This project is for my 3rd year module graph theory which I am using neo4j to represent a prototype timetabling system for a college in graph database form. The project is a small prototype of my current semester with some mildly tidied data that I scraped from the college timetableing website and the gmit website. My agument for the reason that iv chosen to only represent a semester is if it works for one semester it should work for a whole college timetable.
The aims of the project are to show I can reperesent a prototype timetabling system using the neo4j software and that I am able to learn how to us it capable to use the software.
A timetable is a visual representation of a period of time and the events that happen over that period of time, so a college a timetable is a representation that shows the times in the week when subjects are taught at, what lecturer is teaching the subject and what room it is happening at as well as what student group(s) are attending the class.
Neo4j is an open-source NoSQL graph database implemented in Java and Scala. With development starting in 2003, it has been publicly available since 2007. The source code and issue tracking are available on GitHub, with support readily available on Stack Overflow and the Neo4j Google group. Neo4j is used today by hundreds of thousands of companies and organizations in almost all industries. Use cases include matchmaking, network management, software analytics, scientific research, routing, organizational and project management, recommendations, social networks, and more.
Cypher is a declarative, SQL-inspired language for describing patterns in graphs visually using an ascii-art syntax. It allows us to state what we want to select, insert, update or delete from our graph data without requiring us to describe exactly how to do it.

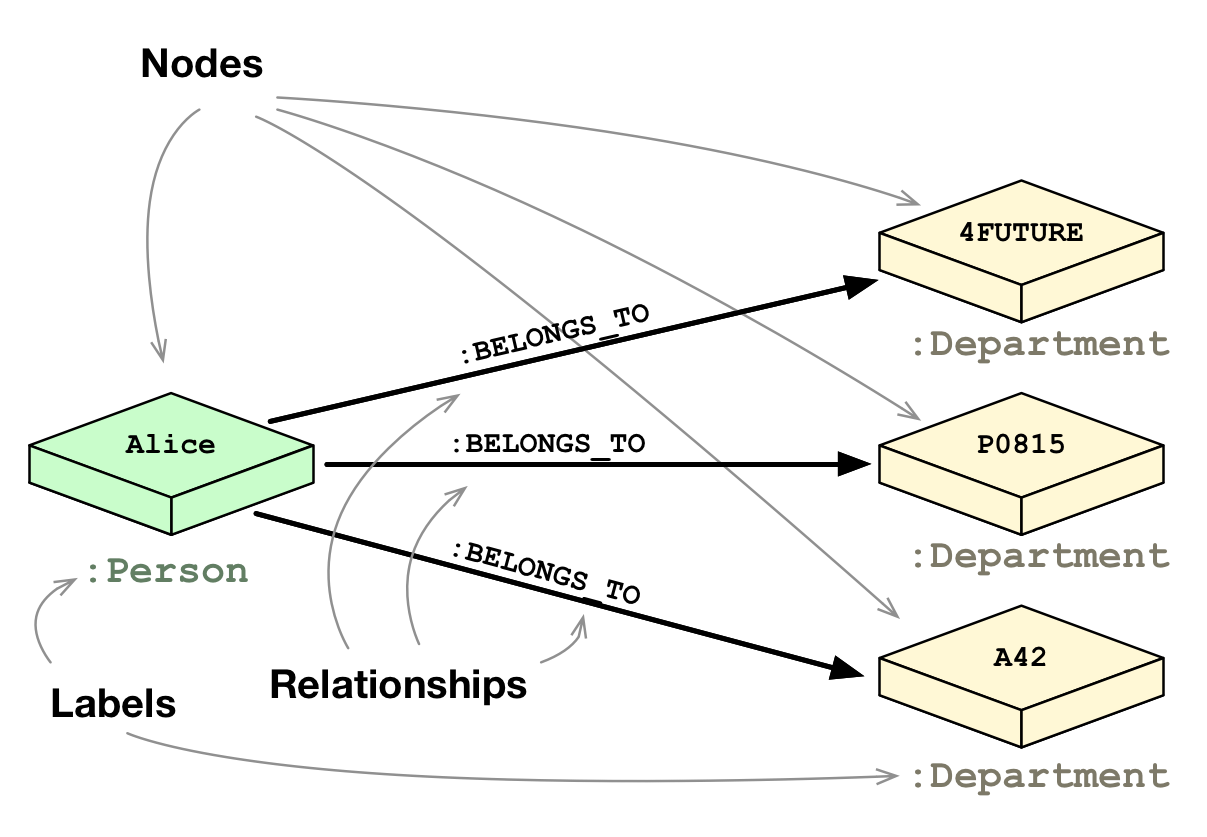
Node are essentially entities which can hold any number of attributes (key-value-pairs). Nodes can be tagged with labels representing their different roles in your domain. In addition to contextualizing node and relationship properties, labels may also serve to attach metadata—index or constraint information—to certain nodes. The nodes of the database are as below the picture.
| Node(Node label) | Description |
|---|---|
| Campus | node(s) to represent the campuses of the college |
| Course | node(s) to represent the course(s) of the college |
| Department | node(s) to represent the department(s) of the college |
| Lecturer | node(s) to represent the lecturer(s) of the college |
| Rooms | node(s) to represent the room(s) in a campus |
| Time slots | node(s) to represent the times(s) that classes were in session |
| Group | node(s) to represent the group(s) in a course |
| Module | node(s) to represent the modules(s) of a course |
| Student | node(s) to represent the students(s) of the college |
To create the nodes I used a cypher command called Load CSV which allowed me to store the data I scraped in csv files then load the data in and create a group of nodes. An example command I used to create nodes is as follows,
LOAD CSV WITH HEADERS FROM "file:///C:/LecturersTidy.csv" AS csvLine
CREATE (n:Lecturer {title: csvLine.Title, surname: csvLine.Surname, firstname: csvLine.FName, campus: csvLine.Campus, extension: csvLine.Extension, contact: csvLine.Contact, email: csvLine.Email})
Labels are a way to group nodes into catagories so it is easier query and find groups of nodes. Lecturer is a label for a group of nodes in my db.
Properties are named values that are stored inside nodes and are used to contain data such as title and firstname which are properties of a lecturer node. Properties are capable of storing Numeric values, String values, Boolean values and Lists of any of the above values. An example of a proerty in the db is seen below,
| Property | Description |
|---|---|
| firstname | property that contains data such as a lecturers first name |
The properties of the lecture nodes were created along with the nodes using the th load CSV command as follows,
LOAD CSV WITH HEADERS FROM "file:///C:/LecturersTidy.csv" AS csvLine
CREATE (n:Lecturer {title: csvLine.Title, surname: csvLine.Surname, firstname: csvLine.FName, campus: csvLine.Campus, extension: csvLine.Extension, contact: csvLine.Contact, email: csvLine.Email})
Relationships provide directed, named semantically relevant connections between two node-entities. A relationship always has a direction, a type, a start node, and an end node. Like nodes, relationships can have any properties. As relationships are stored efficiently, two nodes can share any number or type of relationships without sacrificing performance.

{kind=link}
{kind=link}
Below are the tools you need to setup and use this project
-
Neo4j - Website where to download neo4j graph database
-
Regex editor - Online Regex editor (This is optional as info is supplied)
-
Notepad++ - Text editor that can use regex and create/use csv files
I used the gmit timetabling and home website to extract data about the campus, departments, rooms, course, modules and lecturers. I then modeled the data into nodes and properties (key-value-pairs) and the relationships between them. I was able to extract the data by viewing the webpages source code and coping the raw data scraped into a text editor and using reglur expessions to edit an manipulate the data and tidy it up.
I implimented the data by tiding up the data that I extracted from the gmit websites and putting it into csv files and then using a cypher feature called Load CSV which allowed me to create nodes, labels, properties and relationships quickly. The raw and tidy data are on in folders in the git repo if you wish to look at the files.

The database design is the part of this project I spent most time on because I made a few different designs on paper but each one when implementated had issues with being queried or it did'nt seem to suit graphically in my opinion. Time was the biggest issue for me as it is hard to represent time in a simple way while neo4j uses milliseconds from the Epoch to measure time I was trying to represent the working week for a semester in a simple form so In my finaly design I chose to represent time as very specific timeslot nodes so for example one timeslot has a node with a Unique string property "fri at 11 to 12".
These are some queries that I ran on the database some are specific to retrive data I have in the db and some are just logical kind of queries,
- Find how many nodes are in the db and count how many relationships each node has
start n=node(*)
match (n)-[r]-()
return n, count(r) as rel_count
order by rel_count desc
- Count how many leaf nodes are in the db
START n=node(*)
MATCH (n)-[r*]->(l)
WHERE NOT((l)-->())
RETURN DISTINCT LABELS(l) as Nodes, COUNT(l) as Number_Of_Leaf_Nodes;
- How many times does Ian teach in a week
MATCH (a:Lecturer)-[:Lecturing]->(Timeslot)
Where a.firstname = "Ian"
RETURN a as Lecturer,count(*) AS Classes_Weekly
- Find all lecturers lecturing on a monday
MATCH (n:Lecturer)-[:Lecturing]->(m:Timeslot) WHERE m.slotid contains 'mon'
RETURN n,m
- Shortest path between Ian and Deirdre
MATCH p=shortestPath((l:Lecturer {firstname:"Ian"})-[*]-(n:Lecturer {firstname:"Deirdre"}))
RETURN p
- When are lecturers lecturing at the same time
MATCH p=(l:Lecturer)-[:Lecturing]-()-[]-(n:Lecturer)
RETURN p
- This is a union query example to find lecturer on a friday and find when graph theory is on a friday
MATCH p=(l:Lecturer)-[]-(t:Timeslot)-[]-(g:Group)
where t.slotid Contains'fri' and t.classtype="Lecture"
RETURN p
UNION
Match p=(m:Module)-[]->(tt:Timeslot)
where tt.slotid Contains 'fri' and m.modulename = "GRAPH THEORY"
RETURN p
Below here are design ideas that I chose not to go ahead with as they did not suit the project design in this case but are useful for future projects.
In my second last db design I was using represented time as day nodes rather than timeslots while it would work for querying it just didnt seem to sit well with me so I chose not to stick with that design the csv files are in the not in use folder in the tidy data folder.

The graphaware framework is a useful one that works with neo4j and spring(Java) which also uses a REST api. It can be used with neo4j by itself to quickly create a tree of nodes and relationships to reperesent date & time as neo4j doesnt have a very good built in way of designing that and this also saves you time in having to design a calander for a long date range.
To enable the framework you need to download the jar file put it in the plugin folder of the neo4j install directory C:\Program Files\Neo4j CE 3.1.2\plugins.
You then need to edit the neo4j.conf file by adding the following line to the file,
dbms.unmanaged_extension_classes=com.graphaware.server=/graphaware
To use the timetree library you need to download the jar, do the same as before and put the jar in the plugin folder C:\Program Files\Neo4j CE 3.1.2\plugins.
Then restart the neo4j server and log into your db.
The next step is to run a query try the following and see that it creates a tree with nodes, relationships and properties for yyyy-mm-dd.
$ CALL ga.timetree.range({start: 1491811200000, end: 1492189200000, create: true})
Note the numbers in the query, Neo4j measures the time in milliseconds between the dates of 2017-04-10 to 2017-04-14 however the first number is actualy the time its been since the Unix Epoch.
I didnt use these plugins because they would'nt work in this project with the design I have choosen, I choose to go with a simpler design because I was having issues with getting the framework to build the nodes that had weekday names that matched the date nodes, I also had an issue to change the resolution : (default is day) to hours. I felt it was better then to go with a simple prototype design for the day & time representation in the database as I didnt have enough time to use this approach to represent time even tho I think it would have worked great.
My conclusion for this project is that neo4j and graph databases are very useful tools to use in representing data altough representing a timetable can be a hard thing to do properly because its an np hard/complete issue. The reasons I have learned how it is usefull is due to the fact that neo4j offers a great way to query a db and get results quickly no matter the db size which is extreamely useful in modern db's where as relational databases tend to become much slower as they get larger. Another big benifit of using a Graph db over a relational db is due to the fact that there is much more freedom with adding, updating and deleting data where as in a relational db you have to worry about strong referental integrity, also graph dbs are a great alternative to other types of nosql db's because they offer their own ways to enforce some for of constraints on data in the db so that there isnt a total lack of control on inconsistent data. There are many other reasons a person might like a graph database such as it is easy to learn how to use one and its a great way to get a db up and running quickly and its free software , hell yeah. So overall im happy with my experience of learing neo4j and i even learned that there are a lot of third party plugins that work with the program.