[NVIDIA SPADE / GauGAN] Semantic Image Synthesis with Spatially-Adaptive Normalization (Mar 2019 CVPR) #12
Description
0. Article Information and Links
- Paper link: https://nvlabs.github.io/SPADE/
- Release date: YYYY/MM/DD
- Number of citations (as of 2020/MM/DD):
- Implementation code: Official GitHub repo | Direct link to the SPADE class definition
- Supplemental links (e.g. results): Interactive Demo http://nvidia-research-mingyuliu.com/gaugan
- Publication: CVPR 2019
1. What do the authors try to accomplish?
Semantically manipulate an image, controlled through the segmentation mask.
2. What's great compared to previous research?
Replaces the standard encoder layers with a novel SPADE normalization layer. SPADE preserves semantic information throughout the network, and seems to achieve SOTA for encoding information in GANs. Furthermore, SPADE results in a lighter architecture because encoder layers are removed.
3. Where are the key elements of the technology and method?
SPatially-Adaptive (DE)normalization1 (SPADE)
A special normalization layer for the generator designed for Semantic image synthesis. Meant to replace InstanceNorm that washes away semantic information (weakness of pix2pixHD).
What's wrong with InstanceNorm? Imagine a uniform segmentation mask of a single label, e.g. all grass or all sky. Instance Normalization would squash both of these to 0, even though they're semantically different.
Unlike AdaIn that modulates global style, SPADE varies by spatial location (because it takes in a tensor).
NO large encoder at the base to parse the segmentation mask, unlike other typical generators. Instead, the mask is passed in to SPADE layers.
How it works
"Similar to the Batch Normalization [21], the activation is normalized in the channel-wise manner and then modulated with learned scale and bias."
But SPADE's gamma and beta are tensors because they're applied per spatial unit.
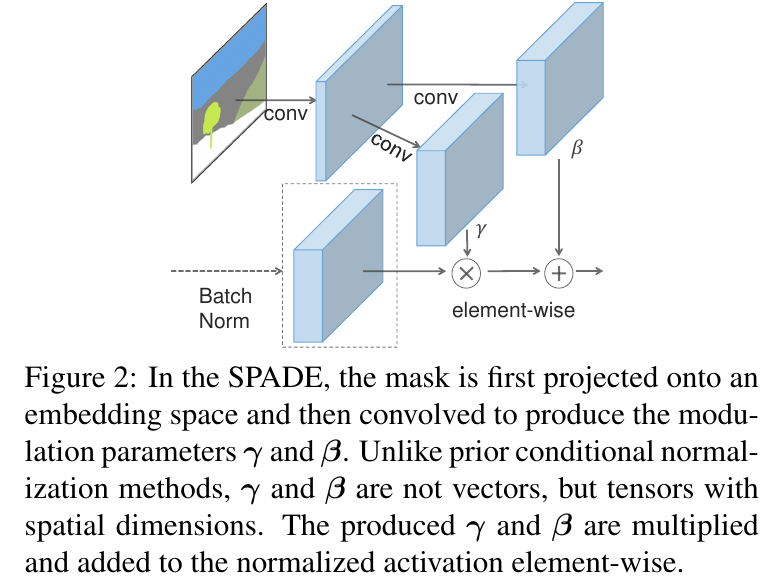 |
| 
"SPADE is related to, and is a generalization of several existing normalization layers (...) For any
spatially-invariant conditional data, our method reduces to the Conditional BatchNorm. Similarly, we can arrive at AdaIN by replacing m with a real image, making the modulation parameters spatially-invariant, and setting N = 1."
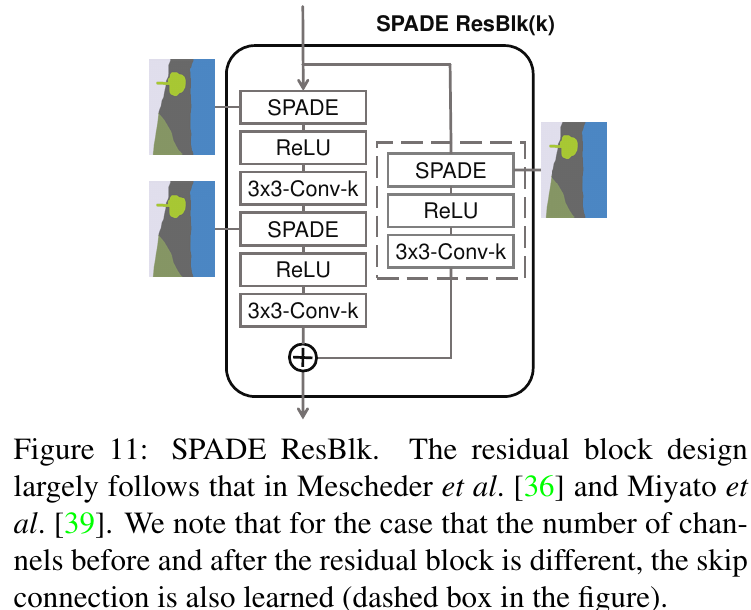
More diagrams from appendix:
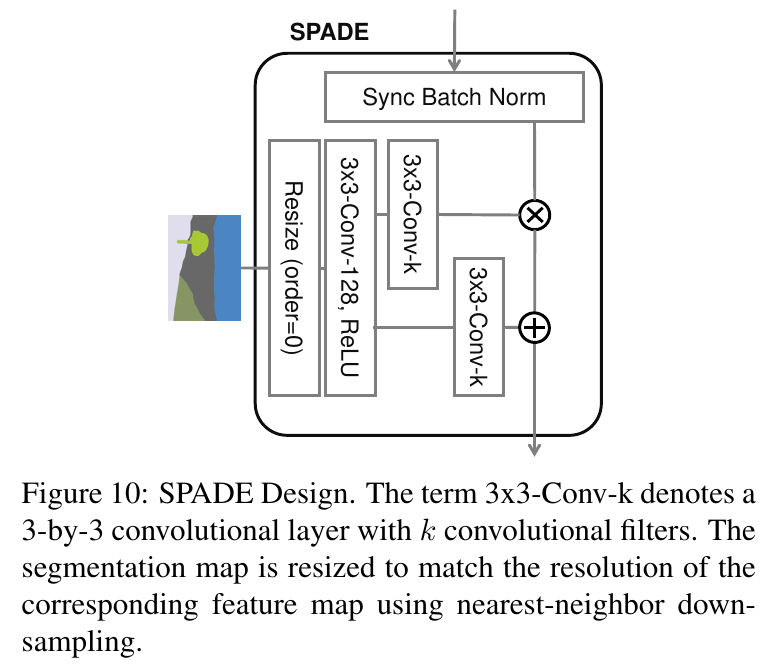 |
| 
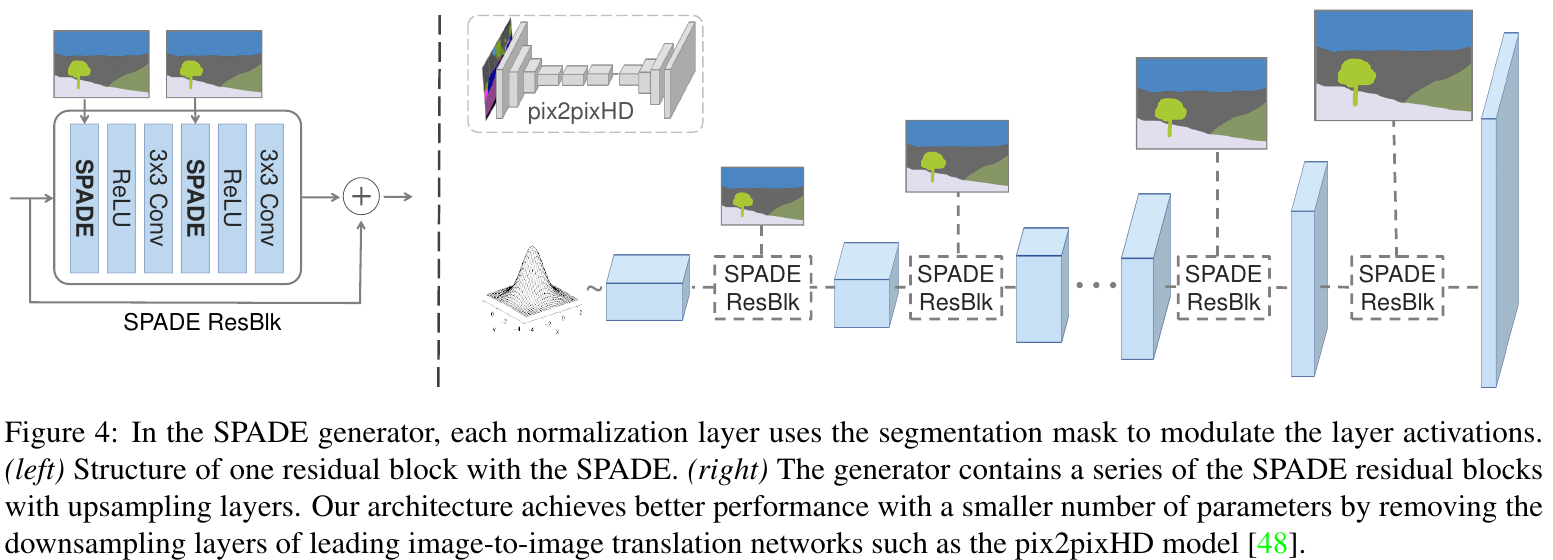
4. How did you verify that it works?
Public GauGAN interactive demo http://nvidia-research-mingyuliu.com/gaugan.
Still need to test in my own experiments.
5. Things to discuss? (e.g. weaknesses, potential for future work, relation to other work)
6. Are there any papers to read next?
- NVIDIA's World-Consistent Vid2Vid uses a "Multi-spade" layer (basically 3 sequential SPADEs) to encode multiple annotations, and achieve SOTA on video-to-video synthesis