-
Notifications
You must be signed in to change notification settings - Fork 2.9k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Showing
1 changed file
with
248 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,248 @@ | ||
|
|
||
| # 模型参数初始化对齐方法 | ||
|
|
||
| # 1. 背景 | ||
|
|
||
| Paddle提供了大量的初始化方法,包括`Constant`, `KaimingUniform`, `KaimingNormal`, `TruncatedNormal`, `Uniform`, `XavierNormal`, `XavierUniform`等,合适的初始化方法能够帮助模型快速地收敛或者达到更高的精度。 | ||
|
|
||
| 论文复现的过程中,在训练对齐环节,需要保证Paddle的复现代码和参考代码保持一致,从而实现完全对齐。然而由于不同框架的差异性,部分API中参数提供的默认初始化方法有区别,该文档以`nn.Conv2D`以及`nn.Linear`这两个最常用的API为例,介绍怎样实现对齐。 | ||
|
|
||
| **更多参考链接:** | ||
|
|
||
| * Paddle初始化相关API链接:[初始化API官网文档](https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/Overview_cn.html#chushihuaxiangguan) | ||
| * Paddle提供的初始化方式为直接修改API的`ParamAttr`,与`torch.nn.init`等系列API的使用方式不同,PaddleDetection中实现了与`torch.nn.init`系列API完全对齐的初始化API,包括`uniform_`, `normal_`, `constant_`, `ones_`, `zeros_`, `xavier_uniform_`, `xavier_normal_`, `kaiming_uniform_`, `kaiming_normal_`, `linear_init_`, `conv_init_`,可以参考[initializer.py](https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/initializer.py),查看更多的实现细节。 | ||
|
|
||
|
|
||
| # 2. 不同框架的初始化差异 | ||
|
|
||
| ## 2.1 默认初始化的对齐方法 | ||
|
|
||
| 在此情况下,一般需要查看文档,了解参考代码的初始化方法,从而通过修改初始化方法,实现初始化的对齐。 | ||
|
|
||
| 下面以`nn.Conv2D` API为例进行说明。 | ||
|
|
||
| * **Step1:** 基于Paddle与torch,定义2个卷积操作,绘制其weight参数的直方图,如下所示。 | ||
|
|
||
| ```python | ||
| import paddle | ||
| import torch | ||
| import numpy as np | ||
| import matplotlib.pyplot as plt | ||
| %matplotlib inline | ||
|
|
||
| conv2d_pd = paddle.nn.Conv2D(4096, 512, 3) | ||
| conv2d_pt = torch.nn.Conv2d(4096, 512, 3) | ||
|
|
||
| conv2d_pd_weight = conv2d_pd.weight.numpy().reshape((-1, )) | ||
| conv2d_pt_weight = conv2d_pt.weight.detach().numpy().reshape((-1, )) | ||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([conv2d_pd_weight, conv2d_pt_weight], bins=100, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Conv2D weight", "torch.nn.Conv2d weight"}) | ||
| ``` | ||
|
|
||
| <div align="center"> | ||
| <img src="https://paddle-model-ecology.bj.bcebos.com/images/initializer/conv2d_weight_default_diff.jpeg" width = "600" /> | ||
| </div> | ||
|
|
||
| 结合[paddle文档](https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/ParamAttr_cn.html#paramattr)和[torch文档](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html?highlight=conv2d#torch.nn.Conv2d)可知,paddle的初始化是`XavierNormal`,torch的初始化是`uniform`,初始化方法边界值是`(-sqrt(groups/(in_channels*prod(*kernal_size))), sqrt(groups/(in_channels*prod(*kernal_size))))`。 | ||
|
|
||
|
|
||
| * **Step2:** 由上述分析,基于`paddle.nn.initializer.Uniform` API,自定义Paddle中Conv2D的初始化,代码如下所示: | ||
|
|
||
| ```python | ||
| import paddle | ||
| import torch | ||
| import numpy as np | ||
| import matplotlib.pyplot as plt | ||
| import paddle.nn.initializer as init | ||
| %matplotlib inline | ||
| # 该例子中,对应上述公式的group=1,in_channels=4096,kernal_size=3,由于二维卷积的卷积核是二维的,所以此处的结果为4096*3*3 | ||
| conv2d_pd = paddle.nn.Conv2D(4096, 512, 3, | ||
| init.Uniform(-1/math.sqrt(4096*3*3), 1/math.sqrt(4096*3*3))) | ||
| conv2d_pt = torch.nn.Conv2d(4096, 512, 3) | ||
|
|
||
| conv2d_pd_weight = conv2d_pd.weight.numpy().reshape((-1, )) | ||
| conv2d_pt_weight = conv2d_pt.weight.detach().numpy().reshape((-1, )) | ||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([conv2d_pd_weight, conv2d_pt_weight], bins=100, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Conv2D weight", "torch.nn.Conv2d weight"}) | ||
| ``` | ||
|
|
||
| <div align="center"> | ||
| <img src="https://paddle-model-ecology.bj.bcebos.com/images/initializer/conv2d_weight_fixed_diff.jpeg" width = "600" /> | ||
| </div> | ||
|
|
||
| 从图中可知,二者的初始化参数分布实现一致。 | ||
|
|
||
|
|
||
| ## 2.2 自定义初始化的对齐方法 | ||
|
|
||
|
|
||
| 部分参考代码中,初始化的方法是通过使用`torch.nn.init`系列API实现,可以认为是自定义初始化。例如:[resnet](https://github.com/pytorch/vision/blob/ec1c2a12cf00c6df83c7fb88f75b8117cda2f970/torchvision/models/resnet.py#L208)中使用的`kaiming_normal_`传入了`mode`和`nonlinearity`两个参数: | ||
|
|
||
| ```python | ||
| if isinstance(m, nn.Conv2d): | ||
| nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu") | ||
| ``` | ||
|
|
||
| 在这类问题中,可以先尝试使用`2.1`章节中的`Step1`,查看使用Paddle同名初始化方式的默认参数是否能够对齐。如果无法对齐,可以查阅[initializer.py](https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/initializer.py),使用该文件中的初始化函数,实现对齐。 | ||
|
|
||
| 不同框架的初始化方法有所不同,开发者论文复现过程中难以排查,因此下面第3章介绍通过自定义初始化的方式,实现不同框架的参数初始化分布一致,最终帮助大家更加顺利地完成论文复现。 | ||
|
|
||
| **注意:** BatchNorm2D等大多数的API中,可学习参数的初始化分布相同,在此为进一步对比,也给出其权重的可视化对比图像。 | ||
|
|
||
| # 3. 初始化参数分布对比 | ||
|
|
||
| ## 3.1 默认初始化不同的API权重直方图对比 | ||
|
|
||
| | Paddle API | torch API | 默认初始化方法的参数分布对比图 | 修改初始化参数方法 | 修改之后的参数分布对比 | | ||
| |:---------:|:------------------:|:------------:|:------------:|:------------:| | ||
| | `paddle.nn.Conv2D` weight参数 | `torch.nn.Conv2d` weight参数 | 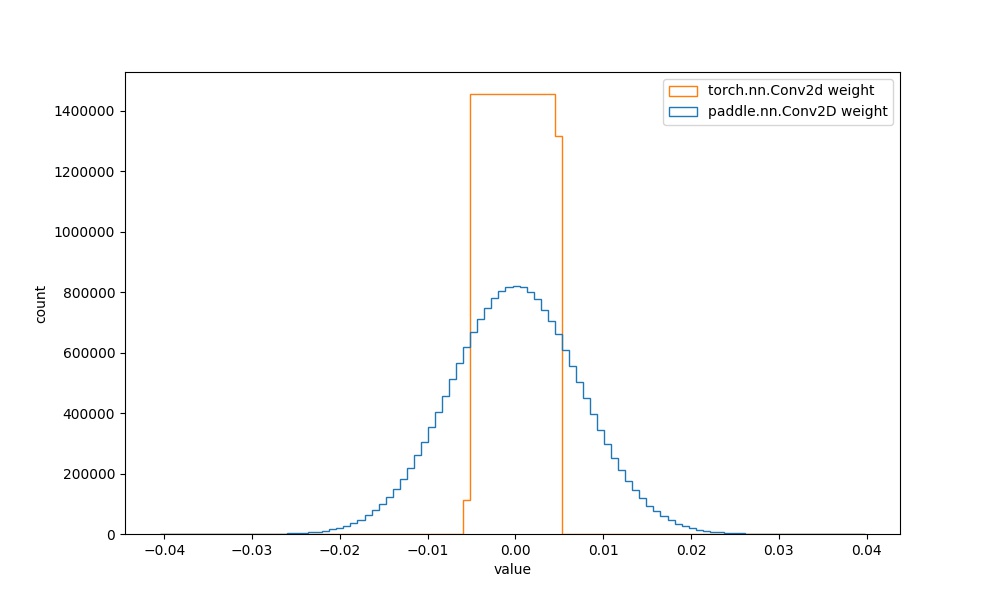 | 见附录`4.1` | 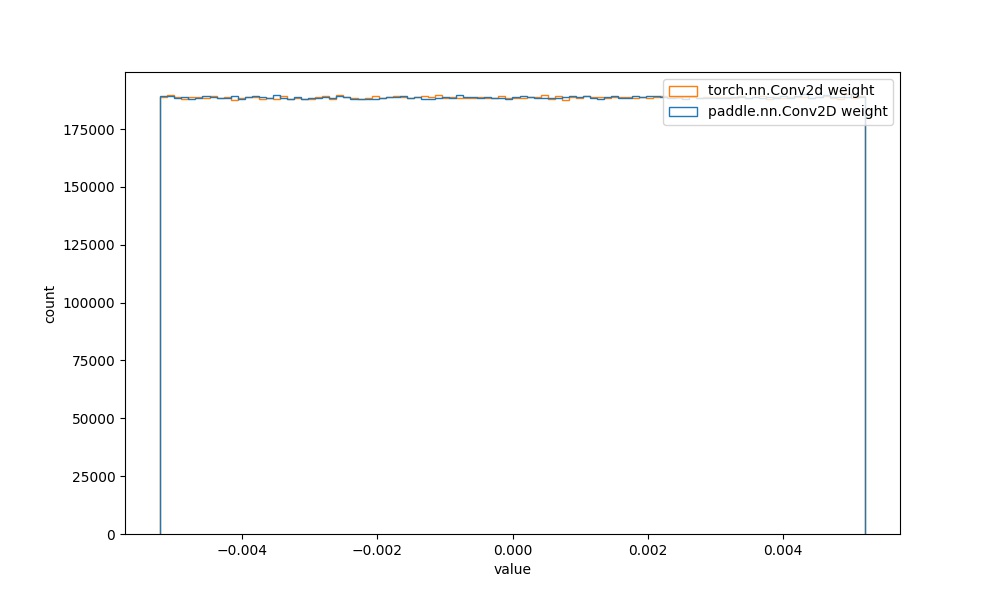 | | ||
| | `paddle.nn.Conv2D` bias参数 | `torch.nn.Conv2d` bias参数 | 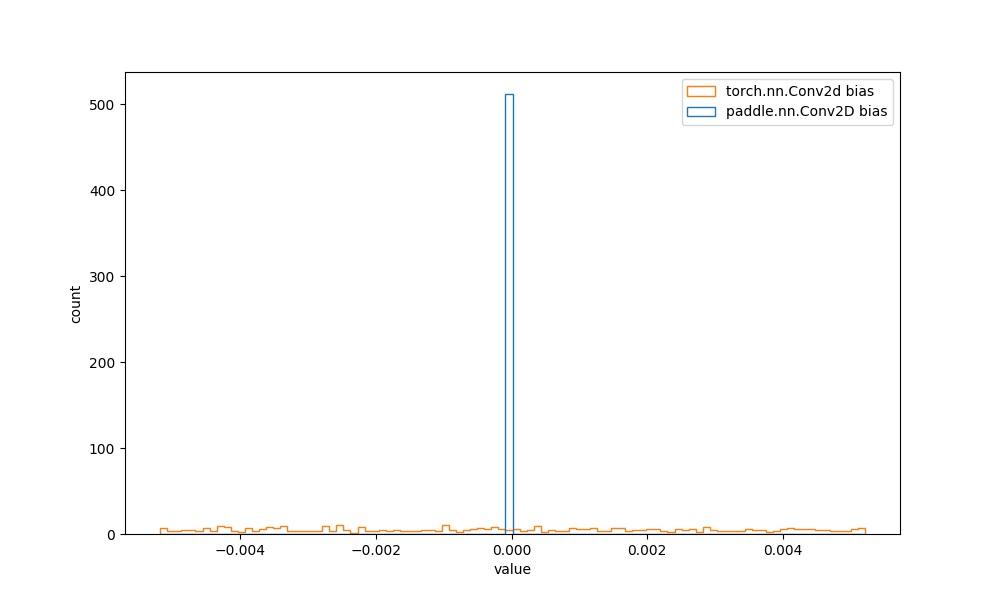 | 见附录`4.1` | 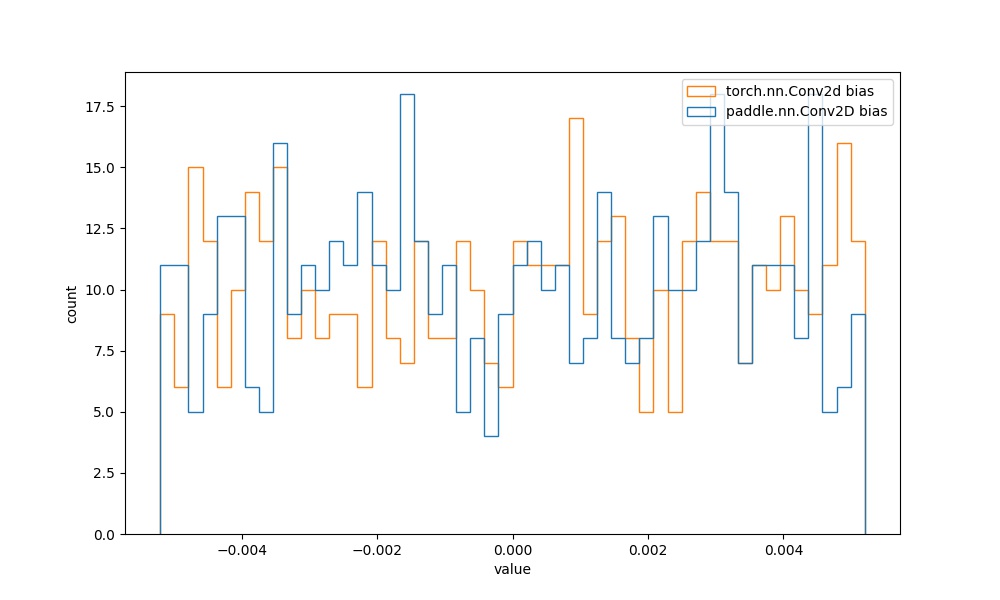 | | ||
| | `paddle.nn.Linear` weight参数 | `torch.nn.Linear` weight参数 | 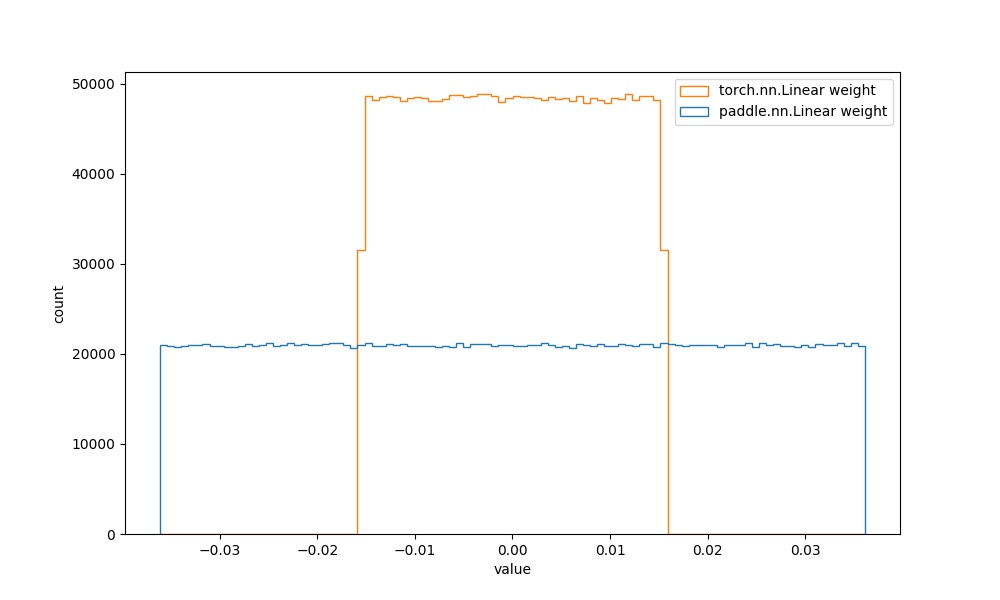 | 见附录`4.2` | 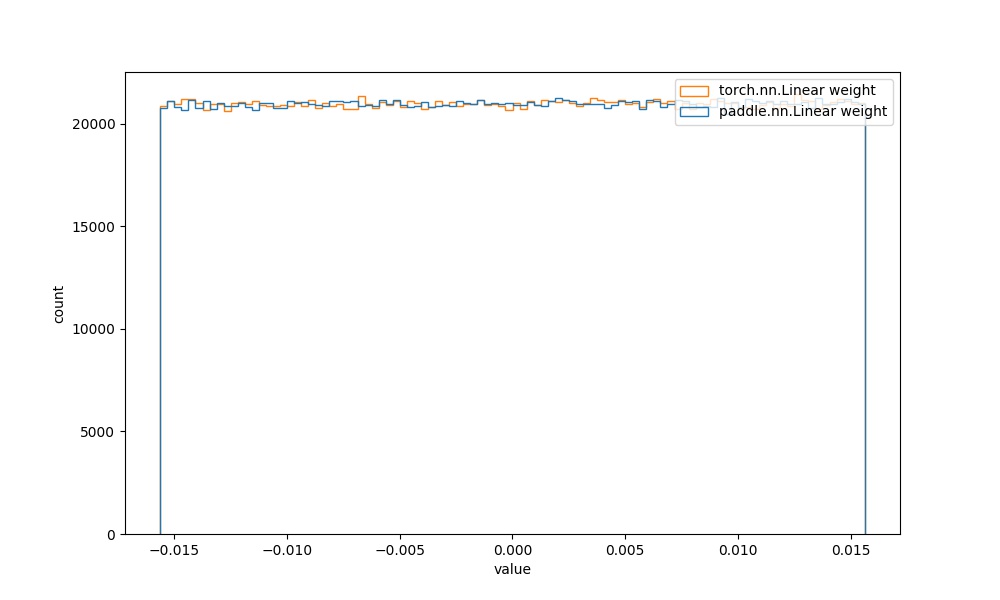 | | ||
| | `paddle.nn.Linear` bias参数 | `torch.nn.Linear` bias参数 | 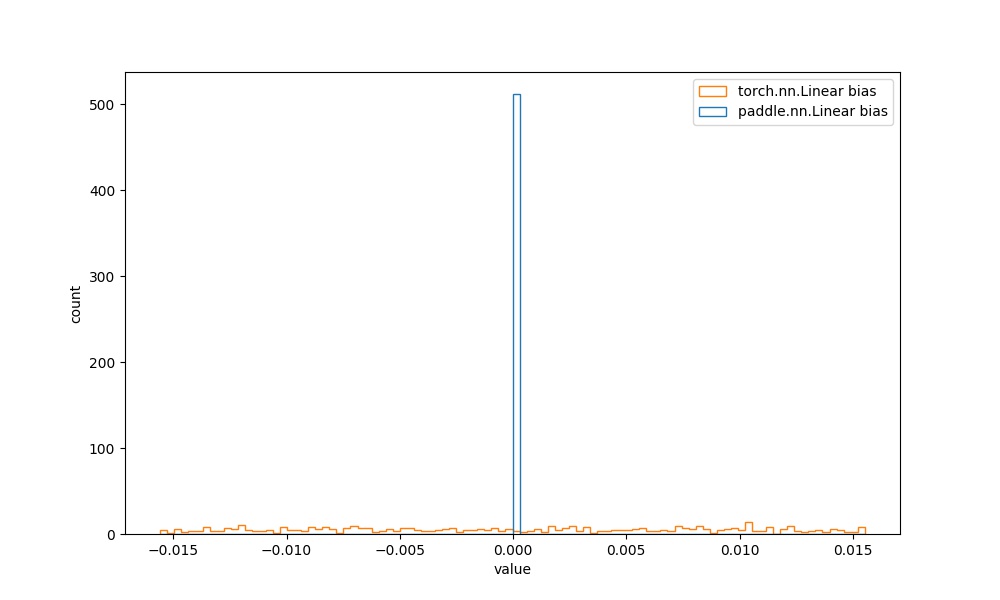 | 见附录`4.2` | 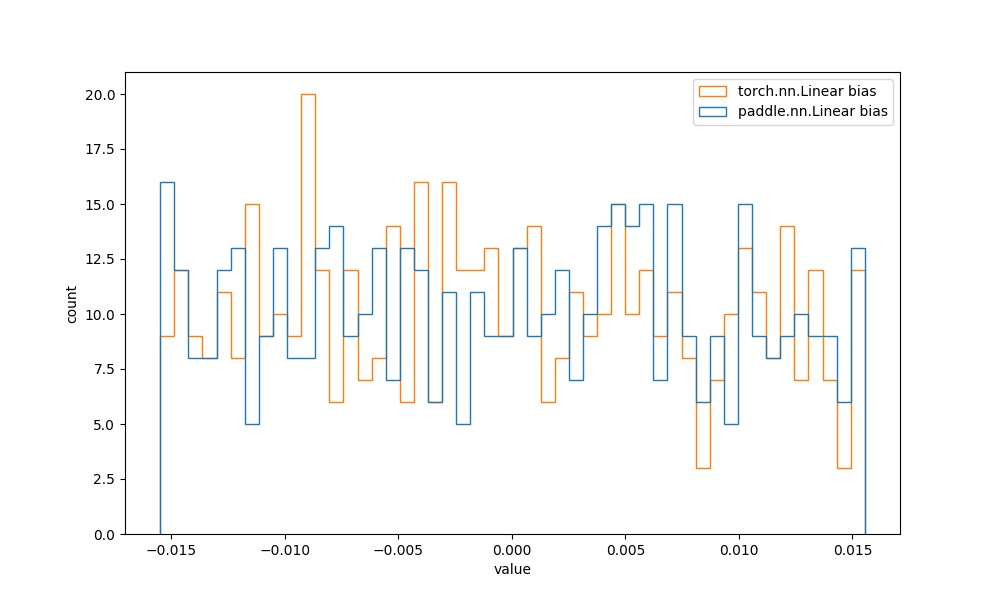 | | ||
|
|
||
|
|
||
|
|
||
| ## 3.2 默认初始化相同的API权重直方图对比 | ||
|
|
||
| | Paddle API | torch API | 默认初始化方法的参数分布对比图 | | ||
| |:---------:|:------------------:|:------------:| | ||
| | `paddle.nn.BatchNorm2D` weight参数 | `torch.nn.BatchNorm2d` weight参数 | 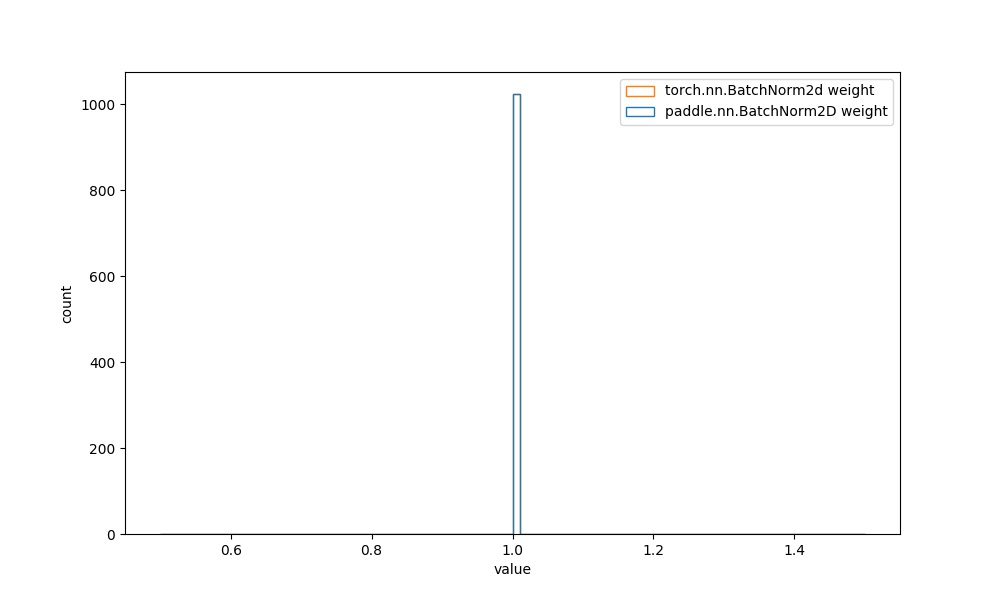 | | ||
| | `paddle.nn.BatchNorm2D` bias参数 | `torch.nn.BatchNorm2d` bias参数 | 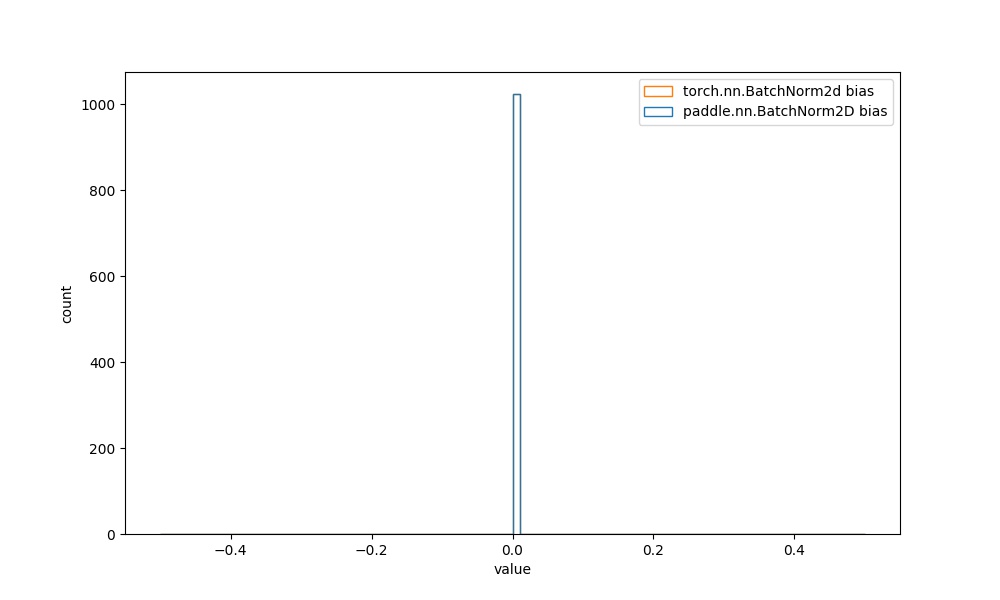 | | ||
|
|
||
| # 4. 附录 | ||
|
|
||
| ## 4.1 初始化对齐代码 | ||
|
|
||
| ### 4.1.1 paddle.nn.Conv2D | ||
|
|
||
| * 默认初始化以及可视化代码 | ||
|
|
||
| ```python | ||
| import paddle | ||
| import torch | ||
| import numpy as np | ||
| import matplotlib.pyplot as plt | ||
| %matplotlib inline | ||
|
|
||
| conv2d_pd = paddle.nn.Conv2D(4096, 512, 3) | ||
| conv2d_pt = torch.nn.Conv2d(4096, 512, 3) | ||
|
|
||
| conv2d_pd_weight = conv2d_pd.weight.numpy().reshape((-1, )) | ||
| conv2d_pd_bias = conv2d_pd.bias.numpy().reshape((-1, )) | ||
| conv2d_pt_weight = conv2d_pt.weight.detach().numpy().reshape((-1, )) | ||
| conv2d_pt_bias = conv2d_pd.bias.numpy().reshape((-1, )) | ||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([conv2d_pd_weight, conv2d_pt_weight], bins=100, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Conv2D weight", "torch.nn.Conv2d weight"}) | ||
|
|
||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([conv2d_pd_bias, conv2d_pt_bias], bins=50, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Conv2D bias", "torch.nn.Conv2d bias"}) | ||
| ``` | ||
|
|
||
|
|
||
|
|
||
| * 修正后初始化以及可视化代码 | ||
|
|
||
| ```python | ||
| import paddle | ||
| import torch | ||
| import numpy as np | ||
| import matplotlib.pyplot as plt | ||
| import paddle.nn.initializer as init | ||
| %matplotlib inline | ||
|
|
||
| conv2d_pd = paddle.nn.Conv2D(4096, 512, 3, | ||
| weight_attr=init.Uniform(-1/math.sqrt(4096*3*3), 1/math.sqrt(4096*3*3)), | ||
| bias_attr=init.Uniform(-1/math.sqrt(4096*3*3), 1/math.sqrt(4096*3*3))) | ||
| conv2d_pt = torch.nn.Conv2d(4096, 512, 3) | ||
|
|
||
| conv2d_pd_weight = conv2d_pd.weight.numpy().reshape((-1, )) | ||
| conv2d_pd_bias = conv2d_pd.bias.numpy().reshape((-1, )) | ||
| conv2d_pt_weight = conv2d_pt.weight.detach().numpy().reshape((-1, )) | ||
| conv2d_pt_bias = conv2d_pd.bias.numpy().reshape((-1, )) | ||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([conv2d_pd_weight, conv2d_pt_weight], bins=100, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Conv2D weight", "torch.nn.Conv2d weight"}) | ||
|
|
||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([conv2d_pd_bias, conv2d_pt_bias], bins=50, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Conv2D bias", "torch.nn.Conv2d bias"}) | ||
| ``` | ||
|
|
||
|
|
||
| ### 4.1.2 paddle.nn.Linear | ||
|
|
||
| * 默认初始化以及可视化代码 | ||
|
|
||
| ```python | ||
| import paddle | ||
| import torch | ||
| import numpy as np | ||
| import matplotlib.pyplot as plt | ||
| %matplotlib inline | ||
|
|
||
| linear_pd = paddle.nn.Linear(4096, 512) | ||
| linear_pt = torch.nn.Linear(4096, 512) | ||
|
|
||
| linear_pd_weight = linear_pd.weight.numpy().reshape((-1, )) | ||
| linear_pd_bias = linear_pd.bias.numpy().reshape((-1, )) | ||
| linear_pt_weight = linear_pt.weight.detach().numpy().reshape((-1, )) | ||
| linear_pt_bias = linear_pt.bias.numpy().reshape((-1, )) | ||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([linear_pd_weight, linear_pt_weight], bins=100, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Linear weight", "torch.nn.Linear weight"}) | ||
|
|
||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([linear_pd_bias, linear_pt_bias], bins=50, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Linear bias", "torch.nn.Linear bias"}) | ||
| ``` | ||
|
|
||
| * 修正后初始化以及可视化代码 | ||
|
|
||
| ```python | ||
| import paddle | ||
| import torch | ||
| import numpy as np | ||
| import matplotlib.pyplot as plt | ||
| %matplotlib inline | ||
| # linear的初始化方法同样适用于2.1节中的公式,此处的kernal_size等价于1。 | ||
| linear_pd = paddle.nn.Linear(4096, 512, | ||
| weight_attr=init.Uniform(-1/math.sqrt(4096), 1/math.sqrt(4096)), | ||
| bias_attr=init.Uniform(-1/math.sqrt(4096), 1/math.sqrt(4096))) | ||
| linear_pt = torch.nn.Linear(4096, 512) | ||
|
|
||
| linear_pd_weight = linear_pd.weight.numpy().reshape((-1, )) | ||
| linear_pd_bias = linear_pd.bias.numpy().reshape((-1, )) | ||
| linear_pt_weight = linear_pt.weight.detach().numpy().reshape((-1, )) | ||
| linear_pt_bias = linear_pt.bias.numpy().reshape((-1, )) | ||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([linear_pd_weight, linear_pt_weight], bins=100, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Linear weight", "torch.nn.Linear weight"}) | ||
|
|
||
| plt.figure(figsize=(10, 6)) | ||
| temp = plt.hist([linear_pd_bias, linear_pt_bias], bins=50, rwidth=0.8, histtype="step") | ||
| plt.xlabel("value") | ||
| plt.ylabel("count") | ||
| plt.legend({"paddle.nn.Linear bias", "torch.nn.Linear bias"}) | ||
| ``` |