Video captioning project using deep learning models.
- Date : 20/01/16 ~ 20/03/13
- Goal :
- 아래의 이미지처럼, video 이미지를 학습하여 영상에 video captioning을 생성하는 것
- 나아가 CCTV 영상을 가지고 영상 내의 객체들이 하고 있는 행동을 captioning log로 남겨서 CCTV 상황을 기록하고 사용자에게 알려줄 수 있다.

<img source : https://github.com/mzolfaghari/ECO-efficient-video-understanding >
- ECO: Efficient Convolutional Network for Online Video Understanding
- (https://paperswithcode.com/paper/eco-efficient-convolutional-network-for)
- 저자 깃허브 주소 (https://github.com/mzolfaghari/ECO-efficient-video-understanding)
- 논문 1차 리딩 완료, 주요 개념 학습 중
- 깃허브 코드 실행을 해보려고 했으나 오류 발생
- 영상을 모델에 넣기 위해서는 통째로 넣는 것이 아니라 N개의 샘플로 나누어서 학습을 시켜야 함
- 영상을 프레임 단위로 나눌 수 있는 코드가 (https://github.com/yjxiong/temporal-segment-networks#extract-frames-and-optical-flow-images)에 있으나 make과정에서 'E: Unable to locate package libboost1.55-all-dev' 오류 발생
- 프레임 추출 대신 우선 본 코드를 다시 실행해보려고 했으나 pre-train 파일이 없어서 막힘.
- 위에서 언급한 ECO 논문을 기반으로 한 코드를 사용하여 프로젝트를 진행하려고 했음.
- 그러나, 코드 양이 상당히 방대하고 오류 사항이 너무 많아 우선 다른 코드를 찾아보기로 함
- 좀 더 쉽게 구현이 가능한 코드를 먼저 찾아보고 ECO paper에 있는 이론들을 적용해보려고 함.
- 새로 찾은 코드는 video-caption.pytorch(https://github.com/xiadingZ/video-caption.pytorch)로 좀 더 쉽게 구현이 가능해보임
- 튜토리얼을 따라 데이터를 받고 코드를 진행하는 중에 영상 프레임 단위로 쪼갠 이미지들이 네트워크에 크기와 매칭되지 않는 오류가 발생함 "RuntimeError: size mismatch, m1: [12000 x 2048], m2: [4096 x 512] at /opt/conda/conda-bld/pytorch_1579022034529/work/aten/src/THC/generic/THCTensorMathBlas.cu:290"
- 해당 오류를 디버깅하기 위해 코드를 분석했으나 네트워크 layer에 대한 부분을 찾지 못함
- 이미지 파일을 확인 해보려고 했으나 npy로 되어있어 불러오는 방법을 찾는 중임.
- video-caption.pytorch(https://github.com/xiadingZ/video-caption.pytorch)을 구현하기 위해 다양한 시도를 해봄
- 환경을 구축하고 github에 있는 튜토리얼을 따라 실행하는 중
- Train.py를 실행시켜서 비디오 파일을 프레임 단위로 나누고 .npy파일로 변환하여 Feature를 추출하는 작업을 함
- Train.py 코드를 실행시켰을 때 Feature들이 추출되었고 모델의 weight파일이 생성되었으나
- Eval.py 코드를 통해 모델 평가를 진행하려고 했으나 오류가 발생함
- 구동에 필요한 파일이 없는 것으로 보임
- video-caption.pytorch(https://github.com/xiadingZ/video-caption.pytorch)
- 필요한 데이터 다운로드
- Eval.py를 실행
- Eval.py에 필요한 데이터셋의 가중치 파일이 없어서 오류가 나는 것으로 보임
- 코드와 Github를 분석해본 결과 Video Captioning에 대한 결과물이 나오는 부분을 찾지 못함
- 영상 데이터에 대한 Feature 추출, model 학습까지는 가능한 코드지만, 최종적으로 결과물(캡션이 달리는 영상)이 나오지 않는 코드라고 판단됨
- 다시 ECO: Efficient Convolutional Network for Online Video Understanding로 돌아가기로 결정함
- ECO 논문 코드 구동에 필요한 작업 진행
- ECO 코드의 선처리 작업으로 필요한 TSN을 진행하는중
- Docker 학습
- ECO 코드의 선처리 작업으로 필요한 TSN을 구동하려고 했으나 개발환경이 달라서 구동이 안됨
- 구글링을 통해서 간단하게 실행해보려고 했으나 Docker를 조원 전체가 다뤄보지 않아서 어려움이 발생함
- 같은 개발환경을 만들기 위해 개인적으로 Docker를 공부
- ECO video captioning 구동을 위한 영상 데이터 프레임 추출 진행
- UCF101 dataset을 사용하여 video 목록 별로 폴더를 나누고 개별 video 파일을 기준으로 영상 프레임을 추출
- dataset.py, gen_dataset_list.py 파일 코드 분석 중
- ECO pytorch 사용법을 따라 구동을 진행했으나 파일 경로를 찾지 못한다는 에러가 계속적으로 발생함.
- 코드 내에 경로 문제이거나 train과 validation을 나누는 tuple 형식의 datalist의 양식과 프레임 파일이 맞지 않아 오류가 발생하는 것으로 예상됨
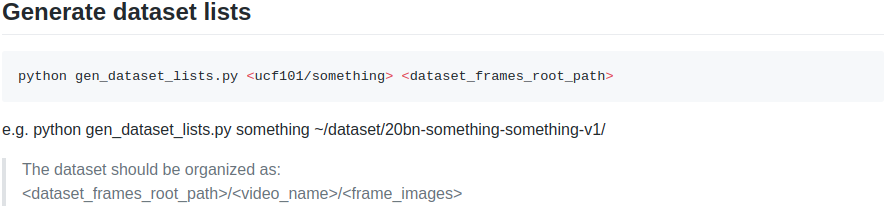
- 위의 이미지와 같이 Generate dataset lists 부분을 진행
- 예제에 보면 python gen_dataset_lists.py ucf101 <프레임추출 파일 경로>로 입력하라고 되어있음
- frame 이미지 파일을 <dataset_frames_root_path>/<video_name>/<frame_images> 형식으로 정렬하라고 되어있음
- 기존에 오류가 나던 경로 정렬은 ./dataset/UCF101/<영상분류폴더>/<개별영상폴더>/<추출된프레임이미지> 순으로 했으나 오류가 발생함
- 오류 수정 중에 변경한 정렬 방식은 ./dataset/UCF101/<개별영상폴더>/<추출된프레임이미지> 순으로 하였다.
- 새로운 방식으로 정렬하니 gen_dataset_lists.py가 정상적으로 작동하고 dataset_list.txt 파일을 생성하는데 성공함
- 이후에 ECO 파일의 demo를 구동하려고 하니 key error가 발생함
- 모델을 학습시키고 weight 파일을 생성하는 main.py 코드를 실행시키는데 성공함.
- 계속적으로 발생했던 문제가 경로를 찾지 못하는 것이었고 또 CUDA OUT OF MEMORY 에러가 발생하는 것이었다.
# main.py 실행에 필요한 코드
python main.py ucf101 RGB <ucf101_rgb_train_list> <ucf101_rgb_val_list> \
--arch ECO --num_segments 4 --gd 5 --lr 0.001 --lr_steps 30 60 --epochs 80 \
-b 32 -i 1 -j 1 --dropout 0.8 --snapshot_pref ucf101_ECO --rgb_prefix img_ \
--consensus_type identity --eval-freq 1- 이 코드를 실행시키면 항상 오류가 발생하여 진행 할 수 없었으나, batch size를 32에서 16으로 줄이니 병렬 GPU에서 코드가 구동되었다.
- 또한 epoch이 지나치게 높은 편이었고 epoch을 많이 준다고해도 loss는 이미 수렴하여 모델이 개선되지 않았기 때문에 epochs는 5번 정도로 설정하였다.
- 또한 CPU에서 GPU로 이미지 파일을 넘겨주는 -j 파라미터를 8로 변경하여 좀 더 빠르게 학습을 시킬 수 있었다.
- main.py를 실행시켰으나 모델 파일만 생성되고 별다르게 산출물이 없었다.
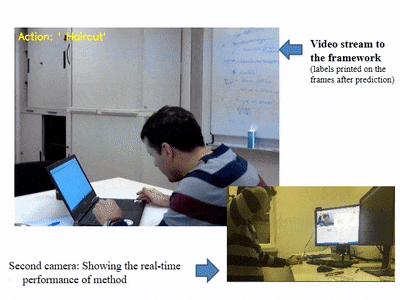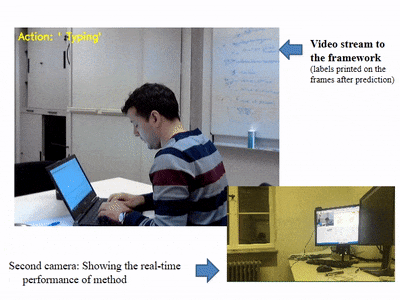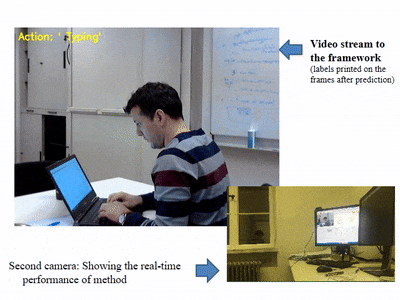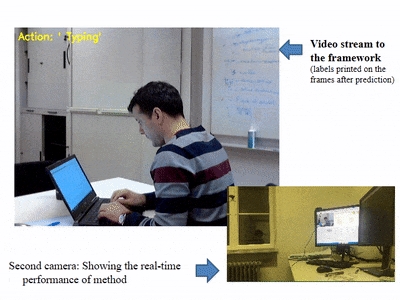
- 영상에 캡셔닝을 진행하고 싶었지만 영상에 대한 demo는 존재하지 않았다.
- ECO 저자의 깃허브를 가보니 모델 부분까지만 코드를 업로드 해놨고 실제 비디오에 적용하는 내용은 없었다.
- 다른 딥러닝 기법(YOLO) 등에서 실시간으로 웹캠 등을 사용하여 디텍팅하는 것에 착안하여 코드를 분석하고
- Train한 모델을 가지고 실제 영상에 적용해보는 방향으로 진행할 계획이다.
- 계속해서 진행하던 ECO를 포기하고 다른 코드를 찾기로 결정했다.
- 찾은 코드는 두개이다.
 |
 |
 |
| a dog is running around a field | a woman is cooking | two men are talking about a cooking show |
- 코드 선정 기준은 우선 간단하고 구동이 가능한 코드로 찾아봤다. 두 코드는 모두 결과물이 영상이 표시되는 코드이다.
- 우선 코드 설명이 자세하고 결과물이 확실하게 나오는 scopeInfinity/Video2Description이 코드를 진행하기로 했다.
- 코드가 python2.7로 되어있어 환경을 설정하는데 어려움이있었다.
- 코드 배포자가 conda 환경을 yml파일로 올려주긴 했지만 패키지들간의 충돌로인해 제대로 환경이 구축되지않았다.
- 하나하나 라이브러리를 설치하는 작업이 오래걸렸다.
- 모델을 Train 시키려고했지만 data_generator에서 오류가 발생하여 제대로 실행되지 않았다.
- 또한 실시간으로 데이터를 웹에서 다운받아 진행하는 부분이 있는데 배포자가 구현해놓은 코드에 있는 URL 홈페이지가 개편되어 더 이상 사용할 수 없는 문제가 있었다.
- Video2Description 코드 오류 수정중
- 사용한 데이터가 MSR-VTT dataset인데 데이터를 다운받았을 때 동영상 파일명이 "video*.map" 형식으로 되어있음
- 코드 중에 int를 리스트에 추가하여 datalist를 만드는 코드가 있었는데 video+숫자 형식으로 들어가버려서 오류가 발생함
- video string을 제거해주고 진행을 했으나 그 방식으로 하니 Train 코드가 돌아가지 않고 오류가 발생함
- 이 부분을 해결하기 위해 데이터 자체에 파일명에서 'video'라는 것을 빼버리고 '숫자.mp4'형식으로 변경해주니
- train 파일이 제대로 돌아감
- 너무 시간이 오래걸려 epoch을 2만 주고 결과를 살펴보려고 했으나 상당히 오래걸림
- keras 코드라 gpu를 가동을 하는지 안하는지 확인하기가 어려움.
Pre-trained Models 다 다운받아 압축풀고 그 중 하나 실행시킴
python parser.py server -s -m /home/pirl/Downloads/project/Video2Description/ResNet_D512L512_G128G64_D1024D0.20BN_BDLSTM1024_D0.2L1024DVS_model.dat_4987_loss_2.203_Cider0.342_Blue0.353_Rouge0.572_Meteor0.256- Preparing for Register Server
- Listening to 5001 메세지가 나오면
# 터미널창 하나 더 열어서 입력.
python app.py실행 후 동영상 업로드하면 비디오 캡셔닝 확인 가능
- 새로운 코드를 찾아 진행해보는 중
- 대용량 동영상 파일 데이터를 받는 중
- Video2Description 코드는 동영상 전체에 대한 묘사로만 끝나는, 정확도가 부족한 코드라고 판단하였다.
- Video2Description으로 학습 데이터 외에 다른 영상을 넣어보니 제대로 된 묘사를 하지 못했다.
- 어두운 저녁에 도로에서 흉기로 위협하여 자전거를 강탈하는 영상이었는데 주변에 차들의 전조등 때문인지 "어두운 배경에서 불빛이 나타나고 있다"라고만 묘사했다.
- 이전에 우리가 다루었던 ECO와 같이 동영상의 각 부분 마다 흐름과 문맥을 파악하여 계속적인 캡셔닝을 생성할 수 있는 코드가 필요하다.
- 새로 찾은 코드는 grounded-video-description이다.
- 데이터 파일을 받는데 상당히 오래걸린다.
- grounded-video-description 실행시키고 코드를 분석하는 단계
- 한 장의 이미지에 대해 dense captioning이 달린 결과물을 얻었다. dense captioning은 아래의 이미지를 참고

- 코드 데모를 실행하여 산출된 결과물


- No mudile named 'pycocoevalcap' 에러가 발생하였는데 사이트마다 제시한 해결 방법이 달라 시행착오를 겪었다.
- train 모드가 아닐 때 evaluation이 실행되어야하나 main 모듈안에 eval 함수는 정의되어 있지만 구동되지 않아 이 부분에 대한 코드를 직접 작성해야 한다.
- evaluation 과정 중에 결과물(dense caption된 이미지)은 생성되나 오류가 발생해 끝까지 실행되지 않는다. 현재 이 문제를 해결중
- grounded-video-description 실행 완료
- evaluation 및 visulization을 위해 코드를 분석하는 중
- 이 코드를 통해 나온 추가적인 결과물들을 얻음.




- 데이터 셋 때문인지 동물에 대한 캡셔닝이 비교적 정확했다.
- 안 좋게 나온 결과들이 있었지만 대부분 괜찮은 캡셔닝을 생성했다.
- 안 좋은 케이스는 정확하게 행동을 캐치하지 못하거나 이미지 내에서 더 중요한 객체보다 주변을 캡셔닝하는 경우였다.
최종 결과:
- 최종 목표로 했던 동영상에 대한 실시간 캡셔닝은 달성하지 못했다.
- 한 이미지에 여러 객체들을 추출하여 캡션을 생성하는 grounded-video-description은 결과물을 산출하는데 성공하였다.
- 동영상에 대한 캡션은 각 영상에 하나의 캡션을 만들어내는 것까지는 성공하였다.
- 하지만 pretrained 모델을 사용해서 그런지 외부 데이터를 test로 넣었을 때는 좋은 결과를 내지못했다.
| # | title | framework | note |
|---|---|---|---|
| 1 | ECO: Efficient Convolutional Network for Online Video Understanding | Pytorch | 핵심 이론 및 실행 코드 참고 |
| 2 | TSN-Pytorch | Pytorch | 영상 데이터 프레임 단위 추출 |
| 3 | video-caption.pytorch | Pytorch | |
| 4 | scopeInfinity/Video2Description | Keras | LSTM, GRU 사용 |
| 5 | grounded-video-description | Pytorch | |
| 6 | a-PyTorch-Tutorial-to-Image-Captioning | Pytorch | Image Captioning |