{kind=link}
{kind=link}
We conducted a study to classify text as either AI-generated or human-authored using a custom dataset of 2075 entries (505 human-written abstracts from Springer journals and 1570 AI-generated texts from three chatbots, in a 1:3 ratio). Multiple machine learning (ML) and deep learning (DL) models were evaluated to determine their effectiveness in this binary classification task, with the aim of advancing academic integrity and text authenticity detection.
- Dataset Preparation: We created a balanced dataset (1:3) and split it into training (80%) and testing (20%) sets.
- Baseline Preprocessing: Text was processed using standard techniques—lowercasing, tokenization (NLTK), stopword removal, special character removal, and TF-IDF vectorization (5000 max features, unigrams, and bigrams).
- Evaluation: We tested nine traditional ML/DL models: RoBERTa, SVM, CNN, Random Forest, Decision Tree, Logistic Regression, ANN, KNN, and Naive Bayes, measuring accuracy, precision, recall, and F1-score.
- RST Implementation: We introduced Rhetorical Structure Theory (RST) preprocessing, incorporating Chi-squared feature selection and an H-score method (based on Hellinger distance) to refine features and capture discourse patterns. Four top-performing models (RoBERTa, SVM, CNN, Random Forest) were re-evaluated with RST.
- Testing: Performance was assessed using classification reports, confusion matrices, and ROC curves with AUC scores.
The RST preprocessing improved feature extraction by analyzing text coherence and rhetorical relationships, reducing noise and enhancing class separability. This led to accuracy gains in most models:
- SVM: From 93% to 96%
- CNN: From 92% to 94%
- Random Forest: From 92% to 95%
- RoBERTa: From 96% to 97%
The H-score method, however, underperformed at 65%, indicating its limitations as a standalone classifier.
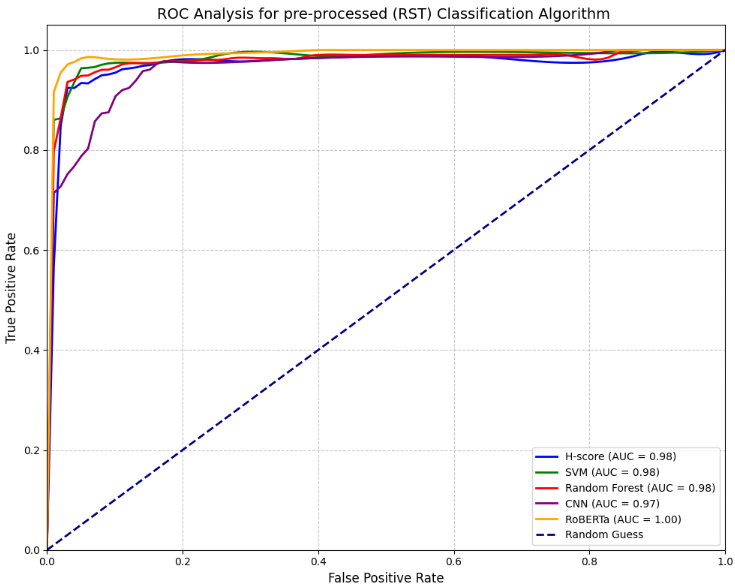
Our best result was a 97% accuracy achieved by RoBERTa with RST preprocessing. This was accomplished by:
- Leveraging RoBERTa’s pre-trained transformer architecture (roberta-base, 12 layers, 768 hidden units) for contextual understanding.
- Fine-tuning it on our dataset with tokenized inputs via RobertaTokenizer.
- Enhancing input quality with RST, which used TF-IDF with Chi-squared selection to focus on discriminative terms, boosting RoBERTa’s ability to distinguish AI-generated text (Label 1) from human text (Label 0). Metrics included precision (0.94), recall (0.95), and F1-score (0.95) for Label 0, and 0.98, 0.98, 0.98 for Label 1.
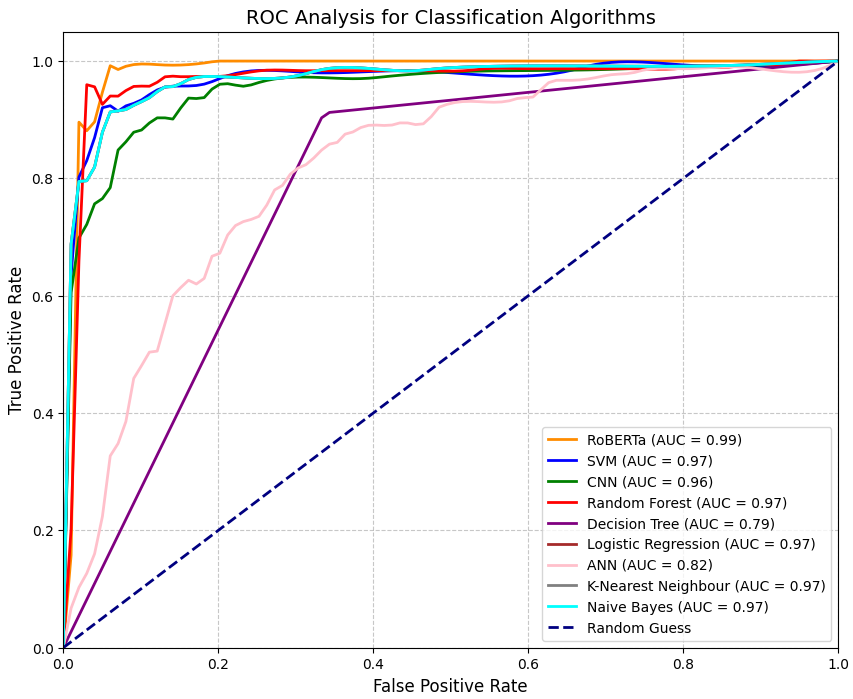
- Traditional Baseline: RoBERTa (96%), SVM (93%), CNN/Random Forest (92%), Decision Tree (85%), Logistic Regression/ANN (83%), KNN (79%), Naive Bayes (73%).
- RST-Enhanced: RoBERTa (97%), SVM (96%), Random Forest (95%), CNN (94%), H-Score (65%).
- Previous Works: Sankalp Bahad et al. (86.5%), Ayat A. Najjar et al. (85%), Mudasir Ahmad Wani et al. (98.8%).
- Our Model: 97% accuracy, with 0.98 precision, recall, and F1-score, rivals Wani et al.’s 98.8% and surpasses others, showing competitive performance with a custom approach.