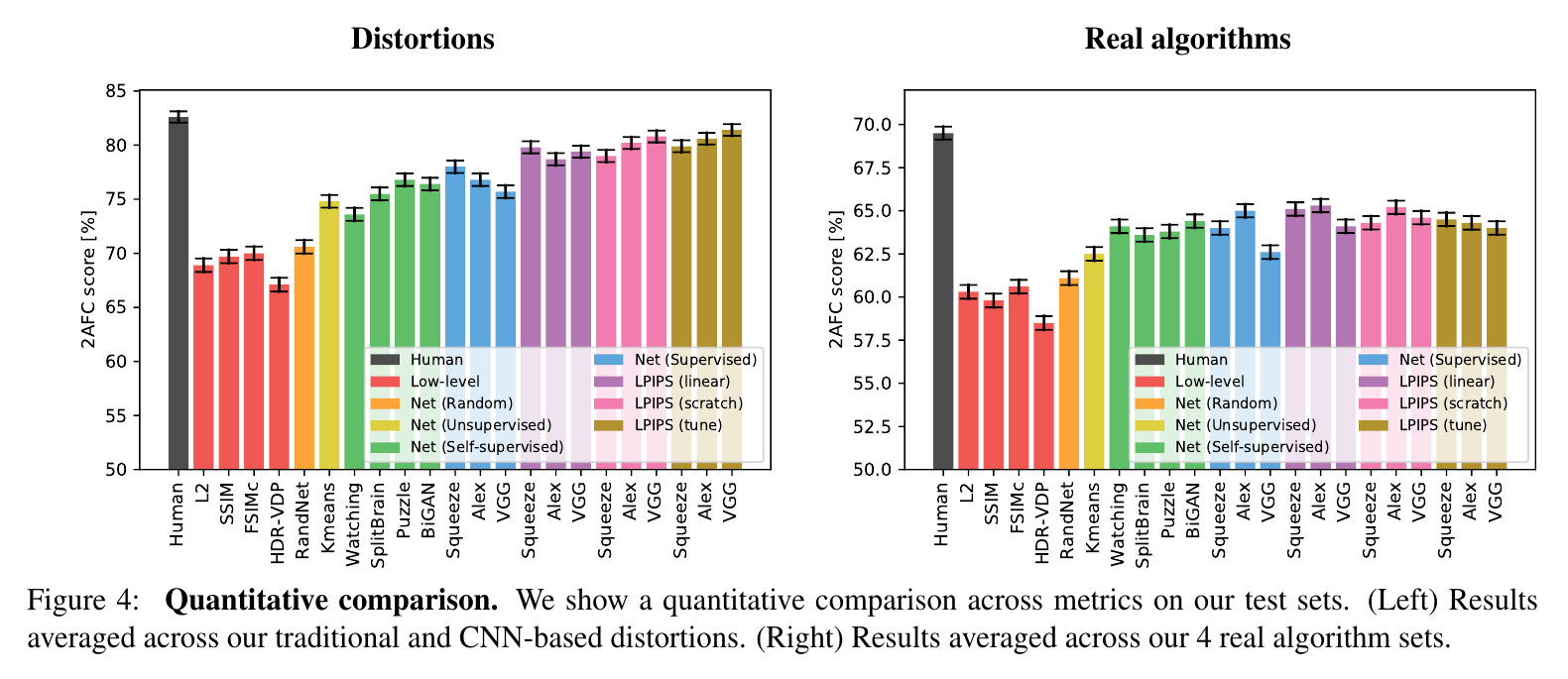
The proposed method agrees more often with human perception.
3. Where are the key elements of the technology and method?
Berkeley-Adobe Perceptual Patch Similarity Dataset
-
Dataset of many distortions
- Traditional augmentations e.g. blurring; and CNN tasks e.g. autoencoder, coloring, denoising, superresolution

- Traditional augmentations e.g. blurring; and CNN tasks e.g. autoencoder, coloring, denoising, superresolution
-
Use 64x64 patches for low-level similarity aspects. 161K patches total from 5K images
-
Collect human judgement from AMT on below tasks
Tasks
- Two Alternative Forced Choice (2AFC): present two distortions, ask which is more similar to the original? Used for training
- Just Noticeable Differences: validation metric, ask if 2 images (original and distorted) are the same or different.
NN Similarity Task and Prediction
- x is source image, x0 is distorted image. Compare two distortions to judge which is more similar to source image.
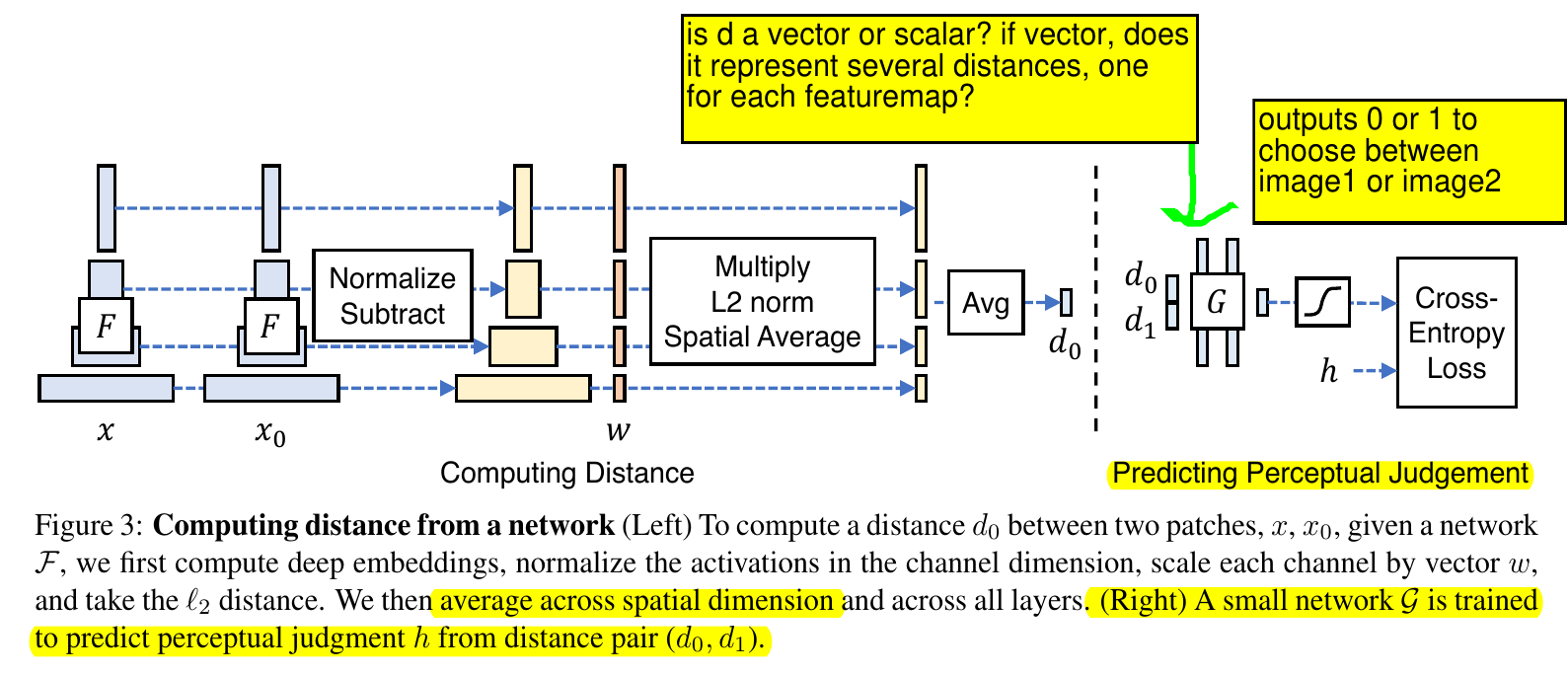
4. How did you verify that it works?
TODO
5. Things to discuss? (e.g. weaknesses, potential for future work, relation to other work)
Weaknesses
- Evaluator can ONLY make binary prediction of whether IMAGE 1 or IMAGE 2 is more similar to a reference image. There is no meaningful quantitative scale. Even though NNs output a float between [0, 1], it's commonly known that this number does not reflect statistical confidence.
- Training an evaluator Net requires collection of a human-judgement dataset of perceptual differences. Requires finetuning the classification net on the dataset. Could be theoretically done for any evaluation task, but possibly expensive.
Questions
- Would traditional classification ConvNet evaluators work on 3D invariance? probably not
Potential for future work
-
Ideally we can provide a trained evaluator Net that performs similarly to humans at virtual try-on perception. Could do it for different perception tasks:
- given two possible try-ons, which is more accurate to the original cloth image?
- given two possible try-ons, which is more accurate to the original person image?
- given a boundary between two clothing items, which is more realistic?
-
Still have to figure out how to modify this to be a quantitative continuous metric