İhtiyaç duyduğumuz verilerin özellikle CSV’lerde olmak üzere birçok dosyaya dağılmış olması çok yaygındır. Bazen de veri tek bir dosyadadır ama birden fazla çalışma sayfasına (worksheet) bölünmüştür. Şimdiye kadar genelde pandas.read_csv() fonksiyonunu kullandık; kullanımı basittir: bir CSV verirsin, o da CSV’deki tüm sütun ve satırlarla bir DataFrame oluşturur.
Birden fazla dosya olunca iş biraz değişir. Elbette 10 dosyayı 10 farklı DataFrame’e yükleyebilirsin; peki veriyi uzlaştırmak / bir araya getirmek istersen? İşte Pandas ile birleştirme (merge) dünyasına hoş geldin.
Pandas, iki DataFrame’i “bir araya getirmek” için üç temel yöntem sunar:
Hepsi dokümantasyondaki Merge, join and concatenate yazısında anlatılıyor; ancak bu yazı çok (gerçekten çok!) uzun. Tek seferde okuyup “tamamını anlayıp hatırlamak” pek gerçekçi değil.
Gerçek CSV’leri yükleyip merge/join/concat denemeden önce, sözlüklerden (dictionary) üretilen küçük DataFrame’lerle çalışacağız. Böylece daha az veriyle uğraşırız ve kavramları daha rahat oturturuz.
Bu alıştırma klasöründeki multiple_files.ipynb not defterini aç ve ilk hücreye her zamanki gibi şu import’ları ekleyerek başla:
import numpy as np
import pandas as pd
import matplotlibNot defterine yeni bir markdown hücresi ekle:
## Merge AlıştırmasıŞimdi Google’dan derlediğimizi varsaydığımız ülke bilgilerini tutan ilk DataFrame’i oluşturalım:
a_df = pd.DataFrame({
'Country': ['Germany', 'France', 'Belgium', 'Finland'],
'Population (M)': [82.8, 67.2, 11.4, 5.5],
'Capital': ['Berlin', 'Paris', 'Brussels', 'Helsinki']
})
a_dfYeni bir hücrede de HDI tablomuz olduğunu varsayalım:
b_df = pd.DataFrame({
'Country': ['Germany', 'France', 'Belgium', 'Canada'],
'HDI': [0.936, 0.901, 0.916, 0.926]
})
b_dfNot defterine yeni bir markdown hücresi ekle:
### İç Birleştirme Alıştırmasıa_df ve b_df DataFrame’lerini merge ile birleştirip null değer içermeyen bir DataFrame elde etmeye çalış. Ortaya çıkan DataFrame’i inner_merged_df adlı bir değişkene ata. Fonksiyonun dokümantasyonunu özellikle on parametresi açısından oku. Hangi seçenek olmalı? Sadece bu argümanı verip başka hiçbir şey geçmezsen; Kanada ve Finlandiya hakkında ne söyleyebilirsin?
Yeni bir markdown hücresi ekle:
#### Kodunu kontrol etve ardından yeni DataFrame’ini test etmek için bir kod hücresi ekle:
from nbresult import ChallengeResult
result = ChallengeResult('inner_merge',
inner_merged_shape=inner_merged_df.shape,
inner_merged_nulls=sum(inner_merged_df.isnull().sum())
)
result.write()
print(result.check())Az önce iç (inner) birleştirme yaptık. Yani birleştirmeyi yaptığımız sütunda (on ile belirlenen Column) hem a_df hem de b_df içinde bulunan değerlerin yer aldığı satırları yalnızca tuttuk.
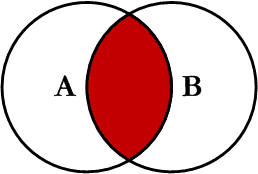
Bu örnekte a_df içinde Finland satırı var ama b_df içinde yok; bu yüzden iç birleştirmede Finlandiya satırı yer almaz. Canada için de aynı durum geçerli: b_df içinde var ama a_df içinde yok; dolayısıyla iç birleştirmede o da görünmez.
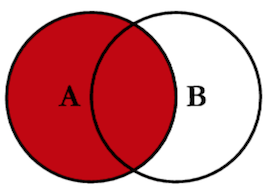
Toplam dört farklı birleştirme türü var. Bir önceki bölümde iç birleştirmeyi gördük. Şimdi sol birleştirmeyi deneyelim:
Not defterine yeni bir markdown hücresi ekle:
### Sol Birleştirme AlıştırmasıYeni bir hücre oluştur ve a_df’yi “sol” veri kümesi kabul ederek left_merged_df değişkenini oluştur. Ne görüyorsun? Finland ne durumda? Canada?
Yeni bir markdown hücresi ekle:
#### Kodunu kontrol etve ardından yeni DataFrame’ini test etmek için bir kod hücresi ekle:
from nbresult import ChallengeResult
result = ChallengeResult('left_merge',
left_merged_shape=left_merged_df.shape,
left_merged_nulls=sum(left_merged_df.isnull().sum())
)
result.write()
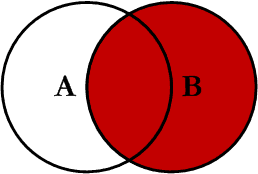
print(result.check())Muhtemelen nereye gittiğimizi tahmin ediyorsun. Az önce sol birleştirme yaptık; şimdi de sağ birleştirmeye bakalım!
Not defterine yeni bir markdown hücresi ekle:
### Sağ Birleştirme AlıştırmasıAynı fikir: Yeni bir hücre oluştur ve a_df hâlâ “sol” veri kümen olacak şekilde right_merged_df değişkenini üret. Ne görüyorsun? Finland? Canada?
Yeni bir markdown hücresi ekle:
#### Kodunu kontrol etve ardından yeni DataFrame’ini test etmek için bir kod hücresi ekle:
from nbresult import ChallengeResult
result = ChallengeResult('right_merge',
right_merged_shape=right_merged_df.shape,
right_merged_nulls=sum(right_merged_df.isnull().sum())
)
result.write()
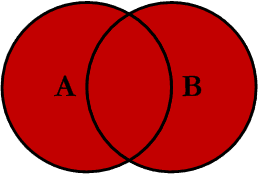
print(result.check())Son olarak, hem a_df hem de b_df içindeki tüm satırları tutan birleştirme türü var: dış (outer) birleştirme.
Not defterine yeni bir markdown hücresi ekle:
### Dış Birleştirme AlıştırmasıArdından yeni bir hücre oluştur ve outer_merged_df’yi üret.
Yeni bir markdown hücresi ekle:
#### Kodunu kontrol etve ardından yeni DataFrame’ini test etmek için bir kod hücresi ekle:
from nbresult import ChallengeResult
result = ChallengeResult('outer_merge',
outer_merged_shape=outer_merged_df.shape,
outer_merged_nulls=sum(outer_merged_df.isnull().sum())
)
result.write()
print(result.check())ℹ️ Pandas dokümantasyonunda Eksik verilerle çalışma (Working with missing data) üzerine ayrı bir bölüm var. Bu da epey uzun; şu an okumak zorunda değilsin ama bir dahaki sefere NaN’lerle dolu bir veri seti incelerken aklında olsun.
merge fonksiyonu belirli bir sütuna göre birleştirme yapmak için idealdir. Şimdi de index (satırlar) üzerinden birleştirmek isteyeceğin bir senaryoya bakalım.
Not defterine yeni bir markdown hücresi ekle:
## Join AlıştırmasıŞimdi Country sütununu yeni index olacak şekilde ayarlayıp aa_df ve bb_df adında iki yeni DataFrame oluşturalım.
aa_df = a_df.set_index("Country")
aa_dfbb_df = b_df.set_index("Country")
bb_dfŞimdi pandas.DataFrame.join() kullanalım:
aa_df.join(bb_df)❓ Sonuç ne? Bu işlem sol, sağ, iç ya da dış join mi oldu?
Çözümü görüntüle
Varsayılan olarak .join() sol join yapar. Diğer join türlerini de dene:
aa_df.join(bb_df, how='inner')
aa_df.join(bb_df, how='right')
aa_df.join(bb_df, how='outer')❓ Görüyorsun ki .merge() ve .join() sonunda aynı sonucu verebiliyor. Peki hangisini ne zaman kullanmalısın?
Çözümü görüntüle
Belirli bir sütuna göre birleştirmek istediğinde .merge(); index üzerinden birleştirmek istediğinde .join() kullanabilirsin.
İki DataFrame’i bir araya getirmenin üçüncü bir yolu da pandas.concat() kullanmaktır. Hemen deneyelim:
Not defterine yeni bir markdown hücresi ekle:
## Concat Alıştırmasıconcat_df = pd.concat([a_df, b_df], axis="index", sort=False)
concat_dfBu yöntem biraz daha “düz” çalışır: iki DataFrame’i satırlarını üst üste ekleyerek tek bir DataFrame’e dönüştürür. Bazı durumlarda çok işine yarayabilir; bu yüzden nasıl kullanıldığını bilmekte fayda var.
Şimdi öğrendiklerimizi pratiğe dökelim. Birden fazla CSV yükleme ve bunları birleştirme alıştırması için, 3 dosyadan oluşan Olimpik Sporlar ve Madalyalar, 1896-2014 veri setini kullanacağız:
dictionary.csvsummer.csvwinter.csv
- Bu üç dosyayı Kaggle’dan indir
- Dosyaları mevcut klasörüne kopyala (klasör şu olmalı:
~/code/<user.github_nickname>/{{ local_path_to("02-Data-Toolkit/01-Data-Analysis/04-Multiple-Files-With-Pandas") }})
Çalışmayı düzenli tutmak için not defterine yeni bir markdown hücresi ekleyelim:
## Olympic Sports and Medals, 1896-2014Şimdi şu dosyaları yükleyecek kodu yaz:
dictionary.csvdosyasınıcountries_dfadlı bir DataFrame’esummer.csvdosyasınısummer_dfadlı bir DataFrame’ewinter.csvdosyasınıwinter_dfadlı bir DataFrame’e
countries_df, summer_df ve winter_df DataFrame’lerini hangi sütun üzerinden birleştirmeliyiz?
İpucu
Winter ve summer DataFrame’lerinde pandas.DataFrame.rename() fonksiyonunu kullanman gerekecek.
Not defterine yeni bir markdown hücresi ekle:
### Verileri BirleştirmeŞimdi countries_df ile summer_df arasında iç birleştirme yapıp yeni bir summer_countries_df oluşturma zamanı. En sonunda tüm oyunları tek bir DataFrame’de birleştireceğimiz için summer_countries_df içine Season adlı bir sütun ekle.
Aynı yaklaşımı winter_countries_df için de uygula ve burada da mutlaka Season sütununu ekle.
Artık summer_countries_df ve winter_countries_df (aynı sütunlara sahipler!) DataFrame’lerini concat ederek all_df adlı tek bir DataFrame elde edebiliriz.
Yeni bir markdown hücresi ekle:
#### Kodunu kontrol etve ardından yeni DataFrame’ini test etmek için bir kod hücresi ekle:
from nbresult import ChallengeResult
result = ChallengeResult('all_df',
all_df_shape=all_df.shape,
all_df_columns=set(all_df.columns)
)
result.write()
print(result.check())Not defterine yeni bir markdown hücresi ekle:
### En Başarılı Ülkeler AnaliziBoolean indexing, gruplama ve sıralama kullanarak 1984’ten beri en çok toplam madalya kazanan ilk 10 ülkeyi içeren yeni bir DataFrame oluştur.
- Sonucu
top_10_dfadlı bir değişkene kaydet - DataFrame 10 satırdan oluşmalı ve tek bir sütunu olmalı:
Medal Count
Sonucu çubuk grafikle çizdirmek için şunu kullanabilirsin:
top_10_df.plot(kind="bar");Yeni bir markdown hücresi ekle:
#### Kodunu kontrol etve ardından DataFrame’ini test etmek için şu kodu ekle:
from nbresult import ChallengeResult
result = ChallengeResult('olympic_games',
top_country_1=top_10_df.iloc[0]['Medal Count'],
top_country_10=top_10_df.iloc[9]['Medal Count']
)
result.write()
print(result.check())Analizi bir adım ileri taşıyalım: Bu kez sadece her ülkenin toplam madalya sayısını saymak istemiyoruz. Bir yandan Kış Oyunları, diğer yandan Yaz Oyunları için madalya sayılarını ayrı ayrı hesaplayacağız. Sonra da bunları çizeceğiz (sıralama yine toplam madalya sayısına göre olmalı).
- DataFrame’i
top_10_season_dfadlı bir değişkene kaydet - DataFrame 10 satır ve
SummerWinterTotaladlı 3 sütundan oluşmalı
💡 İpucu 1 pandas.DataFrame.groupby() bir sütun listesi üzerinden gruplama yapabilir.
💡 İpucu 2 pandas.DataFrame.unstack() fonksiyonunu kullanman gerekecek.
Sonucu çubuk grafikle çizdirmek için şunu kullanabilirsin:
top_10_season_df[['Summer', 'Winter']].plot(kind="bar");Yeni bir markdown hücresi ekle:
#### Kodunu kontrol etve ardından DataFrame’ini test etmek için şu kodu ekle:
from nbresult import ChallengeResult
result = ChallengeResult('olympic_games_season',
top_country_season_shape=top_10_season_df.shape,
top_country_1_summer=top_10_season_df.iloc[0]['Summer'],
top_country_10_winter=top_10_season_df.iloc[9]['Winter']
)
result.write()
print(result.check())Olimpiyatları yakından takip ediyorsan madalya sayılarının “tam doğru” görünmediğini fark etmiş olabilirsin. Not defterine yeni bir hücre ekleyip şunu çalıştır:
all_df[(all_df.Year==2008) & (all_df.Event=='Basketball') & (all_df.Medal=='Gold')]Görünüşe göre takım sporları analizimizde fazla sayılıyor. Takım sporları için oluşan ek satırları nasıl çıkarabiliriz?
Aynı şey karma (mixed) etkinlikler için de geçerli; bunlar iki kez sayılıyor. Onları da nasıl çıkarabilirsin?
1984’ten beri toplam event kazanımına göre ilk 10 ülkeyi gösteren yeni bir DataFrame oluştur.
- Yeni DataFrame’i
top_10_events_dfadlı bir değişkene ata - DataFrame 10 satır ve
Event Countadlı 1 sütundan oluşmalı
💡 İpucu 1 pandas.DataFrame.drop() fonksiyonu, analiz için fazla detaylı olan sütunları kaldırmana yardımcı olabilir.
💡 İpucu 2 Daha genelleştirilmiş bir veri seti için pandas.DataFrame.drop_duplicates() fonksiyonu işine yarayabilir.
Bitince sonuçları şöyle görüntüleyebilirsin:
top_10_events_df.plot(kind='bar');Yeni bir markdown hücresi ekle:
#### Kodunu kontrol etve ardından DataFrame’ini test etmek için şu kodu ekle:
from nbresult import ChallengeResult
result = ChallengeResult('olympic_games_event',
top_country_event_shape=top_10_events_df.shape,
top_country_1_event=top_10_events_df.iloc[0]['Event Count'],
top_country_10_event=top_10_events_df.iloc[9]['Event Count']
)
result.write()
print(result.check())top_10_events_df ve top_10_df DataFrame’lerini top_10_combined adlı yeni bir DataFrame’de birleştir. Birleştirme sonucunda, madalya kazanımında ilk 10’a giren veya event kazanımında ilk 10’a giren tüm ülkeler dahil olsun. Sonucu toplam Medal Count değerine göre sırala.
Grafiğini çiz
top_10_combined.plot(kind='bar');Yeni bir markdown hücresi ekle:
#### Kodunu kontrol etve ardından DataFrame’ini test etmek için şu kodu ekle:
from nbresult import ChallengeResult
result = ChallengeResult('olympic_games_combined',
top_combined_shape=top_10_combined.shape,
top_combined_1_event=top_10_combined.iloc[0]['Event Count'],
top_combined_1_medal=top_10_combined.iloc[0]['Medal Count'],
top_combined_10_event=top_10_combined.iloc[9]['Event Count'],
top_combined_10_medal=top_10_combined.iloc[9]['Medal Count']
)
result.write()
print(result.check())