欢迎您联系 @abbkit.com.
@2018-2024 下一个更新会是支持JAVA25 , 功能上不会再更新
https://www.oracle.com/java/technologies/java-se-support-roadmap.html
- java21支持
- lemondb存储引擎支持分布式
- RAFT分布式协议实现 ( RAFT GROUP )
- 表 一写多读 ( 表级别,表的Primary分布在一个节点 )
- 集群 多写多读 ( 节点级别, 多个节点可以同时写入,每张表的Primary分布在不同的节点 )
- 移除了MYSQL的依赖,现在元数据不再存储在MYSQL,而是存储在lemondb存储引擎内部(分布式元数据表)
- lemondb存储引擎可以独立于RAFT协议使用,这样就是本地化的单节点存储引擎
- 底层存储引擎插件化优化
- MYSQL支持优化
- REDIS支持优化
- 移除HBASE
- 移除ES
- 移除Lucene
- lemondb存储引擎支持fetch-next,使用行主键扫描行数据的时候,最大支持10000行数据的拉取
- 内存优化
- 行扫描过程中共享块内存、页内存
- lemondb存储引擎segment合并过程中锁优化,减少锁持有的时间
- 合并过程中增加checkpoint,使用增量buffer存储合并过程中新put或者delete的数据
VUE+ELEMENT PLUS ( MVVM ): http://lemon.abbkit.com/
- 移除zookeeper, 使用RAFT实现leader选取、同时增加底层lemondb存储引擎的多副本支持
- 从JAVA8迁移到 JAVA17
- 项目拆分为两个部分:
- lemondb存储,支持LQL的执行,数据存储,多节点(stateless)支持其他存储引擎的访问,比如MYSQL、REDIS、NO-SQL等
- lemondb ui服务,lemondb存储的前端管理页面
- 元数据同时存在MYSQL和lemondb存储引擎中,lemondb存储引擎中的元数据通过RAFT协议复制到集群中的所有节点
一个简单的存储引擎,所有的数据以行的形式存储,数据行以行键升序排序,存储在本地文件系统中,文件生成之后不能修改。 文件数据的管理以页为最小单位,1个页16K大小,64个页为一个块,N个块组成一个segment,一个文件就是一个segment,所有的segment都是只读的, 多个segment组成tablespace,tablespace表示一类数据,或者说一张表。
一个数据
块对象的描述,PAGE磁盘空间是由块对象管理的,每次申请的磁盘空间是一个块的大小
一个文件就是一个segment,
PAGE的infKey和supKey构成整个skip-list
- | - | - | - | - | - | - | - | - | - | - | - | -
\ / \ / \ / \ / \ / \ /
P0 P1 P2 P3 P4 P5
PX(infKey,supKey)
--------------------------------------------
开始节点是一个PAGE的infKey , 则这个PAGE为第一个PAGE
开始节点是一个PAGE的supKey ,如果包含开始节点, 则这个PAGE为第一个PAGE;否则下一个PAGE为第一个PAGE
结束节点是一个PAGE的infKey ,如果包含结束节点, 则这个PAGE为最后一个PAGE;否则上一个PAGE为最后一个PAGE
结束节点是一个PAGE的supKey , 则这个PAGE为最后一个PAGE
1. 范围查询:
由多个segment组成
可以给某个字段添加索引,索引数据也是以行的形式存储到segment中,索引行的行键是由被索引行的索引字段值和索引序号组合而成,索引行的值是被索引行的行键, 索引行的版本和被索引行的版本一样。
vcc id age vcc index(age,seq) id
1 ab, 2 2 1 abc
2 abc, 1 1 2 ab
7 abe, 3 => 7 3 abe
9 fd, 10 12 7 fo
10 fk, 8 10 8,0 fk
12 fo, 7 19 8,1 xz
19 xz, 8 9 10 fd
因为segment不能修改,数据删除的时候,会把删除的行键存储到对应的.del文件中,一个segment对应一个.del文件, .del文件会存在多个版本,在新的segment持久化到磁盘到时候,会生成一个更高版本的.del文件,其操作是通过复制当前的.del文件 ,然后追加当前新删除的数据行键完成的。
有NOSQL、SQL-RELATED 存储,比如HBAE、ElasticSearch、MongoDB、MYSQL,每种存储有自己独特的数据访问结构和连接方式,在使用这些存储的过程中,突然有一天,我想是否可以有一种公共的方式来隔离这些差异性,由此这个项目试探性的通过在这些存储的上层建立一个公共的数据结构,使用HTTP协议的访问方式来隔离这些存储。设计目标
- 行级别的操作,包括PUT和SELECT
- 多行查询操作,SELECT
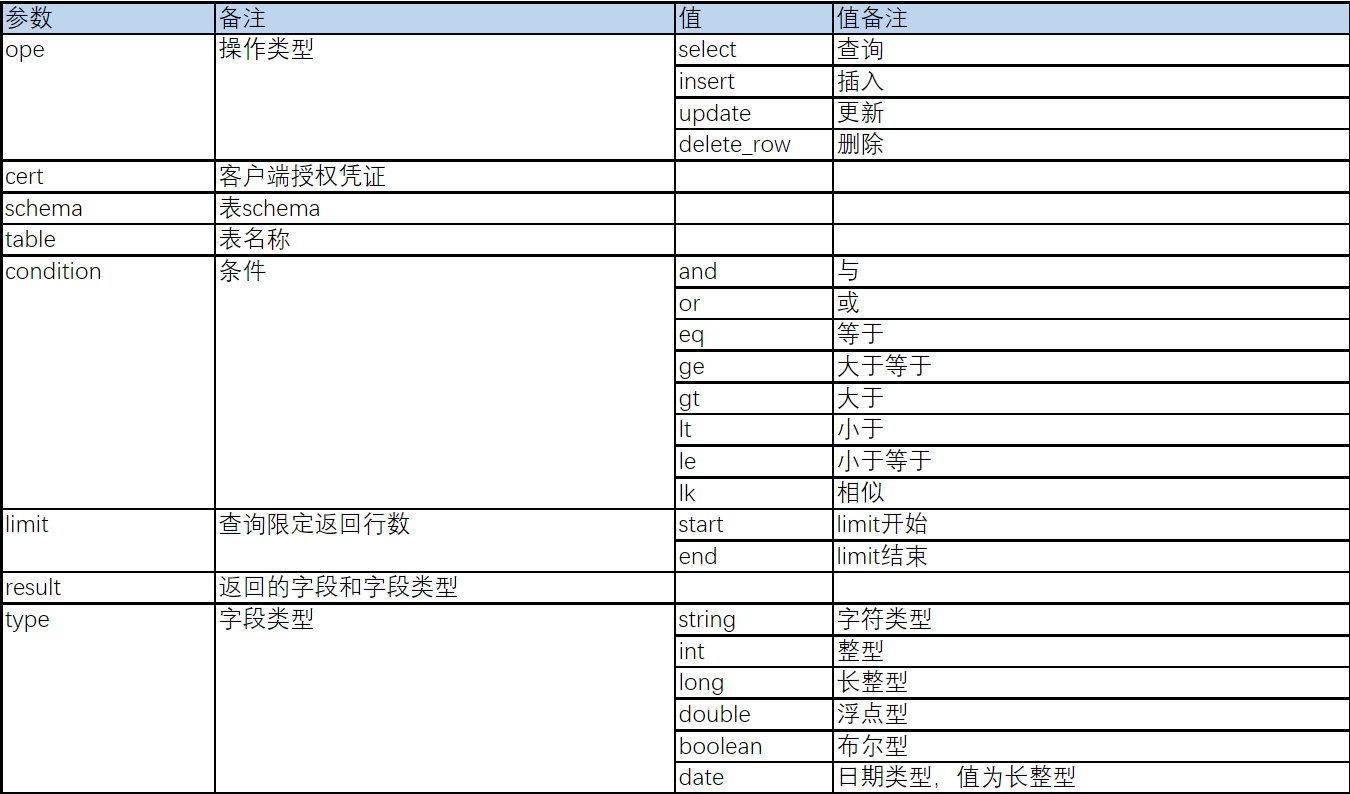
- 数据类型支持int 、long 、 double 、boolean 、date 、string
- 存储引擎插件化开发支持,HBASE、MySQL、ElasticSearch、MongoDB
- 不同存储下的行级别操作的事务支持
| HBASE | MySQL | ElasticSearch | MongoDB | |
|---|---|---|---|---|
| 行事务 | YES | YES | ? | ? |
? 表示未做集成
跨表、跨存储引擎的行操作一致性,参考分布式事务支持
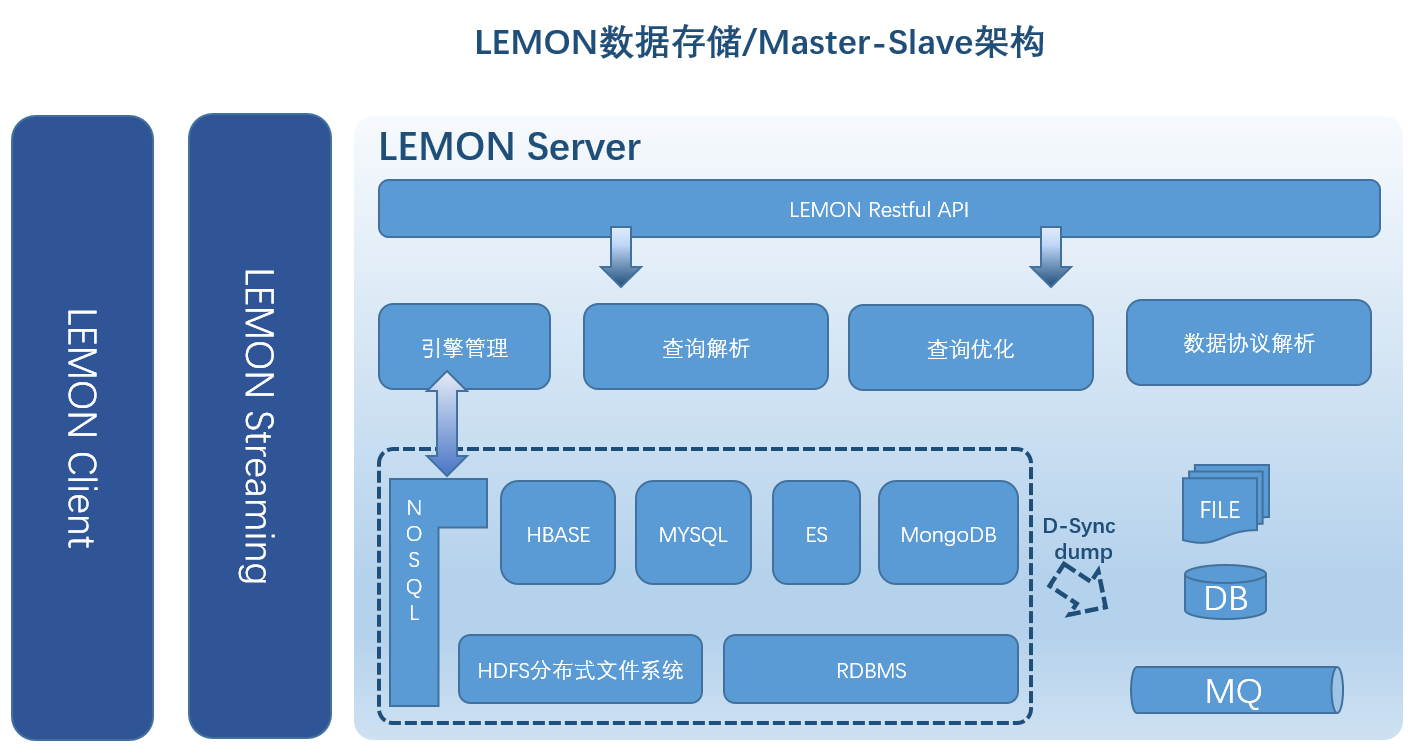
服务端采用分层的设计理念,分为HTTP层,解析、执行层,存储引擎层;客户端提供JAVA库,包装数据结构提供统一的数据访问API .
Tips: Master Slave架构模式,使用到了SpringBoot、MySQL、JSON、HBASE、REDIS、ZooKeeper.
使用JSON数据协议,行业上有很好的开源JSON协议解析框架,比如Jackson,使用JSON数据协议,不需要自己再做词法、语法分析解析成AST(Antlr4 ???),就能方便的直接映射到自定义的统一数据模型上。
数据类型支持int、long、double、boolean、date、string这几种常使用的类型。
服务端定义统一数据模型来处理数据协议,把JSON数据结构转换成友好度更高的统一数据模型,便于后面采用visitor设计模式来方便的处理各种逻辑,比如字段合法性验证、字段是否存在验证等。
把JSON数据结构转换成统一数据模型
定义统一的数据访问接口,规范底层存储的数据访问方式,支持多种存储引擎。
支持表管理操作,包括create table、drop table、alter table等
- 支持单一条件或者多条件的查询
- 支持嵌套查询
- 不支持跨表/跨存储引擎查询,跨表/跨存储引擎查询使用LQL
- 支持单行插入
- 不支持多行插入
行级别操作接口,支持行级别事务。
- 支持单行更新
- 不支持多行更新
行级别操作接口,支持行级别事务。
- 支持单行删除
- 不支持多行删除
验证统一数据模型操作是否授权,以及表、字段是否合法,包括
- 是否有字段不属于当前操作的表
- 操作是否被授权,比如某个客户端key是只读的,就不能执行update、insert、delete操作
- 验证操作的表是否存在
把嵌套查询模型转换成底层引擎支持的查询结构,解析过程中会处理查询值的类型转换。
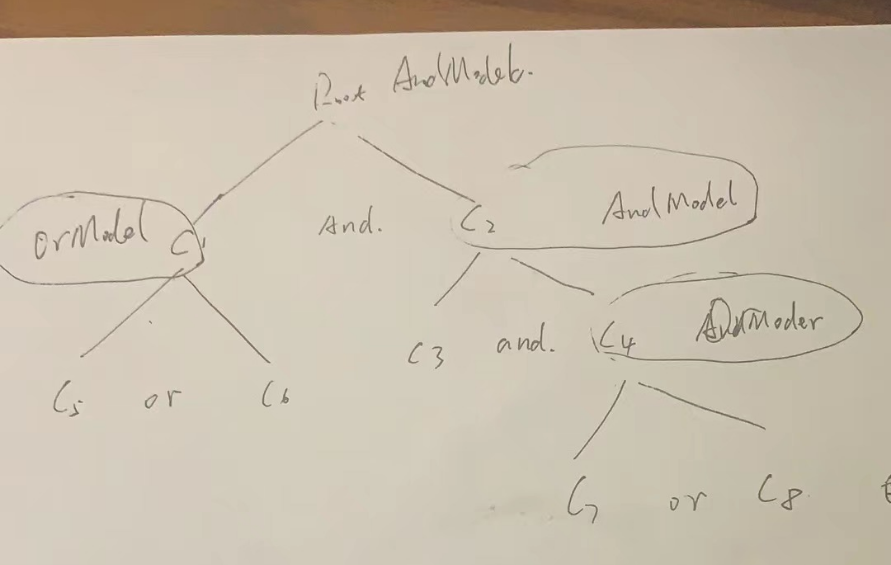
在查询解析过程中,会判断查询树的某些节点是否可以合并、丢弃等,比如
- and节点只有一个子节点,就会把子节点作为and节点
- 如果某个子节点是字面值判断,则根据父节点的查询类型优化子节点的判断,比如
- 父节点是and,某个子节点的字面值判断为false,不需要查询后面的条件,则直接替换父节点为false
- 父节点是or,某个子节点的字面值判断为true,不需要查询后面的条件,则直接替换父节点为true
把执行的时间存到log日志中,包括执行开始时间、执行结束时间、执行花费、执行涉及到的行数,select会检查返回的行数,其他的语句默认为1
底层存储引擎实现负责具体的数据存储、查询任务,以插件化的方式在引擎中心(Engine Hub)注册,Engine Hub负责引擎生命周期的管理,包括引擎的加载、卸载。引擎选择器解析统一的数据结构模型,选择具体的引擎执行相应的任务。
把统一的数据结构模型解析成SQL语句,通过MYSQL客户端(JDBC驱动)连接远程集群,执行任务。
把统一的数据结构模型解析成MongoDB语句,通过MongoDB客户端连接远程集群,执行任务。
把统一的数据结构模型解析成HBASE认识的语句,通过HBASE客户端连接远程集群,执行任务。
- 每个客户端key的最大连接数,MAX=W*N
- W指存储系统worker节点数量
- N指客户端能够连接到一个worker节点的连接数量,在客户端申请KEY的时候指定
- 查询引擎插件,支持SQL-LIKE、跨存储引擎join,不支持group、aggr、order、function
- SQL解析,Thanks: @jsqlparser
- 执行计划生成
- 存储引擎执行单表查询(条件下推)
- JOIN算法
- ONE BY ONE ? NLJ(支持) / BNLJ(支持) / MRR (IO reduce)? / SMJ / HJ
- ALL IN MEMORY ? (不支持)
- RETURN LIMIT RECORD
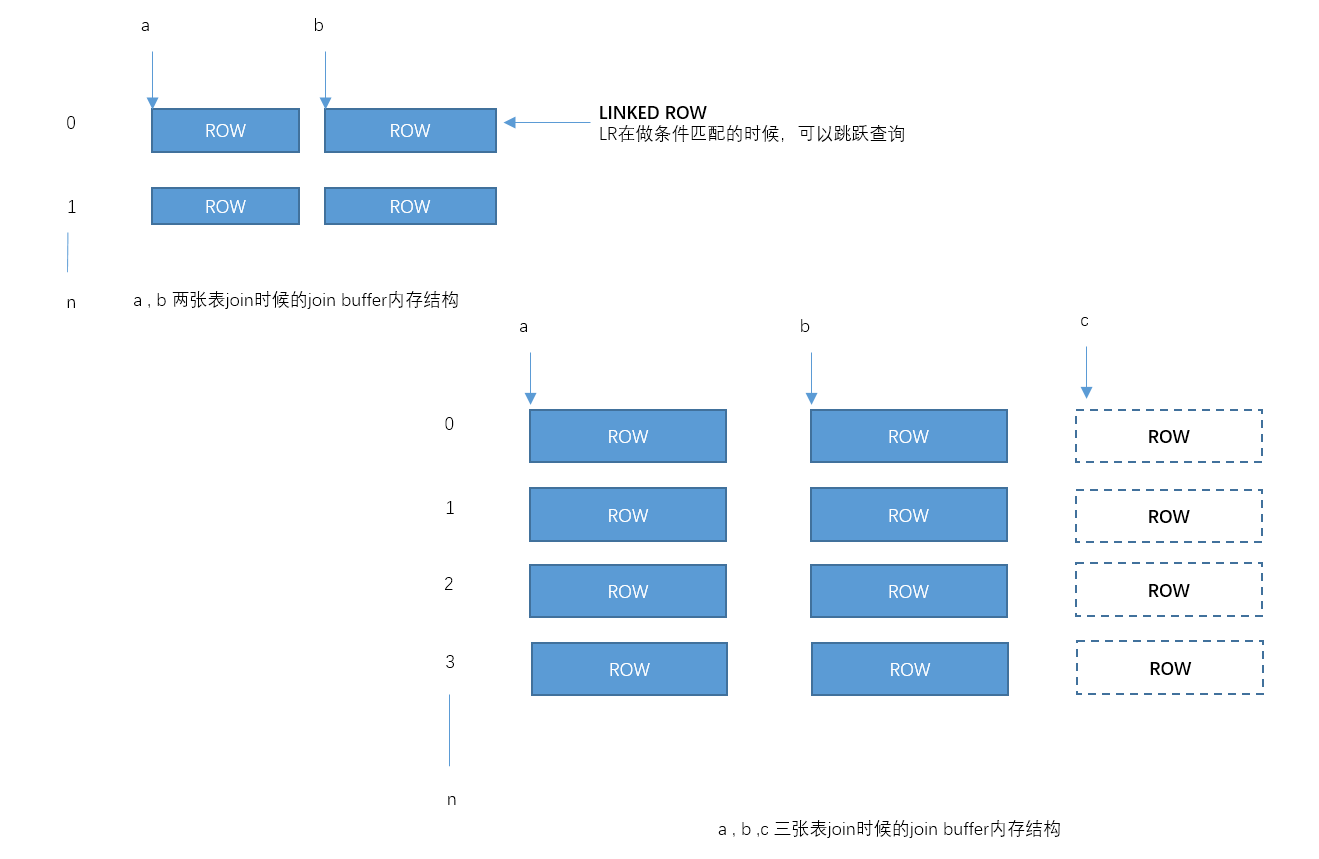
- Join Buffer用来存储表join时候的中间缓存
- 每张表都有一个独立的joinbuffer,joinbuffer的大小为R*C
- R为行数,默认为100_000行
- C为列数,存储临时列的数量
- ObjectSizeCalculator可以计算这张临时表的大小
- join buffer通过内存预分配的方式,循环覆盖使用
- 每张表都有一个独立的joinbuffer,joinbuffer的大小为R*C
-
join优化
- left join优化为inner join
- 在where条件树上找到被join表的字段,判定条件是否为非null
- 在当前条件所在的树分支上向上判定父节点(是否是and),直到根节点,是否影响根节点值的判定,如果影响了就可以转换为inner join
- 依次处理LQL语句中的其他join,根据条件转换为inner join
- 从第一张表开始,在连续的多个inner join的表中,根据查询条件,预选一个结果集比较小的表作为驱动表
- left join优化为inner join
-
order by 支持,使用快速排序算法处理
- 支持多个字段的不同排序方式(比如order by name asc, age desc),解析成先按name升序,再按age降序
- 第一次排序(不需要扫描临时磁盘文件sortfile),WHERE过滤后的第一条数据作为算法的分隔数据,对后面的数据,依次比较name和age字段,比分隔数据小,则放到左边,否则放到右边, 如果有limit,在第一次排序的过程中,如果左边的数据行数已经满足limit,则右边的数据不需要落到硬盘上了,也不需要在内存中缓存; 否则在到达内存缓存限制之后,右边的数据需要落盘(sortfile)。左边的数据在到达内存缓存限制之后也需要落盘(sortfile)
- 第二次排序(扫描临时磁盘文件sortfile),从左边的文件列表中随机选择一个文件,从磁盘加载第一条数据作为分隔数据,使用相同的比较规则,把数据分成左右两部分, 再递归处理左边部分的文件,直到左边部分的文件数为1,然后从左到右开始收敛,收集满足limit条件的文件数
- 从满足limit条件的文件列表中,按序扫描sortfile,把数据返回给客户端
sortfile的大小暂定为5MB 或者 100_000 BEST, O(nlogn); limit < n/2+n/4+n/8+...+n/(2*m) limit : 返回行数 n: join笛卡儿积的行数 m: sortfile扫描次数 -
group by having 支持,先排序再分组
- 使用快速排序算法对where过滤之后的记录按group by的字段排序
- 扫描已经排序完的sortfile列表,按group by字段分组,某一个分组如果满足having的filter条件,则为可返回的数据,否则忽略这个数据
-
count , sum , max , min , avg 函数支持
LQL执行执行顺序
FROM --> WHERE --> GROUP BY HAVING --> ORDER BY --> LIMIT
1. select count(1) from hot.t_class where `name` like '%一年级%'
2. select * from hot.t_class where `name` like '%一年级%' limit 10
3. SELECT
a.id AS 'a.id',
a.`name` AS 'a.name',
b.id AS 'b.id',
b.`name` AS 'b.name',
b.age,
b.money,
c.`name` AS 'c.name',
c.score
FROM
hot.t_class a
LEFT JOIN hot.t_student b ON a.id = b.classId
OR b.age > 20
LEFT JOIN hot.t_student_score c ON b.id = c.studentId
AND c.score > 60
WHERE
b.`name` LIKE '%166%'
AND a.`name` LIKE '%一年级%'
AND c.score < 90
ORDER BY
b.age,
c.`name` DESC
LIMIT 2147483647
4. SELECT
a.id AS 'classId',
a.`name` AS 'className',
b.id AS 'stuId',
b.`name` AS 'stuName',
LENGTH(c.`name`) AS 'cnLength',
count( 1 ) countScore,
max( c.score ) maxScore,
min( c.score ) minScore,
avg( c.score ) avgScore,
sum( c.score ) sumScore
FROM
hot.t_class a
LEFT JOIN hot.t_student b ON a.id = b.classId
OR b.age > 20
LEFT JOIN hot.t_student_score c ON b.id = c.studentId
AND c.score > 60
WHERE
b.`name` LIKE '%166%'
AND a.`name` LIKE '%一年级%'
AND c.score < 90
GROUP BY
cnLength,a.id, a.`name`, b.id, b.`name`
HAVING
countScore > 1
ORDER BY
maxScore DESC,
avgScore DESC
LIMIT 2147483647
数据源管理 http://lemon.abbkit.com:10088/static/datasource.html- 分布式数据dump(测试性),dump操作通过分布式锁,给表加上S锁,阻止其他进程或者线程对此表的写操作
- MQ dump , 把数据dump到kafka
- file dump ,把数据dump到文件系统
- sql dump ,把数据dump都sql文件
- http dump, 把数据dump到某个http接口
- 分布式事务(实验性),支持跨表put操作的事务一致性,通过整合seata实现
- 只支持MySQL存储引擎
- 存储引擎必须支持XA事务
- HBase存储引擎不支持
- 客户端必须也整合seata
- 需要使用柠檬存储的XADefaultClient客户端
- LQL分片执行(思考性),支持把复杂的LQL查询,特别是多个大表的join查询,分解成多个子任务在多个work节点执行
- 分解LQL查询的节点定义为驱动节点,负责聚合多个work节点的数据
- 各个节点之间建立专用的TCP通道处理join任务
- 分解、执行流程
- 按固定行数分区(全表扫描主键,拿到分区的主键值)分解join任务,每固定行数定义为一个分区,比如3张表的join操作,第一张表分解成3个分区,第二张表分解成5个分区, 第三张表分解成2个分区,则总的join任务数为分区join的笛卡尔积: 30(3x5x2)
- 驱动节点把join任务分发到其他节点执行
- 其他节点按定义的约定把满足条件的数据批量多次地返回给驱动节点
- 驱动节点拿到满足的行数,中断远程work节点的执行
- 驱动节点把数据返回给客户端
得不偿失,数据传输比计算更重,更耗资源
-
LQL join buffer并行处理,支持把join buffer的数据发送到不同的work节点执行,每个节点只执行join buffer和下一张表的join任务, 然后把新生成的join buffer再发送到下一个节点
-
分布式LQL
项目是JAVA项目,只能使用在JAVA8的环境中, 依赖的中间件
- HBASE => Version 2.2.5
- HADOOP => Version 2.7.5
- MYSQL => Version 8.0
- REDIS => Version 5.0.9
- docker | docker-compose
在你环境准备好完成之后,就可以在根目录下执行执行
mvn clean install -Dmaven.test.skip=true
执行完成之后,在lemon-starter目录下会有一个可执行的jar包(springboot maven plugin打出来的jar包)
docker build --network=abbkit -t lemon:latest .
# 生成docker镜像
启动master
docker-compose -f lemon-compose.yml up -d lemonMaster
启动backup master
docker-compose -f lemon-compose.yml up -d lemonMaster
# 执行之后这个新的进程会参与master选举
启动worker
docker-compose -f lemon-compose.yml up -d lemonWorker
# worker需要在master启动完成后才能启动,因为worker在启动过程中会去检查master是否存在
VUE+ELEMENT PLUS ( MVVM ): http://lemon.abbkit.com/
JQUERY : http://lemon.abbkit.com:10088/static/index.html
- MySQL 8.0 Reference Manual - MySQL 8.0 Reference Manual Including MySQL NDB Cluster 8.0.
- Apache HBase ™ Reference Guide - Apache HBase ™ Reference Guide.
Feel free to dive in! Open an issue or submit PRs.
This project exists thanks to all the people who contribute. Contributors
Apache-2.0 license © abbkit.com
MySQL优化流程
- 慢SQL查询,查询哪些SQL是慢的
- Explain SQL , 是否有use key | full table scan
- 看是否有use filesort , use temporary , 排序算法(二路排序算法,一路排序算法), 检查select部分是否返回了过多的字段,超过了排序时行大小的长度(字段类型长度之和)
- join优化,小表驱动大表(join buffer 256k>R×C),减少IO访问次数 ( NLJ / BNLJ (8.0.20后被HJ代替)/ MRR (IO reduce)? / SMJ / HJ )
- 最后检查事务锁 ,是不是有锁过长等待问题,这种情况一般出现在系统有大事务执行的情况下
- ICP技术, 这个要看底层存储引擎是否支持,目前InnoDB是支持的。注意ICP只能在联合索引参与查询的情况下才有用,因为是在索引树上做过滤,不涉及到数据行过滤
- InnoDB BufferPool(LRU队列5/8)优化
- 磁盘IO优化,比如不同的space、redo、undo文件都可以放到不同的磁盘上,或者RAID上,SSD, 加速IO