1.3.0
WARNING
⚠️ : The1.3.0has been yanked from PyPi due to a packaging issue. This should have been now resolved in>= 1.3.1.
What's Changed
Custom Model Environments
More often that not, your custom runtimes will depend on external 3rd party dependencies which are not included within the main MLServer package - or different versions of the same package (e.g. scikit-learn==1.1.0 vs scikit-learn==1.2.0). In these cases, to load your custom runtime, MLServer will need access to these dependencies.
In MLServer 1.3.0, it is now possible to load this custom set of dependencies by providing them, through an environment tarball, whose path can be specified within your model-settings.json file. This custom environment will get provisioned on the fly after loading a model - alongside the default environment and any other custom environments.
Under the hood, each of these environments will run their own separate pool of workers.

Custom Metrics
The MLServer framework now includes a simple interface that allows you to register and keep track of any custom metrics:
[mlserver.register()](https://mlserver.readthedocs.io/en/latest/reference/api/metrics.html#mlserver.register): Register a new metric.[mlserver.log()](https://mlserver.readthedocs.io/en/latest/reference/api/metrics.html#mlserver.log): Log a new set of metric / value pairs.
Custom metrics will generally be registered in the [load()](https://mlserver.readthedocs.io/en/latest/reference/api/model.html#mlserver.MLModel.load) method and then used in the [predict()](https://mlserver.readthedocs.io/en/latest/reference/api/model.html#mlserver.MLModel.predict) method of your custom runtime. These metrics can then be polled and queried via Prometheus.

OpenAPI
MLServer 1.3.0 now includes an autogenerated Swagger UI which can be used to interact dynamically with the Open Inference Protocol.
The autogenerated Swagger UI can be accessed under the /v2/docs endpoint.
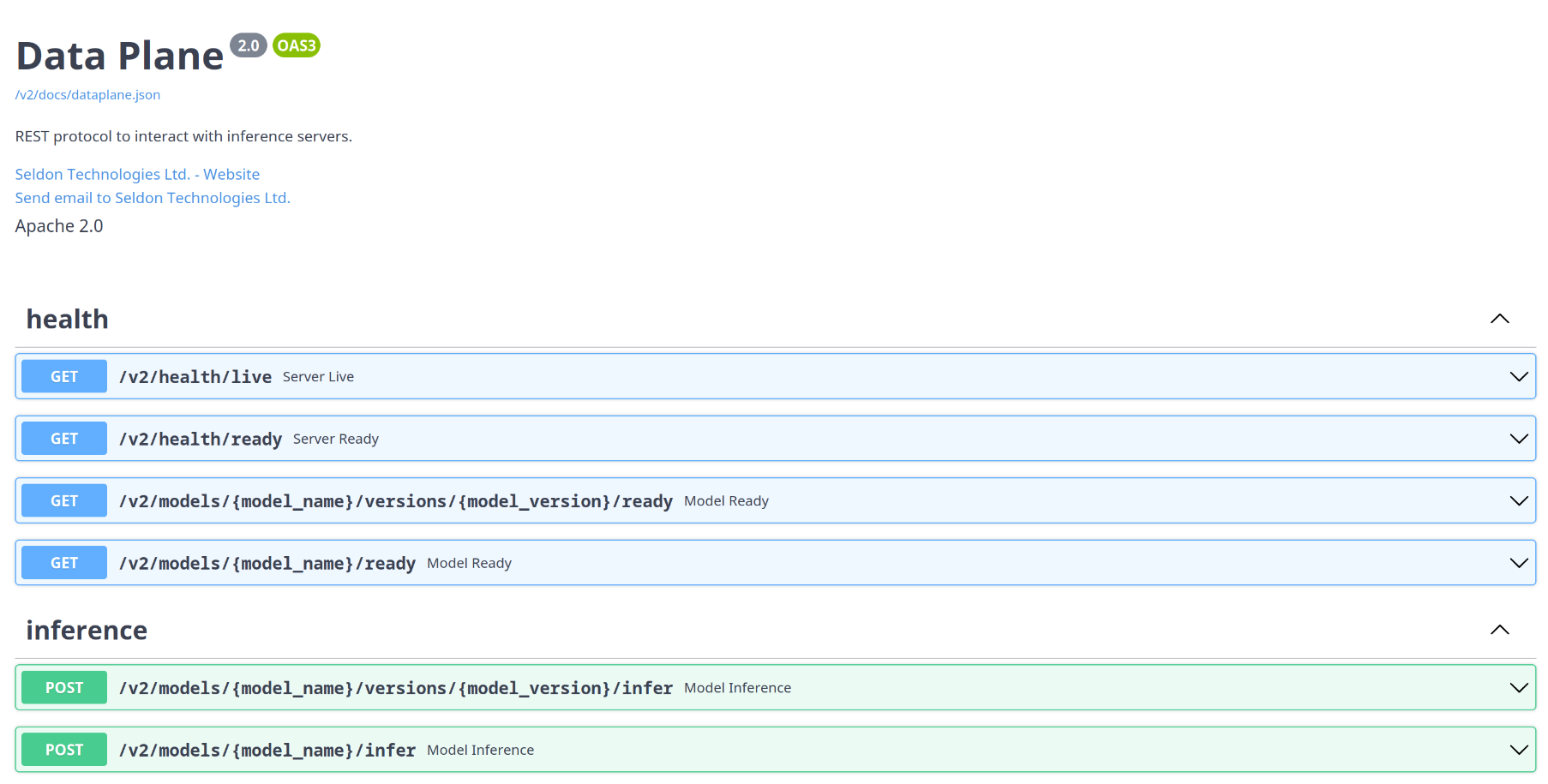
Alongside the general API documentation, MLServer also exposes now a set of API docs tailored to individual models, showing the specific endpoints available for each one.
The model-specific autogenerated Swagger UI can be accessed under the following endpoints:
/v2/models/{model_name}/docs/v2/models/{model_name}/versions/{model_version}/docs
HuggingFace Improvements
MLServer now includes improved Codec support for all the main different types that can be returned by HugginFace models - ensuring that the values returned via the Open Inference Protocol are more semantic and meaningful.
Massive thanks to @pepesi for taking the lead on improving the HuggingFace runtime!
Support for Custom Model Repositories
Internally, MLServer leverages a Model Repository implementation which is used to discover and find different models (and their versions) available to load. The latest version of MLServer will now allow you to swap this for your own model repository implementation - letting you integrate against your own model repository workflows.
This is exposed via the model_repository_implementation flag of your settings.json configuration file.
Thanks to @jgallardorama (aka @jgallardorama-itx ) for his effort contributing this feature!
Batch and Worker Queue Metrics
MLServer 1.3.0 introduces a new set of metrics to increase visibility around two of its internal queues:
- Adaptive batching queue: used to accumulate request batches on the fly.
- Parallel inference queue: used to send over requests to the inference worker pool.
Many thanks to @alvarorsant for taking the time to implement this highly requested feature!
Image Size Optimisations
The latest version of MLServer includes a few optimisations around image size, which help reduce the size of the official set of images by more than ~60% - making them more convenient to use and integrate within your workloads. In the case of the full seldonio/mlserver:1.3.0 image (including all runtimes and dependencies), this means going from 10GB down to ~3GB.
Python API Documentation
Alongside its built-in inference runtimes, MLServer also exposes a Python framework that you can use to extend MLServer and write your own codecs and inference runtimes. The MLServer official docs now include a reference page documenting the main components of this framework in more detail.
New Contributors
- @rio made their first contribution in #864
- @pepesi made their first contribution in #692
- @jgallardorama made their first contribution in #849
- @alvarorsant made their first contribution in #860
- @gawsoftpl made their first contribution in #950
- @stephen37 made their first contribution in #1033
- @sauerburger made their first contribution in #1064