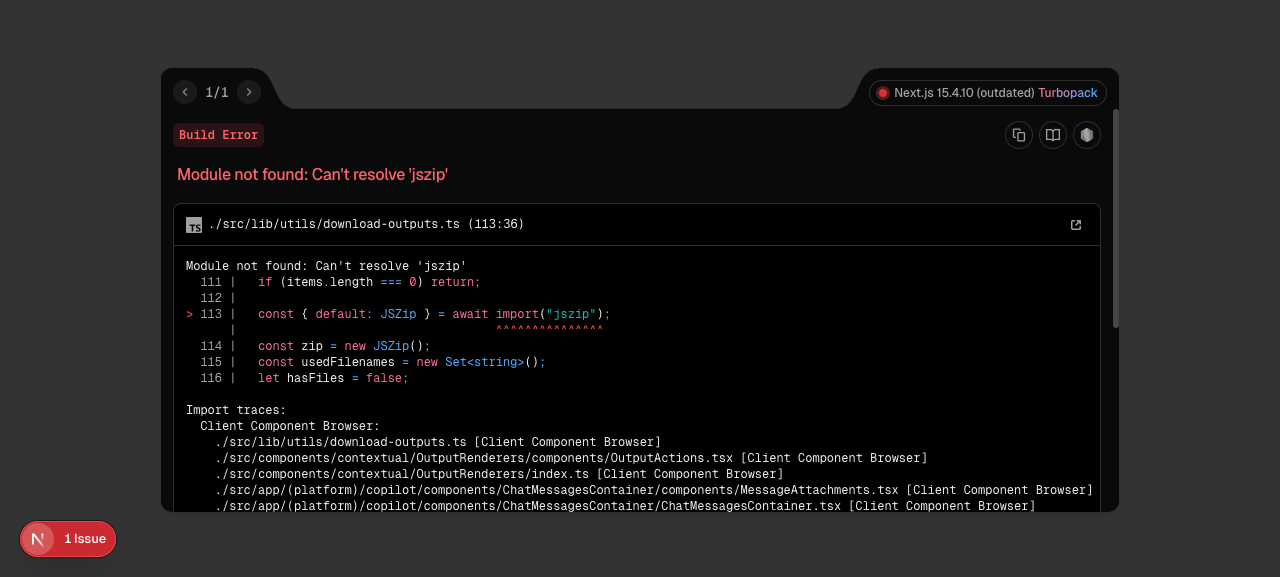
fix(backend/copilot): re-prompt on thinking-only finish; route storage-limit through DB-manager#12992
Conversation
…e-limit through DB-manager
Two production fixes from John's dev testing on 2026-05-01.
**Issue 5 — "(Done — no further commentary.)" hides the real answer**
When a turn after tool results ended with only a ThinkingBlock (no
TextBlock, no ToolUseBlock), the adapter immediately emitted the
"(Done — no further commentary.)" placeholder. Sessions like
`c93dc51f-...` (Langfuse `7d1a674e...`) had the model writing the full
restaurant-list answer inside extended thinking and finishing with empty
TextBlock, so the user saw only the placeholder.
Layered fallback now:
1. First detection — adapter sets `pending_thinking_only_reprompt` and
skips StreamFinish; driver in `service.py` re-enters the SDK loop with
one synthetic `client.query("Please write a brief user-facing summary…")`.
2. If the re-prompt also produces thinking-only — promote the most recent
ThinkingBlock content to a visible TextDelta (the answer is already
there, no need to lose it to the placeholder).
3. Only when thinking is also empty — emit the original placeholder.
Bounded to one re-prompt per turn to cap added latency / cost.
**Issue 2 — `prisma.errors.ClientNotConnectedError` on workspace writes**
PR #12780's tier-based storage-limit pre-check at `util/workspace.py:225`
imported `get_workspace_total_size` directly from `backend.data.workspace`,
which calls Prisma. On the copilot-executor (Prisma not connected), every
image-generation tool's `manager.write_file()` blew up — John's 10
staffy-photo requests all failed with "query engine not connected".
Routed through the existing `workspace_db()` accessor and exposed
`get_workspace_total_size` on `DatabaseManager` so the executor RPCs into
database-manager just like the other workspace queries on the same path.
|
Note Reviews pausedIt looks like this branch is under active development. To avoid overwhelming you with review comments due to an influx of new commits, CodeRabbit has automatically paused this review. You can configure this behavior by changing the Use the following commands to manage reviews:
Use the checkboxes below for quick actions:
WalkthroughAdds a two-stage “thinking-only” reprompt flow: the adapter captures recent ThinkingBlock text and defers final emission on the first thinking-only ResultMessage, the service issues a synthetic reprompt and re-streams to surface captured thinking (or a placeholder), and CLI JSONL uploads are stripped of the synthetic reprompt. Also routes workspace quota checks to the DB accessor RPC and updates related tests. ChangesThinking-Only Reprompt Flow
Workspace Quota Accessor Refactor
Sequence DiagramsequenceDiagram
actor Client
participant Service as copilot/sdk/service
participant Adapter as SDKResponseAdapter
participant Model as LLM
Client->>Service: start streaming (original prompt)
Service->>Model: client.query(original_prompt)
loop initial stream
Model-->>Service: streaming messages (may be ThinkingBlock-only)
Service->>Adapter: dispatch SDK message
Adapter->>Adapter: record ThinkingBlock -> _last_thinking_content\nif final thinking-only: set pending_thinking_only_reprompt and suppress final emission
Adapter-->>Service: suppressed final text/finish
end
Note over Service: initial stream ended
alt pending_thinking_only_reprompt && not thinking_only_reprompted
Service->>Service: pending=False\nthinking_only_reprompted=True\nreset adapter._text_since_last_tool_result\nacc.stream_completed=False
Service->>Model: client.query(_THINKING_ONLY_REPROMPT)
loop re-entry stream
Model-->>Service: streaming messages (user-facing text or empty)
Service->>Adapter: dispatch SDK message
Adapter->>Adapter: emit StreamTextDelta (promoted thinking or placeholder)\nthen emit StreamFinish
Adapter-->>Service: StreamTextDelta + StreamFinish
end
end
Service-->>Client: final visible stream completed
Estimated code review effort🎯 4 (Complex) | ⏱️ ~50 minutes Possibly related PRs
Suggested reviewers
Poem
🚥 Pre-merge checks | ✅ 4 | ❌ 1❌ Failed checks (1 warning)
✅ Passed checks (4 passed)
✏️ Tip: You can configure your own custom pre-merge checks in the settings. ✨ Finishing Touches📝 Generate docstrings
🧪 Generate unit tests (beta)
Thanks for using CodeRabbit! It's free for OSS, and your support helps us grow. If you like it, consider giving us a shout-out. Comment |
🔍 PR Overlap DetectionThis check compares your PR against all other open PRs targeting the same branch to detect potential merge conflicts early. 🔴 Merge Conflicts DetectedThe following PRs have been tested and will have merge conflicts if merged after this PR. Consider coordinating with the authors.
🟢 Low Risk — File Overlap OnlyThese PRs touch the same files but different sections (click to expand)
Summary: 2 conflict(s), 0 medium risk, 1 low risk (out of 3 PRs with file overlap) Auto-generated on push. Ignores: |
There was a problem hiding this comment.
Actionable comments posted: 4
🤖 Prompt for all review comments with AI agents
Verify each finding against the current code and only fix it if needed.
Inline comments:
In `@autogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py`:
- Around line 497-550: Add a regression test that simulates an end-to-end
sequence: create an adapter via _adapter(), feed it a pre-tool ThinkingBlock (so
adapter._last_thinking_content is set implicitly by processing a ThinkingBlock
message), then feed a ToolResult (or messages that set
adapter._any_tool_results_seen and flush text via a UserMessage), then simulate
a re-prompt round that produces an empty thinking-only ResultMessage
(subtype="success", result="") with adapter.thinking_only_reprompted True;
assert the adapter emits the placeholder "(Done — no further commentary.)" (via
StreamTextDelta) and a final StreamFinish instead of promoting the earlier
planning text. Locate the flow using adapter.convert_message, ResultMessage,
StreamTextDelta and StreamFinish and name the new test something like
test_thinking_block_before_tool_then_reprompt_uses_placeholder.
In `@autogpt_platform/backend/backend/copilot/sdk/response_adapter.py`:
- Around line 472-479: The code uses fallback_text sourced from
_last_thinking_content which is never cleared when a tool result begins a new
answer phase, so stale pre-tool planning can be promoted; update the logic that
resets _text_since_last_tool_result to also clear _last_thinking_content (or
introduce and maintain a separate post-tool thinking buffer) so that when a tool
result or flushed tool output occurs (i.e., the same boundary where
_text_since_last_tool_result is reset) any previous ThinkingBlock content is
discarded and only thinking produced after the last tool result can be used for
fallback_text.
In `@autogpt_platform/backend/backend/copilot/sdk/service.py`:
- Around line 3079-3095: The one-time reprompt guard
(state.adapter.thinking_only_reprompted and
state.adapter.pending_thinking_only_reprompt) is currently stored on the adapter
which gets rebuilt on transient/context retries; move this budget into the
retry-scoped state by adding corresponding fields to _RetryState or
_StreamContext (e.g., thinking_only_reprompted and
pending_thinking_only_reprompt) and initialize/seed new adapters from that
retry-state when adapters are reconstructed; update the branch that currently
reads/writes state.adapter.thinking_only_reprompted and
state.adapter.pending_thinking_only_reprompt to use the new
_RetryState/_StreamContext properties, and ensure any adapter creation code
copies the retry-state flag into the adapter if an adapter-local view is still
needed.
- Around line 3092-3095: The hidden reprompt `_THINKING_ONLY_REPROMPT` is sent
via `client.query(...)` which causes it to be appended to `session.messages` and
included in the persisted CLI JSONL/upload in the `finally` block, leaking an
internal instruction into `--resume` history; fix by sending that reprompt
out-of-band (do not call `client.query` on the real SDK session) or mark it
in-memory as internal and ensure a strip step before persistence: update the
`client.query` usage around `_THINKING_ONLY_REPROMPT` to either (a) use a
separate non-persistent channel/API or local-only handler, or (b) tag the
resulting message with an internal marker and filter out any messages with that
marker from `session.messages` and `message_count` before the code that
writes/uploads the JSONL in the `finally` block so the internal turn never
reaches persisted history.
🪄 Autofix (Beta)
Fix all unresolved CodeRabbit comments on this PR:
- Push a commit to this branch (recommended)
- Create a new PR with the fixes
ℹ️ Review info
⚙️ Run configuration
Configuration used: Organization UI
Review profile: CHILL
Plan: Pro
Run ID: 0b881699-b68d-463e-aee9-b7e4b21ed48b
📒 Files selected for processing (6)
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/util/workspace_test.py
📜 Review details
⏰ Context from checks skipped due to timeout of 90000ms. You can increase the timeout in your CodeRabbit configuration to a maximum of 15 minutes (900000ms). (12)
- GitHub Check: check API types
- GitHub Check: Seer Code Review
- GitHub Check: types
- GitHub Check: test (3.13)
- GitHub Check: test (3.12)
- GitHub Check: type-check (3.13)
- GitHub Check: test (3.11)
- GitHub Check: type-check (3.11)
- GitHub Check: end-to-end tests
- GitHub Check: Check PR Status
- GitHub Check: Analyze (python)
- GitHub Check: Analyze (typescript)
🧰 Additional context used
📓 Path-based instructions (5)
autogpt_platform/backend/**/*.py
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
autogpt_platform/backend/**/*.py: Use Python 3.11 (required; managed by Poetry via pyproject.toml) for backend development
Always run 'poetry run format' (Black + isort) before linting in backend development
Always run 'poetry run lint' (ruff) after formatting in backend development
autogpt_platform/backend/**/*.py: Usepoetry run ...command for executing Python package dependencies
Use top-level imports only — avoid local/inner imports except for lazy imports of heavy optional dependencies likeopenpyxl
Use absolute imports withfrom backend.module import ...for cross-package imports; single-dot relative imports are acceptable for sibling modules within the same package; avoid double-dot relative imports
Do not use duck typing — avoidhasattr/getattr/isinstancefor type dispatch; use typed interfaces/unions/protocols instead
Use Pydantic models over dataclass/namedtuple/dict for structured data
Do not use linter suppressors — no# type: ignore,# noqa,# pyright: ignore; fix the type/code instead
Prefer list comprehensions over manual loop-and-append patterns
Use early return with guard clauses first to avoid deep nesting
Use%sfor deferred interpolation indebuglog statements for efficiency; use f-strings elsewhere for readability (e.g.,logger.debug("Processing %s items", count)vslogger.info(f"Processing {count} items"))
Sanitize error paths by usingos.path.basename()in error messages to avoid leaking directory structure
Be aware of TOCTOU (Time-Of-Check-Time-Of-Use) issues — avoid check-then-act patterns for file access and credit charging
Usetransaction=Truefor Redis pipelines to ensure atomicity on multi-step operations
Usemax(0, value)guards for computed values that should never be negative
Keep files under ~300 lines; if a file grows beyond this, split by responsibility (extract helpers, models, or a sub-module into a new file)
Keep functions under ~40 lines; extract named helpers when a function grows longer
...
Files:
autogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
autogpt_platform/backend/backend/data/**/*.py
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
All data access in backend requires user ID checks; verify this for any 'data/*.py' changes
Files:
autogpt_platform/backend/backend/data/db_manager.py
autogpt_platform/{backend,autogpt_libs}/**/*.py
📄 CodeRabbit inference engine (AGENTS.md)
Format Python code with
poetry run format
Files:
autogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
autogpt_platform/**/data/**/*.py
📄 CodeRabbit inference engine (AGENTS.md)
For changes touching
data/*.py, validate user ID checks or explain why not needed
Files:
autogpt_platform/backend/backend/data/db_manager.py
autogpt_platform/backend/**/*_test.py
📄 CodeRabbit inference engine (autogpt_platform/backend/AGENTS.md)
autogpt_platform/backend/**/*_test.py: Use pytest with snapshot testing for API responses
Colocate test files with source files using*_test.pynaming convention
Mock at boundaries — mock where the symbol is used, not where it's defined; after refactoring, update mock targets to match new module paths
UseAsyncMockfromunittest.mockfor async functions in tests
When writing tests, use Test-Driven Development (TDD): write failing tests marked with@pytest.mark.xfailbefore implementation, then remove the marker once the implementation is complete
When creating snapshots in tests, usepoetry run pytest path/to/test.py --snapshot-update; always review snapshot changes withgit diffbefore committing
Files:
autogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
🧠 Learnings (10)
📚 Learning: 2026-02-26T17:02:22.448Z
Learnt from: Pwuts
Repo: Significant-Gravitas/AutoGPT PR: 12211
File: .pre-commit-config.yaml:160-179
Timestamp: 2026-02-26T17:02:22.448Z
Learning: Keep the pre-commit hook pattern broad for autogpt_platform/backend to ensure OpenAPI schema changes are captured. Do not narrow to backend/api/ alone, since the generated schema depends on Pydantic models across multiple directories (backend/data/, backend/blocks/, backend/copilot/, backend/integrations/, backend/util/). Narrowing could miss schema changes and cause frontend type desynchronization.
Applied to files:
autogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
📚 Learning: 2026-03-05T15:42:08.207Z
Learnt from: ntindle
Repo: Significant-Gravitas/AutoGPT PR: 12297
File: .claude/skills/backend-check/SKILL.md:14-16
Timestamp: 2026-03-05T15:42:08.207Z
Learning: In Python files under autogpt_platform/backend (recursively), rely on poetry run format to perform formatting (Black + isort) and linting (ruff). Do not run poetry run lint as a separate step after poetry run format, since format already includes linting checks.
Applied to files:
autogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
📚 Learning: 2026-03-16T16:35:40.236Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12440
File: autogpt_platform/backend/backend/api/features/workflow_import.py:54-63
Timestamp: 2026-03-16T16:35:40.236Z
Learning: Avoid using the word 'competitor' in public-facing identifiers and text. Use neutral naming for API paths, model names, function names, and UI text. Examples: rename 'CompetitorFormat' to 'SourcePlatform', 'convert_competitor_workflow' to 'convert_workflow', '/competitor-workflow' to '/workflow'. Apply this guideline to files under autogpt_platform/backend and autogpt_platform/frontend.
Applied to files:
autogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
📚 Learning: 2026-03-31T15:37:38.626Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12623
File: autogpt_platform/backend/backend/copilot/tools/agent_generator/fixer.py:37-47
Timestamp: 2026-03-31T15:37:38.626Z
Learning: When validating/constructing Anthropic API model IDs in Significant-Gravitas/AutoGPT, allow the hyphen-separated Claude Opus 4.6 model ID `claude-opus-4-6` (it corresponds to `LlmModel.CLAUDE_4_6_OPUS` in `autogpt_platform/backend/backend/blocks/llm.py`). Do NOT require the dot-separated form in Anthropic contexts. Only OpenRouter routing variants should use the dot separator (e.g., `anthropic/claude-opus-4.6`); `claude-opus-4-6` should be treated as correct when passed to Anthropic, and flagged only if it’s used in the OpenRouter path where the dot form is expected.
Applied to files:
autogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
📚 Learning: 2026-04-15T02:43:36.890Z
Learnt from: ntindle
Repo: Significant-Gravitas/AutoGPT PR: 12780
File: autogpt_platform/backend/backend/copilot/tools/workspace_files.py:0-0
Timestamp: 2026-04-15T02:43:36.890Z
Learning: When reviewing Python exception handlers, do not flag `isinstance(e, X)` checks as dead/unreachable if the caught exception `X` is a subclass of the exception type being handled. For example, if `X` (e.g., `VirusScanError`) inherits from `ValueError` (directly or via an intermediate class) and it can be raised within an `except ValueError:` block, then `isinstance(e, X)` inside that handler is reachable and should not be treated as dead code.
Applied to files:
autogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
📚 Learning: 2026-04-21T04:35:34.710Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12865
File: autogpt_platform/backend/backend/data/credit.py:1584-1584
Timestamp: 2026-04-21T04:35:34.710Z
Learning: When reviewing this codebase, don’t flag snake_case attribute names (e.g., `subscription_tier`, `stripe_customer_id`, `top_up_config`) on the app-layer Pydantic `User` model as “wrong” field names. These are correct for the app-layer model and are expected to be mapped from the Prisma-layer camelCase fields (e.g., `subscriptionTier`, `stripeCustomerId`) inside methods like `User.from_db()`. Only Prisma-returned/raw objects would use camelCase, but functions like `get_user_by_id(user_id: str)` are expected to return the Pydantic app-layer model.
Applied to files:
autogpt_platform/backend/backend/data/db_manager.py
📚 Learning: 2026-04-22T11:46:04.431Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12881
File: autogpt_platform/backend/backend/copilot/config.py:0-0
Timestamp: 2026-04-22T11:46:04.431Z
Learning: Do not flag the Claude Sonnet 4.6 model ID as incorrect when it uses the project’s established hyphenated convention: `anthropic/claude-sonnet-4-6`. This hyphen form is the intentional, production convention and should be treated as valid (including in files like llm.py, blocks tests, reasoning.py, `_is_anthropic_model` tests, and config defaults). Note that OpenRouter also accepts the dot variant `anthropic/claude-sonnet-4.6`, so either form may be tolerated, but `anthropic/claude-sonnet-4-6` should be considered the standard to match project usage.
Applied to files:
autogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
📚 Learning: 2026-04-22T11:46:12.892Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12881
File: autogpt_platform/backend/backend/copilot/baseline/service.py:322-332
Timestamp: 2026-04-22T11:46:12.892Z
Learning: In this codebase (Significant-Gravitas/AutoGPT), OpenRouter-routed Anthropic model IDs should use the hyphen-separated convention (e.g., `anthropic/claude-sonnet-4-6`, `anthropic/claude-opus-4-6`). Although OpenRouter may accept both hyphen and dot variants, treat the hyphen-separated form as the intended, correct codebase-wide convention and do not flag it as an error. Only flag the dot-separated variant (e.g., `anthropic/claude-sonnet-4.6`) as incorrect when reviewing/validating model ID strings for OpenRouter-routed Anthropic models.
Applied to files:
autogpt_platform/backend/backend/data/db_manager.pyautogpt_platform/backend/backend/util/workspace.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/util/workspace_test.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
📚 Learning: 2026-03-04T08:04:35.881Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12273
File: autogpt_platform/backend/backend/copilot/tools/workspace_files.py:216-220
Timestamp: 2026-03-04T08:04:35.881Z
Learning: In the AutoGPT Copilot backend, ensure that SVG images are not treated as vision image types by excluding 'image/svg+xml' from INLINEABLE_MIME_TYPES and MULTIMODAL_TYPES in tool_adapter.py; the Claude API supports PNG, JPEG, GIF, and WebP for vision. SVGs (XML text) should be handled via the text path instead, not the vision path.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
📚 Learning: 2026-04-01T04:17:41.600Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12632
File: autogpt_platform/backend/backend/copilot/tools/workspace_files.py:0-0
Timestamp: 2026-04-01T04:17:41.600Z
Learning: When reviewing AutoGPT Copilot tool implementations, accept that `readOnlyHint=True` (provided via `ToolAnnotations`) may be applied unconditionally to *all* tools—even tools that have side effects (e.g., `bash_exec`, `write_workspace_file`, or other write/save operations). Do **not** flag these tools for having `readOnlyHint=True`; this is intentional to enable fully-parallel dispatch by the Anthropic SDK/CLI and has been E2E validated. Only flag `readOnlyHint` issues if they conflict with the established `ToolAnnotations` behavior (e.g., missing/incorrect propagation relative to the intended annotation mechanism).
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py
🔇 Additional comments (6)
autogpt_platform/backend/backend/data/db_manager.py (2)
120-129: LGTM — import aligns with the existing workspace symbol block.
329-337: LGTM — binding is consistent with all other workspace RPC registrations on bothDatabaseManagerandDatabaseManagerAsyncClient.Also applies to: 555-563
autogpt_platform/backend/backend/util/workspace.py (2)
18-18: LGTM —get_workspace_total_sizecorrectly removed from the direct import; routing now goes through theworkspace_db()accessor.
225-228: LGTM — routingget_workspace_total_sizethroughworkspace_db()insideasyncio.gatheris correct.Both arguments produce awaitables:
get_workspace_storage_limit_bytesis an async function (Python 3.8+ auto-detects it and wraps it inAsyncMockin tests), andworkspace_db().get_workspace_total_size(...)is anAsyncMock. Gather semantics are sound and the call cannot leave orphaned storage files on failure since it executes before any storage write.autogpt_platform/backend/backend/util/workspace_test.py (2)
67-74: LGTM —AsyncMock(return_value=0)is the correct mock type for the new async RPC method; the zero default ensures pre-existing tests remain well within any quota.
266-292: LGTM — the new regression test is well-structured and correctly verifies the routing fix.
assert_awaited_once_with("ws-123")outside thewithblock is intentional and correct (mock call history is retained after the patch context exits). The test covers both the happy path (write completes) and the routing invariant in a single pass, which is more valuable than a rejection-only check.
…y re-prompt The driver was resetting both _text_since_last_tool_result and _any_tool_results_seen to False before issuing the re-prompt. The adapter's thinking-only guard requires _any_tool_results_seen to be True to fire — so when the re-prompt round also returned thinking-only, the guard was skipped, no fallback text was emitted, and the user saw nothing. Keep _any_tool_results_seen sticky across the round so the second-pass placeholder/thinking-promote still fires. Adds a regression test that simulates the full two-round flow with the exact driver reset behaviour, asserting that the second pass emits fallback text when the model still produces thinking-only.
Codecov Report❌ Patch coverage is Additional details and impacted files@@ Coverage Diff @@
## dev #12992 +/- ##
==========================================
+ Coverage 69.88% 69.93% +0.05%
==========================================
Files 2140 2140
Lines 159436 159830 +394
Branches 16451 16488 +37
==========================================
+ Hits 111420 111779 +359
- Misses 44735 44766 +31
- Partials 3281 3285 +4
Flags with carried forward coverage won't be shown. Click here to find out more.
🚀 New features to boost your workflow:
|
…ONL, persist cap across retries, reset stale thinking on tool-result Address coderabbit + sentry findings on the original PR: * `thinking_only_reprompted` now lives on `_RetryState` (not the adapter) so a transient mid-turn retry that rebuilds `state.adapter` does not unlock another re-prompt round per attempt. * `_last_thinking_content` is reset whenever a new tool_result lands so pre-tool reasoning cannot bleed into the post-tool fallback as the model's "answer". * The synthetic re-prompt user message is now stripped from the CLI session JSONL before upload to GCS — `client.query(...)` would otherwise persist it and the next turn's `--resume` would replay it as a phantom user turn. Tests: * New `test_tool_result_clears_stale_thinking_so_fallback_does_not_leak_pre_tool_thinking` exercises the cross-tool-boundary case coderabbit asked for. * New `TestStripSyntheticReprompt` in service_test covers the JSONL filter for list-content / string-content user messages, image blocks (must be preserved), empty input, and malformed lines.
|
Addressed bot feedback in 99b0aff (and 2498c6b from the earlier round):
All 150 tests across |
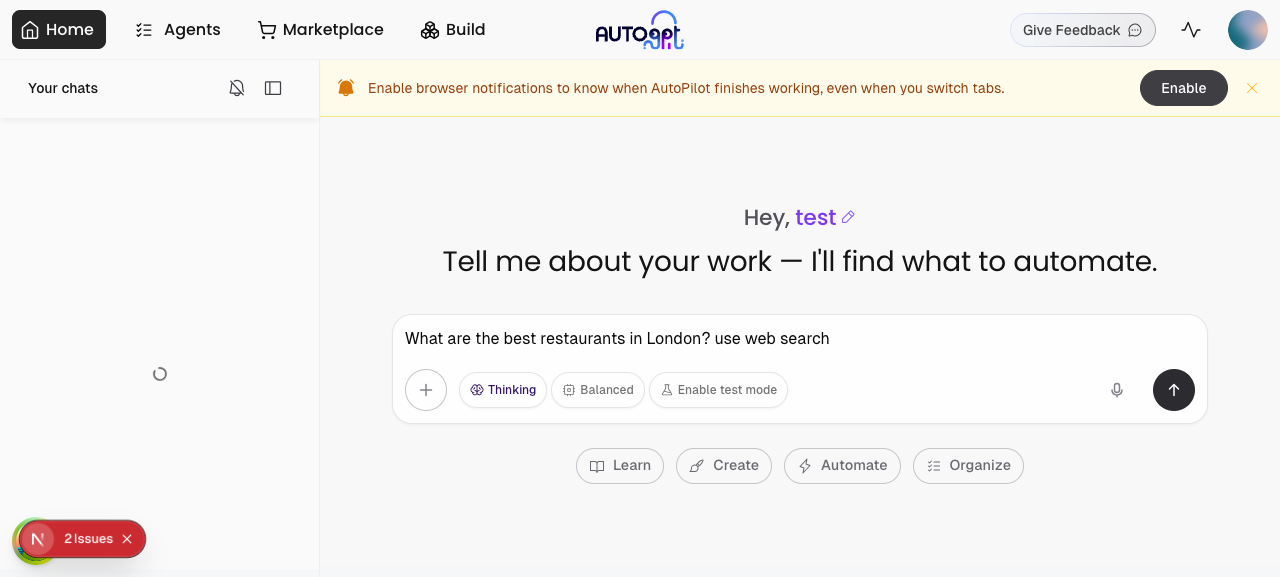
E2E Test ReportNative dev stack ( Issue 5 — copilot thinking-only fallbackRepro: "What are the best restaurants in London? use web search" (extended_thinking)
In this run the model produced real text alongside thinking, so the new re-prompt path was not triggered — the layered fallback (re-prompt → promote-thinking → placeholder) is in place but the happy path didn't need it. Verdict: PASS. Issue 2 — workspace storage-limit pre-check on copilot_executorRepro: Asked the copilot to use
Verdict: PASS. The original Out of scope
Safe to merge from a runtime perspective: yes.Screenshots
|
Also compresses the multi-line narrative comment per minimal-comments rule.
There was a problem hiding this comment.
♻️ Duplicate comments (2)
autogpt_platform/backend/backend/copilot/sdk/response_adapter.py (1)
385-389:⚠️ Potential issue | 🟠 Major | ⚡ Quick winAlso clear stale thinking on flushed tool-result boundaries.
Line 385 correctly resets
_last_thinking_contentfor explicitUserMessagetool results, but the flush path can still carry stale pre-tool thinking into fallback text promotion.Suggested patch
@@ def flush_unresolved_tool_calls(self, responses: list[StreamBaseResponse]) -> None: if flushed: # Mirror the UserMessage tool_result path: a flushed tool output is # still a tool_result as far as the thinking-only-final-turn guard # is concerned. Without this, a turn whose ONLY tool outputs come # from the flush path (SDK built-ins like WebSearch) would miss # the fallback synthesis if the model then produced no text. self._text_since_last_tool_result = False self._any_tool_results_seen = True + self._last_thinking_content = "" if self.step_open: responses.append(StreamFinishStep()) self.step_open = False🤖 Prompt for AI Agents
Verify each finding against the current code and only fix it if needed. In `@autogpt_platform/backend/backend/copilot/sdk/response_adapter.py` around lines 385 - 389, The code resets self._last_thinking_content for explicit UserMessage tool results but does not clear it when tool-result flush boundaries occur, allowing stale pre-tool thinking to leak into fallback promotion; update the flush-path logic that handles flushed tool results (the function/method that emits or processes flushed tool-result boundaries) to also set self._last_thinking_content = "" whenever a tool-result flush is processed, ensuring both explicit UserMessage handling and the flush branch clear the same state.autogpt_platform/backend/backend/copilot/sdk/service.py (1)
4260-4263:⚠️ Potential issue | 🟠 Major | ⚡ Quick winPropagate the re-prompt cap through transient adapter rebuilds too.
This copy only covers context-retry rebuilds.
_do_transient_backoff()also recreatesstate.adapterand currently resetsthinking_only_reprompted, which can allow a second synthetic re-prompt in the same turn after a transient retry.Suggested fix
diff --git a/autogpt_platform/backend/backend/copilot/sdk/service.py b/autogpt_platform/backend/backend/copilot/sdk/service.py @@ def _do_transient_backoff( state.adapter = SDKResponseAdapter( message_id=message_id, session_id=session_id, render_reasoning_in_ui=config.render_reasoning_in_ui, ) + # Preserve per-turn thinking-only re-prompt cap across transient retries. + state.adapter.thinking_only_reprompted = state.thinking_only_reprompted state.usage.reset()🤖 Prompt for AI Agents
Verify each finding against the current code and only fix it if needed. In `@autogpt_platform/backend/backend/copilot/sdk/service.py` around lines 4260 - 4263, When rebuilding the adapter inside _do_transient_backoff(), preserve the per-turn re-prompt cap by copying state.thinking_only_reprompted onto the new adapter instead of resetting it; locate the adapter recreation in _do_transient_backoff() and set state.adapter.thinking_only_reprompted = state.thinking_only_reprompted (and remove any code that clears or resets thinking_only_reprompted) so transient retries don't allow a second synthetic re-prompt in the same turn.
🧹 Nitpick comments (2)
autogpt_platform/backend/backend/copilot/sdk/response_adapter.py (1)
147-517: 🏗️ Heavy liftExtract the ResultMessage thinking-only branch into a helper.
convert_messagekeeps growing in a critical path; pulling the thinking-only result handling into a dedicated helper would lower regression risk and make step/text/reasoning state transitions easier to validate.As per coding guidelines: Keep functions under ~40 lines; extract named helpers when a function grows longer.
🤖 Prompt for AI Agents
Verify each finding against the current code and only fix it if needed. In `@autogpt_platform/backend/backend/copilot/sdk/response_adapter.py` around lines 147 - 517, convert_message's ResultMessage handling is too long—extract the "thinking-only final turn" branch into a new helper (e.g. _handle_thinking_only_final_turn) that encapsulates the condition checks and all state transitions/emissions for the thinking-only path; move the logic that reads/sets self._any_tool_results_seen, self._text_since_last_tool_result, self.thinking_only_reprompted, self.pending_thinking_only_reprompt, and manipulates step_open/text/reasoning (calls to _end_text_if_open, _end_reasoning_if_open, _ensure_text_started, appending StreamStartStep/StreamFinishStep/StreamTextDelta/StreamFinish as needed) into that helper and have convert_message call it where the original branch was, preserving early returns and side effects (retain use of _last_thinking_content, text_block_id, and existing Stream* classes); update/keep unit tests verifying identical emitted responses and state after ResultMessage handling.autogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py (1)
497-607: ⚡ Quick winTighten the driver-reset regression with an explicit guard assertion.
This test currently proves the emitted fallback text, but it would be stronger to assert the reset state the comment calls out directly. Otherwise, a future regression that clears
_any_tool_results_seencould still slip through if some other path happens to emit text.Suggested tweak
adapter.pending_thinking_only_reprompt = False adapter.thinking_only_reprompted = True adapter._text_since_last_tool_result = False + assert adapter._any_tool_results_seen is True🤖 Prompt for AI Agents
Verify each finding against the current code and only fix it if needed. In `@autogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py` around lines 497 - 607, Add an explicit guard assertion that the driver reset preserved the tool-result flag: in test_result_success_thinking_only_two_rounds_with_driver_reset_emits_fallback, after the "Driver behaviour between rounds" block where you set pending_thinking_only_reprompt = False, thinking_only_reprompted = True, and _text_since_last_tool_result = False, add assert adapter._any_tool_results_seen is True to ensure the reset didn't clear that state used by the ResultMessage guard.
🤖 Prompt for all review comments with AI agents
Verify each finding against the current code and only fix it if needed.
Duplicate comments:
In `@autogpt_platform/backend/backend/copilot/sdk/response_adapter.py`:
- Around line 385-389: The code resets self._last_thinking_content for explicit
UserMessage tool results but does not clear it when tool-result flush boundaries
occur, allowing stale pre-tool thinking to leak into fallback promotion; update
the flush-path logic that handles flushed tool results (the function/method that
emits or processes flushed tool-result boundaries) to also set
self._last_thinking_content = "" whenever a tool-result flush is processed,
ensuring both explicit UserMessage handling and the flush branch clear the same
state.
In `@autogpt_platform/backend/backend/copilot/sdk/service.py`:
- Around line 4260-4263: When rebuilding the adapter inside
_do_transient_backoff(), preserve the per-turn re-prompt cap by copying
state.thinking_only_reprompted onto the new adapter instead of resetting it;
locate the adapter recreation in _do_transient_backoff() and set
state.adapter.thinking_only_reprompted = state.thinking_only_reprompted (and
remove any code that clears or resets thinking_only_reprompted) so transient
retries don't allow a second synthetic re-prompt in the same turn.
---
Nitpick comments:
In `@autogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py`:
- Around line 497-607: Add an explicit guard assertion that the driver reset
preserved the tool-result flag: in
test_result_success_thinking_only_two_rounds_with_driver_reset_emits_fallback,
after the "Driver behaviour between rounds" block where you set
pending_thinking_only_reprompt = False, thinking_only_reprompted = True, and
_text_since_last_tool_result = False, add assert adapter._any_tool_results_seen
is True to ensure the reset didn't clear that state used by the ResultMessage
guard.
In `@autogpt_platform/backend/backend/copilot/sdk/response_adapter.py`:
- Around line 147-517: convert_message's ResultMessage handling is too
long—extract the "thinking-only final turn" branch into a new helper (e.g.
_handle_thinking_only_final_turn) that encapsulates the condition checks and all
state transitions/emissions for the thinking-only path; move the logic that
reads/sets self._any_tool_results_seen, self._text_since_last_tool_result,
self.thinking_only_reprompted, self.pending_thinking_only_reprompt, and
manipulates step_open/text/reasoning (calls to _end_text_if_open,
_end_reasoning_if_open, _ensure_text_started, appending
StreamStartStep/StreamFinishStep/StreamTextDelta/StreamFinish as needed) into
that helper and have convert_message call it where the original branch was,
preserving early returns and side effects (retain use of _last_thinking_content,
text_block_id, and existing Stream* classes); update/keep unit tests verifying
identical emitted responses and state after ResultMessage handling.
ℹ️ Review info
⚙️ Run configuration
Configuration used: Organization UI
Review profile: CHILL
Plan: Pro
Run ID: bfcca2bc-bdf7-423d-8283-b6955fd56f27
📒 Files selected for processing (4)
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
📜 Review details
⏰ Context from checks skipped due to timeout of 90000ms. You can increase the timeout in your CodeRabbit configuration to a maximum of 15 minutes (900000ms). (12)
- GitHub Check: check API types
- GitHub Check: test (3.13)
- GitHub Check: type-check (3.11)
- GitHub Check: test (3.11)
- GitHub Check: type-check (3.13)
- GitHub Check: test (3.12)
- GitHub Check: type-check (3.12)
- GitHub Check: Seer Code Review
- GitHub Check: Check PR Status
- GitHub Check: Analyze (python)
- GitHub Check: Analyze (typescript)
- GitHub Check: end-to-end tests
🧰 Additional context used
📓 Path-based instructions (3)
autogpt_platform/backend/**/*.py
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
autogpt_platform/backend/**/*.py: Use Python 3.11 (required; managed by Poetry via pyproject.toml) for backend development
Always run 'poetry run format' (Black + isort) before linting in backend development
Always run 'poetry run lint' (ruff) after formatting in backend development
autogpt_platform/backend/**/*.py: Usepoetry run ...command for executing Python package dependencies
Use top-level imports only — avoid local/inner imports except for lazy imports of heavy optional dependencies likeopenpyxl
Use absolute imports withfrom backend.module import ...for cross-package imports; single-dot relative imports are acceptable for sibling modules within the same package; avoid double-dot relative imports
Do not use duck typing — avoidhasattr/getattr/isinstancefor type dispatch; use typed interfaces/unions/protocols instead
Use Pydantic models over dataclass/namedtuple/dict for structured data
Do not use linter suppressors — no# type: ignore,# noqa,# pyright: ignore; fix the type/code instead
Prefer list comprehensions over manual loop-and-append patterns
Use early return with guard clauses first to avoid deep nesting
Use%sfor deferred interpolation indebuglog statements for efficiency; use f-strings elsewhere for readability (e.g.,logger.debug("Processing %s items", count)vslogger.info(f"Processing {count} items"))
Sanitize error paths by usingos.path.basename()in error messages to avoid leaking directory structure
Be aware of TOCTOU (Time-Of-Check-Time-Of-Use) issues — avoid check-then-act patterns for file access and credit charging
Usetransaction=Truefor Redis pipelines to ensure atomicity on multi-step operations
Usemax(0, value)guards for computed values that should never be negative
Keep files under ~300 lines; if a file grows beyond this, split by responsibility (extract helpers, models, or a sub-module into a new file)
Keep functions under ~40 lines; extract named helpers when a function grows longer
...
Files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
autogpt_platform/{backend,autogpt_libs}/**/*.py
📄 CodeRabbit inference engine (AGENTS.md)
Format Python code with
poetry run format
Files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
autogpt_platform/backend/**/*_test.py
📄 CodeRabbit inference engine (autogpt_platform/backend/AGENTS.md)
autogpt_platform/backend/**/*_test.py: Use pytest with snapshot testing for API responses
Colocate test files with source files using*_test.pynaming convention
Mock at boundaries — mock where the symbol is used, not where it's defined; after refactoring, update mock targets to match new module paths
UseAsyncMockfromunittest.mockfor async functions in tests
When writing tests, use Test-Driven Development (TDD): write failing tests marked with@pytest.mark.xfailbefore implementation, then remove the marker once the implementation is complete
When creating snapshots in tests, usepoetry run pytest path/to/test.py --snapshot-update; always review snapshot changes withgit diffbefore committing
Files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
🧠 Learnings (9)
📚 Learning: 2026-02-26T17:02:22.448Z
Learnt from: Pwuts
Repo: Significant-Gravitas/AutoGPT PR: 12211
File: .pre-commit-config.yaml:160-179
Timestamp: 2026-02-26T17:02:22.448Z
Learning: Keep the pre-commit hook pattern broad for autogpt_platform/backend to ensure OpenAPI schema changes are captured. Do not narrow to backend/api/ alone, since the generated schema depends on Pydantic models across multiple directories (backend/data/, backend/blocks/, backend/copilot/, backend/integrations/, backend/util/). Narrowing could miss schema changes and cause frontend type desynchronization.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
📚 Learning: 2026-03-04T08:04:35.881Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12273
File: autogpt_platform/backend/backend/copilot/tools/workspace_files.py:216-220
Timestamp: 2026-03-04T08:04:35.881Z
Learning: In the AutoGPT Copilot backend, ensure that SVG images are not treated as vision image types by excluding 'image/svg+xml' from INLINEABLE_MIME_TYPES and MULTIMODAL_TYPES in tool_adapter.py; the Claude API supports PNG, JPEG, GIF, and WebP for vision. SVGs (XML text) should be handled via the text path instead, not the vision path.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
📚 Learning: 2026-04-01T04:17:41.600Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12632
File: autogpt_platform/backend/backend/copilot/tools/workspace_files.py:0-0
Timestamp: 2026-04-01T04:17:41.600Z
Learning: When reviewing AutoGPT Copilot tool implementations, accept that `readOnlyHint=True` (provided via `ToolAnnotations`) may be applied unconditionally to *all* tools—even tools that have side effects (e.g., `bash_exec`, `write_workspace_file`, or other write/save operations). Do **not** flag these tools for having `readOnlyHint=True`; this is intentional to enable fully-parallel dispatch by the Anthropic SDK/CLI and has been E2E validated. Only flag `readOnlyHint` issues if they conflict with the established `ToolAnnotations` behavior (e.g., missing/incorrect propagation relative to the intended annotation mechanism).
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
📚 Learning: 2026-03-05T15:42:08.207Z
Learnt from: ntindle
Repo: Significant-Gravitas/AutoGPT PR: 12297
File: .claude/skills/backend-check/SKILL.md:14-16
Timestamp: 2026-03-05T15:42:08.207Z
Learning: In Python files under autogpt_platform/backend (recursively), rely on poetry run format to perform formatting (Black + isort) and linting (ruff). Do not run poetry run lint as a separate step after poetry run format, since format already includes linting checks.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
📚 Learning: 2026-03-16T16:35:40.236Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12440
File: autogpt_platform/backend/backend/api/features/workflow_import.py:54-63
Timestamp: 2026-03-16T16:35:40.236Z
Learning: Avoid using the word 'competitor' in public-facing identifiers and text. Use neutral naming for API paths, model names, function names, and UI text. Examples: rename 'CompetitorFormat' to 'SourcePlatform', 'convert_competitor_workflow' to 'convert_workflow', '/competitor-workflow' to '/workflow'. Apply this guideline to files under autogpt_platform/backend and autogpt_platform/frontend.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
📚 Learning: 2026-03-31T15:37:38.626Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12623
File: autogpt_platform/backend/backend/copilot/tools/agent_generator/fixer.py:37-47
Timestamp: 2026-03-31T15:37:38.626Z
Learning: When validating/constructing Anthropic API model IDs in Significant-Gravitas/AutoGPT, allow the hyphen-separated Claude Opus 4.6 model ID `claude-opus-4-6` (it corresponds to `LlmModel.CLAUDE_4_6_OPUS` in `autogpt_platform/backend/backend/blocks/llm.py`). Do NOT require the dot-separated form in Anthropic contexts. Only OpenRouter routing variants should use the dot separator (e.g., `anthropic/claude-opus-4.6`); `claude-opus-4-6` should be treated as correct when passed to Anthropic, and flagged only if it’s used in the OpenRouter path where the dot form is expected.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
📚 Learning: 2026-04-15T02:43:36.890Z
Learnt from: ntindle
Repo: Significant-Gravitas/AutoGPT PR: 12780
File: autogpt_platform/backend/backend/copilot/tools/workspace_files.py:0-0
Timestamp: 2026-04-15T02:43:36.890Z
Learning: When reviewing Python exception handlers, do not flag `isinstance(e, X)` checks as dead/unreachable if the caught exception `X` is a subclass of the exception type being handled. For example, if `X` (e.g., `VirusScanError`) inherits from `ValueError` (directly or via an intermediate class) and it can be raised within an `except ValueError:` block, then `isinstance(e, X)` inside that handler is reachable and should not be treated as dead code.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
📚 Learning: 2026-04-22T11:46:04.431Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12881
File: autogpt_platform/backend/backend/copilot/config.py:0-0
Timestamp: 2026-04-22T11:46:04.431Z
Learning: Do not flag the Claude Sonnet 4.6 model ID as incorrect when it uses the project’s established hyphenated convention: `anthropic/claude-sonnet-4-6`. This hyphen form is the intentional, production convention and should be treated as valid (including in files like llm.py, blocks tests, reasoning.py, `_is_anthropic_model` tests, and config defaults). Note that OpenRouter also accepts the dot variant `anthropic/claude-sonnet-4.6`, so either form may be tolerated, but `anthropic/claude-sonnet-4-6` should be considered the standard to match project usage.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
📚 Learning: 2026-04-22T11:46:12.892Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12881
File: autogpt_platform/backend/backend/copilot/baseline/service.py:322-332
Timestamp: 2026-04-22T11:46:12.892Z
Learning: In this codebase (Significant-Gravitas/AutoGPT), OpenRouter-routed Anthropic model IDs should use the hyphen-separated convention (e.g., `anthropic/claude-sonnet-4-6`, `anthropic/claude-opus-4-6`). Although OpenRouter may accept both hyphen and dot variants, treat the hyphen-separated form as the intended, correct codebase-wide convention and do not flag it as an error. Only flag the dot-separated variant (e.g., `anthropic/claude-sonnet-4.6`) as incorrect when reviewing/validating model ID strings for OpenRouter-routed Anthropic models.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/response_adapter.pyautogpt_platform/backend/backend/copilot/sdk/service.pyautogpt_platform/backend/backend/copilot/sdk/response_adapter_test.pyautogpt_platform/backend/backend/copilot/sdk/service_test.py
🔇 Additional comments (5)
autogpt_platform/backend/backend/copilot/sdk/service_test.py (1)
1236-1288: Good coverage for synthetic re-prompt stripping behavior.This suite validates the critical keep/drop paths (including malformed JSONL and non-text user blocks) and matches the intended upload/resume safety behavior.
autogpt_platform/backend/backend/copilot/sdk/response_adapter.py (1)
448-484: The one-shot defer/re-prompt/fallback flow is well-structured.This correctly bounds re-prompting to one round and only promotes fallback text after the second thinking-only outcome.
autogpt_platform/backend/backend/copilot/sdk/response_adapter_test.py (3)
455-494: Good first-pass coverage.The deferral behavior is asserted clearly here: no placeholder, no
StreamFinish, and the pending reprompt flag is set as expected.
609-688: Nice regression pair.These two tests cover the important stale-thinking cases well: pre-tool reasoning gets cleared, and the post-reprompt placeholder still appears when there is no promoted thinking content.
1035-1038: Good assertion on the unresolved-tool flush path.This keeps the built-in-tool flush behavior tied to the new thinking-only reprompt flow, so the adapter doesn't silently finish too early.
…op the while-True wrapper The previous re-prompt structure wrapped the entire 535-line `async for sdk_msg in _iter_sdk_messages(client):` block in a `while True: ... continue/break` loop, which indented the body by +4 spaces and made the diff hadouken-shaped. Pull the loop body out as a module-level async generator helper `_consume_sdk_until_done(client, ctx, state, acc, loop_state)` and a small `_SDKLoopState` dataclass for the per-attempt locals (`last_real_msg_time`, `last_flush_time`, `msgs_since_flush`, `consecutive_empty_tool_calls`, `ended_with_stream_error`). Caller in `_run_stream_attempt` is now a flat sequence: construct `loop_state` → first pass → if thinking-only re-prompt needed, fire the synthetic query → second pass. No wrapper, body indent unchanged from pre-refactor. `_FLUSH_INTERVAL_SECONDS` / `_FLUSH_MESSAGE_THRESHOLD` promoted to module-level constants so the helper sees them. All 150 unit tests on changed files still green.
There was a problem hiding this comment.
Actionable comments posted: 1
♻️ Duplicate comments (1)
autogpt_platform/backend/backend/copilot/sdk/service.py (1)
1820-1841:⚠️ Potential issue | 🟠 Major | ⚡ Quick winPropagate
thinking_only_repromptedon transient backoff too.There’s still one adapter rebuild path that drops the per-turn cap.
_do_transient_backoff()creates a freshSDKResponseAdapterwithout copyingstate.thinking_only_reprompted, so a post-reprompt transient retry can setpending_thinking_only_repromptagain even though the service will refuse a second reprompt. That leaves the turn without a normal finish and can fall into the stopped-by-user cleanup path.Suggested fix
state.adapter = SDKResponseAdapter( message_id=message_id, session_id=session_id, render_reasoning_in_ui=config.render_reasoning_in_ui, ) + state.adapter.thinking_only_reprompted = state.thinking_only_reprompted state.usage.reset()Also applies to: 4285-4287
🤖 Prompt for AI Agents
Verify each finding against the current code and only fix it if needed. In `@autogpt_platform/backend/backend/copilot/sdk/service.py` around lines 1820 - 1841, The transient backoff path rebuilds the SDKResponseAdapter without preserving the per-turn reprompt cap, so copy the current state.thinking_only_reprompted into the new adapter: when creating the SDKResponseAdapter in _do_transient_backoff (the shown adapter instantiation) set the adapter's thinking_only_reprompted/pending_thinking_only_reprompt field from state.thinking_only_reprompted (or assign it immediately after construction) so the per-turn cap is preserved; apply the same change to the other adapter-rebuild site referenced (lines ~4285-4287) to ensure both transient-retry paths propagate the flag.
🤖 Prompt for all review comments with AI agents
Verify each finding against the current code and only fix it if needed.
Inline comments:
In `@autogpt_platform/backend/backend/copilot/sdk/service.py`:
- Around line 194-208: The helper _consume_sdk_until_done no longer propagates
detailed handled-error info, so add fields to _SDKLoopState (e.g.,
stream_error_msg and stream_error_code or stream_error_exc) and set those fields
inside the idle_timeout, transient_api_error, and circuit-breaker branches
within _consume_sdk_until_done; then have _run_stream_attempt inspect those
fields after the helper returns (instead of just checking
ended_with_stream_error) and raise or reclassify using the stored
stream_error_msg/code so transient backoff and finalize paths receive the
original handled error details.
---
Duplicate comments:
In `@autogpt_platform/backend/backend/copilot/sdk/service.py`:
- Around line 1820-1841: The transient backoff path rebuilds the
SDKResponseAdapter without preserving the per-turn reprompt cap, so copy the
current state.thinking_only_reprompted into the new adapter: when creating the
SDKResponseAdapter in _do_transient_backoff (the shown adapter instantiation)
set the adapter's thinking_only_reprompted/pending_thinking_only_reprompt field
from state.thinking_only_reprompted (or assign it immediately after
construction) so the per-turn cap is preserved; apply the same change to the
other adapter-rebuild site referenced (lines ~4285-4287) to ensure both
transient-retry paths propagate the flag.
🪄 Autofix (Beta)
Fix all unresolved CodeRabbit comments on this PR:
- Push a commit to this branch (recommended)
- Create a new PR with the fixes
ℹ️ Review info
⚙️ Run configuration
Configuration used: Organization UI
Review profile: CHILL
Plan: Pro
Run ID: 232942e8-5e48-4169-b5e8-9503904cd175
📒 Files selected for processing (1)
autogpt_platform/backend/backend/copilot/sdk/service.py
📜 Review details
⏰ Context from checks skipped due to timeout of 90000ms. You can increase the timeout in your CodeRabbit configuration to a maximum of 15 minutes (900000ms). (13)
- GitHub Check: type-check (3.13)
- GitHub Check: lint
- GitHub Check: type-check (3.11)
- GitHub Check: type-check (3.12)
- GitHub Check: test (3.12)
- GitHub Check: test (3.13)
- GitHub Check: test (3.11)
- GitHub Check: check API types
- GitHub Check: Seer Code Review
- GitHub Check: end-to-end tests
- GitHub Check: Analyze (typescript)
- GitHub Check: Analyze (python)
- GitHub Check: Check PR Status
🧰 Additional context used
📓 Path-based instructions (2)
autogpt_platform/backend/**/*.py
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
autogpt_platform/backend/**/*.py: Use Python 3.11 (required; managed by Poetry via pyproject.toml) for backend development
Always run 'poetry run format' (Black + isort) before linting in backend development
Always run 'poetry run lint' (ruff) after formatting in backend development
autogpt_platform/backend/**/*.py: Usepoetry run ...command for executing Python package dependencies
Use top-level imports only — avoid local/inner imports except for lazy imports of heavy optional dependencies likeopenpyxl
Use absolute imports withfrom backend.module import ...for cross-package imports; single-dot relative imports are acceptable for sibling modules within the same package; avoid double-dot relative imports
Do not use duck typing — avoidhasattr/getattr/isinstancefor type dispatch; use typed interfaces/unions/protocols instead
Use Pydantic models over dataclass/namedtuple/dict for structured data
Do not use linter suppressors — no# type: ignore,# noqa,# pyright: ignore; fix the type/code instead
Prefer list comprehensions over manual loop-and-append patterns
Use early return with guard clauses first to avoid deep nesting
Use%sfor deferred interpolation indebuglog statements for efficiency; use f-strings elsewhere for readability (e.g.,logger.debug("Processing %s items", count)vslogger.info(f"Processing {count} items"))
Sanitize error paths by usingos.path.basename()in error messages to avoid leaking directory structure
Be aware of TOCTOU (Time-Of-Check-Time-Of-Use) issues — avoid check-then-act patterns for file access and credit charging
Usetransaction=Truefor Redis pipelines to ensure atomicity on multi-step operations
Usemax(0, value)guards for computed values that should never be negative
Keep files under ~300 lines; if a file grows beyond this, split by responsibility (extract helpers, models, or a sub-module into a new file)
Keep functions under ~40 lines; extract named helpers when a function grows longer
...
Files:
autogpt_platform/backend/backend/copilot/sdk/service.py
autogpt_platform/{backend,autogpt_libs}/**/*.py
📄 CodeRabbit inference engine (AGENTS.md)
Format Python code with
poetry run format
Files:
autogpt_platform/backend/backend/copilot/sdk/service.py
🧠 Learnings (9)
📚 Learning: 2026-02-26T17:02:22.448Z
Learnt from: Pwuts
Repo: Significant-Gravitas/AutoGPT PR: 12211
File: .pre-commit-config.yaml:160-179
Timestamp: 2026-02-26T17:02:22.448Z
Learning: Keep the pre-commit hook pattern broad for autogpt_platform/backend to ensure OpenAPI schema changes are captured. Do not narrow to backend/api/ alone, since the generated schema depends on Pydantic models across multiple directories (backend/data/, backend/blocks/, backend/copilot/, backend/integrations/, backend/util/). Narrowing could miss schema changes and cause frontend type desynchronization.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/service.py
📚 Learning: 2026-03-04T08:04:35.881Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12273
File: autogpt_platform/backend/backend/copilot/tools/workspace_files.py:216-220
Timestamp: 2026-03-04T08:04:35.881Z
Learning: In the AutoGPT Copilot backend, ensure that SVG images are not treated as vision image types by excluding 'image/svg+xml' from INLINEABLE_MIME_TYPES and MULTIMODAL_TYPES in tool_adapter.py; the Claude API supports PNG, JPEG, GIF, and WebP for vision. SVGs (XML text) should be handled via the text path instead, not the vision path.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/service.py
📚 Learning: 2026-04-01T04:17:41.600Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12632
File: autogpt_platform/backend/backend/copilot/tools/workspace_files.py:0-0
Timestamp: 2026-04-01T04:17:41.600Z
Learning: When reviewing AutoGPT Copilot tool implementations, accept that `readOnlyHint=True` (provided via `ToolAnnotations`) may be applied unconditionally to *all* tools—even tools that have side effects (e.g., `bash_exec`, `write_workspace_file`, or other write/save operations). Do **not** flag these tools for having `readOnlyHint=True`; this is intentional to enable fully-parallel dispatch by the Anthropic SDK/CLI and has been E2E validated. Only flag `readOnlyHint` issues if they conflict with the established `ToolAnnotations` behavior (e.g., missing/incorrect propagation relative to the intended annotation mechanism).
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/service.py
📚 Learning: 2026-03-05T15:42:08.207Z
Learnt from: ntindle
Repo: Significant-Gravitas/AutoGPT PR: 12297
File: .claude/skills/backend-check/SKILL.md:14-16
Timestamp: 2026-03-05T15:42:08.207Z
Learning: In Python files under autogpt_platform/backend (recursively), rely on poetry run format to perform formatting (Black + isort) and linting (ruff). Do not run poetry run lint as a separate step after poetry run format, since format already includes linting checks.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/service.py
📚 Learning: 2026-03-16T16:35:40.236Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12440
File: autogpt_platform/backend/backend/api/features/workflow_import.py:54-63
Timestamp: 2026-03-16T16:35:40.236Z
Learning: Avoid using the word 'competitor' in public-facing identifiers and text. Use neutral naming for API paths, model names, function names, and UI text. Examples: rename 'CompetitorFormat' to 'SourcePlatform', 'convert_competitor_workflow' to 'convert_workflow', '/competitor-workflow' to '/workflow'. Apply this guideline to files under autogpt_platform/backend and autogpt_platform/frontend.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/service.py
📚 Learning: 2026-03-31T15:37:38.626Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12623
File: autogpt_platform/backend/backend/copilot/tools/agent_generator/fixer.py:37-47
Timestamp: 2026-03-31T15:37:38.626Z
Learning: When validating/constructing Anthropic API model IDs in Significant-Gravitas/AutoGPT, allow the hyphen-separated Claude Opus 4.6 model ID `claude-opus-4-6` (it corresponds to `LlmModel.CLAUDE_4_6_OPUS` in `autogpt_platform/backend/backend/blocks/llm.py`). Do NOT require the dot-separated form in Anthropic contexts. Only OpenRouter routing variants should use the dot separator (e.g., `anthropic/claude-opus-4.6`); `claude-opus-4-6` should be treated as correct when passed to Anthropic, and flagged only if it’s used in the OpenRouter path where the dot form is expected.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/service.py
📚 Learning: 2026-04-15T02:43:36.890Z
Learnt from: ntindle
Repo: Significant-Gravitas/AutoGPT PR: 12780
File: autogpt_platform/backend/backend/copilot/tools/workspace_files.py:0-0
Timestamp: 2026-04-15T02:43:36.890Z
Learning: When reviewing Python exception handlers, do not flag `isinstance(e, X)` checks as dead/unreachable if the caught exception `X` is a subclass of the exception type being handled. For example, if `X` (e.g., `VirusScanError`) inherits from `ValueError` (directly or via an intermediate class) and it can be raised within an `except ValueError:` block, then `isinstance(e, X)` inside that handler is reachable and should not be treated as dead code.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/service.py
📚 Learning: 2026-04-22T11:46:04.431Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12881
File: autogpt_platform/backend/backend/copilot/config.py:0-0
Timestamp: 2026-04-22T11:46:04.431Z
Learning: Do not flag the Claude Sonnet 4.6 model ID as incorrect when it uses the project’s established hyphenated convention: `anthropic/claude-sonnet-4-6`. This hyphen form is the intentional, production convention and should be treated as valid (including in files like llm.py, blocks tests, reasoning.py, `_is_anthropic_model` tests, and config defaults). Note that OpenRouter also accepts the dot variant `anthropic/claude-sonnet-4.6`, so either form may be tolerated, but `anthropic/claude-sonnet-4-6` should be considered the standard to match project usage.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/service.py
📚 Learning: 2026-04-22T11:46:12.892Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12881
File: autogpt_platform/backend/backend/copilot/baseline/service.py:322-332
Timestamp: 2026-04-22T11:46:12.892Z
Learning: In this codebase (Significant-Gravitas/AutoGPT), OpenRouter-routed Anthropic model IDs should use the hyphen-separated convention (e.g., `anthropic/claude-sonnet-4-6`, `anthropic/claude-opus-4-6`). Although OpenRouter may accept both hyphen and dot variants, treat the hyphen-separated form as the intended, correct codebase-wide convention and do not flag it as an error. Only flag the dot-separated variant (e.g., `anthropic/claude-sonnet-4.6`) as incorrect when reviewing/validating model ID strings for OpenRouter-routed Anthropic models.
Applied to files:
autogpt_platform/backend/backend/copilot/sdk/service.py
…reset out of consume helper Three follow-ups on the helper-extraction refactor: * Promote ``stream_error_msg`` and ``stream_error_code`` to fields on ``_SDKLoopState`` and rewrite the helper's writes accordingly. Without this, idle-timeout / transient_api_error / circuit-breaker error metadata set inside ``_consume_sdk_until_done`` was lost when the caller raised ``_HandledStreamError`` — the outer retry loop saw a generic ``"Stream error handled"`` instead of the specific code and could not decide whether to retry transient errors. (sentry HIGH + coderabbit CRITICAL on the previous push.) * Reset ``acc.has_tool_results = False`` alongside the other re-prompt resets so the second round's pre-text placeholder branch does not fire on a stale tool_result from round one. (sentry MEDIUM.) * Initialise ``ended_with_stream_error = False`` at the top of ``stream_chat_completion_sdk`` so the post-loop guards see a bound name even on early-exit paths — fixes pyright 5x ``reportPossiblyUnboundVariable`` on the prior commit and the matching ``UnboundLocalError`` runtime failures in ``retry_scenarios_test.py``. 48 retry-scenarios tests + 150 unit tests on changed files all green.
…ce-storage-limit-prisma
…ynthetic reprompt; cover consume helper Two follow-ups for the post-refactor review pass: * **transcript / JSONL asymmetry on resume** (sentry MEDIUM) — the strip helper was only dropping the synthetic re-prompt user line, leaving the empty thinking-only AssistantMessage that immediately preceded it in the persisted JSONL. After strip, the role-alternation went ``assistant (empty) → assistant (real reply)`` with no user message between, which Anthropic's resume contract rejects. Extend ``_strip_synthetic_reprompt_from_cli_jsonl`` to also drop that preceding empty / thinking-only AssistantMessage so the post-strip JSONL stays well-formed. Adds ``_is_synthetic_reprompt_user_entry`` and ``_is_empty_assistant_entry`` helpers + two new unit tests. * **codecov patch coverage** — add direct integration coverage for ``_consume_sdk_until_done`` (the helper extracted in the earlier refactor) by patching ``_iter_sdk_messages`` and driving the helper with a fake message stream. Three tests cover the happy path (TextBlock → ResultMessage success), the heartbeat sentinel (``None`` → lock refresh + ``StreamHeartbeat``), and the thinking-only-after-tool-result deferral (no ``StreamFinish`` so the caller can re-prompt). Together with the new strip helpers this pulls the ``service.py`` patch lines into covered territory.
…oundtrip + result-error branch Two more integration tests against the patched-``_iter_sdk_messages`` rig: * ``test_tool_use_roundtrip`` — full SystemMessage(init) → AssistantMessage with ToolUseBlock → UserMessage with ToolResultBlock → AssistantMessage with TextBlock → ResultMessage(success). Hits the ``StreamToolInputAvailable`` / ``StreamToolOutputAvailable`` dispatch paths and the AssistantMessage continuation after a tool result. * ``test_result_subtype_error_yields_stream_error`` — covers the ``ResultMessage(subtype="error")`` branch: helper must surface ``StreamError`` paired with ``StreamFinish``. Pulls additional ``_consume_sdk_until_done`` body lines into the codecov-covered patch tally.
…nly re-prompt Sentry MEDIUM finding on the re-prompt block: a borderline round-1 streak of empty-tool-call AssistantMessages (e.g. counter at 2 of the breaker's threshold) carried into the re-prompt round. A single empty AssistantMessage in round 2 would trip the breaker prematurely and bail the turn before the model could produce closing text. Reset `loop_state.consecutive_empty_tool_calls = 0` alongside the other re-prompt resets (text-since-last-tool, has_tool_results) so the re-prompt round starts with a clean breaker counter. No new tests — the existing thinking-only-defer integration test already exercises this code path; the fix is a one-line state reset.
…ompt Sentry MEDIUM: `loop_state.last_real_msg_time` carried over from round 1 into the re-prompt round. A long round 1 (e.g. 29 min) plus a tiny delay before the first re-prompt SDK message would push the cumulative clock past the 30-min idle threshold and trip a phantom idle-timeout abort, even though the re-prompt itself was not idle. Reset the clock to `time.monotonic()` alongside the other re-prompt state resets so each round gets its own independent idle window.
…hint for baseline (#13002) ## Why The autopilot SDK already carries a per-query `max_budget_usd` ceiling that the CLI uses to nudge the model when it's close to the cap (see `claude_agent_max_budget_usd: 10.0` in `config.py` — that's the "$10 session budget" you see in the UI). Two gaps in the current setup: 1. **The cap is static.** A user with $1.50 of daily USD headroom left still gets `max_budget_usd=10.0`, so the in-CLI "wrap up" reminder never fires until *after* they've blown the real cap (the post-turn Redis recorder catches it then, which is too late for the model to pace itself). 2. **Baseline has no equivalent.** The OpenRouter-direct path streams completions and accumulates `cost_usd` post-turn, but the model never sees its own running cost or remaining USD headroom mid-stream. So baseline turns burn through to the limit blindly. Tracked via the autopilot dev testing thread: https://discord.com/channels/1126875755960336515/1499923303609925793/ ## What - **SDK**: per-query `max_budget_usd` now resolves dynamically to `min(static_cap, remaining_daily_or_weekly_usd)`, floored at `$0.50` so a near-cap user still dispatches. - **Baseline**: parity via a small `<budget_context>` block injected through `inject_user_context`'s existing `env_ctx` param, carrying the same remaining-USD figure. - Both fed by a single new helper `get_remaining_usd_budget(user_id, daily, weekly)` in `rate_limit.py` so the source of truth stays one place. Note that "balance" here is the **remaining daily/weekly USD spend cap** (the real money we infra-budget per user) — not the credit wallet. The two budgets are separate by design (see the existing module docstring on `rate_limit.py`); credit balance is a future unification. ## How `backend/copilot/rate_limit.py` - `get_remaining_usd_budget(...)`: returns the smaller of `(daily_limit - daily_used)` and `(weekly_limit - weekly_used)` in USD. `inf` when both caps are 0 (unlimited). Floored on Redis brown-out so observability paths don't pretend the user has unlimited budget. - `build_budget_env_ctx(...)`: thin wrapper that formats the result as a `<budget_context>` block; returns `""` for unlimited / no-user-id (skip injection). `backend/copilot/sdk/service.py` - New module-level `_resolve_dynamic_max_budget_usd(user_id)` reads the user's tier limits via `get_global_rate_limits` and clamps `claude_agent_max_budget_usd` to `[_MAX_BUDGET_USD_FLOOR, remaining_usd]`. - Wired into `ClaudeAgentOptions` construction (replaces the bare `config.claude_agent_max_budget_usd`). `backend/copilot/baseline/service.py` - On the first user message of a turn, fetches `daily/weekly` via `get_global_rate_limits`, builds the env_ctx block, passes it through `inject_user_context(env_ctx=...)`. SDK does NOT do this — its CLI already has a richer running-cost mechanism, so adding a one-shot env_ctx hint there would just be noise. ## Test plan - [x] `poetry run pytest backend/copilot/rate_limit_test.py::TestGetRemainingUsdBudget backend/copilot/rate_limit_test.py::TestBuildBudgetEnvCtx backend/copilot/sdk/service_test.py::TestResolveDynamicMaxBudgetUsd` — 14 pass - [x] `poetry run black` / `poetry run isort` / `poetry run ruff check` on changed files — clean - [ ] Manual: chat session at 90% of daily cap → SDK CLI surfaces "wrap up" reminder ~$0.50 of spend later, not $10 later - [ ] Manual: baseline chat with `<budget_context>` injected — verify model is more conservative on tool depth ## Related - Builds on the per-query `max_budget_usd` mechanism shipped earlier (P0 guardrail). - Independent of #12992 (re-prompt fix); both can ship in parallel.
|
This pull request has conflicts with the base branch, please resolve those so we can evaluate the pull request. |
…nly-closing-and-workspace-storage-limit-prisma # Conflicts: # autogpt_platform/backend/backend/copilot/sdk/service_test.py
|
Conflicts have been resolved! 🎉 A maintainer will review the pull request shortly. |
…NL strip role-alternation Sentry MEDIUM: `_is_empty_assistant_entry` only recognised plain `thinking` blocks as empty. Anthropic also emits `redacted_thinking` (encrypted-thinking variant for safety-redacted content) — an assistant message containing only those should drop in the same way so the post-strip JSONL keeps valid role alternation when a thinking-only re-prompt fires on a redacted reasoning round. Otherwise `--resume` later sees `assistant (redacted) → assistant (real reply)` back-to-back and the API rejects it. Adds `test_drops_preceding_redacted_thinking_only_assistant`.
…e-prompt Sentry MEDIUM: `acc.has_appended_assistant` was carried over from round 1 into the re-prompt round. The dispatch loop uses that flag to decide whether to allocate a new ChatMessage for the next text delta or accumulate into the existing one — so the re-prompt's reply got fused into the previous (empty thinking-only) assistant row, producing a single corrupted ChatMessage instead of two distinct logical turns. Reset alongside the other re-prompt state resets (has_tool_results, text-since-last-tool, breaker counter, idle clock).
…nly re-prompt Sentry HIGH: `acc.assistant_response` carried into the re-prompt round still held round 1's `tool_calls` list. When the re-prompt's first text delta arrived, the dispatch code appended that same ChatMessage object to `session.messages` again — now containing both the stale tool calls and the new text — duplicating the assistant row and corrupting the chat history with a fused turn. Allocate a fresh `ChatMessage(role='assistant', content='')` and clear `accumulated_tool_calls` alongside the other re-prompt resets, so round 2 starts with a clean accumulator the same way every other turn does.
…e-prompt Sentry MEDIUM: round 1's post-tool thinking content survived into the re-prompt round. If round 2 produced no fresh thinking and ended thinking-only again, the adapter's promote-thinking fallback would surface round 1's stale reasoning to the user as if it were the answer to the re-prompt. Reset `state.adapter._last_thinking_content = ''` alongside the other re-prompt state resets so round 2 either promotes its OWN thinking content or falls through to the placeholder.
…ce-storage-limit-prisma
…branches in consume helper Two more integration tests against the patched-_iter_sdk_messages rig to push patch coverage past the 80% threshold: * test_task_progress_message_yields_heartbeat — exercises the SystemMessage non-init branch (subtype='task_progress') so the StreamHeartbeat dispatch path lights up. * test_empty_tool_calls_breaker_increments_counter — drives two consecutive AssistantMessages with empty ToolUseBlock input through the helper to exercise the breaker counter write-through to loop_state.consecutive_empty_tool_calls.
/pr-test results — post-merge dev validationRun against Companion branch with all artefacts: Test 1 — Re-prompt golden path (issue 5) — ✅ PASS
Session: The Langfuse trace metadata for this turn does NOT carry
Test 2 — Prisma fix (issue 2) — ✅ PASSSession:
Test 3 — Multi-tool reasoning regression — ✅ PASS
Same session (follow-up). Multiple web searches + a coherent final summary covering deno, tauri, etc. No regression from the helper extraction (
Test 6 — Plain Q&A regression — ✅ PASS
Welcome message returned in ~10s. No regression.
Test 7 — Refresh /
|
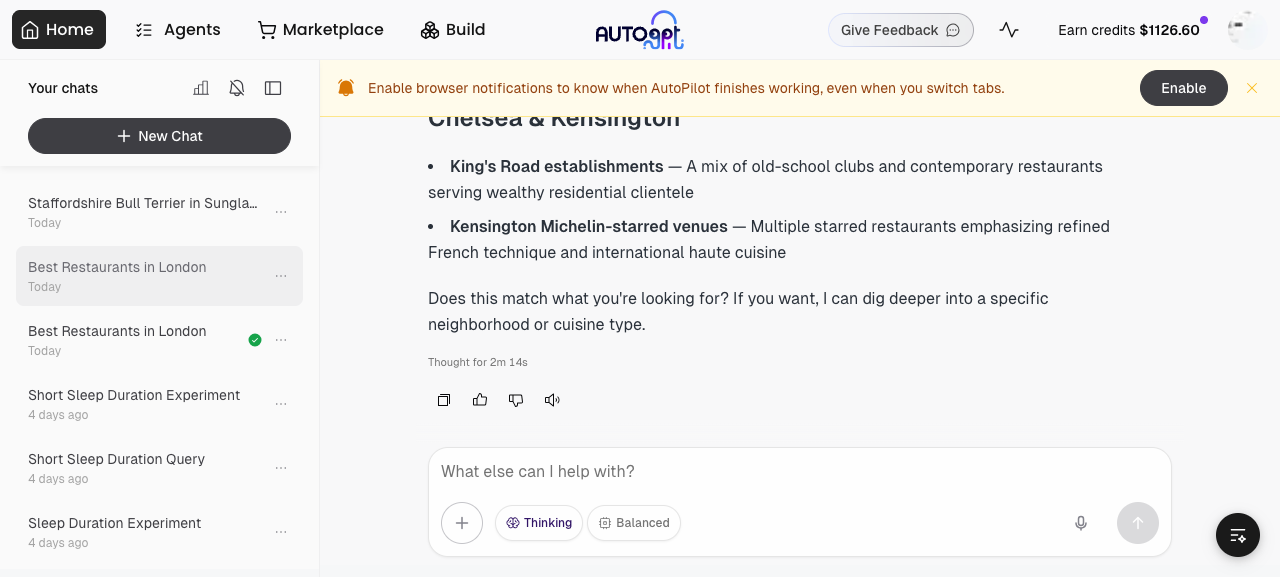
…hint for baseline (#13002) ## Why The autopilot SDK already carries a per-query `max_budget_usd` ceiling that the CLI uses to nudge the model when it's close to the cap (see `claude_agent_max_budget_usd: 10.0` in `config.py` — that's the "$10 session budget" you see in the UI). Two gaps in the current setup: 1. **The cap is static.** A user with $1.50 of daily USD headroom left still gets `max_budget_usd=10.0`, so the in-CLI "wrap up" reminder never fires until *after* they've blown the real cap (the post-turn Redis recorder catches it then, which is too late for the model to pace itself). 2. **Baseline has no equivalent.** The OpenRouter-direct path streams completions and accumulates `cost_usd` post-turn, but the model never sees its own running cost or remaining USD headroom mid-stream. So baseline turns burn through to the limit blindly. Tracked via the autopilot dev testing thread: https://discord.com/channels/1126875755960336515/1499923303609925793/ ## What - **SDK**: per-query `max_budget_usd` now resolves dynamically to `min(static_cap, remaining_daily_or_weekly_usd)`, floored at `$0.50` so a near-cap user still dispatches. - **Baseline**: parity via a small `<budget_context>` block injected through `inject_user_context`'s existing `env_ctx` param, carrying the same remaining-USD figure. - Both fed by a single new helper `get_remaining_usd_budget(user_id, daily, weekly)` in `rate_limit.py` so the source of truth stays one place. Note that "balance" here is the **remaining daily/weekly USD spend cap** (the real money we infra-budget per user) — not the credit wallet. The two budgets are separate by design (see the existing module docstring on `rate_limit.py`); credit balance is a future unification. ## How `backend/copilot/rate_limit.py` - `get_remaining_usd_budget(...)`: returns the smaller of `(daily_limit - daily_used)` and `(weekly_limit - weekly_used)` in USD. `inf` when both caps are 0 (unlimited). Floored on Redis brown-out so observability paths don't pretend the user has unlimited budget. - `build_budget_env_ctx(...)`: thin wrapper that formats the result as a `<budget_context>` block; returns `""` for unlimited / no-user-id (skip injection). `backend/copilot/sdk/service.py` - New module-level `_resolve_dynamic_max_budget_usd(user_id)` reads the user's tier limits via `get_global_rate_limits` and clamps `claude_agent_max_budget_usd` to `[_MAX_BUDGET_USD_FLOOR, remaining_usd]`. - Wired into `ClaudeAgentOptions` construction (replaces the bare `config.claude_agent_max_budget_usd`). `backend/copilot/baseline/service.py` - On the first user message of a turn, fetches `daily/weekly` via `get_global_rate_limits`, builds the env_ctx block, passes it through `inject_user_context(env_ctx=...)`. SDK does NOT do this — its CLI already has a richer running-cost mechanism, so adding a one-shot env_ctx hint there would just be noise. ## Test plan - [x] `poetry run pytest backend/copilot/rate_limit_test.py::TestGetRemainingUsdBudget backend/copilot/rate_limit_test.py::TestBuildBudgetEnvCtx backend/copilot/sdk/service_test.py::TestResolveDynamicMaxBudgetUsd` — 14 pass - [x] `poetry run black` / `poetry run isort` / `poetry run ruff check` on changed files — clean - [ ] Manual: chat session at 90% of daily cap → SDK CLI surfaces "wrap up" reminder ~$0.50 of spend later, not $10 later - [ ] Manual: baseline chat with `<budget_context>` injected — verify model is more conservative on tool depth ## Related - Builds on the per-query `max_budget_usd` mechanism shipped earlier (P0 guardrail). - Independent of #12992 (re-prompt fix); both can ship in parallel.
…e-limit through DB-manager (#12992) ## Why Two production fixes surfaced from John Ababseh's dev testing on 2026-05-01 (Discord thread `1499923303609925793`): - **Issue #5** — chat session `c93dc51f-bb38-4427-975a-6dc033358689` finished after multiple minutes of work and showed only `(Done — no further commentary.)` Langfuse trace `7d1a674eb7c84ffb5a4b34875306eea9` shows the model wrote the entire restaurant-list answer **inside an extended-thinking `ThinkingBlock`** (931 completion tokens, $0.50 spend) and ended the turn with empty `content: []`. Our existing thinking-only guard immediately stamped the placeholder, so the user never saw the actual answer the model already generated. - **Issue #2** — every image-generation request (`AIImageCustomizerBlock` / `AIImageGeneratorBlock`) on dev failed with `prisma.errors.ClientNotConnectedError: Client is not connected to the query engine`. Regression from #12780 (tier-based workspace file storage limits): the new pre-write quota check at `util/workspace.py:225` called `get_workspace_total_size` directly from `backend.data.workspace`, which is a Prisma read. The copilot-executor process doesn't connect Prisma — it RPCs into `database-manager` for everything else — so every `manager.write_file()` from a tool blew up. ## What - **Issue 5** — layered fallback for thinking-only final turns: 1. Adapter sets `pending_thinking_only_reprompt` and defers placeholder/StreamFinish. 2. Driver re-enters the SDK loop and fires one synthetic `client.query("Please write a brief user-facing summary of what you found...")`. 3. If the re-prompt also returns thinking-only, promote the most recent `ThinkingBlock` content to a visible `TextDelta`. 4. Only when thinking is also empty, emit the original `(Done — no further commentary.)` placeholder. Bounded to **one** re-prompt per turn so the worst case is ~one extra LLM call. - **Issue 2** — route the storage-limit pre-check through the existing `workspace_db()` accessor and expose `get_workspace_total_size` on `DatabaseManager` so the copilot-executor RPCs into database-manager (where Prisma is connected), the same path other workspace queries on this codepath use. ## How `backend/copilot/sdk/response_adapter.py` - New `pending_thinking_only_reprompt`, `thinking_only_reprompted`, `_last_thinking_content` fields on `SDKResponseAdapter`. - Capture latest `block.thinking` when streaming reasoning so the second-tier promote-fallback has content. - ResultMessage thinking-only branch — first hit defers; second hit prefers `_last_thinking_content`, falls back to placeholder. `backend/copilot/sdk/service.py` - Wrap the `async for sdk_msg in _iter_sdk_messages(client):` block in a `while True:` retry loop. After the inner loop ends, check `pending_thinking_only_reprompt` — if set and not yet retried, fire `client.query(_THINKING_ONLY_REPROMPT, ...)` and re-enter; else break. Most of the diff is +4-space indentation churn. - Module-level `_THINKING_ONLY_REPROMPT` constant for the re-prompt copy. `backend/data/db_manager.py` - Import `get_workspace_total_size` and expose it via `_(...)` so it becomes an RPC on `DatabaseManager` and the corresponding async client. `backend/util/workspace.py` - Drop the direct `get_workspace_total_size` import; call `workspace_db().get_workspace_total_size(self.workspace_id)` instead. `backend/util/workspace_test.py`, `backend/copilot/sdk/response_adapter_test.py` - Existing thinking-only test split into three: defer-on-first-pass, promote-thinking-on-second-pass, fallback-to-placeholder-when-no-thinking. - Updated `test_flush_unresolved_at_result_message` to expect deferral instead of immediate placeholder. - New `test_write_file_storage_check_routes_through_workspace_db_accessor` proving the storage-limit pre-check goes through the accessor (would have caught Issue 2). ## Test plan - [x] `poetry run pytest backend/copilot/sdk/response_adapter_test.py backend/util/workspace_test.py` — 67 pass - [x] `poetry run ruff check` on changed files — clean - [x] `poetry run black` / `poetry run isort` on changed files — clean - [x] `/pr-test --fix` against dev preview to exercise the re-prompt + image-write paths end-to-end - [x] `/pr-polish` until merge-ready ## Related - Regression introduced by #12780 (tier-based workspace file storage limits)
Why
Two production fixes surfaced from John Ababseh's dev testing on 2026-05-01 (Discord thread
1499923303609925793):c93dc51f-bb38-4427-975a-6dc033358689finished after multiple minutes of work and showed only(Done — no further commentary.)Langfuse trace7d1a674eb7c84ffb5a4b34875306eea9shows the model wrote the entire restaurant-list answer inside an extended-thinkingThinkingBlock(931 completion tokens, $0.50 spend) and ended the turn with emptycontent: []. Our existing thinking-only guard immediately stamped the placeholder, so the user never saw the actual answer the model already generated.AIImageCustomizerBlock/AIImageGeneratorBlock) on dev failed withprisma.errors.ClientNotConnectedError: Client is not connected to the query engine. Regression from feat(backend): tier-based workspace file storage limits #12780 (tier-based workspace file storage limits): the new pre-write quota check atutil/workspace.py:225calledget_workspace_total_sizedirectly frombackend.data.workspace, which is a Prisma read. The copilot-executor process doesn't connect Prisma — it RPCs intodatabase-managerfor everything else — so everymanager.write_file()from a tool blew up.What
Issue 5 — layered fallback for thinking-only final turns:
pending_thinking_only_repromptand defers placeholder/StreamFinish.client.query("Please write a brief user-facing summary of what you found...").ThinkingBlockcontent to a visibleTextDelta.(Done — no further commentary.)placeholder.Bounded to one re-prompt per turn so the worst case is ~one extra LLM call.
Issue 2 — route the storage-limit pre-check through the existing
workspace_db()accessor and exposeget_workspace_total_sizeonDatabaseManagerso the copilot-executor RPCs into database-manager (where Prisma is connected), the same path other workspace queries on this codepath use.How
backend/copilot/sdk/response_adapter.pypending_thinking_only_reprompt,thinking_only_reprompted,_last_thinking_contentfields onSDKResponseAdapter.block.thinkingwhen streaming reasoning so the second-tier promote-fallback has content._last_thinking_content, falls back to placeholder.backend/copilot/sdk/service.pyasync for sdk_msg in _iter_sdk_messages(client):block in awhile True:retry loop. After the inner loop ends, checkpending_thinking_only_reprompt— if set and not yet retried, fireclient.query(_THINKING_ONLY_REPROMPT, ...)and re-enter; else break. Most of the diff is +4-space indentation churn._THINKING_ONLY_REPROMPTconstant for the re-prompt copy.backend/data/db_manager.pyget_workspace_total_sizeand expose it via_(...)so it becomes an RPC onDatabaseManagerand the corresponding async client.backend/util/workspace.pyget_workspace_total_sizeimport; callworkspace_db().get_workspace_total_size(self.workspace_id)instead.backend/util/workspace_test.py,backend/copilot/sdk/response_adapter_test.pytest_flush_unresolved_at_result_messageto expect deferral instead of immediate placeholder.test_write_file_storage_check_routes_through_workspace_db_accessorproving the storage-limit pre-check goes through the accessor (would have caught Issue 2).Test plan
poetry run pytest backend/copilot/sdk/response_adapter_test.py backend/util/workspace_test.py— 67 passpoetry run ruff checkon changed files — cleanpoetry run black/poetry run isorton changed files — clean/pr-test --fixagainst dev preview to exercise the re-prompt + image-write paths end-to-end/pr-polishuntil merge-readyRelated