The dataset used to build the predicitve model is the adult dataset form the UCI machine learning repository.
The dataset contains two attributes specific to each row as the target value, “>50k” for income over $50,000 and “<=50k” for income under $50,000 dollars. The dataset contains 32,560 entries excluding headers and 15 columns with 24 duplicate entries.
There isn't much diversity in the dataset for features such as capital gain, capital loss, work class, native country and race.
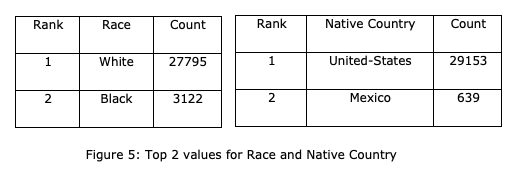
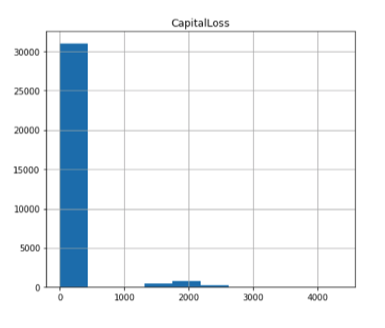
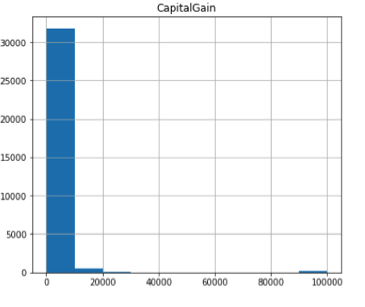
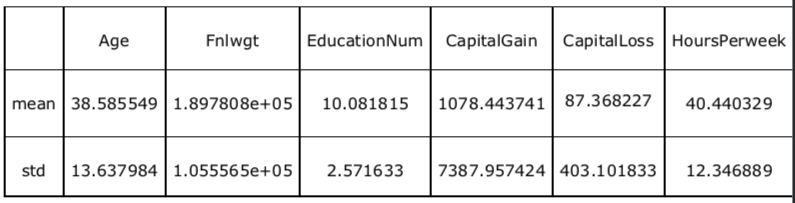
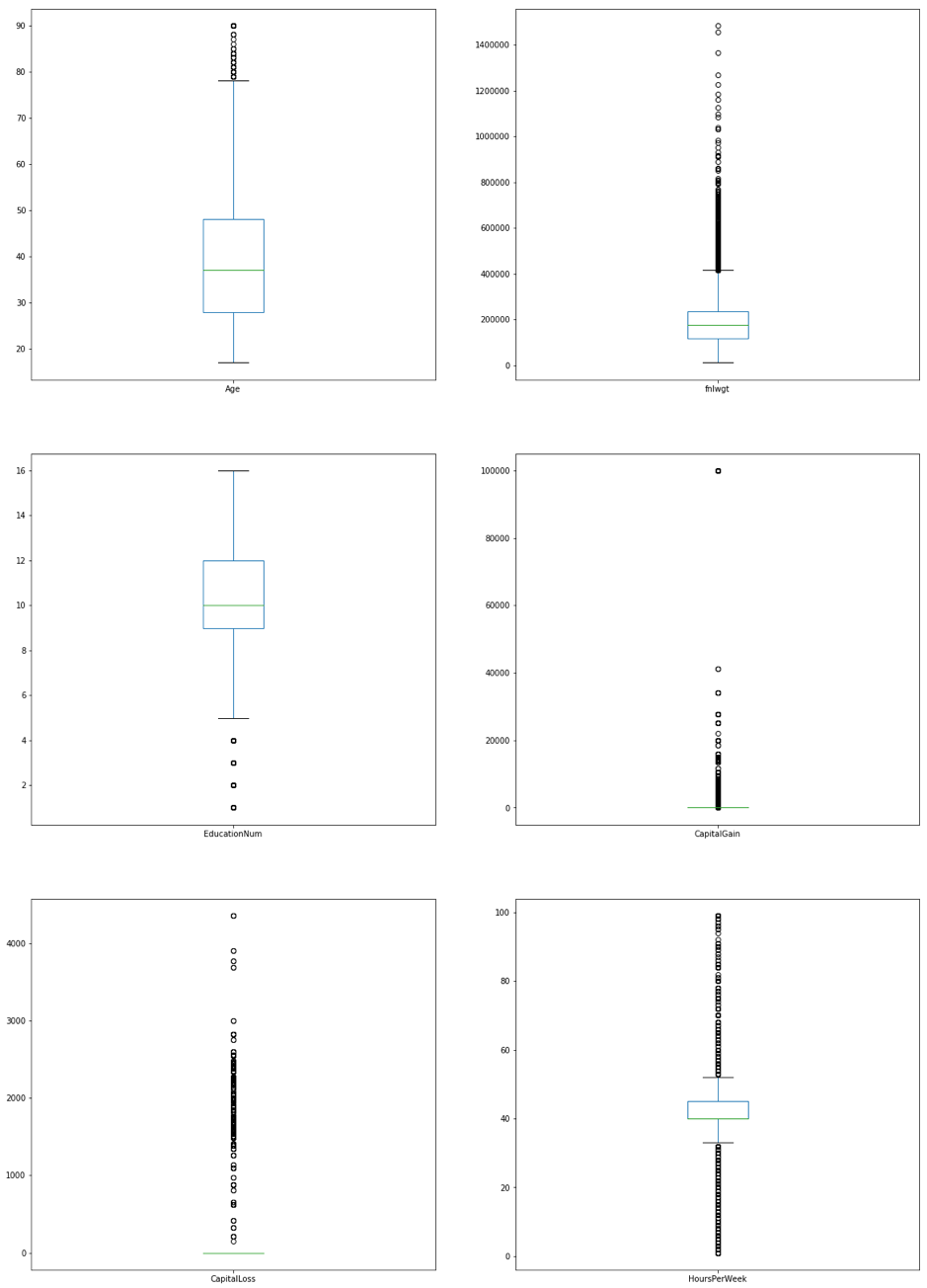
Furthermore, it is evident from the table below there is quite a bit of deviation in the dataset for hours per week, fnlwgt, capital loss and capital gain. Additionally, the box and whiskers plot below further solidifies the fact there are a significant number of outliers in these values. This is why the the MinMax scaler was used instead of the Standard scaler as the MinMax scaler is not sensitive to outliers.
k-Fold Validation: 87.1%
Logarithmic Loss: 4.25
