The problem to be solved in this project consists in training an agent through reinforcement learning algorithms. The goal of the agent is to collect as many yellow bananas as possible while avoiding blue bananas in a large, square world.

The state space has 37 dimensions and contains the agent's velocity, along with ray-based perception of objects around agent's forward direction. Given this information, the agent has to learn how to best select actions. Four discrete actions are available, corresponding to:
0- move forward.1- move backward.2- turn left.3- turn right.
Yellow bananas provides a reward of +1, while blue ones provide a reward of -1. The problem is considered to be solved when the average score of the last 100 episodes is equal or greater than 13 points.
The whole training of the agent is implemented in the Navigation.ipynb notebook. You can either visualize the last execution or run it by yourself in a Jupyter server. To do so, you can take the following steps to fulfill the requirements:
-
Create (and activate) a new environment with Python 3.6.
- Linux or Mac:
conda create --name drlnd python=3.6 source activate drlnd- Windows:
conda create --name drlnd python=3.6 activate drlnd
-
Follow the instructions in this repository to perform a minimal install of OpenAI gym.
-
Install the dependencies in the
python/folder.cd ./python/ pip install .
-
Create an IPython kernel for the
drlndenvironment.python -m ipykernel install --user --name drlnd --display-name "drlnd" -
Download the Unity Environment and unzip it inside the
solution/directory. (If you are using Windows 64 bits, you can skip this step since the repository already contains the environment files. Otherwise, delete the environment files and place the ones matching your OS). -
Before running the notebook, change the kernel to match the
drlndenvironment by using the drop-downKernelmenu.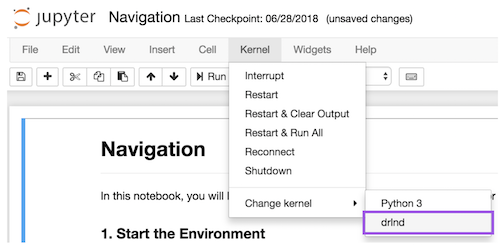
The agent is able to solve the problem in 395 episodes. The weights of the deep Q-network are stored in agent.pth. Here's the agent's score history:
