TokenLoom is a TypeScript library for progressively parsing streamed text (LLM/SSE-like) into structured events. It detects:
- Custom tags like
<think>...</think>(non-nested in v1) - Fenced code blocks (``` or ~~~), including language info strings
- Plain text emitted as tokens/words/graphemes
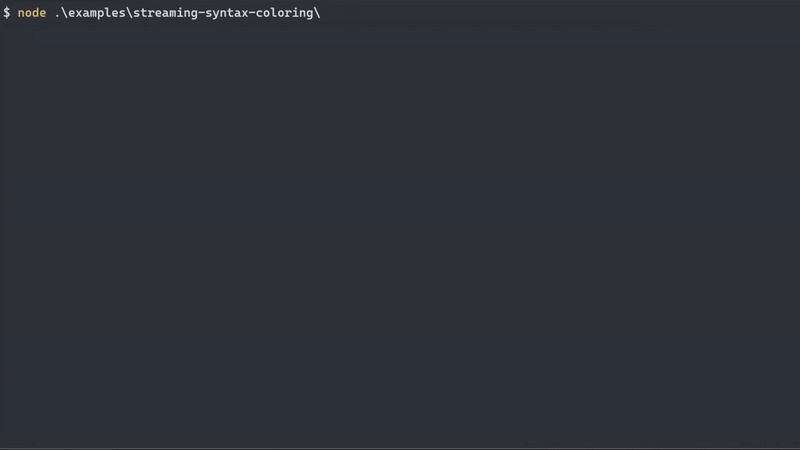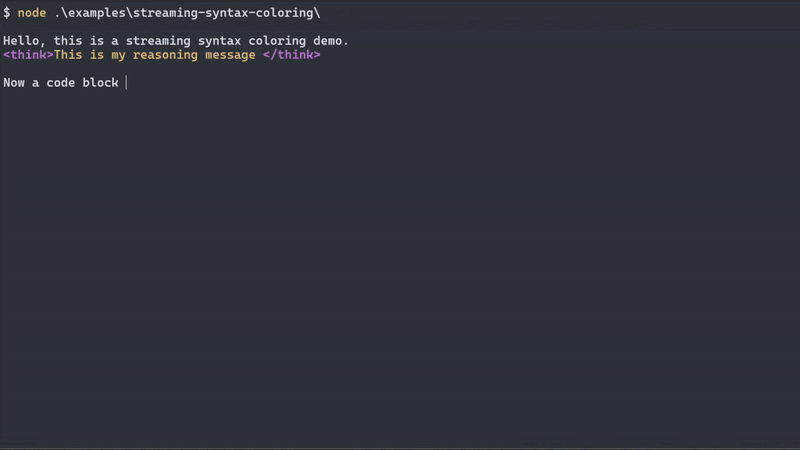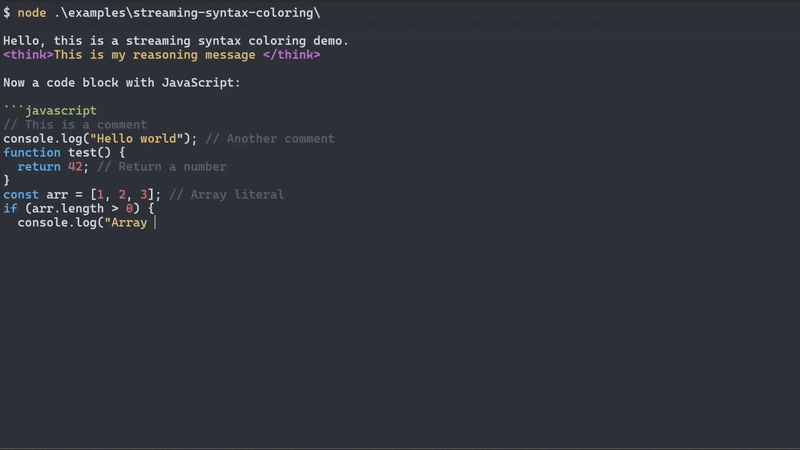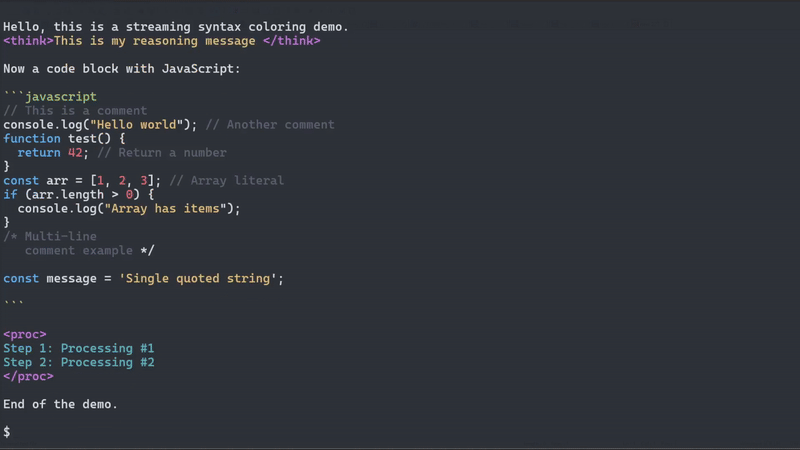
The Problem: When working with streaming text from LLMs, SSE endpoints, or real-time data sources, you often need to parse structured content that arrives in arbitrary chunks. Traditional parsers fail because they expect complete, well-formed input. You might receive fragments like:
"<thi"+"nk>reasoning</think>"(tag split across chunks)"```java"+"script\nconsole.log('hello');\n```"(code fence fragmented)- Incomplete sequences that need buffering without blocking the stream
Existing Solutions Fall Short:
- DOM parsers require complete markup and fail on fragments
- Markdown parsers expect full documents and don't handle streaming
- Regex-based approaches struggle with boundary conditions and backtracking
- Custom state machines are complex to implement correctly for edge cases
TokenLoom's Solution:
- Stream-native design that handles arbitrary chunk boundaries gracefully
- Progressive emission - start processing immediately, don't wait for completion
- Intelligent buffering with configurable limits to prevent memory issues
- Robust boundary detection that works even when tags/fences split mid-sequence
- Plugin architecture for flexible post-processing and output formatting
Perfect for AI applications, real-time chat systems, streaming markdown processors, and any scenario where structured text arrives incrementally.
Design intent:
- Tolerate arbitrary chunk fragmentation (e.g.,
<thi+nk>or ````+javascript\n) - Emit start → progressive chunks → end; do not stall waiting for closers
- Bound buffers with a high-water mark; flush when needed
- Streaming-safe detection of custom tags and code fences
- Incremental emission: does not block waiting for closers; emits start, progressive chunks, then end
- Configurable segmentation: token, word, or grapheme units with named constants (
EmitUnit.Token,EmitUnit.Word,EmitUnit.Grapheme) - Controlled emission timing: configurable delays between outputs for smooth streaming
- Async completion tracking:
flush()returns Promise,endevent signals complete processing - Buffer monitoring:
buffer-releasedevents track when output buffer becomes empty - Non-interfering display:
once()method for status updates that wait for buffer to be empty - Plugin system: pluggable post-processing via simple event hooks
- Backpressure-friendly: exposes high-water marks and flushing
- v1 supports custom tags and fenced code blocks; Markdown headings and nested structures are intentionally out-of-scope for now.
npm install tokenloomTokenLoom includes a browser-compatible build that can be used directly in web browsers:
<script src="node_modules/tokenloom/dist/index.browser.js"></script>
<script>
// Simple syntax - TokenLoom is available directly
const parser = new TokenLoom();
// All exports are also available as properties
const { EmitUnit, LoggerPlugin } = TokenLoom;
// Use parser as normal...
</script>Or with a CDN:
<script src="https://unpkg.com/tokenloom/dist/index.browser.js"></script>The browser build includes all necessary polyfills and works in modern browsers without additional dependencies.
For development:
npm ci
npm run buildRequirements: Node 18+
import { TokenLoom, EmitUnit } from "tokenloom";
const parser = new TokenLoom({
tags: ["think"], // tags to recognize
emitUnit: EmitUnit.Word, // emit words instead of tokens
emitDelay: 50, // 50ms delay between emissions for smooth output
});
// Listen to events directly
parser.on("text", (event) => process.stdout.write(event.text));
parser.on("tag-open", (event) => console.log(`\n[${event.name}]`));
parser.on("end", () => console.log("\n✅ Processing complete!"));
// Non-interfering information display
parser.once("status", () => console.log("📊 Status: Ready"));
const input = `Hello <think>reasoning</think> world!`;
// Simulate streaming chunks
for (const chunk of ["Hello <thi", "nk>reason", "ing</think> world!"]) {
parser.feed({ text: chunk });
}
// Wait for all processing to complete
await parser.flush();See examples/ directory for advanced usage including syntax highlighting, async processing, and custom plugins.
new TokenLoom(opts?: ParserOptions)// Named constants for emit units
namespace EmitUnit {
export const Token = "token";
export const Word = "word";
export const Grapheme = "grapheme";
export const Char = "grapheme"; // Alias for Grapheme
}
type EmitUnit =
| typeof EmitUnit.Token
| typeof EmitUnit.Word
| typeof EmitUnit.Grapheme;
interface ParserOptions {
emitUnit?: EmitUnit; // default "token"
bufferLength?: number; // maximum buffered characters before attempting flush (default 2048)
tags?: string[]; // tags to recognize e.g., ["think", "plan"]
/**
* Maximum number of characters to wait (from the start of a special sequence)
* for it to complete (e.g., '>' for a tag open or a newline after a fence
* opener). If exceeded, the partial special is treated as plain text and
* emitted. Defaults to bufferLength when not provided.
*/
specBufferLength?: number;
/**
* Minimum buffered characters to accumulate before attempting to parse a
* special sequence (tags or fences). This helps avoid boundary issues when
* very small chunks arrive (e.g., 1–3 chars). Defaults to 10.
*/
specMinParseLength?: number;
/**
* Whether to suppress plugin error logging to console. Defaults to false.
* Useful for testing or when you want to handle plugin errors silently.
*/
suppressPluginErrors?: boolean;
/**
* Output release delay in milliseconds. Controls the emission rate by adding
* a delay between outputs when tokens are still available in the output buffer.
* This helps make emission smoother and more controlled. Defaults to 0 (no delay).
*/
emitDelay?: number;
}use(plugin: IPlugin): this– registers a pluginremove(plugin: IPlugin): this– removes a pluginfeed(chunk: SourceChunk): void– push-mode; feed streamed textflush(): Promise<void>– force flush remaining buffered content and emitflush, resolves when all output is releasedonce(eventType: string, listener: Function): this– add one-time listener that waits for buffer to be empty before executingdispose(): void– cleanup resources and dispose all pluginsgetSharedContext(): Record<string, any>– access the shared context object used across events[Symbol.asyncIterator](): AsyncIterator<Event>– pull-mode consumption
TokenLoom extends Node.js EventEmitter, so you can listen to events directly:
on(event: string, listener: Function): this– listen to specific event types or '*' for all eventsemit(event: string, ...args: any[]): boolean– emit events (used internally)- All other EventEmitter methods are available (once, off, removeAllListeners, etc.)
TokenLoom emits the following event types:
text- Plain text contenttag-open- Custom tag start (e.g.,<think>)tag-close- Custom tag end (e.g.,</think>)code-fence-start- Code block start (e.g.,```javascript)code-fence-chunk- Code block contentcode-fence-end- Code block endflush- Parsing complete, buffers flushedend- Emitted after flush when all output processing is completebuffer-released- Emitted whenever the output buffer is completely emptied
Each event includes:
context: Shared object for plugin state coordinationmetadata: Optional plugin-attached datain: Current parsing context (inside tag/fence)
Plugins use a transformation pipeline with three optional stages:
preTransform- Early processing, metadata injectiontransform- Main content transformationpostTransform- Final processing, analytics
parser.use({
name: "my-plugin",
transform(event, api) {
if (event.type === "text") {
return { ...event, text: event.text.toUpperCase() };
}
return event;
},
});Built-in plugins:
LoggerPlugin()- Console loggingTextCollectorPlugin()- Text accumulation
See examples/syntax-highlighting-demo.js for advanced plugin usage.
const parser = new TokenLoom({
tags: ["think"],
emitUnit: EmitUnit.Word,
emitDelay: 100, // Smooth output with 100ms delays
});
parser.on("text", (event) => process.stdout.write(event.text));
parser.on("tag-open", (event) => console.log(`[${event.name}]`));
parser.on("buffer-released", () => console.log("📤 Buffer empty"));
// Non-interfering status updates
parser.once("debug-info", () => console.log("🔍 Debug: Processing stream"));
// Simulate streaming chunks
for (const chunk of ["Hello <thi", "nk>thought</th", "ink> world"]) {
parser.feed({ text: chunk });
}
await parser.flush(); // Wait for completionfor await (const event of parser) {
console.log(`${event.type}: ${event.text || event.name || ""}`);
if (event.type === "end") break; // Wait for complete processing
}const parser = new TokenLoom({
emitDelay: 200, // 200ms between emissions
emitUnit: EmitUnit.Grapheme,
});
// Events will be emitted with smooth 200ms delays
parser.feed({ text: "Streaming text..." });
await parser.flush(); // Waits for all delayed emissions// Display info without interrupting the stream
parser.once("status-update", () => {
console.log("📊 Processing 50% complete");
});
parser.once("debug-info", () => {
console.log("🔍 Memory usage: 45MB");
});
// These will execute when buffer is empty, not interfering with outputparser.on("buffer-released", (event) => {
console.log(`📤 Buffer emptied at ${event.metadata.timestamp}`);
// Triggered every time output buffer becomes completely empty
});
parser.on("end", () => {
console.log("🏁 All processing complete");
// Triggered after flush() when everything is done
});You can run the examples after building the project:
# Build first
npm run build
# Basic parsing with plugins and direct event listening
node examples/basic-parsing.js
# Streaming simulation with random chunking and event tracing
node examples/streaming-simulation.js
# Syntax highlighting demo with transformation pipeline
node examples/streaming-syntax-coloring/index.js
# Pipeline phases demonstration
node examples/pipeline-phases-demo.js
# Async processing demo
node examples/async-processing.js
# Custom plugin example
node examples/custom-plugin.jsnpm ci # install
npm run build # build with rollup
npm run dev # watch build
npm test # run tests (vitest)
npm run test:run # run tests once
npm run test:coverage # coverage reportTokenLoom uses a handler-based architecture that switches between specialized parsers:
- TextHandler - Plain text and special sequence detection
- TagHandler - Custom tag content processing
- FenceHandler - Code fence content processing
- Stream-safe: Handles arbitrary chunk fragmentation (
<thi+nk>) - Progressive: Emits events immediately, doesn't wait for completion
- Bounded buffers: Configurable limits prevent memory issues
- Enhanced segmentation: Comment operators (
//,/*,*/) as single units - No nesting: Tags and fences are non-nested in v1
- Optional nested tag/block support
- Markdown structures (headings, lists, etc.)
- More robust Unicode segmentation and locale controls
- Additional built-in plugins (terminal colorizer, markdown renderer)
- Performance optimizations for very large streams
MIT