Paper Abstract
- SWI: Speaking with Intent in Large Language Models
- Authors: Yuwei Yin, EunJeong Hwang, and Giuseppe Carenini
- Publication: The 18th International Natural Language Generation Conference (INLG 2025)
- INLG 2025 Paper: https://aclanthology.org/2025.inlg-main.39
- arXiv Preprint: https://arxiv.org/abs/2503.21544
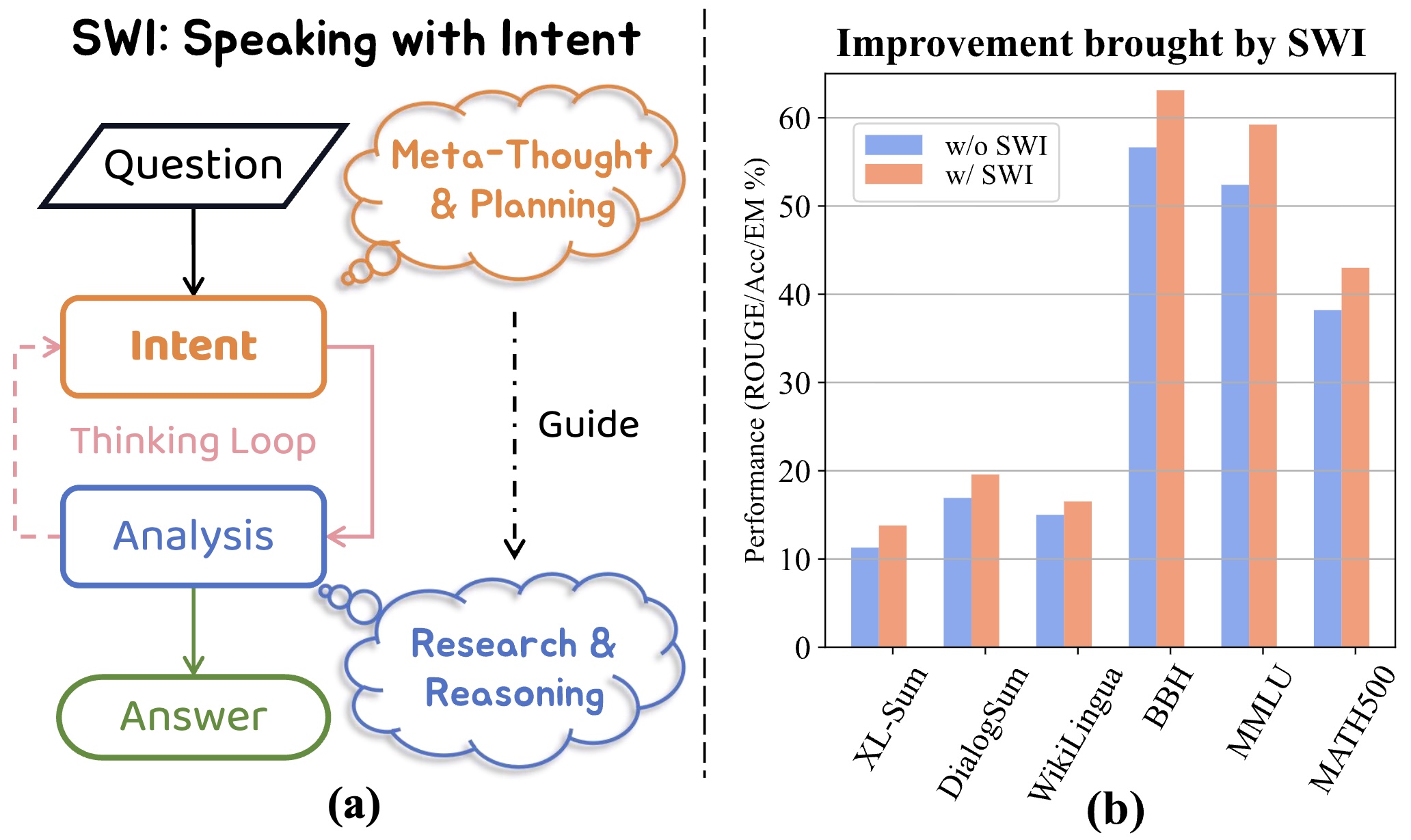
Intent, typically clearly formulated and planned, functions as a cognitive framework for communication and
problem-solving. This paper introduces the concept of Speaking with Intent (SWI) in large language models (LLMs),
where the explicitly generated intent encapsulates the model's underlying intention and provides high-level planning
to guide subsequent analysis and action. By emulating deliberate and purposeful thoughts in the human mind, SWI is
hypothesized to enhance the reasoning capabilities and generation quality of LLMs. Extensive experiments on text
summarization, multi-task question answering, and mathematical reasoning benchmarks consistently demonstrate the
effectiveness and generalizability of Speaking with Intent over direct generation without explicit intent. Further
analysis corroborates the generalizability of SWI under different experimental settings. Moreover, human evaluations
verify the coherence, effectiveness, and interpretability of the intent produced by SWI. The promising results in
enhancing LLMs with explicit intents pave a new avenue for boosting LLMs' generation and reasoning abilities with
cognitive notions.
Environment Setup
- Python: Python 3.10
- GPU: NVIDIA CUDA GPU (
float16inference mode only)
git clone https://github.com/YuweiYin/SWI
cd SWI/
# Now, "/path/to/SWI/" is the project root directory
# https://docs.conda.io/projects/miniconda/en/latest/
conda create -n swi python=3.10 -y
conda activate swi
pip install -r requirements.txt -i https://pypi.org/simple/
pip install -e . -i https://pypi.org/simple/
# We can set the Hugging Face cache directory to store the datasets and models.
export HF_HOME="/path/to/your/.cache/huggingface/" # Default: "${HOME}/.cache/huggingface/"- Download the datasets and models beforehand if the computing nodes have no Internet access or HOME storage is limited.
- Please ensure
CACHE_DIRis a correct directory andHF_TOKENis valid.
# https://huggingface.co/datasets
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
HF_TOKEN="YOUR_HF_TOKEN" # https://huggingface.co/settings/tokens
bash run_download_datasets.sh "${CACHE_DIR}" "${HF_TOKEN}" # Download data to "${CACHE_DIR}/datasets/"# https://huggingface.co/models
CACHE_DIR="YOUR_HF_CACHE_DIR" # E.g., "${HOME}/.cache/huggingface/"
HF_TOKEN="YOUR_HF_TOKEN" # https://huggingface.co/settings/tokens
bash run_download_models.sh "${CACHE_DIR}" "${HF_TOKEN}" # Download models to "${CACHE_DIR}/"For each bash script, please ensure CACHE_DIR is the correct Hugging Face cache directory
(default: "~/.cache/huggingface/") and PROJECT_DIR is the project root directory ("/path/to/SWI/").
Experiment Script
- SWI: Speaking with Intent (ours)
- DA: Direct Answer (without intent)
CACHE_DIR="YOUR_HF_CACHE_DIR" # the datasets and models cache directory, such as "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/SWI/" # the absolute path to the project root directory, something like "/path/to/SWI/"
MODEL="meta-llama/Llama-3.1-8B-Instruct" # the model used for generation/evaluation
OUTPUT_DIR="${PROJECT_DIR}/results/results" # where we save the experimental results
BSZ="1" # set the batch size to a larger value for a higher GPU utility
# [Reasoning & Answer Generation] **First**, freely generate answers with reasoning:
echo -e "\n\n >>> bash run_gen_lm.sh --hf_id ${MODEL} ALL [DA]" # Direct Answer (DA)
bash run_gen_lm.sh "1;42;${MODEL};${BSZ};ALL;0.0;4096" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--da"
echo -e "\n\n >>> bash run_gen_lm-swi.sh --hf_id ${MODEL} ALL [SWI]" # Speaking with Intent (SWI) - ours
bash run_gen_lm-swi.sh "1;42;${MODEL};${BSZ};ALL;0.0;4096" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi"
# [Answer Extraction & Evaluation] **Second**, extract the answers and evaluate them:
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [DA]"
bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--da"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [SWI]"
bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi"Experimental Settings
- Datasets: CNN/DailyMail (CDM), XSum, XL-Sum, DialogSum, and WikiLingua
- Comparison:
- DA: Direct Answer (w/o SWI)
- SWI (Ours): Require LLMs to speak with (their own) intent.
- Setting:
- Reference: BottleHumor (Section 4.4)
- Sample 100 data points from each summarization dataset.
- Let GPT decompose the atomic facts in the candidate summary and the reference,
- and then compare the recall and precision of the fact coverage (against LLM hallucinations).
- Models:
gpt-4o-miniAPI (Link)
Experiment Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # the datasets and models cache directory, such as "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/SWI/" # the absolute path to the project root directory, something like "/path/to/SWI/"
MODEL="meta-llama/Llama-3.1-8B-Instruct" # the model used for generation/evaluation
OUTPUT_DIR="${PROJECT_DIR}/results/results" # where we save the experimental results
OPENAI_KEY="${OPENAI_API_KEY}" # Input your valid key here. We use "gpt-4o-mini" by default
EVAL_NUM="100"
echo -e "\n\n >>> bash run_eval_prf.sh --hf_id ${MODEL} SUM_ALL PRF [DA]"
bash run_eval_prf.sh "1;${MODEL};1;SUM_ALL;0.0;${EVAL_NUM}" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--da" "${OPENAI_KEY}"
echo -e "\n\n >>> bash run_eval_prf.sh --hf_id ${MODEL} SUM_ALL PRF [SWI]"
bash run_eval_prf.sh "1;${MODEL};1;SUM_ALL;0.0;${EVAL_NUM}" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi" "${OPENAI_KEY}"Experiment Script - CoT
CACHE_DIR="YOUR_HF_CACHE_DIR" # the datasets and models cache directory, such as "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/SWI/" # the absolute path to the project root directory, something like "/path/to/SWI/"
MODEL="meta-llama/Llama-3.1-8B-Instruct" # the model used for generation/evaluation
OUTPUT_DIR="${PROJECT_DIR}/results/results" # where we save the experimental results
BSZ="1" # set the batch size to a larger value for a higher GPU utility
# [Reasoning & Answer Generation] **First**, freely generate answers with reasoning:
echo -e "\n\n >>> bash run_gen_lm-cot.sh --hf_id ${MODEL} ALL [DA+CoT]"
bash run_gen_lm.sh "1;42;${MODEL};${BSZ};ALL;0.0;4096" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--da-cot"
echo -e "\n\n >>> bash run_gen_lm-swi-cot.sh --hf_id ${MODEL} ALL [SWI+CoT]"
bash run_gen_lm-swi.sh "1;42;${MODEL};${BSZ};ALL;0.0;4096" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi-cot"
# [Answer Extraction & Evaluation] **Second**, extract the answers and evaluate them:
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [DA+CoT]"
bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--da-cot"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [SWI+CoT]"
bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi-cot"Experiment Script - PS
CACHE_DIR="YOUR_HF_CACHE_DIR" # the datasets and models cache directory, such as "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/SWI/" # the absolute path to the project root directory, something like "/path/to/SWI/"
MODEL="meta-llama/Llama-3.1-8B-Instruct" # the model used for generation/evaluation
OUTPUT_DIR="${PROJECT_DIR}/results/results" # where we save the experimental results
BSZ="1" # set the batch size to a larger value for a higher GPU utility
# [Reasoning & Answer Generation] **First**, freely generate answers with reasoning:
echo -e "\n\n >>> bash run_gen_lm-ps.sh --hf_id ${MODEL} ALL [DA+PS]"
bash run_gen_lm.sh "1;42;${MODEL};${BSZ};ALL;0.0;4096" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--da-ps"
echo -e "\n\n >>> bash run_gen_lm-swi-ps.sh --hf_id ${MODEL} ALL [SWI+PS]"
bash run_gen_lm-swi.sh "1;42;${MODEL};${BSZ};ALL;0.0;4096" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi-ps"
# [Answer Extraction & Evaluation] **Second**, extract the answers and evaluate them:
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [DA+PS]"
bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--da-ps"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [SWI+PS]"
bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi-ps"Experiment Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # the datasets and models cache directory, such as "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/SWI/" # the absolute path to the project root directory, something like "/path/to/SWI/"
OUTPUT_DIR="${PROJECT_DIR}/results/results" # where we save the experimental results
BSZ="1" # set the batch size to a larger value for a higher GPU utility
for MODEL in "meta-llama/Llama-3.2-3B-Instruct" "deepseek-ai/DeepSeek-R1-Distill-Llama-8B"
do
# [Reasoning & Answer Generation] **First**, freely generate answers with reasoning:
echo -e "\n\n >>> bash run_gen_lm.sh --hf_id ${MODEL} MATH_ALL [DA]" # Direct Answer (DA)
bash run_gen_lm.sh "1;42;${MODEL};${BSZ};MATH_ALL;0.0;4096" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--da"
echo -e "\n\n >>> bash run_gen_lm-swi.sh --hf_id ${MODEL} MATH_ALL [SWI]" # Speaking with Intent (SWI) - ours
bash run_gen_lm-swi.sh "1;42;${MODEL};${BSZ};MATH_ALL;0.0;4096" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi"
# [Answer Extraction & Evaluation] **Second**, extract the answers and evaluate them:
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} MATH_ALL [DA]"
bash run_eval_lm.sh "1;42;${MODEL};1;MATH_ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--da"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} MATH_ALL [SWI]"
bash run_eval_lm.sh "1;42;${MODEL};1;MATH_ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi"
doneExperiment Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # the datasets and models cache directory, such as "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/SWI/" # the absolute path to the project root directory, something like "/path/to/SWI/"
MODEL="meta-llama/Llama-3.1-8B-Instruct" # the model used for generation/evaluation
OUTPUT_DIR="${PROJECT_DIR}/results/results" # where we save the experimental results
BSZ="1" # set the batch size to a larger value for a higher GPU utility
# [Reasoning & Answer Generation] **First**, freely generate answers with reasoning:
#echo -e "\n\n >>> bash run_gen_lm-swi.sh --hf_id ${MODEL} ALL [SWI-var0] (default)"
#bash run_gen_lm-swi.sh "1;42;${MODEL};1;ALL;0.0;4096;0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi_var0"
echo -e "\n\n >>> bash run_gen_lm-swi.sh --hf_id ${MODEL} ALL [SWI-var1]"
bash run_gen_lm-swi.sh "1;42;${MODEL};${BSZ};ALL;0.0;4096;1" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi_var1"
echo -e "\n\n >>> bash run_gen_lm-swi.sh --hf_id ${MODEL} ALL [SWI-var2]"
bash run_gen_lm-swi.sh "1;42;${MODEL};${BSZ};ALL;0.0;4096;2" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi_var2"
echo -e "\n\n >>> bash run_gen_lm-swi.sh --hf_id ${MODEL} ALL [SWI-var3]"
bash run_gen_lm-swi.sh "1;42;${MODEL};${BSZ};ALL;0.0;4096;3" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi_var3"
# [Answer Extraction & Evaluation] **Second**, extract the answers and evaluate them:
#echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [SWI-var0]"
#bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi_var0"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [SWI-var1]"
bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi_var1"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [SWI-var2]"
bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi_var2"
echo -e "\n\n >>> bash run_eval_lm.sh --hf_id ${MODEL} ALL [SWI-var3]"
bash run_eval_lm.sh "1;42;${MODEL};1;ALL;ALL;0.0" "${CACHE_DIR}" "${PROJECT_DIR}" "${OUTPUT_DIR}--swi_var3"Analysis Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # the datasets and models cache directory, such as "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/SWI/" # the absolute path to the project root directory, something like "/path/to/SWI/"
MODEL="meta-llama/Llama-3.1-8B-Instruct" # the model used for generation/evaluation
MODEL_NAME="${MODEL//[\/]/--}" # the model_name used for naming the filepath
OUTPUT_DIR="${PROJECT_DIR}/results/results" # where we save the experimental results
# Stat 1: Stat of the input tokens (with or without SWI, i.e., extra tokens in the system prompt)
python3 run_stat.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --seed "42" --task "1" --hf_id "${MODEL}"
# Stat 2: Stat of the output tokens (LLMs' generation using or not using SWI)
for DATASET in "cnn_dailymail" "xsum" "xlsum" "dialogsum" "wiki_lingua" "bbh" "mmlu" "mmlu_pro" "gsm8k" "gsm8k_platinum" "math500"
do
python3 run_stat.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --seed "42" --task "2" --hf_id "${MODEL}" \
--output_filepath "${OUTPUT_DIR}--da/${DATASET}/${MODEL_NAME}/results_gen.json"
python3 run_stat.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --seed "42" --task "2" --hf_id "${MODEL}" \
--output_filepath "${OUTPUT_DIR}--swi/${DATASET}/${MODEL_NAME}/results_gen.json"
doneAnalysis Script
CACHE_DIR="YOUR_HF_CACHE_DIR" # the datasets and models cache directory, such as "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/SWI/" # the absolute path to the project root directory, something like "/path/to/SWI/"
MODEL="meta-llama/Llama-3.1-8B-Instruct" # the model used for generation/evaluation
MODEL_NAME="${MODEL//[\/]/--}" # the model_name used for naming the filepath
OUTPUT_DIR="${PROJECT_DIR}/results/results" # where we save the experimental results
# Stat 3: Stat of the intents (i.e., to count the verbs in the specified intent format: "To do something")
for DATASET in "cnn_dailymail" "xsum" "xlsum" "dialogsum" "wiki_lingua" "bbh" "mmlu" "mmlu_pro" "gsm8k" "gsm8k_platinum" "math500"
do
python3 run_stat.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --seed "42" --task "3" --hf_id "${MODEL}" \
--output_filepath "${OUTPUT_DIR}--swi/${DATASET}/${MODEL_NAME}/results_gen.json"
done
# Stat 4: Aggregate the intent-verb stat by the task type
for TASK in "sum" "qa" "math"
do
python3 run_stat.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --seed "42" --task "4" --hf_id "${MODEL}" \
--output_dir "${OUTPUT_DIR}--swi/" --stat_task_type "${TASK}"
done
# Plot the bar charts of top 10 common intent verbs
python3 run_plot.py --verbose --seed "42" --task "1" --do_save --save_format "pdf"
# Plot the t-SNE distribution of intents
# t-SNE Step 1: Prepare for the text data
python3 run_tsne.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --seed "42" --task "1" --hf_id_generation "${MODEL}" \
--output_dir "${OUTPUT_DIR}--swi/"
# t-SNE Step 2: Prepare for the embeddings (Note: GPU is needed here)
python3 run_tsne.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --seed "42" --task "2" --hf_id_generation "${MODEL}" \
--output_dir "${OUTPUT_DIR}--swi/" --hf_id_embedding "${MODEL}" \
--do_normalize
# t-SNE Step 3: Plot intent distribution (t-SNE)
python3 run_tsne.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --seed "42" --task "3" --hf_id_generation "${MODEL}" \
--output_dir "${OUTPUT_DIR}--swi/" --hf_id_embedding "${MODEL}" \
--do_normalize --draw_option "all_tasks" --do_save
python3 run_tsne.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --seed "42" --task "3" --hf_id_generation "${MODEL}" \
--output_dir "${OUTPUT_DIR}--swi/" --hf_id_embedding "${MODEL}" \
--do_normalize --draw_option "all_vs_eng" --do_savePreparing Data for Human Evaluation
CACHE_DIR="YOUR_HF_CACHE_DIR" # the datasets and models cache directory, such as "${HOME}/.cache/huggingface/"
PROJECT_DIR="/path/to/SWI/" # the absolute path to the project root directory, something like "/path/to/SWI/"
MODEL="meta-llama/Llama-3.1-8B-Instruct" # the model used for generation/evaluation
OUTPUT_DIR="${PROJECT_DIR}/results/results" # where we save the experimental results
# We sample 12 data points per dataset and convert the JSON results into CSV for Human Evaluation.
# Each data point has 3 duplications and each of them is evaluate by different native English speaker. 420 in total
for TASK_TYPE in "QA_TWO" "MATH_TWO" "SUM_TWO"
do
echo -e "\n\n >>> python3 run_human_eval_intent.py ${TASK_TYPE}"
python3 run_human_eval_intent.py --cache_dir "${CACHE_DIR}" --project_dir "${PROJECT_DIR}" \
--verbose --task "1" --hf_id "${MODEL}" \
--output_dir "${OUTPUT_DIR}--swi" \
--min_doc_length 500 --max_doc_length 1000 \
--num_item_per_task 12 --num_duplication 3 --num_item_in_a_row 6 --eval_task_name "${TASK_TYPE}"
doneThe CSV files and HTML pages for human evaluation are under the human_eval directory.
Please refer to the LICENSE file for more details.
@inproceedings{yin2025swi,
title = {SWI: Speaking with Intent in Large Language Models},
author = {Yin, Yuwei and Hwang, Eunjeong and Carenini, Giuseppe},
booktitle = {Proceedings of the 18th International Natural Language Generation Conference},
month = {October},
year = {2025},
address = {Hanoi, Vietnam},
publisher = {Association for Computational Linguistics},
pages = {684--698},
url = {https://aclanthology.org/2025.inlg-main.39}
}