Grafana dashboard #45
Comments
|
There aren't any public dashboards at the moment, no. We're still trying to decide what our strategy is with that particular distribution option (we have some dashboards internally, but they are earmarked for a separate project that we can't open source yet). If you happen to work on something though, we'd be happy to update our README to point to it! |
|
Hi @joehandzik, I found this Images upstream, but without a Dashboards source. I have to check if those metrics are already exported/supported or not. |
|
Thanks for taking a look, @mjtrangoni! At a glance, it looks like we support most or all of those metrics, so t should be doable to emulate using our Prometheus metrics. Feel free to file an issue if we're missing anything critical. |
|
Hello, is this question still opened? I have developed some Grafana dashboards that I could share with the project if needed. |
|
Maybe post a link to it from the grafana registry? |
|
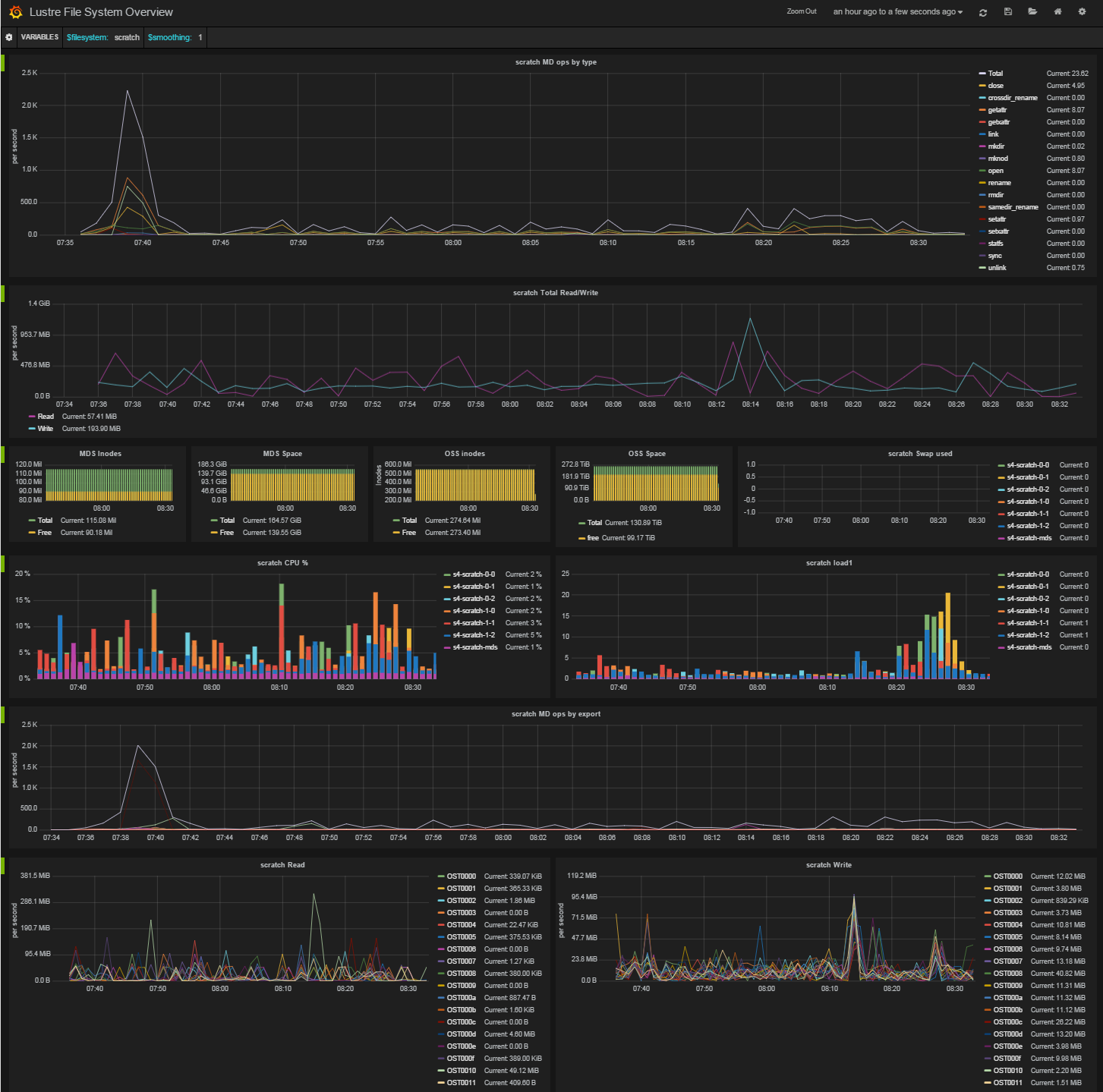
I have made something (screenshot included) but I am not sure it's the right way to visualize Lustre metrics, so I never published it on the Grafana web site:
Any thoughts? |

|
LGTM, I have a similar dashboard at my site with very very similar graphs |
|
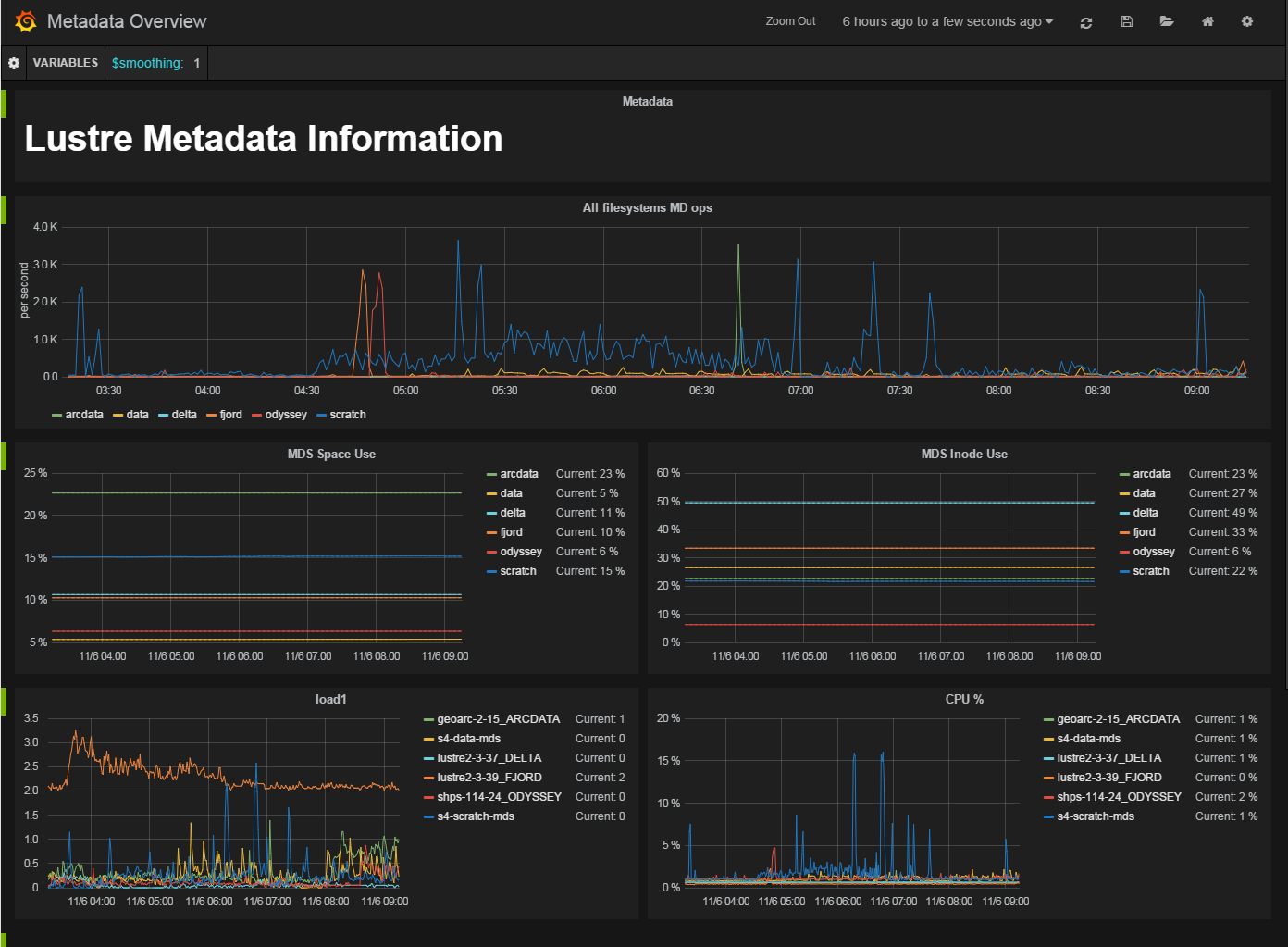
In my case I have 4 different panels but they combine also other non-Lustre exporters for server load or disk utilization:
I'll probably need to triage the non-Lustre exporter stats from the panels (disk utilization, CPU) or we just assume that someone running the Lustre exporter might also be running this exporter as well.
|



{kind=link}
{kind=link}
|
@diegolmoreno just a couple of questions:
The Lustre dashboard I have developed is indeed not particular useful to my colleagues There are ton of metrics exported but aggregation proved to be quite difficult and If anybody is willing to add comments/insights/prometheus queries on this thread I would |
Jobstats and Grafana has been without any doubt the most painful thing on this setup. The reason is that having sometimes up to 4k jobs running on the cluster the amount of stats generated on the jobstats side is massive. For that reason you cannot be very greedy when trying to integrate jobstats in Grafana. You need to find a good compromise between resolution and information or your query will time out. We created a specific jobstas panel and from there we can go to another panel for all specific details about a job in particular. |
|
Hey all, Sorry for the radio silence across a lot of this repo, we've been heads down on some different work for a bit. In general, I think given the variety of dashboards that folks are discussing here, I think we'd be more than happy to collect links to wherever others are uploading their dashboards (Grafana's website or even your own repos, similar to what @jcftang suggested). That way the dashboards can evolve separately from our codebase here, and it provides flexibility to link to dashboards that go beyond the Lustre export (like @diegolmoreno's). Based on the response that @diegolmoreno just sent, some of the same issues we've run into have been experienced by others. You really need to balance needs vs wants, as was mentioned. We have waffled back and forth on if it was a design "mistake" to enable the exporter to generate that massive amount of data, but it seems folks are finding a way to use it beyond just us. It seems like Prometheus itself does a decent job of keeping up with the metrics that Lustre can spit out, IMO the problem is that Grafana chokes on large amounts of data. It's worth ongoing investigation for sure. Appreciate the ongoing discussion here. |
|
As @joehandzik said, Grafana is not meant to present a dashboard with dozens of panels I have also enabled Lustre job stats on our (Slurm) side but I found it difficult to integrate them On the Prometheus side, if you want to push these metrics you may fall on 'batch jobs' on a I have used a method which is also proposed on the 'Lustre Statistics' wiki page and it The output could be useful on the fly: >>> lctl get_param *.*.job_stats | perl /usr/local/sbin/show_high_jobstats.pl -s 1000000000
[...]
Job 24141632 has done read operations with sum of 2,547,593,216 bytes.
Job 24141632 has done write operations with sum of 59,826,833,885 bytes.
Job 24381103 has done read operations with sum of 1,786,433,536 bytes.
Job 24381103 has done write operations with sum of 1,149,587,115 bytes.
Job 24381143 has done read operations with sum of 1,780,846,592 bytes.
Job 24381143 has done write operations with sum of 1,149,688,421 bytes.Also, the type of operations executed by a certain job (above a certain threshold) can >>> lctl get_param *.*.job_stats | perl show_high_jobstats.pl -o 100000
Job 24141632 has done 237650 write operations.
List of found job IDs: 24141632but I still did not find an easy way to integrate this kind of information into a dashboard in a meaningful way. Another issue is aggregation: how to aggregate info about all the OSSs for certain metrics? |
|
Hi all, First of all sorry for the radio silence in the last couple of months. I had other stuff and some dashboards needed some refactoring to be shareable. I've finally uploaded in the Grafana repository our 4 dashboards that use the prometheus data exported by the lustre exporter here but also by node exporter (CPU, load, memory, etc...). Just be aware that there're lots and lots of information, some people will find all they need in just 1 or 2 dashboards, others might end up removing some panels, it's up to you. The dashboards:
We hope this helps the Lustre community as much as this exporter did to us. Comments or any bug reporting are welcome. |
|
@diegolmoreno thanks for the dashboards. I had a flick through the dashboard definitions and I couldn't see anything which used the metrics exported when using the client flag? Do the dashboards only show metrics from the ost/mdt/mgs/mds side of things? |
|
There're unfortunately no client stats dashboard since I only run the
exporter on the servers and not on the thousands of clients I have though
this could be a nice option in the future.
…On Tue, 2 Feb 2021 at 12:42, Steve Brasier ***@***.***> wrote:
@diegolmoreno <https://github.com/diegolmoreno> thanks for the
dashboards. I had a flick through the dashboard definitions and I couldn't
see anything which used the metrics exported when using the client flag? Do
the dashboards only show metrics from the ost/mdt/mgs/mds side of things?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#45 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AFJ76FUF7JZBVG5VFD4POT3S47QJXANCNFSM4DK7GA6A>
.
|
Is anyone already working on a (public) Lustre dashboard for Grafana using
Prometheus as a data source?
My search in the Grafana dashboard community didn't turn up with a match.
The text was updated successfully, but these errors were encountered: