- 第一遍,看题目,想解法,如果十几分钟想不出解法,看题解,看别人的解法,最好能默写出来
- 第二遍,自己尝试写出
- 第三遍,隔几天后再次写一次,体会+自己的优化
- 第四遍,一周过去后,再来一遍
- 第五遍,复习
注意要将next数组求得的值减一,防止next数组对应的数字与下标相同导致的回溯时造成死循环。如下图


具体求next数组的代码如下
private int[] getNext(String s) {
char[] charArray = s.toCharArray();
int[] next = new int[charArray.length];
int j = -1;
next[0] = j;
for (int i = 1; i < charArray.length; i++) {
//注意这里时与j+1位置上进行比较,且j>=0
while (j >= 0 && charArray[i] != charArray[j+1]) {
j = next[j];
}
if (charArray[i] == charArray[j+1]) {
j++;
}
next[i] = j;
}
return next;
}KMP不仅可以解决字符串匹配问题,还可以判断一个字符串是否由它的一个子串重复多次构成
具体思路是检查next数组最后一位是否为-1;若不为-1则说明该字符串有最长的相同前后缀,再进行如下判断


具体代码如下
package com.github.aliez;
/**
* 459
*
* @author lm
* @date 2021/4/1 12:54
*/
public class Solution459 {
public boolean repeatedSubstringPattern(String s) {
if (s.length()==0){
return false;
}
char[] array = s.toCharArray();
int[] next = getNext(s);
return next[next.length - 1] != -1 && array.length % (array.length - (next[next.length - 1] + 1)) == 0;
}
private int[] getNext(String s){
char[] array = s.toCharArray();
int[] next = new int[array.length];
int j=-1;
next[0]=j;
for (int i=1;i<array.length;i++){
while (j>=0&&array[i]!=array[j+1]){
j=next[j];
}
if (array[i]==array[j+1]){
j++;
}
next[i]=j;
}
return next;
}
public static void main(String[] args) {
System.out.println(new Solution459().repeatedSubstringPattern("ababab"));
//true
}
}要注意,当输出栈有元素的时候,直接pop输出栈即可,没有元素时再将输入栈压入输出栈
具体代码如下
public int pop() {
//此处一定要先判断一下是否为空
if (!stack2.isEmpty()){
return stack2.pop();
}
pushToStack2();
return stack2.pop();
}
//讲输入栈压入输出栈
private void pushToStack2() {
while (!stack1.empty()) {
stack2.push(stack1.pop());
}
}
//当两个栈都没有元素的时候,队列空
public boolean empty() {
return stack2.empty() && stack1.empty();
}可以考虑简单的方法,只使用一个队列,入队前先取出队列的大小n,然后入队,再把前n个元素先出队后入队,这样新加入的元素就在队首了,代码如下
public void push(int x) {
int n = queue.size();
queue.offer(x);
for (int i = 0; i < n; i++) {
queue.offer(queue.poll());
}
}思路是依次将字符串压入栈,当遍历到当前的元素时与栈顶元素比较,若相同则弹栈,否则进栈
具体代码如下
public String removeDuplicates(String S) {
Stack<Character> characterStack1 = new Stack<>();
char[] array = S.toCharArray();
for (int i = 0; i < array.length; i++) {
if (!characterStack1.isEmpty()) {
if (array[i] == characterStack1.peek()) {
characterStack1.pop();
} else {
characterStack1.push(array[i]);
}
} else {
characterStack1.push(array[i]);
}
}
StringBuilder stringBuilder = new StringBuilder();
int size = characterStack1.size();
for (int i = 0; i < size; i++) {
stringBuilder.append(characterStack1.pop());
}
return stringBuilder.reverse().toString();
}需要注意的是遍历栈时千万不能把栈的大小当成for结束的条件,因为栈的大小是动态变化的。
错误示例如下
for (int i = 0; i < characterStack1.size(); i++) {
stringBuilder.append(characterStack1.pop());
}正确的做法应该是将 characterStack1.size()在for循环外取出
如下
int size = characterStack1.size();
for (int i = 0; i < size; i++) {
stringBuilder.append(characterStack1.pop());
} String str = "123";
Pattern pattern = Pattern.compile("[0-9]+");
Matcher matcher = pattern.matcher((CharSequence) str);
boolean result = matcher.matches();
if (result) {
System.out.println("true");
} else {
System.out.println("false");
}此题重难点是实现一个单调队列,队列里只维护可能为最大值的元素
实现滑动窗口,精髓在于此单调队列的pop()函数,每次移动时比较出窗口的元素与当前队首元素,若相等则说明此时最大值滑出窗口,要将队列中的队首元素弹出,
代码如下
public void pop(int value) {
if (!deque.isEmpty() && value == deque.getFirst()) {
deque.pollFirst();
}
}入队操作就是比较当前要入队的元素与队尾元素,当要入队的元素大于队尾元素时将队尾元素弹出,直到要入队的元素小于队尾元素或者队为空时将要入队的元素入队
public void push(int value) {
while (!deque.isEmpty() && value > deque.getLast()) {
deque.pollLast();
}
deque.offerLast(value);
}实际操作队列时,要先将前k个元素一次性入队也就是执行push(value)操作,入队完成后取队首元素加入ArryList中,之后的元素每次执行循环都要执行pop(value)操作,因为窗口是滑动的,每次需要判断出窗口的是否为队列中最大的元素,然后将第i个元素入队,最后将队首元素添加到ArryList中去。
public int[] maxSlidingWindow(int[] nums, int k) {
MyQueue myQueue = new MyQueue();
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < k; i++) {
myQueue.push(nums[i]);
}
list.add(myQueue.peek());
for (int i=k;i<nums.length;i++){
myQueue.pop(nums[i-k]);
myQueue.push(nums[i]);
list.add(myQueue.peek());
}
return list.stream().mapToInt(i->i).toArray();
}注意List数组可以通过list.stream().mapToInt(i->i).toArray();转换成int[]数组
此题应用优先级队列对数字出现的频率进行排序,优先级队列PriorityQueue数据结构为小顶堆,即最小的元素在队首,小顶堆是一个完全二叉树,其父节点不大于左右子节点的值
此题思路是利用getOrDefault()函数对数组数字出现的频率进行统计,key为数组中的数组,value为数组中该数字出现的频率,然后将map中的键值对入队,当队中元素大于K个是出队,由于总是出现频率最小的在队首,所以每次弹出的都是频率最小的元素,剩下的就是前K个高频元素
该题需要自定义Entry键值对,如下:
static class Entry<K, V> implements Map.Entry<K, V> {
private final K key;
private V value;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
@Override
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
}具体代码逻辑如下:
for (int num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
for (Integer integer : map.keySet()) {
queue.add(new Entry<>(integer, map.get(integer)));
if (queue.size() > k) {
queue.poll();
}
}另外,可以使用Map.Entry.comparingByValue();以Entry的值进行排序生成一个比较器
Comparator<Map.Entry<Integer, Integer>> byValue = Map.Entry.comparingByValue();构造优先级队列时将这个Comparator传入即可
PriorityQueue<Map.Entry<Integer, Integer>> queue = new PriorityQueue<>(byValue);递归解法较简单如下:
ArrayList<Integer> ans = new ArrayList<>();
private void preorder(TreeNode root) {
if (root == null) {
return;
}
ans.add(root.val);
preorder(root.left);
preorder(root.right);
}
public List<Integer> preorderTraversal(TreeNode root) {
preorder(root);
return ans;
}重点实现迭代解法,迭代解法利用了栈先入后出的特点,将二叉树的右节点先入栈,再将二叉树的左节点入栈,这样弹栈的时候,就是正常的顺序了
public List<Integer> preorderTraversal2(TreeNode root) {
List<Integer> ans = new ArrayList<>();
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode cur = stack.pop();
//注意此处顺序是反的,先入右边再入左边,弹栈时才会是先左后右
if (cur.right != null) {
stack.push(cur.right);
}
if (cur.left != null) {
stack.push(cur.left);
}
}
return ans;
}中序遍历迭代的思路是将树的左节点依次入栈,当左节点为空时弹栈,并将出栈的元素右节点赋值给当前root节点,如果出栈节点没有右节点,则不会进入while (root != null)循环
代码如下:
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if (root == null) {
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
while (!stack.isEmpty() || root != null) {
while (root != null) {
stack.push(root);
root = root.left;
}
root = stack.pop();
ans.add(root.val);
root = root.right;
}
return ans;
}迭代思路与单词的反转类似,are you ok ----> ok you are 可以先将每个单词逐个反转 era uoy ko,再整体反转 ok you are 此题类似
前序遍历的顺序是中左右 ---->中右左 ----> 左右中
后序遍历的顺序是左右中
具体思路时先将树的左节点入栈,再将右节点入栈,使用LinkedList保存,每次遍历前将栈顶元素弹出,头插法插入LinkedList,先遍历左节点后遍历右节点相当于局部反转,头插法相当于全局反转
具体代码如下
public List<Integer> postorderTraversal(TreeNode root) {
LinkedList<Integer> ans = new LinkedList<>();
if (root == null) {
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode cur = stack.pop();
ans.addFirst(cur.val);
if (cur.left != null) {
stack.push(cur.left);
}
if (cur.right != null) {
stack.push(cur.right);
}
}
return ans;
}解题思路:维护一个队列,取队列的长度进行出队操作,每次出队后将当前节点的左节点入队,右节点入队,将本次出队的元素加入到List集合中,再将本次循环得到的List数组加入的ans里
例如:
1
2 3
4 5 6 7
第一次入队1,队列大小为1,弹出1后队列加入2 3 第二次遍历队列大小为2 弹出2 3 入队 4 5 6 7 以此类推
具体代码如下:
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> ans = new ArrayList<>();
if (root == null) {
return ans;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
int size = queue.size();
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < size; i++) {
TreeNode cur = queue.poll();
assert cur != null;
list.add(cur.val);
if (cur.left != null) {
queue.offer(cur.left);
}
if (cur.right != null) {
queue.offer(cur.right);
}
}
ans.add(list);
}
return ans;
}此题思路是利用前序遍历的次序翻转当前节点左右节点的引用
利用迭代法写出二叉树前序遍历
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode cur = stack.pop();
TreeNode temp = cur.left;
cur.left = cur.right;
cur.right = temp;
if (cur.right != null) {
stack.push(cur.right);
}
if (cur.left != null) {
stack.push(cur.left);
}
}
return root;
}此题可以用递归法解,如下
public TreeNode invertTreePre(TreeNode root) {
if (root == null) {
return null;
}
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
invertTreePre(root.left);
invertTreePre(root.right);
return root;
}注意,用递归法写的时候,中序遍历如果不注意会将一个子树翻转两次
代码如下
/**
* 此解法为错误示范,中序遍历中间交换后右子树变成了左子树,这样做会将左子树翻转两次
* 正确解法应该是将invertTree(root.right); 改成 invertTree(root.left)
* @param root
* @return
*/
public TreeNode invertTreeIn(TreeNode root) {
if (root == null) {
return null;
}
invertTreeIn(root.left);
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
invertTreeIn(root.right);
return root;
}分几种情况
- 左右都为空,对称
- 左空右不空,不对称
- 左不空右空,不对称
- 左右都不为空,但是值不相等,不对称
- 左右都不为空吗,值也相等,对称
出现第5种情况后,可以递归比较两边外侧的节点,递归比较两边内测的节点
如果外侧节点和内侧节点都相同,则返回true
具体代码如下:
private boolean isSam(TreeNode left, TreeNode right) {
if (left == null && right == null) {
return true;
} else if (left != null && right == null) {
return false;
} else if (left == null && right != null) {
return false;
} else if (left.val != right.val) {
return false;
}
boolean out = isSam(left.left, right.right);
boolean inner = isSam(left.right, right.left);
return out && inner;
}迭代写法类似
注意Queue 的子类都不能实现插入null LinkedList可以插入null
代码如下:
public boolean isSymmetric2(TreeNode root) {
if (root == null) {
return true;
}
//LinkedList 允许push(null)
//Queue不允许添加null
LinkedList<TreeNode> stack = new LinkedList<>();
stack.push(root.right);
stack.push(root.left);
while (!stack.isEmpty()) {
TreeNode left = stack.pop();
TreeNode right = stack.pop();
if (left == null && right == null) {
continue;
}
if ((left == null || right == null || (left.val != right.val))) {
return false;
}
stack.push(left.left);
stack.push(right.right);
stack.push(left.right);
stack.push(right.left);
}
return true;
}此题可以用层序遍历的方法求出最大深度,代码如下
public int maxDepth2(TreeNode root) {
if (root == null) {
return 0;
}
Queue<TreeNode> queue =new LinkedList<>();
queue.offer(root);
int count=0;
while (!queue.isEmpty()){
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode cur = queue.poll();
if (cur.left!=null){
queue.offer(cur.left);
}
if (cur.right!=null){
queue.offer(cur.right);
}
}
count++;
}
return count;
}注意:此题指的最小深度时指从根节点到最近叶子节点的最短路径上的节点数量。
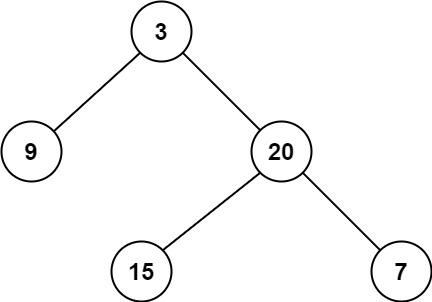
此时树的最小深度为2
解此题可用递归法解,
要注意两点,
- 当左子树为空,右子树不为空的时候,最小深度为右子树最小深度+1
- 当左子树不为空,右子树为空的时候,最小深度为左子树最小深度+1
代码如下:
相当于后序遍历 左右中
只有当左右孩子都为空的时候,才说明遍历的最低点了。如果其中一个孩子为空则不是最低点
public int minDepth(TreeNode root) {
if (root == null) {
return 0;
}
int leftDepth = minDepth(root.left);//左
int rightDepth = minDepth(root.right);//右
//中
if (root.left == null && root.right != null) {
return 1 + rightDepth;
}
if (root.left != null && root.right == null) {
return 1 + leftDepth;
}
return 1 + Math.min(leftDepth, rightDepth);
}迭代法写法要注意:当首次遍历到一个节点的左右子树均为空,则此时遍历的高度为二叉树的最小高度,此时应该退出循环,返回树的最小高度,利用了层序遍历的特点。
代码如下
public int minDepth2(TreeNode root) {
if (root == null) {
return 0;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int depth = 0;
while (!queue.isEmpty()) {
int size = queue.size();
depth++;
int flag = 0;
for (int i = 0; i < size; i++) {
TreeNode cur = queue.poll();
assert cur != null;
if (cur.left != null) {
queue.offer(cur.left);
}
if (cur.right != null) {
queue.offer(cur.right);
}
//当首次遍历到左右节点都为空的节点的时候说明此节点为最小高度,此时退出循环,flag的作用是告诉外层循环退出
if (cur.left == null && cur.right == null) {
flag = 1;
break;
}
}
if (flag == 1) {
break;
}
}
return depth;
}力扣实测,此解法耗时较少。
思路:分别求出左右子树的高度,然后如果差值小于等于1,则返回当前二叉树的高度,否则则返回-1,表示已经不是二叉树了
每次递归前判断左子树或者右子树的值是否为-1;若为-1则直接返回-1;说明该树不平衡
相当于后序遍历
代码如下
private int getDepth(TreeNode root) {
if (root == null) {
return 0;
}
int left = getDepth(root.left);
if (left == -1) {
return -1;
}
int right = getDepth(root.right);
if (right == -1) {
return -1;
}
int result;
if (Math.abs(left - right) > 1) {
result = -1;
} else {
result = Math.max(left, right) + 1;
}
return result;
}
public boolean isBalanced(TreeNode root) {
return getDepth(root) != -1;
}递归逻辑是判断当前节点是否为空,若不为空,则将当前节点加入到path路径中
-
如果当前节点是叶子节点,则将之前的
path加入到paths中去,也就是加入到List<String>中去 -
如果当前节点不是叶子节点,则将
path后面加->然后递归getPath()左子树和右子树
private void getPath(TreeNode root, String path, List<String> paths) {
if (root != null) {
StringBuilder sb = new StringBuilder(path);
sb.append(root.val);
//如果当前节点为叶子节点,说明已经遍历到最底层,加入List<String>中去即可
if (root.left == null && root.right == null) {
paths.add(sb.toString());
} else {
//如果当前节点不是叶子节点,继续递归
sb.append("->");
getPath(root.left, sb.toString(), paths);
getPath(root.right, sb.toString(), paths);
}
}
}此题根据当前节点不能判断是否是左子叶,要根据父节点判断
具体逻辑是父节点左子树不为空,左子树的左右子树都是空的时候,父节点的左子树就是左叶子节点
代码如下:
public int sumOfLeftLeaves(TreeNode root) {
if (root == null) {
return 0;
}
int middleValue = 0;
if (root.left != null && root.left.left == null && root.left.right == null) {
middleValue = root.left.val;
}
return middleValue + sumOfLeftLeaves(root.left) + sumOfLeftLeaves(root.right);
}迭代写法如下
public int sumOfLeftLeaves2(TreeNode root) {
if (root == null) {
return 0;
}
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
int result = 0;
while (!stack.isEmpty()) {
TreeNode cur = stack.pop();
if (cur.left != null && cur.left.left == null && cur.left.right == null) {
result += cur.left.val;
}
if (cur.right != null) {
stack.push(cur.right);
}
if (cur.left != null) {
stack.push(cur.left);
}
}
return result;
}解法:层序遍历,每层遍历的第一个赋值给ans,最后返回的ans就是最左下角的值
代码如下
注意,LinkedList 使用push的时候相当于栈,使用offer的时候相当于队列
public int findBottomLeftValue(TreeNode root) {
if (root == null) {
return 0;
}
LinkedList<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int ans=0;
while (!queue.isEmpty()) {
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode cur = queue.poll();
if (i == 0) {
ans = cur.val;
}
if (cur.left != null) {
queue.offer(cur.left);
}
if (cur.right != null) {
queue.offer(cur.right);
}
}
}
return ans;
}或者可以先添加右边的再添加左边的,这样就是从右到左层序遍历,最后一个赋值的就是ans;
递归解法
要注意返回true的条件是targetSum==root.val而非targetSum==0
public boolean hasPathSum(TreeNode root, int targetSum) {
if (root==null){
return false;
}
//当targetSum==root.val的时候,说明targetSum-root==0,此时路径存在,直接返回true;
if (root.left==null&&root.right==null&&targetSum==root.val){
return true;
}
return hasPathSum(root.left,targetSum- root.val)||hasPathSum(root.right,targetSum-root.val);
}也可以将所有路径的和保存在一个HashSet中,然后判断是否右targetSum
此解法耗时较长
private void getSum(TreeNode root, int sum, Set<Integer> sums) {
if (root != null) {
int newSum = sum;
if (root.left == null && root.right == null) {
newSum+=root.val;
sums.add(newSum);
} else {
newSum += root.val;
getSum(root.left, newSum, sums);
getSum(root.right, newSum, sums);
}
}
}此题思路是根据postorder数组中的最后一个数字确定当前节点的数值,
- 如果postorder数组为空,则返回null
- 如果postorder数组长度为1,说明该节点为叶子节点,直接返回即可
- 如果不是上面两种情况则对数组进行分割,从中序数组中找到后序数组中最后一个值的索引
- 根据索引将中序数组和后序数组分割成左右各两个
- 构造左子树,将中左,后左传入
- 构造右子树,将中右,后右传入
代码如下
注意分割数组的上下界问题
public TreeNode buildTree(int[] inorder, int[] postorder) {
if (postorder.length == 0) {
return null;
}
int rootValue = postorder[postorder.length - 1];
TreeNode root = new TreeNode(rootValue);
if (postorder.length == 1) {
return root;
}
int delimiterIndex;
for (delimiterIndex = 0; delimiterIndex < inorder.length; delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) {
break;
}
}
int[] inLeft = new int[delimiterIndex];
int[] inRight = new int[inorder.length - delimiterIndex - 1];
System.arraycopy(inorder, 0, inLeft, 0, delimiterIndex);
System.arraycopy(inorder, delimiterIndex + 1, inRight, 0, inorder.length - delimiterIndex - 1);
int[] postLeft = new int[delimiterIndex];
int[] postRight = new int[postorder.length - delimiterIndex - 1];
System.arraycopy(postorder, 0, postLeft, 0, delimiterIndex);
System.arraycopy(postorder, delimiterIndex, postRight, 0, postorder.length - delimiterIndex - 1);
root.left = buildTree(inLeft, postLeft);
root.right = buildTree(inRight, postRight);
return root;
}此题较简单,用迭代法和递归法各写一遍
递归比较当前节点的数值和目标数值
- 如果当前节点数值比目标数值大,则去节点的左子树寻找
- 如果当前节点数值比目标节点小,则去节点的右子树寻找
- 如果当前节点数值和目标数值相等,则放回当前节点
代码如下
递归法
public TreeNode searchBST(TreeNode root, int val) {
if (root == null) {
return null;
}
if (root.val == val) {
return root;
} else if (root.val > val) {
return searchBST(root.left, val);
} else {
return searchBST(root.right, val);
}
}迭代法
如果当前节点数值比目标数值大,左子树进栈,小则右子树进栈,相等返回当前树
public TreeNode searchBST2(TreeNode root, int val) {
if (root == null) {
return null;
}
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode cur = stack.pop();
if (cur.val == val) {
return cur;
}
if (cur.val > val && cur.left != null) {
stack.push(cur.left);
}
if (cur.val < val && cur.right != null) {
stack.push(cur.right);
}
}
return null;
}简单的迭代法如下
public TreeNode searchBST3(TreeNode root, int val) {
while (root != null) {
if (root.val > val) {
root = root.left;
} else if (root.val < val) {
root = root.right;
} else {
return root;
}
}
return null;
}思路就是当节点数值比目标数值大的时候令左子树等于当前节点,小的时候令右子树等于当前节点
相等直接返回即可
本题利用了二叉树中序遍历是个递增的有序序列的特征,把前一个遍历的节点存储起来,与当前节点比较,如果当前节点小于前一个节点,则说明不是二叉搜索树
具体代码如下
TreeNode pre;
public boolean isValidBST(TreeNode root) {
if (root == null) {
return true;
}
boolean left = isValidBST(root.left);
if (pre != null && root.val <= pre.val) {
return false;
}
//记录前一个节点
pre = root;
boolean right = isValidBST(root.right);
return left && right;
}和上一题类似
代码如下:
TreeNode pre;
int minAbs=Integer.MAX_VALUE;
public void travel(TreeNode root) {
if (root == null) {
return;
}
travel(root.left);
if (pre != null) {
minAbs = Math.min(root.val - pre.val, minAbs);
}
pre = root;
travel(root.right);
}
public int getMinimumDifference(TreeNode root) {
travel(root);
return minAbs;
}此题定义一个count用于统计树中的某一个元素出现的个数
maxCount用于统计树中出现最多的那个数
定义一个pre指向遍历二叉树时的前一个节点
中序遍历,当前一个节点的数值与当前遍历到的数值相等时,count++;否则将count置1
如果当前count等于maxCount说明此数为众数,加入到List集合中去
如果当前count大于maxCount说明此数是新的众数
令maxCount=count,将队列清空然后再加入当前节点的数值即可
注意一定要先将队列清空再添加元素,因为当出现count大于maxCount的时候,队列里维护的就不再是众数了,应该及时删去,添加上新的众数
代码如下
public int[] findMode(TreeNode root) {
int maxCount = 0;
int count = 0;
TreeNode pre = null;
List<Integer> ans = new ArrayList<>();
if (root == null) {
return ans.stream().mapToInt(i -> i).toArray();
}
Deque<TreeNode> stack = new ArrayDeque<>();
while (!stack.isEmpty() || root != null) {
while (root != null) {
stack.push(root);
root = root.left;
}
root = stack.pop();
if (pre == null) {
count = 1;
} else if (pre.val == root.val) {
count++;
} else {
count = 1;
}
if (count == maxCount) {
ans.add(root.val);
}
if (count > maxCount) {
maxCount = count;
ans.clear();
ans.add(root.val);
}
pre = root;
root = root.right;
}
return ans.stream().mapToInt(i -> i).toArray();
}此题利用后序遍历,自底向上层层回溯
当遇到root与p或者q相等或者root为空的时候返回root
遍历左子树和右子树,当左子树或者右子树有返回值的时候返回左子树或者右子树
如果左右子树返回值都为空,则返回null
代码如下
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == p || root == q || root == null) {
return root;
}
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
if (left != null && right != null) {
return root;
}
if (left == null) {
return right;
}
return left;
}此题解法巧妙,前序遍历,如果当前节点在p和q的区间内则直接返回
如果<---[]当前节点比p和q都小,则遍历该树的右子树
如果[]--->当前节点比p和q都大,则遍历该树的左子树
如果[----]则直接返回当前节点
代码如下
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while (root != null) {
if (root.val > q.val && root.val > p.val) {
root = root.left;
} else if (root.val < p.val && root.val < q.val) {
root = root.right;
} else {
return root;
}
}
return null;
}此题为搜索二叉搜索树中的插入位置
递归解法为判断当前节点值是否大于给定的值,如果大于则判断当前节点左子树是否为空,若为空则直接插入,若不为空则递归插入左子树,右边类似
需要注意,当树为空的时候,插入的值直接作为该树本身返回
代码如下
public void insert(TreeNode root, int val) {
if (root == null) {
return;
}
if (root.val > val) {
if (root.left != null) {
insert(root.left, val);
} else {
root.left = new TreeNode(val);
return;
}
}
if (root.val < val) {
if (root.right != null) {
insert(root.right, val);
} else {
root.right = new TreeNode(val);
return;
}
}
}
public TreeNode insertIntoBST(TreeNode root, int val) {
if (root == null) {
return new TreeNode(val);
}
insert(root, val);
return root;
}精简解法
public TreeNode insertIntoBST2(TreeNode root, int val) {
if (root == null) {
return new TreeNode(val);
}
if (root.val > val) {
root.left = insertIntoBST2(root.left, val);
}
if (root.val < val) {
root.right = insertIntoBST2(root.right, val);
}
return root;
}迭代写法
注意while循环过后cur为空 cur的父节点为pre也就是要插入的val要插在pre节点的左子树或者右子树上
判断一下再插入即可
public TreeNode insertIntoBST3(TreeNode root, int val) {
if (root == null) {
return new TreeNode(val);
}
TreeNode cur = root;
TreeNode pre = root;
while (cur != null) {
pre = cur;
if (cur.val > val) {
cur = cur.left;
}
if (cur.val < val) {
cur = cur.right;
}
}
TreeNode node = new TreeNode(val);
if (val < pre.val) {
pre.left =node;
}else {
pre.right=node;
}
return root;
}思路:首先要找到当前要删除的节点,如果当前节点为空则直接返回空即可
如果当前节点值与key相同,则进入判断
- 当前节点的左子树为空,返回当前节点的右子树即可
- 当前节点右子树为空,返回当前节点的左子树即可
- 如果当前左子树和右子树都不为空,则将当前节点的左子树插入到当前节点的右子树的最左边的节点的左子树上,也就是比左子树数值大的最小的数的位置上
- 如果当前节点数值大于key,则向左子树中寻找并删除
- 如果当前节点小于key,则向右子树中寻找并删除
具体代码如下
public TreeNode deleteNode2(TreeNode root, int key) {
if (root == null) {
return null;
}
if (root.val == key) {
if (root.left == null) {
return root.right;
} else if (root.right == null) {
return root.left;
} else {
TreeNode cur = root.right;
while (cur.left != null) {
cur = cur.left;
}
cur.left = root.left;
//将当前节点删除
root = root.right;
return root;
}
}
if (root.val > key) {
root.left = deleteNode(root.left, key);
}
if (root.val < key) {
root.right = deleteNode(root.right, key);
}
return root;
}迭代写法如下,要保存当前遍历到的节点的前一个节点,定义一个指针pre
当pre为空时说明该二叉搜索树只有一个根节点,返回null即可
当pre左子树不为空且左子树的数值等于key时,进入删除逻辑
- 当左子树的右子树为空时,令pre节点的左子树也就是cur节点等于cur的左子树即可
- 当cur的左子树为空时,令cur等于cur的右子树即可
- 当cur的左右子树都不为空时,将cur的左子树插入到cur右子树的最左子树的左子树上,也就是cur的左子树的后继节点,比cur左子树数值大的最小的树的位置上,然后返回cur的右子树即可
代码如下
public TreeNode deleteNode(TreeNode root, int key) {
if (root == null) {
return null;
}
TreeNode cur = root;
TreeNode pre = null;
while (cur != null) {
if (cur.val == key) {
break;
}
pre = cur;
if (cur.val > key) {
cur = cur.left;
}
if (cur.val < key) {
cur = cur.right;
}
}
//未找到要删除的节点,直接返回root节点即可
if(cur==null){
return root;
}
//只有头节点的情况
if (pre == null) {
return deleteOneNode(cur);
}
if (pre.left != null && pre.left.val == key) {
pre.left = deleteOneNode(cur);
}
if (pre.right != null && pre.right.val == key) {
pre.right = deleteOneNode(cur);
}
return root;
}
其中删除逻辑如下
private TreeNode deleteOneNode(TreeNode cur) {
if (cur == null) {
return null;
}
if (cur.right == null) {
return cur.left;
}
if (cur.left==null){
return cur.right;
}
TreeNode temp = cur.right;
while (temp.left != null) {
temp = temp.left;
}
temp.left = cur.left;
return cur.right;
}/**
* 有返回值,更好操作
* 当当前节点的数值比low小或者比high大的时候删除该节点
* 比low小 删除该节点的左子树
* 修剪右子树
* 比high大 删除该节点的右子树
* 修剪左子树
*
* @param root
* @param low
* @param high
* @return
*/
public TreeNode trimBST(TreeNode root, int low, int high) {
if (root == null) {
return null;
}
if (root.val < low) {
return trimBST(root.right, low, high);
}
if (root.val > high) {
return trimBST(root.left, low, high);
}
root.left = trimBST(root.left, low, high);
root.right = trimBST(root.right, low, high);
return root;
}如下代码相当于把节点0的右孩子节点2返回个上一层
if (root.val < low) {
return trimBST(root.right, low, high);
}然后下面代码相当于用节点3的左孩子把下一层返回的节点0的右孩子,节点2接住
root.left = trimBST(root.left, low, high);此时节点3的右孩子就变成了节点2,将节点0从二叉搜索树中删除了
解题思路:
取数组中的中间元素当成一次遍历的根节点,然后利用类似二分查找的特点构造左子树和右子树
private TreeNode traversal(int[] nums, int left, int right) {
if (left > right) {
return null;
}
int mid = left + ((right - left) / 2);
TreeNode root = new TreeNode(nums[mid]);
root.left = traversal(nums, left, mid - 1);
root.right = traversal(nums, mid + 1, right);
return root;
}
public TreeNode sortedArrayToBST(int[] nums) {
return traversal(nums, 0, nums.length - 1);
}此题利用了二分查找的特点,是一道经典题
此题思路是,累加树反中序遍历是有序的,只需要定义一个sum,令sum=前一个节点的数值,每次遍历到一个节点只要将数值+sum即可
代码如下
int sum = 0;
public TreeNode convertBST(TreeNode root) {
if (root == null) {
return null;
}
TreeNode right = convertBST(root.right);
int temp = root.val;
root.val += sum;
sum += temp;
TreeNode left = convertBST(root.left);
return root;
}终止条件:当path的大小等于k的时候,向结果集中添加new ArrayList<>(path)注意此时一定不能添加path过去,因为path在后续过程中一直在改变
具体代码如下:
LinkedList<Integer> path = new LinkedList<>();
List<List<Integer>> ans = new ArrayList<>();
private void backtracking(int n, int k, int startIndex) {
if (path.size() == k) {
ans.add(new ArrayList<>(path));
return;
}
for (int i = startIndex; i <= n; i++) {
path.add(i);
System.out.println("递归之前" + path);
backtracking(n, k, i + 1);
path.removeLast();
System.out.println("递归之后" + path);
}
}
public List<List<Integer>> combine(int n, int k) {
backtracking(n, k, 1);
return ans;
}掌握调试技巧对理解回溯算法有重大意义
当n=5,k=4的时候,
如果当前path中已经有0个元素,则说明还需要4个元素,搜索起点最大为2
如果当前path中已经有1个元素,则说明还需要3个元素,搜索起点最大为3
如果当前path中已经有2个元素,则说明还需要2个元素,搜索起点最大为4
如果当前path中已经有3个元素,则说明还需要1个元素,搜索起点最大为5
可以得出
搜索起点的上界 + 接下来要选择的元素个数 - 1 = n
n - (k - path.size()) + 1就是搜索起点的上界
剪枝优化后的代码如下
LinkedList<Integer> path = new LinkedList<>();
List<List<Integer>> ans = new ArrayList<>();
private void backtracking(int n, int k, int startIndex) {
if (path.size() == k) {
ans.add(new ArrayList<>(path));
return;
}
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) {
path.add(i);
System.out.println("递归之前" + path);
backtracking(n, k, i + 1);
path.removeLast();
System.out.println("递归之后" + path);
}
}
public List<List<Integer>> combine(int n, int k) {
backtracking(n, k, 1);
return ans;
}此题与组合问题类似,但是要注意回溯的终止条件,以及要定义一个sum,sum在上一帧返回之后要进行回溯,path也要进行回溯
代码如下
LinkedList<Integer> path = new LinkedList<>();
List<List<Integer>> ans = new ArrayList<>();
int sum = 0;
private void backtracking(int k, int n, int startIndex) {
if (sum>n){
return;
}
if (path.size() == k) {
if (sum == n) {
ans.add(new ArrayList<>(path));
return;
}
}
for (int i = startIndex; i <= 9; i++) {
sum += i;
path.add(i);
backtracking(k, n, i + 1);
sum -= i;
path.pollLast();
}
}
public List<List<Integer>> combinationSum3(int k, int n) {
backtracking(k, n, 1);
return ans;
}对该回溯算法剪枝优化,需要注意当遍历的时候sum已经大于targetNum的时候直接返回到上一栈帧即可
注意该题将数字与字母的映射关系添加到map中极为方便
另外,在取出每个字符串时一定要记得将当前字符串-‘0’方可得到当前字符串对应的数字
这题每个数字对应的字符串的长度为遍历的宽度,数字的数目为回溯的深度,每次回溯深度+1,然后遍历宽度
index指的是遍历的深度,也作为回溯返回的条件,同时也是每次回溯时取出哪个digit的依据
代码如下
List<String> ans = new ArrayList<>();
StringBuilder sb = new StringBuilder();
Map<Integer, String> map = new HashMap<>(16);
private void backtracking(char[] array, int index) {
if (index == array.length) {
ans.add(String.valueOf(sb));
return;
}
int digit = array[index] - '0';
String letters = map.get(digit);
for (int i = 0; i < letters.length(); i++) {
sb.append(letters.charAt(i));
backtracking(array, index + 1);
sb.deleteCharAt(sb.length() - 1);
}
}
public List<String> letterCombinations(String digits) {
if (digits.length() == 0) {
return Collections.emptyList();
}
map.put(0, "");
map.put(1, "");
map.put(2, "abc");
map.put(3, "def");
map.put(4, "ghi");
map.put(5, "jkl");
map.put(6, "mno");
map.put(7, "pqrs");
map.put(8, "tuv");
map.put(9, "wxyz");
char[] array = digits.toCharArray();
backtracking(array, 0);
return ans;
}此题为回溯法经典题型
要注意,不能有重复的集合,当选了第0个的时候,接下来能从0开始选,当选了第1个的时候,接下来只能从1开始选了,剪枝优化是当sum>target的时候直接返回
代码如下
记录第一次 一次AC
LinkedList<Integer> path = new LinkedList<>();
List<List<Integer>> ans = new ArrayList<>();
int sum = 0;
private void backtracking(int[] candidates, int target, int startIndex) {
if (sum > target) {
return;
}
if (sum == target) {
ans.add(new ArrayList<>(path));
return;
}
for (int i = startIndex; i < candidates.length; i++) {
path.add(candidates[i]);
sum += candidates[i];
backtracking(candidates, target, i);
sum -= candidates[i];
path.removeLast();
}
}
public List<List<Integer>> combinationSum(int[] candidates, int target) {
backtracking(candidates, target, 0);
return ans;
}注意此题要求是给定的数组中有重复数组,但是找出的组合不能有重复的,涉及到去重逻辑
输入: candidates = [10,1,2,7,6,1,5], target = 8,
所求解集为:
[
[1, 7],
[1, 2, 5],
[2, 6],
[1, 1, 6]
]
注意:该题可以出现[1,1,6]这样的解集但是不允许[1,2,5]这样的解集出现两次
思路是先排序数组,每次回溯过后,令当前数组元素等于pre,下次循环时如果pre与当前遍历到的元素相等,则直接跳过该层循环,相当于在整颗树上去重第一次选了1,第二次就不能重复选1了,但是每颗节点可以任意选择
代码如下
LinkedList<Integer> path = new LinkedList<>();
List<List<Integer>> ans = new ArrayList<>();
int sum = 0;
int pre = 0;
private void backtracking(int[] candidates, int target, int startIndex) {
if (sum > target) {
return;
}
if (sum == target) {
ans.add(new ArrayList<>(path));
return;
}
for (int i = startIndex; i < candidates.length&&candidates[i]+sum<=target; i++) {
if (pre == candidates[i]) {
continue;
}
path.add(candidates[i]);
sum += candidates[i];
backtracking(candidates, target, i + 1);
sum -= candidates[i];
path.removeLast();
pre = candidates[i];
}
}
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
backtracking(candidates, target, 0);
return ans;
}此题难点是切割点的选择,将startIndex到i切割出来然后判断是否为回文串,如果不是则跳过该层循环,如果是则加入到path中去。
代码如下
此题尽量不要使用string的substring方法
自己通过String字符串的构造方法构造字符串
subString()方法的参数是开始位置beginIndex和结束位置endIndex
LinkedList<String> path = new LinkedList<>();
List<List<String>> ans = new ArrayList<>();
private boolean isPalindrome(char[] array, int left, int right) {
while (right > left) {
if (array[left] != array[right]) {
return false;
}
left++;
right--;
}
return true;
}
private void backtracking(char[] array, int startIndex) {
if (startIndex >= array.length) {
ans.add(new ArrayList<>(path));
return;
}
for (int i = startIndex; i < array.length; i++) {
if (!isPalindrome(array, startIndex, i)) {
continue;
}
String substring = new String(array, startIndex, i + 1 - startIndex);
path.add(substring);
backtracking(array, i + 1);
path.removeLast();
}
}
public List<List<String>> partition(String s) {
char[] array = s.toCharArray();
backtracking(array, 0);
return ans;
}此题求子集是收集所有节点,所以不必在判断的时候加入结果集,直接加入即可
代码如下
LinkedList<Integer> path = new LinkedList<>();
List<List<Integer>> ans = new ArrayList<>();
private void backtracking(int[] nums, int startIndex) {
ans.add(new ArrayList<>(path));
if (startIndex >= nums.length) {
return;
}
for (int i = startIndex; i < nums.length; i++) {
path.add(nums[i]);
backtracking(nums, i + 1);
path.removeLast();
}
}
public List<List<Integer>> subsets(int[] nums) {
Arrays.sort(nums);
backtracking(nums, 0);
return ans;
}此题要注意,之前使用过的元素可以重复使用,但是已经在path中的不能再重复使用了
定义一个boolean数组,数组大小和给定数组的大小相同,记录再path中的元素
代码如下
LinkedList<Integer> path = new LinkedList<>();
List<List<Integer>> ans = new ArrayList<>();
boolean[] used;
private void backtracking(int[] nums) {
if (path.size() == nums.length) {
ans.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < nums.length; i++) {
if (used[i]) {
continue;
}
path.add(nums[i]);
used[i] = true;
backtracking(nums);
used[i] = false;
path.removeLast();
}
}
public List<List<Integer>> permute(int[] nums) {
used = new boolean[nums.length];
Arrays.fill(used, false);
backtracking(nums);
return ans;
}与上题类似,但是要加上树层去重的功能,所以再for循环外面定义一个hashset检测到hashset中有当前元素的时候就直接continue
代码如下
LinkedList<Integer> path = new LinkedList<>();
List<List<Integer>> ans = new ArrayList<>();
boolean[] used;
private void backtracking(int[] nums){
if(path.size()==nums.length){
ans.add(new ArrayList(path));
return;
}
Set<Integer> hashset = new HashSet<>();
for(int i=0;i<nums.length;i++){
if(used[i]||hashset.contains(nums[i])){
continue;
}
path.add(nums[i]);
used[i]=true;
hashset.add(nums[i]);
backtracking(nums);
used[i]=false;
path.removeLast();
}
}
public List<List<Integer>> permuteUnique(int[] nums) {
used = new boolean[nums.length];
Arrays.fill(used,false);
backtracking(nums);
return ans;
}重点理解 同一行不能有两个,同一列不能有两个,对角线不能有两个
这样判断是否能放皇后的逻辑就变成了
因为每次都是遍历一行,只取一个元素,所以不需要判断一行中有重复的皇后
因为在单层搜索的过程中,每一层递归,只会选for循环(也就是同一行)里的一个元素,所以不用去重了。
将棋盘定义为一个char型二维数组
其中每一行是ans中的一个list
private boolean isValid(int n, int row, int col) {
//同一列有Q
for (int i = 0; i < n; i++) {
if (chessboard[i][col] == 'Q') {
return false;
}
}
//45°对角线有Q
for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
//135°对角线有Q
for (int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
return true;
}完整代码如下
List<List<String>> ans = new ArrayList<>();
char[][] chessboard;
private boolean isValid(int n, int row, int col) {
//同一列有Q
for (int i = 0; i < n; i++) {
if (chessboard[i][col] == 'Q') {
return false;
}
}
//45°对角线有Q
for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
//135°对角线有Q
for (int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
if (chessboard[i][j] == 'Q') {
return false;
}
}
return true;
}
private void backtracking(int n, int row) {
if (row == n) {
List<String> path = new ArrayList<>();
for (int i = 0; i < n; i++) {
path.add(new String(chessboard[i]));
}
ans.add(path);
}
for (int col = 0; col < n; col++) {
if (isValid(n, row, col)) {
chessboard[row][col] = 'Q';
backtracking(n, row + 1);
chessboard[row][col] = '.';
}
}
}
public List<List<String>> solveNQueens(int n) {
chessboard = new char[n][n];
for (int i = 0; i < n; i++) {
Arrays.fill(chessboard[i], '.');
}
backtracking(n, 0);
return ans;
}总体思想是局部最优从而达到全局最优
大的饼干最先满足它能满足胃口最大的孩子,因为只需要返回满足几个孩子,将数组排序后从后向前遍历数组g,判断s[index]是否大于等于g[i]若大于则说明找到了,小于则说明这块饼干满足不了这个孩子,i--即可
代码如下
public int findContentChildren(int[] g, int[] s) {
int index = s.length - 1;
int count = 0;
Arrays.sort(g);
Arrays.sort(s);
for (int i = g.length - 1; i >= 0; i--) {
if (index >= 0 && s[index] >= g[i]) {
index--;
count++;
}
}
return count;
}局部最优是大块饼干先满足胃口大的孩子,全局最优是饼干满足最多的孩子
此题利用贪心算法,删除除去收尾的递增或递减节点,该题解法较为巧妙,比较前一对差值和当前一对差值,如果当前一对差值和前一对差值符号不同,则说明遇到峰值,将result++即可,统计峰值的个数即为摆动序列的最大长度
代码如下
public int wiggleMaxLength(int[] nums) {
if (nums.length <= 2) {
return nums.length;
}
//当前一对的差值
int curDiff = 0;
//前一对的差值
int preDiff = 0;
//峰值个数
int result = 1;
for (int i = 1; i < nums.length; i++) {
curDiff = nums[i] - nums[i - 1];
if ((curDiff > 0 && preDiff <= 0) || (preDiff >= 0 && curDiff < 0)) {
result++;
preDiff = curDiff;
}
}
return result;
}时间复杂度为O(n)
遍历nums,从头开始用count累积,如果count一旦加上nums[i]变为负数,那么就应该从nums[i+1]开始从0累积count了,因为已经变为负数的count,只会拖累总和。
代码如下
public int maxSubArray(int[] nums) {
int ans = Integer.MIN_VALUE;
int count = 0;
for (int num : nums) {
count += num;
if (count > ans) {
ans = count;
}
if (count <= 0) {
count = 0;
}
}
return ans;
}每次只收集正利润,最后收集的利润是最高的,局部最优推导出全局最优
public int maxProfit(int[] prices) {
int result = 0;
for (int i = 1; i < prices.length; i++) {
result += Math.max(prices[i] - prices[i - 1], 0);
}
return result;
}此题利用贪心算法,判断能否到达最后一个只需要判断覆盖范围是否能到数组长度-1即可
定义一个for循环在0和cover中循环每次遇到比cover大的覆盖范围就把大的覆盖范围赋值给cover
最后判断一下cover是否大于等于数组长度-1即可
贪心算法
public boolean canJump(int[] nums) {
if (nums.length == 1) {
return true;
}
int cover = nums[0];
for (int i = 0; i <= cover; i++) {
cover = Math.max(nums[i] + i, cover);
if (cover >= nums.length - 1) {
return true;
}
}
return false;
}定义一个curDistance记录当前达到的最大距离,定义一个nextDistance记录当前覆盖范围内的元素的最大f覆盖范围如果当前指针达到了curDistance最大范围则判断一下当前curDistance是否达到数组最后一个元素,如果有直接返回结果即可,如果没有则步数加1,将nextDistance赋值给curDistance
代码如下
public int jump(int[] nums) {
if (nums.length == 1) {
return 0;
}
int step = 0;
int curDistance = 0;
int nextDistance = 0;
for (int i = 0; i <= nums.length; i++) {
//下一步能覆盖的最大范围
nextDistance = Math.max(nums[i] + i, nextDistance);
//走到当前最大覆盖范围了
if (i == curDistance) {
//还没有到最后一个元素
if (curDistance != nums.length - 1) {
step++;
curDistance = nextDistance;
if (nextDistance >= nums.length - 1) {
break;
}
} else {
break;
}
}
}
return step;
}此题用到快速排序,不熟悉快速排序导致算法时间复杂度底下
此题利用贪心算法,如果数组中有绝对值大的负数则先翻转绝对值大的负数,如果全部都为正了则将最小的那个数反复反转直到K为0
快速排序算法如下,此题是利用绝对值来排序
private void quickSort(int[] nums, int left, int right) {
if (left < right) {
int partitionIndex = partition(nums, left, right);
quickSort(nums, left, partitionIndex - 1);
quickSort(nums, partitionIndex + 1, right);
}
}
private int partition(int[] nums, int left, int right) {
swap(nums, left, (left + right) >> 1);
int pivot = left;
int index = pivot + 1;
for (int i = index; i <= right; i++) {
if (Math.abs(nums[i]) > Math.abs(nums[pivot])) {
swap(nums, i, index);
index++;
}
}
swap(nums, pivot, --index);
return index;
}
private void swap(int[] nums, int p1, int p2) {
if (p1 == p2) return;
int tmp = nums[p1];
nums[p1] = nums[p2];
nums[p2] = tmp;
}完整无快速排序的代码如下
public int largestSumAfterKNegations(int[] A, int K) {
int sum = 0;
int[] absA = Arrays.stream(A).boxed().sorted(Comparator.comparingInt(Math::abs)).mapToInt(i -> i).toArray();
for (int i = absA.length - 1; i >= 0; i--) {
if (absA[i] < 0 && K > 0) {
absA[i] *= -1;
K--;
}
sum += absA[i];
}
if (K > 0 && K % 2 != 0) {
return sum - 2 * absA[0];
}
return sum;
}此题利用贪心算法,如果当前前面剩余总和小于0了,则说明至少要从后面一个开始才能保证跑一圈,如果还小于0则再后面一个
具体代码如下
如果全部总和都小于0说明无论从哪开始都跑不了一圈
public int canCompleteCircuit(int[] gas, int[] cost) {
int minAbsCost = Integer.MAX_VALUE;
int start = 0;
int totalSum = 0;
int curSum = 0;
for (int i = 0; i < gas.length; i++) {
curSum += gas[i] - cost[i];
totalSum += gas[i] - cost[i];
if (curSum < 0) {
start = i + 1;
curSum = 0;
}
}
if (totalSum < 0) {
return -1;
}
return start;
}此题 10元 5元都是固定套路,当顾客给20的时候要优先找给顾客10元,因为相对于10元5元更加万能
具体代码如下
public boolean lemonadeChange(int[] bills) {
int five = 0;
int ten = 0;
for (int bill : bills) {
if (bill == 5) {
five++;
}
if (bill == 10) {
if (five != 0) {
five--;
ten++;
} else {
return false;
}
}
if (bill == 20) {
if (ten != 0) {
if (five != 0) {
ten--;
five--;
} else {
return false;
}
} else if (five >= 3) {
five -= 3;
} else {
return false;
}
}
}
return true;
}此题先使用快速排序对二维数组进行升序排序,然后比对后一个的上界与前一个的下界,如果有重叠即后一个上界小于上一个下界此时需要一个气球引爆当前遍历到的气球,不断更新右边界,右边界为最小右边界,如果后一个比最小右边界大则需要一个箭
代码如下
private void quickSort(int[][] nums, int left, int right) {
if (left < right) {
int partitionIndex = partition(nums, left, right);
quickSort(nums, left, partitionIndex - 1);
quickSort(nums, partitionIndex + 1, right);
}
}
private int partition(int[][] nums, int left, int right) {
swap(nums, left, (left + right) >> 1);
int pivot = left;
int index = pivot + 1;
for (int i = index; i <= right; i++) {
if (nums[i][0] < nums[pivot][0]) {
swap(nums, i, index);
index++;
}
}
swap(nums, pivot, --index);
return index;
}
private void swap(int[][] nums, int p1, int p2) {
if (p1 == p2) {
return;
}
int[] tmp = nums[p1];
nums[p1] = nums[p2];
nums[p2] = tmp;
}
public int findMinArrowShots(int[][] points) {
if (points.length == 0) {
return 0;
}
quickSort(points, 0, points.length - 1);
int ans = 1;
for (int i = 1; i < points.length; i++) {
if (points[i][0] > points[i - 1][1]) {
ans++;
} else {
points[i][1] = Math.min(points[i - 1][1], points[i][1]);
}
}
return ans;
}按照上界排序,上界小的说明留给后面的多,按照右边界排序,就要从左向右遍历,因为右边界越小越好,只要右边界越小,留给下一个区间的空间就越大,所以从左向右遍历,优先选右边界小的。
我们要选最多的非交叉区间,最后用区间总数减去非交叉区间就能算出最少移除多少就能不重复
每次取非交叉区间的时候,都是取右边界最小的来做分割点(这样留给下一个区间的空间就越大),所以第一条分割线就是区间1结束的位置
代码如下
private void quickSort(int[][] nums, int left, int right) {
if (left < right) {
int partitionIndex = partition(nums, left, right);
quickSort(nums, left, partitionIndex - 1);
quickSort(nums, partitionIndex + 1, right);
}
}
private int partition(int[][] nums, int left, int right) {
swap(nums, left, (left + right) >> 1);
int pivot = left;
int index = pivot + 1;
for (int i = index; i <= right; i++) {
if (nums[i][1] < nums[pivot][1]) {
swap(nums, i, index);
index++;
}
}
swap(nums, pivot, --index);
return index;
}
private void swap(int[][] nums, int p1, int p2) {
if (p1 == p2) {
return;
}
int[] tmp = nums[p1];
nums[p1] = nums[p2];
nums[p2] = tmp;
}
public int eraseOverlapIntervals(int[][] intervals) {
if (intervals.length == 0) {
return 0;
}
quickSort(intervals, 0, intervals.length - 1);
int count = 1;
int end = intervals[0][1];
for (int i = 1; i < intervals.length; i++) {
//记录非交叉区间
if (end <= intervals[i][0]) {
end = intervals[i][1];
count++;
}
}
//返回区间总数减去非交叉区间就是要求的
return intervals.length - count;
}以上QuickSort可以使用下面一行代码代替
Arrays.sort(intervals, Comparator.comparingInt(a -> a[1]));此题思路是统计每一个字母的边界**「如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点了」**。此时前面出现过所有字母,最远也就到这个边界了。
具体步骤如下
- 统计每一个字符最后出现的位置
- 从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点
代码如下
public List<Integer> partitionLabels(String S) {
List<Integer> ans = new ArrayList<>();
char[] array = S.toCharArray();
int[] alpha = new int[27];
for (int i = 0; i < array.length; i++) {
alpha[array[i] - 'a'] = i;
}
int left = 0;
int right = 0;
for (int i = 0; i < array.length; i++) {
right = Math.max(right, alpha[array[i] - 'a']);
if (i == right) {
ans.add(right - left + 1);
left = i + 1;
}
}
return ans;
}按照每个数组的左边界排序,将数组添加到list集合中,当遇到下一个数组的左边界小于等于当前list中的最后一个的右边界的时候,说明有重叠,更新list中数组的右边界的值即可,如果大于,直接加入到list数组中去即可
代码如下
public int[][] merge(int[][] intervals) {
LinkedList<int[]> list = new LinkedList<>();
if (intervals.length == 1) {
return intervals;
}
Arrays.sort(intervals, Comparator.comparingInt(a -> a[0]));
list.add(intervals[0]);
for (int i = 1; i < intervals.length; i++) {
if (list.peekLast()[1] >= intervals[i][0]) {
list.peekLast()[1] = Math.max(list.peekLast()[1], intervals[i][1]);
} else {
list.add(intervals[i]);
}
}
int[][] ans = new int[list.size()][];
ListIterator<int[]> it = list.listIterator();
int i = 0;
while (it.hasNext()) {
ans[i] = it.next();
i++;
}
return ans;
}如下方法可以直接将List<int[]> list转换成int[][]
return list.toArray(new int[list.size()][]);此题使用贪心算法未理解,后期使用动态规划解题
动态规划中每一个状态一定是由上一个状态推导出来的,这一点就区分于贪心,贪心没有状态推导,而是从局部直接选最优的,
解题步骤
- 确定
dp数组(dp table)以及下标的含义 - 确定递推公式
dp数组如何初始化- 确定遍历顺序
- 举例推导
dp数组
经典的dp题,根据前两个的状态推出当前的状态,但是要注意DP数组初始化的大小,DP数组应初始化为n+1
代码如下
public int fib(int n) {
if (n == 0) {
return 0;
}
if (n == 1) {
return 1;
}
int[] dp = new int[n+1];
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i < n+1; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}此题与上一题斐波那契数类似
难点是推导出dp数组的状态转移公式,当在第一层的时候,只有一种方法,第二层的时候,有两种,第三层的时候有三种,第四层的时候有五种,推出公式为dp[i]=dp[i-1]+dp[i+2]
代码如下
public int climbStairs(int n) {
if (n <= 2) {
return n;
}
int[] dp = new int[n + 1];
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}此题可以从第一层第二层来开始,dp[i]是由dp[i-1] dp[i-2]推出,取最小的可以确定递推公式为
dp[i] = Math.min(dp[i - 1], dp[i - 2]) + cost[i];
最后不要忘了返回的时候比较一下倒数第一个和倒数第二个的大小,因为dp[i-1]不一定是最小花费,也可能是dp[i-2]
代码如下
public int minCostClimbingStairs(int[] cost) {
int[] dp = new int[cost.length];
dp[0] = cost[0];
dp[1] = cost[1];
for (int i = 2; i < cost.length; i++) {
dp[i] = Math.min(dp[i - 1], dp[i - 2]) + cost[i];
}
return Math.min(dp[cost.length - 1], dp[cost.length - 2]);
}确定dp数组的含义:dp[i][j]表示(i,j)位置上有多少种方式到达
当i为0或者j为0的时候由常识可知只有一种方式可以到达
不为0的时候当前的dp[i][j]是由上一个或者左一个决定的,将他们相加就是当前由多少种方式可以到达
dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
具体代码如下
public int uniquePaths(int m, int n) {
int[][] dp = new int[m][n];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (i == 0 || j == 0) {
dp[i][j] = 1;
} else {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
}
return dp[m - 1][n - 1];
}此题相对于62题加了障碍,初始化的时候要注意dp[i][0] = 1的时候如果遇到障碍,后面的需要初始化为0,因为不可能到达,dp[0][i] = 1同理
代码如下
public int uniquePathsWithObstacles(int[][] obstacleGrid) {
int m = obstacleGrid.length;
int n = obstacleGrid[0].length;
if (obstacleGrid[m - 1][n - 1] == 1 || obstacleGrid[0][0] == 1) {
return 0;
}
int[][] dp = new int[m][n];
for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++) {
dp[i][0] = 1;
}
for (int i = 0; i < n && obstacleGrid[0][i] == 0; i++) {
dp[0][i] = 1;
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] == 0) {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
}
return dp[m - 1][n - 1];
}