Adopt TypeScript for core package#1877
Conversation
 ang-zeyu
left a comment
ang-zeyu
left a comment
There was a problem hiding this comment.
Nice work on this huge environment change 👍, just a brief look:
Some files are not yet duplicated to .ts, would like some assistance on whether we should do it or keep it as-is:
Ditto on the 2nd.
As for the other files, I'm thinking - as long as we've adopted it from somewhere considerably in its original code style, we keep it as is for now, since we may need to cross-refer the original external implementation. (e.g. convert HighlightRule but not double-delimiter.js)
As for the "midway" ones like markdown-it/index.js which are more subjective, I'm leaning toward converting them for now as type annotations may be helpful for development.
Publishing requires an additional manual build step because the build returns an error exit code (due to the files not adopting the type system yet), meaning we can't put this as a part of the npm lifecycle methods (it will abort as error). Added documentation on projectManagement.md for this.
👍
|
@jonahtanjz @ang-zeyu I found a way to suppress the error exit code when running the build, so now I can put the build script as part of the npm's lifecycle scripts, but it's admittedly quite hacky (just string the command with However, it still outputs a ton of TypeScript error logs as part of the job (see the |
Will this suppress legitimate errors from typescript as well (e.g some files failed to compile)? If it does, the developer doing the release may not be aware of the errors and broken/missing files may get published? Not sure if this is a potential issue? |
Good concern. I just found out that even if you write a broken To guard against publishing compiled files that have these errors, I think we can chain the lifecycle scripts with For context, the reason why I went with the hack is that our checks fail when core is not yet compiled (see the checks for |
|
@ang-zeyu @jonahtanjz I have adapted to the new strategy as outlined in #1877 (comment). This way, the hack to suppress error exit code is not required. However, this strategy brings a problem about keeping the file history. To retain the file history of the The answer in the StackOverflow ref above is to rename first, then commit, then change. I tried just that for my working branch (e.g. cf88527 then 31c6412), however in this PR I think it is now compared against master instead, so the totality of the two commits will still make the file be regarded as a deletion and addition. Unless, we rename the files first, merge it to master, then fix it, which brings us back to the old strategy 😅 In my opinion, I think it is better to stick to the new strategy, but not sure whether this is agreeable to us. Any thoughts? (Edit: I think I can work around all this and adopt a balanced migration that can introduce types and keep the similarity index high, but no guarantees all files can be done this way, e.g. |
From what I am seeing, most of these files that you've mentioned don't have a lot of commit history (except for |
|
Would this work?
Was going to suggest some commit organisation for large PRs like this near the end so you don't have to use a fixup workflow, might make sense it to do it now perhaps. Something like this:
|
|
Btw, I remember seeing a comment about converting |
Sorry, can you clarify about this? Not sure which this is targeted to (in the working branch / target branch). I mentioned that splitting the rename and changes into separate commits can still retain the history in the working branch, but when diffed to the target branch, the history is lost. Assuming you mean those commits are in the target branch, it could be possible. I just tried to play around in my code playground, I noticed that the history is lost only when using the squash strategy. When merged with a normal merge commit, the history is retained in the target branch. I think the key here is that we must keep those two commits separate in the target branch. I guess this calls for a multi-commit PR with a normal merge commit? I might need to get this organized if that's the case.
👍 This structure is a good start. Should I follow the rename-adapt commits for the test files as well (assuming we also want to retain the history for test files)? Or I can also put the renaming of test files on the same commit as the renaming of code files? Also just to confirm, I would structure this through soft reset and commits, but then I have to force push to here, right? Or do I need to create another PR for the clean one? |
Oh yeah, I deleted it and wanted to put it as an edit of a comment but forgot to 😅 I think the |
No, I missed this part.
Not getting this part with the above though, would a merge commit be subject to the same issue if so? 👀 (working -> target)
Feel free to try it out. Anything reasonable and clear enough (not too much in one commit) is fine : ) example merge commit PR if needed:
Yup. I've bumped the relevant "guide" from last year in telegram as well if you need it. (note the part on fixups too) |
I found out that it's not the case, that is the history is retained when the separate commits are merged with a merge commit. Here's a small demo I cooked up, where I tried to do both strategies. The file history in the working branch is like so ("Slowly adapt..." is the renaming commit, "Fully adapt..." is the fix commit, and the rest is history from master):
If I merge this branch to master with a squash commit, the history is lost (see the blame and git log --follow):
While if I merge it with a merge commit, the history is retained (see the blame and git log --follow):
|

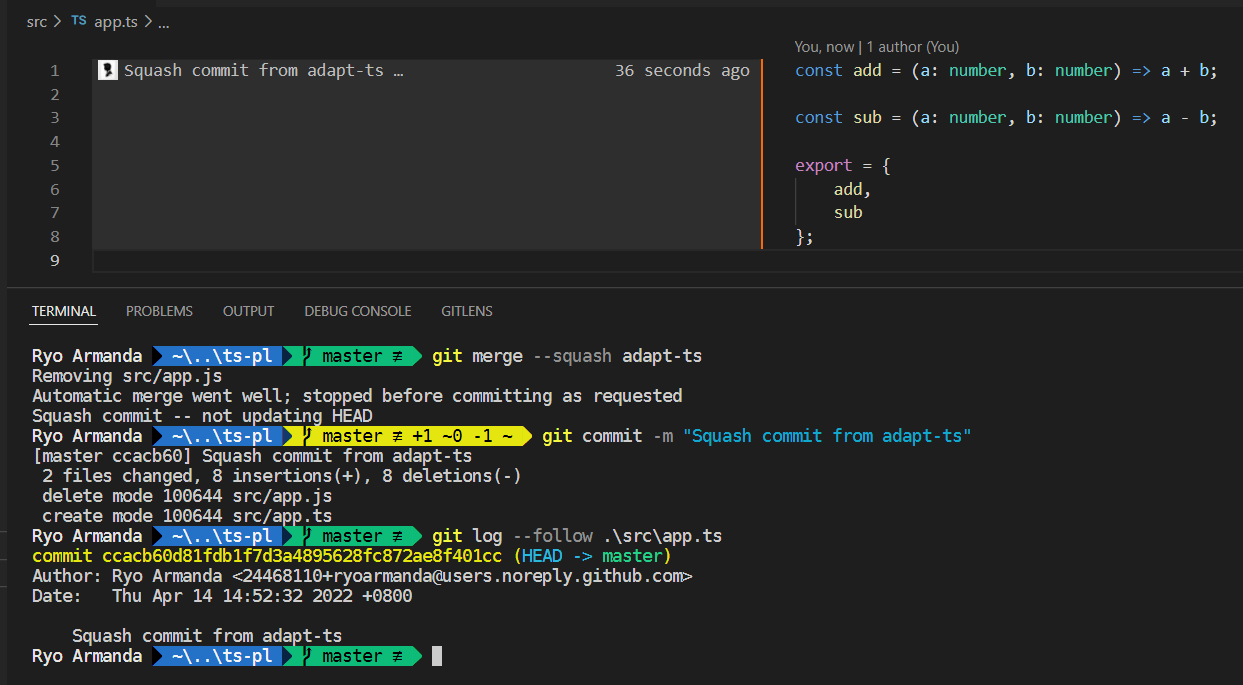
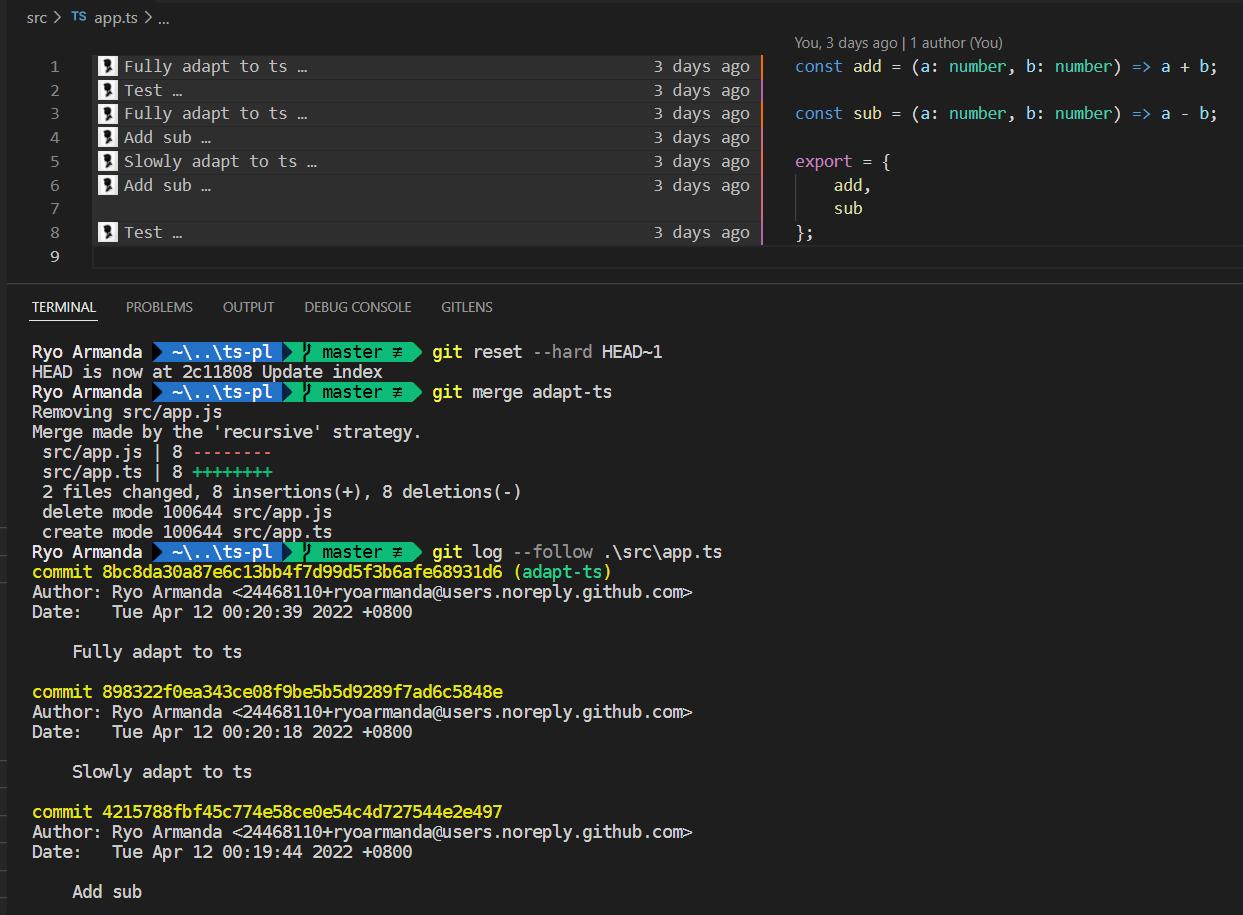
Thanks for testing 👍, ok let's go for that then. Fyi I was suggesting merge commit (otherwise no point in structuring the commits here). Though, still not too sure on it ( There are a couple of alternatives we can try if that (github merge) fails too -- reverting the merge and do it manually:
Hopefully github's merge commit is sufficient. :-) |
6da0221 to
e3fbd4f
Compare
ang-zeyu
left a comment
There was a problem hiding this comment.
Nice work organizing the commits, a breeze to read through 👍
Just in case the "guide" is unclear: you can deliver the changes using "fixups" in this way for a reviewer
E.g. if "add initial typescript support" and "add typescript migration and development docs" had comments,
Add initial typescript support
Rename starter files to TypeScript
Adapt starter files to TypeScript
Add TypeScript migration and development docs
# Add these 2 commits
Fixup: Add initial typescript support
Fixup: Add TypeScript migration and development docs
Once the fixups are reviewed again, you can use git's fixup feature or interactive rebase (my personal preference) to squash them back into 4 commits.
8466ce9 to
7d5ca85
Compare
|
Thanks for the weekend reviewing @ang-zeyu 🙇 I pushed some WIP stuff earlier haha. Some parts of the docs and the scripts are a little bit different now as I discovered more quirks along the way. Feel free to do another read through, and I will check out your comments in the meantime. |
 jonahtanjz
left a comment
jonahtanjz
left a comment
There was a problem hiding this comment.
Couple of suggested changes
|
I'd like to ask for advice about the migration specifics:
As a reference, here's our internal dependency graph for core at the current point in this PR (only js files, leaving out lib, patches,
|
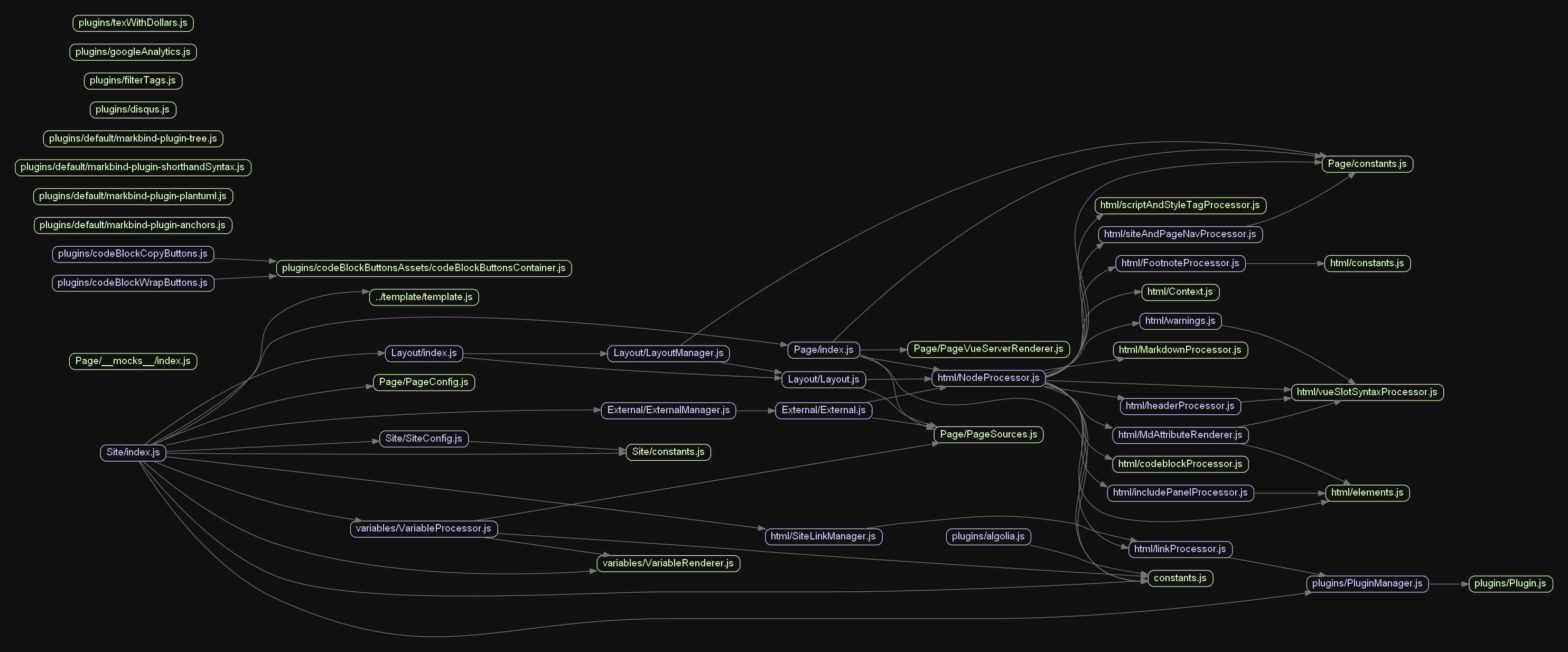
|
No comments on the second fixup, nice work with tailoring all the linting configurations 👍 |
Agreed. Though, I don't really have a preference on enforcing this. It might become apparent to anyone who tries to do some conversion that we should proceed in topological order. There might also be better ways at this we can't think of right now 🤔
I think one of the main motivations for adopting typescript is avoiding mistakes from this. I'm favouring something along options 1 & 3 as such, to deal with this on a case-by-case basis. // e.g.
const x = node.name as string; // forcibly "recast"I think we might figure out better solutions as we go along in other conversion PRs though, I can't really say for sure right now. One alternative worth sharing (but likely not applicable in this case) I came across in my previous internship was to override @types declarations in a custom |
ce939e8 to
52a6223
Compare
|
Have fixed the wording nits @ang-zeyu , also updated tsconfig as I found out that |
ang-zeyu
left a comment
There was a problem hiding this comment.
Lgtm 👍
Let's squash the fixups in and rebase this over the latest commit on the main branch (so it goes in "immediately after" - just to keep things neat)
|
You can it merge in after if @jonahtanjz has nothing else to add : ) |
jonahtanjz
left a comment
There was a problem hiding this comment.
Nice work @ryoarmanda 👍
LGTM :)
a34f5c9 to
662fe14
Compare
|
Okay, will do the merge tonight. Will update on the merge results on whether we need |
662fe14 to
4a35c48
Compare
|
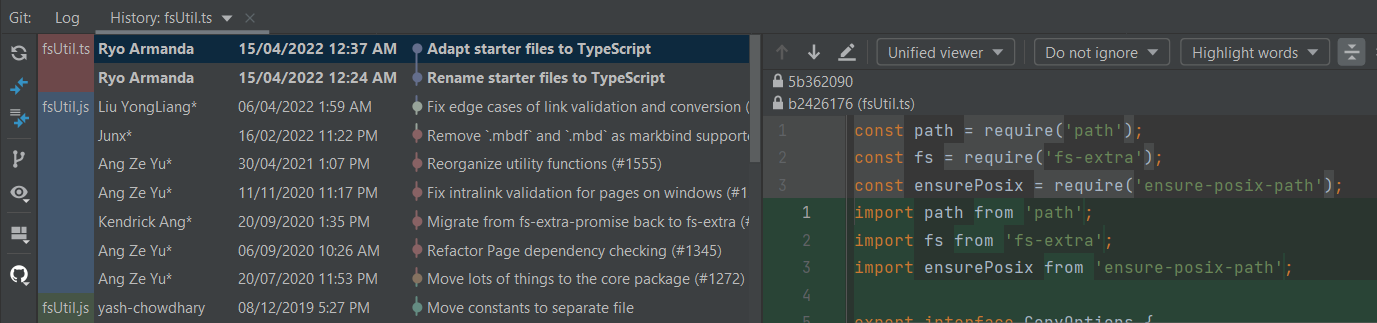
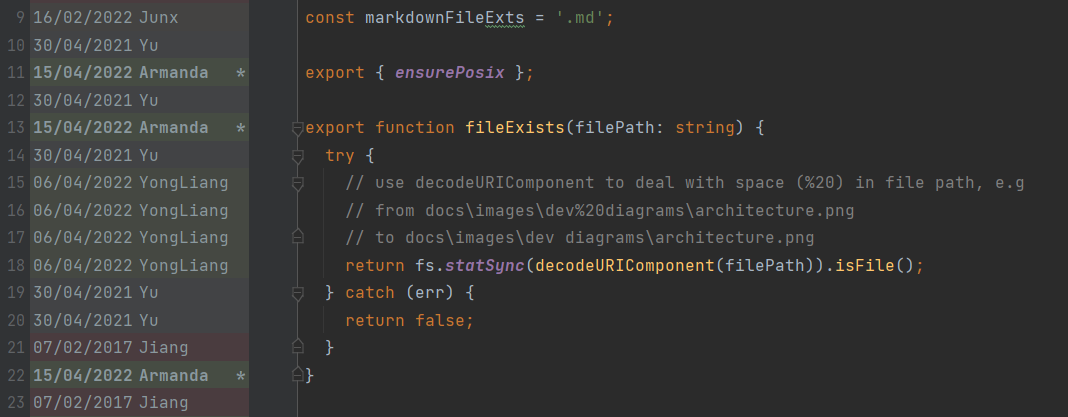
@ang-zeyu To report: I believe the merge process is working well, but the matter of displaying the history differs from the situations below. GitHub history does not follow renames by design, WebStorm's history and annotate follow the rename out of the box, and VS Code (+ GitLens)'s has to modify some settings in order to follow renames and ignore whitespaces. Here it is in WebStorm checking
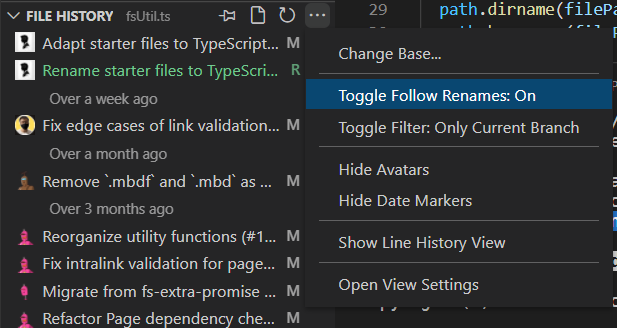
In VS Code (+ GitLens):
(
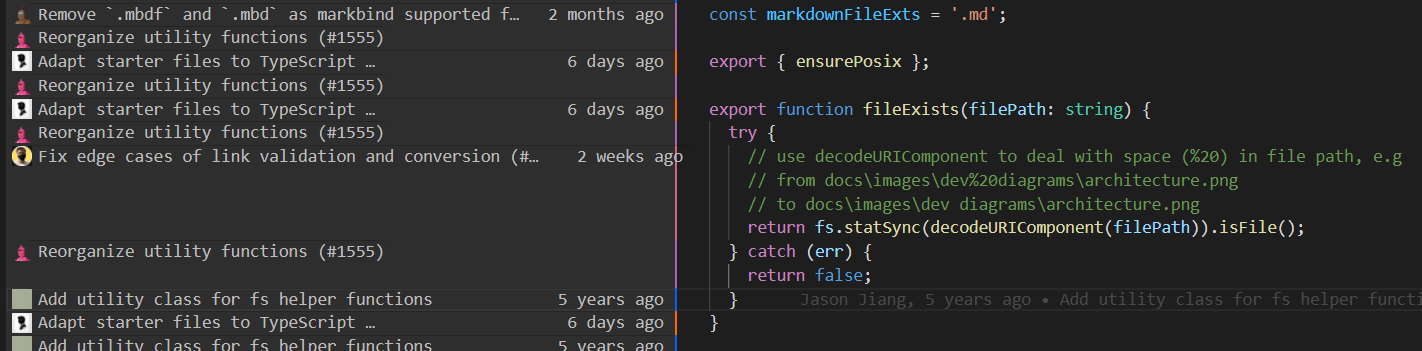
And in GitHub:
(GitHub's situation is unavoidable for now, the follow renames has been requested since 2009 and hasn't seen the light since... discussion tracker) |
|
Thanks for investigating @ryoarmanda, this is new to me as well. I think not much we can do here since it depends on the git client involved. (unavoidable for github; for vscode since its a preference, we can leave it up to individual developers) Noticed as well with cli Other git clients:
For later merges, we could try a manual merge with --rename-threshold option mentioned earlier to see if it fixes the " |
What is the purpose of this pull request?
First phase of #1421
Overview of changes:
(Edited as of 17/04)
Some of the
.jscode files incorehave been renamed as.tsfiles and adapted into TypeScript as a starter.See the documentation on migrating to TypeScript: https://deploy-preview-1877--markbind-master.netlify.app/devguide/migratingtotypescript
Workflow of
coreand by extension the whole project are slightly changed:npm run build:backendto build the TypeScript files,npm run cleanto remove built files, andnpm run devto start the development environment which builds the files and automatically rebuilds on changesnpm run dev.npm run buildto build the TypeScript files,npm run cleanto remove built files, andnpm run preparewhich is explained in Installation and Publishing belowprepareis added in core which doesnpm run buildand automatically runs as part of installation of the package (npm run setup)..js.map) which provides the ability to directly debug.tsfiles (e.g. put breakpoints, etc)typescript-eslintis integrated toeslintto enable lint on.tsfilesnpm run lintnow lints.tsfilests-jestis integrated tojestto perform direct unit tests to.tsfiles without the need to manually build themcliwill require for the files to be built first.d.ts) and their maps (.d.ts.map) for type-checking and definitions support across projectspreparescript in core will automatically run as part of publishing of the package (lerna publish)Anything you'd like to highlight / discuss:
Testing instructions:
Setup test:
npm run setupshould compile the TypeScript files.Development test:
npm run testshould be fine.Development usage test (with linked
markbind-cli): Anymarkbindcommands should be fine.Proposed commit message: (wrap lines at 72 characters)
Adopt TypeScript for core package
The dynamic typing nature of JavaScript can create avenues for subtle
bugs during runtime related to parameter types. Strict typing system,
like TypeScript, can address such cases and benefit development of
MarkBind.
Let's introduce TypeScript to the core package to improve the quality
and security of our codebase. Furthermore, let's adapt starter files
to TypeScript as an example, and document on the steps to migrate other
files to TypeScript for developers.
Checklist: ☑️