Pixel Polyglots: Pronunciation Enhancement in Online Language Learning
Language learning applications like Duolingo and Babbel have catalyzed a digital revolution, yet a critical gap persists in effectively teaching pronunciation and speech. As linguists emphasize, conversing with native speakers is optimal for attaining fluency. However, the absence of comprehensive speech visualization tools impedes the immersive experience many enthusiasts seek. This predicament inspires an ingenious solution: creating a service that leverages AI-generated deepfake avatars to provide realistic visualizations of users speaking in their target language, processed directly on their mobile devices with minimal GPU usage.
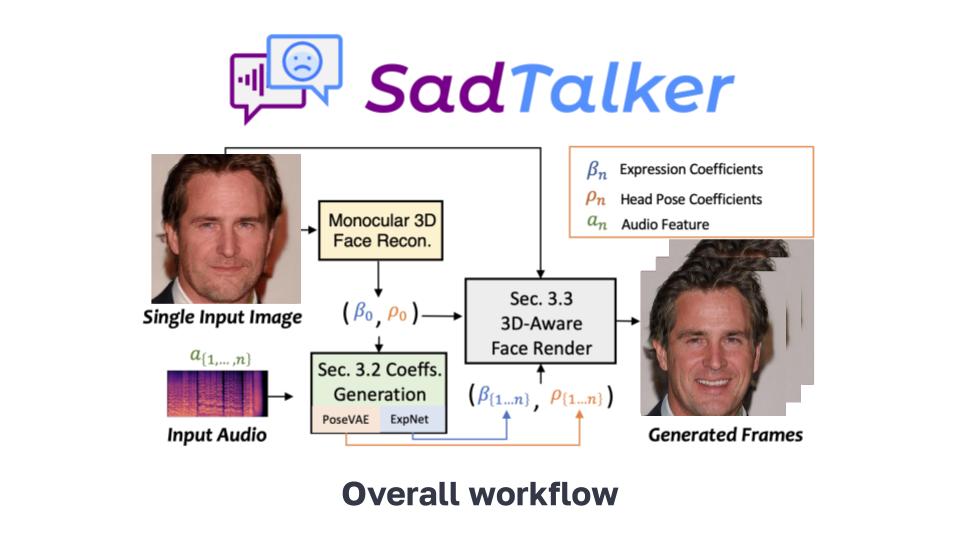
This network takes the audio features and generates realistic facial expression coefficients for the 3D face model over time. It is trained using a distillation loss from a lip sync model, landmark loss on rendered faces, and a lip reading loss.
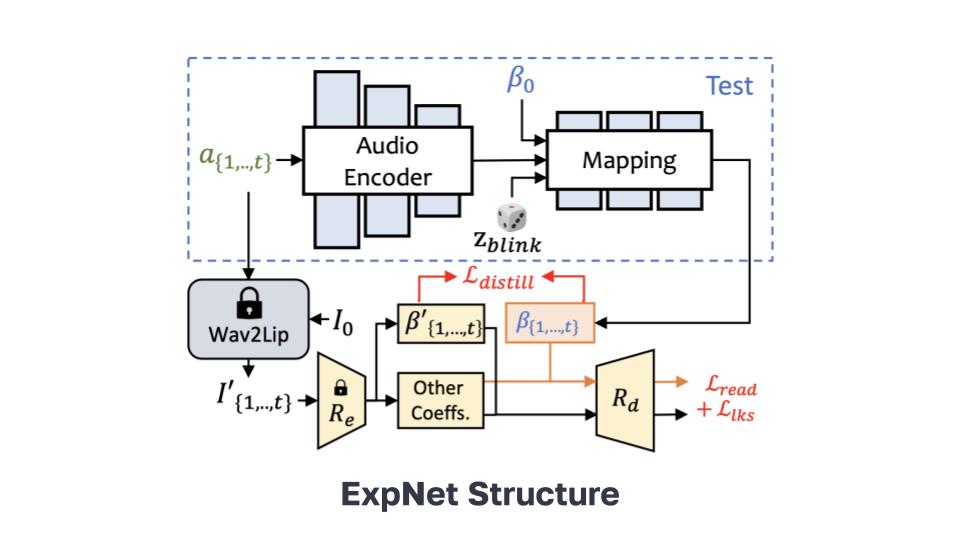
This is a variational autoencoder that takes the audio and an identity code as input and outputs a diverse set of head pose coefficients over time. It is trained using reconstruction, GAN, and other losses.
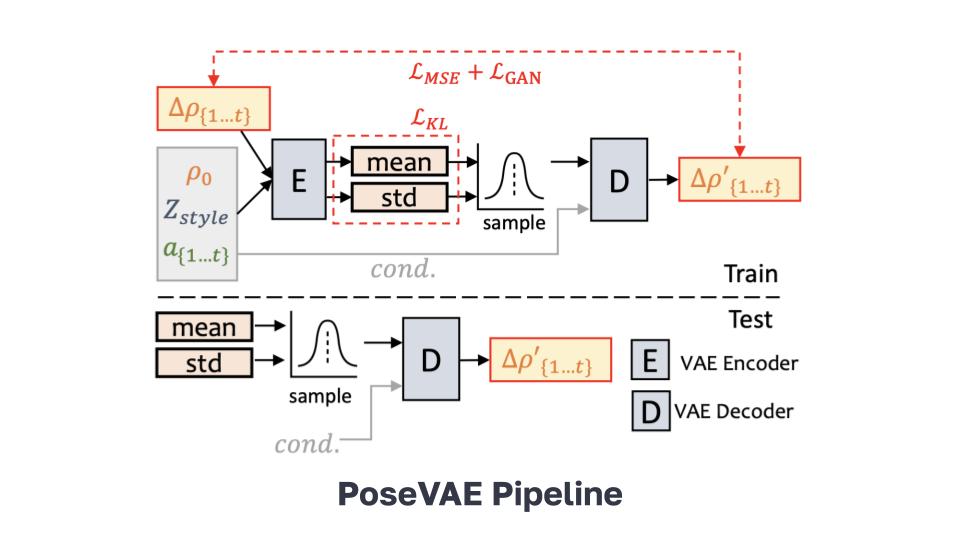
This module maps the generated 3D coefficients to an unsupervised space of facial keypoints. Next, it uses warping and blending to generate the final talking head video that matches the coefficients.
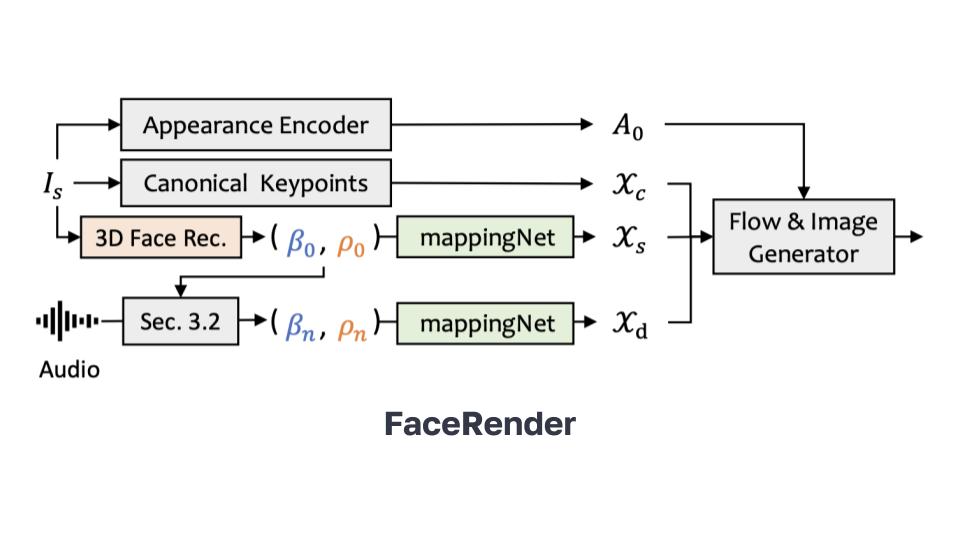
The SadTalker paper faces challenges in representing eye and teeth variations due to limitations in the 3D Morphable Models (3DMM) used, leading to distorted video generation by failing to capture facial landmarks and treating expressive images as neutral. To address this, the method enhances control over image style and features by manipulating latent codes in a redesigned generator architecture. Disentanglement in the intermediate latent space improves control, potentially correcting specific attributes, including facial expressions.


Made with ❤️ by:
- Saket Pradhan
- Kanishka Gabel
- Srushti Hippargi
- Shrey Shah